A French corpus annotated
for multiword expressions
and named entities
Marie Candito1, Mathieu Constant2, Carlos Ramisch3, Agata Savary4, Bruno Guillaume5, Yannick Parmentier6,7 and Silvio Ricardo Cordeiro1
1Université de Paris, CNRS, LLF 2Université de Lorraine, CNRS, ATILF 3Aix Marseille Univ, Université de Toulon, CNRS, LIS
4Université de Tours, LIFAT 5Université de Lorraine, CNRS, Inria, LORIA
6Université de Lorraine, CNRS, LORIA 7Université d’Orléans, LIFO
ABSTRACT Keywords: multiword expressions, annotation, corpus, French We present the enrichment of a French treebank of various genres with
a new annotation layer for multiword expressions (MWEs) and named entities (NEs).1Our contribution with respect to previous work on NE and MWE annotation is the particular care taken to use formal criteria, organized into decision flowcharts, shedding some light on the inter-actions between NEs and MWEs. Moreover, in order to cope with the well-known difficulty to draw a clear-cut frontier between composi-tional expressions and MWEs, we chose to use sufficient criteria only. As a result, annotated MWEs satisfy a varying number of sufficient criteria, accounting for the scalar nature of the MWE status. In addi-tion to the span of the elements, annotaaddi-tion includes the subcategory 1For verbal MWEs, we have reused the annotation performed within the PARSEME COST multilingual project (Savary et al. 2017), so the present article focuses on named entities and non-verbal MWEs.
of NEs (e.g., person, location) and one matching sufficient criterion for non-verbal MWEs (e.g., lexical substitution). The 3,099 sentences of the treebank were double-annotated and adjudicated, and we paid attention to cross-type consistency and compatibility with the syntac-tic layer. Overall inter-annotator agreement on non-verbal MWEs and NEs reached 71.1%. The released corpus contains 3,112 annotated NEs and 3,440 MWEs, and is distributed under an open license.
1 INTRODUCTION
Multiword expressions (MWEs) such as idioms (e.g., dead end, break the ice) and light-verb constructions (e.g., make decision) have been the focus of a vast amount of linguistic studies and annotation projects (re-viewed in Section 2). The idiosyncrasy at the heart of the concept of MWE is a challenge for any linguistic theory and disrupts automatic processing, as MWEs mix idiosyncratic and regular patterns. Because of their partly unpredictable behavior, MWEs have been widely listed in lexicons and annotated in corpora. Yet, for many languages, MWE-annotated resources are generally not associated with operational de-cision criteria, the guidelines being often reduced to examples of the various MWE categories.
Corpora annotated for named entities (NEs) such as person (e.g., Theresa May) and location (e.g., Colombia) also abound in many lan-guages.2 However, the overlap between MWEs and NEs has rarely been studied. Given these challenges, our first objective is to provide operational criteria for defining MWEs on the one hand and NEs on the other hand, so that both categories can be precisely distinguished and annotated within the same framework. Secondly, we test the pro-posed criteria against actual annotation in a French corpus. We chose not to use pre-existing MWE and NE lexicons, to avoid biases, but we use post-annotation coherence checking tools to improve cross-type consistency of annotations.
2Our work covers single-word and multiword NEs. Although multiword NEs can be considered MWEs, hereafter we reserve the term MWE for expressions that are not NEs, see Section 3.2 for details.
A fundamental trait of our approach is to model the MWE status in parallel to the syntactic layer: depending on its distribution and in-ternal pattern, a given MWE can be considered syntactically regular, hence receiving a regular internal structure. Another originality stands in our choice to use sufficient criteria for the MWE status, in order to cope with their varying degree of idiosyncrasy. Indeed, when applied to non-prototypical MWE examples, MWE criteria may often contra-dict each other. We thus opted for sufficient criteria, instead of relying on a subjective quantification of how many and which criteria should prevail. The resulting resource thus comprises annotated MWEs with varying degrees of idiosyncrasy.
The remainder of this article is organized as follows: in Section 2 we discuss related work, covering the general MWE definition and ty-pologies, their annotation in corpora, and NE annotation. In Section 3, we present and motivate the main distinctions we made, in particu-lar between NEs and MWEs, and present our typologies. Section 4 describes the formal constraints for our MWEs and NEs, and the top decision flowchart guiding the annotators to the various sub-guides. Section 5 is devoted to the guidelines for NEs, Section 6 summarizes the guidelines for verbal MWEs defined in the PARSEME project, and Section 7 describes our guidelines for non-verbal MWEs. In Section 8 we describe the source corpus, the annotation process and annotation quality. Section 9 is devoted to the interaction between MWEs and syntactic annotations. Finally, we present various statistics for the re-sulting resource in Section 10, we mention some lessons learned from the project in Section 11 and we conclude in Section 12.
2 RELATED WORK
This section presents some of the previous work in the field of MWE and NE annotation. Due to their extensive use in multiple information extraction tasks, NEs have received by far much more attention than MWEs in the last two decades. We have thus decided to put a stronger emphasis on prior work in MWE annotation. We first provide various definitions for the term “multiword expression” that encompasses a wide body of linguistic phenomena (Section 2.1). Then, we summarize
existing MWE typologies (Section 2.2). Next, we present emblematic initiatives for MWE-annotated corpora and treebanks, focusing on the criteria and tests used (Section 2.3). Finally, we synthesize the large body of work on NE annotation in corpora (Section 2.4).
2.1 MWE definitions
The term multiword expression (MWE) has emerged in the natural lan-guage processing (NLP) community in the early 2000s, notably in the famous paper of Sag et al. (2002). The authors roughly define MWEs as “idiosyncratic interpretations that cross word boundaries (or spaces)”, emphasizing the unpredictability of their linguistic behav-ior. This informal definition actually captures a wide body of hetero-geneous linguistic phenomena, including phrasal verbs, idioms, light-verb constructions, complex function words, and nominal compounds. Since then, many other definitions have been proposed (Constant et al. 2017). Among others, Baldwin and Kim (2010) propose a more pre-cise definition, stating that MWEs are “lexical items that: (a) can be decomposed into multiple lexemes; and (b) display lexical, syntactic, semantic, pragmatic and/or statistical idiomaticity”. They provide an overview of the main properties for every type of idiomaticity, as well as a simple procedure to test whether a candidate word combination is an MWE or not, by testing all types of idiomaticity. Still, this definition is not operational because it does not indicate the precise individual idiomaticity tests to apply systematically. NLP researchers tend to give rough definitions of MWEs, and illustrate them with lists of categories and examples to specify the concept denoted by the term. These usu-ally emphasize the idiosyncratic nature of these expressions, and the difficulty to process them from a computational (linguistic) point of view. There are several reasons for this vagueness.
First, the status of MWEs is not clearly defined from a linguis-tic point of view. As they are located at the lexicon-grammar inter-face, their definition depends on the underlying linguistic framework. MWEs are highly related to phraseology, a historical field of linguistics in which researchers have been extensively describing MWEs for sev-eral decades. Mel’čuk (2012) goes even further, stressing that “there is no agreement on either the exact content of the notion of ‘phraseol-ogy’, nor on the way phraseological expressions should be described,
nor on how they should be treated in linguistic applications, in partic-ular, in lexicography and Natural Language Processing”.
Second, from an NLP point of view, MWEs embrace word combi-nations that need to be considered as units at some level of linguistic processing (Calzolari et al. 2002). As a consequence, in NLP, the set of considered MWEs heavily depends on the target application. For instance, Copestake et al. (2002) suggest that idiomatic expressions with regular syntactic structures are of no use in a system producing syntactic trees.3 Furthermore, NLP models heavily rely on linguistic resources, in particular MWE resources in case of MWE-aware models. The role of precisely defining MWEs is therefore entrusted to the re-source designers. Indeed, building an MWE-aware rere-source requires a set of operational criteria to identify them: either to create and encode MWE entries in lexical resources, or to annotate them in corpora.
