HAL Id: tel-03206946
https://tel.archives-ouvertes.fr/tel-03206946
Submitted on 23 Apr 2021HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Contributions à la sélection des attributs de signaux non
stationnaires pour la classification
Nicole Challita
To cite this version:
Nicole Challita. Contributions à la sélection des attributs de signaux non stationnaires pour la clas-sification. Traitement du signal et de l’image [eess.SP]. Université de Technologie de Troyes, 2018. Français. �NNT : 2018TROY0012�. �tel-03206946�
THESE
pour l’obtention du grade de
D
OCTEUR
de l’U
NIVERSITE
DE
T
ECHNOLOGIE DE
T
ROYES
Spécialité : OPTIMISATION ET SURETE DES SYSTEMES
présentée et soutenue par
Nicole CHALLITA
le 28 avril 2018
Contributions à la sélection des attributs de signaux
non stationnaires pour la classification
JURY
Mme C. MARQUE PROFESSEUR DES UNIVERSITES Rapporteure et Présidente M. P. BEAUSEROY PROFESSEUR DES UNIVERSITES Directeur de thèse
M. M. O. DIAB ASSOCIATE PROFESSOR Rapporteur
M. C. FRANCIS PROFESSEUR Examinateur
2
Remerciements
Je tiens tout d’abord à remercier mes directeurs de thèse, Monsieur Pierre Beauseroy, professeur à l'université de technologie de Troyes, et Monsieur Mohamad Khalil, professeur à l'université libanaise, pour leur patience, leurs précieux conseils et leur encouragement continuel durant toute la période d’encadrement.
Je tiens à exprimer mes sincères remerciements à Madame Catherine Marque, professeur à l'université de technologie de Compiègne, et Monsieur Mohamad Diab, professeur à l'université Rafik Hariri, pour avoir accepté de rapporter mon travail.
J’exprime mes profonds remerciements à Monsieur Clovis Francis, professeur à l'université libanaise, pour avoir accepté de participer au jury en tant qu'examinateur.
Mes remerciements s’adressent finalement à ma famille pour leur patience et leur encouragement infaillible durant toutes les années de mes études.
Enfin et surtout, je remercie mon mari pour son encouragement et son soutien. Il a toujours été disponible et compréhensif. Je le remercie aussi pour son écoute et surtout son amour qui m'a été essentiel durant ces dernières années. Mes remerciements ne seraient pas complets sans y avoir associé ma fille Chloé que je remercie du fond du cœur pour m’avoir motivé à surmonter les difficultés et à travailler dur.
4
Résumé
Pour surveiller le fonctionnement d’un système, le nombre de mesures et d’attributs peut désormais être très grand. Mais il est souhaitable de réduire la dimension du problème en ne conservant que les attributs discriminants pour l’apprentissage de la règle de surveillance et pour réduire le volume de traitement. Il s’agit donc de choisir un sous-ensemble d'attributs pour obtenir les meilleures performances de classification possible. Ce manuscrit présente différentes méthodes de sélection d'attributs existantes et en propose deux nouvelles. La première nommée "EN-ReliefF" est une combinaison d’une méthode séquentielle sous-optimale ReliefF et d’une approche basée sur une régression pondérée : Elastic Net. La seconde s’inspire des réseaux de neurones. Elle est formulée comme un problème d’optimisation permettant de définir simultanément une régression non linéaire qui s’adapte aux données d’apprentissage et une pondération parcimonieuse des attributs. Les poids sont ensuite utilisés pour sélectionner les attributs pertinents. Les deux méthodes sont testées sur des données de synthèse et sur des données issues de machines tournantes. Les résultats expérimentaux montrent l’efficacité des deux méthodes. Les caractéristiques remarquables sont la stabilité de la sélection et la capacité à gérer des attributs linéairement corrélés pour "EN-ReliefF" et la sensibilité et la capacité à gérer des dépendances non linéaires pour la seconde.
5
Abstract
To monitor the functioning of a system, the number of measurements and attributes can now be very large. But it is desirable to reduce the size of the problem by keeping only the discriminating features to learn the monitoring rule and to reduce the processing demand. The problem is therefore to select a subset of attributes to obtain the best possible classification performance. This thesis dissertation presents different existing methods for feature selection and proposes two new ones. The first one, named "EN-ReliefF", is a combination of a sequential ReliefF method and a weighted regression approach: Elastic Net. The second one is inspired by neural networks. It is formulated as an optimization problem allowing defining at the same time a non-linear regression that adapts to the learning data and a parsimonious weighting of the features. The weights are then used to select the relevant features. Both methods are tested on synthesis data and data from rotating machines. Experimental results show the effectiveness of both methods. Remarkable characteristics are the stability of selection and ability to manage linearly correlated attributes for "EN-ReliefF" and the sensitivity and ability to manage non-linear dependencies for the second method.
6
Table des matières
Introduction ... 13
Chapitre 1: Sélection d'attributs pour la réduction de dimension ... 17
1.1 Introduction ... 17
1.2 Réduction de dimension ... 17
1.3 La sélection d'attributs ... 19
1.4 La formalisation du problème ... 20
1.5 Processus de sélection d'attributs ... 21
1.5.1 Les procédures de recherches ... 22
1.5.2 Les procédures d'évaluation ... 23
1.5.3 Les critères d'arrêt ... 26
1.6 Conclusion ... 27
Chapitre 2: Etat de l'art ... 28
2.1 Introduction ... 28
2.2 Les méthodes séquentielles ... 28
2.2.1 La méthode "Sequential Forward Selection"(SFS) ... 29
2.2.2 La méthode "Sequential Backward Selection"(SBS) ... 30
2.2.3 La méthode "Sequential Floating Forward Selection"(SFFS) ... 30
2.2.4 La méthode "Sequential Floating Backward Selection"(SFBS) ... 31
2.2.5 La méthode "plus L minus R selection "(LRS) ... 31
2.2.6 La méthode "Bidirectional search "(BDS) ... 33
2.3 La méthode Relief et son extension Relief-F ... 34
2.4 Branch and Bound ... 34
2.4.1 Description de l'algorithme Branch and Bound ... 34
2.4.2 Avantages de l’algorithme Branch and Bound ... 36
2.4.3 Inconvénients de l’algorithme Branch and Bound ... 37
2.4.4 Améliorations de l’algorithme BB ... 38
2.4.5 Look-ahead Search Strategy for Suboptimal Solutions ... 39
7
2.6 LASSO et Elastic Net ... 44
2.7 Les critères de sélection de paramètres ... 44
2.7.1 La sélection d'attributs à base de corrélation ... 44
2.7.2 Le rapport BW (Between-Within) ... 47
2.7.3 La distance Kullback–Leibler ... 49
2.8 Conclusion ... 50
Chapitre 3: Signaux et caractérisations ... 52
3.1 Introduction ... 52
3.2 Les signaux aléatoires ... 52
3.2.1 Définition... 52
3.2.2 Exemples de signaux aléatoires ... 52
3.2.3 Les signaux stationnaires ... 54
3.3 Attributs ... 55
3.3.1 Les caractéristiques temporelles ... 55
3.3.2 Les caractéristiques fréquentielles ... 56
3.4 Signaux utilisés dans la partie expérimentale ... 60
3.4.1 Génération des signaux simulés SIM1 ... 60
3.4.2 Génération des signaux simulés SIM2 ... 61
