HD28
.M414
v^.
1990
)
D&'JHV
WORKING
PAPER
ALFRED
P.SLOAN
SCHOOL
OF
MANAGEMENT
An
Accounting
Model-Based Approach
to
Semantic
Reconciliation
in
Heterogeneous
Database
Systems
Y.
Richard
Wang
October
1990
WP
#
MSA
3212-90
MASSACHUSETTS
INSTITUTE
OF
TECHNOLOGY
50
MEMORIAL
DRIVE
CAMBRIDGE,
MASSACHUSETTS
02139
An
Accounting
Model-Based
Approach
to
Semantic
Reconciliation
in
Heterogeneous Database
Systems
Y.
Richard
Wang
October
1990
WP
#
MSA
3212-90
Composite
Information
Systems
Laboratory
E53-320. Sloan School
of
Management
Massachusetts
Institute
of
Technology
Cambridge. Mass.
02139
Tel.
(617)
253-0442
Fax
(617)
492-4655
E-mciil:
[email protected]
©
1990
Y.Richard
Wang
ACKNOWLEDGEMENTS
Work
reportedherein
has been
supported,
in part,by
MIT's
International Financial Service
Research
Center
and
MITs
Center
forInformation
Systems
Research.
The
author wishes
tothank
AllenMoulton
for his insightduring
the early stage of this researchand
Sung Khang
forhisfieldwork.
An
Accounting
Model-Based
Approach
to
Semantic
Reconciliation
in
Heterogeneous
Database
Systems
ABSTRACT
Many
importantManagement
SupportSystems
require access toand
seamlessintegration ofmultiple heterogeneous database systems. In this paper,
we
present amodel-based
approach
forreconciling semantic heterogeneity of financial data retrieved
from
various data sources—
financialdata
which
areneeded
inmany
Management
SupportSystems.Specifically, a top-down, accounting model-based approach is presented to reconcile semantic
heterogeneity
among
the data retrievedfrom
multiple financial accounting databases.Knowledge
represented inthis
model
isapplied toreconciledataconflictsand
toinfernew
information. Accountingmodel-based
rules for reconciling semantic heterogeneity at the data level are illustrated withintriguing cases using real data.
To
the best ofourknowledge,
thisapproach
has notbeen
applied tothe heterogeneous database systems area for reconciling semantic heterogeneity at the data level as
well as the
schema
level.The
accountingmodel-based
approach
checks the reliabilityand
validity of data usingknowledge encoded
in the model. It enablesManagement
Support Systems
toproduce
integratedfinancial statements so that theirusers can focus on utilizing these integrated financial statements for
I. Introduction 1 Research
Goal
and
Contribution 4Research
Background
and Assumptions
5II.
An
AccountingModel-BasedApproach
7Relationship Representation 9
III. ReconcilingSchema-Level Semantic Heterogeneity 11
Schema
Integration 12IV. Reconciling Data-Level Semantic Heterogeneity 14
UnitConversion 16
Model-Based
Judgement
16V.
Profitability Analysis 21VI. Concluding
Remarks
22An
Accounting
Model-Based
Approach
to
Semantic
Reconciliation
in
Heterogeneous
Database
Systems
I.
Introduction
The
increasing complexity, interdependence,and
competitionintheglobalbusinessenvironmenthas profoundly
changed
how
corporations operateand
how
theyalign their information technology forcompetitiveadvantage in the marketplace. It has been argued that thechanging corporate operations
will accelerate
demands
formore
effectiveManagement
SupportSystems
for product development,productdelivery,
and
customer serviceand
management
(Rockart&
Short, 1989).With
theincreasingexploitationofdatabase
and
telecommunication technologies inorganizationsand
thedissemination ofManagement
SupportSystems from
the executive to the line level, it is inevitable thatmany
futuresystems will require
dynamic
access to information stored in disparate databases with disparatequalities, located both within
and
across organizational boundaries(Wang
&
Madnick, 1988).Already, corporations are placing increasing
emphasis
on
themanagement
of data.Case
studies of 31 data
management
efforts in 20 diverse firmshave
been reported(Goodhue,
Quillard,&
Rockart, 1988) in
which
fivedatamanagement
systemswere
identified:(1) Subject area databases for operational systems containing data organized
around
important businessentitiesorsubject areas,suchascustomer
and
product.(2)
Common
systemswhich
are applications developedby
a single,most
often a central, organization tobe
used
by
multiple organizational units. For example,manufacturing
applications such asproduction scheduling
and
spare parts inventory.(3) Informalior. databases
which
periodicallydraw
their contentsfrom
operational databasesand
externalsources,
and
often storedata inaggregatedforms.(4) Data access services
which
focus mainlyon improving
managerial access to existing data, withoutattemptingto
upgrade
the quality or structureofthedata.(5)Architectural foundations
which
are policies that force systemsdevelopment
efforts toconform
to awell structured, overall plan.
The
first three systemsemphasize
developingnew
databases or files with pertinent, accurate.and
consistentdata.They
requirea major systemdevelopment
and
on-going maintenance. Subject areadatabases
and
common
systems aredeveloped
in firms seeking better operational coordination;whereas
information databases arc developed in firms seeking improved managerial information.Data access services,
on
the other hand, are usually providedby
a smallgroup
of personnel,often part ofan information center,
whose
goal is tobetterunderstandwhat
data isavailable incurrentsystems
and
to put into placemechanisms
to deliver this data. Thesemechanisms
include locatingappropriate data, extracting data
from
production files, or training users in fourth generationlanguages.