Formal criteria are especially useful to operationalize (vague) MWE definitions. Historically, formal criteria have been designed mainly for lexicographic purposes, on top of linguistic studies. Such criteria are usually based on the fact that the fixedness of one or several component(s) of a candidate MWE entails some idiomaticity. Fixedness is characterized by the fact that applying a transformation to a given MWE leads to unexpected meaning shifts or unacceptable sequences compared to similar linguistic contexts. For instance, the MWE from time to time does not accept modifier insertion (e.g., *from a time to another time), whereas in similar linguistic contexts this is ac-cepted (e.g., from place to place vs. from a place to another place). Gross (1986) applies formal criteria to classify and encode the properties of MWEs in a syntactic lexicon in French, the so-called lexicon-grammar tables.4 This formal approach largely inspired the guidelines used to annotate MWEs in various French corpora (Abeillé et al. 2003; Laporte et al. 2008b,a). It led to new definitions such as the one in Laporte et al. (2008b), who consider “a phrase composed of several words to be a multiword expression if some or all of their elements are frozen 3This claim, though very illustrative, has some counter-examples in the parsing literature: e.g. Cafferkey et al. (2007) show the positive impact of pre-identifying prepositional MWEs on syntactic constituency parsing accuracy.
4Lexicon-grammar tables have also been developed for other languages, e.g. Freckleton (1985) for English, and Català and Baptista (2007) for Spanish.
together in the sense of Gross (1986), that is, if their combination does not obey productive rules of syntactic and semantic compositionality”. In other words, we have a MWE if and only if its meaning cannot be derived from its individual components using a grammar including both a syntactic and a semantic component.
Recently, a breakthrough was witnessed in the way of defining MWEs with the creation of corpora annotated for verbal MWEs for the PARSEME shared tasks (Savary et al. 2017; Ramisch et al. 2018). The proposed definition is fully operational as it is entirely based on decision flowcharts relying on formal tests. Note that the main prin-ciples of this definition are in line with the ones adopted in our work. In our annotation of a French corpus with MWEs and NEs, we started by integrating the verbal MWE annotation of the French part of the PARSEME corpora (Section 6). Also note that, in the PARSEME an-notation of verbal MWEs, as well as in our anan-notation of all kinds of MWEs, statistical idiomaticity (Baldwin and Kim 2010), that is, out-standing cooccurrence frequency, is not a sufficient criterion for the MWE status. Thus, “collocations” that do not satisfy other criteria are considered MWEs neither in PARSEME, nor in the present work.
2.2 MWE typologies
Because MWEs encompass heterogeneous linguistic objects, their de-scription is usually accompanied by defining a typology of MWEs. Savary et al. (2018) present a comparison of several NLP-dedicated MWE typologies – those which were particularly influential, have been tested against representative datasets, or focus on verbal MWEs – pro-posed by Sag et al. (2002), Baldwin and Kim (2010), Mel’čuk (2010), Schneider et al. (2014), Laporte (2018), Sheinfux et al. (2019), and Savary et al. (2018) themselves. The analysis shows a large hetero-geneity of these typologies in terms of:
• the number of languages covered – the first 6 works focus on a single language among English, French, and Hebrew whereas the last one covers 18 languages;
• the scope – from verbal MWEs only, to all syntactic categories of MWEs, including or not some categories of collocations;
• the number and granularity of MWE categories – from flat lists of 2–3 categories, to a 2–4-level hierarchy with 6–8 leaf categories; • the number of classified expressions – from 15 to dozens of
thou-sands of MWE lexicon entries or corpus occurrences;
• the criteria used for defining the categories – lexical (lexicaliza-tion, selection constraints, association strength), morphosyntactic (structure, presence of support verb, morphological and syntac-tic flexibility), semansyntac-tic (decomposability, non-compositionality, transparency, figuration), and cross-lingual (universality). Some works performed on French are inspired by the Meaning-Text Theory applied to phraseology by Mel’čuk (2010). For instance, Lux-Pogodalla and Polguère (2011), Polguère (2014) and Pausé (2017) integrate 4,400 collocations and 3,200 idioms in the French Lexical Network, where simple-word and multiword lexemes are densely in-terconnected. Mel’čuk’s typology also inspired corpus annotation ef-forts by Tutin and Esperança-Rodier (2019), who notably extended it with multiword NEs and complex terms. They also defined a sep-arate category for functional MWEs (adverbs, prepositions, conjunc-tions, determiners and pronouns). Let us finally mention the updated version of the PARSEME typology (Ramisch et al. 2018), with 5 main categories, 4 of which are relevant to French (Section 6).
2.3 MWE-annotated corpora and treebanks
We present some emblematic corpora annotated for MWEs, focusing on their annotation process and guidelines. We discuss annotation in syntactically non-annotated corpora (Section 2.3.1); and then in tree-banks, in interaction with syntactic annotation (Section 2.3.2).
2.3.1 MWE annotation in corpora
Laporte et al. (2008b) and Laporte et al. (2008a) present the annota-tion process of a French corpus for adverbial and nominal compounds. The corpus (a Jules Verne’s novel and parliamentary debates) con-tains 8,794 sentences, 168,856 words, 4,383 occurrences of MWEs with adverbial function, and 5,054 occurrences of multiword nouns. The annotation process starts with an automatic annotation based on compound dictionary lookup, followed by a manual validation
based on guidelines.5 These do not elaborate much on the linguis-tic tests/criteria to identify MWEs, but mainly rely on Gross (1986). For adverbial compounds, emphasis is laid on detecting when an MWE functions as an adverbial. Regarding multiword nouns, the guidelines focus on NEs and their category (place, person name, quotation), ti-tle and function nouns, nested MWEs, and non-predicating adjectives. The quality of the annotation process was not assessed.
Schneider et al. (2014) present a methodology for the annotation of a 55,000-word corpus of English web texts, the Streusle corpus. They aim at full coverage, with no limitations in terms of syntactic constructions, including both continuous and discontinuous MWEs. “Strong” and “weak” MWEs are distinguished, roughly correspond-ing to idiomatic MWEs and collocations. The guidelines are mainly a list of cases and examples (depending on the MWE structure). They rely on the following definition: MWEs are token combinations that are “idiosyncratic in form, function, or frequency”.6The annotators’ judgements on the MWE status of a candidate expression are largely driven by their intuitions, informed by classical linguistic cues (e.g., semantic opacity, fixedness). Three types of annotation sessions were conducted: individual, joint and consensus sessions, with one, two, or more than two annotators collaborating. All sentences were annotated at least in one joint and one individual session, and 1/5 in a consensus session.
The Wiki50 corpus contains 50 English Wikipedia articles, to-talling 4,350 sentences, annotated for NEs and MWEs (Vincze et al. 2011). A subset of 15 articles was double-annotated by linguists, and disagreements were discussed and resolved by the annotators them-selves. The annotation scheme covers 6 MWE and 4 NE categories, with discontinuous expressions (light-verb and verb-particle construc-tions) represented using two-level hierarchical encoding. The MWE categories do not cover fixed adverbials nor functional MWEs, whereas the NE categories cover mainly person, organization and location. The
5http://infolingu.univ-mlv.fr/corpus/fr-MW-N/fr-MW-N/ guidelines.doc for nouns and http://infolingu.univ-mlv.fr/corpus/ fr-MW-Adv/fr-MW-Adv-corpus/guidelines.docfor adverbials.
