UNIVERSITÉ MOHAMMED V – AGDAL
FACULTÉ DES SCIENCES
Rabat
Faculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat – Maroc Tel +212 (0) 37 77 18 34/35/38, Fax : +212 (0) 37 77 42 61, http://www.fsr.ac.ma
N° d’ordre : 2430.
THÈSE DE DOCTORAT
Présentée par
Atman JBARI
Discipline : Sciences de l’ingénieur
Spécialité : Informatique et Télécommunications
Séparation Aveugle de Sources par contrastes à références
et analyse du contenu temps-échelle
Soutenue le ………10/01/2009………..
Devant le jury
Président :
Prof Driss ABOUTAJDINE
PES, FS-RABAT
Examinateurs :
Abdellah ADIB
PES, FST- Mohammedia
Mohamed JEDRA
PES, FS-RABAT
M'hamed BAKRIM PES, FST-Marrakech
Aziz ETTOUHAMI
PES, FS-RABAT
Avant propos
Le travail de cette thèse a été réalisé au sein du Laboratoire de Recherche en Informatique et Télécommunications (LRIT) de la Faculté des Sciences de Rabat Université Mohammed V Agdal. Je tiens tout d’abord à exprimer ma profonde gratitude à Monsieur Driss ABOUTAJDINE, professeur à la Faculté des Sciences de Rabat et responsable du LRIT, pour m’avoir encadré avec un intérêt constant et une grande compétence, pour sa disponibilité, son soutien, son encadrement et les encouragements qui m’ont permis de mener à bien ce travail. J’exprime ma profonde re-connaissance à Monsieur Abdellah ADIB, membre du laboratoire LRIT et professeur à la faculté des sciences et techniques de Mohammedia, pour la qualité de l’encadrement qu’il m’a assuré, sa rigueur scientifique, son aide précieuse et les efforts qu’il a prodigués pour l’accomplissement de ce travail.
Sincères remerciements au professeur M’hammed BAKRIM, professeur à la faculté des sciences et techniques de Marrakech, pour avoir accepter d’être rapporteur de cette thèse. Je le remercie aussi pour les discussions et ses remarques. Que Monsieur Mohamed JEDRA, profes-seur à la faculté des sciences de Rabat, trouve ici l’expression de mes remerciements les plus sincères d’avoir accepté de juger ce travail et d’en être rapporteur.
Je suis très honoré par la présence des professeurs Aziz ETTOUHAMI et Hamid TOUMA, à la faculté des sciences de Rabat. Qu’ils trouvent ici mes plus vifs remerciements d’avoir accepté de juger ce travail, et pour les discussions que nous avons menées sur le sujet de cette thèse.
J’exprime également mes remerciements aussi bien au Doyen de la faculté des sciences, qu’au personnel du département de physique et des différents services. Mes remerciements vont aussi à tous mes collègues dans le laboratoire LRIT. Finalement, je remercie chaleureusement mes pa-rents, ma femme, et ma famille pour leur soutien.
Résumé
Le travail de cette thèse est consacré à la séparation aveugle de sources (SAS) par utilisation des fonctions de contrastes à références et analyse du contenu temps-échelle. Le problème se pré-sente quand les mesures, effectuées par un réseau de capteurs, correspondent aux mélanges d’un ensemble de signaux sources inobservables. Ainsi, la restitution des différentes composantes de chaque mélange est indispensable pour reconstruire le contenu original, dont le traitement per-met d’évaluer les grandeurs physiques recherchées dans plusieurs domaines : biomédical, parole, communications numériques, imagerie satellitaire,...
Dans le cas d’un mélange linéaire et sur-déterminé (plus de capteurs que de sources), les techniques développées suivent trois approches : approche statistique, approche spectrale et ap-proche hybride. Dans la première apap-proche, le contenu à extraire est de type statistique, les sources sont supposées statistiquement indépendantes et les statistiques d’ordre supérieur sont utilisées pour construire des contrastes de séparation. La deuxième approche traite le contenu spectral des sources présentant une diversité de signatures dans le domaine temps-échelle, et pouvant être non-stationnaires. Un ensemble de mesures du contenu, et d’indices de performances sont proposés également par analyse locale des signaux dans le temps et pour plusieurs échelles. Tandis que la dernière approche propose des solutions hybrides en combinant des blocs de pré-traitement et de séparation.
Enfin, nous appliquons les techniques précédentes dans deux domaines : domaine biomédical et domaine des communications numériques. La première application consiste à extraire le signal d’activité cardiaque fECG du fœus, à partir de l’ensemble de mesures ECG sur le thorax et l’abdo-men de la mère. La seconde application traite la séparation de signaux CDMA, après construction d’un modèle de mélange linéaire instantané, équivalent au modèle convolutif de transmission, et bloc-diagonalisation conjointe d’un ensemble de matrices exprimant l’indépendance statistique entre les données émises.
Mots-clefs :
Séparation Aveugle de Sources, Fonctions de contrastes, Système à références, Diagonalisa-tion conjointe, EvaluaDiagonalisa-tion du contenu, Analyse temps-échelle, Indices de performances.
Introduction générale
La Séparation Aveugle de Sources (SAS) consiste à reconstruire les différents signaux origi-naux contribuant dans un ensemble de mesures. En effet, le milieu de propagation agit, par ses caractéristiques, sur l’ensemble des signaux sources, et les capteurs utilisés ne peuvent mesurer qu’un mélange des différentes contributions de chaque source. Ainsi, l’extraction du contenu inté-gré dans chaque mesure est nécessaire pour traiter et évaluer les paramètres recherchés. Le terme aveugle signifie que les sources ne sont pas directement observables, et que le système de mélange est inconnu.
Les applications des techniques de la séparation aveugle de sources sont très nombreuses et touchent les domaines suivants : Traitement des signaux audio (démixage d’enregistrements mu-sicaux, séparation de paroles,...) [43] [108] [127], séparation de signaux biomédicaux (Electro-cardiapraphie ECG, Electroencephalographie EEG, Electromyographie EMG) [82], communica-tion numériques (égalisacommunica-tion, SDMA, CDMA, OFDM,...) [35] [103] [111] [128], imagerie satelli-taire [31] [74] [75],...
La résolution du problème de la SAS exploite des hypothèses sur les sources et le mélange. La stationnarité, l’indépendance ou la décorrélation concernent les sources, tandis que le problème de la linéarité et l’effet mémoire de la mesure du capteur, relativement à chaque source, concernent le mélange. Un autre paramètre très important est celui du rapport nombre de capteurs/nombre de sources, permettant de distinguer deux cas : mélange sur-déterminé et mélange sous-déterminé. Ainsi, toute méthode de séparation doit tenir compte des caractéristiques des sources et du mé-lange. Les premiers travaux, dans le domaine de la SAS, sont attribués à Hérault & Jutten au milieu des années 80 [58] [59].
Dans cette thèse, les techniques développées, pour la résolution du problème de la SAS, suivent trois approches : approche statistique, approche spectrale et approche hybride. L’organisation de ce document respecte la même logique : un chapitre sera réservé pour chaque approche.
Le premier chapitre est consacré à la description des différents contenus d’un signal, ainsi qu’aux représentations mathématiques adaptées à la caractérisation et le traitement de chaque type de contenu. Ces représentations sont comparées et discutées à travers plusieurs exemples et
ap-INTRODUCTION GÉNÉRALE iii
plications. Ce chapitre nous permettra de bien poser le problème de séparation dans un contexte général, et de déterminer l’approche de travail, en répondant aux questions suivantes : Quels types de contenus intégrés dans les sources ? et quelle représentation devant être utilisée pour caracté-riser et séparer, sans dégradation, ces contenus ? Dans le deuxième chapitre, nous rappelons la formulation du problème de séparation et nous discutons les hypothèses sur les sources et sur le mélange. Un ensemble de critères et indices de performances relatifs à la séparation est également présenté. Nous terminons ce chapitre par un exemple d’illustration sur des signaux déterministes et des signaux audio, suivi par les domaines d’application de la SAS.
Nous abordons la résolution du problème de la SAS, selon l’approche statistique, dans le cha-pitre 3. Dans ce cas, les signaux sources sont supposés stationnaires et mutuellement indépen-dants. Ainsi des critères de séparation, sous le nom de fonctions de contraste à références, sont proposés pour l’évaluation et la séparation du contenu statistique, par utilisation des cumulants ( statistiques d’ordre supérieur). Afin d’optimiser ces fonctions de contraste, nous développons des solutions analytiques et nous montrons le lien du critère proposé avec celui de la diagonalisation conjointe [62] [63] [70].
Pour la séparation de sources non-stationnaires et non nécessairement indépendantes, l’ap-proche spectrale est appliquée dans le chapitre 4. Ainsi, nous utilisons la transformée en ondelettes pour évaluer le contenu temps-échelle et pour construire des distributions spatiales permettant de caractériser l’énergie des signaux et de leurs interférences. Ainsi, l’hypothèse de la diversité temps-échelle est introduite. Sur la base de cette hypothèse, nous proposons deux algorithmes et un en-semble de mesures du contenu et de performances de séparation dans le domaine temps-échelle. Les algorithmes et les mesures proposées sont testés et comparés dans le cas d’un mélange linéaire instantané et d’un mélange convolutif de signaux audio [67] [72].