From
thetechni-^l point ofview, these systemsrepresenttwo ends
of a spectrum ofapproachesaimingat retrieving information
from
variousdata sources. At one end, data access servicesprovide a"quick
and
dirty"approach
formanagers
toget theirhands on
existing op>crational databasesin anon-intrusive
manner,
thus maintaining the localautonomy
of operational databases.At
the other end,subject area databases,
common
systems,and
information databases provide a binding integration ofinformation
by
developingbrandnew
databases, oftenat significantcost.Evolution is an often-neglected factor in the
development and
deployment
of these systems.Each
system, as well as theneeds forsharingamong
systems, willchange
overtime.The
rateand form
of this evolution
may
tip the balancebetween
autonomy
and
integration.Although
autonomy
and
integration areconflicting factors, with evolution as a further complication, it
may
be possible todefinea
system
architecture with sufficient flexibility toaccommodate
diverse requirementssuch
asintegration,
autonomy, and
evolution.It is interesting to note, at this point, that database researchers
have been
actively addressingissues indeveloping such systemarchitectures.
They have
referred to this type of systemarchitecturesas heterogeneous database systems^, Federated Database Systems (Czejdo, Rusinkiewicz,
&
Embley,
1987; Elmasri, Larson,
&
Navathe, 1987;Heimbigner
&
McLeod,
1985;Lyngbaek
&
McLeod,
1983),For example. National Science Foundation (NSF) sponsored a workshop on Heterogeneous Database
Systems in cooperation with Northwestern University and lEEE-CSTechnical Committeeon Distributed Processing in December, 1989.
MuUidatabases
(Ferrier&
Strangrct, 1982; Litwin&
Abdellatif, 1986; Litwin, et al., 1982)2, qj.Composite Information Systems (Madnick, Sicgel,
&
Wang,
1990;Wang
&
Madnick,
1988).The
goal ofheterogeneous database systemsresearch is to cover a spectrum of capabihties in a coherent
manner.
These
capabilities rangefrom
providing real-time connection to operational databases, to betterOfjerational coordination, to
improved
managerial information.Many
critical researchand
commercializationproblems need tobe reconciled inordertoprovidea solution for access to
and
seamless integration of heterogeneous database systems (Reiner, 1990).These
problems
include semantic reconciliation, data attribute tagging, networking, specificationand
processing ofmultidatabase quencs, queryoptimization, transaction
management, and
toolsforbuildingmultidatabases. In thispaper,
we
focuson semantic reconciliation.Reconciling semanticheterogeneityisan
advanced
issuein theheterogeneous database systemsarea. In the commercial world, establishing a physical
network
infrastructureand
data access serviceshave been
the key concerns of executivesmaking
information systems decisions(Madnick
&
Wang,
1986). In a recent study ofcorporate needs for heterogeneous database systems^,
80%
of themanagers
surveyed cited data access as their
immediate
need.Speed
of data accesswas
cited as the secondpriority after data access
was
satisfied.The
third prioritywas
functionalities such as semanticreconciliation. Currently, semantic reconciliation is largely
done by
users.However,
as usersbecome
more
sophisticated, their attention will be directed to reconciliation of data values retrievedfrom
disparate databases.
Researchers
have
started to address the reconciliation of data values through techniques suchas frames
and
abstract data types (ADT). In theKSYS
research project (Wiederhold, 1987), forexample, thenotion of framesas a data
model
was
introduced. It investigates the implementationof aframe-based
system
residing at a levelabove
the databaseschema
to provide virtual attributefacility. In the
CISL
research project (Madnick,Siegel,&
Wang,
1990),ADT
was
used to determine ifNSF
willsponsorasimilar workshopon Multidatabases&
SemanticInteroperabilitywhichin cooperation with the UniversityofKentucky andAmoco
ProductionCompany
Research Centerin November, 1990. Private communication with Lotus Development Corporation's Datalcns industry marketing team, October1990.the semantics of data
provided
by
databases aremeaningful
to the appHcation.Methods
were
proposed
for detecting changes in data semanticsand
fordetermining if thedatabases can continue tosupply meaningful data to the application. Inthese researchefforts, the
bottom-up
notionisimbedded
and
theword
"mod
'"isused inthecontextofdata modeling.
Most
other research efforts in the area of heterogeneous database systemshave
focusedon
system building, transaction
management, and
query processing (Breitbart, Olson,&
Thompson,
1986;Brill,
Templeton,
&
Yu, 1984; Czejdo, Rusinkiewicz,&
Embley,
1987;Deen,
Amin,
&
C,
1987;Elmagarmid,
et al., 1990; Ferrier&
Strangret, 1982;Heimbigner
&
McLeod,
1985; Litwin&
Abdellatif,1986; Litwin, et al., 1982;
Lyngbaek
&
McLeod,
1983; Smith, et al., 1981;Wang
&
Madnick,
1988).A
common
assumption
of all these research efforts is that semantic heterogeneity willbe
reconciledthrough
schema
integration.However,
work
on
schema
integration (Batini, Lenzirini,&
Navathe,1986; Dayal
&
Hwang,
1984; Elmasri, Larson,&
Navathe, 1987) has also beenbottom-up
oriented.A
group
of Data Base Administrators(DBAs)
would
get together tocompare
the entities, relationships,and
attributes in their local databases. After figuring out the differences in their local databases, anintegrated
schema
would
be proposed, together with the mapp>ed relationshipsbetween
the integratedschema and
thecorresponding local schemas.Although
appropriate for integrating a smallnumber
oflocal databases, the task
becomes
formidable as thenumber
of local databases increases (Batini,Lenzirini,
&
Navathe, 1986; Elmasri, Larson,&
Navathe, 1987).More
important, theDBAs
may
integrate local databases
from
only the technical viewpoint without fully considering managerialimplications.