6https://github.com/nschneid/nanni/wiki/ MWE-Annotation-Guidelines
corpus documentation does not mention detailed annotation guide-lines nor formal criteria, but each category contains a few examples and a brief description, along with some general annotation principles. PolyCorp (Tutin et al. 2016; Tutin and Esperança-Rodier 2019) is a French corpus annotated with MWEs and NEs comprising almost 70,000 tokens from various genres. A lexicon of 5,000 MWEs, com-piled from different sources, has been used to pre-identify MWEs, which were then classified as literal versus idiomatic. Expert anno-tators also completed the annotation with MWEs not present in the dictionary, and with NEs. The typology of MWEs builds on Mel’čuk (2012) (Section 2.2), and includes pragmatic MWEs (e.g. you’re wel-come). Although the annotation guidelines provide rough definitions of the MWE categories, they lack operational criteria for the identifi-cation task.7
Savary et al. (2017) and Ramisch et al. (2018) present two releases of multilingual corpora annotated for verbal MWEs in 18 (resp. 20) languages belonging to more than 5 language families in the frame-work of the PARSEME project. The corpora contain around 5.4M (resp. 6.1M) tokens, 62k (resp. 79k) occurrences of verbal MWEs, dis-tributed over 5 (resp. 8) linguistic categories. A contribution of this work is the use of guidelines with precise decision flowcharts relying on linguistic tests, which have proved to be robust across languages. We summarize them in Section 6, as our work actually builds on the PARSEME annotation: we reuse the French part of the PARSEME 1.1 annotations of verbal MWEs (those made on the Sequoia corpus), and further annotate all other categories of MWEs.8
2.3.2 MWE annotation within treebanks
While treebanks are quite numerous, treebanks including consistent MWE annotation are rarer. Annotation guidelines for MWEs are more or less detailed depending on the project’s focus. Rosén et al. (2015) present a survey on MWEs in treebanks. The 17 investigated tree-banks have different annotation schemes and heterogeneous cover-age in terms of MWE categories. Overall, one take-away messcover-age is 7We thank Agnès Tutin for sending us the PolyCorp annotation guidelines. 8Only a few corrections were made to the PARSEME annotation.
that better documentation of treebanks is needed, including annota-tion guidelines and tagsets, to help interpret MWE annotaannota-tions.
We now detail some treebanks whose authors make substantial efforts to consistently annotate MWEs. The French treebank (Abeillé et al. 2003, 2019) contains about 20,000 sentences from the Le Monde newspaper, with MWEs annotated on top of morphological and syntac-tic layers. The annotation guide (Abeillé and Clément 1999–2015) lists a number of generic graphical, morphological, syntactic and semantic properties of MWEs. These are explicitly considered neither sufficient nor necessary, but should be used to evaluate whether there is suf-ficient evidence for the MWE status. Additionally, a typology based on the MWE’s part of speech is proposed with 8 main types (multi-word nouns, pronouns, determiners, adjectives, prepositions, adverbs, conjunctions and verbs) and 10 subtypes. Some hints are given as to the choice among competing types (e.g. multiword adjectives vs. nouns vs. adverbs, etc.). The annotated verbal MWEs are limited to those which exhibit no flexibility or contain cranberry words. For-mally, the annotated MWEs are almost all continuous.9 No evalua-tion of the MWE annotaevalua-tion quality was carried out. In the context of joint MWE identification and syntactic parsing, Candito and Con-stant (2014) have automatically remodeled the dependency version of the French treebank so that syntactically regular MWEs get a regular syntactic structure. MWE status is indicated using features. We have retained this principle in the MWE annotation of the Sequoia corpus (Section 9).
The Prague Dependency Treebank (Hajič et al. 2017) is a project for the Czech language started in the nineties. Several layers of an-notation are defined, with MWE anan-notation appearing at the level of the tectogrammatical layer, which abstracts away from grammatical marking (Mikulová et al. 2006; Bejček and Straňák 2010). Tectogram-matical layers contain nodes corresponding to semantically full lex-emes, potentially realized as MWEs in lower layers. The guidelines consist of examples of various MWE categories (Mikulová et al. 2006). They contain precise definitions for some MWE categories, such as verbal MWEs containing reflexive markers, or numerals, but for other 9Discontinuity is allowed according to the guidelines, but among the 32 thou-sand annotated instances, only 59 are discontinuous (Abeillé et al. 2019).
cases, the guidelines focus on how to annotate once an MWE is iden-tified, and do not contain operational tests nor criteria.
Universal Dependencies is an international initiative to collec-tively construct a highly multilingual set of syntactic-dependency tree-banks using the same annotation guidelines, while leaving some space for language specificities (Nivre et al. 2016). For instance, version 2.5 comprises 157 treebanks and 90 languages. The annotation guidelines have a section devoted to MWEs, limited to three categories: fixed grammaticalized expressions (e.g., in spite of), exocentric semi-fixed expressions (e.g., Barak Obama) and endocentric compounds (e.g., noun phrase). Each category is roughly defined without operational criteria.
2.4 Named entity annotation
Named entity annotation has a long-standing tradition, notably be-cause of the high semantic charge of NEs in texts, and thus their crucial role in semantically-oriented applications such as information extrac-tion and sentiment analysis. The high popularity of NEs in NLP tasks was initiated by the MUC conferences (Chinchor 1998) in English, and by the benchmark for multilingual NE recognition established by the CoNLL shared tasks (Tjong Kim Sang 2002; Tjong Kim Sang and De Meulder 2003).10This benchmark consists of datasets in Dutch, En-glish, German and Spanish with 13,000, 35,000, 20,000 and 18,000 annotated NEs, respectively, mainly person, organization and location names; as well as some NEs of other categories, aggregated as “mis-cellaneous”. In these corpora, the annotation schema is rather sim-ple: 4 main categories are used, nested NEs are not distinguished, and metonymy (e.g., person names used as names of companies) is disregarded, that is, only the effective NE categories (here: organi-zation) are indicated. However, the 2003 CoNLL shared task edition acknowledged the interaction between syntax and NEs, in that the NE annotation is accompanied by a parallel annotation layer dedicated to chunks.
10Available athttps://www.clips.uantwerpen.be/conll2002/ner/and https://www.clips.uantwerpen.be/conll2003/ner/.
The complexity of the syntax-NE interplay lies in the fact that some NEs form a sublanguage with specific, though regular, syntac-tic rules. For instance, in French it is hard to identify the headword in complex person names (Mr. Joël Bucher) or addresses (Jean Jaurès Str. 3) because, differently from other languages like Greek or Polish, there is no morphological agreement hinting at a name’s internal struc-ture. Also, passages in a foreign language cannot be analysed by the grammar of the main language of a treebank (Bejček et al. 2011). No-tably for these reasons, NEs are often addressed jointly with syntax in treebanks (Rosén et al. 2015). Namely, as many as 16 treebanks in 14 languages report on at least a partial coverage of NEs in their annota-tions. In the simplest cases, components of continuous NEs are merged into single tokens (Alejandro_Couceiro). If NE components are kept as separate tokens, NEs can form flat subtrees marked with uniform la-bels (e.g., the name relation in Universal Dependencies).11 In more elaborate annotation schemas, the NE marking belongs to a different annotation layer than syntax, the NE typology includes several cate-gories and subcatecate-gories, and nested NEs are identified (Savary et al. 2010). Finally, NEs can also be represented in the deep syntactic layer, built upon the surface syntactic layer, so that morphosyntactic vari-ation, ellipsis and discontinuity are neutralised (Bejček et al. 2011). NEs annotated in treebanks can be further interlinked with their lexi-cal entries (Bejček and Straňák 2010), allowing coreference markup.
A more comprehensive account of NE-annotated corpora world-wide is beyond the scope of this article.12Unfortunately, hardly any NE annotation guidelines are accessible online. Those few which could be accessed at the time of writing are often mainly repositories of NE categories to account for and examples to illustrate them, as well as more precise guidelines about a NE’s span in text (e.g., inclusion of qualifiers and titles). We found no guidelines in which tests and deci-sion flowcharts guide the annotator, as in our guidelines (Section 5).