3.4.3 Les signaux réels utilisés ... 62
3.5 Conclusion ... 63
Chapitre 4: EN-ReliefF nouvelle méthode de sélection d'attributs ... 64
4.1 Introduction ... 64
4.2 LASSO et Elastic Net ... 64
4.2.1 Méthodes pré-LASSO ... 64
4.2.2 Définition du LASSO ... 65
4.2.3 Résolution du problème LASSO ... 65
4.2.4 Vers l’algorithme LARS (Least Angle Regression) ... 67
4.2.5 Algorithme LARS-LASSO ... 67
4.2.6 Group LASSO ... 68
4.2.7 Elastic Net ... 69
4.3 Relief et Relief-F ... 70
8
4.3.2 La méthode relief-F ... 72
4.4 Proposition d'une nouvelle technique de sélection d'attributs ... 73
4.5 Principe de la technique de sélection d'attributs proposée EN-ReliefF ... 73
4.6 Analyse et simulations ... 75
4.6.1 Application du LASSO ... 75
4.6.2 Application de relief-F ... 81
4.6.3 Application de la technique proposée EN-ReliefF ... 82
4.6.4 Etude de performance et analyse des résultats de la méthode proposée ... 84
4.7 Conclusion ... 93
Chapitre 5: Nouvelle méthode de sélection d'attributs basée sur les réseaux de neurones et sur l'apprentissage automatique ... 94
5.1 Introduction ... 94
5.2 Réseaux de neurones et machine learning ... 94
5.3 La méthode proposée ... 97
5.4 Résultats et expériences ... 102
5.4.1 Description ... 102
5.4.2 Choix de λ ... 103
5.4.3 Choix de C ... 105
5.4.4 Performance de la méthode proposée ... 107
5.4.5 Performance de la méthode proposée sur des signaux simulés en utilisant des filtres butterworth ... 108
5.4.6 Etude de stabilité de la méthode proposée sur des signaux simulés en utilisant des filtres butterworth ... 111
5.4.7 Influence du nombre de neurones sur la performance de la méthode proposée sur des signaux simulés en utilisant des filtres butterworth ... 112
5.4.8 Comparaison des deux méthodes proposées ... 113
5.5 Conclusion ... 114
Conclusion générale et perspectives ... 115
Références ... 117
Liste des publications ... 124
10
Liste des figures
Figure 1.1 La technique d'extraction d'attributs. ... 18
Figure 1.2 La technique de sélection d'attributs. ... 19
Figure 1.3 Définition de sélection d'attributs. ... 19
Figure 1.4 Processus de sélection des attributs. ... 22
Figure 1.5 Sélection d'attributs à base de filtre. ... 24
Figure 1.6 Sélection d'attributs à base Wrapper. ... 25
Figure 1.7 Sélection d'attributs à base Embedded. ... 25
Figure 2.1 L'arbre solution de l'algorithme BB lorsque m=2 et p=5. ... 36
Figure 2.2 Exemple de l'avantage de l'algorithme BB. ... 37
Figure 2.3 L'algorithme CFS en conjonction avec un système d'apprentissage. ... 46
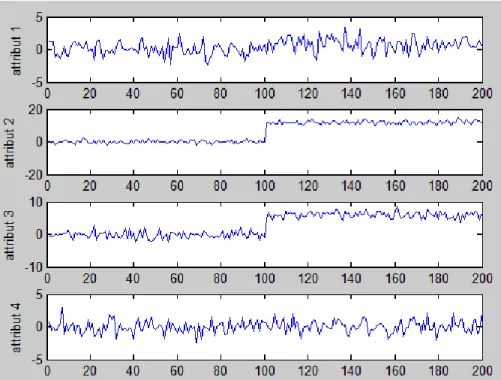
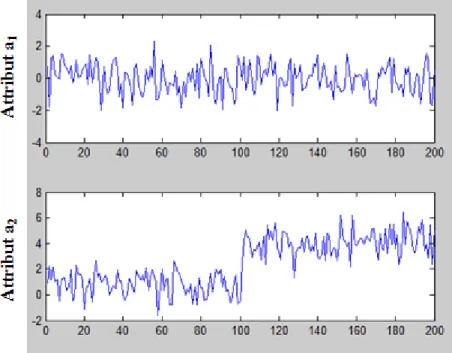
Figure 2.4 Attributs a1, a2, a3 et a4 sur les deux classes. ... 48
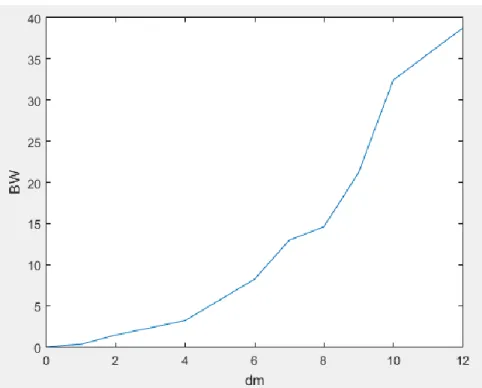
Figure 2.5 Le rapport BW en fonction de dm. ... 49
Figure 3.1 Signal de vibrations d’engrenages. ... 52
Figure 3.2 Signal réel acoustique: réponse d’une salle à un bruit impulsionnel. ... 53
Figure 3.3 Signal biomédical (EEG). ... 53
Figure 3.4 Signal non aléatoire: modulation d’amplitude. ... 53
Figure 3.5 Signal stationnaire. ... 54
Figure 3.6 Signal non stationnaire. ... 54
Figure 3.7 Exemple de fréquence pic... 57
Figure 3.8 Exemple d'énergies relatives par bandes de fréquences. ... 58
Figure 3.9 Exemple de percentiles. ... 59
Figure 3.13 Distance δ entre les fréquences centrales des deux classes. ... 60
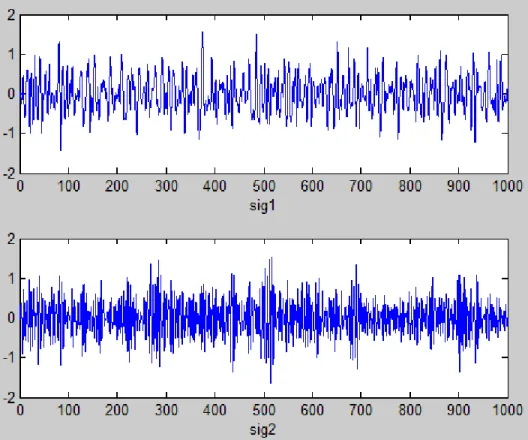
Figure 3.14 Sig1 et Sig2. ... 61
Figure 3.15 Le banc d'essai. ... 62
Figure 4.1 Attribut a1 et attribut a2 sur les deux classes. ... 76
Figure 4.2 Elastic Net (a2 et a4)( a3 et a5) corrélés ... 76
Figure 4.3 : 𝚫𝛌𝐦𝐧 suivant Elastic Net pour (a2 et a4)( a3 et a5) corrélés. ... 77
Figure 4.4 Elastic net (a2 et a4)(a3, a5 et a8) corrélés ... 78
Figure 4.5 Δλmn suivant Elastic Net pour (a2 et a4)( a3,a5 et a8) corrélés. ... 78
Figure 4.6 Elastic Net sur 100 signaux de 2 classes et 7 attributs... 79
Figure 4.7 𝚫𝛌𝐦𝐧 suivant Elastic Net (MPF, fmed et 5*MPF corrélés). ... 80
Figure 4.8 Elastic net sur 100 signaux de 2 classes et 6 attributs. ... 80
Figure 4.9 𝚫𝛌𝐦𝐧 suivant Elastic Net (MPF et fmed corrélés). ... 81
Figure 4.10 Les attributs a1, a2, a3 et a4 sur les deux classes. ... 85
Figure 4.11 Erreur en fonction de ρ. ... 85
Figure 4.12 les six attributs parmi les deux classes (classe1:1...50, classe2:51...100) pour δ=0.3 ... 89
Figure 4.13 Erreur de classification après sélection par EN-ReliefF en fonction de δ(distance entre les classes). ... 90
11
Figure 4.14 Erreur de classification sans sélection en fonction de δ (distance entre les classes). ... 91
Figure 5.1 Modèle d'un neurone [82]. ... 95
Figure 5.2 Fonction sigmoïde. ... 96
Figure 5.3 Fonction tangente hyperbolique. ... 96
Figure 5.4 Fonction de Heaviside. ... 96
Figure 5.5 Structure d'un réseau de neurones. ... 97
Figure 5.6 Modèle de réseau de neurones utilisée dans la méthode proposée. ... 99
Figure 5.7 Les attributs importants 1 et 2 dans ℝ𝟐. ... 102
Figure 5.8 Les attributs non importants 3 et 4 dans ℝ𝟐. ... 103
Figure 5.9 dif en fonction de λ. ... 104
Figure 5.10 Les poids affectés aux différents attributs en fonction de λ. ... 105
Figure 5.11 Les poids affectés aux différents attributs en fonction de C. ... 106
Figure 5.12 Nombre d'attributs choisis en fonction de C. ... 107
Figure 5.13 Le poids final pour chaque attribut en utilisant la nouvelle méthode de sélection des attributs avec λ=10 et C=10. ... 108
12
Liste des tableaux
Tableau 1.1 Avantages et inconvénients des méthodes filtres, wrapper et embedded ... 26
Tableau 4.1: Trois exemples d'application de Relief-F. ... 82
Tableau 4.2 Différentes expériences d'application de la méthode proposée EN-ReliefF. ... 82
Tableau 4.3: Matrice de confusion en moyenne sans sélection des attributs. ... 86
Tableau 4.4: Matrice de confusion en moyenne après sélection des attributs (EN-ReliefF, knn et k=10). 87 Tableau 4.5: Comparaison de l'erreur de classification en utilisant deux classifieurs différents. ... 87
Tableau 4.6: Nombre de fois où chaque attribut est choisi (50 essais). ... 88
Tableau 4.7: Nombre de fois parmi 50 essais chaque attribut est choisi en fonction de dm. ... 92
Tableau 5.1: Le poids final pour chaque attribut avec λ=10 et C=10 (signaux butterworth)(Ca choisi) .. 109
Tableau 5.2: Le poids final pour chaque attribut avec λ=0.5 et C=0.5 (signaux butterworth)(Ca choisi) 109 Tableau 5.3: Deuxième exemple du poids final pour chaque attribut avec λ=10 et C=10 (MPF choisi) . 110 Tableau 5.4: Deuxième exemple du poids final pour chaque attribut avec λ=0.5 et C=0.5 (MPF choisi) 110 Tableau 5.5: Poids moyen pour chaque attribut (Ca choisi, sélection répétée 500 fois )... 111
Tableau 5.6: Poids moyen pour chaque attribut (MPF choisi, sélection répétée 500 fois ) ... 112
13
Introduction
Une des formes les plus avancées de la maintenance industrielle est la maintenance prévisionnelle. En effet, l’analyse présente du comportement d’un matériel aide à prévoir son comportement futur. L’analyse sert aussi à prédire la nature de la défaillance et à minimiser le retard à la détection de la panne [1] [2].
