Analyse de la similarité du code source pour la
réutilisation automatique de tests unitaires à l’aide du
CBR
Mémoire Xu Zhang Maîtrise en informatique Maître ès sciences (M.Sc.) Québec, Canada © Xu Zhang, 2013Résumé
Réutiliser les tests unitaires automatiquement est une solution pour faciliter le travail de cer-tains développeurs. Dans notre recherche, nous proposons une ébauche de solution en utilisant le raisonnement à base de cas (Case Based reasoning - CBR) issu du domaine de l’intelligence artificielle. Cette technique tente de trouver le cas le plus similaire dans une base de cas pour ensuite, après modifications, le réutiliser pour résoudre un nouveau problème.
Nos travaux de recherche se concentrent sur l’analyse de la similarité du code dans l’optique de réutiliser des tests unitaires. Nous porterons donc une attention particulière à l’élaboration d’une technique de comparaison des classes adaptées au contexte des tests.
Plus précisément, dans ce mémoire, nous aborderons les questions suivantes :
1. Trouver la classe la plus similaire dans le but de réutiliser ses tests unitaires (travaux principaux) ;
2. Trouver les méthodes similaires entre les deux classes similaires ;
3. Chercher les tests réutilisables en fonction de la similarité des méthodes de ces deux classes.
Pour ce faire, nous mènerons des expérimentations afin de trouver les meilleures attributs (caractéristiques) permettant de comparer deux classes. Ces attributs doivent être choisis en considérant le contexte particulier des tests qui ne sont pas les mêmes que pour, par exemple, détecter du code dupliqué.
Cette recherche nous permet de proposer un premier algorithme d’analyse de la similarité des classes qui fonctionne assez bien dans le contexte de notre expérimentation. Nous avons également étendu le processus à la sélection et la réutilisation de tests à l’aide d’une tech-nique simple permettant de vérifier que l’algorithme d’analyse de similarité des classes peut potentiellement fonctionner et s’intégrer à un processus complet.
Nos travaux montrent qu’il est possible de réutiliser des tests unitaires, bien que l’algorithme reste à être améliorer. Nous proposons d’ailleurs plusieurs pistes à ce sujet.
Abstract
Automatically reusing unit tests is a possible solution to help developers with their daily work. Our research proposes preliminary solutions using case base reasoning (CBR), an approach coming from artificial intelligence. This technique try to find the most similar case in a case base to reuse it after some modifications against some new problems to solve.
Our works focus on the similarity analysis of a program code with the goal of reusing unit tests. Our main focus will be on the elaboration of a technique to compare classes in the test context.
To be more precise, in the thesis, we will discuss :
1. How to find the most similar class for which it will be possible to reuse its tests (main focus) ;
2. How to find similar methods between the new class and the most similar one ; 3. Find which test could be reused considering the similarity of the methods.
To achieve this, we will run some experiments to find the bests attributes (characteristics) to compare two classes. Those attributes must be chosen considering the specific context of testing. For example, those characteristics are not the same as for finding duplicated code.
This research propose an algorithm to analyze the similarity of classes. Our experiment shows that this algorithm works quite well in the context of the experiment. We also extended the experiment to see if it could possibly work within the whole process of selection and reuse of unit tests. We did this by using some simple techniques that could certainly be refined.
In fact, our works demonstrate that it is possible to reuse unit tests despite the fact that our algorithm could be perfected and we suggest some improvements about it.
Table des matières
Résumé iii
Abstract v
Table des matières vi
Liste des tableaux viii
Liste des figures ix
1 Introduction 1
1.1 Motivation . . . 1
1.2 Objectifs . . . 2
1.2.1 Objectifs à long terme . . . 2
1.2.2 Objectifs de notre recherche . . . 2
1.3 Problématique . . . 4 1.4 Méthodologie . . . 5 1.5 Plan du document . . . 5 2 Revue de littérature 7 2.1 Qualité logicielle . . . 8 2.1.1 ISO-9126 . . . 8
2.1.2 Qualité utilisateur ou développeur . . . 8
2.2 Test unitaire en génie logiciel . . . 9
2.3 Les systèmes de génération de tests . . . 10
2.3.1 JUnit Factory . . . 10 2.3.2 JCrasher . . . 12 2.3.3 Jartege . . . 12 2.3.4 Randoop . . . 13 2.3.5 CodePro. . . 14 2.3.6 Catégories de générateurs . . . 14 2.4 Système de recommandation . . . 16
2.4.1 Système de recommandation pour le génie logiciel. . . 18
2.4.2 Principes généraux du raisonnement à base de cas . . . 18
2.4.3 Réutilisation du code à l’aide du CBR . . . 19
2.5 Discussion sur la génération automatique de tests unitaires à l’aide du CBR . 20 2.6 Analyse de la similarité . . . 20
2.6.2 Techniques d’analyse de la similarité . . . 23
Technique basée sur le texte. . . 23
Technique basée sur l’arbre. . . 25
Technique basée sur le PDG. . . 26
Technique basée sur les métriques. . . 27
Approche hybride . . . 28
2.6.3 Comparaison . . . 28
3 Similarité entre les classes 31 3.1 Processus de recherche de la classe la plus similaire . . . 31
3.2 Extraction des attributs . . . 35
3.3 Sélection d’attributs . . . 35
3.4 Calcul de la similarité entre les classes . . . 36
3.4.1 Attribut : import . . . 36
3.4.2 Attribut : nom de la classe . . . 39
3.4.3 Attribut : nom de la méthode . . . 42
3.4.4 Attribut : appel de méthode . . . 44
3.4.5 Autres attributs . . . 45
3.4.6 Similarité globale et sélection du cas le plus similaire . . . 46
4 Trouver les tests à réutiliser 47 4.1 Étape 1 : Association de la classe avec ses tests . . . 49
4.2 Étape 2 : Sélectionner les méthodes similaires . . . 50
4.3 Étape 3 : Sélectionner les tests réutilisables . . . 54
4.4 Discussion . . . 54
5 Expérimentations 57 5.1 Résultats expérimentaux . . . 57
5.1.1 Première expérimentation . . . 57
5.1.2 Deuxième expérimentation . . . 60
Similarité entre les classes . . . 60
Méthodes similaires avec la classe la plus similaire . . . 63
Sélection des tests unitaires réutilisables . . . 65
Réutilisation des tests . . . 70
5.2 Discussion . . . 71
6 Conclusion 75 6.1 Démarche et contributions . . . 76
6.2 Travail à long terme . . . 77
Liste des tableaux
2.1 Techniques d’analyse de la similarité du code. . . 29
3.1 Attribut d’une classe et éléments Java associés. . . 36
3.2 Exemple du calcul de la similarité des importations . . . 38
3.3 Résultat de comparaison des noms des classes. . . 41
5.1 Résultats pour la première expérimentation . . . 58
5.2 Exemples de réussites pour la première expérimentation. . . 59
5.3 Exemples d’échecs pour la première expérimentation. . . 59
5.4 Résultats pour les classes d’algorithmes similaires. . . 60
5.6 Résultats de l’analyse de la similarité des méthodes (deuxième expérimentation, étape 2). . . 65
Liste des figures
2.1 Test unitaire avec JUnit et un rapport dans Eclipse. . . 11
2.2 Annotation JML pour préconditions et postconditions [Ori05]. . . 13
2.3 Le processus de Randoop [Pac]. . . 13
2.4 Les tests unitaires générés par CodePro. . . 15
2.5 Le problème d’oracle. . . 17
2.6 Processus du CBR [Wik12b]. . . 19
2.7 Système pour générer le test unitaire automatique. . . 21
2.8 Structure d’un fichier Java. . . 22
2.9 Comparer les nœuds et trouver les sous-arbres similaires[20112]. . . 26
2.10 Exemple avec le PDG [aja]. . . 26
2.11 Exemple de code source d’un graphique d’appels déduit après deux itérations avec la technique de Chilowicz et al [CDR09]. . . 28
3.1 Le processus pour trouver la classe la plus similaire. . . 32
3.2 Les étape de processus pour trouver la classe la plus similaire. . . 33
3.3 Les attributs d’un fichier Java. . . 34
3.4 Comparaison entre les noms de classes. . . 40
3.5 Mocks pour isoler la classe. (Référence : Cours - Qualité et métriques du logiciel). 45 4.1 Le processus de trouver les tests à réutiliser. . . 48
4.2 Associer les tests aux méthodes dans la base de cas. . . 50
4.3 Sous-classes de la classe CaseBase. . . 51
4.4 Sélectionner les méthodes similaires. . . 52
4.5 Sélection des tests réutilisables. . . 55
5.1 Les composantes du projet pour le essai. (Référence : Cours - Qualité et métriques du logiciel). . . 60
Remerciements
Je voudrais tout d’abord remercier mon directeur de recherche Luc Lamontagne pour le soutien et la grande patience dont il a fait preuve tout au long des travaux que nous avons menés. Je tiens à remercier Félix-Antoine pour ses conseils, ainsi que mes collègues pour leur aide et la motivation que chacun m’a apporté.
