Publisher’s version / Version de l'éditeur:
Vous avez des questions? Nous pouvons vous aider. Pour communiquer directement avec un auteur, consultez la première page de la revue dans laquelle son article a été publié afin de trouver ses coordonnées. Si vous n’arrivez pas à les repérer, communiquez avec nous à [email protected].
Questions? Contact the NRC Publications Archive team at
[email protected]. If you wish to email the authors directly, please see the first page of the publication for their contact information.
https://publications-cnrc.canada.ca/fra/droits
L’accès à ce site Web et l’utilisation de son contenu sont assujettis aux conditions présentées dans le site LISEZ CES CONDITIONS ATTENTIVEMENT AVANT D’UTILISER CE SITE WEB.
The Ninth Conference of the Association for Machine Translation in the Americas
(AMTA) [Proceedings], 2010-12-01
READ THESE TERMS AND CONDITIONS CAREFULLY BEFORE USING THIS WEBSITE. https://nrc-publications.canada.ca/eng/copyright
NRC Publications Archive Record / Notice des Archives des publications du CNRC :
https://nrc-publications.canada.ca/eng/view/object/?id=0ef63443-5a4e-442f-8944-118cc9ddd266
https://publications-cnrc.canada.ca/fra/voir/objet/?id=0ef63443-5a4e-442f-8944-118cc9ddd266
NRC Publications Archive
Archives des publications du CNRC
This publication could be one of several versions: author’s original, accepted manuscript or the publisher’s version. / La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur.
Access and use of this website and the material on it are subject to the Terms and Conditions set forth at
Using WeBiText to Search Multilingual Web Sites
Using WeBiText to Search Multilingual Web Sites
Alain Désilets
National Research Council of Canada
[email protected]
Benoit Farley
National Research Council of Canada
[email protected]
Frances Urdininea
Translation Bureau of Canada
[email protected]
Marta Stojanovic
National Research Council of Canada
[email protected]
ABSTRACT
In this paper, we describe WeBiText (www.webitext.ca) and how it is being used. WeBiText is a concordancer that allows translators to search in large, high-quality multilingual web sites, in order to find solutions to translation problems. After a quick overview of the system, we present results from an analysis of its logs, which provides a picture of how the tool is being used and how well it performs. We show that it is mostly used to find solutions for short, two or three word translation problems. The system produces at least one hit for 58% of the queries, and hits from at least five different web pages in 41% of cases. We show that 36% of the queries correspond to specialized language problems, which is much higher than what was previously reported for a similar concordancer based on the Canadian Hansard (TransSearch). We also provide a back of the envelope calculation of the current economic impact of the tool, which we estimate at $1 million per year, and growing rapidly.
Keywords
WeBiText, multilingual concordancer, Translation Memory, web parallel corpora
1.
INTRODUCTION
In spite of the growing availability of Translation Memory tools, field observations conducted by Désilets et al. (2008) indicate that translators often use web search engines (like Google), to manually search in bilingual web sites, particularly those produced by government and international organizations (ex: Canadian government, European Union organizations). This manual procedure is fairly involved, and a conservative estimate is that it requires in the order of two minutes to retrieve a single pair of aligned sentences1. When asked why they used this manual
web search approach instead of searching in a Translation Memory (TM), translators interviewed evoked a variety of reasons. For freelance and for amateur translators, this was a way to tap into parallel corpora which are much larger than their own private translation archives. For translators working in organizations that had large TMs, this was seen as a way to tap into additional top quality corpora, the assumption being that if
1
Anecdotal evidence from field interviews and informal discussion with several translators. See Désilets et al, 2008 for a complete description of this manual procedure.
something is published on the web by a government or international organization, its quality must be high.
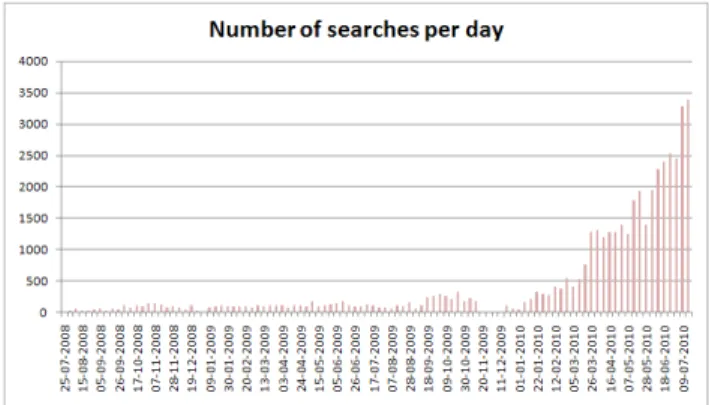
In order to facilitate this common practice, we built WeBiText (www.webitext.ca), a system that allows translators to retrieve several pairs of relevant sentences from multilingual web sites in a matter of seconds, saving them both time and cognitive effort. The system has been freely available since July of 2008, but it has only been actively advertised since December 2009, at which point it started experiencing rapid and steady growth (see Figure 1). In this paper, we focus on the system from a user's perspective, and in particular, on how translators have been using it for two years. For details on the inner workings of the system, the reader is referred to Désilets et al., 2008.