Le diagnostic des défauts dans une machine tournante constitue un bon exemple de ce type de problème et un sujet important sur le plan pratique. Dans le but d'augmenter la productivité et la fiabilité de ces matériels, le choix des attributs qui seront utilisés pour la classification et le diagnostic constitue un défi important qui est au cœur de ce mémoire. L'ensemble des attributs calculés est immense et l'utilisation de tous les attributs va induire un coût de calcul très important et peut conduire à dégrader les performances d'une règle de classification apprise à cause de l'existence des attributs redondants et non significatifs [3].
L'objectif de cette thèse est de traiter des algorithmes qui tentent de sélectionner les meilleurs attributs existants pris dans un ensemble pour ensuite construire une règle de classification-identification en utilisant les attributs sélectionnés. Dans ce but, la première étape consiste à identifier les différentes méthodes de sélection des attributs puis à trouver de nouvelles méthodes en s'inspirant des celles existantes. La dernière étape consiste à étudier les performances des méthodes proposées.
Il existe deux approches générales pour la réduction de la dimension.
L'extraction des attributs qui permet de transformer les attributs existants dans un espace de dimension inférieure [4] [5].
La sélection des attributs qui permet la sélection d'un sous-ensemble d'attributs existants sans transformation [4] [5].
Comme déjà mentionné, la sélection des attributs est une étape de traitement qui permet de trouver les attributs pertinents, les plus intéressants et les plus importants afin de résoudre un problème donné.
14
L'objectif ultime de la sélection des attributs est de réduire la quantité de données en minimisant le nombre des attributs utilisés. Ainsi elle présente divers avantages : elle facilite l'acquisition des données, leur gestion et elle réduit le temps d'apprentissage. D'autre part, elle permet de mieux comprendre les résultats obtenus par un système basé sur les attributs choisis en pointant le lien entre le sous-ensemble d'attributs et le résultat attendu.
Les algorithmes de sélection des attributs sont divisés généralement en trois catégories :"filter", "wrapper" et "embedded" [5].
Dans cette thèse, notre but est de présenter en détails la nécessité et l'importance de la sélection des attributs et les différentes étapes du processus de sélection. Nous présentons différents algorithmes de sélection des attributs existants dans la littérature tout en exposant leurs principaux avantages et inconvénients.
Dans la littérature, de nombreux algorithmes de sélection de sous-ensembles d'attributs ont été proposé au cours des dernières décennies [6] [7] [8] [9] [10] [11] [12] [13] [14]. Par exemple, mais sans s'y limiter, des méthodes séquentielles ont été proposées (SFS, SBS, SFFS, SFBS, BDS, LRS ...) depuis 1963. Relief (et son extension Relief-F) est une des méthodes les plus connues pour la sélection des attributs. Elle a été proposé en 1992 par Kira et Rendell [7]. C'est une méthode statistique basée sur le calcul de scores associé à l'importance des attributs. Plus récemment, LASSO (Least Absolute Shrinkage and Selection Operator), introduit par Tibshirani en 1996, est une méthode permettant de sélectionner des variables en déterminant la solution d'un problème d'optimisation [15]. Elastic Net (EN) est une variante de LASSO qui ajoute à ce dernier un effet de regroupement. Il y a encore de nombreuses méthodes de sélection existantes dans la littérature... Et jusqu'à aujourd'hui, les chercheurs travaillent pour trouver de nouveaux algorithmes de sélection d'attributs.
Les réseaux de neurones artificiels sont des modèles de calcul qui s'inspirent schématiquement du fonctionnement des neurones biologiques [16]. Ils sont utilisés dans différents domaines comme la classification, la reconnaissance des formes... L'optimisation de leur performance en pondérant les attributs peut aussi être une approche envisageable pour la sélection d'attributs.
15
Nous proposons deux nouvelles méthodes de sélection des attributs. La première méthode combine des méthodes déjà existantes : Elastic Net (EN) et Relief-F pour bénéficier des avantages de ces deux méthodes et limiter l'effet de leurs inconvénients. La deuxième méthode est basée sur l'idée de réseau de neurones en affectant un poids à chaque attribut afin d'aboutir à une sélection d’attributs. Les performances des deux méthodes proposées seront étudiées pour conclure sur l'efficacité de ces deux algorithmes.
Ce manuscrit est composé de cinq chapitres dont nous présentons une brève description dans les paragraphes suivants :
Chapitre 1, il aborde l'importance de la réduction de dimension. Les deux approches permettant cette réduction, l'extraction des attributs et la sélection des attributs, sont bien définies. Puis on présente les différents avantages qu'apporte la procédure de sélection des attributs. Le problème de sélection des attributs est introduit et ses concepts de base sont présentés en détails. Les éléments clés d’un processus de sélection sont définis en détail.
Chapitre 2, il présente l’état de l’art des différentes méthodes de sélection des attributs. Les algorithmes des méthodes de sélection ainsi que leurs avantages et leurs inconvénients sont présentés en détails.
Chapitre 3, il décrit différents attributs qui peuvent être extraits d'un signal et utilisés pour la classification. Les différents types de signaux aléatoires trouvés dans la vie réelle sont aussi présentés. Une description des signaux utilisés dans notre travail expérimental sera présentée.
Chapitre 4, il décrit une nouvelle technique "EN-ReliefF" que nous proposons pour une meilleure sélection des attributs. Des simulations et des expériences sur des signaux de synthèse ainsi que sur des signaux réels sont présentées pour étudier les performances et l'efficacité de la méthode proposée. Une étude de stabilité est ensuite effectuée pour montrer la stabilité de la méthode proposée dans le processus de sélection des attributs.
16
Chapitre 5, il décrit une nouvelle méthode de sélection des attributs que nous proposons en se basant sur les concepts des réseaux de neurones et de l'apprentissage automatique (machine learning). Une étude de la performance de cette méthode sur des données simulées sera ensuite présentée.
Enfin une conclusion générale résume les différents travaux réalisés ainsi que les perspectives qui permettront d’élargir et de poursuivre l’étude menée dans cette thèse.
17
Chapitre 1: Sélection d'attributs pour la réduction de
dimension
1.1 Introduction
Dans de nombreuses applications, un très grand nombre d'attributs peut être défini à partir des données recueillies. Par exemple, plusieurs problèmes en bioinformatique, réseaux de capteurs… traitent un très grand nombre d'attributs et souvent, comparativement, peu d'échantillons. La "malédiction de la dimensionnalité" se définit par le fait qu'à qualité d'estimation identique, le nombre d'exemples nécessaires pour l'apprentissage du classificateur croît exponentiellement avec le nombre de caractéristiques considérées [17]. Pour éviter la « malédiction de la dimensionnalité » et pour réduire le coût de calcul, il est toujours préférable de se limiter à un petit nombre d'attributs discriminants. Le problème qui se pose alors est de choisir le sous-ensemble d'attributs permettant d'obtenir les meilleures performances et la meilleure classification.
Dans ce chapitre, nous présenterons l'importance et la nécessité de la réduction de dimension. Puis nous définissons les deux approches de réduction de dimension : l'extraction et la sélection des attributs. Ensuite, nous détaillerons la sélection des attributs en donnant ses différents avantages. Enfin, nous présenterons en détails le processus général de traitement d'une méthode de sélection d’attributs en identifiant ses différentes étapes.
1.2 Réduction de dimension
De nos jours, le nombre de mesures recueillies dans les systèmes surveillés croît rapidement. Pour cette raison la réduction de dimension fait l'objet de nombreuses recherches afin d'éviter la « malédiction de la dimensionnalité » et de réduire les coûts de stockage et de calcul associés aux traitements de ces données. Ainsi, la réduction de dimension est un domaine de recherche à l'intersection de plusieurs disciplines dont la bioinformatique, la reconnaissance de formes, l'apprentissage automatique, l'intelligence artificielle, l'optimisation...
18
En général, les grandeurs caractéristiques sont déduites des mesures brutes sur la base de l'intuition et de connaissance à priori sur le processus. Il est fréquent que les variables ainsi obtenues ne s’avèrent pas toutes pertinentes pour le processus de classification. Certaines variables peuvent être peu informatives, corrélées et redondantes ou même inutiles et correspondre à du bruit [18]. En plus, lors de l’exploration et de l’analyse des données, plusieurs problèmes liés à la dimension des données peuvent impacter les performances des classificateurs. Pour une taille d'échantillon donnée, il existe une dimension au-delà de laquelle la qualité de l'estimation du classificateur va se dégrader plutôt que s'améliorer [17]. De ce fait, il devient fondamental de traiter préalablement ces données et de réduire autant que possible leur dimension. Une identification efficace des variables pertinentes et discriminantes s’avère indispensable pour réduire la dimension des données et limiter les effets induits. Vue l'importance de ce sujet dans de nombreux domaines beaucoup de travaux de recherche [18], [19], [20], [21], [22] [23] [24] ont été effectués sur ce sujet.