Enfin je remercie ma famille en Chine, ainsi que ma nouvelle famille de Québec. Sans leur soutien et encouragements, je n’aurais pas persisté dans cette aventure.
Chapitre 1
Introduction
1.1
Motivation
Dans l’industrie informatique moderne, les tests ont un rôle très important pour assurer la qualité du logiciel car ils permettent de vérifier que le logiciel a le comportement désiré. L’utilisation de tests est une méthode connue afin de faciliter la maintenabilité d’un logiciel, de réduire la quantité de bogues et de produire le bon logiciel pour le client.
Les tests unitaires sont de plus en plus utilisés dans les entreprises et sont courants [Tor06]. Cependant plusieurs développeurs trouvent fastidieux l’écriture de tests automatisés et ils négligent cet aspect important du travail d’un informaticien.
Un générateur de tests pourrait les aider en permettant de développer plus rapidement les tests. De plus, ils pourraient aider les développeurs novices à choisir les vérifications à effectuer. C’est pour cette raison que nous commençons à étudier les systèmes de génération de tests. Il existe déjà plusieurs systèmes pour générer automatiquement des tests (sans ou avec peu d’interventions d’un programmeur). Mais la majorité des générateurs de tests automatisés ont un problème pour déterminer si un résultat est bon ou non (problème de l’oracle). C’est pour cela que nous avons eu l’idée d’utiliser le raisonnement à base de cas (CBR) pour générer des tests.
Le CBR (raisonnement à base de cas) [Wik12b] est une approche d’intelligence artificielle qui résout de nouveaux problèmes à partir d’exemples connus dont les solutions peuvent être réutilisées. Ces exemples sont contenus dans une base de cas.
Le CBR est déjà utilisé pour plusieurs usages dont la réutilisation du code source [Hum10]. En effet, les recherches dans ce domaine visent principalement à réutiliser le code source en identifiant la similarité dans les conceptions ou les spécifications. Personne n’a encore tenté d’utiliser le CBR dans le but de générer des tests unitaires.
Ce travail a pour objectif à long terme d’utiliser un système intelligent pour générer des tests unitaires. Il existe souvent du code source présentant des ressemblances. Il est alors possible
Listing 1.1: Une classe simple à tester. public c l a s s B u b b l e S o r t { public i n t [ ] s o r t ( i n t a r r [ ] ) { i n t tmp = 0 ; f o r ( i n t i = 0 ; i < a r r . l e n g t h − 1 ; i ++) { f o r ( i n t j = a r r . l e n g t h − 1 ; j > i ; j −−) { i f ( a r r [ j ] < a r r [ j − 1 ] ) { tmp = a r r [ j ] ; a r r [ j ] = a r r [ j − 1 ] ; a r r [ j − 1 ] = tmp ; } } } return a r r ; } }
de partir du test de ce code déjà testé et de l’adapter pour le nouveau code similaire.
1.2
Objectifs
1.2.1 Objectifs à long terme
Notre objectif à long terme est de générer automatiquement des tests unitaires en utilisant l’approche du CBR.
Par exemple, imaginons deux développeurs ayant codé deux algorithmes de tri. Ces deux algorithmes sont représentés aux figures 1.1 et 1.2. Cet exemple illustre bien comment il est possible d’avoir deux structures de code et un style de programmation assez différents, mais qui produisent le même comportement attendu.
Cette différence peut aussi être plus subtile et n’être qu’une différence de style entre deux programmeurs. Il pourrait s’agir du même algorithme, mais codé différemment (nommage, appels, etc.).
L’idéal serait donc de pouvoir fournir un code et de laisser le système trouver le code le plus similaire, puis produire un test adapté en faisant les modifications appropriées. Un objectif plus réaliste, mais à moyen terme, serait de demander l’aide d’experts afin de faire les modifications et les réinjecter dans la base de cas. Le système aiderait donc les experts dès le début de leur travail, en identifiant les similitudes et les modifications nécessaires.
1.2.2 Objectifs de notre recherche
L’objectif à long terme est d’utiliser le CBR qui comprend quatre parties : recherche, réutilisa-tion, révision et rétention. La partie « recherche » demande de trouver le cas le plus similaire
Listing 1.2: Le cas plus similaire dans la base de connaissances. //Code Source public c l a s s Q u i c k S o r t { private i n t [ ] numbers ; private i n t number ; public i n t [ ] s o r t ( i n t [ ] v a l u e s ) { i f ( v a l u e s == n u l l | | v a l u e s . l e n g t h == 0 ) { return n u l l ; } t h i s . numbers = v a l u e s ; number = v a l u e s . l e n g t h ; q u i c k s o r t ( 0 , number − 1 ) ; return v a l u e s ; }
private void q u i c k s o r t ( i n t low , i n t h i g h ) {
i n t i = low , j = h i g h ;
i n t p i v o t = numbers [ low + ( h i g h − low ) / 2 ] ;
while ( i <= j ) { // . . .
// Test pour c l a s s e QuickSort public c l a s s S o r t T e s t { @Test public void t e s t S o r t ( ) { Q u i c k s o r t q u i c k s o r t = new Q u i c k s o r t ( ) ; i n t [ ] i n i t i a l N o t S o r t e d = { 5 0 , 6 3 , 25 } ; i n t [ ] e x p e c t e d S o r t e d = { 2 5 , 5 0 , 63 } ; i n t [ ] r e s u l t S o r t e d = q u i c k s o r t . s o r t ( i n i t i a l N o t S o r t e d ) ; a s s e r t A r r a y E q u a l s ( e x p e c t e d S o r t e d , r e s u l t S o r t e d ) ; } }
dans la base de cas. Par conséquent, la première étape vers l’objectif à long terme est de réussir à comparer les cas.
Notre recherche a pour objectif de contribuer à trouver une méthode pour analyser la simi-larité des codes sources.
Nous gardons à l’esprit que nous faisons cela afin de pouvoir réutiliser des tests unitaires. Nous verrons plus tard que le fait d’être dans ce contexte change les techniques applicables par rapport à d’autres utilisations possibles telle la détection de codes similaires. Par exemple, les techniques pour détecter des clones (code identique suggérant un plagiat) ne fonctionnent pas forcément bien pour trouver du code source afin de réutiliser le test correspondant. Le domaine étant très jeune, très peu de recherches ont été réalisées sur l’application de tech-niques d’intelligence artificielle pour la réutilisation de tests.(voir chapitre2). Par conséquent, notre objectif est de défricher différents aspects et de monter un prototype fonctionnel dé-montrant la faisabilité de cette approche. Par conséquent, nous allons explorer trois grandes
parties de la phase « recherche » de la similarité : 1. Trouvé une unité similaire (une classe).
Pour cela, il faudra trouver un algorithme ou technique d’analyse de la similarité des classes qui convient à la réutilisation de tests. Le chapitre 3présente ces résultats. Cette étape constitue l’orientation principale de notre projet de recherche.
2. Une fois l’unité la plus similaire trouvée, déterminer les méthodes les plus similaires. Il faudra trouver un autre algorithme ou technique d’analyse de la similarité, mais adapté aux méthodes.
Cette étape ne constitue pas le principal objectif, mais elle nous permet de nous appro-cher un peu plus de notre objectif à long terme qui est de modifier semi-automatiquement les tests.
3. Trouver les tests unitaires correspondants qui pourront être réutilisés.
Lorsque la similarité des méthodes aura été analysée, nous filtrerons et/ou catégoriserons les méthodes qui seraient potentiellement réutilisables, qui doivent être modifiées ou qui sont inutiles.
La principale difficulté est d’identifier le contenu ou le sens du code car différents programmeurs programment de manière différente façons pour produire le même résultat. Ainsi, nous allons explorer différentes façons de comparer le code afin de tenir compte de l’intention, car c’est ce qu’un test unitaire vérifie.
1.3
Problématique
Comme pour la réutilisation de codes sources à l’aide du CBR, nous partageons les mêmes deux grands problèmes liés à l’utilisation du CBR : la quantité de cas nécessaires pour construire la base de cas et la technique d’analyse de la similarité. Il existe déjà des solutions pour la taille de la base de cas, dont l’utilisation de projets ouverts (Open Source).
Pour le deuxième problème, il existe déjà des méthodes pour analyser la similarité qui per-mettent de détecter des clones (copies). Cependant, ces méthodes ne s’appliquent pas direc-tement pour analyser la similarité dans le but de réutiliser un test unitaire (voir chapitre2). En résumé, voici les deux principales différences :
– Pour déterminer les clones, le plus important est de vérifier que le contenu (lignes) est similaire.
– Pour réutiliser les tests unitaires, le plus important est que la logique et le résultat produit soient similaires, peu importe la manière dont cela a été écrit.
Notre problématique consiste donc à explorer et essayer des méthodes pour comparer la simi-larité des codes sources qui pourraient servir à déterminer quels tests unitaires peuvent être réutilisables. Nous nous intéressons principalement à la partie de l’analyse de la similarité et du choix des tests unitaires.
1.4
Méthodologie
En premier lieu, nous ferons une étude des systèmes de génération de tests existants et nous regarderons les avantages, inconvénients et façons de faire. Suite à cette analyse, nous propo-serons une alternative utilisant l’approche CBR (voir chapitre2).
