Les optimisations d'algorithmes de traitement de signal sur les architectures modernes parallèles et embarquées
Texte intégral
Figure
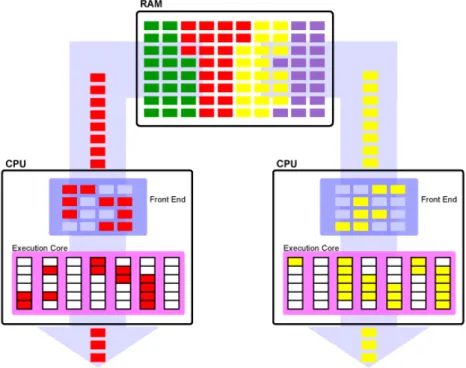

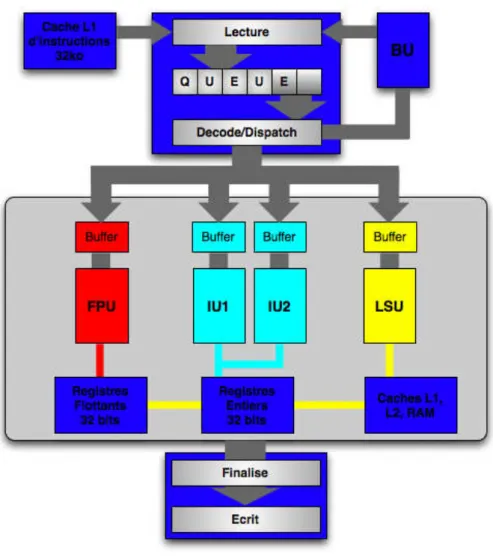


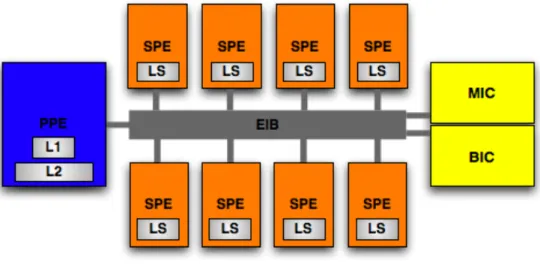
Documents relatifs
Il y a plus d'attributs communs entre le chien et la poule (yeux, bouche ; squelette interne ; 4 membres) qu'avec le poisson (yeux, bouche ; squelette interne mais il ne possède pas
Et l‘on se demande peut-être si ce Français utilisé dans la Trilo- gie est compris uniquement par l‘analyste ou bien éga- lement par les Français... Dans sa culture
Nous avons recensé 32 items dans le menu trophique du moineau (Tableau.05).. et Belhamra M., 2010 : Aperçu sur la faune Arthropodologique des palmeraies d’El-Kantara .Univ. Mohamed
Meyerson précise qu’il ne vise pas le pan-algébrisme de l’école de Marburg, pourtant présenté comme la « forme la plus définie » d’idéalisme
Cette approche pour l'optimisation de fonne, quoique très générale, est en fait très contraignante, car si on désire implanter un algorithme génétique dans la boucle
Il semble intéressant d’étudier le rapport entre le discours autoritaire du III ème Reich et la littérature consacrée après la guerre aux Provinces de l’est perdues en 1945
Le suréchantillonnage par L doit être suivie d’un filtre passe-bas coupant à F e /2L pour supprimer les spectres dus à l’suré- chantillonnage, où F e est la
Cette phrase montre que Solvay prend appui sur son référentiel de compétences dans son nouvel accord de GPEC pour saisir les différentes sources de compétences : lors de la