Nous développons une approche hybride dans le chapitre 5, en combinant le débruitage, l’ana-lyse temps-échelle et les statistiques d’ordre supérieur. Nous étudions l’effet du débruitage et l’analyse multi-résolution des observations sur la séparation par un contraste à références. Après, les non-stationnarités seront évaluées par l’analyse temps-échelle des variations des statistiques d’ordre supérieur [66] [73].
Enfin, deux applications seront traitées dans le dernier chapitre. La première application, liée au domaine biomédical, vise l’extraction du signal du fœtus à partir des mesures effectuées par les électrodes ECG placés sur l’abdomen et le thorax de la mère. Trois techniques sont utilisées et comparées. La deuxième application traite la séparation de signaux du système CDMA. Nous construisons un modèle de données adapté au problème de la séparation de sources, puis nous validons ce modèle par des simulations.
Nous terminons ce rapport par une conclusion générale et des perspectives de recherche pour résoudre et améliorer quelques contraintes.
Table des matières
Résumé i Introduction générale ii Abréviations xiii Notations xiv 1 Représentation du contenu 1 1.1 Introduction . . . 1 1.2 Contenu spectral . . . 2 1.2.1 Transformée de Fourier . . . 2 1.2.2 Représentation temps-fréquence . . . 5 1.2.3 Représentation temps-échelle . . . 7 1.3 Contenu statistique . . . 10 1.4 Contenu vibratoire . . . 11 1.5 Contenu objet . . . 131.6 Mélange de contenus et problème de séparation . . . 14
1.7 Conclusion . . . 15
2 Théorie et domaines de la séparation de sources 16 2.1 Formulation du problème . . . 16
2.1.1 Modèles et séparation . . . 17
2.1.2 Indéterminations . . . 18
TABLE DES MATIÈRES v
2.3 Outils statistiques . . . 21
2.3.1 Corrélations et moments . . . 21
2.3.2 Les cumulants . . . 22
2.3.3 Comparaison des statistiques . . . 23
2.4 Pré-traitement de données . . . 24
2.5 Fonctions de contrastes . . . 25
2.5.1 Définition et propriétés . . . 25
2.5.2 Exemples de contrastes . . . 26
2.6 Transformée en ondelette . . . 27
2.7 Diagonalisation et bloc-diagonalisation conjointe . . . 32
2.8 Indices de performances . . . 34
2.8.1 Diagonalité de la matrice globale . . . 34
2.8.2 Comparaison sources-estimations . . . 35 2.9 Exemples d’illustration . . . 37 2.10 Domaines d’applications . . . 39 2.11 Conclusion . . . 42 3 Contrastes à références 43 3.1 Introduction . . . 43
3.2 Généralisation d’un contraste à référence . . . 44
3.2.1 Contraste de base et généralisation . . . 44
3.2.2 Solution analytique . . . 45
3.3 Système à double référence . . . 47
3.3.1 Nouveau contraste à double référence . . . 47
3.3.2 Optimisation . . . 49
3.3.3 Choix de la référence . . . 51
3.3.4 Indice de comparaison du contenu statistique . . . 52
3.4 Simulations et comparaisons . . . 53
3.5 Conclusion . . . 60
4 Séparation de sources dans le domaine temps-échelle 61 4.1 Introduction . . . 61
TABLE DES MATIÈRES vi
4.2 Analyse temps-échelle . . . 62
4.2.1 Transformation en ondelettes . . . 62
4.2.2 Interprétation de l’analyse temps-échelle . . . 62
4.3 Distributions spatiales . . . 65
4.3.1 Distribution temps-échelle directe . . . 65
4.3.2 Distribution temps-échelle isolée . . . 66
4.4 Techniques de séparation . . . 67
4.4.1 Critères de sélection . . . 67
4.4.2 Diagonalisation conjointe . . . 68
4.4.3 Algorithmes de séparation . . . 68
4.5 Evaluation du contenu dans le domaine temps-échelle . . . 69
4.5.1 Contenu temps-échelle . . . 69
4.5.2 Nouveaux indices de performances . . . 74
4.6 Séparation de mélanges convolutifs . . . 75
4.6.1 Modèle de données et hypothèses . . . 75
4.6.2 Distributions et séparation . . . 76
4.7 Simulations . . . 78
4.7.1 Exemple d’évaluation . . . 79
4.7.2 Performances et comparaisons . . . 80
4.8 Conclusion . . . 87
5 Techniques de séparation hybrides 88 5.1 Introduction . . . 88
5.2 Analyse multi-résolution et débruitage . . . 88
5.3 Analyse temps-échelle des statistiques d’ordre supérieur . . . 92
5.3.1 Mesure des variations statistiques . . . 92
5.3.2 Technique de séparation . . . 93
5.4 Simulations . . . 93
5.5 Conclusion . . . 97
6 Applications 99 6.1 Introduction . . . 99
TABLE DES MATIÈRES vii
6.2 Extraction du signal fECG . . . 99
6.2.1 Description et modèle de données . . . 99
6.2.2 Analyse et séparation . . . 101
6.3 Système CDMA . . . 106
6.3.1 Description du système CDMA . . . 106
6.3.2 Modèle de données . . . 107
6.3.3 Séparation et performances . . . 110
6.4 Conclusion . . . 112
Conclusion générale et perspectives 113
A Détail de la solution analytique 116
B Bloc-diagonalisation simultanée de matrices 119
Liste des figures
1.1 Description des contenus et des méthodes d’analyse associées. . . 2
1.2 Signal ECG et son spectre, canal 1, durée =4s, fréquence d’échantillonnage Fe= 250Hz (signal e1(t)). . . . 3
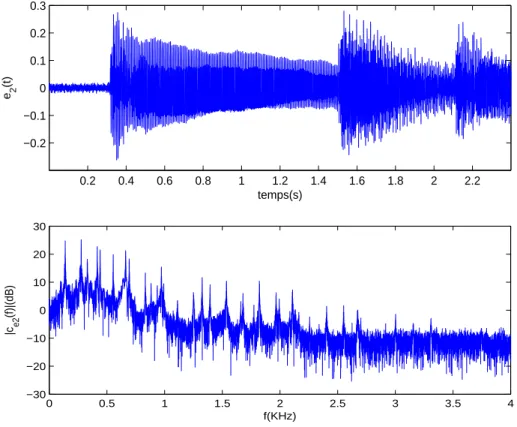
1.3 Signal audio et son spectre, durée =2.5ms, fréquence d’échantillonnage Fs = 8KHz, nombre de bits=16 (signal e2(t)). . . . 4
1.4 Déviation fréquentielle d’un oscillateur de 150Hz (signal e3(t)). . . . 4
1.5 Spectrogramme de la déviation e3(t). . . . 5
1.6 Représentation temps-fréquence du signal ECG (e1(t)) : Wigner-Ville (à gauche), Choi-Williams ( à droite). . . 6
1.7 Représentation temps-fréquence du signal e3(t) : Wigner-Ville (à gauche), Choi-Williams ( à droite). . . 7
1.8 Représentation temps-échelle du signal ECG (e1(t)). . . . 8
1.9 Représentation temps-échelle du signal audio (e2(t)). . . . 8
1.10 Représentation temps-échelle de la déviation (e3(t)). . . . 8
1.11 Auto-corrélation du signal ECG (e1(t)). . . . 11
1.12 Auto-corrélation du signal audio (e2(t)). . . . 11
1.13 Décomposition EMD d’une séquence audio [375ms, 624.9ms] de e1(t). . . . 12
1.14 Disque à quartz (1cm de diamètre, qq µm d’épaisseur) et modes de résonance. . . 13
1.15 Microbalance à quartz et extraction du contenu des oscillations : Amplitude A0, fréquence d’oscillation f , constante de temps τ et facteur de dissipation D [98]. . 13
1.16 Segmentation de la région d’intérêt : image initiale (à gauche) et extraction de la fenêtre d’analyse (à droite) [52]. . . 14
1.17 Image SPOT du Barrage EL Wahda, Maroc [2]. . . 14
LISTE DES FIGURES ix
2.1 Mélange de sources dans un milieu de propagation. . . 16
2.2 Modèle général du problème mélange-séparation. . . 18
2.3 Séparation adaptative . . . 18
2.4 Analyse continue par ondelette. . . 28
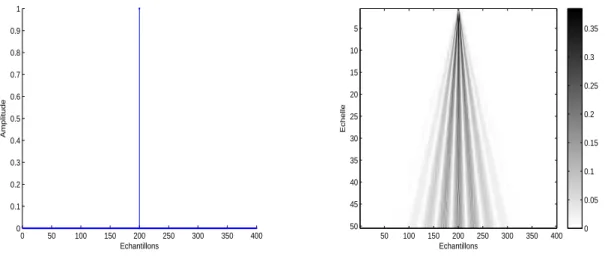
2.5 Impulsion de dirac (unitaire) et le module de sa CWT. . . 29
2.6 Décalage de l’impulsion unitaire et sa CWT. . . 30
2.7 Localisation temps-échelle des composantes d’une tension d’alimentation alterna-tive. . . 31
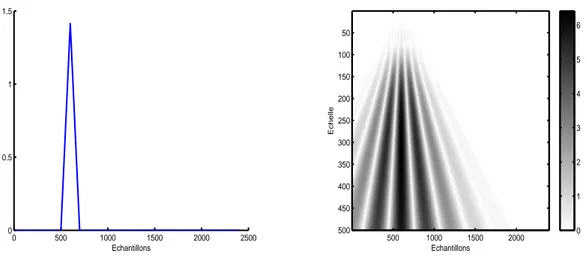
2.8 Impulsion triangulaire et sa CWT. . . 31
2.9 Changement d’échelle de l’impulsion triangulaire et sa CWT. . . 32
