Débogage à large échelle sur des systèmes hétérogènes parallèles
100
0
0
Texte intégral
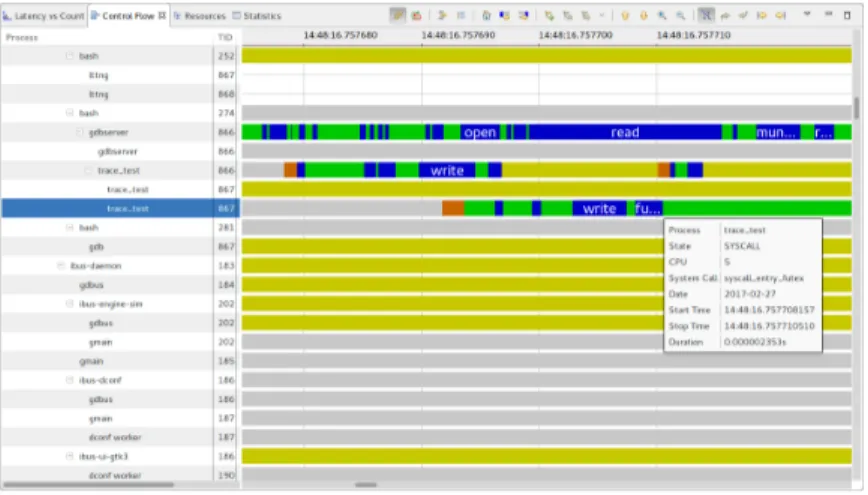
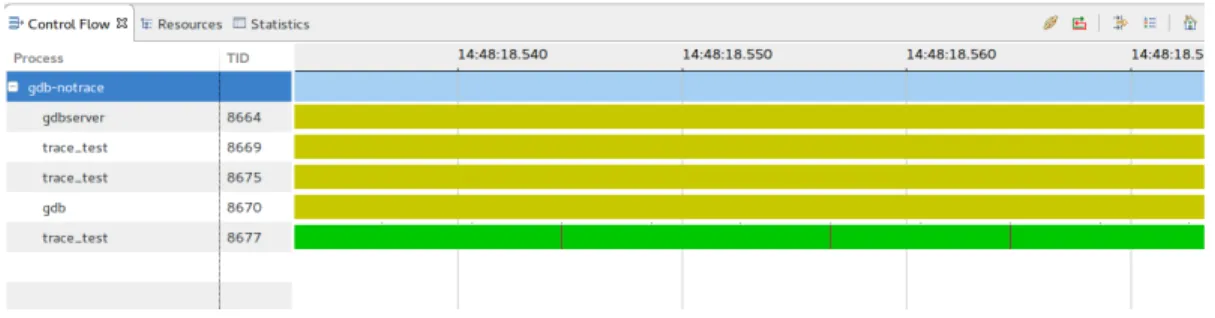
Figure
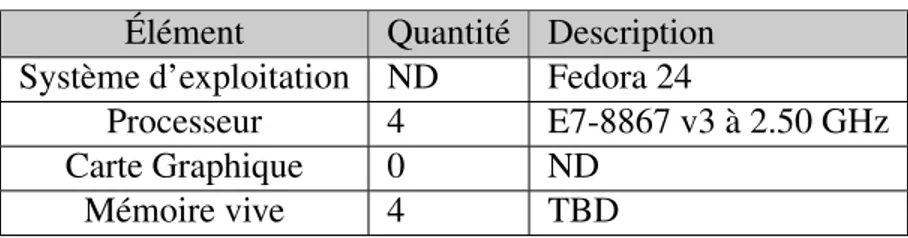
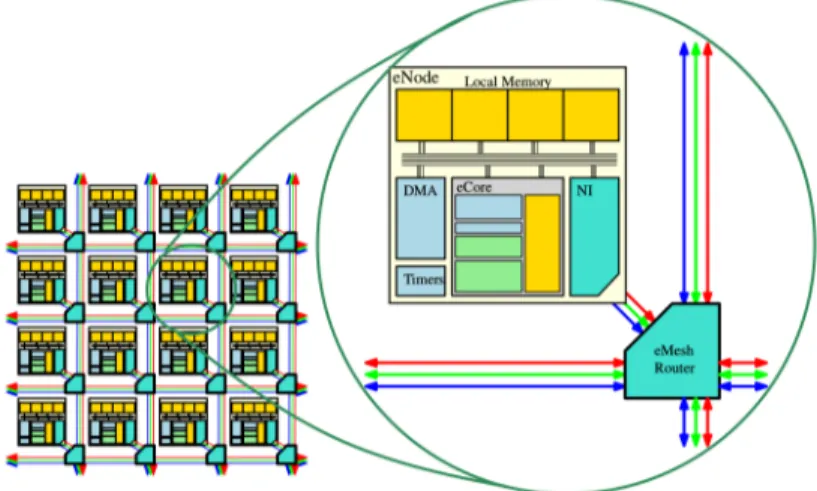
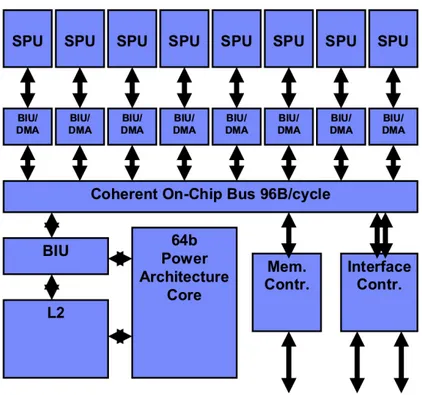
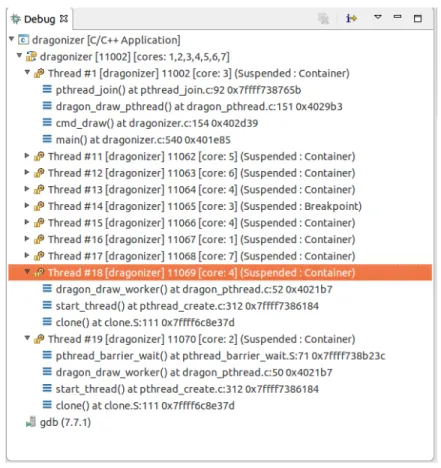
+7
Documents relatifs