Concerning French, one of the most advanced NE annotation projects was undertaken for the 1.4-million-word Quaero corpus (Grouin et al. 2011) of transcribed speech, manually annotated with
11https://universaldependencies.org/docs/en/dep/name.html 12A list of 177 such resources in 34 languages, documented with 16 attributes, can be found athttp://damien.nouvels.net/resourcesen/corpora.html.
a NE taxonomy of 7 categories and 32 subcategories. There, complex NEs are not only marked for nesting but also for fine-grained cate-gories of internal components such asname.last,zip-code,month, etc. Also, metonymy is accounted for by primitive and effective cat-egories (Section 5.1).13While the Quaero corpus is not openly avail-able, its biomedical spin-off corpus, inspired by the same guidelines, is distributed under an open license (Névéol et al. 2014). It contains more than 100,000 words and 26,409 entity annotations mapped to 5,797 unique concepts of the UMLS ontology. Another French re-source, the French Treebank, was extended with about 11,000 NE annotations by Sagot et al. (2012). Their typology contains 7 main categories and a number of subcategories, but nested NEs were disre-garded. Some of their pairs of categories correspond to a single one in our tagset. Their seven categories have the same coverage as our four coarser categories ORG, LOC, PERS, PROD. Conventions on NE spanning are very similar to ours. This resource includes an additional feature compared with our work: each mention of NE is linked to the entity database Aleda (Sagot and Stern 2012). The annotation process consisted of an automatic pre-annotation followed by a manual cor-rection/validation by a single annotator. No quality evaluation of the resource was performed. This corpus is available for research under a specific license.
3 MAIN DISTINCTIONS IN PARSEME-FR
TYPOLOGIES
Both for organizational and scientific reasons, we design our guide-lines along two primary distinctions. First, we set aside verbal MWEs, which were already annotated within the multilingual PARSEME net-work (Section 3.1). Second, we distinguish between NEs and MWEs (Section 3.2). This results in two typologies and three categories of annotated expressions: NEs, verbal MWEs and non-verbal MWEs (Sec-tion 3.3).
13See the Quaero annotation guidelines at http://www.quaero.org/ media/files/bibliographie/quaero-guide-annotation-2011.pdf.
3.1 Building on the verbal MWE annotation from PARSEME
The identification of verbal multiword expressions (VMWEs) has been the focus of the PARSEME shared tasks (Savary et al. 2017; Ramisch et al. 2018), initiated within the PARSEME European COST project. The PARSEME 1.1 guide for VMWEs was designed and used to pro-duce annotations for 20 languages, including French.14 Four of the five defined categories of VMWEs are relevant for French (detailed in Section 6). We thus focused on other MWEs (non-verbal MWEs), and simply imported the existing annotations of VMWEs from PARSEME. Since members of the French spin-off project PARSEME-FR were highly involved in designing the multilingual PARSEME guide, both guides are similar in spirit.
3.2 Distinguishing NEs from nominal MWEs
For nominal expressions, we make a primary distinction between NEs and MWEs. A first motivation for this distinction is that, roughly speaking, most categories of NEs are inherently more productive than MWEs, and thus the latter are more suitable to be listed in a lexicon. Secondly, although both categories do share some properties that can be used in identification criteria, we found it simpler to use distinct guidelines. Moreover, we annotate both multiword and single-word NEs, since excluding the latter would have reduced the usefulness of the annotated corpus.
The NE versus MWE distinction concerns the naming convention linking an expression and the entity (or entities) it refers to. The start-ing distinction among nominal expressions is between a name assigned to an instantiation of a category versus a name assigned to a category (and used to refer to the category or more frequently to instances of this category):
(A) The nominal expression e is the direct name of an entity (for in-stance [Anna Duval]PERS),15“direct” meaning here that the entity name is not at the same time the name of a concept which this 14https://parsemefr.lis-lab.fr/parseme-st-guidelines/1.1/ 15NEs appear in square brackets with a subscript category code (Section 5.1).
entity is an instantiation of. The name e may well be ambigu-ous (namely there can be several women named Anna Duval), but the key aspect is that a speaker must learn a naming convention for each entity bearing that name (Kleiber 2007). Even though a speaker knows a person x named Anna Duval, when meeting a new person y named that way, the speaker cannot guess her name, and has to learn the specific naming convention between y and the name.
(B) The nominal expression e is an instantiable concept name, which can be used to refer to a concept or more often to instances of this concept (e.g., the simple noun table or the compound neural net-work). A naming convention does exist, but it links the name and the concept. Knowing the defining characteristics of the concept enables a speaker to use e to name previously unknown instances of that concept, without the need to learn any new naming con-vention. For instance a speaker can use the noun table to name a previously unseen table.
Like entity names, compositional noun phrases may unambigu-ously refer to entities, whether independently of the linguistic context (e.g., the first British female prime minister) or thanks to the context (e.g., the woman used for a specific woman, disambiguated in context). However, as opposed to entity names, the reference of compositional noun phrases is momentary, not intended to last (Kleiber 2007).
The distinction between entity direct names and instantiable con-cept names is reminiscent of the proper noun versus common noun dis-tinction, but the latter proves not so easy to draw. Of course, lexical items that are exclusively devoted to directly naming entities (e.g., the first and last names for people) are easily classified as proper nouns (sometimes called pure proper nouns). This is why Ehrmann (2008) roughly defines proper nouns as “the designation of a precise entity via a description whose meaning plays a minor role with respect to the denomination of the referent, which operates directly”.16 However, abundant literature shows that the proper vs. common noun distinc-tion is difficult to characterize in linguistic terms (Kleiber 2001, 2007; Ehrmann 2008). Within direct names of entities, we rather distinguish:
(A1) names made of lexical items dedicated to naming specific entities (pure proper nouns), such as [Italy]LOCand [Anna Duval]PERS; (A2) names that are semantically compositional, either totally (such
as the [International League against Racism and Anti-Semitism]ORG) or partially (such as [massif central]LOC‘central massif’, referring to a specific massif at the center of France, or [mer de glace]LOC ‘sea of ice’ for a specific glacier in the Alps); the important fea-ture, though, is that these are names of specific entities for which a direct naming convention must be learnt;
(A3) names which designate unique abstract entities, such as abstract simple nouns (taxidermy) or abstract MWEs (Euclidean geometry, natural language processing): because of the unicity of the entity that can be called that way, they too can be viewed as entity names, for which the speakers have to learn the naming conven-tion at the level of the entity.
However, cases (A3) are traditionally not viewed as proper nouns. Kleiber (1996) argues that pure proper nouns are meant to name a particular entity within a well-identified semantic class (e.g., a per-son), whereas for (A3) cases, the relevant hypernym is not obvious. We have chosen to follow this tradition, considering cases (A1) and (A2) as proper nouns, and (A3) as common nouns. In short, we distin-guish:
• NEs: We tag cases (A1) and (A2) as named entities and associate them with a semantic category. Although the term is confusing (one should speak of an entity name, not a named entity) we use it for entity names, as it is usual in the NLP community. We annotate these as NEs using dedicated guidelines (Section 5).
• MWEs: We tag as multiword expressions cases (B) and (A3), pro-vided they are composed of more than one component.
Finally, there are also names referring to unique concrete entities such as the sun or the moon (often called “unica”), whose status is widely debated. We have chosen to tag these as NEs (e.g., I can see you thanks to the [moon]LOC), unless when it is clear they refer to a concept instance (e.g., Many planets have a moon).
The MWE vs. NE dichotomy is particularly challenging due to at least three facts. Firstly, MWEs can contain NEs, as in maladie de
[Paget]PERS ‘Paget’s disease’ and vice versa [Association nationale des anciens combattantsde la Résistance]ORG‘Association of the Old Fight-ers of the Resistance’⇒‘Resistance Veteran Association’.17 Secondly, due to ellipsis, an NE can boil down to those components which form an MWE, e.g., [Anciens combattant]ORG ‘Old fighters’⇒‘Veterans’ can either refer to a class of people or be a shortcut for the full organiza-tion name. Our guidelines, however, exclude annotating a sequence both as NE and MWE (here, only the NE annotation applies). Thirdly, as pointed out above, many NEs have a descriptive basis, e.g., [Cour d’appelde [Paris]LOC]ORG‘Court of Appeal of Paris’, and their status as NEs stems from the naming convention, possibly specific to a particu-lar domain of expertise (e.g., law) not familiar to the annotators. Given these challenges, we formalized dedicated decision flowcharts, dis-cussed in Sections 4.2, 5.3 and 6, so as to maximise the reproducibility of the process.