In contrast, a top-down,application model-based approach
would
enable usto focuson
thedatarequired
by
this application model, thus reducing the scope of integration. Applicationmodels
willalso
meet
theneeds ofapplication usersand
provideamore
naturaland
stabledata environment.RESEARCH
GOAL
AND
CONTRIBUTION
The
goal of this research is todevelop
amodel-based approach
for reconciling semanticmodel-based approach
for producing integrated financial statementsfrom
databaseswhich
are beingused
by
practitioners.The
accountingmodel
isbuiltfrom
general accountingknowledge
(Foster, 1986;Kohler, 1983). For illustrativepurpose,
we
focuson
accountingknowledge
pertinent for constructingfinancial statements.
The
significanceof thispaper is as follows:A
top-down, accounting model-basedapproach
ispresented to reconcile semantic heterogeneity
among
the data retrievedfrom
multiple financialaccountingdatabases.
Knowledge
representedinthismodel
isapplied toreconciledataconflictsand
toinfer
new
information. Accounting model-based rules forreconcilingsemantic heterogeneityat thedatalevel are illustrated with intriguing cases using real data.
The
concept ofknowledge
representationformodel
management
systems hasbeen
examined
inthe context of mathematical
programming
and
other areas (Bhargava&
Kimbrough,
1990; Bhargava,Kimbrough,
&
Krishnan, 1989; Dolk, 1986; Dolk, 1988;Dolk
&
Konsynski, 1984).However,
tothe bestofour
knowledge,
thisapproach
has not been applied to the heterogeneous database systems area forreconciling semantic heterogeneity at thedata level as well as the
schema
level.By
virtue of its rigorous nature, the accounting disciplinelends itself to a solid foundation forreconciling semantic heterogeneity inherent in disparate financial accounting databases.
The
requirement to balance all the accounts has provided a
model-based approach
for evaluating thereliability
and
validity of data retrievedfrom
heterogeneous database systems.The top-down,
accounting
model-based approach
has further enabled financial analysts to focuson
the applicationrequirements that
most
concerned them: utilizing integrated financial statements for tasks such asprofitability analysis.
RESEARCH
BACKGROUND AND
ASSUMPTIONS
We
have
evolved a heterogeneous database system with source tagging capabilities (Codes,1989; Gupta,ct al., 1989; Madnick, Sicgel,
&
Wang,
1990; Paget, 1989;Wang &
Madnick, 1988;Wang
&
Madnick,
1990;Yuan,
1990).The query
processor architecture is depicted in Figure 1. Briefly, theQuery
Processor(PQP)
basedon
the user's applicationschema.The
term "polygen" isused (instead ofthe
more
conventional term - "global") to signify a query processor with source tagging capabilities.The
PQP
in turn translates the polygen query into a set of local queries basedon
the correspondingpolygen schema,
and
routesthem
tothe LocalQuery
Processors (LQP).The
detailsofthemapping
and
communication mechanisms between
anLQP
and
itslocal database is encapsulated in theLQP.
Upon
return
from
theLQPs,
the retrieved data arc further processedby
thePQP
in order toproduce
thedesired compositeinformation.
Application
Schema
Metadata Dictionary1^
Application _QueryComposite
Answer
DBMS
Query
DBMS
ResultSection IIpresentsan accounting model-based approach. SectionIIIaddressesissuesinvolvedin
reconciling semantic heterogeneity at the
schema
level basedon
theknowledge
represented in theaccounting model. Section IV illustrates
how
semantic heterogeneity at the account-data level canbe
reconciled. In Section V, a profitability analysis is presented based
on
financial ratios. Finally,concludingremarksare
made
inSectionVI.II.
An
Accounting
Model-Based
Approach
Financial statements such as the balance sheet,
income
statement,and
cash flow statement arethe
most widely
distributed accounting information. Financial analysts routinely utilize suchinformation as a starting point to analyze the financial status of companies. Since accounting
terminology,suchas accountsreceivable,arewellunderstood
by
accountants,an
accountingmodel
couldbeconstructed fora heterogeneousdatabase system.
An
Entity-Relationship (ER)view
ofaccountingmodels
(McCarthy, 1979;McCarthy,
1982)was
proposed as a generalized approach forboth accountants
and
non-accountants.Correspondence
oftheapproach
with the accounting theorieswas
discussed. Applications of thisapproach
in the databasedesign phases of
view
modeling
and view
integrationwere
presented. Finally,ER
representations ofaccounting objects
were
reconciled with those representationsfound
in conventional double-entrysystems. This
approach
deals with problems ina single databaseenvironment
and
attheschema
level.Efforts toextend this
ER
view
ofaccountingmodels
for reconciling data values retrievedfrom
variousdata sources can be
found
elsewhere(Chen
&
Wang,
1990). In this paper,we
focuson
the accountingaspect.
