Towards Improving the Reliability of Live Migration Operations in Openstack Clouds
84
0
0
Texte intégral
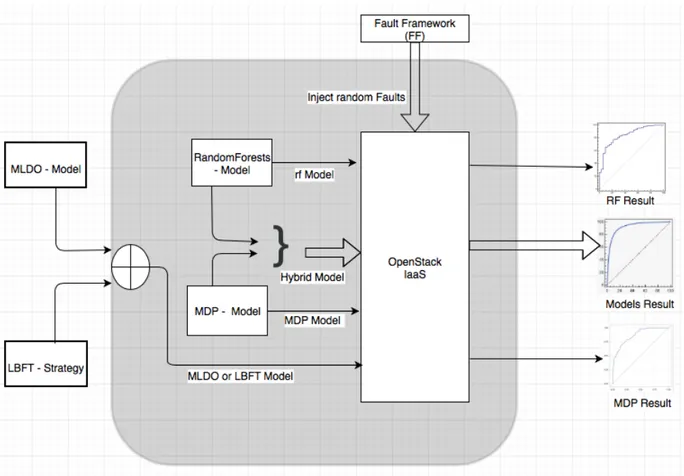
Figure




+7

Documents relatifs