3.3 PARSEME-FR typologies
The typologies resulting from the distinctions explained above and used in our annotation are depicted in Figure 1. NEs are split into 5 categories, and MWEs divide into non-verbal MWEs – subdivided into syntactically regular and irregular (Section 9) – and VMWEs, with 4 relevant categories and 2 subcategories inherited from PARSEME.
Comparing these typologies to the ones described in Section 2.2, several facts are worth noting. Firstly, like Sag et al. (2002) and Tutin and Esperança-Rodier (2019), we model and annotate MWEs and NEs in the same framework. However, unlike these two previous works, we distinguish named entities and MWEs. More precisely we make a semantic difference concerning the level at which the naming con-vention operates (cf. Section 3.2), and hence we consider the MWE typology as disjoint from the NE typology, the latter including both single- and multi-word NEs.
Secondly, our typologies are heterogeneous, as we define NE and MWE subtypes using different criteria. The typology of NEs is based 17In examples, components of MWEs are shown in bold. Idiomatic translations of MWEs in inline examples, when required, are preceded by an arrow⇒.
named entity
PERS [Gutenberg] [Bernard Bonnet]
LOC [Abainville][golfe d’[Ajaccio]] ‘Ajaccio Bay’ ORG [Peugeot][Centre communal d’aide sociale]
‘Communal Center of Social Aid’
PROD [Angiox][Charte européenne des droits de l’homme] ‘European Charter of Human Rights’
EVE [Coupe d’[Europe]]
‘UEFA European Championship’
. multiword expression non-verbal MWE verbal MWE IRV LVC VID MVC
se dérouler ‘RCLI unroll’→‘take place’ lancer un appel ‘launch a call’ →‘make a call’
LVC.full
LVC.cause donner un espoir →‘give hope’
arme blanche ‘white weapon’ → ‘cold weapon’ à la suite de ‘to the following of’ → following
prendre part →‘take part’
faire savoir ‘make know’→‘let know’ Figure 1: Named entity and multiword expression typologies used in the PARSEME-FR corpus
on the semantic types of the named objects and ignores the linguistic properties of the names themselves. Conversely, the MWE typology is largely driven by the syntactic structure of the annotated expressions. Also, while verbal MWEs are further divided into finer subtypes, non-verbal MWEs are not. This situation results from a mixture of histor-ical and linguistic factors. NE annotation has a long-standing tradi-tion and opposing it in such fundamental aspects as typology design principles might jeopardise the utility of the corpus. In particular, an-notating single-word NEs seemed valuable from an applicative per-spective. The PARSEME typology and guidelines are exclusively ded-icated to verbal MWEs but have the advantage of being validated in a multilingual framework. Their elaboration is justified by the fact
that VMWEs show a relatively high degree of syntactic flexibility and discontinuity. Thus, to make the guidelines operational, the syntac-tic tests included therein must be structure-specific. For non-verbal MWEs, such structure-specific guidelines proved unnecessary in our experience. What is more, when defining the syntactic categories for non-verbal MWEs, we would have to face hard challenges,18 not cen-tral to our interests. Note however that considerable effort was ded-icated to part-of-speech annotation for syntactically irregular MWEs (cf. Section 9).
Thirdly, our NE typology is coarser than in some previous efforts dedicated to NEs alone, notably in the French corpus by Gravier et al. (2012) with 7 categories and 32 subcategories. Also, while other NE-dedicated efforts cover temporal expressions (e.g., dates) and mea-sures (e.g., amounts of money), we exclude them from our annotation scope, because we believe that, while they stem from specific gram-matical subsystems, their semantics remain compositional and require no entity-specific naming convention (Section 3.2).
Fourthly, our annotation scope does not cover collocations, which we define as word combinations whose idiosyncrasy is of statistical nature only (e.g., drastically drop). However, what other projects call collocations is partly included in our scope. For instance, our light-verb constructions cover a subset of Mel’čuk’s collocations, namely those concerned by the lexical function called Oper.
Fifthly, the number of annotated NEs and MWEs (Section 10), exceeds 6,500 corpus occurrences, roughly balanced between NEs and MWEs, which is comparable to the work of Schneider et al. (2014), who however only use 2 main categories.
Finally, and most importantly, our typologies are endorsed by ex-tensive annotation guidelines based on decision flowcharts over lin-guistic tests, which are meant to guide the annotator – in a relatively deterministic and reproducible way – to both identify and categorize candidate MWEs/NEs into one of the proposed categories. In particu-lar, we largely cover the challenge of distinguishing between NEs and MWEs themselves – in terms of operational definitions, even though 18For instance, preposition-noun patterns, as in à raison de ‘in reason of’⇒‘at a rate of’, are notoriously hard to categorise into adjectival, adverbial or prepo-sitional phrases.
both categories of expressions share properties. To the best of our knowledge, this constitutes an unprecedented outcome.
4 GENERAL ANNOTATION GUIDELINES
Our annotation guidelines start with a description of some formal con-straints (Section 4.1) and a top decision flowchart (Section 4.2).
4.1 Formal constraints and format
While annotating MWEs and NEs, we face most of the annotation chal-lenges pointed at by Mathet et al. (2015) and Savary et al. (2018):
• unitizing, that is, identifying the boundaries of the NE or MWE, which is often challenging, in particular for NEs;
• categorising (for NEs);
• free overlap, in particular in coordinated MWEs il peut plaider1,2 coupable1ou non2coupable2‘he can plead guilty or non guilty’. • nesting, as in Il a fait1 un véritable faux pas1,2 ‘he made a true
false step’⇒‘He really made a faux pas’, which contains a light-verb construction whose predicative noun is itself a MWE. • discontinuities (as in the previous examples).
The sole formal constraint we have put on the annotation is that we only consider MWEs that are syntactically connected, that is, whose components form a connected dependency subtree in the syn-tactic representation.19A counter-example is ce là ‘this NOUN-here’⇒‘this NOUN’.20 The two potential components ce and -là syn-tactically depend on the noun, which is an open slot and cannot be part of the MWE.
19More precisely, a canonical form of the MWE needs to form a connected de-pendency subtree. A canonical form of a MWE is one of its least marked syntactic forms preserving the idiomatic meaning. This mainly affects VMWEs. Note that the canonical form of a MWE is not necessarily the most frequent one.
Apart from this restriction, in a given sentence, any set of tokens can form a MWE or NE, and a given token can belong to several MWEs or NEs.
In practice, the annotations of MWEs and NEs are provided as the 11th column added to a CoNLL-U file21containing morphological and syntactic annotations.22 MWEs/NEs are annotated using integer identifiers, which are sentence-specific. Additional information is pro-vided on the first token of an MWE/NE: (i) the part of speech of the MWE, unless the MWE is considered syntactically regular (see below Section 9); (ii) the MWE versus NE category, plus the subcategory of NE or of verbal MWEs, e.g., NE-PERS or MWE-LVC; and (iii) for non-verbal MWEs: one matching sufficient criterion.
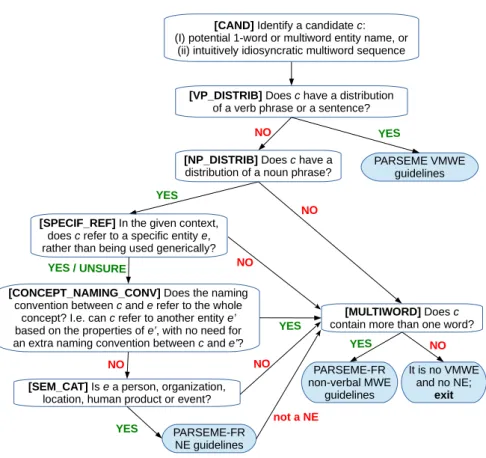
4.2 Top decision flowchart
As discussed in Section 3, the three main categories of expressions in our typologies are NEs, VMWEs and non-verbal MWEs, each of which is covered by separate annotation guidelines. Figure 2 shows the top decision flowchart23 which guides the annotator to the appropriate guidelines.