Il existe deux approches générales pour la réduction de dimension: l'extraction d'attributs et la sélection d'attributs [25] [26].
L'extraction d'attributs consiste à déterminer une transformation des variables existantes pour produire des attributs dans un espace de dimension inférieure. Etant donné un espace de variables S ∈ ℝp on veut trouver un espace S
e tel que Se = f(S): ℝp⟶ ℝm avec m < p de façon
qu'idéalement l'espace transformé Se préserve l'information contenue dans l'espace d'origine (Figure 1.1).
La sélection d'attributs, en revanche, consiste à choisir un sous-ensemble d'attributs de l'espace de variables S sans transformation (Figure 1.2).
19
Figure 1.2 La technique de sélection d'attributs.
1.3 La sélection d'attributs
En général, le problème de sélection d'attributs peut être défini comme suit :
Etant donné un espace d'attributs S={xi | i=1…p}, Y la sortie, on veut trouver un sous-ensemble
de ces attributs, qui prédit bien la sortie, soit Sm={xi1, xi2, …, xim}, avec m < p (Figure 1.3). Pour
sélectionner ce sous-ensemble, on cherche en général à formaliser le problème comme un problème consistant à optimiser une fonction objectif (ou critère) J. Ce critère peut, par exemple, être la probabilité d'erreur dans le cas d'un problème de classification [20].
20
Dans ce cas, la sélection des attributs consiste à trouver le sous-ensemble de plus faible dimension qui conduit à une faible erreur de classification [6] [27]. Ce sous espace de dimension réduite sera, par exemple, utilisé ensuite pour l'apprentissage d'une règle de classification.
En conséquence, la sélection des attributs présente les avantages suivants :
1. Elle réduit le nombre des attributs en cherchant à enlever les attributs non pertinents, redondants, non appropriés et bruitées. Conformément à la définition, ce processus sélectionne les attributs en se basant sur certains critères pour éliminer tous les facteurs qui ne sont pas en rapport avec le problème traité, et garder efficacement les attributs importants.
2. La sélection des attributs peut augmenter la précision et améliorer les performances du classificateur. Après l'opération de sélection d'attributs, un grand nombre de données non pertinentes est supprimé. Seuls les attributs les plus importants sont choisis et gardés, ce qui rend le modèle de classification obtenu beaucoup plus simple afin d'améliorer sa capacité de résolution du problème, et sa précision de classification.
3. La sélection d'attributs réduit le temps de calcul. En effet, après la sélection des attributs, la complexité de calcul est réduite, ce qui augmente la vitesse d'exécution de l'algorithme et la vitesse d'apprentissage.
4. Les attributs conservés correspondent aux variables liées aux phénomènes d'intérêt et permettent d'en faire une interprétation plus simple.
1.4 La formalisation du problème
Le problème principal est lié au fait que tous les algorithmes de sélection d'attributs ne sont pas appropriés pour un problème de sélection d'attributs donné [28].
De nombreux algorithmes de sélection d'attributs ont été proposés au cours des dernières décennies. Les références [6], [12] et [13] présentent des études complètes de nombreuses méthodes existantes à partir des années 1970 jusqu'à nos jours. Dans [7] Kira et Rendell ont
21
proposé Relief, un algorithme de sélection des attributs qui utilise une méthode statistique. Dans [9] Tibshirani a proposé LASSO pour faire la sélection des attributs, mais LASSO ne construit pas véritablement de sous-ensembles d'attributs. LASSO optimise un critère associé à un problème de régression et on interprète le résultat comme une sélection d'attributs. Beaucoup d'auteurs dont [8], [10], [11] ont développé l'idée de LASSO et ont proposé des extensions de cet algorithme.
Dans ce contexte, nous sommes intéressés dans cette thèse par des algorithmes qui tendent à sélectionner les meilleurs attributs pour arriver à la classification en utilisant les attributs sélectionnés. Dans ce but, la première étape consiste à donner un aperçu des différentes méthodes de sélection d'attributs de la littérature puis à proposer de nouvelles méthodes s'inspirant de celles existantes. La deuxième étape consiste à étudier les performances des méthodes proposées.
1.5 Processus de sélection d'attributs
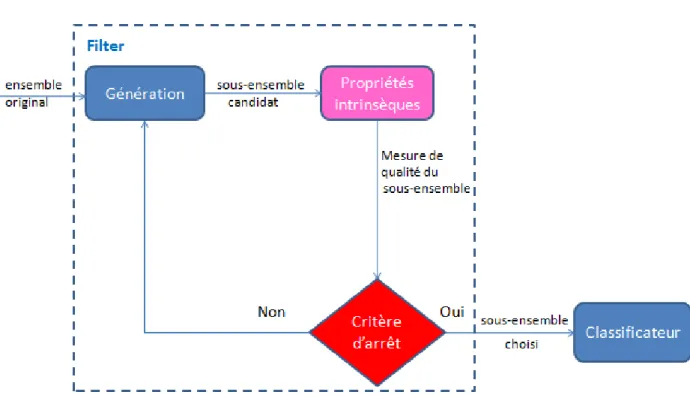
Une procédure générale [6] [29] pour élaborer une méthode de sélection d'attributs est illustrée par la Figure 1.4. On distingue 4 étapes pour la sélection des attributs en commençant par l'ensemble initial des attributs : la génération du sous-ensemble, l'évaluation du sous-ensemble, le critère d'arrêt, et la validation des résultats.
La génération du sous-ensemble est une stratégie de recherche utilisée pour déterminer des sous-ensembles d’attributs candidats pour l'évaluation.
L'évaluation du sous-ensemble : un certain critère d'évaluation est estimé pour mesurer la qualité du ensemble candidat. Ensuite il est comparé [30] avec le meilleur sous-ensemble précédent pour déterminer si ce sous-sous-ensemble est convenable ou non. Si le nouveau sous-ensemble candidat est meilleur, il remplace le précédent meilleur. En répétant ce processus le sous-ensemble associé à la meilleure valeur du critère est sélectionné.
Critère d'arrêt: il est nécessaire que chaque sous-ensemble d'attributs après l'évaluation soit comparé au critère d'arrêt pour vérifier si les attributs du sous-ensemble actuel ont atteint
22
un niveau prédéfini [31]. Si les exigences sont vérifiées, la sélection d'attributs s'arrête et le sous-ensemble courant est considéré comme le résultat final; sinon le processus de recherche continue.
La validation: le sous-ensemble choisi doit généralement être validé par différents tests avec des données du monde réel ou non réel [32].
Figure 1.4 Processus de sélection des attributs.
1.5.1 Les procédures de recherches
En général, les stratégies de recherche pour la génération des sous-ensembles dans le processus de sélection des attributs peuvent être classées en trois catégories : exhaustive, heuristique et aléatoire [32].
a) Génération exhaustive ou complète :
Dans cette approche, on examine tous les sous-ensembles d'attributs possibles afin de sélectionner le "meilleur" sous-ensemble d'attributs. Dans ce cas il est garanti de trouver le sous-ensemble optimal. Mais cette méthode nécessite trop de calcul et de temps. Le problème essentiel de cette approche est que le nombre de combinaisons croit exponentiellement avec le nombre des attributs (2p sous-ensembles possibles si p est le nombre d'attributs).
23
Dans cette approche, la sélection est dirigée par certaines règles. Les algorithmes qui utilisent la recherche heuristique sont généralement des algorithmes itératifs. Les sous-ensembles considérés sont déterminés en fonction des sous-ensembles précédemment examinés. En conséquence, la recherche peut commencer avec un ensemble vide ou complet d'attributs et à chaque itération un ou plusieurs attributs seront ajoutés (i.e., Sequential Forward Selection) ou retirés (i.e., Sequential Backward Selection) ou commencer par les deux extrémités et ajouter et supprimer des attributs simultanément (i.e., Bidirectional Selection). Les algorithmes basés sur la recherche heuristique sont simples et rapides, mais ils peuvent conduire à une solution sous optimale.
c) Génération aléatoire :
Pour la recherche aléatoire il n'existe pas une méthode prédéfinie pour le choix. L'approche de recherche aléatoire consiste à générer aléatoirement les sous-ensembles d'attributs afin de sélectionner le meilleur.
1.5.2 Les procédures d'évaluation
L'évaluation constitue une partie importante de la sélection d'attributs. On peut distinguer trois catégories pour l'évaluation dans les algorithmes de sélection: "filter", "wrapper" et "embedded" [30] [33] [34].