Deuxièmement, Nous nous concentrerons ensuite sur la comparaison de la similarité des codes sources. Nous chercherons une approche pouvant bien fonctionner dans le cadre de la phase « recherche » du CBR et qui pourrait servir à réutiliser des tests.
Pour ce faire, nous allons utiliser Java, un langage orienté objet. Nous construirons des couples <Classe Java, Test unitaire associé> et formerons une base de cas. Nous pourrons ensuite comparer la similarité d’une autre classe Java et tenter de réutiliser le test unitaire associé. Pour ce faire, nous allons décomposer la classe Java en identifiant les éléments et caractéristiques qui la composent afin de pouvoir utiliser un algorithme qui mettra en évidence les similarités entre elles. Nous combinerons des techniques différentes à chaque attribut (méthodes, variables, etc.) afin d’améliorer l’analyseur de similarité.
Nous procéderons par expérimentation en montant un prototype fonctionnel sur une base de cas tirée de plusieurs versions d’un même projet codé par différentes équipes (voir chapitre3). Finalement, nous chercherons un algorithme simple permettant de comparer la similarité des méthodes testées. Cela permettra de filtrer les méthodes du test associé que nous pourrons réutiliser (voir chapitre 4).
1.5
Plan du document
Le chapitre 2 présente une revue de littérature. Nous débuterons par le sujet général de la qualité des logiciels afin de présenter le contexte dans lequel nous effectuons notre recherche. Puis, nous présenterons des études sur les systèmes de génération de tests, ainsi que l’approche par CBR. Finalement, nous regarderons des techniques existantes d’analyse de la similarité du code qui sont utilisées dans différents contextes.
Le chapitre3expose notre approche de l’analyse de la similarité des classes. Nous parlerons de l’extraction de l’information d’un code source en attributs et du choix de ces attributs. Enfin, nous présenterons le coeur de notre recherche, soit, le calcul de la similarité entre les classes pour trouver des tests unitaires à réutiliser.
Le chapitre 4 est consacré à la détection de la similarité entre les méthodes et au filtrage des méthodes dans un test unitaire.
Le chapitre 5, présente tous les résultats de nos expérimentations avec deux bases de cas différentes.
Finalement, le chapitre 6, conclut sur nos contributions et donne des pistes d’amélioration pour poursuivre nos expérimentations et nous rapprocher de l’objectif à long terme.
Chapitre 2
Revue de littérature
Dans ce chapitre, nous présenterons une revue de littérature sur le domaine de la génération de tests unitaires à l’aide du CBR et, plus particulièrement, sur l’analyse de la similarité.
Nous exposerons d’abord quelques caractéristiques de la qualité du logiciel à l’aide du standard international ISO-9126 [fSI01] à la section 2.1.1.
Nous présenterons ensuite les tests unitaires pour le logiciel à la section 2.2.
La section 2.3 exposera quant à elle les systèmes de tests automatiques de manière générale avant de parler particulièrement du CBR à la section 2.4.2.
Enfin, pour pouvoir utiliser le CBR dans ce contexte, il nous faut d’abord trouver une technique d’analyse de la similarité qui s’applique à notre contexte. Pour cela, nous ferons une revue des techniques existantes à la section 2.6.2.
2.1
Qualité logicielle
La définition de la qualité diffère selon les domaines. Dans notre cas, nous nous concentrons sur la qualité en génie logiciel.
2.1.1 ISO-9126
Selon ISO-9126 [fSI01], il existe six caractéristiques et sous-caractéristiques relatives à la qua-lité logicielle.
Voici quelques caractéristiques importantes s’appliquant à notre contexte tiré de ISO-9126 [fSI01] : Fonctionnalité : le logiciel fonctionne tel que demandé par le client, dans l’environnement
du client.
Fiabilité : capacité du logiciel à continuer de fonctionner correctement dans un contexte particulier (ex. : suite à une faute, perte de connexion imprévue, etc).
Utilisabilité : le logiciel est facile à utiliser et à apprendre.
Maintenabilité : capacité de modifier facilement le logiciel (nouvelles fonctionnalités, réusi-nage, etc.).
Testabilité : C’est une sous-caractéristique de la maintenabilité. C’est la capacité de tester facilement le logiciel. Cela permet de faire des ajouts au logiciel, de le modifier de façon sécuritaire et, conséquemment, d’accélérer la maintenabilité.
Ce point est particulièrement important pour les développeurs car c’est ce qui leur permet de s’assurer que leur travail fonctionne tel que demandé et sans bogue.
Pour le client, c’est une façon de s’assurer que le produit livré correspond bien à ses attentes. De plus, les tests sont très utiles afin d’éviter une augmentation importante du coût des changements qu’il y aura à faire avec le temps.
2.1.2 Qualité utilisateur ou développeur
En plus des caractéristiques, on peut catégoriser la qualité selon le point de vue ou le rôle [NT08] : Point de vue utilisateur : Dans ce cas, on regarde la qualité de l’extérieur, comme un
utili-sateur. On s’intéresse alors à des caractéristiques comme l’utilisabilité, les fonctionnalités, la fiabilité, etc.
Par exemple : les personnes âgées ayant des problèmes de vision considéreront qu’un clavier plus simple et plus grand est de meilleure qualité, peu importe la qualité interne (maintenabilité, etc.) du logiciel intégré.
Point de vue développeur : Pour les développeurs, c’est la qualité interne qui importe le plus, car c’est la qualité intrinsèque du logiciel qui permet de modifier ou d’ajouter faci-lement de nouvelles fonctionnalités ou encore de développer le plus rapidement possible sans introduire de bogues.
Nous considérerons donc plutôt des caractéristiques comme la maintenabilité ou la tes-tabilité (sous-caractéristique). Par contre, il est évident que ces problèmes ont une im-portance pour le client, bien qu’elle soit indirecte.
2.2
Test unitaire en génie logiciel
Les tests sont une méthode connue pour faciliter la maintenabilité d’un logiciel, réduire la quantité de bogues et produire le bon logiciel pour le client.
Notre recherche se concentre sur la testabilité d’un logiciel grâce à l’utilisation d’un générateur de tests unitaires automatisés basé sur le CBR comme nous l’expliquerons à la section2.5.
Test unitaire Nous convenons également de dire que la qualité d’un logiciel est très impor-tante, tant d’un point de vue extérieur (le client) qu’intérieur (performance, maintenabilité, réutilisabilité, etc.).
Un test unitaire est un type de test pour tester les unités (ex. : une classe) en isolation. Il permet de s’assurer que chaque unité fonctionne bien avant l’intégration de celles-ci.
De plus, il permet de s’assurer que les unité existantes fonctionnent toujours après une modi-fication ou un ajout. On appelle cela vérifier la régression.
Ainsi, quand il y a un problème, nous pouvons identifier rapidement quelle unité est la cause du problème sans avoir à chercher dans tous les chemins d’appels de toute l’application. Cela permet de construire l’application sur des composantes solides et testées individuellement avant de les intégrer.
Le test unitaire permet de vérifier que cette unité fonctionne seule et donc, de la réutiliser dans un autre contexte.
Finalement, un test unitaire opère à un niveau très détaillé et permet de tester chaque méthode et comportement dans le détail et en isolation.
Dans notre cas, nous remarquons qu’un test unitaire ne teste pas des lignes de codes mais des comportements. En effet, un test unitaire permet de tester le résultat de l’exécution des méthodes d’une classe donnée. C’est ce comportement final attendu qui est testé et non pas la manière dont le code est écrit. Il est possible de produire le même comportement avec différents codes. La section2.6.2 montre un exemple.
Cela nous oblige à adapter les techniques d’analyse de la similarité qui sont souvent basées sur la comparaison du texte et non sur les comportements.
JUnit Il existe plusieurs outils pour écrire des tests unitaires et les plus populaires sont ceux de la famille XUnit[Wik12d]. XUnit est une famille de frameworks pour écrire des tests
dans différents langages1. JUnit est un framework de cette famille pour Java.
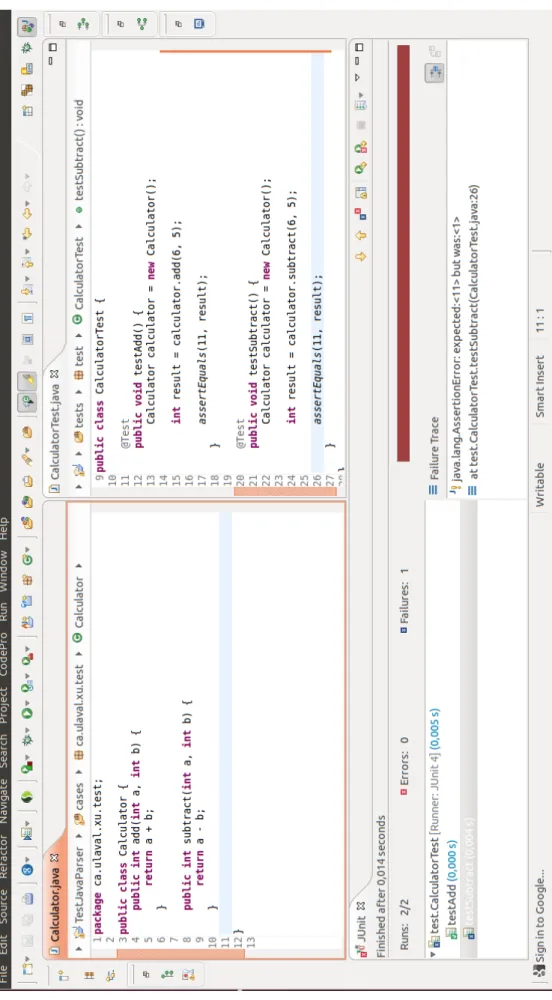
JUnit exécute et trouve les tests unitaires automatiquement dans un projet sans avoir à écrire un point de départ (« main »). Nous allons montrer comment écrire un test unitaire avec JUnit à la figure2.1.