The initial step (CAND) of identifying a potential expression to annotate is largely based on the annotator’s intuition, which is further confirmed or contradicted by more rigorous guidelines. In this step, a candidate c can be composed of one or more lexemes since single-word NEs are also annotated.24
21https://universaldependencies.org/format.html
22The precise description of the format is available at https: //gitlab.lis-lab.fr/PARSEME-FR/PARSEME-FR-public/wikis/
Corpus-format-description
23https://gitlab.lis-lab.fr/PARSEME-FR/PARSEME-FR-public/ wikis/Guide-annotation-PARSEME_FR-chapeau#top-decision-tree
24Lexemes are only roughly approximated by tokens, depending on the corpus tokenization. We use the original tokenization of the corpus, but consider certain tokens as multiword if they contain non-alphanumeric characters, annotating them as MWEs when the guidelines apply, e.g., peut-être ‘may-be’⇒‘maybe’.
PARSEME VMWE guidelines It is no VMWE and no NE; exit YES YES YES / UNSURE YES YES NO NO NO NO NO
[CAND] Identify a candidate c:
(I) potential 1-word or multiword entity name, or (ii) intuitively idiosyncratic multiword sequence
[VP_DISTRIB] Does c have a distribution
of a verb phrase or a sentence?
[NP_DISTRIB] Does c have a
distribution of a noun phrase?
[MULTIWORD] Does c
contain more than one word?
[SPECIF_REF] In the given context,
does c refer to a specific entity e, rather than being used generically?
PARSEME-FR non-verbal MWE
guidelines
[CONCEPT_NAMING_CONV] Does the naming
convention between c and e refer to the whole concept? I.e. can c refer to another entity e’ based on the properties of e’, with no need for an extra naming convention between c and e’?
[SEM_CAT] Is e a person, organization,
location, human product or event?
NO
PARSEME-FR NE guidelines
YES not a NE
Figure 2: Top decision flowchart of the annotation guidelines
The next step (VP_DISTRIB) redirects to the PARSEME VMWE guidelines if c has a distribution of a verbal phrase or a sentence, e.g. il vide son sac ‘he empties his bag’⇒‘he gets it off his chest’.25
If c is neither verbal nor nominal (NP_DISTRIB), e.g., à l’issue de ‘at the outcome of’⇒‘after’, it is tested against our non-verbal MWE guidelines, provided that it is composed of two or more lexemes, and discarded otherwise.26
If c is nominal, it can (in the given context) either be used gener-ically, as in (1), or refer to a specific entity e (SPECIF_REF), as in (2).
25https://parsemefr.lis-lab.fr/parseme-st-guidelines/1.1/ 26https://gitlab.lis-lab.fr/PARSEME-FR/PARSEME-FR-public/-/ wikis/Criteres
(1) Le conseil régional est l’assemblée délibérante d’une région. ‘The general council is the deliberating assembly of a region.’ (2) Le conseil régional a délibéré hier soir.
‘The general council deliberated last night.’
In the former case, c cannot be a NE but, if multiword, it might be a non-verbal MWE. In the latter case (or if the test is hard to ap-ply), it is necessary to determine the naming convention which links c to its referent e. If this convention covers the whole concept (CON-CEPT_NAMING_CONV), as in (2), then c can (in other contexts) refer to another referent e0on the basis of the properties of e0. In this case, if c is multiword, it might be a non-verbal MWE.
Conversely, the naming convention may cover only the link be-tween c and e, rather than a whole concept. In this case, one of the two possibilities arises: (i) c can refer to another referent e0only if a new naming convention is established, as in [Anna Duval]PERS, or (ii) e is, by nature, unique, so there can be no other e0which c can refer to, as in physique quantique ‘quantum physics’ or in [Journal officiel de la [République française]ORG]PROD ‘Official Journal of the French Repub-lic’. In any of these two cases c might be an NE. Thus, if e belongs to one of the pre-selected semantic categories (person, organization, location, human product or event), then c is tested against the PARSEME-FR NE guidelines. If their outcome is negative and if c is multiword, it might still be a non-verbal MWE.
The SPECIF_REF and CONCEPT_NAMING_CONV tests are meant to distinguish cases (A) and (B) from Section 3.2. The distinction be-tween cases (A1) and (A2) on the one hand, and (A3) on the other hand, is implemented by the SEM_CAT test and the PARSEME-FR NE guidelines.
5 GUIDELINES FOR NAMED ENTITIES
This section describes the typology (Section 5.1), principles (Sec-tion 5.2) and tests (Sec(Sec-tion 5.3) used for the annota(Sec-tion of NEs.
5.1 Named entity categories
The scope of the NE annotation covers the following categories: • persons (PERS), e.g., [Gutenberg]PERS, [Bernard Bonnet]PERS; • locations (LOC), e.g., [Abainville]LOC‘a French city’,
[golfe d’[Ajaccio]]LOC]LOC‘Ajaccio Bay’;
• organizations and human collectives (ORG), e.g., [Comité dé-partemental d’action touristique]ORG ‘Departement Committee of Tourism’;
• products, including titles of works and documents (PROD), e.g., [Angiox]PROD, [Charte européenne des droits de l’homme]PROD ‘Eu-ropean Charter of Human Rights’, [Libération]PROD‘a newspaper’; • named events (EVE), e.g., [L’affaire [Dumas]PERS]EVE‘Dumasgate’,
[Coupe d’[Europe]LOC]EVE‘UEFA European Championship’. Dates, amounts, and numerical expressions, commonly covered by the NE term in the NLP literature (e.g., in the work of Chinchor (1997) followed by Tjong Kim Sang and De Meulder (2003)) are not included in this scope, since they do not name a specific entity in the discourse world.
A pervasive feature of NEs is that they occur as metonyms, in which case a change of NE category frequently occurs. Since metonymy is one of the hardest challenges in NE recognition (Mark-ert and Nissim 2007), we account for it in the annotation schema. For metonymic uses of NEs, we mark both the effective (called fi-nal) and the primitive NE category. For instance, in chauffeur-routier chez [Caillaud]PERS
ORG ‘truck driver from Caillaud’, the last token Caillaud is originally the name of a person, further assigned to a company. Thus, the primitive and the final categories are PERS and ORG, re-spectively.27 In some cases it is hard to decide which of the two considered types is primary or final. For instance, we may hesitate between considering a journal name as primary and its editorial of-fice as final, or vice versa. In such controversial cases, we follow the default priority order LOC< PERS < ORG < PROD (where < means less final, more primitive). For instance, in informations publiées dans
[Le Canard enchaîné]ORG
PROD‘information published in The Chained Duck (a newspaper)’ we indicate both the primary and the final type. Con-versely, in accusation portée par [Le Canard enchaîné]ORG ‘accusation brought by The Chained Duck’ only the final type appears (i.e. there is no metonymy).28
A NE can undergo a series of metonymies, in which case we only mark as primitive the category which directly precedes the final cate-gory in this series. For instance, in [Reuters]ORG
PROD the surname (PERS) of the founder Paul Reuter of the press agency (ORG) further became the name of the released informational content (PROD). Here, only the last two categories are annotated as primary and final, respectively.
Note also that metonymy can invalidate the NE status in some cases. Notably, trade marks used metonymically (to refer to prod-ucts themselves), e.g., BMW in [Anna]PERS a acheté une BMW ‘Anna has bought a BMW’, are not annotated as NEs.29 Here, the naming convention (addressed by the CONCEPT_NAMING_CONV test in Sec-tion 4.2) between a particular car and the BMW name need not be re-established, but stems from the car’s properties instead.
5.2 Nested and overlapping named entities
NEs frequently exhibit nesting, with or without intervening MWEs. We annotate all these nested instances, as in [Cour d’appel de [Paris]LOC]ORG ‘Court of Appeal of Paris’, which implies that some tokens belong to several annotated entities. Note that in people’s names like [Jean-Paul Alègre]PERS the given names and surnames are no autonomous nested NEs but rather ellipses of the full names, or components (Grouin et al. 2011), therefore they are not to be anno-tated separately.