Filter méthods:
Cette technique est généralement utilisée pour la sélection d'attributs. Elle évalue la pertinence des attributs en examinant seulement leurs propriétés intrinsèques. Cette technique est considérée comme une étape de prétraitement (filtrage) avant le processus d'apprentissage, cela signifie que l'évaluation de cette technique est indépendante du classificateur [30] [34]. Dans la majorité des cas, un score de pertinence d'attributs est calculé, et les attributs à faible score sont supprimés [30]. Le meilleur sous-ensemble d'attributs obtenus par cette technique est présenté en entrée de l'algorithme de classification. La procédure du modèle "filter" est illustré par la Figure 1.5.
24
Figure 1.5 Sélection d'attributs à base de filtre.
Wrapper method :
Le principal inconvénient de la technique "filter" provient du fait qu'elle ignore l'influence des attributs sélectionnés sur la performance du classificateur. Dans [35], Kohavi et John proposent la technique wrapper pour résoudre ce problème. Cette technique évalue un sous-ensemble d'attributs en utilisant l’algorithme de classification. Cette technique produit une précision plus élevée puisque les attributs sélectionnés correspondent bien aux algorithmes d'apprentissage. Mais cette méthode présente l'inconvénient d'avoir un coût de calcul plus élevé que dans le cas des méthodes filtres dû à l’appel de l’algorithme de classification pour chaque sous-ensemble considéré. En plus, le sous-ensemble sélectionné dépend de l'algorithme de classification, ainsi si on change l'algorithme de classification, il faut recommencer la sélection ! La procédure du modèle "wrapper" est illustré par la Figure 1.6.
25
Figure 1.6 Sélection d'attributs à base Wrapper.
Embedded method:
Cette technique accomplit la sélection simultanément avec la procédure de classification [18]. Le sous-ensemble optimal d'attributs est déterminé lors de l'apprentissage du classificateur [5]. Tout comme les techniques "wrapper", les techniques "Embedded" sont spécifiques à un algorithme d'apprentissage donné [5]. L’avantage principal de cette technique est qu'elle est plus rapide que la technique "Wrapper" [36]. La procédure du modèle "embedded" est illustré par la Figure 1.7.
26
Dans le chapitre suivant on présente différentes méthodes de sélection d'attributs appartenant aux différentes catégories introduites.
Le Tableau 1.1 présente les avantages et les inconvénients de ces trois approches [30] [37].
Tableau 1.1 Avantages et inconvénients des méthodes filtres, wrapper et embedded
Méthode Avantages Inconvénients
Filter • exécution rapide
• coût de calcul faible • Aucune interaction avec le classificateur
Wrapper • Interaction avec le
classificateur
• Bonne performance de classification
• coût de calcul élevé • exécution lente
Embedded • Interaction avec le
classificateur
• Bonne performance de classification
• coût de calcul élevé mais plus faible que Wrapper.
• exécution lente mais plus rapide que Wrapper.
• pas adapté à tous les types de classificateurs.
1.5.3 Les critères d'arrêt
Certains critères doivent être définis pour arrêter le processus de recherche sur les sous-ensembles d'attributs [30] [34].
Certains critères d'arrêt fréquemment utilisés sont :
• Un seuil est atteint, tel que le nombre minimal d'attributs ou le nombre maximal d'itérations.
• Il n'y a plus d'amélioration de précision, autrement dit, lorsqu'il n'y a pas de possibilité de trouver un sous-ensemble meilleur que le sous-ensemble actuel.
Certains critères d'arrêt couramment utilisés sont basés sur l'ordre d'attributs classés selon un score de pertinence. Ceux qui ont les scores les plus élevés seront sélectionnés et utilisés par un classificateur (méthode "filtre"). Un exemple est la méthode Relief qui sera présentée plus tard.
27
1.6 Conclusion
La sélection d'attributs constitue un problème majeur dans plusieurs domaines. Par conséquent, il a été un sujet d'intérêt pour de nombreux chercheurs. Dans ce chapitre, nous avons présenté l'importance et les avantages de la réduction de dimension tout en exposant les deux approches de réduction de dimension : l'extraction d'attributs et la sélection d'attributs. Après avoir présenté en détails la sélection d'attributs et ses différents avantages, nous avons exposé le processus de sélection d'attributs. Puis nous avons détaillé les différentes étapes de ce processus.
Dans le chapitre suivant, nous proposons un état de l'art en présentant différentes méthodes de sélection d'attributs de la littérature.
28
Chapitre 2: Etat de l'art
2.1 Introduction
La sélection d'attributs est un domaine de recherche actif depuis des décennies [38], qui a fait ses preuves dans la théorie et la pratique. Dans le contexte de la classification, l'objectif principal de la sélection des attributs est de déterminer le sous-ensemble d'attributs de taille minimale tel que la précision de la classification ne diminue pas de façon significative. Contrairement à d'autres procédés de réduction de la dimension comme l'extraction des attributs [39], les méthodes de sélection des attributs ne modifient pas la représentation originale des attributs. Ainsi, elles conservent la sémantique initiale des attributs. La recherche de cette statistique en envisageant tous les sous-ensembles possibles, recherche exhaustive, est la solution optimale de ce problème mais elle est très coûteuse en temps dès que le nombre d'attributs est important. On cherche ainsi la méthode sous optimale la plus efficace et dont le résultat est proche du résultat optimal.
Dans ce chapitre, nous présentons plusieurs méthodes de sélection d'attributs de la littérature. Nous avons choisi de présenter des méthodes fondées sur les différentes techniques de recherche définies dans le chapitre précédent ainsi que différentes techniques d'évaluation. Tout d'abord, on présente les méthodes séquentielles (SFS, SBS, SFFS, SFBS, LRS, BDS). Puis on décrit les méthodes de sélection d'attributs suivants : Relief et son extension Relief-F, Branch and Bound (BB), Information Mutuelle avec regroupement, LASSO et Elastic Net. Ensuite on décrit les critères de sélection d'attributs suivants : Correlation based Feature Selector (CFS), le rapport des dispersions inter et intra classes BW et la distance Kullback-Leibler.
2.2 Les méthodes séquentielles
Les méthodes séquentielles sont basées sur une génération heuristique de sous-ensembles d'attributs.
Les méthodes séquentielles incluent les méthodes suivantes : · "Sequential Forward Selection" SFS
· "Sequential Backward Selection" SBS
29 · "Sequential Floating Backward Sequential" SFBS · "Plus-l Minus-r Selection" LRS
· Recherche bidirectionnelle BDS
Ces méthodes séquentielles sont sous optimales mais elles sont plus rapides que la recherche exhaustive.
2.2.1 La méthode "Sequential Forward Selection"(SFS)
Sequential Forward Selection (SFS) a été proposée par Marill et Green [40]. Le principe de cette méthode consiste à commencer par un sous-ensemble vide et à chaque itération on ajoute l'attribut qui maximise la valeur d'une fonction objectif J. Le processus continue jusqu'à que le critère J n'augmente plus. Algorithme 2.1 présente l'algorithme de cette méthode [41]. Mais cette méthode souffre de l'effet d'emboitement (nesting effect) c.-à-d. un attribut ajouté dans une étape donnée ne peut pas être enlevé lors de l'étape suivante; ceci conduit à une solution non optimale.
Algorithme 2.1
1. Commencer par un ensemble vide S0 = ∅; k = 0;
2. a+ = argmax a+∉S k [J(a+)] 3. Tant que J(Sk∪ {a+}) > J(Sk) a. Mettre à jour Sk+1 = Sk∪ {a+}; k = k + 1
b. Sélectionner le meilleur attribut parmi les attributs non inclus dans Sk : a+ = argmax
a+∉S k
[J(Sk∪ {a+})]
30
2.2.2 La méthode "Sequential Backward Selection"(SBS)
Sequential Backward Selection (SBS) a été proposée par Whitney [42]. SBS fonctionne d'une manière opposée à SFS. On commence tout d'abord par un ensemble qui contient tous les attributs [41] et on enlève à chaque itération le plus mauvais attribut c.-à-d. celui dont l'exclusion maximise la valeur de la fonction objectif J. Le processus continue jusqu'à ce que J diminue. La principale limitation de SBS est son incapacité à réévaluer l'utilité d'un attribut après qu'il ait été écarté.
L'algorithme de SBS est représenté dans l'annexe A (Algorithme A.1).
2.2.3 La méthode "Sequential Floating Forward Selection"(SFFS)
Sequential Floating Forward Selection (SFFS) a été proposée par Pudil et al [12]. Cette méthode limite l'effet d'emboitement (nesting effect) [36] mais ne l'élimine pas totalement.
Cette méthode commence avec un ensemble vide, à chaque étape un sous-ensemble est généré en ajoutant un attribut a+ puis on cherche à éliminer l'attribut a- de S
k jusqu'à ce que J(Sk− {a−})
diminue [43]. Les itérations se poursuivent jusqu'à ce qu' aucun attribut ne puisse être ajouté et ne parvienne à augmenter J(Sk∪ {a+}).