2.10 Exemple de séparation : sources (s1, s2, s3), mélanges (x1, x2, x3) et estimations (y1, y2, y3). . . 38
2.11 Exemple de séparation d’un mélange audio. . . 39
2.12 Séparation aveugle de sources audio [4]. . . 40
2.13 Problème d’Electrocardiographie ECG [33]. . . 40
2.14 Problème d’Electromyographie EMG [33]. . . 41
2.15 Problème d’Electroencephalographie EEG [33]. . . 41
2.16 Problème de communication sans fil [33]. . . 42
3.1 Séparation par un système à référence. . . 43
3.2 Système de séparation à double référence. . . 47
3.3 Signaux sources de la famille de contraste. . . 53
3.4 Performances de séparation par la famille de contraste. . . 54
3.5 Sources et observations, SNR=5dB. . . 54
3.6 Performances de séparation : DRCS-1, DRCS-2 et JADE. . . 55
3.7 Performances de séparation, nombre de sources = 4. . . 56
3.8 Performances de séparation, nombre de sources = 5. . . 57
3.9 Performances de séparation, nombre de sources = 6. . . 57
3.10 Performances de séparation vs la taille de données, SNR = 5dB. . . . 58
3.11 Performances de séparation vs la taille de données, SNR = 10dB. . . . 58 3.12 Comparaison du contenu statistique sources-estimations et relation avec l’indice PI. 59
LISTE DES FIGURES x
4.1 Translation et mise en échelle de l’ondelette ’morlet’. . . 62
4.2 Spectres de l’ondelette ’morlet’ pour les échelles : 2, 1, 0.5, 0.25, 0.2. . . . 64
4.3 Représentation temps-échelle et temps-fréquence d’une séquence audio (du-rée=0.25s, Fe=8kHz, 16bits). . . 65
4.4 Signal audio, durée= 2.4s, Fe= 8kHz, 16bits. . . . 70
4.5 Distribution en échelle du contenu TSAC aux instants t1= 0.125s,t2= 0.625s,t3= 1.25s,t4= 1.75s,t5= 2.375s. . . . 70
4.6 Distribution temporelle du contenu TSAC. . . 71
4.7 Distribution temporelle du contenu temps-échelle du signal s1(t). . . . 71
4.8 Variation relative du contenu TSAC. . . 72
4.9 Analyse du contenu temps-échelle, par l’ondelette ’morlet’, d’une mesure pertur-bée de la vitesse d’un moteur à courant continu. . . 73
4.10 Signal audio s2(t), durée= 2.4s, Fe= 8kHz. . . . 73
4.11 Distribution de l’inter-contenu temps-échelle des signaux s1(t) et s2(t). . . . 74
4.12 Taille mémoire des observations en fonction de la longueur du canal. Les courbes sont paramétrées par le nombre de capteurs. . . 77
4.13 Mélange de quatre signaux audio et séparation par l’algorithme TSS. . . 79
4.14 Distributions temps-échelle des énergies des sources (Auto-termes). . . 80
4.15 Distribution du contenu audio temps-échelle des estimations. . . 81
4.16 Influence du seuil de sélection sur le nombre des auto-termes des distributions STSD et Wigner-Ville. . . 82
4.17 Performances de séparation des algorithmes ITSS,TSS, et SOBI. . . 82
4.18 Indice de séparation PI vs SNR pour les algorithmes : TSS, ITSS et TF-WV. . . . 83
4.19 Erreur quadratique du contenu temps-échelle TSACE en fonction du SNR. . . . 84
4.20 Contenu ACPS d’une source vs SNR. . . 84
4.21 Comparaison du contenu global ACPS vs SNR pour les algorithmes : TSS, ITSS et TF-WV. . . 85
4.22 Mélanges réels de deux signaux audio . . . 86
4.23 Séparation audio par l’algorithme ITSS-conv, sources et estimations. . . 86
4.24 Indice de comparaison localisée NTSACD vs SNR. . . 87
LISTE DES FIGURES xi
5.2 Modèle général du problème mélange-séparation. . . 89
5.3 Les deux types de sélection des coefficients de détail : ’hard’ et ’soft’. . . 91
5.4 Séparation par débruitage et statistiques. . . 91
5.5 Séparation par analyse multi-résolution et statistiques. . . 91
5.6 Système de séparation par analyse temps-échelle des statistiques à référence. . . 92
5.7 Signaux sources (a) et mélanges (b). . . 94
5.8 Performances de séparation avec filtrage des observations par ondelettes. . . 95
5.9 Performances de séparation avec analyse multi-résolution des observations, onde-lette de type ’db2’(a) et ’haar’ (b). . . 96
5.10 Performances de séparation des algorithmes JADE et TSHS. . . 97
6.1 Diagramme ECG. . . 100
6.2 Les 8 canaux de mesures ECG. . . 101
6.3 Distribution temps-échelle de la mesure ECG-canal ch1. . . 102
6.4 Extraction du signal fECG par contraste à référence. . . 102
6.5 Extraction du signal fECG par analyse multi-résolution, niveau= 3. . . 103
6.6 Extraction du signal fECG par analyse temps-échelle. . . 103
6.7 Distribution temps-échelle de la composante fECG. . . 104
6.8 Distribution temps-échelle de la composante mECG. . . 105
6.9 Système CDMA pour une ligne de transmission. . . 107
6.10 Système CDMA dans un canal hertzien. . . 108
6.11 Technique de séparation aveugle des signaux CDMA. . . 110
6.12 Les signaux sources du système CDMA. . . 111
Liste des tableaux
1.1 Les durées d’exécution des différentes représentations. . . 9
4.1 Algorithmes de séparation TSS et ITSS. . . 68
5.1 Technique de débruitage à base d’analyse multi-résolution. . . 91
Abréviations
CDMA : Code Division Multiple Access CWT : Continuous Wavelet Transform
DRCS : Contraste à double référence (Double Referenced Contrast for Separation) ECG : Electrocardiographie
EEG : Electroencephalographie EMG : Electromyographie
FDMA : Frequency Division Multiple Access
FFT : Transformée de Fourier rapide (Fast Fourier Transform) HOS : Statistiques d’ordre supérieur (High Order Statistics)
JADE : algorithme JADE (Joint Approximate Diagonalisation of Eigenmatrices)
MIMO : Système à plusieurs entrées et plusieurs sorties (Multiple Input Multiple Output) SAS : Séparation Aveugle de Sources
SITSD : Distribution spatiale temps-échelle isolée (Spatial Isolated Time Scale Distribution) SOBI : Algorithme SOBI (Second Order Blind Identification)
SRCS : Contraste à simple référence (Simple Referenced Contrast for Separation) STSD : Distribution spatiale temps-échelle (Spatial Time Scale Distributions) TDMA : Time Division Multiple Access
TSC : Contenu temps-échelle (Time Scale Content)
TSAC : Contenu temps-échelle audio (Time Scale Audio Content) WT : Wavelet Transform
Notations
Nous adopterons le long de ce rapport les notations générales suivantes : R : Corps des nombres réels
C : Corps des nombres complexes Z : Ensemble des nombres entiers relatifs N : Ensemble des nombres entiers naturels A : Matrice de mélange.
B : Matrice de séparation. W : Matrice de blanchiment. G : Matrice globale de séparation. D : Matrice diagonale.
P : Matrice de permutation.
IN: Matrice identité de dimension N × N.
N : Nombre de sources. M : Nombre de capteurs.
s(t) : Vecteur des signaux sources (N × 1). x(t) : Vecteur des observations (M × 1).
x(t) : Vecteur des signaux normalisés (ˆx(t) = Wx(t)). y(t) : Vecteur des estimations (N × 1).
e(t) : Signal utilisé comme entrée d’une transformation quelconque. Cumq[x] = Cumq[x1, · · · , xq] : Cumulant d’ordre q du vecteur x(t).
z(t), v(t) : Vecteurs de référence.
ce(τ, ξ) : Coefficient de la transformation en ondelette du signal e(t).
NOTATIONS xv
AH: Matrice transposée hermitienne. A#: Matrice pseudo-inverse de la matrice A.
