Mean Field Games of Controls: Finite Difference Approximations
33
0
0
Texte intégral
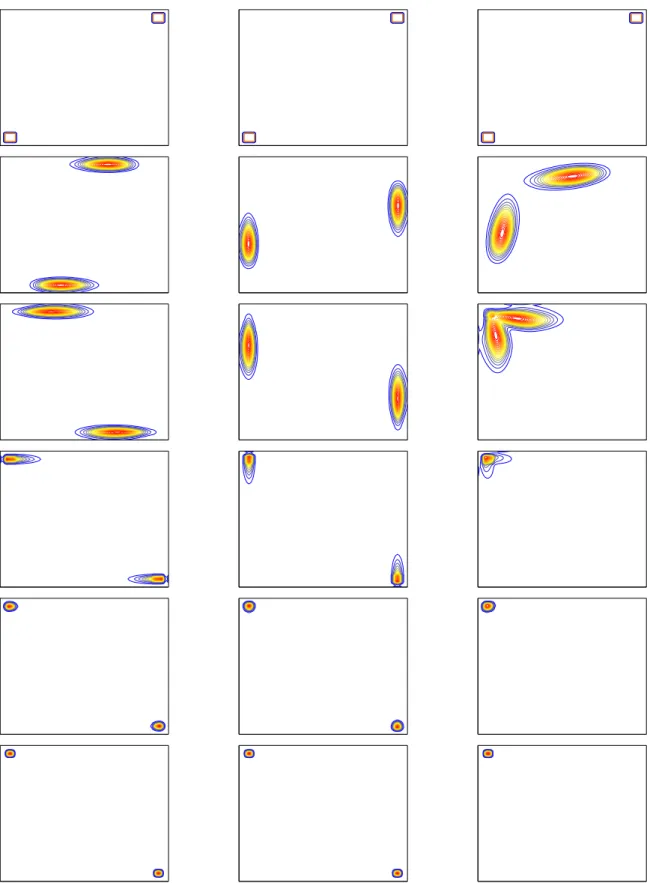
Figure



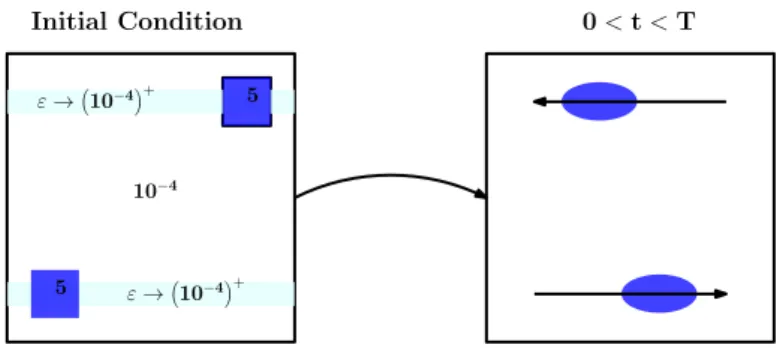
+7

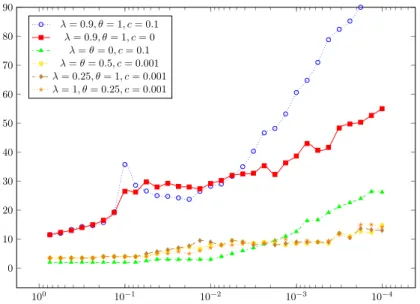
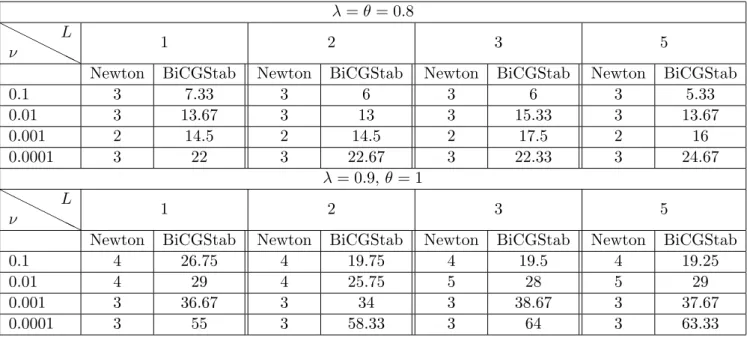
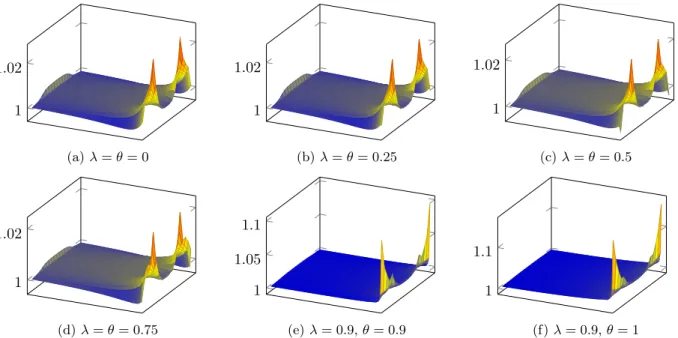
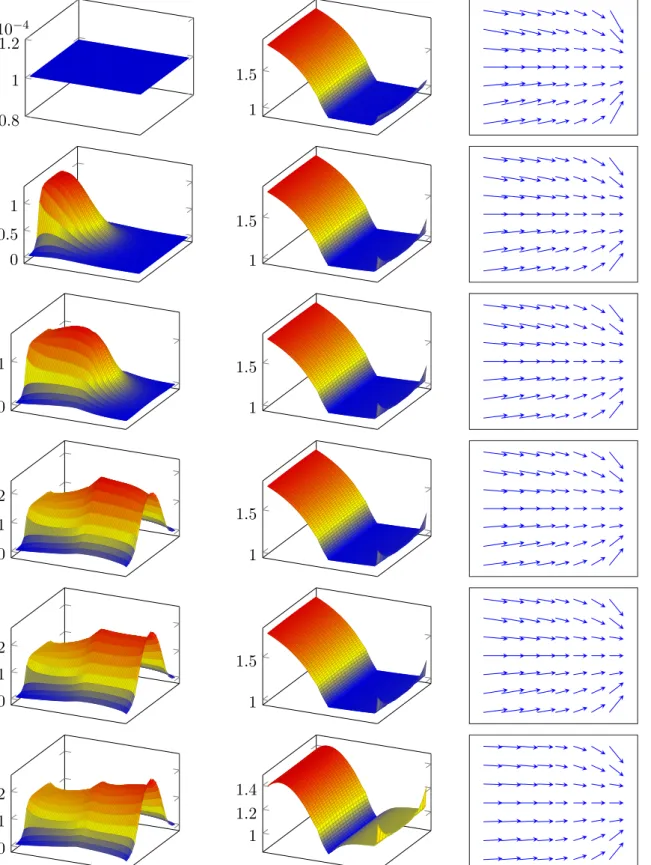
Documents relatifs