L'algorithme de SFFS est le suivant (Algorithme 2.2) [44]:
Algorithme 2.2
1. Commencer par un ensemble vide S0 = ∅; k = 0; 2. a+ = argmax a+∉S k [J(a+)] 3. Tant que J(Sk∪ {a+}) > 𝐽(Sk) a. Mettre à jour Sk+1 = Sk∪ {a+}; k =k+1 b. a− = argmax a−∈S k [J(Sk− {a−})]
31 c. Tant que J(Sk− {a−}) > J(S k) Mettre à jour Sk+1 = Sk− {a−} ; k = k+1; a− = argmax a−∈S k [J(Sk− {a−})] d. a+ = argmax a+∉S k [J(Sk∪ {a+})] 4. Fin
2.2.4 La méthode "Sequential Floating Backward Selection"(SFBS)
Cette méthode est une adaptation de SBS utilisant une stratégie similaire à SFFS. Elle commence avec un ensemble qui contient tous les attributs. A chaque étape un sous-ensemble est généré en rejetant un attribut a- puis en ajoutant les attributs a+ tant que J(Sk∪ {a+}) augmente [43]. Les itérations se poursuivent jusqu'à ce qu'on ne puisse plus enlever d'attributs parce que J(Sk− {a−})
n'augmente plus.
L'algorithme de SFBS est décrit en détail en annexe A (Algorithme A.2). 2.2.5 La méthode "plus L minus R selection "(LRS)
Cette méthode est une généralisation et une combinaison de deux méthodes SFS et SBS. LRS tente de compenser les faiblesses de SFS et de SBS avec un retour en arrière (backtracking) dans le processus de sélection des attributs [30] [45]. Dans cet algorithme, on utilise deux paramètres L et R, correspondant respectivement au nombre d'attributs à ajouter (L) et à enlever (R) à chaque itération du processus. Si L > R LRS commence par un ensemble vide d'attributs [41] [45] et ajoute répétitivement L attributs l'un après l'autre et supprime R attributs l'un après l'autre. Cette procédure (ajouter L attributs et supprimer R attributs) est répétée, par exemple, pour atteindre un nombre fixé m d'attributs sélectionnés. Si L < R alors LRS commence par un ensemble contenant tous les attributs et d'une manière répétitive, elle supprime R attributs l'un après l'autre et ajoute L
32
attributs l'un après l'autre. Cette procédure (supprimer R attributs et ajouter L attributs) est répétée, par exemple, pour atteindre un nombre fixe m d'attributs sélectionnés.
Son principal inconvénient est l'absence d'une théorie permettant de prévoir les valeurs optimales de L et R [41] et de choisir un critère d'arrêt complètement pertinent.
Algorithme 2.3 présente l'algorithme LRS pour le cas L > R. L'algorithme du cas L < R est décrit en annexe A (Algorithme A.3).
Algorithme 2.3
1. Si L > R
Commencer par un ensemble vide S0= ∅;
k = 0; 2. Tant que |Sk| < 𝑚 Répéter L fois a+ = argmax a+∉S k [J(Sk∪ {a+})] Sk+1 = Sk∪ {a+}; k = k + 1 Répéter R fois a− = argmax a−∈S k [J(Sk− {a−})] Sk+1 = Sk− {a−}; k = k + 1
33 2.2.6 La méthode "Bidirectional search "(BDS)
BDS est une application conjointe de SFS et SBS [20] [30]. Pour assurer que SFS et SBS convergent vers la même solution, BDS respecte les deux conditions suivantes :
L'attribut déjà choisi par SFS ne doit pas être supprimé par SBS
L'attribut supprimé par SBS ne doit pas être sélectionné par SFS.
Si cette procédure se poursuit jusqu'à ce que l'ensemble avant et l'ensemble arrière soient égaux cet ensemble sera le résultat favorisé et BDS converge ainsi à p
2 attributs où p est le nombre total
d'attributs.
Algorithme 2.4 présente l'algorithme BDS. Algorithme 2.4
1. Commencer l'algorithme SFS avec un ensemble vide SF0 = ∅.
2. Commencer l'algorithme SBS avec l'ensemble de tous les attributs SB0 = A 3. Tant que |SFk| <
p 2
a. Sélectionner le meilleur attribut a+ = argmax a+∉ SFk a+∈ SBk [J(SFk∪ {a +})] ; SFk+1 = SFk∪ {a +}
b. Enlever le plus mauvais attribut a− = argmax a−∈ SBk a−∉ SFk+1 [J(SBk− {a−})] SBk+1 = SBk− {a −} c. k = k + 1 4. Fin
34
2.3 La méthode Relief et son extension Relief-F
L'une des méthodes les plus couramment connus pour la sélection des attributs est Relief et son extension Relief-F. Cette méthode a été proposée en 1992 par Kira et Rendell [7]. Son idée principale [34] dans le cas d'un problème de classification à deux classes consiste à calculer une mesure globale de la pertinence des attributs en estimant un contraste. Ce dernier est défini comme la différence de deux distances. La distance cumulée entre des exemples d'apprentissage choisis au hasard et leurs voisins les plus proches de la même classe d'une part et la même distance cumulée avec les plus proches voisins de l'autre classe d'autre part. Toutefois, cette méthode ne tient pas compte de la corrélation entre les attributs et donc ne supprime pas les attributs redondants. Nous expliquons en détails cette méthode et nous présentons son algorithme dans le chapitre 4.
2.4 Branch and Bound
2.4.1 Description de l'algorithme Branch and Bound
L’algorithme Branch& Bound (BB) a été présenté pour la première fois en 1977 par Narendra et Fukunaga [46]. BB est un algorithme "descendant" avec marche arrière qui garantit de trouver le sous-ensemble optimal si l'estimation de J est parfaite. Il est basé sur l'hypothèse que le critère de sélection adopté est monotone par rapport au nombre d'attributs [47] [48].
𝐽(𝐴) ≥ 𝐽(𝐵) si 𝐵 ⊂ 𝐴
Soit 𝐴̅𝑗 l'ensemble des attributs obtenus par la suppression de j attributs à partir de l'ensemble A
de tous les p attributs. La condition de monotonie suppose que pour des sous-ensembles 𝐴̅1, 𝐴̅2,
..., 𝐴̅𝑗 tels que
𝐴̅1 ⊃ 𝐴̅2 ⊃ ⋯ ⊃𝐴̅𝑗
la fonction de critère J vérifie 𝐽(𝐴̅1) ≥ 𝐽(𝐴̅2) ≥ ⋯ ≥ 𝐽(𝐴̅𝑗). Par une application directe de cette
35
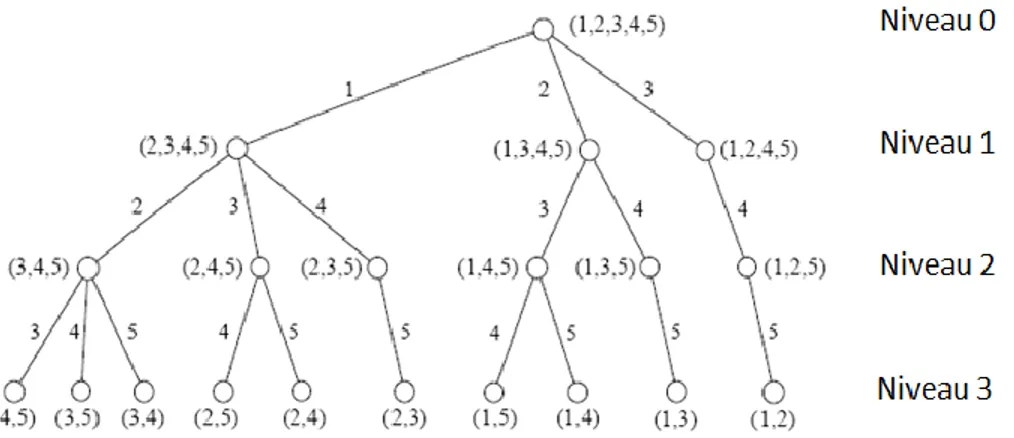
Soit m le nombre d'attributs que l'on souhaite garder, l'algorithme de base BB sélectionne p − m attributs à rejeter. La Figure 2.1 illustre un arbre de solutions correspondant à la sélection des meilleurs m = 2 attributs parmi 5.
Il comporte autant de niveaux que d'attributs à supprimer (trois dans notre exemple) un attribut étant supprimé à chaque niveau de l'arbre.
La racine de l'arbre (sommet) [49] correspond à l'ensemble d'origine des attributs A, et les feuilles au bas de l'arbre correspondent à l'ensemble des sous-ensembles possibles de m attributs [50]. Le problème est de trouver la meilleure feuille, celle qui maximise J, en limitant au plus le nombre de calculs de J.
L'algorithme BB commence la recherche au sommet de l'arbre (niveau 0), et tous les nœuds au niveau 1 sont analysés. Les nœuds successeurs (tous les nœuds dessous) du nœud avec le plus grand J sont explorées, et la recherche continue jusqu’aux feuilles de l'arbre (niveau 3 dans notre exemple).
Le meilleur sous-ensemble actuel (feuille) est trouvé avec une borne initiale B.
L'algorithme revient en arrière alors à tous les nœuds inexplorés au niveau 2, puis les nœuds inexplorés au niveau 1.