En plus de découvrir les tests (@Test dans JUnit 4) et de les exécuter, il offre des méthodes de vérification (Assert) permettant de comparer les valeurs ou le résultat attendu. En utilisant ces méthodes, cela permet ensuite à JUnit de fournir un rapport indiquant quels tests ont réussi ou non. Dans le cas de tests qui ont échoué, JUnit indique généralement la raison, le résultat attendu par rapport au résultat obtenu et quel test a échoué.
2.3
Les systèmes de génération de tests
Nous avons déjà parlé de l’importance des tests à la section 2.2. Les tests unitaires sont de plus en plus utilisés dans les entreprises et commencent à devenir courants [Tor06]même si dans la réalité il y a encore beaucoup de développeurs qui n’écrivent pas de tests.
Il y a plusieurs raisons pour lesquelles certains développeurs n’écrivent pas de tests unitaires. Cela peut être parce qu’eux-mêmes ou leur employeur considèrent que ça coûte cher ou que ça ne vaut pas la peine.
En fait, il n’ont pas totalement raison, parce que le coût comprend deux parties : écrire le code puis, la maintenance. Le temps de développement prend un peu plus de temps à cause des tests. Mais en même temps, ils en sauvent car le temps de débogage est moindre. Ainsi il est possible de développer des logiciels plus vite et en toute confiance. Ainsi, les bogues peuvent être trouvés immédiatement par un test unitaire.
Nous pensons qu’un générateur de tests pourrait aider en permettant de développer plus rapidement et en éliminant la crainte liée à l’écriture des tests, surtout pour les développeurs débutants.
Il existe déjà plusieurs systèmes pour générer automatiquement (sans ou avec peu d’interven-tions d’un programmeur) des tests. Les secd’interven-tions qui suivent présenteront différents outils que nous avons analysés. Une comparaison expliquant les avantages et inconvénients sera présentée à la section2.3.6.
2.3.1 JUnit Factory
JUnit Factory [aut] est un générateur de tests qui s’intéresse à la création de tests de régression. Il est très différent des autres outils que nous présenterons puisqu’on ne peut pas le télécharger et qu’il est offert sous forme de service. Les utilisateurs doivent envoyer leur projet sur un serveur d’Agitar. Agitar est la compagnie qui a développé JUnit Factory.
Cette approche fonctionne mieux pour quelques petites classes indépendantes mais pas pour de gros projets [aut]. Les tests générés ont une bonne couverture mais il impossible d’apprendre et de perfectionner le système car le code source n’est pas libre. Il n’est donc pas très intéressant pour poursuivre des recherches et les faire évoluer.
Finalement, c’est aussi un problème de sécurité pour l’utilisateur car il doit envoyer son code sur un serveur Internet.
2.3.2 JCrasher
Csallner et al. [CS04] ont présenté JCrasher. C’est un outil qui génère les tests pour un code source en Java. Il est un générateur de tests pour la détection des erreurs.
Son but est d’essayer à détecter les bogues quand un programme lance une exception. Il génère les données d’entrée aléatoirement mais en considérant le bon type.
Le processus de génération des tests avec JCrasher fonctionne comme suit : 1. On donne la classe T à JCrasher.
2. JCrasher charge la classe T.
3. Il analyse la classe T en utilisant la réflexion Java [Wik12c]. Il trouve chaque méthode déclarée dans la classe T. Pour chaque méthode, il trouve également les paramètres et leur type.
4. Il sélectionne quelques combinaisons selon le graphe de paramètres pour écrire le test en JUnit. Un graphe de paramètres est une représentation des paramètres d’une méthode et des valeurs aléatoires à passer. Différentes combinaisons de paramètres pour chaque méthode à tester sont créées en traversant le graphe.
5. Les tests sont exécutés avec JUnit.
6. Filtre d’exception : quand une exception est lancée, il utilise une heuristique pour déter-miner si l’exception doit être considérée comme un bogue ou si les entrées de JCrasher ont violé des conditions préalables.
Ce outil est totalement automatique, sauf que le rapport des erreurs doit être interprété par les humains.
2.3.3 Jartege
Oriat et al. [Ori05] ont proposé l’outil Jartege. C’est un générateur de tests unitaires aléa-toires en cours d’exécution. Il est conçu pour fonctionner avec le langage JML (Java Modeling Language).
JML est un langage de spécifications pour Java. Il permet de spécifier des programmes Java à l’aide de différentes assertions : invariants, préconditions et postconditions.
Figure 2.2: Annotation JML pour préconditions et postconditions [Ori05].
Figure 2.3: Le processus de Randoop [Pac].
Après avoir spécifié le programme en JML, on peut vérifier que ce dernier est conforme à sa spécification en évaluant les assertions JML, comme le montre l’exemple à la figure 2.2. Dans cet exemple, la précondition exige que « l’histoire » n’est pas « null » et la et la postcondition vérifie que le solde et l’historique du compte ont été mis à jour.
Du point de vue de l’utilisateur, un outil comme Jartege est moins facile et rapide à utiliser car il a besoin d’ajouter des spécifications en JML.
2.3.4 Randoop
Pacheco et al. [Pac] ont présenté l’outil Randoop (Random Tester for Object-Oriented Pro-grams). Il est un générateur de tests de régression et de tests de détection.
Le processus de Randoop est illustré à la figure 2.3. Il prend en entrée les classes non encore testées, le temps limite ainsi que les options que Randoop doit offrir.
Il utilise une technique de type aléatoire. Cependant, comme le montre la figure 2.3, il utilise en plus une rétroaction basée sur l’exécution pour générer de nouvelles séquences. En effet, il se sert du résultat des tests pour trouver de nouvelles entrées et ainsi éviter la redondance. De plus, il génère les tests de régression et les tests de détection.
2.3.5 CodePro
CodePro est un outil de Google. Il permet de créer des cas de test JUnit. Il permet de prendre une classe qui n’est pas encore testée et de générer des tests unitaires. Il peut analyser toutes les méthodes de la classe pour générer les tests. De plus, les tests générés sont très compréhensibles. La figure2.4 montre un exemple de test généré.
Malheureusement, la technique utilisée n’a pas été publiée. On ne sait donc pas comment elle fait pour analyser toutes les méthodes et produire des cas de tests.
Bien que cet outil présente beaucoup d’avantages et est facile à utiliser pour les développeurs, le problème de l’oracle (déterminer ce qui est un comportement voulu ou une erreur) persiste toujours. Une intervention manuelle est donc toujours nécessaire pour créer des tests complets.
2.3.6 Catégories de générateurs
Dans les outils que nous venons de présenter, il y a deux types de tests générés : les tests de régression et la détection des erreurs.
Ces deux techniques sont deux façons de résoudre le problème de l’oracle. Par exemple, à la fin de tests unitaires on fait souvent une assertion pour comparer la valeur actuelle et la valeur attendue. Le problème de l’oracle, c’est de déterminer la valeur attendue. Sans un expert ou une référence, il est difficile de savoir si une valeur obtenue est exacte ou non.
Générateurs de tests de régression.
JUnit Factory et CodePro créent des tests de régression qui assurent que le comportement actuel du code sera toujours valide dans le futur. Ils vérifient que le code continuera à être valide dans le futur ; ce qui fonctionne continuera à fonctionner. Dans cette situation, on utilise le code actuel comme l’oracle ce qui suppose que le code actuelle est bon et fonctionne correctement.
