Damaris: Leveraging Multicore Parallelism to Mask I/O Jitter
Texte intégral
Figure
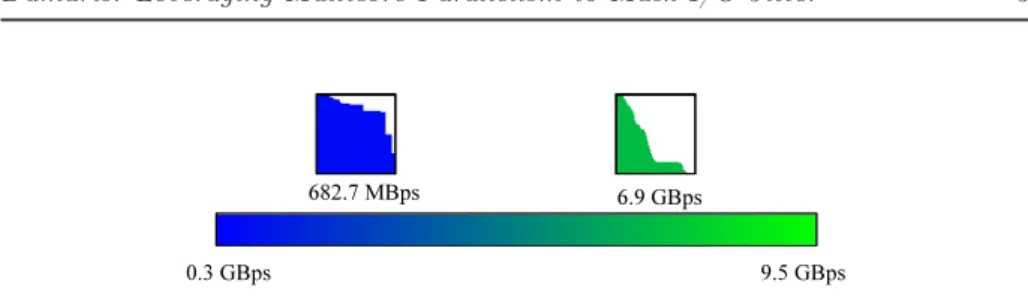
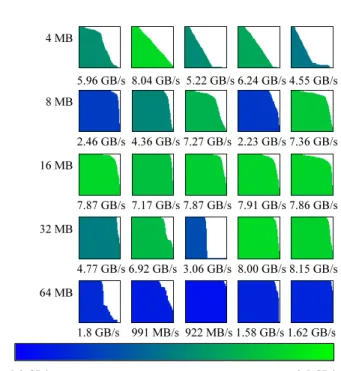
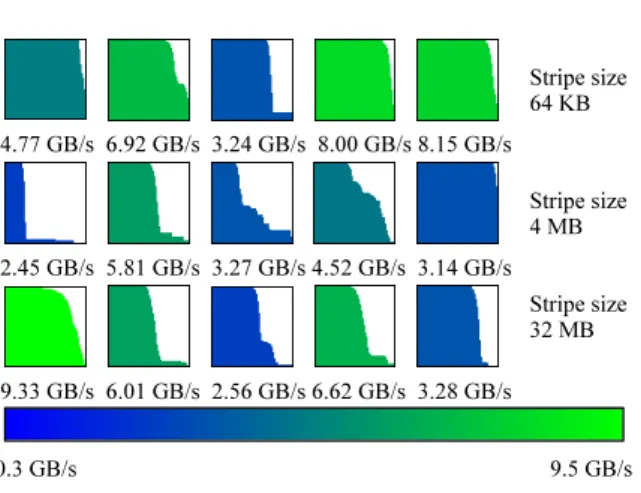
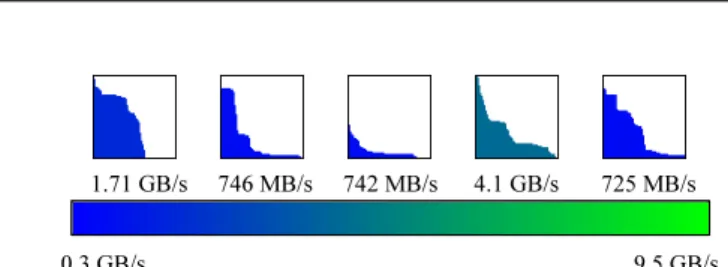


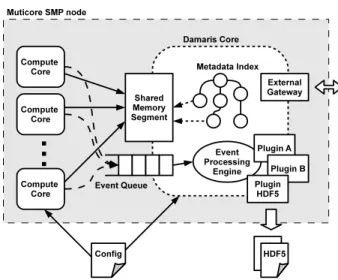
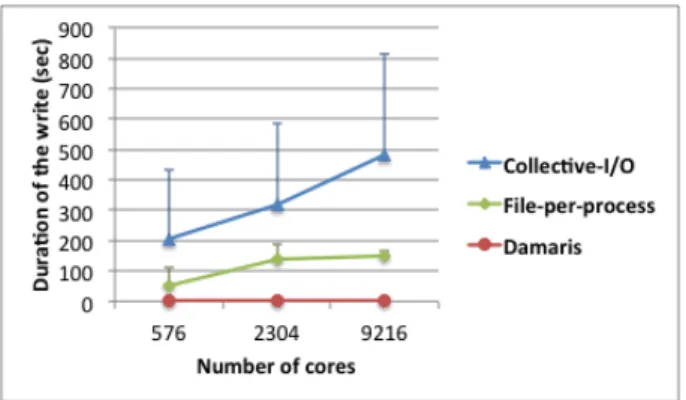
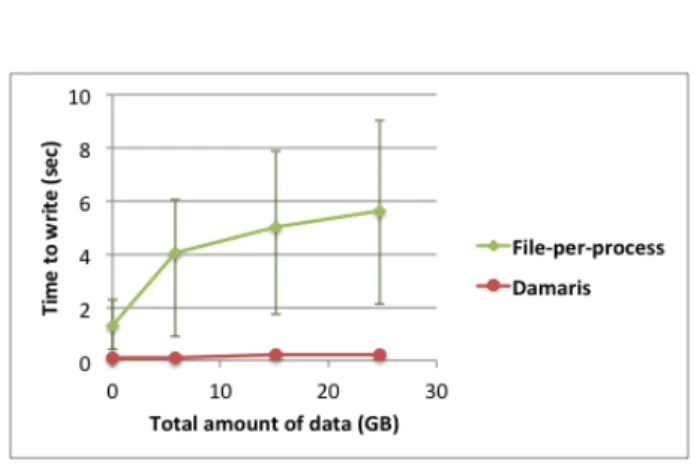
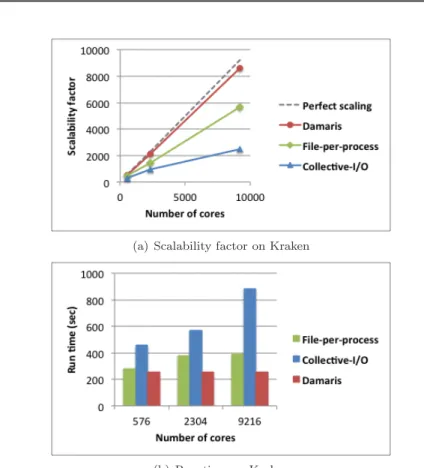
Documents relatifs
Présenter à l’examinateur le protocole mis au point pour la préparation de la solution de chlorure de baryum et pour le titrage des ions sulfate de la solution S 0.. Mettre en œuvre
[r]
• Maintenant créez un nouveau calque que vous remplissez de la couleur que vous voulez pour le fond (ici du jaune très clair R255 V248 B152) puis ajoutez lui un masque par clique
To enhance the classic GOP level parallelism approach, we focused on hiding communication overhead. Our optimization is based on two strategies as shown on Figure 1: the
Our implementation can mine all 34 Declare constraints for the BPI challenge log in 287 seconds (so the reduction allows us to check all constraints in the same amount of time we
respectively nanospheres and background in our
Le bilan le plus lourd à été enregistré dans la wilaya d’Aïn- Témouchent où 3 personnes ont trouvé la mort et 10 autres ont été blessées dans 3 accidents de la route..
Sources synchrones C’est la différence des distances d’un point du champ d’interférence aux deux sources secondaires. Différence de marche C’est la distance qui