The remainder of the paper is organized as follows. In section 2, we provide an overview of the system's functionality from the point of view of end users. In section 3, we carry out an analysis of the system's logs, in order to understand how it is actually being used and how well it performs. In section 4, we provide a back of the envelope calculation of the system's current economic impact. Finally, section 5 presents conclusions and areas for future research and development.
Figure 1: Average number of daily queries on a week by week basis. The short gap from mid-November to mid-December 2009 is due to the fact that the system logs for that period were lost in the process of migrating the system to a new machine.
2.
SYSTEM OVERVIEW
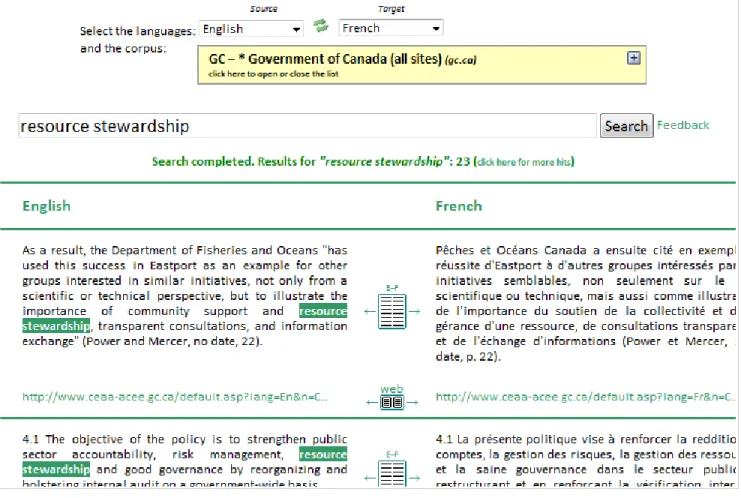
Figure 2 depicts the system's main screen. The user starts by selecting the source and target languages (which default to English-French, or to the last pair used) and then selects a web domain from the lists of corpora. This list only includes sites that have parallel content in the selected languages, and the default corpus is set to a domain that is known to work well for that particular pair (ex: Government of Canada web sites for English-French). The user enters the query expression in source language and hits the Search button, at which point the system starts searching and showing relevant sentence pairs in a familiar side-by-side display.
It is worth noting that WeBiText does not actually prealign content from multilingual web sites. Instead, it invokes the Yahoo search engine to find pages on the selected web domain that contain the query expression, and then uses a number of heuristics to identify the corresponding pages in the target language. The system then downloads the source and target language pages and aligns them on the fly, displaying as many hits as it can find in 90 seconds. The advantage of this approach is that it makes it easy to add new web domains to the list of corpora, without incurring the cost of large scale crawling and alignment. The disadvantage is that it is slow, and may require several seconds to process a single pair of pages. However, because the system prints results as soon as if finds them, the first hits is
displayed within an average of three seconds, while hits from the first five pages are displayed within an average of eight seconds (see Section 3.3 for details). Feedback from users indicate that this response time is acceptable. As we pointed out in the introduction, translators currently carry out this kind of search manually, and it takes them an estimated two minutes or more to retrieve a single pair of aligned sentences. Also, translators rarely need to consult more than a few sentence pairs to find a relevant solution to a translation problem, so they may not need to wait for the full list of hits to be displayed before coming to a decision. The list of results comes with features that allow translators to assess the trustworthiness of a given sentence pair. The URL of the pages is provided, so that translators can tell what specific organization published the document. Each hit also comes with two buttons (located between the source and target language sentences) which allow users to see sentences in context. Clicking the first button opens a side-by-side aligned display of all sentences pairs that come from the same page as that particular hit (not shown). Clicking the second button opens up a side-by-side display of the two pages exactly as they appear on the web (Figure 3). One might think that this second display is not as useful as the first one, because sentences are not presented as aligned pairs. However this turns out to be one of the features most frequently praised by our users. User feedback indicates that this web display allows them to immediately get a sense of the type of document at hand (ex: is it a “high profile” document
destined to the public at large, or a more internal memo?), which turns out to be important for assessing its trustworthiness. Also, it gives users a feel for the relative importance of the text in which the query expression appears inside the document (ex: does it appear in a title with large font, or in a caption with small font?), which is also useful for assessing the trustworthiness of a given sentence pair.
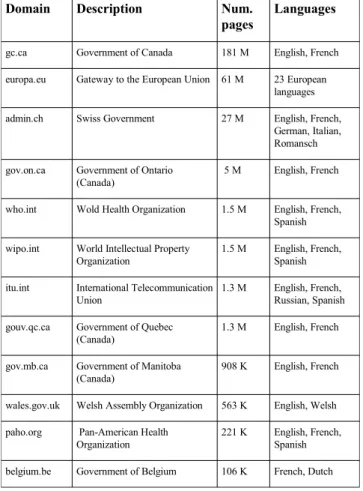
Table 1 lists the 12 most important web domains (i.e., those with 100,000 pages or more) included in WeBiText. In total, the system currently support 26 domains, for a total of 285 million pages approximately. These domains cover a total of 30 languages, mostly European ones. However the system does include content in some more “exotic” languages like Inuktitut (the language of the Inuit people of Canada) and Haitian Creole. It is worth noting that not all languages are served equally well by the system. The best supported pair is English-French, thanks to the very large, comprehensive and diligently translated gc.ca domain (Government of Canada sites). For other language pairs, mileage may vary.
