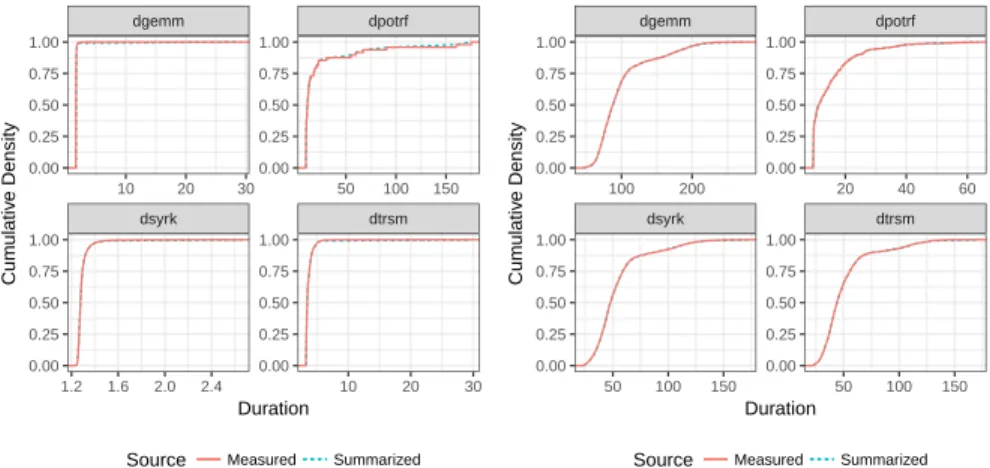
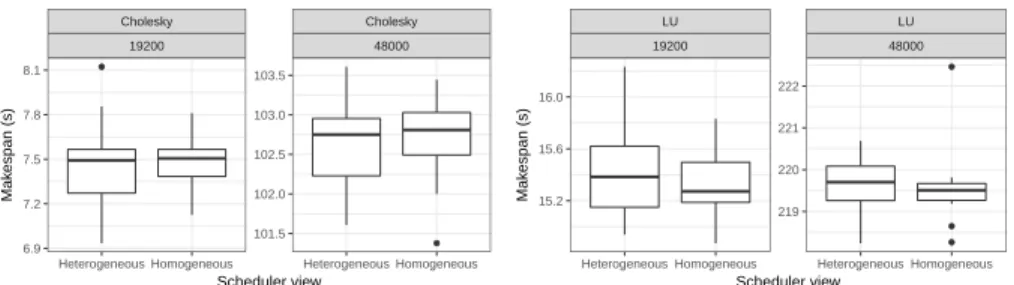
Influence of Tasks Duration Variability on Task-Based Runtime Schedulers
19
0
0
Texte intégral
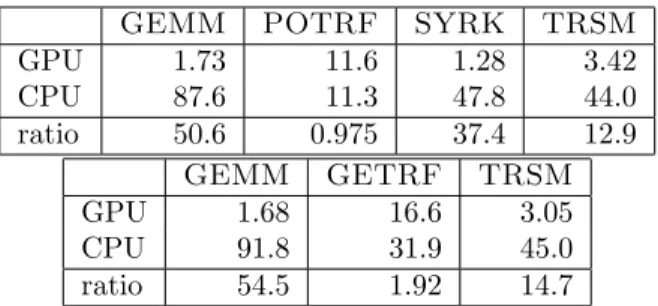
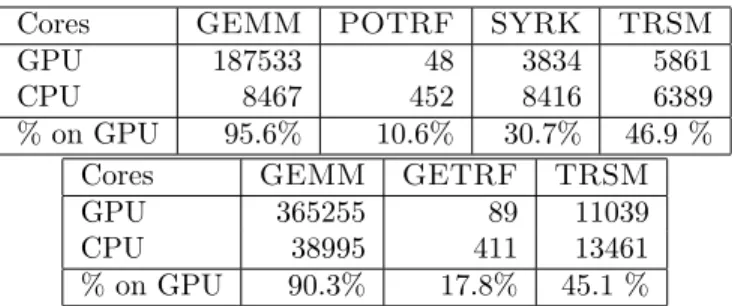
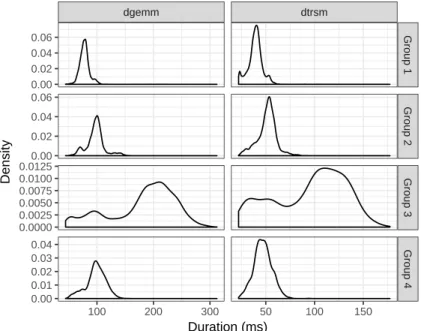
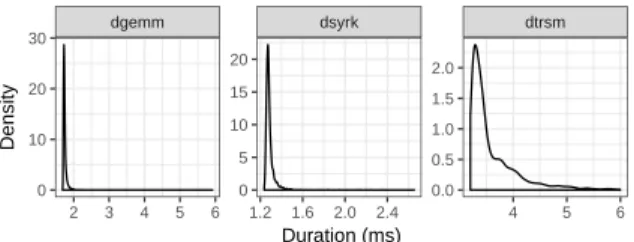
(2)
(3)
(4)
(5)
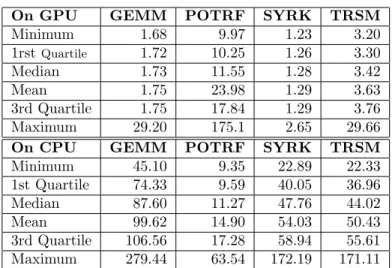
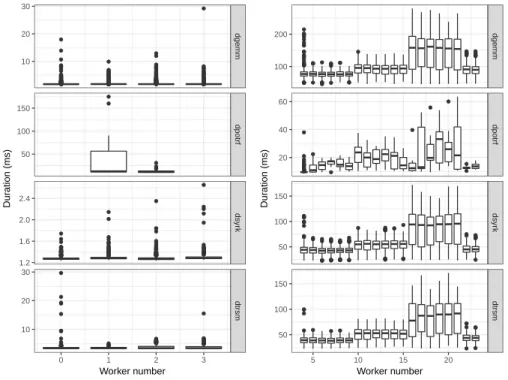
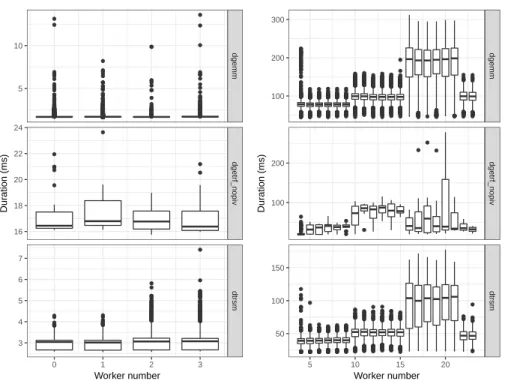
(6)
(7)
(8)
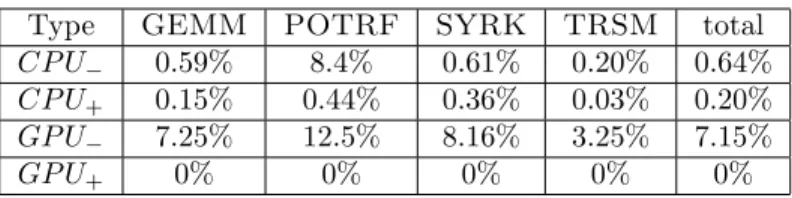
(9)
(10)
Figure
+7
Documents relatifs
For our study, we analyzed reproductive success of female and male Barbary macaques living in 1 group in the provisioned, free-ranging colony on Gibraltar over a period of 6 yr
When examining the between methods RV coefficients (e.g., metabolic profiling convergence between NMR and LCMS), the values decreased from *0.75 in Test #1 (urine samples) to 0.54
The phasing of precession and obliquity appears to influence the persistence of interglacial conditions over one or two in- solation peaks: the longest interglacials are
[r]
We conjecture that the right choice of weights could help to improve matrix factorization results on analogy questions, where skip- gram with negative sampling (SGNS) remains
They showed that the problem is NP -complete in the strong sense even if each product appears in at most three shops and each shop sells exactly three products, as well as in the
represents an irrational number.. Hence, large partial quotients yield good rational approximations by truncating the continued fraction expansion just before the given
Florian Lemaitre 1,2,3 , Camille Tron 1,2,3 , Caroline Jezequel 4 Marie-Clémence Verdier 1,2,3 , Michel Rayar 2,4.. 1 Service de Pharmacologie Clinique et épidémiologique,
![[PDF] Tutoriel pdf Arduino DHT11 [Eng] | Cours Arduino](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)