(.)T : Opérateur de transposition.
ce( f ) : Coefficient de la transformation de Fourier du signal e(t).
ce(τ, ξ) : Coefficient de la transformation en ondelette du signal e(t).
C : Matrice de coefficients d’une représentation exploitée dans la séparation. j : imaginaire pur (j2= −1)
t : variable du temps discret u : variable du temps continu
f : fréquence
Fe: Fréquence d’échantillonnage
arg(.) : argument du nombre complexe en paramètre.
Les éléments suivants : définitions, figures, tableaux, équations, proposition, propriétés et hy-pothèses sont référencés, respectivement, par les préfixes : def., fig., tab., Eq., H., Prop. et Pro.
CHAPITRE
1
Représentation du contenu
1.1 Introduction
Le traitement du signal est basé sur un ensemble de techniques de modélisation, de représen-tation et d’extraction de l’information utile, avec la plus faible dégradation. Le signal à traiter peut être le support d’un contenu simple : amplitude, énergie, bande de fréquence,..., ou un mélange de contenus : une séquence vidéo mélange le son et l’image, document hyper-texte mélange le texte, l’image et l’audio. Dans ce sens, le travail sur la modélisation de la transmission des in-formations de différents types (positions, vitesses) concernant le mouvement d’une articulation a donné naissance au problème de la Séparation Aveugle de Sources (SAS), il y a une vingtaine d’années [13] [58] [59]. Ainsi, le traitement du signal doit développer des techniques pour l’ex-traction du contenu à partir d’un mélange et non simplement son isolation et sa protection contre le bruit. Ce type de contenu, intégré dans un ensemble de données, peut être analysé et interprété selon la nature et les objectifs des applications associées. L’extraction de paramètres caractéris-tiques ou la recherche, selon des critères, d’un objet particulier est nécessaire pour le traitement et l’interprétation de ces données. De la multiplicité des objectifs de traitement, découle la diversité des approches et les outils utilisés. L’objectif principal d’un traitement quelconque est d’extraire le contenu informatif du phénomène traité : contenu spectral, vibratoire, statistique ou objet. La fig.1.1 résume les différents types de contenus et les méthodes d’analyse associées.
La nature du contenu à extraire implique l’utilisation des outils appropriés. Pour bien situer le présent sujet de thèse, dans son contexte général, on va aborder dans ce chapitre, la représentation de chaque type de contenu et ses domaines d’applications suivi de plusieurs exemples d’illustra-tion.
1.2 Contenu spectral 2
Figure 1.1 Description des contenus et des méthodes d’analyse associées.
1.2 Contenu spectral
L’analyse spectrale de données consiste à déterminer les composantes fréquentielles et leurs contributions en terme d’amplitude, phase, puissance ou énergie. Dans un système de transmission, par exemple, la fréquence centrale de l’onde porteuse et la bande occupée sont deux paramètres très déterminants. L’analyse et la synthèse de ces paramètres sont les fonctions essentielles des modulateurs/démodulateurs, des relais de transmission, des stations radio et télédiffusion et des équipements des réseaux de communication. Le spectre est encore exploité dans le cas du filtrage pour la séparation de signaux ou la suppression du bruit. On présente ci-dessous trois techniques d’analyse spectrale : transformée de Fourier, représentation temps-fréquence et transformée par ondelettes (temps-échelle).
1.2.1 Transformée de Fourier
La transformée de Fourier est une technique très répandue dans le domaine du traitement du signal. Elle permet de décomposer un signal e(t) (temps discret t) en composantes fréquentielles , caractérisées par des coefficients ce( f ) de l’équation Eq.1.1, portant l’information de l’amplitude et de la phase à chaque fréquence f :
ce( f ) = T −1
∑
t=0 e(t) exp(−j2π f t T) (1.1)1.2 Contenu spectral 3
L’évaluation de cette transformée est très rapide par utilisation de l’algorithme FFT. Cependant, cette technique possède plusieurs inconvénients :
1. La description du contenu spectral est globale.
2. Le résultat de la décomposition dépend fortement de la fréquence d’échantillonnage et du
contenu spectral du signal
3. L’absence de la localisation temporelle des composantes fréquentielles.
Les spectres des deux signaux discrets : ECG (e1(t)) de la fig.1.2 et audio (e2(t)) de la fig.1.3
ne reflètent pas les durées actives (activité cardiaque et vibration audio) et mortes, mais donnent le contenu global. De même, la fig.1.4 représente une déviation linéaire rattrapée (e3(t)) d’une valeur
∆F = 150Hz, d’un oscillateur harmonique autour de sa fréquence centrale F0= 1MHz. La FFT
caractérise le domaine de variation fréquentielle sans aucune information sur le retour d’oscillateur vers son point de stabilité. Donc, la FFT se trouve mal adaptée à l’analyse des signaux présentant un spectre variable dans le temps tels que les signaux audio. Ainsi, des représentations adaptatives temps-fréquence ont été proposées pour le suivi dynamique du contenu spectral du signal [37] [84].
0 0.5 1 1.5 2 2.5 3 3.5 4 −6 −4 −2 0 2 4 e 1 (t) temps(s) 0 20 40 60 80 100 120 −10 0 10 20 30 f(Hz) |c e 1 (f)|(dB)
Figure 1.2 Signal ECG et son spectre, canal 1, durée =4s, fréquence d’échantillonnage Fe=
1.2 Contenu spectral 4 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 2.2 −0.2 −0.1 0 0.1 0.2 0.3 e 2 (t) temps(s) 0 0.5 1 1.5 2 2.5 3 3.5 4 −30 −20 −10 0 10 20 30 f(KHz) |c e 2 (f)|(dB)
Figure 1.3 Signal audio et son spectre, durée =2.5ms, fréquence d’échantillonnage Fs =
8KHz, nombre de bits=16 (signal e2(t)).
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 −1 −0.5 0 0.5 1 e3 (t) temps(s) 0 50 100 150 200 250 300 350 400 450 500 −30 −20 −10 0 10 20 f(Hz) |c e 3 (f)|(dB)
1.2 Contenu spectral 5
1.2.2 Représentation temps-fréquence
Pour les applications exploitant les caractéristiques instantanées des signaux, évoluant dans le temps et en fréquence, il est important d’utiliser des représentations temps-fréquence. Par exemple, l’étude de régimes transitoires (phase de cinétique d’une réaction chimique, démarrage et changement de vitesse de machines tournantes, perturbations,...) et la localisation d’ondes particulières (radar, astrophysique, arcs électriques) [38] [93]. Ces représentations permettent de concentrer l’analyse en temps et en fréquence du signal, mais la décomposition est toujours mono-fréquentielle. Le temps de calcul dépend donc du nombre de composantes [84]. En plus, l’amélioration des résolutions en fréquence et en temps ne peuvent être arbitraires ; leur produit est constant pour un système donné [114]. Dans ce sens, plusieurs distributions ont été proposées pour approximer le spectre instantané idéal :
Spectrogramme : Le spectrogramme est l’estimation de la transformée de Fourier sur une
durée très courte du signal. Ainsi, le suivi du signal selon des fenêtres permet d’évaluer le spectre instantané. Cependant, les résolutions fréquentielles et temporelles restent insuffisantes. La fig.1.5 montre le spectrogramme du signal e3(t), où chaque composante
mono-fréquentielle est représentée par un nuage de fréquence. Cette méthode est utilisable dans le cas d’applications ne nécessitant pas un pouvoir séparateur important.
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0 100 200 300 400 500 Time Frequency (Hz) −120 −100 −80 −60 −40 −20
Figure 1.5 Spectrogramme de la déviation e3(t).
Distribution de Wigner-Ville : Dans ce cas, tous les points e(t + τ) et e(t − τ) contribuent
dans l’analyse du contenu fréquentiel centré sur le point e(t) comme le montre l’équation Eq.1.2 [51]. L’effet négatif de cette contribution totale est la non-localisation temporelle et fréquentielle de l’analyse. Par conséquent, deux composantes très proches, en temps ou en fréquence, provoquent un chevauchement dans le contenu temps-fréquence. Les points de cet intervalle subissent la transformée FFT dont l’évaluation, point par point, permet de
1.2 Contenu spectral 6
fournir le spectre instantané.
WVe(t, f ) = 2
+∞
∑
τ=−∞
E[e(t + τ)e?(t − τ)] exp(− j4π f τ);
t ∈ [0, T − 1], f ∈ [−1
2 ,12]
(1.2)
Distribution de Choi-Williams : La distribution de Choi-Williams est similaire à celle de
Wi-gner mais elle réduit les effets négatifs de cette dernière [37]. La différence réside dans l’utilisation d’une fonction (noyau) Φ(τ, m) = exp(−α(mτ)2) (α est un paramètre
d’ajuste-ment)) pour ajuster l’influence des points éloignés Eq.1.3.