Briefly, total assets, total liabilities,
and
shareholders' equity are threeprimary
accounts inthe balance sheet. For example, total assets equals total current assets plus total non-currentassets.
Each
account, in turn, iscomputed
from
othermore
detailed accounts, asshown
in Figure 2.The
hierarchical structure exhibits the inter-relationship ofaccounts.
We
call the highest level account ineach hierarchical structure a "root account."
An
account is called a "parent" account in relation to itsaccount is
more
aggregated than itschildren accounts. Thus,on
theone
hand,we
attainmore
detailedinformationas
we move
down
a hierarchy;on
the other hand,we
attainmore
aggregated informationas
we move
up
a hierarchy-N/R (+)TOTAL
CURRENT
ASSETS(+)TOTAL
NON-CURRENT
ASSETS(+) INTEREST
RECEIVABLE
SUPPUES
(+) PREPAID EXPENSE(+)INVENTORY
(+) INTANGIBLE ASSETS(+)OTHER
CURRENT
ASSETS (+)DEFERRED
CHARGES(+)MARKETABLE
SEcuRrn£S(+)T
INVESTMENT
&
ADVANCES
TO
SUBSIDIARIES (+)OTHER
NON-CURRENT
ASSETS(-(-)NET
FIXEDASSETS(+)
MERCHANDISE
INVENTORY(-t-)z
RAW
MATERIAL
STOCK-IN PROCESS(-h)GROSS
FIXEDASSETS
(+)ACCUMULATED
DEPRECIATION (-)A/R:
ACCOUNTS
RECEIVABLE
Kfi:
NOTES
RECEIVABLE
FINISHED
GOODS
(+)
RELATIONSHIP REPRESENTATION
Broadly, the intcr-rclationships of the various accounts can be classified into
two
categories:explicit
and
implicit.Explicit Relationship.
The
relationshipbetween
the parent accountand
the child account isrepresented
by
an
arithmetic sign in parentheses, such as (+) or (-). For example, in Figure 2, theexplicit relationship of net fixed assets, grossfixed assets,
and
accumulated depreciation is "Net FixedAssets" = "GrossFixed Assets"-
"Accumulated
Depreciation."The income
statementand
the balance sheet are linked together because net income, the rootaccount in the
income
statement, isa child account ofretained earningsin thebalancesheet.'*The
cashflow statementisderived
from
thebalance sheetand
theincome
statement.Implicit Relationship.
The
hierarchical inheritance property can be exploited.From
Figure 3an application system can determine that:
cash flow - cash flow
from
operation + cash flowfrom
finance + disposal of fixed assets- acquisition of fixed assets- othercapital expenditure
As
another example, in addition to the relationship of"Net
Fixed Assets" = "Gross FixedAssets" -
"Accumulated
Depreciation"mentioned
earlier,netfixed assetsshould belessthan grossfixedAssets. This relationship is based
on
the supposition that as long as a firm has fixed assets, its grossfixed assets
and accumulated
depreciation willhave
positive valueand
its accumulated depreciationwill notexceed grossfixed assets.
Figures3
and
4summarize
the relationshipsof the financial statements.This comes from the relationship of "Retained Earnings" = "Retained Earnings at Beginning" + "Net Income" - "Dividend".
Two
separate tasks,schema
integrationand
queryprocessing,need
tobe performedinapplyinga
top-down,
accountingmodel-based
approach
toproducing
integrated financial statementsfrom
multiple databases.
During schema
integration, the semantic heterogeneityof entities, attributes,and
relationshipsare reconciled.
During
query processing, the semantic heterogeneity of data values arereconciled.
We
focuson
the schema-level heterogeneity inSection III,and
data-level heterogeneity inSection IV.
III.
Reconciling
Schema-Level
Semantic Heterogeneity
We
first introduce three financial accounting databaseswhich
will beused
to present anapplication
example
in this paper.They
arc Finsbury's Dataline, LP. Sharp's Disclosure,and
Lotus'LotusOne.
As
mentioned
earlier, thesedatabases are currentlybeing usedby
practitioners toperform
financial analysis.
Dataline provides various financial statements
from
the previous five years formore
thanthreethousand
companies
inEurope
and
Japan.The
financial statements includebalancesheets,income
statements,
and
major accountingratios.Disclosure contains financial
and
management
informationfrom
more
than 12,000 publiccompanies
which
file reports with the U.S. Securitiesand Exchange
Commission
(SEC).As
such,companies
whose
information is provided in Disclosurehave
at least500 shareholders ofone
class ofstock
and
at least $5 million in assets.The
financial data providedby
Disclosure includes quarterlyand
yearly financial statementssuch as balancesheets,income
statements, changes in financial status,and
key financial ratios.LotusOne
alsoprovidesfinancialand
management
informationaboutcompanies
which
report tothe
SEC
in the U.S. Sincethe information inLotusOne
isquite similar to that ofDisclosure, it iseasy toillustrate important semantic heterogeneity by
comparing
theoverlapping information.As
an example,we
focuson
the financial statementsofVolvo
Corporation basedon
raw
datafrom
the three databases.SCHEMA
INTEGRATION
Many
issuesneed
to be addressed inschema
integration of multiple financial accountingdatabases either with or without a top-down, accounting
model-based
approach.The
difference isthat an accounting
model-based approach
enables us to reconcile semantic heterogeneityamong
disparate databasesbased
on
the accountsrepresented in themodel and
theirrelationships.We
have
found
that thearrangement and
choice ofaccounting termsof these financial accounting databasesareso incompatible that
even
an experienced accountantwould
take a fairamount
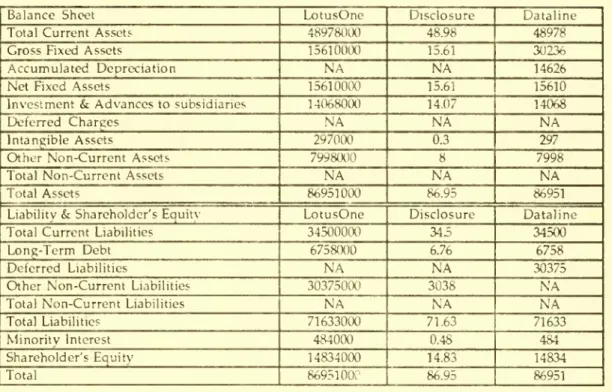
of time in order toreconcile the semantic heterogeneity. Table 1
shows
the reconciled total assets for these threematch
any
accountsemployed
in the model,but theparent account can beidentified, then a questionmark
isentered. Forexample, in the caseof "Debtors" from Dataline,we
recognize that this account istheaggregationof "AccountsReceivable"
and
"Notesreceivable." Thus, itbelongs totheparent account"Current Assets."
