Modeling 1D distributed-memory dense kernels for an asynchronous multifrontal sparse solver
15
0
0
Texte intégral
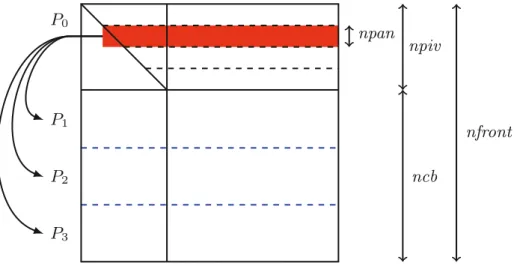
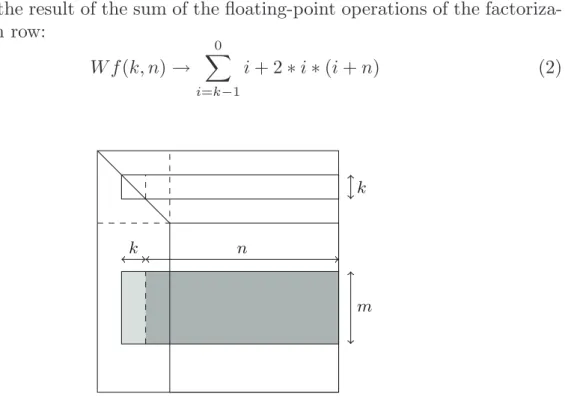
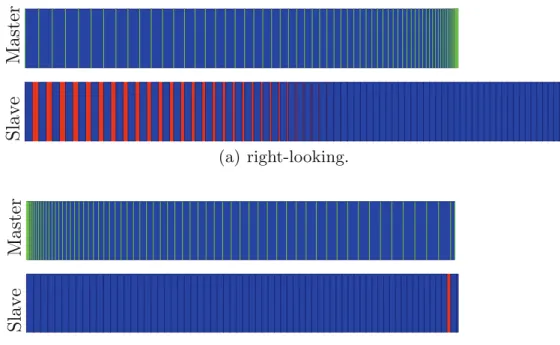