CWe(t, f ) = 2 +∞
∑
τ=−∞ +∞∑
m=−∞e(t + m + τ)e∗(t + m − τ)Φ(τ, m) exp(− j4π f τ);
t ∈ [0, T − 1], f ∈ [−12 ,12]
(1.3)
la taille de la fenêtre peut être ajustée pour bien localiser le contenu. Les chevauchements, produits par cette distribution, possèdent une amplitude très faible par rapport à celles de la distribution de Wigner [84]. En plus, les deux distributions de Wigner-Ville et Choi-Williams possèdent, comme inconvénient, un coût de calcul élevé [84].
Les deux figures fig.1.6 et fig.1.7 présentent le résultat d’analyse temps-fréquence des deux signaux, ECG et la déviation de l’oscillateur, pour les deux distributions. On constate que la dis-tribution de Choi-Williams possède la capacité d’extraire le contenu local par rapport à celle de Wigner-Ville, mais au détriment du temps de calcul (au moins le double). Dans les deux cas, la fréquence apparaît et évolue dans le même sens de l’évolution temporelle, mais les composantes proches du signal e3(t) ont crées des coefficients incorrects dans la représentation temps-fréquence
par la distribution de Wigner-Ville (fig.1.7). Dans le même but, de caractériser le contenu spectral, une autre idée consiste à estimer la contribution du signal dans une bande de fréquence et non pas à une fréquence stricte. Plus généralement, cette idée a donnée naissance à l’analyse temps-échelle par utilisation des fonctions d’ondelette.
temps(s) f(Hz) 1 2 3 4 20 40 60 80 100 120 temps(s) f(Hz) 1 2 3 4 20 40 60 80 100 120
Figure 1.6 Représentation temps-fréquence du signal ECG (e1(t)) : Wigner-Ville (à gauche),
1.2 Contenu spectral 7 temps(s) f(Hz) 0.2 0.4 0.6 0.8 1 50 100 150 200 250 temps(s) f(Hz) 0.2 0.4 0.6 0.8 1 50 100 150 200 250
Figure 1.7 Représentation temps-fréquence du signal e3(t) : Wigner-Ville (à gauche),
Choi-Williams ( à droite).
1.2.3 Représentation temps-échelle
L’analyse temps-échelle diffère de l’analyse temps-fréquence par la décomposition du signal en fonctions non sinusoïdales appelées ondelettes [117]. Ce type d’analyse ne produit pas d’infor-mations au sens fréquentiel classique, mais plutôt des coefficients selon des échelles Eq.1.4.
ce(τ, ξ) =
Z
Re(u)ψτ,ξ(u)du (1.4)
avec τ ∈ R et ξ > 0. Cependant, l’interprétation fréquentielle est toujours possible. En effet, la fonction ondelette agit comme un filtre passe-bande dont le support temporel peut être déplacé dans le temps, et la fréquence centrale peut être localisée dans la bande d’analyse. Le changement d’échelle ξ est la compression ou la dilatation de l’ondellete. La corrélation de l’ondellete, centrée sur l’instant t, avec le signal e(t) donne le coefficient ce(t, ξ). La reconstruction du signal est
possible, en utilisant les coefficients et l’ondelette "mère" d’analyse.
L’utilisation des ondelettes assure plusieurs avantages par rapport aux distributions temps-fréquence [84] :
– Le temps de calcul est de l’ordre de l’algorithme FFT, ce qui est adapté aux systèmes de traitement en temps-réel et utilisant des circuits programmables (DSP, FPGA,..)
– La transformation en ondelettes (WT) assure un moyen important de compression de don-nées. Cela est dû au fait que peu de coefficients sont significatifs et représentent le contenu du signal. Les autres coefficients sont faibles et, par conséquent, peuvent être éliminés sans aucun effet sur le contenu original du signal.
– L’ondelette possède son propre support temporel réduit et peut être localisé, par translation, sur le bloc de données à analyser ; tandis que les distributions temps-fréquence prennent en considération toutes les données autour du point d’analyse, ce qui affecte la finesse et induit les effets de bord.
Les figures fig.1.8, fig.1.9 et fig.1.10 représentent le résultat d’analyse temps-échelle des trois signaux : ECG, audio et déviation de l’oscillateur, en utilisant l’ondelette ’morlet’ comme onde-lette "mère". Dans tous les cas, on constate la localisation en temps et en échelle du contenu de ces
1.2 Contenu spectral 8 temps(s) Echelle 0 0.5 1 1.5 2 20 40 60 80 100 2 4 6
Figure 1.8 Représentation temps-échelle du signal ECG (e1(t)).
temps(s) Echelle 0.5 1 1.5 2 20 40 60 80 100 0.2 0.4 0.6 0.8
Figure 1.9 Représentation temps-échelle du signal audio (e2(t)).
signaux. La comparaison entre ces résultats et celles des figures fig.1.5, fig.1.6 et fig.1.7 montrent la relation inverse entre l’évolution des fréquences et l’évolution des échelles, avec une rapidité d’évaluation du contenu pour la transformation temps-échelle. Le tableau tab.1.1 donne les diffé-rentes valeurs des durées nécessaires à l’évaluation du contenu des signaux pour le même nombre de 1024 points échelles/fréquences, avec exécution sur un processeur Intel Core Duo (1.83GHz).
Les applications industrielles des ondelettes sont très nombreuses. On cite, de manière non exhaustive, les domaines suivants :
Traitement acoustique : Les applications de la transformée en ondelette discrète
unidimen-sionnelle (1D-WT) dans le domaine du traitement des signaux acoustiques sont très diverses. Ko-bayashi [83] présente quelques exemples de techniques intégrées dans une machine automatisée
time(s) Scale 0 0.5 1 1.5 2 20 40 60 80 100 120 0.5 1 1.5 2 2.5 3 3.5 4
1.2 Contenu spectral 9
représentation \ signal e1(ECG) e2(son) e3(chirp)
Spectrogramme (s) 1.076 0.271 0.267
Wigner-Ville (s) 0.199002 7.807792 0.209567
Choi-Williams (s) 5.710111 140.155425 5.689424 WT (haar/db2) (s) 0.836/2.075 7.963/21.324 0.541/1.310
Tableau 1.1 Les durées d’exécution des différentes représentations.
détectant et traitant des sons. Les engins automobiles produisent des vibrations sonores qu’on peut analyser par la transformée en ondelette continue (CWT) pour marquer les défauts et les irrégu-larités de pièces ou de montages mécaniques (roulements, billes, roues,...) [80]. Des mesures ex-périmentales ont validé l’utilisation de la WT pour l’analyse en fréquence d’échos ultra-soniques suite à une excitation par une impulsion de même bande [6]. Dans cette application, le bruit et les paramètres caractéristiques ont été traités et évalués grâce à une analyse temps-échelle sans destruction du milieu.
Production et contrôle d’énergie électrique : La production d’énergie électrique et le contrôle
des machines tournantes ont été traités par WT. La vitesse de rotation et la fréquence instanta-née peuvent être estimées par analyse temps-échelle des courants statoriques. Toute technique de contrôle de la qualité de puissance produite doit mesurer ou estimer l’influence des harmoniques, des perturbations et des impulsions parasites se propageant dans les lignes de distributions. Si l’analyse FFT fournit des résultats de vue globale sur un ensemble d’acquisitions, l’analyse par ondelettes détecte la corrélation dans les structures des courants/tensions et leurs caractéristiques permettant ainsi d’effectuer un contrôle en temps réel [10] [93].
Processus chimique : Dans l’industrie chimique, le traitement du signal a été largement
ex-ploité et la transformée en ondelettes a bien démontré ses apports. L’analyse temps-échelle permet de réduire le bruit dans les enregistrements électrochimiques, mesurer les énergies des différentes composantes du signal ou de les séparer (reconstitution par transformée inverse), localiser des événements et détecter les paramètres caractéristiques des grandeurs d’influence [11] [38].
Compression d’image : Un algorithme de compression basé sur les coefficients d’ondelettes
d’une image produit un bon rapport compression/qualité relativement à un algorithme JPEG. Le standard de compression JPEG2000 est basé sur la quantification des coefficients DWT dans la base bio-orthogonale de Daubechies [15]. Une application, très connue, est la compression des empreintes digitales exploitant la transformée en ondelettes adoptée par le FBI en 1993, pour stocker 200 millions d’enregistrements représentant une quantité de 2000 TeraBytes. Dans cette application, une simple quantification scalaire de 64-sous bandes a été exploitée pour assurer une bonne qualité d’image avec un taux de compression de 20/1 [36]. La compression video est une extension naturelle des applications de la transformée en ondelette dans le domaine d’imagerie [31].
1.3 Contenu statistique 10
Imagerie satellitaire : L’imagerie Haute Résolution est devenue un élément axial dans
l’indus-trie geospatiale comme dans l’indusl’indus-trie civile. Les tailles demandées nécessitent une compression de données sans dégrader la qualité. La transformée 3D-WT a été utilisée pour la réduction du bruit et le traitement spatial et spectral de données des images Landsat avec application dans la surveillance forestière [74] [75]. Le système d’information géographique (SIG), outil très utilisé dans les applications topographiques, exploite les avantages de la WT pour modéliser des relations géographiques complexes [102].