However,
we
cannotspecify theexactmatchinglevel of theaccount intheaccountingmodel. Therefore, this account is
marked
with "?." Accounts in themodel which do
nothave
any
matching
accountsfrom
any
databases are filled with"NA."
Thisphenomenon
willhappen
becausethe
model
has amore
detailed level ofaggregation than theactualdatabasesunder
investigation.Some
typicalschema
integrationproblems
(Batini, Lenzirini,&
Navathe,
1986) in theaccounting
domain
areexemplifiedbelow.Same Terms
for DifferentConcepts
. In Dataline, the term"Cash
+ Equivalents" is used torepresent "Cash." In Disclosure, the term
"Cash
&
Equivalents" is used to include the"Cash"
and
"Marketable Securities."
Different Accounting
Terms
. Differentaccounting termsareused torepresent thesame
concept.For example,
"NI
Before ExtraordinaryIncome"
is used in LotusOne,"Net
Income
Before Ext" inDisclosure,
and
"Earned for Ordinary" in Dataline.As
another example, "Shareholders' Equity" isused inLotusOne, "Total Equity" inDisclosure,
and
"Capitaland
Reserves" inDataline.Account
Incompleteness.LotusOne and
Disclosure contain accountssuchR&D
expensesand
Selling
&
Administration Expenses,whereas
Datalinedoesnot.^Different Levels of Aggregation.
LotusOne and
Disclosure provide aggregated data for totalgross fixed assets,
whereas
Dataline provides data for each item of gross fixed assets, such as land,buildings, plants
and
machinery.These
issues are reconciled during theschema
integration process following the accountingmodel.
The knowledge
ofschema
level semantic heterogeneity is recorded ina metadata dictionary.Forexample. Table 1 forms part of the metadata dictionary.
Thereare alsocases in which although thedatabase
may
havea specificaccount, ithas nodata forit. Forinstance, although all throe databases have an item for "Accumulated Depreciation." LotusOne and Disclosuredo not havedata in forit. This account-value level issue willbe addressed at run-timeby the
queryprocessor.
During
run-time, the metadata dictionaryis usedby
thequery
processortomatch
the accountsfrom
theaccounting terms used in each database so that data canbe
retrievedfrom
these databases.After the data
have
been retrieved, reliabilityand
credibility of the dataneed
to beexamined
beforeintegrated financial statementscan be produced.
The
following section presents the solution techniquesthatwe
have
developed.IV.
Reconciling
Data-Level
Semantic
Heterogeneity
At run time, a
copy
of theaccountingmodel
is created to hold the data retrievedfrom
each ofthe financial databases.
As
long as the data for the aggregated accounts are semantically consistent,we
will ignore thesemanticconflictswhich
may
occur inthelowerlevelaccounts. Indoingso,we
have
assumed
that the data for the children accounts will not beneeded
later for further financial analysis.In general,
depending on
the users' requirements,we
may
have
to obtain data for a child account. Forexample, Dataline
does
not provide data for"Accounts
Receivable" butdoes
provide thesum
of"Accounts Receivable"
and
"Notes Receivable"under
thename
of "Debtors." Ifwe
have
to calculatethe accounts-receivable turn over ratio, then a lessaggregated child account will
be
needed.Although
we
still won't be able to obtain data for accounts receivablefrom
Dataline in that case, the data fordebtorscan be used toverify thedata
from
LotusOnc
and
Disclosure.Tables 2
and
3 present the data for the balance sheetand
theincome
statementofVolvo from
LotusOne,
Disclosure,and
Dataline respectively. At this stage, the data for each account willbe
compared and
the three financial statements willbemerged
intoone.Table
2:Comparison
of theBalance Sheet
forVolvo
(1988)UNIT
CONVERSION
The
three databases use different units in representing values for each account. Consequently,the values for the
same
account appear to be different. For example, intangible assets is recorded as29700Uin LotusOnc, 0.3 in Disclosure,
and
297in Dataline. Thesethree valuesappeartobeinconsistent.However,
they are essentially thesame
becauseLotusOne
reports the data inSwedish
Kronor,Dataline in
thousands
ofSwedish
kronor,and
Disclosure in millions ofSwedish
kronor (round up).Therefore,before
moving
on
tothenextstep, the unitsshould beadjusted sothattheaccountvaluesfrom
each database can be
compared.