Si J(𝐴̅𝑖) > B pour un nœud , ses nœuds successeurs sont explorées tant que les valeurs de J restent plus grands que B).
Si J(𝐴̅𝑖) < B pour un nœud, ses nœuds successeurs (feuilles) au bas de l'arbre sont coupés,
l'évaluation de J ne peut qu'être plus petite que B en raison de la propriété de monotonie de J. Ils ne peuvent pas être le sous-ensemble optimal.
Si une nouvelle feuille avec un J>B est trouvée, la borne B est mise à jour avec la nouvelle valeur plus grande J.
La recherche et retour en arrière se poursuit jusqu'à ce que toutes les feuilles de l'arbre soient explorées ou coupées ainsi, l'algorithme BB donne la solution optimale.
36
Figure 2.1 L'arbre solution de l'algorithme BB lorsque m=2 et p=5.
2.4.2 Avantages de l’algorithme Branch and Bound
L'avantage de l'algorithme BB [47] sur une recherche exhaustive découle de la capacité de supprimer la construction de certaines branches de l’arbre de recherche.
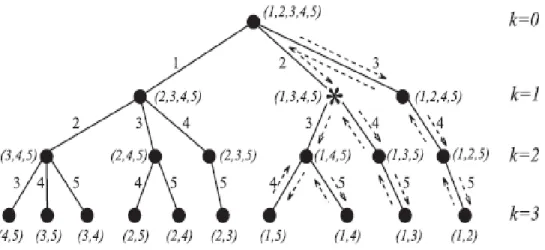
Considérons une situation où l'algorithme atteint le nœud * dans la figure ci-dessous (Figure 2.2). La borne a été mise à jour récemment selon le sous-ensemble cible contenant les attributs a1, a2.
Il y a une chance que la valeur du critère calculée pour l'ensemble actuel (a1, a3, a4, a5) soit
inférieure à la borne actuelle. Dans ce cas, en raison de la condition de monotonie aucun sous-ensemble issu du nœud * ne peut produire une meilleure valeur du critère J que la borne B. Par conséquent, la construction du sous-arbre est inutile (le sous-arbre serait coupé), économisant ainsi du temps.
37
Figure 2.2 Exemple de l'avantage de l'algorithme BB.
2.4.3 Inconvénients de l’algorithme Branch and Bound
L'algorithme BB présente plusieurs inconvénients [47]. Prenons l'utilisation de l’algorithme BB avec des fonctions de critère dont la complexité de calcul est élevée.
La faible performance de BB dans certaines situations peut résulter de simples faits que plus près de la racine :
i. Le calcul de la valeur de critère est généralement plus lent (sous-ensembles d'attributs évalués sont plus grands),
ii. Les sous-arbres à couper sont moins fréquents près de la racine (valeurs critères plus élevées peuvent être attendues pour les grands sous-ensembles, ce qui réduit le risque pour la valeur du critère d'être inférieur à la meilleure valeur courante).
L'algorithme BB passe habituellement la plupart de son temps à évaluer le critère aux nœuds d'arbre les moins prometteurs près de la racine. Cet effet est particulièrement important lorsque m << p.
38 2.4.4 Améliorations de l’algorithme BB
Plusieurs améliorations ont été apportées à l'algorithme de base BB [49]. a) L’algorithme Ordered BB ( OBB ) :
Les nœuds sont ordonnés dans l'arbre lors de la conception de l'arbre de solution tels que le nœud successeur le plus à gauche d'un nœud donné a une valeur du critère J inférieure à celle du nœud successeur à droite de ce nœud. L'objectif est d'augmenter les chances de couper les nœuds successeurs les plus à gauche, qui ont plus de branches que tous les autres nœuds.( cf. Figure 2.2)
b) L’algorithme Fast BB ( FBB ):
Cet algorithme met en œuvre un mécanisme de prédiction statistique pour estimer J plutôt que de calculer sa vraie valeur pour chaque nœud, réduisant ainsi l'effort de calcul nécessaire puisque le calcul du critère est la partie la plus complexe de la recherche. Le calcul de l'estimation de J est beaucoup plus rapide que le calcul de la vraie fonction de critère J. Lorsque J, estimé pour un nœud, est inférieur à la borne B actuelle, la véritable valeur du critère J pour ce nœud est calculée, et si ce nœud est coupé il le sera en se basant sur la véritable valeur du critère J et la valeur actuelle de B. Par conséquent, l'algorithme FBB sélectionne bien la solution optimale, étant donné que les nœuds ne sont jamais coupés sur la base de l'estimation de J. Mais on réduit significativement le nombre d'évaluations de J.
c) L’algorithme Adaptive BB ( ABB ) :
Cet algorithme améliore les algorithmes BB précédents dans quatre grands aspects [51]. Tout d'abord, l'algorithme ABB utilise la technique ( SFFS cf. 2.2.3) pour sélectionner une grande valeur initiale de la borne B. Une grande borne initiale permet à la recherche de couper rapidement de nombreuses branches aux niveaux proches de la racine de l'arbre. Ensuite, un simple ordonnancement des attributs est utilisé pour ordonner les nœuds de l'arbre. En troisième lieu, le niveau de recherche de départ dans l'arbre n'est pas le niveau 1. La technique d’ordonnancement des nœuds et la borne initiale B sont utilisées pour
39
trouver ce niveau de départ. Quatrièmement, ABB modélise la fonction de critère J par une équation déterministe simple :
Ĵ(A\ψk) = J(A) × (1 − (k/p)β)
où Ĵ(A\ψk) est la valeur de la fonction de critère prédite à un nœud au niveau k lorsque
l'ensemble ψk de k attributs est supprimé de l'ensemble A de tous les p attributs ; J(A) est la valeur exacte de la fonction de critère au sommet de l'arbre avec l'ensemble A de tous les p attributs et β (> 1) est une variable unique pour chaque nœud de l'arbre de solutions. [51] vérifie que Ĵ est une bonne estimation de toute fonction de critère J et l'utilise avec la valeur de J du nœud actuel et la borne actuelle B pour passer aux nœuds suivants. Il a été montré que l'algorithme ABB est exécuté plus rapidement que d'autres algorithmes BB quand m << p.
2.4.5 Look-ahead Search Strategy for Suboptimal Solutions
Cette stratégie est utilisée pour augmenter la vitesse de recherche de l'algorithme BB [49].
Si nous renonçons à l'optimalité de l'algorithme BB, nous pouvons éliminer beaucoup plus de nœuds successeurs. Ceci est fait en utilisant la plus grande borne actuelle bk+ r trouvé jusqu'à
présent au niveau k + r, plutôt que le B lié au niveau p - m, pour couper les nœuds, où k est le niveau de l'arbre du nœud étant actuellement recherché et r est un paramètre d'anticipation fixé par l'utilisateur.
Autrement dit, la valeur de J du nœud actuel au niveau k est comparée à la meilleure borne bk + r à
r niveaux plus bas de l'arbre. Si k + r est supérieur à p - m (le niveau de la feuille), on prend B au lieu de bk + r. Puisque bk+ r est toujours supérieure ou égale à la borne B, beaucoup plus de branches
peuvent être coupées plus tôt. Ce schéma d'anticipation a été incorporé dans l'algorithme de base BB et a montré une réduction significative du volume de calcul de J. Cependant, il n'existe aucune garantie que la solution obtenue soit optimale parce que la borne B du nœud feuille n'est pas la borne utilisée pour couper les nœuds de l’arbre.
40
Dans [49] Nakariyakul a étudié l'effet de "Look-ahead Search Strategy" sur quatre algorithmes BB différents. Il l'a testé sur deux ensembles de données réels. Il a trouvé que les solutions fournies par les algorithmes OBB, FBB et ABB sont optimisés même lorsque le paramètre r est petit. D'autre part, le coût de calcul requis par chaque algorithme BB est réduit de manière significative avec "Look-ahead Search Strategy". Pour le problème de la sélection de m attributs à partir d'un grand nombre d'attributs (p ≥ 50), Nakariyakul suggère que cette stratégie soit incorporée dans l'algorithme FBB ou ABB pour accélérer la recherche. L'utilisation de l'algorithme BB basique n'est pas recommandée pour une base de données à grande dimension.
2.5 Sélection par Information mutuelle avec regroupement (MI)
L'information mutuelle nous donne une idée de la quantité d'information partagée entre deux variables A et B [52].
L'information mutuelle de deux variables A et B discrètes est donnée par:
I(A; B) = ∑ ∑ p(a, b)log p(a, b) p(a)p(b)
b∈B a∈A
L'information mutuelle est utilisée dans les méthodes d'extraction des attributs. Dans [53] Grall-Maës et al proposent une méthode d'extraction d'attributs pour des variables aléatoires continues en utilisant un critère d'information mutuelle. En fait, l'extraction est conduite pour maximiser l'information apportée par les attributs à propos de l'appartenance à la classe. Elle utilise un critère d'information mutuelle basé sur des distributions de probabilité estimées. Le cadre méthodologique est développé pour l'extraction d'un seul attribut et il est étendu à plusieurs attributs.