Bio-informatique : Ce sont des applications relatives aux différents champs de la biologie
né-cessitant le traitement du signal et d’image telle que l’analyse de séquences ADN, dans laquelle la qualité de localisation espace-fréquence, offerte par la transformée en ondelette, est très inté-ressante. Dans [78], Kawagashira propose une méthode nommée "wavelet profile" basée sur une analyse multi-résolution. Les séquences de protéines représentées numériquement par plusieurs in-dices (polarité, potentiel d’intégration électron-ion d’acide-amine) peuvent être décomposées par la WT puis sur-échantillonnées pour chercher la similitude entre différents protéines pour plusieurs échelles [85].
1.3 Contenu statistique
Les méthodes précédentes assurent une analyse du contenu dans un espace de propriétés (temps, fréquence, énergie, échelle,...). Les manières de réalisation des processus associés aux données et la relation entre eux n’ont pas été traité. En fait, un phénomène est souvent le résultat de plusieurs sources. L’étude des possibilités de contribution de chaque source et la probabilité de son influence renseigne sur l’évolution du phénomène. Ainsi, l’analyse du contenu statistique fournit des informations importantes sur la réalisation des grandeurs et les relations entre elles. Les applications demandant l’analyse du contenu statistique sont très nombreuses et très diverses : analyse des bourses et des marchés (économie) [12] [18] [81], traitement des maladies et effet des médicaments (médecine) [91], suivi de l’état climatique (écologie), caractéristiques et évolution de la population (démographie), séparation et filtrage de bruit (optique, électronique) [44],...
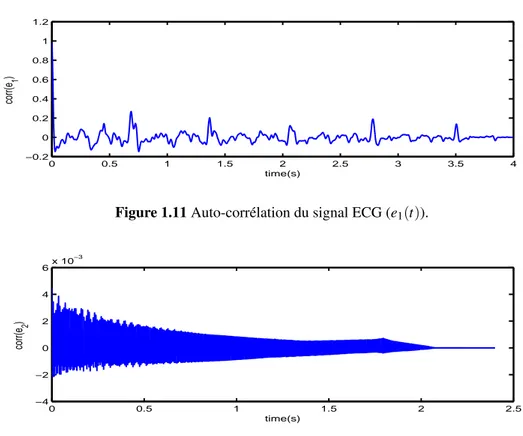
Les fonctions d’évaluation du contenu statistique sont multiples : densité de probabilité, in-formation mutuelle, moments (statistiques du second ordre), cumulants (statistiques d’ordre su-périeur). L’estimation statique ou dynamique de ces fonctions renseigne sur les caractéristiques quantitatives et qualitatives des phénomènes étudiés. Par exemple, le calcul de la fonction de corré-lation, d’une radiation lumineuse, en un point e(t), avec une différence de marche τ, e0(t) = e(t −τ) permet d’extraire, la forme du contenu des franges d’interférences. Les autocorrélations représen-tées dans les figures fig.1.11 et fig.1.12 des signaux ECG e1(t) et audio e2(t) précisent les
dé-pendances de réalisation entre les échantillons successifs, la ressemblance entre le même signal et sa version retardée. En plus, le calcul du cumulant d’ordre quatre, appelé kurtosis, des différents
1.4 Contenu vibratoire 11
signaux (kurt(e1) = 10.2213, kurt(e2) = 3.5213) permet d’évaluer le degré de la non-gaussianité
des distributions respectives des signaux e1(t) et e2(t). L’extraction du contenu peut être effectué
par la construction de classes rassemblées selon des distances statistiques. Ainsi, les connaissances préalables des caractéristiques statistiques d’un phénomène ou d’une composante d’influence sur ce phénomène permet d’isoler le contenu de cette composante [22] [41].
0 0.5 1 1.5 2 2.5 3 3.5 4 −0.2 0 0.2 0.4 0.6 0.8 1 1.2 time(s) corr(e 1 )
Figure 1.11 Auto-corrélation du signal ECG (e1(t)).
0 0.5 1 1.5 2 2.5 −4 −2 0 2 4 6x 10 −3 time(s) corr(e 2 )
Figure 1.12 Auto-corrélation du signal audio (e2(t)).
1.4 Contenu vibratoire
Dans les phénomènes vibratoires (optique, oscillateurs), il est important d’extraire les diffé-rents modes composant les signaux observés. Dans ce cas, un signal doit être écrit sous la forme d’une somme de plusieurs modes fondamentaux. Un mode est une vibration, non nécessairement sinusoïdale, de fréquence pure et devant être encore analysé pour caractériser le phénomène étu-dié. Une méthode récente appelée EMD (Empirical Mode Decomposition) permet d’estimer des modes intrinsèques IMFs (Intrinsic mode functions) par moyennage continu des extrémums jus-qu’à l’obtention d’un mode de très faible énergie [60]. La fig.1.13 représente la décomposition modale d’une séquence du signal audio e1(t). Un ensemble de 7 modes de fréquences et
d’éner-gies différentes évoluent dans le temps.
Dans [99], la décomposition EMD a été appliquée au spectre de Hilbert dans le but de sé-parer les signaux audio à partir d’un mélange. Une autre application est associée au phénomène
1.4 Contenu vibratoire 12 0 0.05 0.1 0.15 0.2 0.25 −0.2 0 0.2 e2 (t) temps(s) 0 0.05 0.1 0.15 0.2 0.25 −0.2 0 0.2 IMF 1 temps(s) 0 0.05 0.1 0.15 0.2 0.25 −0.2 0 0.2 IMF 2 temps(s) 0 0.05 0.1 0.15 0.2 0.25 −0.2 0 0.2 IMF 3 temps(s) 0 0.05 0.1 0.15 0.2 0.25 −0.2 0 0.2 IMF 4 temps(s) 0 0.05 0.1 0.15 0.2 0.25 −0.2 0 0.2 IMF 5 temps(s) 0 0.05 0.1 0.15 0.2 0.25 −0.2 0 0.2 IMF 6 temps(s) 0 0.05 0.1 0.15 0.2 0.25 −0.2 0 0.2 IMF 7 temps(s)
Figure 1.13 Décomposition EMD d’une séquence audio [375ms, 624.9ms] de e1(t).
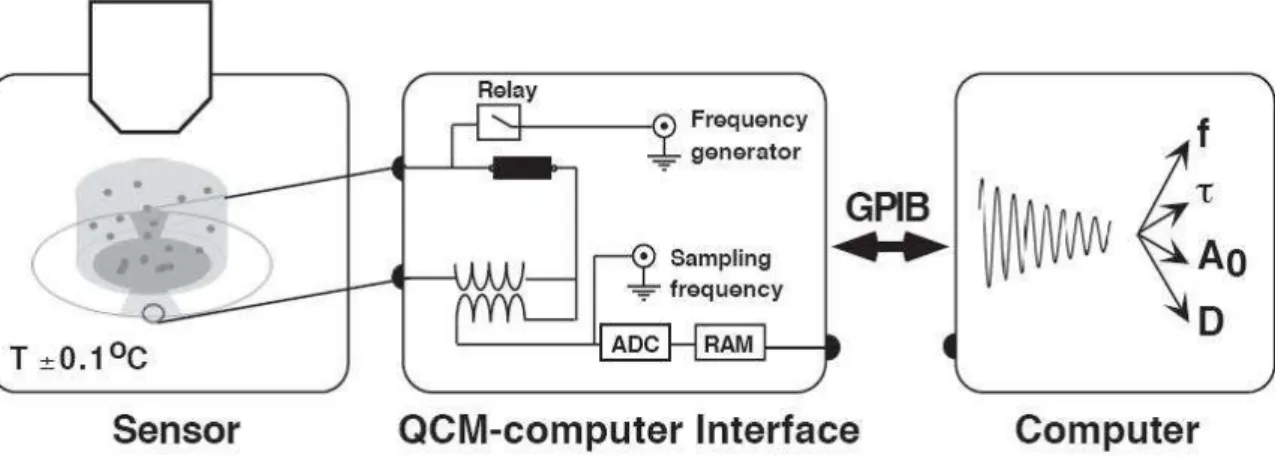
de piézo-électricité (directe et inverse), qui est l’origine des capteurs à quartz générant des oscil-lations de résonance, sous l’action de contraintes mécaniques sur les deux électrodes, comme le montre la fig.1.14. Ces capteurs sont très utilisés dans plusieurs domaines ; on cite, par exemple la microbalance à quartz (QCM) de la fig.1.15, qui permet de quantifier la dynamique de plusieurs grandeurs : Elle a été utilisée pour suivre la cinétique d’adsorption de protéines, et d’acquérir des informations sur les propriétés viscoélastiques de la couche adsorbée [92]. La sensibilité de cette technique est très élevée : de l’ordre de 9ng/cm2 dans les liquides, et de 0.135ng/cm2 dans le vide. Pour améliorer l’interprétation des données QCM, la mesure de l’amplitude du mode fon-damental et du facteur de dissipation sont nécessaires. Ces paramètres permettent de distinguer la contribution dûe à la masse adsorbée de celle dûe aux changements de propriétés du liquide.