Research issues related to unit conversion hasbeen
addressedelsewhere (Rigaldies, 1990).
MODEL-BASED
lUDGEMENT
The
conflicts at the account data level can be classified intotwo
categories: (1) databasesprovide inconsistent data for the
same
entities,and
(2) account data for certain databases are notavailable.
In reconciling these conflicts,
we
need certain rulesto evaluate the reliability of the datafrom
each database.
We
apply the accountingmodel
presented in Section II to reconcile conflicts at theaccount data level.
The two examples
of data level conflictsbelow
illustratehow
the explicitand
implicit relationshipsrepresented in the accounting
model
can beexploited.Example
1.As shown
inTable 2, Lotusreports 15610000forgrossfixed assets. Disclosure 15.61,and
Dataline 30236.At first glance, it appears that the difference
between
15610000and
15.61 isdue
to unitdifference
and
Dataline's 30236 is a typo. Therefore,one
may
conclude that 15.61 millions shouldbe
usedforgrossfixedassets.
However,
from
the accounting model,we
can find that "Net Fixed Assets" = "Gross FixedAssets" -
"Accumulated
Depreciation."From
this relationship,we
can inferwhich
data ismore
reliable.
Both
LotusOne and
Disclosuredo
not providedata for"Accumulated
Depreciation"and
containthe
same number
for both "Gross Fixed Assets"and
"Net Fixed Assets"which does
not satisfy theimplicit relationship that gross fixed assets should be less than net fixed assets. In contrast, Dataline
not only provides data for all of the three accounts but also provides data values
which
satisfy therelationship.
From
this fact,one
would
infer that Dataline providesmore
reliable data for "GrossFixed Assets"
and "Accumulated
Depreciation." Therefore,30236thousands should be usedinstead.Example
2.As
shown
inTable 3, Lotus reports19529000 forgross profit.Disclosure 19.53,and
Dataline 7186.
The
data for "Gross profit"from
Dataline areless reliable than those ofLotusOne and
Disclosurefor thefollowingreasons:
•
The
itemswhich
arc associated with "Gross Profit" are "CostofGoods
Sold"and
"NetSales" (SeeFigure 3). Since Datalinedocsnot provide
any
data for "CostofGoods
Sold"which
is required tocalculate "GrossProfit,"
we
cannot verify the figure for "GrossProfit"from
Dataline.•
The
othertwo
databases,LotusOne and
Disclosure, provide data forboth "CostofGoods
Sold"and
"Net Sales"
and
the data for "Gross Profit" is consistent with the explicit relationship of "GrossProfit" = "NetSales" - "Cost
Of
Goods
Sold."The
above
observation suggests thatnone
of the databasesdominate
others in terms ofreliability. Consequently,
when
we
encounter account data level inconsistencies,we
should infer datareliability, case
by
case, with the help of the following rules.1.
Use
theknowledge
represented in the accountingmodel
to find the relationshipwhich
links theassociatedaccountstotheaccountinquestion.
2. Verify the data
from
each databaseby
using the relationship. Indoing
so,pay
attention to theimplicit relationships as well as the explicit relationships.
3. If thevalues fi:om certain databases
do
not satisfy the relationship, then discard them.4. If
no
associated item orrelationshipcan befound, or theinconsistenciescannotbereconciled throughthe above-mentioned steps, then apply the majority rule.
These
ruleshave been
successfully applied to all of the data inconsistencies at the accountvalue level in the process of producing integrated financial statements.
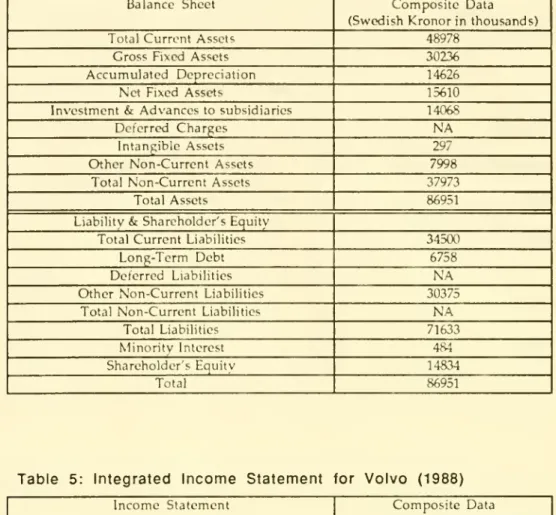
The
integrated balance sheetand income
statement forVolvo
is presented inTable 4and
Table 5 respectively.Table
4: IntegratedBalance
Sheet
forVolvo
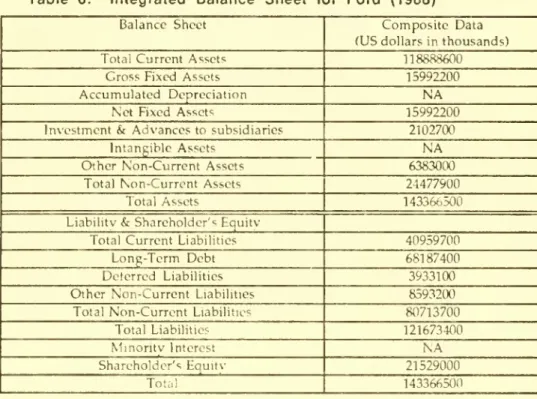
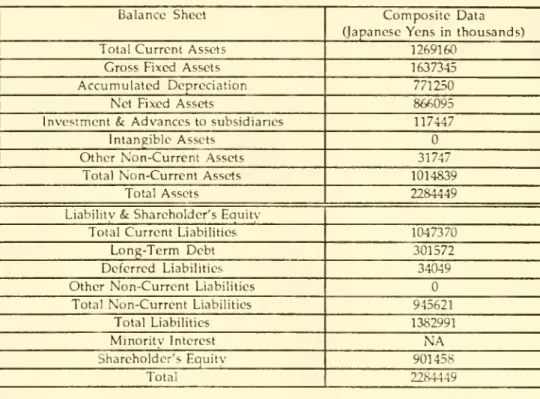
(1988)Tables8-9 respectively.