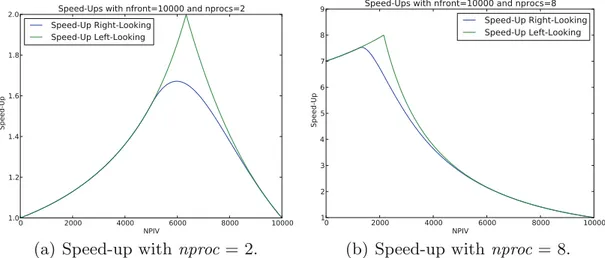
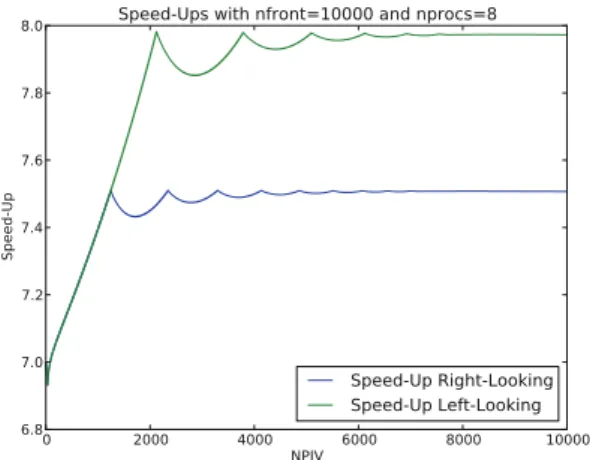
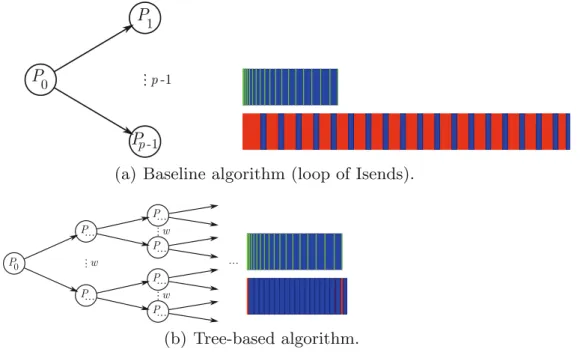
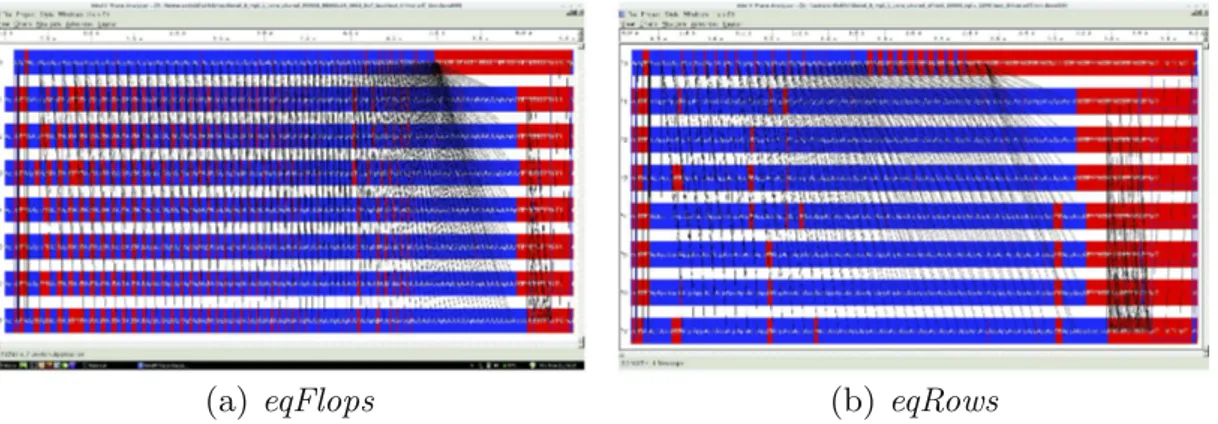
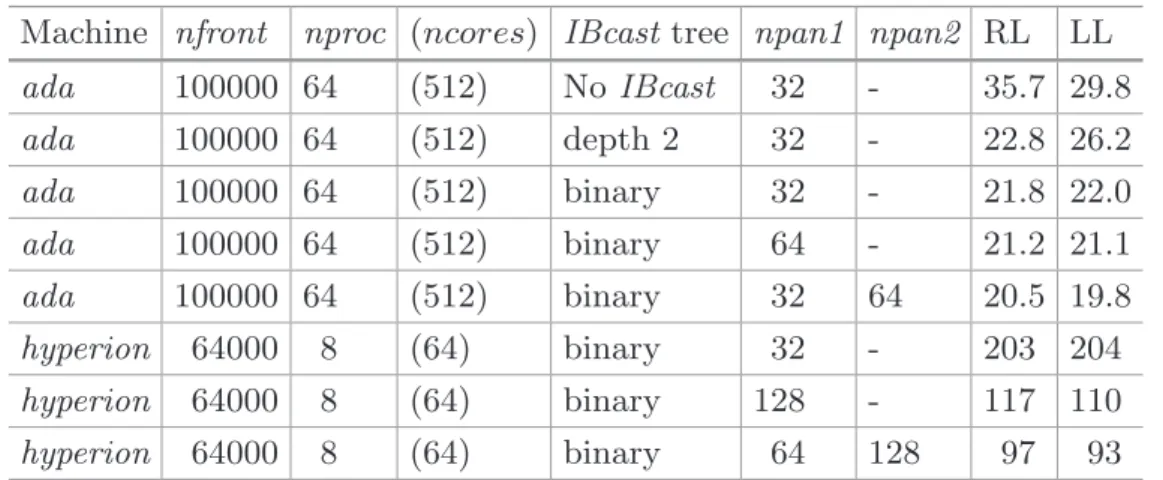
Figure
+5
Documents relatifs
