Interactive Data-Driven Research: the place where databases and data mining research meet
Texte intégral
Figure
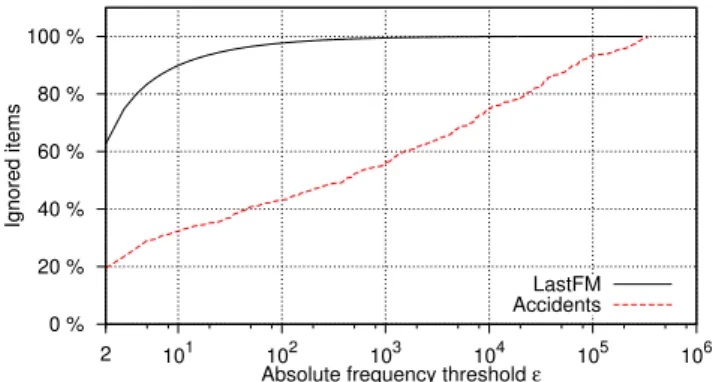
Documents relatifs
Several scientific challenges are still open, including a) the development of robust and e↵ective methods and techniques for prediction of energy production and consumption down to
Moreover, the actual increase of the interests in manufacturing process man- agement and analysis in manufacturing leads some authors to present in [21] a manufacturing data
The boundaries between information retrieval, informa- tion extraction, and data mining are blurring; bringing them together, in an activity commonly referred to as text mining,
z ELMAGARMID, Ahmed K., IPEIROTIS, Panagiotis G., VERYKIOS, Vassilios S., Duplicate Record Detection A Survey, IEEE Transations on knowledge and Data Engineering (TKDE) Vol.
The New Zealand Immigration and Protection Tribunal made a point of saying that the effects of climate change were not the reason for granting residency to the family, but
where we made explicit the dependence on µ and on the
Data generation allows us to both break the bottleneck of too few data sets (or data sets with a too narrow range of characteristics), and to understand how found patterns relate to
”Where the data are coming from?” Ethics, crowdsourcing and traceability for Big Data in Human Language Technology1. Crowdsourcing and human computation multidisciplinary
