Distributed Newton-type algorithms for network resource allocation
101
0
0
Texte intégral
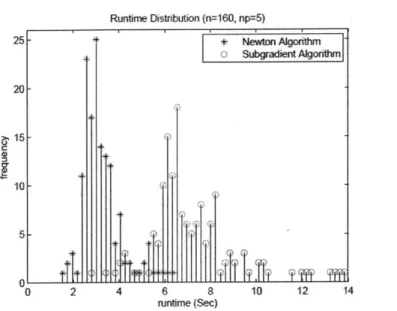
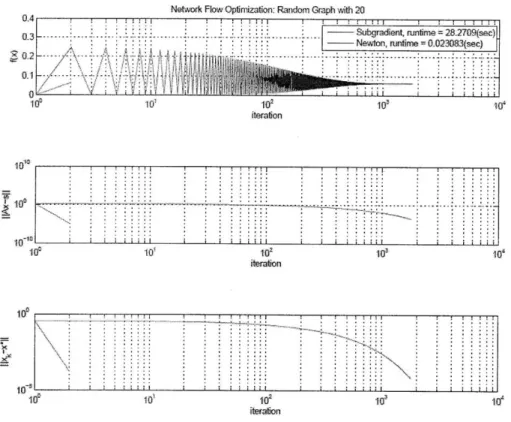
Figure
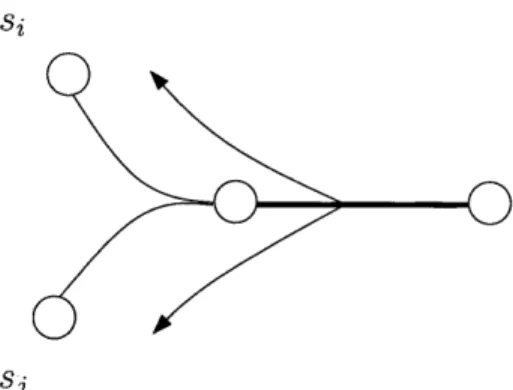
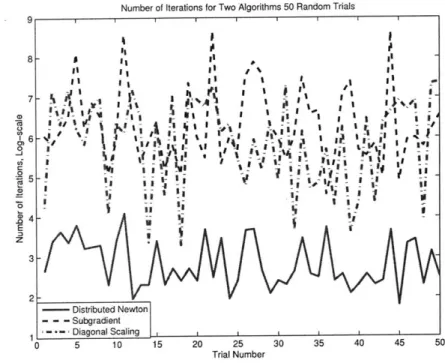
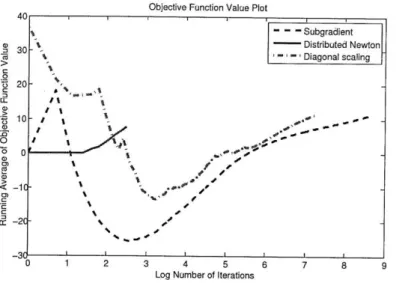
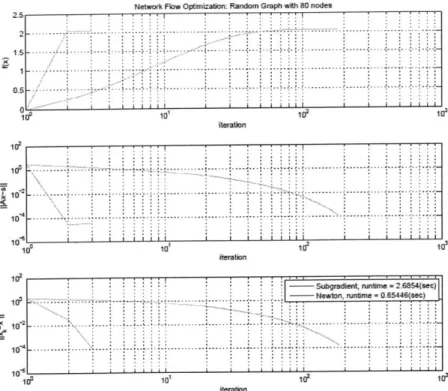
+3
Documents relatifs