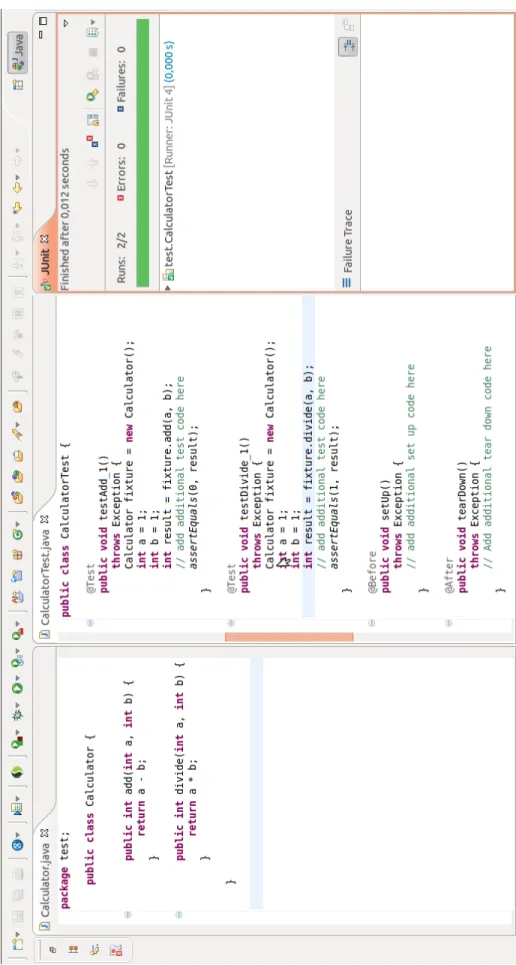
Par exemple, on ne détectera pas si le programmeur a fait des erreurs de logique comme le montre la figure 2.5. En effet, dans ce cas, la méthode « add » fait une soustraction plutôt qu’une addition.
Générateurs de tests de détection.
Avec un outil qui génère des tests de détection d’erreurs, comme JCrasher et Jartege, le problème de l’oracle n’existe pas. Un test de détection d’erreur ne fait que vérifier qu’aucune erreur (exception) ne s’est produite. Par contre, les problèmes qui lancent des erreurs ne sont qu’un petit pourcentage des problèmes possibles. Ce n’est donc pas suffisant pour garantir la qualité d’un logiciel.
Générateurs hybrides.
Randoop, utilise les deux types de création de tests. Il a donc lui aussi le même problème de l’oracle.
C’est à cause de ces problèmes que nous pensons générer les tests unitaires en utilisant un système de recommandation.
2.4
Système de recommandation
Un système de recommandation est un système de filtre spécial. Il est devenu de plus en plus populaire et utilisé dans plusieurs domaines.
Par exemple, le site d’Amazon [ama] utilise ce type de système pour faire des suggestions aux utilisateurs du site pour les livres ou la musique. Dans ce cas, le site recommande d’autres produits en utilisant les caractéristiques de l’utilisateur ainsi que ses achats.
2.4.1 Système de recommandation pour le génie logiciel
En génie logiciel, on utilise un système de recommandations pour aider les développeurs lors du développement de logiciels.
Happel et al. [HM08] ont résumé quelques systèmes de recommandation existants pour le développement en génie logiciel.
Jusqu’à maintenant, il n’y a pas encore de système de recommandation pour suggérer des tests unitaires. C’est l’objectif à long terme de nos travaux de recherche. Pour faire cela, nous pourrons cependant nous inspirer des techniques utilisées dans d’autres domaines, ou les améliorer.
2.4.2 Principes généraux du raisonnement à base de cas Le raisonnement à base de cas (CBR) est analogue au raisonnement humain :
1. Un nouveau problème survient et on cherche dans nos expériences passées des problèmes similaires ;
2. Parmi ces problèmes similaires, on retient celui qui semble le plus prometteur pour s’en servir comme modèle ;
3. On fait un essai avec la solution la plus similaire trouvée et on l’applique au problème en cours.
a) si cela fonctionne : nous avons notre solution ; b) sinon, il faut modifier la solution.
Le CBR est un système composé de deux parties : le processus et les connaissances [Lam04]. Il permet de préserver et de réutiliser les expériences passées.
Connaissances. La connaissance du domaine est une partie très importante du CBR, car c’est en se basant sur cette connaissance antérieure que nous trouverons la solution. L’ensemble des expériences est sauvegardé dans une base de cas.
Dans notre cas particulier, chaque cas contient un couple de la forme :hcode source, test unitaire associéi.
Processus. Normalement, il y a quatre étapes dans le processus du CBR (voir figure2.6) : 1. La recherche (retrieval ) : cette phase permet de rechercher les cas dans la base de cas
qui sont les plus similaires au problème soumis.
2. L’adaptation ou la réutilisation (reuse) : consiste à modifier le ou les anciens cas qui sont les plus similaires pour produire une nouvelle solution adaptée à partir de celle retrouvée dans la base de cas.
Figure 2.6: Processus du CBR [Wik12b].
3. La révision (revision) : le système utilise la version de la solution produite lors de l’étape précédente, la vérifie et mesure ses performances.
4. La rétention (retain) : En cas de succès à l’étape précédente, nous pouvons ajouter cette nouvelle solution dans la base de cas pour utilisation future. Ainsi, cette nouvelle solution pourra servir pour d’éventuels problèmes.
Par contre, la majorité des cas sont ajoutés par des experts du domaine car les cas sont validés et augmentent donc la probabilité d’avoir de meilleurs résultats.
2.4.3 Réutilisation du code à l’aide du CBR
Tessem et al. [TWP98] ont conçu un prototype pour la phase de recherche dans l’approche CBR en Java afin de trouver les bouts de codes similaires à réutiliser.
À partir du code source, ils ont extrait automatiquement les caractéristiques qu’ils ont choisi. Par exemple, les attributs d’une classe, les constructeurs et les signatures de méthodes, car ces caractéristiques sont généralement, selon les auteurs, plus importants pour détecter la similarité.
Une fois les caractéristiques trouvées et les poids identifiés, ils procèdent comme pour un CBR normal :
1. Faire un algorithme de recherche, puis comparer avec chaque cas dans la base de cas ; 2. Trouver le cas le plus similaire avec le nouveau code source ;
Nos travaux sont basées sur cette technique que nous modifierons pour l’adapter à notre contexte, comme le montre la section2.5.
2.5
Discussion sur la génération automatique de tests
unitaires à l’aide du CBR
Généralement, les principales recherches dans le domaine de la réutilisation de code et du CBR portent sur la réutilisation du code source lui-même [TWP98]. Nous nous intéressons à la réutilisation de tests unitaires. Cela demande des étapes supplémentaires et exige que nous adaptions les techniques d’analyse de la similarité.
Notre but à long terme est d’essayer de générer des tests unitaires (voir section2.2) automa-tiquement avec le CBR.
À cause du fait que notre entrée est un code source et que nous voulons obtenir des tests unitaires en sortie, chaque cas de notre base de cas est donc un couple de la forme :hcode source, test unitaire associéi, contrairement à la majorité des recherches où le code source similaire trouvé sera directement utilisé comme sortie.
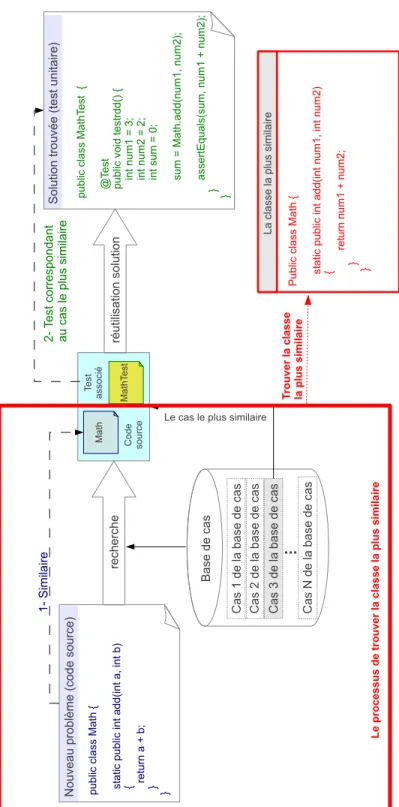
Ainsi, pour chaque nouveau problème qui arrive, on cherche le cas le plus similaire et on tente d’utiliser la solution associée comme base pour la solution finale, comme le montre la figure2.7.
La quantité de cas dans la base de cas est un problème majeur dans le cas des réutilisations du code source.
Dans notre recherche, nous nous intéressons plutôt à un deuxième problème : le calcul de la similarité (section2.6).
2.6
Analyse de la similarité
2.6.1 Similarité des codes en programmation
La similarité du code en programmation est un domaine très important pour pouvoir utiliser le CBR, principalement parce que le CBR doit trouver le cas le plus ressemblant au nouveau cas et la seule manière de faire cela est d’analyser la similarité de ce dernier avec tous les cas de sa base de cas.
Généralement, nous utilisons le CBR et l’analyse de similarité du code pour réutiliser un code équivalent, mais déjà testé. Dans notre cas, nous voulons générer un test adapté au nouveau cas.
Il existe différents types de similarité. Mais nous nous intéresserons uniquement à la similarité syntaxique [WErC+] , car les techniques sémantiques ne sont pas encore matures.
Similarité sémantique Avec la similarité sémantique, on s’intéresse au sens (concept) caché derrière une méthode ou une classe. Ainsi, on regarde quels sont les concepts communs [Wik11].
N ouv eau p robl ème (co de so urce) Sol ut ion trou vée (test uni tai re) Ca s 1 de la b ase de c as C as 2 de l a base d e cas Ca s 3 de la b ase de c as
...
