Speaker information modification in the VoicePrivacy 2020 toolchain
Texte intégral
Figure
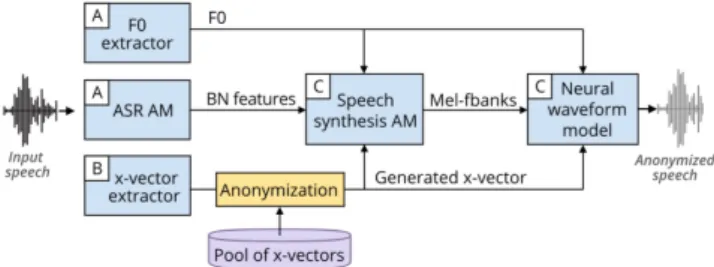
Documents relatifs
Are the rehabilitation services accessible for clients living in rural areas, is there a sufficient legislation base, as well as can the client, who is living in the rural area,
Specifically, ASR performance using a model trained on original (non-anonymized) data and subjective speech intelligibility and naturalness were measured during the challenge,
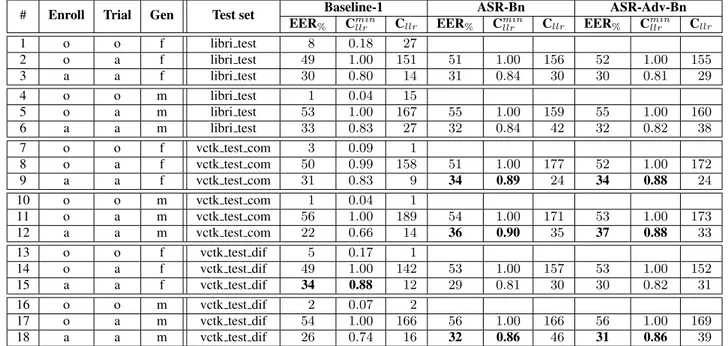
Tables 2 and 3 provide the privacy objective evaluation results in terms of EER, C llr , and C llr min for two attack models — ignorant (oa: original enrollment and anonymized
In the latter case, we assume that the utterances have been anonymized in the same way as the trial data using the same anonymization system, i.e., all enrollment utterances from
Service type templates define the syntax of service: URLs for a particular service type, as well as the attributes which accompany a service: URL in a service
In this case, the content- collection content type is used to gather more than one content item, each with an object identifier to specify the content type.. In this document,
The bootstrap loader MUST reject a firmware package if the list of supported hardware module type identifiers within the firmware package does not include the object identifier
For some issues, consensus has already been arrived at or the liaison statement is a mere statement of facts (e.g., to inform the liaised organization that an IETF Last