We
arenow
in a position tocompute
profitabilityratios foreach of these threecompanies,as discussed in thefollowingsection.
Table
6: IntegratedBalance
Sheet
forFord
(1988)Table
8: IntegratedBalance
Sheet
forHonda
(1988)V.
Profitability
Analysis
The most
widely-used profitability ratios areGross
Profit Rate (GPR),ROE
(ReturnOn
Equity),
ROA
(ReturnOn
Asset),and
ROS
(ReturnOn
Sales). Table 10shows
these popularprofitability ratios.
Table
10: Profitability Ratios RatioSince the costof
goods
soldand income
beforetaxdepends on
theaccounting principlesadopted intheinventory
and
depreciation evaluation, the financial ratios are functions of the accounting principles.The
discussion of theseissues isbeyond
thescopeofthis paper.VI.
Concluding
Remarks
We
have
presented a topvdown, accountingmodel-based approach
forproducing
integratedbalance sheets
and income
statements. In addition, profitability ratios for Volvo, Ford,and
Honda
have been
computed
basedon
the integrated financial statementscomposed
of datafrom
Finsbury'sDataline, l.P. Sharp's Disclosure,
and
Lotus'LotusOne
databases. Thisapproach
has enabled financialanalysts tofocus
on
theapplication requirementsthatmost
concerned them,namely
utilizing integratedfinancial statements for tasks such as profitability analysis.
We
have
focusedon
thefundamental
accounting principles pertinent to financial statementconstruction.
By
virtue ofitsrigorous nature, the accountingdisciplinelendsitselfto a solidfoundationfor reconciling semantic heterogeneity inherent in disparate financial accounting databases.
The
requirement to balance all the accounts has enabled us to evaluate the reliability
and
validity offinancial data retrieved
from
heterogeneous database systems.Our
research thrust isto providea model-based interface forbusinessapplications.The
model-based
approach
checks the reliabilityand
validity of data retrievedfrom
various data sources usingknowledge encoded
in financial models. Thiswould
facilitate access toand
seamless integration offinancial data stored in heterogeneous database systems.
We
believe that this effort will not onlycontribute to the
academic
research frontierbut alsobenefit the businesscommunity
in theforeseeablefuture.
VL
Bibliography
[I] Batini,
C,
Lenzirini, M.,&
Navathe, S. (1986).A
comparative analysis of methodologies for databaseschema
integration.ACM
Computing Survey, 1£(4),pp. 323 -364.[2] Bhargava, H.
&
Kimbrough,
S. (1990).On
Embedded
Languages forModel
Management.
Proceedings of theTwenty-Third
Annual Hawaii
International Conferenceon System
Sciences. Hawaii. January 1990.[3] Bhargava, H.,
Kimbrough,
S.,&
Krishnan, R. (1989).Unique
Names
Violations:A
Problem
forModel
Integration orYou
Say Tomato, I SayTomahto.
To Appear inORSA,
journalon Computing,.[4] Breitbart, Y., Olson, P. L.,
&
Thompson,
G. R. (1986). Database integration in a distributedheterogeneous database system. Los Angeles,
CA.
February 1986. pp. 301-310.[5] Brill, D., Templeton, M.,
&
Yu, C. (1984). Distributed query processing strategies inMERMAID,
afrontend to data
management
systems. First International Conferenceon
Data Engineering. LosAngeles,
CA.
February 1984.pp. 301-310.[6]
Chen,
P.&
Wang,
Y. R. (1990).An
Entity-Relationship Approach for Accounting Systems with Multiple Data Sources. (ClS-90-32)MIT
Sloan School ofManagement.
October 1990.[7] Czejdo, B., Rusinkiewicz, M.,
&
Embley,
D. (1987).An
approach to schema integration and query formulation in federated database systems.The
3rd International Conferenceon
Data Engineering.LosAngeles,
CA.
1987.pp. 477-484.[8] Dayal, U.
&
Hwang,
K. (1984).View
definitionand
generalization for database integration in multidatabasc system.IEEE
Transactions on Software Engineering, SE-10, pp. 628-644.[9] Decn, S. M.,
Amin,
R. R.,&
C,
T.M.
(1987). Data integration in distributed databases./£££
Transactions on Software Engineering, SE-13. pp. 860-864.[10] Dolk, D. R. (1986).
A
GeneralizedModel
Management
System
for MathematicalProgramming.
ACM
Transactions on Mathematical Software, 72(2), pp. 92-126.[II] Dolk, D. R. (1988).
