Mid-level features and spatio-temporal context for activity recognition
Texte intégral
Figure
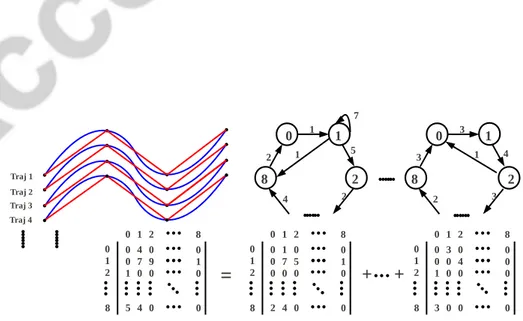
![Figure 1: Examples of extracted activity-components from the UT-Interaction dataset [ 36 ]](https://thumb-eu.123doks.com/thumbv2/123doknet/2640457.59529/9.917.166.751.251.696/figure-examples-extracted-activity-components-ut-interaction-dataset.webp)
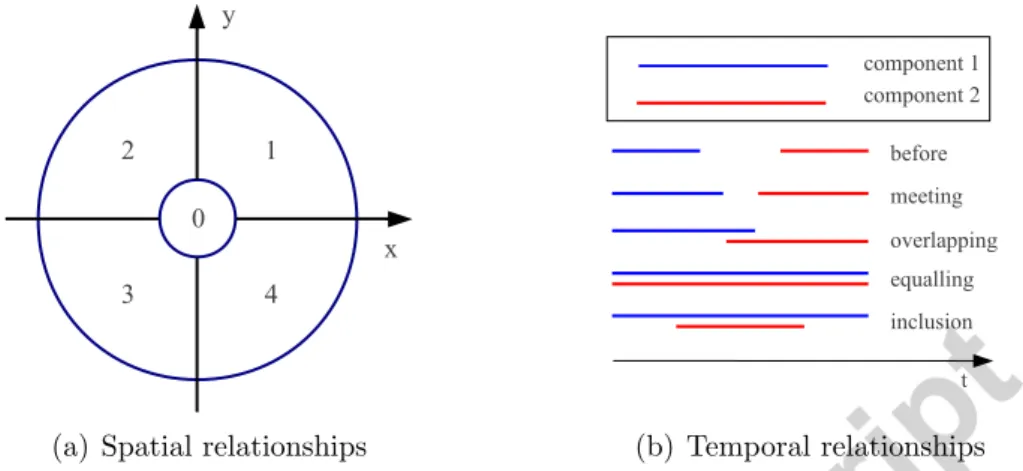
![Figure 5: Snapshot examples of video sequences in two activity datasets: the UT- UT-Interaction Dataset [ 36 ] and the Rochester Activities Dataset [ 19 ].](https://thumb-eu.123doks.com/thumbv2/123doknet/2640457.59529/16.917.181.755.270.524/snapshot-examples-sequences-activity-datasets-interaction-rochester-activities.webp)
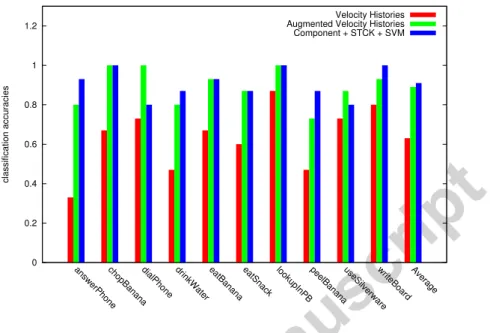
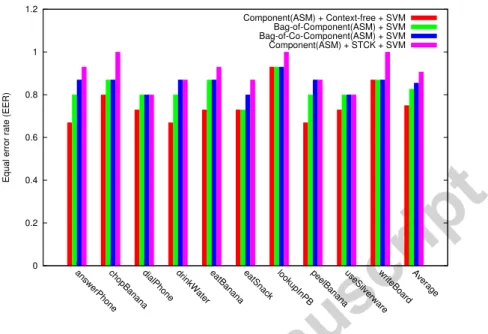
Documents relatifs
In this paper, we extend the Spatio-Temporal Graph Convolutional Network for skeleton- based action recognition by introducing two novel modules, namely, the Graph Vertex
Our representation captures not only global distribution of features but also focuses on geometric and appearance (both visual and motion) relations among the fea- tures.. Calculating
Contrary to the state-of-the-art methods implying procedures to extract feature vectors (mean, variance, skewness, kurtosis...) for all acceleration signals and then reduce
Appearance and flow informa- tion is extracted at characteristic positions obtained from human pose and aggregated over frames of a video.. Our P-CNN description is shown to
Abstract— In robotic navigation, biologically inspired local- ization models have often exhibited interesting features and proven to be competitive with other solutions in terms
A Comparison of Wavelet Based Spatio-temporal Decomposition Methods for Dynamic Texture Recognition... Spatio-temporal Decomposition Methods for Dynamic
Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of
• Spatio-temporal SURF (ST-SURF): After video temporal segmentation and human action detection, we propose a new algorithm based on the extension of the SURF descriptors to the
