Performance analysis of demodulation with diversity - A combinatorial approach I : Symmetric function theoretical methods
15
0
0
Texte intégral
Figure
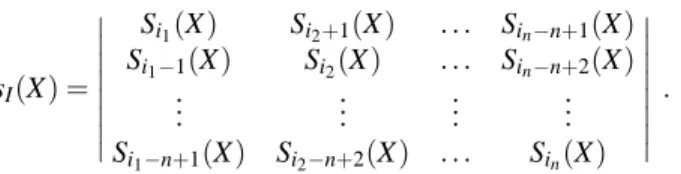
Documents relatifs