1.5 Contenu objet 13
Figure 1.14 Disque à quartz (1cm de diamètre, qq µm d’épaisseur) et modes de résonance.
Figure 1.15 Microbalance à quartz et extraction du contenu des oscillations : Amplitude A0,
fréquence d’oscillation f , constante de temps τ et facteur de dissipation D [98].
1.5 Contenu objet
Dans le cas de documents multimédias, le contenu est composé d’objets : texte, audio, image ou vidéo. Dans le cas d’imagerie, plusieurs travaux ont été menés pour développer des systèmes d’extraction basés sur le contenu. Un tel système opère sur des images d’une base de données en construisant un ensemble d’interrogations sur leurs caractéristiques, afin de les exploiter pour le contrôle d’affichage des images spécifiques présentant une métrique de dissimilarité minimale avec les images de la base de données. Le procédé est utile pour une recherche d’images, telle qu’une extraction d’images à partir de pages Web et une reconnaissance faciale. D’autres domaines très motivants sont ceux de l’imagerie astrophysique [26], satellitaire et médicale [52] [53] [130].
La fig.1.16 illustre la nécessité de segmentation pour l’extraction de la fenêtre d’analyse pour une image médicale [52]. Le contenu, ainsi analysé et interprété, fournit les informations néces-saires sur l’organe et les symptômes associés. De même, la fig.1.17 représente une image SPOT du barrage EL Wahda-Maroc [2] . Ce type d’images satellitaires contribuent à une meilleure
connais-1.6 Mélange de contenus et problème de séparation 14
sance, globale et locale, de la distribution des ressources en eau sur la surface terrestre ainsi qu’à une meilleure compréhension et analyse des phénomènes hydro-géologiques. Cependant, l’extrac-tion des objets d’étude est toujours nécessaire pour isoler leurs caractéristiques propres.
Figure 1.16 Segmentation de la région d’intérêt : image initiale (à gauche) et extraction de la fenêtre d’analyse (à droite) [52].
Figure 1.17 Image SPOT du Barrage EL Wahda, Maroc [2].
1.6 Mélange de contenus et problème de séparation
Dans la réalité physique, les phénomènes à étudier sont souvent le résultat de contribution de plusieurs composantes d’origines et de natures différentes. La différence de contribution provient de la nature du contenu de chaque composante : statistique, spectral, vibratoire, objet ou découle de tous ces contenus. Un ensemble de capteurs est ainsi utilisé pour enregistrer les données avec une certaine diversité. Par conséquent, chaque capteur dispose d’un mélange de contribution des différentes sources. Pour restaurer leurs contenus, on travaille dans le contexte du problème de séparation de sources [22] [29] [40]. La fig.1.18 décrit les différents blocs du système d’extrac-tion/séparation. Selon la nature des signaux et le type du contenu à extraire, les observations, collectées par des capteurs, subissent un processus de séparation afin de fournir des estimations.
1.7 Conclusion 15
L’évaluation du contenu pour l’exploitation finale peut être ainsi effectuée.
Figure 1.18 Schéma des différents blocs du système d’extraction du contenu.
Dans cette thèse, le problème d’extraction du contenu d’un mélange sera résolu par les tech-niques de séparation de sources, selon trois approches :
– Approche statistique : Les techniques développées exploitent l’indépendance statistique des sources pour construire des fonctions de contrastes, dont l’optimisation, fournit une estimation de la matrice de séparation, et par la suite extraire les signaux sources [61] [62] [64] [65] [63] [70] [71].
– Approche spectrale : La caractérisation des signaux dans le domaine temps-échelle présente les points de diversité entre les structures des sources. La diagonalisation conjointe des matrices associées permet de donner une estimation de ces sources [67] [68] [72].
– Approche hybride : Dans cette approche, on va combiner les caractéristiques spectrales et statistiques, afin de développer des techniques de séparation hybrides et de proposer des blocs de pré-traitement ou de post-traitement du système de séparation [66] [69] [73].
1.7 Conclusion
Ce chapitre a été consacré à la présentation des différents types de contenus intégrés dans un signal : spectral, statistique, vibratoire et objet. Pour la caractérisation et l’extraction de ces conte-nus, un ensemble de méthodes d’analyse, adaptés à chaque application, a été décrit et illustré par des exemples. Les informations fournies et les représentations déduites, à partir de ces méthodes, peuvent être exploitées pour la séparation de sources et l’évaluation de leurs contenus.
CHAPITRE
2
Théorie et domaines de la
séparation de sources
2.1 Formulation du problème
L’étude de phénomènes physiques et l’identification des entrées/sorties d’un environnement nécessitent la caractérisation numérique de l’ensemble des grandeurs associées. En général, l’accès direct à ces grandeurs n’est pas possible et on doit utiliser des capteurs. Cependant, les mesures fournies représentent généralement, la contribution de plusieurs grandeurs et le signal de mesure disponible est un mélange. La fig.2.1 illustre le problème général de mélange des signaux émis dans un milieu de propagation et le réseau de capteurs pour l’extraction des informations utiles. Chaque mesure xi(t) sera entachée d’un bruit global ni(t) produit par les perturbations internes du
milieu nint
i (t) et les perturbations externes nexti (t).
Figure 2.1 Mélange de sources dans un milieu de propagation.
On note :
s(t) = [s1(t), · · · , sN(t)]T : le vecteur des N sources (signaux émis inobservables).
x(t) = [x1(t), · · · , xM(t)]T : le vecteur des M observations (mesures des capteurs).
2.1 Formulation du problème 17
En général, chaque observation xi(t) peut s’écrire, en utilisant la fonction de sensibilité
multi-variable
A
ientre le i-ème capteur et les différentes sources, sous la forme suivante :xi(t) =
A
i[s1(t), · · · , sN(t)] + ni(t); i = 1, · · · , M (2.1)Dans ce chapitre, on va présenter les outils théoriques utilisés dans la construction des critères de séparation adaptés à la nature du couple mélange-sources et les domaines d’application du problème de séparation de sources.
2.1.1 Modèles et séparation
La nature des fonctions de sensibilité, entre les capteurs et les sources, dépend du comporte-ment du milieu dans le temps (dérives thermiques, retards, atténuations,...) et des sources (redirec-tions, satura(redirec-tions,...). On distingue les types de mélange suivants :
– Mélange linéaire : Dans le cas d’un système linéaire, la superposition des mesures est pos-sible, par des fonctions de sensibilité élémentaires
A
ik, entre le iemecapteur et la kemesource.On a : xi(t) = N
∑
k=1A
ik[sk(t)] + ni(t); i = 1, · · · , M (2.2)En plus, si la contribution de chaque source, dans chaque mesure, est instantanée. Les fonc-tions de sensibilité
A
ik se réduisent à des constantes aik et le mélange est dit linéaireins-tantané. On aura : xi(t) = N
∑
k=1 aiksk(t) + ni(t); i = 1, · · · , M (2.3) Si on note :ai= [ai1, · · · , aiN]T le vecteur des coefficients de mélange relatif au i-ème capteur.
A = [a1, · · · , aM]T : la matrice de mélange.
On peut écrire la relation entre le vecteur des sources (entrées) et le vecteur des observations (sorties) comme suit :
x(t) = As(t) + n(t) (2.4)
Dans le cas d’effet mémoire sur les sources, les fonctions de sensibilité
A
ikcorrespondent àdes filtres aik(t) et le mélange devient convolutif. On a alors :
xi(t) = N
∑
k=1aik(t) ∗ sk(t) + ni(t); i = 1, · · · , M (2.5)
où ∗ désigne le produit de convolution, et aik(t) est un filtre linéaire qui caractérise la
sen-sibilité du i-ème capteur vis à vis de la k-ème source. La transformation en z de l’équation Eq.2.5 permet d’écrire :
2.1 Formulation du problème 18
La matrice A(z) représente alors tous les coefficients du mélange.
– Mélange non-linéaire : La linéarité consiste à faire travailler le milieu autour d’un point de fonctionnement où les caractéristiques des éléments d’influence sont linéaires. En réalité, les variations énergétiques importantes des sources produisent des saturations ou d’autres termes de non-linéarité (quadratique, exponentielle,...) et la relation entre le vecteur des sources et le vecteur des observations devient une fonction vectorielle non linéaire et à mémoire. Des travaux sur les mélanges non linéaires ont été effectués par Krob [86], Pajunen et al. [106], Taleb et Jutten [119].
Quelque soit le type de mélange, réalisé par le milieu, le problème de la SAS consiste à recons-truire les sources à partir des mesures effectuées par les capteurs. La séparation est dite aveugle si aucune connaissance sur les sources et le milieu de mélange n’est disponible. Ainsi, le critère de séparation ne peux exploiter que les observations. La fig.2.2 illustre le modèle général de la solu-tion du problème de séparasolu-tion par estimasolu-tion d’une matrice B, dite matrice de séparasolu-tion. Dans le cas où les coefficients du mélange, liés aux conditions du milieu, sont variables dans le temps, on peut procéder par une séparation adaptative dans des intervalles de longueurs T , correspondant à une constance des paramètres caractéristiques du mélange, comme le montre la fig.2.3.
