From Encrypted Video Traces to Viewport Classification
Texte intégral
Figure

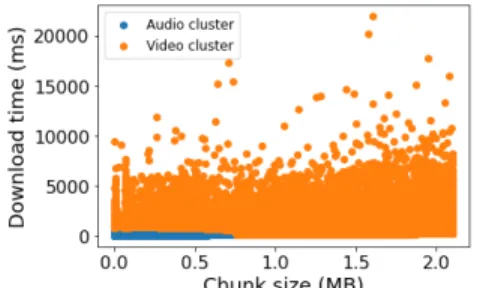
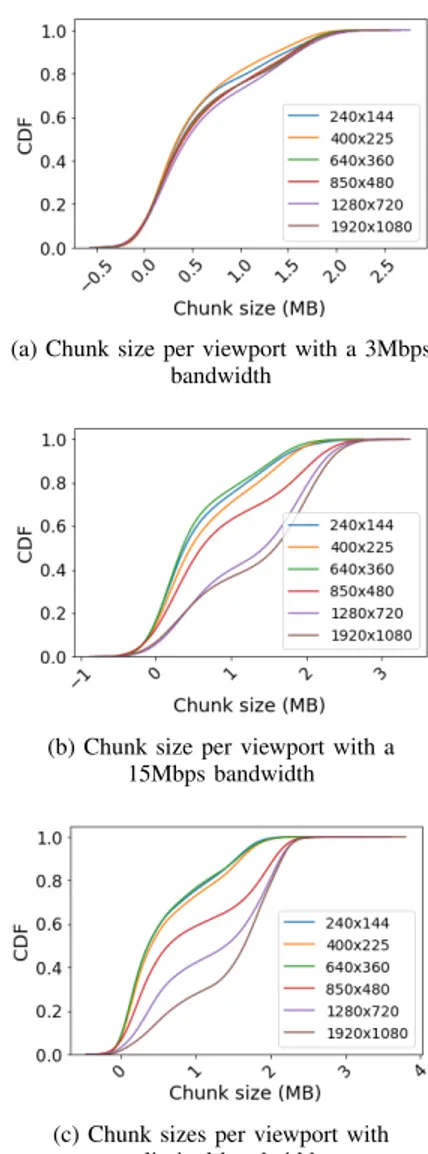
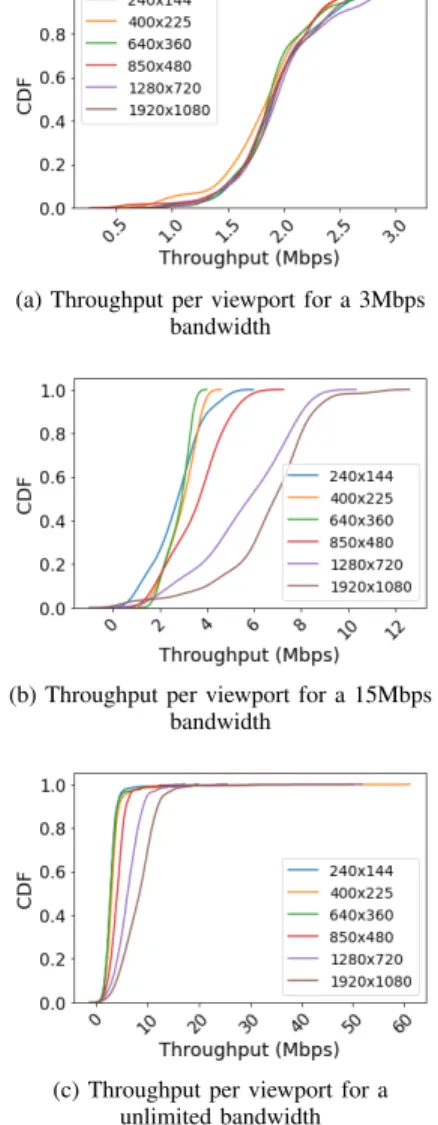


Documents relatifs
1 - Fine-grained, real-time operation: ViCrypt estimates the most important KQIs, i.e., initial delay, stalling, and visual quality, as well as the video bitrate in real time during
We propose two statistical classifiers for encrypted Internet traffic based on Kullback Leibler divergence and Euclidean distance, which are computed using the flow and packet
Table 1 reports the RUMSI inference performance attained by seven different ML models, most of them based on decision trees, for smartphone and tablet devices.. These models
We also showed that features tracking the characteristics of a video session since the start of the streaming are the most relevant ones in terms of prediction accuracy, and that
▪ Evaluation of full feature set update time (done at every new incoming packet) and prediction time (done for every 1s slot), using an upper bound with all
Through empirical evaluations over a large video dataset, we demonstrate that it is possible to accurately predict the specific video resolution, as well as the average video
In order to collect reporting traces, we developed a reporting tool, which can help learners to record information during the learning activities and assist them in reflecting
The proposed state estimation method can then be used in a coding-decoding process of a secret message transmission using the message-modulated chaotic system states and the