28Note that primitive types are marked only in case of a clear metonymic relation between the referenced objects (part/whole, container/contents, cause/effect, artist/work, location/inhabitants, location/institution, etc.). Other cases of polysemy are not relevant, e.g. when a place is named after a person (WashingtonLOC) or a god (MarsLOC).
29An alternative approach would have been to annotate BMW as a NE with the primitive category (PROD) only, but we favor overall coherence instead.
Another case of overlapping annotations stems from coordi-nations, as in les traitésPROD1,PROD2 dePROD1 RomePROD1,LOC1 et dePROD2
ParisPROD2,LOC2 ‘treaties of Rome and of Paris’, where some
compo-nents of the annotated entities are shared (here: traités ‘treaties’).30
5.3 Linguistic tests and decision flowchart
The topmost decision process in the PARSEME-FR guidelines (Sec-tion 4.2) branches to the NE guidelines when the candidate expres-sion refers to a specific discourse entity in context and there might be a naming convention linking this expression with this particular entity. In order to confirm an intuition that the annotator may have about the candidate at hand, the NE guidelines are organized as a deci-sion flowchart, so as to maximize the reproducibility of the annotator’s decisions.31
The two main challenges to be faced here are: (i) identifying the naming convention concerning the NE candidate at hand, and (ii) de-termining the textual span of the candidate. Stage (i) is handled by the following linguistic tests:32
• OBVIOUSPROPER: Is the candidate sequence obviously a proper name, that is, is the annotator confident about the existence of the naming convention concerning the sequence?
• RELEVUPPER: Is the candidate sequence, or its variant in the same text, spelled with an initial uppercase letter to signal a proper name, rather than for other (e.g., honorific) reasons?
• ACRON: Does the candidate sequence have an acronym in the given text?
• WEBPAGE: Is there an official web page or Wikipedia page titled by the candidate sequence?
30Discontinuous NEs are marked by subscript identifiers on each component. 31https://gitlab.lis-lab.fr/PARSEME-FR/PARSEME-FR-public/ wikis/ne-decision-tree
32These tests are not applied sequentially but included within the decision flowchart mentioned above, omitted here for the sake of concision.
Stage (ii) is particularly challenging in French, because in multi-word names of organizations only the initial of the first component is usually capitalised, as in Association paroissiale d’éducation popu-laire ‘Parish Association of Popular Education’. Additionally, the at-tachment of prepositional phrases (PPs) to NEs is notoriously hard, in particular for location PPs. Therefore, stage (ii) also relies on the available external sources via the three last tests above. Namely, if ACRON or WEBPAGE apply, the span is usually easily determined by the acronym or the title of the relevant webpage. Two additional tests dedicated to the NE span are used within the decision flowchart:
• MINSPAN: Does the candidate sequence c have the minimal span, that is, is it true that a shorter span than c no longer refers to the same entity? For instance, the test is passed for [la Rochelle]LOC (since the determiner cannot be omitted).
• SPANPERCAT: If the preceding tests were not sufficient to deter-mine the inclusion of the classifier, it is systematically excluded in names of persons (colonel [Pétain]PERS), products, events, re-gions, departments, cities (la ville de [Loudun]LOC ‘the city of Loudun’), and some organizations (société [Cedel]ORG‘Cedel com-pany’). In other cases, the classifier is systematically included ([école Notre-Dame]LOC‘Our Lady’s School’, [ministère français des Affaires étrangères]ORG ‘French Ministry of Foreign Affairs’). Al-though somewhat arbitrary, this list of cases ensures coherence for some notoriously difficult cases.
6 GUIDELINES FOR VERBAL MWES
The annotation of verbal MWEs in the PARSEME-FR corpus is trans-ferred from the multilingual PARSEME corpus annotated for VMWEs (Savary et al. 2018; Ramisch et al. 2018), and its French subcorpus was described in detail by Candito et al. (2017). Version 1.1 covers 20 languages, including French.33 The guidelines are organized as a
generic flowchart, based on linguistic tests, which redirect to category-specific flowcharts.34Six major categories are defined, four of which are relevant to French.
• Inherently reflexive verbs (IRV) are combinations of a verb v and a reflexive clitic r, such that one of the non-compositionality condi-tions holds: (i) v never occurs without r, like in (3); (ii) r distinctly changes the meaning of v, like in (4); (iii) r changes the subcate-gorization frame of v, like in (5) as opposed to (6).
(3) Je I me self souviens remember de of ce this livre. book ‘I remember this book.’ (4) Une a seconde second opération operation se self déroulait unrolled en in parallèle. parallel ‘Another operation was taking place at the same time.’ (5) Je I m’ self occupe occupy du of-the dessert. dessert ‘I take in charge the dessert.’ (6) J’ I occupe occupy les the enfants kids avec with un a jeu. game ‘I keep the children busy with a game.’
• Light-verb constructions (LVCs) are verb-noun combinations in which the verb is semantically void or bleached, and the noun is a predicate expressing an event or a state. Two subcategories are defined: LVC.full are those LVCs in which the subject of the verb is a semantic argument of the noun, as in (7); LVC.cause are those in which the subject of the verb is the cause of the noun (but is not its semantic argument), as in (8).
(7) Nous we devons must lancer launch un a appel call à to la the raison. reason ‘We must make a call to reason.’
(8) Il he donne gives espoir hope aux to soldats. soldiers ‘He gives hope to soldiers.’
• Verbal idioms (VIDs) are verb phrases of various syntactic struc-tures which contain cranberry words or exhibit lexical, morpho-logical or syntactic inflexibility, as in (9).
(9) petit small resto restaurant qui which ne NEG paye pays pas NEG de DET mine face ‘small restaurant which is not much to look at’
• Multi-verb constructions (MVCs), rare in French, consist of a se-quence of two verbs, so that replacing one verb by a verb from the same broad semantic class leads to ungrammaticality or to an unexpected change in meaning, as in (10).
(10) Il he n’avait NEG’had jamais never entendu heard parler talk de about ça. this ‘He had never heard of this before.’
7 GUIDELINES FOR NON-VERBAL MWES
Below, we justify the use of sufficient criteria (Section 7.1), discuss annotation span (Section 7.2), and present the criteria (Section 7.3).
7.1 General principles: sufficient criteria
A specific decision flowchart35 indicates whether a candidate c (al-ready identified as not being a NE) is an MWE or not. The main char-acteristic of these guidelines is that, unless stated otherwise, each in-dividual criterion is sufficient to tag the candidate as an MWE. This is intended as a solution to the well-known difficulty to make binary de-cisions within the continuous scale of idiomaticity. It is reminiscent of
35https://gitlab.lis-lab.fr/PARSEME-FR/PARSEME-FR-public/ wikis/Criteres
how the lexicon-grammar is organized using dozens of binary prop-erties Gross (1994). The alternative solution, used e.g., for MWEs in the French Treebank, is to ask annotators to judge whether there are enough satisfied criteria in order to tag a sequence as MWE (Abeillé and Clément 1999–2015).36 The number and the relative weight of the criteria being difficult to assess, we thus prefer to consider suffi-cient criteria only. The annotated MWEs will satisfy a varying number of criteria, thus we obtain an MWE lexicon with a varying degree of idiomaticity.
The various criteria are defined using precise linguistic tests, de-signed to formalize lexical, morphological, syntactic or semantic id-iosyncrasy (the former being generally a clue for the last). A test gen-erally consists of studying how a modification of c (such as replacing, adding or removing one component) impacts its acceptability and its interpretation. The considered modifications are only those allowed for non-MWE sequences, within the regular grammar of the language. The test succeeds if the modification leads to unacceptability: for ex-ample, in (11), the adverb bien ‘well’ can normally be modified by the intensifier très ‘very’, but this leads to unacceptability in the context of the MWE bien que ‘well that’⇒‘even though’. The test also succeeds if the result after modification remains acceptable, but exhibits an unex-pected meaning shift given the applied modification (henceforth noted #). For instance, in the MWE carte bleue ‘card blue’⇒‘credit card’, sub-stituting the color adjective by another color is acceptable, but the meaning change is not the expected change of color meaning. (11) Je I continue continue (*très) (very) bien well que that j’ I aie have peur. fear ‘I go on (*very) even though I am afraid.’