L'information mutuelle est aussi utilisée dans les méthodes de sélection d'attributs. C'est une méthode filtre qui permet de connaître la quantité d'information liée aux classes portée par les attributs.
41
Dans [54] Liu et al. proposent une méthode de sélection d'attributs exploitant l'information mutuelle.
Soit S l'ensemble initial formé de p attributs et C représente les classes. Le but est de trouver un sous-ensemble Sbest contenant m attributs et qui maximise l'information mutuelle I(Sbest,C).
Pour ai є S, I(ai,C) est la quantité d'information relative aux classes C apportée par l'attribut ai.
Liu et al. affirment que la mesure de la distance entre l'attribut ai et les classes C est leur information
mutuelle I(ai,C).
Liu et al. proposent, par conséquent, de définir la distance entre l'ensemble d'attributs sélectionné T et le groupe de classes Ccomme suit:
Sb(C, T) = ∑ I(t, C)
t∈T
Une valeur maximale de Sb nous donne les meilleurs attributs qui représentent les classes.
Il est important de prendre en considération la redondance entre l'ensemble des attributs déjà sélectionnés T et l'attribut candidat ai. Par conséquent, la distance entre ai et T (S(ai)) est la somme
de la distance entre ai et tout t ∈ T:
S(ai) = ∑ CR(t, ai)
t∈T
CR(t, ai) est le coefficient de pertinence.
CR(t, ai) = I(t,ai)
H(t) où H est l'entropie.
H(t) = − ∑ p(t) log(p(t))
CR(t, ai)=0 signifie que t et ai sont indépendants, une valeur 1 signifie une dépendance totale.
42 Si CR(t, ai) = 0 alors I(t, ai) H(t) = 0 donc I(t, ai) = 0 donc log p(t, ai) p(t)p(ai) = 0 donc p(t, ai) p(t)p(ai)= 1 donc p(t, ai) = p(t)p(ai)
ce qui implique que t et ai sont indépendants.
Si CR(t, ai) = 1 alors I(t, ai) H(t) = 1 donc I(t, ai) = H(t) Or I(t, ai) = H(t) − H(t|ai) donc H(t|ai) = 0
ce qui implique une dépendance totale entre t et ai.
De même, la distance à l'intérieur du groupe Sw(T) de T peut être obtenue d'une manière
43
Sw(T ∪ ai) = Sw(T) + S(ai)
A part ces deux distances, la taille de T est un autre aspect important qui doit être pris en compte dans la sélection des attributs. Il est préférable que le sous-ensemble sélectionné contienne un nombre limité d'attributs.
D'où la fonction d'évaluation J de l'attribut candidat ai définie comme suit:
J(ai) =
Sb(C, T) + I(ai, C) |T| + Sw(T) + S(ai)
avec |T| est le nombre d'éléments dans T.
L'algorithme est donc le suivant (Algorithme 2.5) :
Algorithme 2.5
1. Initialisation: S=ensemble de tous les attributs, T = ∅, Sbest= ∅, C 2. Calculer la distance Sb(C, ai) = I(ai, C) pour chaque attribut ai є S
3. Choisir ai ayant max (I(ai, C))
4. S=S-{ ai }, T={ ai }; Sw=0
5. Tant que |T|< m alors a) Pour chaque ai є S
Calculer J(ai)
b) Choisir ai qui maximise J(ai)
c) T =T ∪{ ai }; S=S-{ ai }
d) Sw= Sw+ S(ai) , Sb = Sb+ I(ai;C)
Fin Sbest= T
44
2.6 LASSO et Elastic Net
LASSO (Least Absolute Shrinkage and Selection Operator) est un outil utile [33] pour obtenir une régression linéaire entre une variable à expliquer et un ensemble d'attributs. LASSO utilise une régression régularisée à l'aide d'une pénalisation L1. Par conséquent, seul un nombre limité de
coefficients est non nul ce qui permet de les utiliser pour la sélection. On fait la sélection en résolvant un problème d'optimisation continu. On évite ainsi l'effet combinatoire observé dans toutes les méthodes évoquées précédemment. Mais dans le cas où les caractéristiques sont corrélées, on souhaiterait ne conserver qu'un seul des attributs corrélés. LASSO ne parvient pas à opérer cette sélection : il les garde tous ou les élimine tous... Une solution a été développée pour résoudre ce problème : il s'agit d'Elastic Net (EN) dont LASSO est un cas particulier. EN introduit une pénalisation mixte L1 et L2 qui tend à regrouper les attributs fortement corrélés. Ces deux
méthodes LASSO et Elastic Net seront présentées en détail dans le chapitre 4.
2.7 Les critères de sélection de paramètres
2.7.1 La sélection d'attributs à base de corrélation
Dans [55] Hall aborde le problème de la sélection des attributs pour l'apprentissage par une approche à base de corrélation. L'hypothèse centrale est que les bons ensembles d'attributs contiennent des attributs fortement corrélés avec la classe, mais non corrélés les uns avec les autres. Avec Correlation-based Feature Selector (CFS) il propose un algorithme qui combine un critère d'évaluation basé sur la corrélation et une stratégie de recherche heuristique [55].
Des expériences ont montré que CFS identifie et élimine rapidement les attributs inutiles, redondants et bruités, et identifie les attributs pertinents, tant que leur pertinence ne dépend pas fortement d'autres attributs.
45 2.7.1.1 Correlation-based Feature Selector (CFS)
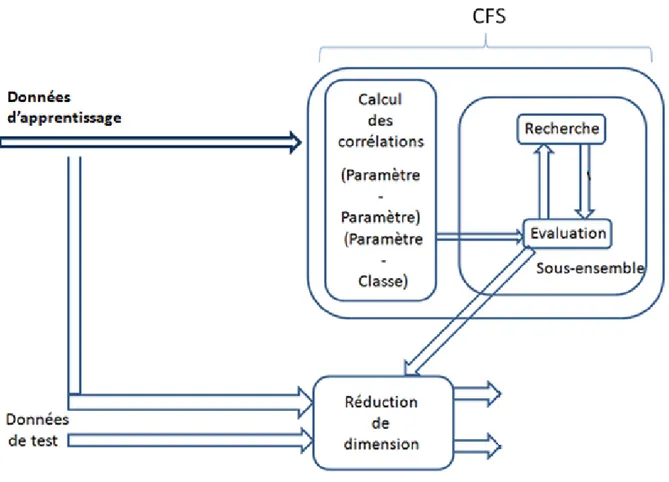
CFS est un algorithme filtre simple [55] qui classe les sous-ensembles d'attributs selon une fonction de mérite déduite des corrélations à l'aide d'une heuristique. La tendance de la fonction d'évaluation est de trouver des sous-ensembles qui contiennent des attributs qui sont fortement corrélés avec la classe (prédictives de la classe) et non corrélés les uns avec les autres. Les attributs qui ont une faible corrélation avec la classe doivent être ignorés car ils ne sont pas pertinents. Les attributs redondants doivent être éliminés car ils seront fortement corrélés avec l'un ou plusieurs des attributs restants.
La fonction d'évaluation d'un sous-ensemble d'attributs de CFS est définie comme suit:
Msk =
k r̅̅̅̅̅ ca √k + k(k − 1)r̅̅̅̅ aa
où Msk est le "mérite" heuristique d'un sous-ensemble d'attributs Sk contenant k attributs (a:
attribut, c:classe), r̅̅̅̅ est une mesure de la corrélation attribut-classe moyenne (a Є Sca k), et r̅̅̅̅ est aa une mesure de l’inter- corrélation moyenne attribut-attribut.
Le numérateur de l'équation peut être considéré [55] comme fournissant une indication du degré de prédictibilité de la classe par un ensemble d'attributs, le dénominateur est un indicateur du degré de redondance entre les attributs de cet ensemble.
Dans [56] une mesure de corrélation basée sur l'entropie conditionnelle est utilisée. Pour deux variables aléatoires V et W, l'entropie et l'entropie conditionnelle sont données par les relations suivantes respectivement [56]: H(W) = − ∑ p(w) w∈W log(p(w)) H(W|V) = − ∑ p(v) v∈V ∑ p(w|v)log(p(w|v)) w∈W
46
C(W|V) =H(W) − H(W|V) H(W)
On retrouve le coefficient de pertinence cité dans le paragraphe 2.5. 2.7.1.2 Etapes de l’algorithme CFS
La Figure 2.3 montre les étapes de l'algorithme CFS [55] et la façon dont il est utilisé en conjonction avec un système d'apprentissage. Une copie des données (training data) est transmise à CFS. CFS calcule les corrélations attributs-classe et attribut-attribut. Le sous-ensemble avec le plus grand mérite trouvé lors de la recherche est utilisé pour réduire la dimension des données. L’ensemble de données réduit peut ensuite être transmis à un système d'apprentissage pour l'apprentissage et les tests. Il est important de noter que toute stratégie de recherche concevable peut être utilisée avec CFS.