Ca s N d e la b ase de ca s Base de c as publ ic cl ass M at h { s tat ic pub lic int a dd( int a , i nt b) { r et ur n a + b; } } publ ic cl as s M at hT est { @ Test pub lic v oi d test rdd( ) { int nu m 1 = 3 ; int nu m 2 = 2 ; int sum = 0 ; su m = M at h. add( num 1, num 2) ; ass er tE qual s( su m , num 1 + num 2) ; } } M at h M at hT es t C ode sour ce Tes t as soc ié 1- Si mil aire T est co rrespo nd an t au ca s le pl us simi lai re rech ercheLe cas le plus similaire
ré
utili
satio
n solu
tion
Fichier Java
Import Class
Interface Package
Implements
Extends Method Field
MethodCalled Parameter Variable
Figure 2.8: Structure d’un fichier Java.
Pour la similarité entre les codes sources, si deux unités représentent le même concept, alors ils sont plus similaires. Mais comme chaque développeur a ses propres habitudes de program-mation et de nommage, il est difficile de déterminer la similarité par une simple comparaison du texte. C’est pourquoi l’analyse sémantique est intéressante.
En théorie, cette forme d’analyse s’applique bien à notre cas, mais jusqu’à maintenant, il y a peu de recherches sur la similarité sémantique qui sont matures et applicables. Il s’agit d’un domaine de recherche en soi. C’est pourquoi, pour l’instant, nous utiliserons uniquement cette forme pour le nommage.
Similarité syntaxique. L’analyse syntaxique consiste à comparer les textes et la syntaxe (structure). Par exemple, une analyse simple consiste à comparer chacun des textes. Nous pou-vons ensuite comparer les noms de méthodes, les appels, etc. en lisant le code du programme. De manière générale, nous pouvons connaître la similarité syntaxique de deux codes source en comparant chacune des caractéristiques du premier code source avec la même caractéristique d’un deuxième code source. La figure 2.8 montre des caractéristiques syntaxiques possibles pour un fichier Java.
Étant donné que la structure du langage de programmation est assez complexe, le recours à la similarité des codes permet d’identifier les différents types de codes. Parfois, nous combinons aussi ces deux éléments pour améliorer la qualité de la validation.
Dans le cas qui nous intéresse, nous comparerons chacune des caractéristiques d’un fichier Java et nous pourrons obtenir une mesure de similarité totale pour les deux fichiers.
2.6.2 Techniques d’analyse de la similarité
Nous venons de couvrir les différents types de similarité. Jusqu’à maintenant il n’existe pas de technique d’analyse de la similarité pour générer des tests unitaires. Mais il existe plusieurs techniques pour détecter les clones de code. Nous détaillons celles qui sont le plus couram-ment utilisées, afin d’identifier les techniques que nous pourrons réutiliser et adapter à notre contexte.
Même si ces techniques ne permettent pas d’analyser directement la similarité dans notre contexte, notre but n’étant pas de détecter les cas de duplication, nous essayons de trouver un ancien test déjà écrit, afin de l’utiliser pour notre nouveau cas.
La grande différence avec la détection des duplications, c’est qu’il est plus important dans notre cas que le résultat du code soit similaire plutôt que le code lui-même le soit. En effet, deux codes très différents mais produisant le même résultat (comportement) pourront être testés par le même test. Ainsi, il est possible de réécrire complètement et autrement le contenu d’une méthode, sans avoir à changer le test.
Dans les prochaines sections, nous expliquerons ces différences en détail à l’aide de chacune des techniques utilisées pour la détection de clones. Nous pourrons donc mieux comprendre notre contexte mais également identifier des adaptations possibles des techniques pour nos recherches.
Technique basée sur le texte.
Elle prend deux codes sources et compare ses chaînes de caractères une à une. Puis, elle essaie de trouver les séquences qui sont exactement identiques. Normalement, avec cette technique, le prétraitement consiste à enlever les lignes blanches, puis enlever les commentaires.
Roy et al. [RC07] ont résumé des travaux concernant la technique basée sur le texte [Bak95,
DNR06, Joh94,MM01]. Ils ont présenté différentes approches pour détecter les clones, mais toutes les approches utilisent la technique basée sur le texte.
Malheureusement, cette technique est généralement meilleure pour analyser la similarité pour des clones que pour générer des tests unitaires, parce que les tests unitaires ne s’occupent pas de l’intérieur du code. Ainsi, si les deux bouts de code ont le même résultat (comportement), nous les considérerons comme similaires.
Comme l’exemple que nous avons montré au chapitre1, le code source2.1montre deux bouts de codes sources qui produisent exactement le même résultat (un tableau trié), mais de manière différente (algorithmes).
Le code2.2montre un test unitaire écrit initialement pour l’algorithme QuickSort. Cependant, en observant bien ce test, on peut remarquer que le test pour le BubbleSort est identique (sauf pour le nom de la classe) à celui du QuickSort. La réutilisation du test est possible, parce que
Listing 2.1: Comparaison entre le code du tri à bulles et le tri rapide. public c l a s s B u b b l e S o r t { public i n t [ ] s o r t ( i n t a r r [ ] ) { i n t tmp = 0 ; f o r ( i n t i = 0 ; i < a r r . l e n g t h − 1 ; i ++) { f o r ( i n t j = a r r . l e n g t h − 1 ; j > i ; j −−) { i f ( a r r [ j ] < a r r [ j − 1 ] ) { tmp = a r r [ j ] ; a r r [ j ] = a r r [ j − 1 ] ; a r r [ j − 1 ] = tmp ; } } } return a r r ; } } public c l a s s Q u i c k S o r t { private i n t [ ] numbers ; private i n t number ; public i n t [ ] s o r t ( i n t [ ] v a l u e s ) { i f ( v a l u e s == n u l l | | v a l u e s . l e n g t h == 0 ) { return n u l l ; } t h i s . numbers = v a l u e s ; number = v a l u e s . l e n g t h ; q u i c k s o r t ( 0 , number − 1 ) ; return v a l u e s ; }
private void q u i c k s o r t ( i n t low , i n t h i g h ) {
i n t i = low , j = h i g h ;
i n t p i v o t = numbers [ low + ( h i g h − low ) / 2 ] ;
while ( i <= j ) { // . . .
les deux algorithmes ont le même comportement et produisent le même résultat à partir d’une même entrée. En fait, le contenu de la méthode n’est pas important et la façon de trier non plus.
Listing 2.2: Test unitaire pouvant servir à la fois pour le Quicksort et le Bubblesort. public c l a s s S o r t T e s t { @Test public void t e s t S o r t ( ) { B u b b l e S o r t b u b b l e S o r t = new B u b b l e S o r t ( ) ; // −− OU −− ( s e l o n l a c l a s s e à t e s t e r ) Q u i c k S o r t q u i c k s o r t = new Q u i c k s o r t ( ) ; i n t [ ] i n i t i a l N o t S o r t e d = { 5 0 , 6 3 , 25 } ; i n t [ ] e x p e c t e d S o r t e d = { 2 5 , 5 0 , 63 } ; i n t [ ] r e s u l t S o r t e d = q u i c k s o r t . s o r t ( i n i t i a l N o t S o r t e d ) ; a s s e r t A r r a y E q u a l s ( e x p e c t e d S o r t e d , r e s u l t S o r t e d ) ; } }
Technique basée sur l’arbre.
Elle permet de convertir le code source sous la forme d’un arbre de syntaxe abstraite (AST) avec un analyseur. L’AST est un arbre qui présente tous les détails (caractéristiques) d’un code source.
On utilise l’arbre syntaxique (AST) parce que c’est une manière de représenter le code source. Une fois l’AST créé, on cherche les sous-arbres similaires d’un arbre avec différents algorithmes. Enfin, on retourne le sous-arbre le plus similaire.
Par exemple, l’outil Coogle [20112] utilise cette technique. Il utilise d’abord un ASTParser pour convertir du code source sous la forme d’un AST, puis transforme les nœuds de l’AST en éléments FAMIX2. FAMIX est un modèle pour représenter différents langages orientés objet. On peut profiter de la capacité du FAMIX pour analyser et comparer la similarité. Pour comparer cette similarité, il utilise un algorithme de similarité sur l’arbre.
Coogle construit l’arbre à partir d’un modèle FAMIX, puis utilise le patron Visitor [GHJV94] pour visiter les éléments du code source et construire un arbre avec ces informations.
Il utilise ensuite un comparateur pour comparer les nœuds de deux arbres comme le montre la figure 2.9. Cette technique a pour but d’essayer de trouver les sous-arbres similaires. Dans ce contexte, ils ne font qu’essayer de trouver le sous-arbre le plus similaire. Par contre, dans notre cas, il est moins important de trouver le sous-arbre similaire que de trouver la même fonctionnalité entre deux bouts de code. L’exemple2.1montre un cas pour lequel il est possible d’utiliser un même test unitaire pour deux codes différents.
Un autre problème réside dans le fait qu’il considère chaque nœud équivalent mais, dans notre cas, les attributs n’ont pas la même importance.
Figure 2.9: Comparer les nœuds et trouver les sous-arbres similaires[20112].
Figure 2.10: Exemple avec le PDG [aja].
Technique basée sur le PDG.