Model
Management
and
Structured Modeling:The
Role of an Information Resource Dictionary System. Cotnmunications oftheACM,
21(6), pp. 704-718.[12] Dolk, D. R.
&
Konsynski, B. R. (1984).Knowledge
Representation forModel
Management
System.IEEE
Transactions on Software Engineering,SE-7Q
(6). pp. 619-628.[13]
Elmagarmid,
A. K., et al. (1990).A
multidatabasc transaction model for InterBase.To
Appear
in the 16th International Conferenceon
Very
Large Data Bases. Brisbane, Australia.August
1990. [14] Elmasri, R., Larson, J.,&
Navathe,
S. (1987).Schema
integration algorithms for federateddatabases and logical database design.
Honeywell
Inc., Submitted for Publication. 1987.[15] Ferrier, A.
&
Strangret, C. (1982). Heterogenity in the distributed databasemanagement
systemsSirius-Delta.
The
8th International Conferenceon
Very
Large Data Bases.Mexico
City, Mexico. 1982.[16] Foster,G. (1986). Financial Statement Analysis (2nd ed.).
New
Jersey: Prentice - Hall, Inc.[17]
Codes,
D. B. (1989). Use of heterogeneous data sources: three case studies. (CIS-89-02)Sloan
School of
Management,
MIT,Cambridge,MA.
June 1989.[18]
Goodhue,
D. L., Quillard, J. A.,&
Rockart, J. F. (1988).Managing The
Data Resources:A
Contingency Perspective.
MIS
Quarterly, 12(3), pp. 373-392.[19] Gupta, A., ct al. (1989).
An
architecture comparison of contemporary approaches and products forintegrating heterogeneous information systems. Sloan School of
Management,
MIT, Cambridge,
MA
02139.1989.[20] Heimbigncr, D.
&
McLeod,
D. (1985).A
Federated architecture for informationmanagement.
ACM
Transactions on Office Information Systems, 1, pp. 253-278.
[211 Kohler, E. L. (1983).
A
Dictionaryfor Accountants .New
Jersey: Prentice - Hall, Inc.122] Litwin,
W.
&
Abdellatif, A. (1986). Multidatabase interoperability./£££
Computer, , pp. 10-18.[23] Litwin, W., et al. (1982).
SIRIUS
system for distributed datamanagement.
InternationalSymposium
on
Distributed Databases. Berlin,West Germany.
1982.pp. 311-366.124)
Lyngbaek,
P.&
McLeod,
D. (1983).An
approach to object sharing in distributed database systems.The
9th InternationalConferenceon Very
Large Data Bases. October1983. pp. 364-374.[25]
Madnick,
S. E., Siegcl, M.,&
Wang,
Y. R. (1990).The Composite
InformationSystems
Laboratory(CISL) project at MIT.
/£££
Data Engineering, ii(2), pp. 10-15.(26)
Madnick,
S E.&
Wang,
Y. R. (1986). Key Concerns ofExecutivesMaking
IS Decisions. 21stHawaii
International Conference
on System
Sciences. Kailu-Kona, Hawaii. January 1986.pp. 254-260.[27]
McCarthy,
W.
E. (1979).An
Entity-RelationshipView
ofAccounting
Models. The AccountingReview, 54(4), pp. 667-686.
McCarthy,
W.
E. (1982).The
REA
Accounting Model:A
GeneralizedFramework
forAccounting
Systems
in a Shared Data Environment. The Accounting Review, 5Z(3), pp. 667-686.[28
[29 Paget,
M.
L. (1989).A
knowledge-based approach toward integrating international on-linedatabases. (CIS-89-01)Sloan School of
Management, MIT, Cambridge,
MA.
May
1989.[30] Reiner, D. (1990). Special Issue
on
Database Connectivity./£££
Data Engineering, 12(2), pp. 52. [31] Rigaldics, B. (1990). Technologies and Policies for the Development ofCIS
in DecentralizedOrganizations.
(WP#
ClS-90-05)Master Thesis,MIT
Sloan School ofManagement.
May
1990. [32] Rockart, J. F.&
Short, ]. E. (1989). IT in the 1990s:Managing
Organizational Interdependence.Sloan
Management
Review, Sloan School ofManagement, MIT,
lfl(2), pp. 7-17.[33] Smith, J. M., et al. (1981). Multibase - Integrating Heterogeneous Distributed Database Systems.
1981 National
Computer
Conference. 1981. pp. 487-499.[34]
Wang,
Y. R.&
Madnick,
S. E. (1988). Connectivityamong
information systems .Cambridge,
Mass.:Composite
InformationSystems
(CIS) Project,MIT
Sloan SchoolofManagement.
[35]
Wang,
Y. R.&
Madnick,
S. E. (1990).A
Source Tagging Theory for Heterogeneous DatabaseSystems.
To Appear
in the 11th International Conferenceon
Information Systems.Copenhagen,
Denmark.
December
1990.[36]
Wicderhold,
G. (1987).KSYS:
an architecture for integrating databases and knowledge bases.Computer
Science Department, Stanford University, Stanford,CA
94305. 1987.[37]
Yuan,
Y. (1990). The design and implementation of system P:A
polygen databasemasnagement
system. (ClS-90-07)
Composite
InformationSystems
Laboratory, Sloan School ofManagement,
MIT,
Cambridge,
MA. May
1990.?96^
062
Date
Due
btP
1
193|l
Mil IIBRARIES