Meaning shift is not a binary property, but rather a fuzzy value in a continuum.37A transformation applied to any phrase may yield a result which ranges from completely expected to totally surprising, with many possible interpretations in between. Ideally, we would like
36The guidelines mention “a beam of criteria” (“un faisceau de critères”). 37One can argue that the same is true for acceptability, although the pre-dictability of a meaning shift is arguably more subtle to assess than a sequence’s acceptability for an average speaker.
to quantify meaning shift, e.g. as the branch distance in Wordnet, or the embeddings’ cosine similarity. This would allow us to establish a numerical threshold beyond which meaning shift is considered un-expected, making annotation more reproducible. In practice, though, this is not feasible because our tests operate on whole multiword phrases, whose representation is not straightforward. We resort to comparing the same transformation to other phrases which are clearly not MWEs, and assessing whether the transformation applied to the candidate follows the same pattern, in which case it should not be an-notated as an MWE, or if the meaning change is indeed unexpected with respect to similar non-MWE phrases.
7.2 Span of MWEs
When a candidate sequence passes at least one MWE test, it remains to decide which elements are actually part of the MWE (Savary et al. 2018). These elements do not vary lexically, that is, their lemma cannot vary (morphological variation is possible). For instance, in the sequence en termes économiques/pratiques/démographiques (‘in eco-nomic/practical/demographic terms’), we consider en termes as forming an MWE, with an open slot.
7.2.1 Selected prepositions and complementizers
introducing open slots
In some cases an MWE selects an argument (mandatory or not) that is not itself frozen, but is introduced by a frozen preposition or comple-mentizer that functions as a grammatical marker. Although the marker is frozen, we have chosen not to include it in the MWE. For instance in example (12), we annotate en and dépit as an MWE, which takes a mandatory prepositional phrase with the preposition de, not included in the MWE. This treatment derives from the general treatment of grammatical markers: we do not consider that a verb plus the prepo-sition it subcategorizes for forms an MWE (e.g., we do not annotate any MWE in Je compte sur toi ‘I am counting on you’, even though the preposition is frozen). Our choice is to privilege a consistent treat-ment of selected prepositions and completreat-mentizers at the expense of excluding some mandatory elements from the MWEs’ annotation span.
(12) Il he a has continué continued en in dépit bitterness de of nos our appels. calls ‘He continued in spite of our calls.’
The rule for excluding final grammatical markers has an excep-tion, though. For a sequence containing just one component plus a selected preposition, we annotate it as MWE if it satisfies other crite-ria than the fixedness of the preposition. This is the case, for instance, for faute de ‘fault of’: it functions as a sentence modifier (13), which is normally not the case for a non-temporal noun such as faute ‘fault’. (13) Faute fault d’ of accord, agreement, la the proposition proposition de of loi law est is rejetée. rejected ‘Since no agreement is reached, the proposed law is rejected.’ For selected complementizers, we generally follow the same rule as for selected prepositions. In particular, prepositions intro-ducing a clause starting by que ‘that’ do not form an MWE with the complementizer. Indeed, in this particular case, the finite clause introduced by the complementizer generally alternates with an in-finitival clause introduced by de, and is generally optional, as in (14). This fact provides an additional justification for not includ-ing the complementizer, and thus not annotatinclud-ing the combination as an MWE. (14) Il he part leaves avant before (; (; | | la the fin end | | de of finir to-end | | que that tu you finisses). end) ‘He leaves before (; | the end | finishing | you finish).’
As an exception, we consider certain sequences of the form ADV + que, as irregular and tag them MWEs (Section 12).
7.2.2 Determiners
The inclusion of a determiner in the annotation span depends on its frozen status. By default, if the determiner is totally frozen, or can vary only in gender, number, or person of the possessor, then it should be included. For instance, in fruit de la passion ‘fruit of the passion’⇒‘passion fruit’, the determiner does not accept any variation #fruit de (cette | une | ma) passion ‘fruit of (this | a | my) passion’.
However, deciding whether a determiner is frozen is not straight-forward because we must deal with a large number of special cases. Therefore, a dedicated decision flowchart and detailed instructions, also covering the special case of “zero” determiners, are presented in the identification criteria named DET and ZERO in Section 7.3.
7.3 Identification criteria
The criteria to determine whether c is a non-verbal MWE are summa-rized as follows:
1. Semantic criteria
• [ID] the syntactic head of c is not its “hypernym”
• [PRED] no predication relation between head and modifier 2. Lexical fixedness criteria
• [CRAN] c contains a cranberry word
• [LEX] no replacement of a content word by a similar word • [DET] the determiner of a noun is totally fixed
• [ZERO] possible empty determiner, while usually required 3. Morphosyntactic fixedness criteria
• [MORPHO] no modification of the morphological features • [IRREG] irregular morphosyntactic structure
• [SYNT] impossibility of syntactic variation for some patterns • [INSERT] no insertion of modifiers, while usually possible The description of each criterion is provided in Appendix.
8 ANNOTATION PROCESS AND QUALITY
We now detail our source corpus (Section 8.1), annotation process (Section 8.2) and the quality of the MWE/NE annotations (Sec-tion 8.3).
8.1 Source corpus
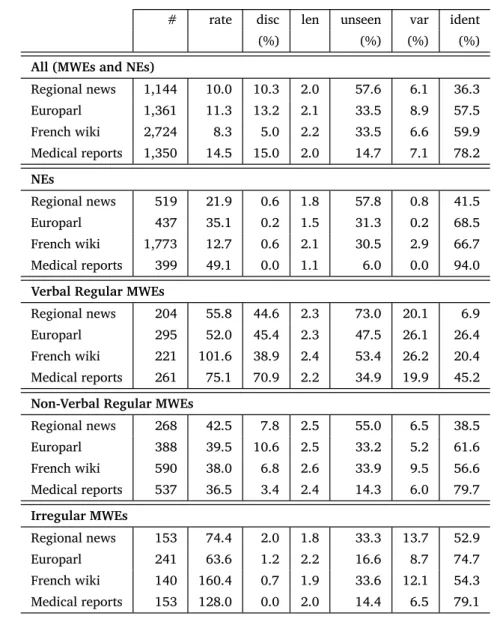
We chose to annotate the Sequoia corpus (Candito and Seddah 2012), which is a freely available corpus containing 3,099 sentences, ini-tially annotated for morphology and syntax. Other kinds of annota-tions were subsequently added (e.g., deep syntax and semantic frames, coarse semantic categories for nouns), thus making the overall corpus richly annotated.
The corpus was first created to perform domain adaptation exper-iments, hence it comprises sentences originating from four different sources: a regional newspaper (L’Est Républicain, narrative historical pages from the French wikipedia, Europarl transcriptions, and two medical reports from the European Medicine Agency). In the original morphosyntactic annotations, only functional MWEs had been anno-tated. We ignored these annotations in our first annotation phase, and used them afterwards to spot potential errors (Section 8.2).
8.2 Annotation process
Our annotation process classically comprises a pilot phase to test and improve the guidelines, a double annotation plus adjudication phase, and a further phase of coherence checking.
We chose not to use any pre-annotating tools, which are known to introduce task-dependent biases (e.g. Fort and Sagot 2010 for POS tagging). Indeed, although such tools speed up annotation and uni-formize simple repetitive annotations, the negative effect is that an-notators will tend to reproduce noise and silence induced by the tool (Savary et al. 2018). Moreover, since our main objective was to op-erationalize and test MWE identification criteria, we did not want to rely on pre-annotating tools, necessarily based on pre-existing MWE resources. This has obviously prevented us from annotating a large corpus.
After a first rough version of the guidelines, we performed a pilot annotation on a fraction of the Sequoia corpus, corresponding to two French wikipedia pages (containing about 2,000 tokens and 93 sen-tences). Four annotators (among the authors of this article) annotated this fraction, and collectively adjudicated it, gathering feedback to complete and amend the guidelines.