Figure 2.2 Modèle général du problème mélange-séparation.
Figure 2.3 Séparation adaptative
2.1.2 Indéterminations
La séparation de sources s’effectue avec deux indéterminations [22] :
2.2 Hypothèses et discussions 19
sont inconnues, toute multiplication de la composante sk(t) par un gain λk (ou un filtre f(z)
dans le cas convolutif) peut être annulée par la division de la i-ème colonne de la matrice A (la matrice A(z)) par le même facteur (filtre). D’où l’expression suivante :
xi(t) =
∑
N i=1 aiksk(t) = N∑
i=1 (1 λkaik)λksk(t) (2.7)avec λk est un nombre constant. La conséquence directe de cette indétermination est qu’on
ne peut pas estimer les sources avec leurs variances exactes.
- Indétermination d’ordre : Les estimations y(t) seront fournies avec un ordre indépendant
de l’ordre des signaux sources s(t). Dans le cas d’un mélange linéaire instantané, la formula-tion de cette indéterminaformula-tion correspond à un produit par une matrice de permutaformula-tion P :
y(t) = GP−1Ps(t) (2.8)
le terme Ps(t) indique le changement d’ordre des sources, tandis que le terme GP−1désigne
une autre solution possible du problème de séparation.
2.2 Hypothèses et discussions
Nous allons présenter et discuter les hypothèses souvent considérées dans le contexte général de la séparation de sources [19] [20] [29] [54] [67] [84] :
- Hypothèses sur le mélange :
Hypothèse 2. 1 La matrice de mélange est de rang plein.
Cette hypothèse, traduite par une matrice inversible dans le cas M = N, est nécessaire pour four-nir des estimations différentes : aucune composante yi(t) ne doit être exprimée linéairement en
fonction d’une autre composante yj(t) pour j 6= i.
- Hypothèses sur les sources :
Hypothèse 2. 2 Les sources sont des processus aléatoires, centrés et de variances unités.
En pratique les sources ont des énergies et des moyennes différentes. La considération de cette hypothèse est bien justifiée par les indéterminations associées à la solution du problème de sépara-tion : indéterminasépara-tion du gain et de l’ordre. Son utilisasépara-tion simplifie énormément les algorithmes de séparation.
2.2 Hypothèses et discussions 20
Si les sources sont décorrélées, leurs matrices de covariances sont diagonales ; ainsi, les statistiques d’ordre deux sont insuffisantes pour décrire toutes les caractéristiques statistiques des signaux. Les statistiques d’ordre supérieur sont souvent utilisées pour apporter plus d’informations.
Hypothèse 2. 4 Les sources sont statistiquement indépendantes.
Cette hypothèse exprime l’indépendance des événements associés aux différents processus des sources. Le critère de séparation peut donc exploiter toute fonction de mesure d’indépendance dont la maximisation fournit une estimation des sources.
Hypothèse 2. 5 Une source, au plus, possède un auto-cumulant nul à l’ordre q.
Cette hypothèse se traduit par l’existence au plus d’une source gaussienne. C’est une contrainte des critères de séparation utilisant les cumulants comme moyen de mesure de l’indépendance statistique des sources.
Hypothèse 2. 6 Les sources sont stationnaires à un ordre q.
Cette hypothèse considère que les propriétés statistiques (moments, cumulants,...) des sources, à un ordre q, sont indépendantes de l’instant d’évaluation. Donc, l’acquisition d’un petit ensemble d’échantillons est suffisante, en pratique, pour l’analyse statistique. Dans le cas de la non station-narité des sources, on se confronte à deux problèmes : la nécessité de circuit mémoire de taille importante pour l’acquisition complète des échantillons des signaux et un retard d’évaluation des statistiques. Pour éviter ces deux problèmes, il est indispensable d’utiliser des techniques caracté-risant le contenu des signaux d’une façon locale.
Hypothèse 2. 7 Les sources possèdent des signatures temps-fréquence différentes.
Cette hypothèse, considérée dans des techniques récentes, trouve son importance dans plusieurs applications présentant une diversité de la distribution énergétique instantanée de leurs compo-santes fréquentielles. L’ensemble des instants, et les différentes fréquences présentes à chaque ins-tant, définit la signature temps-fréquence d’un signal. Deux signaux différents ne peuvent présenter le même ensemble d’analyse temps-fréquence. Les points de diversité des différentes signatures, sont exploités pour la construction de distributions spatiales mettant en jeu un critère de séparation. Hypothèse 2. 8 Les sources possèdent des signatures temps-échelle différentes.
Cette hypothèse représente un apport original de notre thèse. Elle évite les problèmes pratiques (calcul, nombre de points de diversité) de l’hypothèse H.7 et considère la diversité de la distribu-tion des énergies des sources dans l’espace temps-échelle. Par exemple, les signaux audio (parole,
2.3 Outils statistiques 21
musique) représentent une classe importante, répondant à cette hypothèse, puisqu’il y a une diver-sité temporelle, des énergies des différentes excitations sonores.
- Hypothèses sur les bruits :
Hypothèse 2. 9 Les bruits ni(t), i = 1, · · · , M, sont des processus aléatoires blancs, mutuellement
indépendants et indépendants des sources.
Cette hypothèse est souvent prise en compte dans les techniques exploitant les statistiques. Elle ne peut être vérifiée que dans le cas de diversité suffisante dans l’emplacement spatial des sources deux à deux, ainsi que des capteurs deux à deux.
2.3 Outils statistiques
La plupart des techniques de séparation exploitent les propriétés statistiques pour la mesure de l’indépendance des sources et la construction de relations entre les moments ou les cumulants [22] [29].
2.3.1 Corrélations et moments
La fonction de corrélation entre deux signaux xi(t) et xj(t) est donnée par :
rxixj(τ) = E[xi(t)x?j(t − τ)] (2.9)
où E[.] désigne l’espérance mathématique ; et?le complexe conjugué.
Pour le vecteur x(t), on définit la matrice de corrélation par :
Rxx(τ) = E[x(t)xH(t − τ)] (2.10)
dont la diagonale contient les auto-corrélations rxixi(τ) = E[xi(t)x?i(t − τ)], tandis que les
inter-corrélations sont localisées hors diagonale rxixj(τ) = E[xi(t)x?
j(t − τ)], i 6= j. Le vecteur xH(t)
dé-signe le vecteur transposé des conjugués des éléments du vecteur x(t).
Dans le cas des signaux non-stationnaires, toutes les propriétés statistiques dépendent de l’instant d’origine d’évaluation des échantillons des signaux d’étude.
Les moments d’une variable aléatoire multidimensionnelle u(t) = [u1(t), · · · , uN(t)] , de di-mension N, sont déduits à partir de la première fonction caractéristique, utilisant la variable v(t) = [v1(t), · · · , vN(t)] définie par [79] [104] [110] :
Φu(v) = E[exp( jvTu)] =
Z
2.3 Outils statistiques 22
où
F
(u) est la fonction de répartition de la variable u(t). Le moment d’ordre q de la variable u(t) s’exprime par : mq(u1, s2, · · · , uq) = E[u1u2. . . uq] = (− j)q ∂ qΦ u(v) ∂v1∂v2. . . ∂vq |v=0 (2.12) 2.3.2 Les cumulantsLa seconde fonction caractéristique définie par l’équation suivante [110] [104] :
Ψu(v) = ln(Φu(v)) (2.13)
permet d’exprimer, d’une façon simple, les cumulants comme mesures des statistiques d’ordre supérieur. Le cumulant d’ordre q est donné par :
Cumq(u) = Cum[u1, u2, · · · , uq]
= (− j)q ∂qΨu(v) ∂v1∂v2. . . ∂vq
|v=0 (2.14)
Dans le cas de p composantes indépendantes des autres, la première fonction caractéristique se décompose comme suit :
Φu(v) = E £ exp( jvTu)¤ = E " exp( j p
∑
i=1 viui) # E " exp( j q∑
i=p+1 viui) # (2.15)et la seconde fonction caractéristique aura pour expression : Ψu(v) = ln(E[exp( jvTu)]) = ln(E[exp( j p
∑
i=1 viui)]) + ln(E[exp( j q∑
i=p+1 viui)]) (2.16)Donc, le cumulant d’ordre q s’écrit :
Cumq(u) = (− j)q ∂qln(E[exp( j
∑
p i=1 viui)]) ∂v1∂v2. . . ∂vq |v=0+(− j) q ∂qln(E[exp( j∑
q i=p+1 viui)]) ∂v1∂v2. . . ∂vq |v=0 = 0 (2.17) puisque les deux termes ne dépendent pas de toutes les variables vi, i = 1, · · · , q. On conclut ainsique l’indépendance statistique est équivalente à l’annulation des cumulants de tous les ordres. Des critères de séparation ont été proposés pour un ordre général, mais en pratique et pour des raisons de coût de calcul, la majorité des techniques proposées dans la littérature se limitent à l’ordre 4.