La technique du PDG (Program Dependency Graph) utilise un graphe de contrôle ou de données. Même si le graphe peut sembler proche d’un arbre, ces deux techniques sont très différentes. L’AST représente un arbre des caractéristiques du code alors que le PDG représente les chemins d’exécution ou le cycle de vie des données.
La figure2.10 montre un exemple de PDG avec les données.
Flot de données. Les flèches vertes représentent le flot de données. Elles montrent tous les flots de données à l’intérieur d’une classe ou d’une méthode.
Comme pour la technique basée sur le texte (voir section2.6.2), il est possible d’avoir plusieurs flots de données produisant le même résultat final. Il serait donc possible de réutiliser le même
test pour deux flots de données différents.
Flot de contrôle. Les flèches bleus représentent les flots de contrôle. Un flot de contrôle représente les appels de méthodes d’un programme les uns à la suite des autres. C’est un peu comme le chemin d’exécution du programme en fonction des méthodes appelées.
Si deux programmes font les mêmes appels de méthodes dans le même ordre, par exemple, alors il est très probable que les deux produiront les mêmes comportements finaux. Cela ne tient pas compte de l’utilisation des données, mais on peut utiliser cette technique pour comparer le comportement en considérant les appels similaires.
Rappelons cependant que notre but est de générer des tests unitaires. Et un test unitaire est un test d’une unité (classe) isolée sans considérer les appels situés plus loin dans le flot. Cette technique est donc meilleure pour un test fonctionnel (plusieurs unités) que pour un test unitaire (on ne regarde qu’une unité à la fois).
Technique basée sur les métriques
Cette technique compare les métriques du code calculées sur les deux codes à analyser. Une métrique donne une façon de mesurer une caractéristique du code. Par exemple, le nombre de lignes de code, la complexité cyclomatique, etc.
Technique de la factorisation. Par exemple, Chilowicz et al. [CDR09] présentent une technique basée sur les métriques pour détecter la similarité du code source en utilisant la factorisation.
On a souvent entendu parler de la factorisation dans le domaine des mathématiques. Pour les mathématiciens, la factorisation consiste à écrire une expression algébrique (notamment une somme), un nombre ou une matrice sous la forme d’un produit [Wik12a]. Dans le domaine de l’informatique, on peut utiliser cette méthode pour détecter la similarité des codes sources à réutiliser.
En programmation, l’algorithme de la factorisation se base sur le tableau de suffixes. Le facteur n’est pas une expression algébrique ni un chiffre mais sont des fonctions et des sous-fonctions. L’algorithme de factorisation permettra d’obtenir les sous-fonctions liées aux fonctions prin-cipales à partir d’un code source. Par exemple : f 2 ⊃ {f 1, f 20, f 3} c’est ce graphe que l’on pourra comparer pour analyser la similarité comme le montre la figure 2.11.
Pour faire cela, on mesure la similarité entre les sous-fonctions de deux projets. Dans cette recherche, Chilowicz et al. ont défini la métrique de la similarité comme étant scsimil(pi, pj) =
I(pi∩pj)
I(p∪pj) où I(pi) représente le nombre d’informations pour le projet pi. Si scsimil(pi, pj) = 1,
ça veut dire que les deux projets pi et pj sont en fait les mêmes.
Mais le problème avec cette technique est que la métrique a besoin d’une inspection manuelle et est donc difficilement automatisable.
Figure 2.11: Exemple de code source d’un graphique d’appels déduit après deux itérations avec la technique de Chilowicz et al [CDR09].
Approche hybride
Il y a beaucoup d’outils qui utilisent cette approche. Elle consiste à combiner plusieurs tech-niques pour résoudre un problème.
2.6.3 Comparaison
La dernière étape consiste à analyser et comparer les différentes techniques qu’on utilise pour calculer la similarité des codes sources (voir tableau2.1).
Le tableau2.1compare les différentes techniques de détection des clones pour le code source. Nous en avons besoin pour déterminer quel cas est le plus similaire au problème pour lequel nous désirons générer le test. Cette comparaison se fera en comparant le nouveau code avec chacun des codes (1ère partie du couple d’un cas) de la base de cas, tel qu’expliqué à la section2.5et illustré à la figure2.7.
Pour cette étape de comparaison, nous devrons choisir la meilleure technique ou encore les combiner afin d’avoir une technique qui fonctionne bien pour la sélection d’un test.
Plusieurs techniques ont été conçues pour détecter la duplication de codes (voir tableau2.1), sauf que dans notre cas, notre problème est différent : nous voulons générer des tests unitaires.
Propriétés T ec hniques basées sur le texte T ec h niques basées sur l’arbre T ec hniques basées sur PDG T ec hniques basées sur les métriques Appro che h ybrid e (AST + arbre de suffixes) T ransformation Supprime les espaces et commen taires Analyse syn taxique p our créer un AST Analyseur syn taxique p our créer un PDG Analyse syn taxique p our créer un AST afin de générer les métriques Analyse syn taxique p our créer un AST, puis une autre forme p ou r l’ar bre de suffixes Représen tation du co de Filtrées et/ou normalisées L’AST du programme à partir du texte et de la structure du co d e Ensem ble de PDG des pro cédures du système Ensem ble de métriques AST représen té sous la forme d’un arbre de suffixes Gran ularité d e la comparaison Ligne Nœud de l’arbre Nœud PDG Métriques p our chaque métho de/blo c Jeton de l’AST enco dé dans une séquence Complexité de calcul Dép end de l’algorithme Quadratique Quadratique Linéaires Linéaires Opp o rtunités de réusinage Bon p our les corresp ondances exactes T rouv e les clones, b o n p our le réusinage Bon p our réusinage Insp ection man uelle requ ise Clones, b on p our le réusinage Indép endance du langage F acilemen t adaptable Besoin d’un analyseur Besoin d’un générateur de PDG Souv en t b esoi n d’un analyseur Besoin d’un analyseur T able 2.1: T ec hniques d’analyse de la similarité du co de .
Par exemple, la technique de comparaison des lignes ne fonctionnera pas bien parce qu’un même test unitaire peut tester deux codes écrits avec des lignes différentes mais produisant le même comportement.
En résumé, nous pouvons dire que la technique basée sur l’arbre, la technique basée sur PDG et certaines approches hybrides sont bons pour le réusinage. Mais, tel que discuté dans les sections2.6.2 et2.6.2, bien que ces techniques soient très bonnes pour détecter les clones, elles ne le sont pas forcément pour générer des tests unitaires.
Il faut donc trouver quelle sera la bonne technique d’analyse de la similarité convenant pour des tests. Cela se fera probablement à un plus haut niveau dans la structure du code. Ainsi nous essaierons de trouver une approche hybride adaptée au contexte.
Chapitre 3
Similarité entre les classes
Pour comparer deux classes, l’analyse du code textuel ne suffit pas car il est possible de nommer ou d’écrire différemment le même concept. Il faut donc analyser également la structure de la classe.
Nous avons donc essayé d’identifier les éléments qui composent une classe afin de pouvoir utiliser un algorithme qui mettra en évidence les similarités entre elles.
Dans ce chapitre, nous présenterons, tout d’abord, le processus permettant de trouver la classe la plus similaire à partir d’une base de cas.
Ensuite, nous présenterons, à la section 3.2, une méthode d’extraction des attributs (informa-tions) de la base de cas à partir d’une classe.
Par la suite, nous expliquerons, à la section 3.3, quels attributs ont été sélectionnés ainsi que les différentes méthodes pour les calculer afin de déterminer quelle classe est la plus similaire.
3.1
Processus de recherche de la classe la plus similaire
Afin de pouvoir éventuellement sélectionner un test unitaire pour un code donné, il faudra d’abord trouver le cas connu qui lui ressemble le plus dans la base de cas. Ensuite, nous pourrons adapter le test qui était associé à ce cas existant et connu.
Pour ce faire, la première étape consiste à trouver le cas le plus similaire au problème proposé. Cette étape est représentée à la figure3.1 de l’encadré.
Pour y arriver, nous utilisons un analyseur syntaxique (JavaParser) qui permet d’analyser et de découper les différents éléments du langage Java. Nous pourrons ainsi obtenir les différentes composantes de la classe donnée (nom, importations, méthodes, appels, variables, etc.). La figure 3.2montre les différentes étapes de ce processus que nous exposerons ci-dessous.
N ouv eau p robl ème (co de so urce) Sol ut ion trou vée (test uni tai re) Ca s 1 de la b ase de c as C as 2 de l a base d e cas Ca s 3 de la b ase de c as ... Ca s N d e la b ase de ca s Base de c as publ ic cl ass M at h { s tat ic pub lic int a dd( int a , i nt b) { r et ur n a + b; } } publ ic cl as s M at hT est { @ Test pub lic v oi d test rdd( ) { int nu m 1 = 3 ; int nu m 2 = 2 ; int sum = 0 ; su m = M at h. add( num 1, num 2) ; ass er tE qual s( su m , num 1 + num 2) ; } } M at h M at hT es t C ode sour ce Tes t as soc ié 1- Si mil aire T est co rrespo nd an t au ca s le pl us simi lai re rech erche
Le cas le plus similaire
ré utili satio n solu tion P ubl ic cl ass M at h { s tat ic pub lic int add (int n um 1, int n um 2) { ret ur n num 1 + num 2; } } La cl as se la pl us si m ilai re Tr o u ver la cl asse la p lu s si m ilai re L e p ro cessu s d e tr o u ver la cl asse la p lu s si m ilai re
Code Source ( Classe Java)
JavaPaser
Arbre syntaxique abstrait
JavaVisitor Éléments de l'objet Calculateur de la similarité Base De Cas Cas 1 Cas 2 … ... ... Cas N Construire
Trouver la classe la plus similaire
Figure 3.2: Les étape de processus pour trouver la classe la plus similaire.
Un cas est construit à partir d’un fichier source Java. Il est découpé et analysé puis structuré de manière à faciliter son utilisation par la suite (comparaison, recherche, etc.).
L’analyse du fichier source (une classe) par l’analyseur (JavaParser1) permet d’extraire les différents attributs d’une classe Java comme le montre la figure 3.3.
Au fur et à mesure que l’analyseur trouve les éléments de la classe, il utilise un mécanisme pour avertir qu’un élément à été trouvé séquentiellement.
Avant l’analyse, un étape préalable est nécessaire afin de créer le bon cas en fonction du type de fichier Java reçu. En fait, pour Java, il n’y a aucune différence entre une classe de code et une classe de test puisqu’il s’agit d’une classe Java dans les deux cas. Un constructeur (CaseBuilder) est responsable de créer le bon type de cas (JavaCase ou JavaTestCase) en fonction du type de classe. Par contre, à cette étape, seul le code (JavaCase) nous intéresse.
Pour construire le cas, JavaParser utilise le patron visiteur (design pattern [GHJV94]) qui permet d’être averti et d’exécuter du code lorsqu’un certain élément est trouvé. Ainsi, une méthode différente sera exécutée quand une méthode est trouvée ou encore qu’une variable est déclarée, etc. Le fonctionnement sera détaillé à la section3.2.
Après l’analyse complète de la classe, notre visiteur (JavaVisitor) aura construit le cas (JavaCase) à ajouter à la base de cas. Nous allons présenter plus en détails le processus de sélection des attributs à la section 3.3.
2. Chaque cas (JavaCase) est ajouté dans une base de cas.
1. JavaParser (https://code.google.com/p/javaparser/) est un projet tiers qui permet l’analyse de fi-chiers Java. Il est écrit entièrement en Java et s’utilise comme n’importe quelle bibliothèque (JAR).
Package Nom de classe
Méthode appelle
Nom de méthode
Paramètre
Figure 3.3: Les attributs d’un fichier Java.
3. Le cas représentant le problème est construit.
À ce moment, nous avons une base de cas complète contenant différents cas connus. Chaque cas a été construit en analysant les fichiers Java (étapes 1 et 2).
Il reste maintenant à analyser le problème soumis. En fait, le problème est un fichier Java lui aussi, donc nous utiliserons le même processus (étape 1) pour produire un cas (JavaCase). Mais ce dernier ne sera pas ajouté à la base de cas puisqu’il s’agit du problème à comparer.
4. La similarité est calculée en comparant chaque attribut du problème avec tous les cas de la base de cas. La méthode de comparaison est différente pour chaque attribut. Nous présentons les détails à la section 3.4.
5. La similarité globale est calculée entre le problème et chaque cas dans le base de cas.
6. Le cas le plus similaire est trouvé en utilisant la valeur de la similarité globale calculée à l’étape 5.
3.2
Extraction des attributs
Pour extraire les attributs d’une classe, nous utilisons l’outil JavaPaser pour analyser le code Java, repérer ses différentes composantes et éventuellement permettre de générer un AST [jav] ou d’exécuter des fonctions lors de la découverte des éléments. L’analyse est séquentielle et un mécanisme d’avertissement (visiteur) permet de réagir.
Un AST (Abstract syntax tree) représente tous les détails d’un code source comme nous l’avons déjà expliqué à la section2.6.2.
Cependant, dans notre cas, nous n’utilisons pas un AST complet, car notre objectif est de sélectionner uniquement quelques attributs. De plus, les méthodes d’analyse que nous utilisons ne sont pas des analyses de similarité basé sur les arbres (voir sections 2.6.2).
Dans notre cas, nous construisons notre propre structure permettant de représenter les attri-buts nécessaires pour la comparaison. De plus, cette structure nous permet de lier les cas avec les tests qui nous serviront plus tard pour les prochaines étapes du CBR.
Utilisation de JavaPaser JavaParser est une bibliothèque (JAR) utilisable dans beaucoup d’environnements. Cette solution est entièrement écrite en Java et ne requiert aucun environ-nement particulier. Il est indépendant de l’IDE ou de toute autre technologie, et il est simple d’utilisation et de petite taille.
Comme c’est un analyseur syntaxique et non un AST déjà construit, cela nous permet de réagir comme nous le désirons et d’effectuer le traitement particulier pour chaque attribut. Ainsi, nous pouvons construire une représentation adaptée à notre problème et ainsi lier le test, etc.
3.3
Sélection d’attributs
Pour pouvoir calculer la similarité entre deux classes, il est nécessaire de comparer certains attributs (caractéristiques) de ces classes. La choix des attributs à utiliser dépend de la raison pour laquelle nous voulons les comparer. Ainsi, comparer du code pour le réutiliser ou pour générer des tests unitaires, demande différents attributs.
Nous utiliserons certains attributs particuliers comme la signature des méthodes, les variables membres (field ), constructeurs, etc. Chaque attribut aura sa méthode de comparaison (voir section 3.4). Par exemple, pour les méthodes, on va calculer la similarité de sa signature, ses paramètres et son type de retour.
Dans notre cas, nous n’avons pas besoin d’utiliser tous les types de nœuds d’un AST. Nous utilisons un sous-ensemble des types de nœuds d’un AST. Nous avons retenu la combinaison des attributs les plus représentatifs pour calculer la similarité.
Attribut d’un cas Élément de Java trouvé par JavaParser Package PackageDeclaration
Import ImportDeclaration JavaClass ClassOrInterfaceDeclaration
Method MethodDeclaration, ConstructorDeclaration
Field FieldDeclaration
MethodCall MethodCallExpr
Parameter Parameter
Variable VariableDeclaratorId
Table 3.1: Attribut d’une classe et éléments Java associés.
Par chaque élément du code Java trouvé par JavaParser, nous allons les traduire dans notre modèle de représentation (un cas). Le tableau3.1montre la correspondance entre un élément de Java et un attribut de notre modèle qui compose un cas.
3.4
Calcul de la similarité entre les classes
3.4.1 Attribut : import
Import est un attribut pour représenter les dépendances de la classe. C’est un attribut inté-ressant car si deux classes ont les mêmes importations, il y a plus de chance que les classes soient similaires. Plus spécifiquement, les importations invoquant des classes plus spécialisées comme "java.net" sont particulièrement discriminantes. Ces importations donnent une bonne indication de ce qui est utilisé par une classe et, parfois, sur leur responsabilités principales. Ces éléments sont essentiels pour déterminer la similarité entre différentes classes.
En Java, une importation est composée de plusieurs niveaux : « package.souspackage... ». Nous avons trois options pour comparer une importation :
1. Comparer l’importation complète comme une chaîne de caractères sans séparer les ni-veaux ;
2. Séparer les éléments de l’importation par « package », comparer chaque niveau et calculer la similarité totale ;
3. Séparer la partie « package » de la classe importée.
Nous allons présenter les avantages et les inconvénients pour ces trois approches.
Comparer l’importation complète La première façon de faire permet d’obtenir un plus petit nombre de résultats. Par contre, comme les premiers niveaux représentent la provenance (java.util vs ca.ulaval), il est possible que le même concept soit rejeté parce qu’ils n’avaient pas le même préfixe.
Par exemple, si deux développeurs veulent appeler la méthode « getValue() » dans la classe « Attribute » et qu’ils utilisent différents frameworks. Le premier utilise « myCBR » et donc
![Figure 2.2: Annotation JML pour préconditions et postconditions [Ori05].](https://thumb-eu.123doks.com/thumbv2/123doknet/7306160.209558/25.918.271.706.102.306/figure-annotation-jml-préconditions-postconditions-ori.webp)

![Figure 2.6: Processus du CBR [Wik12b].](https://thumb-eu.123doks.com/thumbv2/123doknet/7306160.209558/31.918.327.630.115.367/figure-processus-du-cbr-wik-b.webp)

![Figure 2.10: Exemple avec le PDG [aja].](https://thumb-eu.123doks.com/thumbv2/123doknet/7306160.209558/38.918.264.614.412.713/figure-exemple-avec-le-pdg-aja.webp)
![Figure 2.11: Exemple de code source d’un graphique d’appels déduit après deux itérations avec la technique de Chilowicz et al [CDR09].](https://thumb-eu.123doks.com/thumbv2/123doknet/7306160.209558/40.918.181.707.107.543/figure-exemple-source-graphique-déduit-itérations-technique-chilowicz.webp)