3.
LOG ANALYSIS
WeBiText has been freely available on the web since July 2008 and in that time, users have issued a total of 246,962 searches to it. In this section, we analyze the system logs in order to better understand how the tool is actually being used, and how well it performs.
We analyze two logs. The first one is the Apache log, which spans the complete history of WeBiText, from July 27th, 2008 to July
15th, 2010, except for a short period from November to
mid-December 2009 which was lost when we migrated the system to a new server. This log provides information about how users have been using WeBiText since day one, but it does not provide information about its performance. The second log we analyze is a custom WeBiText log that was deployed in June 2010. The later provides additional information about the performance of the system for each of the queries, but it only covers the period from June 18th to July 14th, 2010.
3.1
Who uses WeBiText?
A first question to ask is how many people use the system? Because we do not require users to register, we are not able to
determine that number exactly. However, WeBiText does track users through system assigned Global Unique Identifiers (guid)2
which are stored as cookies on the user's machine. By counting the number of distinct guids that appear in the log file, we can get an estimate of the number of users. Note however that this is not an exact count, because a same person may use WeBiText from different machines (for example at work and at home, or because they bought a new machine during the period covered by the log), resulting in different guids. Also, some users do not have cookies enabled in their browser, resulting in empty guids.
Looking at the recently deployed WeBiText log, we find a total of 61,228 queries, of which 56,782 were associated with a total of 1,023 guids, for an average of 55.5 queries per guid. The remaining 4,446 queries (7%) did not have guids, because cookies were disabled on those users' browser.
A very conservative upper bound on the number of people who used the system during that month would thus be 5,469 (i.e., 1,023 + 4,446). This assumes that each guid corresponds to a single user and that every user who had cookies disabled used WeBiText only once. A more realistic upper bound can be derived by assuming that those who disable cookies use WeBiText at the same frequency as those who enable them (i.e., 55.5 queries for the period covered by the log). With that assumption, we can say
2 Global Unique Identifier:
http://en.wikipedia.org/wiki/Globally_unique_identifier
Domain Description Num.
pages
Languages
gc.ca Government of Canada 181 M English, French
europa.eu Gateway to the European Union 61 M 23 European languages
admin.ch Swiss Government 27 M English, French, German, Italian, Romansch
gov.on.ca Government of Ontario (Canada)
5 M English, French
who.int Wold Health Organization 1.5 M English, French, Spanish
wipo.int World Intellectual Property Organization
1.5 M English, French, Spanish
itu.int International Telecommunication Union
1.3 M English, French, Russian, Spanish
gouv.qc.ca Government of Quebec (Canada)
1.3 M English, French
gov.mb.ca Government of Manitoba (Canada)
908 K English, French
wales.gov.uk Welsh Assembly Organization 563 K English, Welsh
paho.org Pan-American Health Organization
221 K English, French, Spanish
belgium.be Government of Belgium 106 K French, Dutch
Table 1: List of 12 largest web domains included in WeBiText. Number of pages estimated using Google.
that, had those users activated cookies in their browser, we would have received an additional 80 guids (i.e., 4,446/55.5), for a total of 1,103. Again, assuming that every guid corresponds to a unique user, this would lead us to estimate the size of the user population to be at most 1,103. As pointed out earlier, some users may end up generating more than one guid. For example, if we assume that every user accesses WeBiText from two machines, one at home and one at work, then our estimate would be 551 users (= 1,103/2).
While the above numbers are far from exact, they do give an idea of the order of magnitude of our current user population, which seems to be between a few hundred and a few thousand.
Another interesting issue is the provenance of users. Analyzing the IP addresses of queries in the Apache log, we find that 95% of them originate from Canada. As shown in Figure 4, the bulk of them (64.3%) originate from IP address which are registered to the name of an Internet Service Provides (ISP). We hypothesize that these are predominantly freelancers who access the system through their home internet connection. This is consistent with our field interviews which indicate that multilingual web sites are particularly useful for freelancers who may not have large amounts of multilingual data to pour into a Translation Memory (Désilets et al, 2008). Another 28.2% of queries originate from various Canadian government ministries and departments. This is understandable, given that Government of Canada web sites represent the largest and most diligently translated domain among the list of corpora offered by the system. The next three market segments are much smaller. There is a 3.6% of queries that comes from known large Language Service Providers (LSP), and a small 0.4% that come from universities, where the system is typically used to teach translation students how to work with large multilingual corpora. Finally, 3.5% of queries originate from miscellaneous organizations that could not be classified into specific market segments.
3.2
What do Users Search For?
Given that most queries originate from Canada, it is not surprising that 97% of them involve the English-French pair (with 89% in that direction and 8% in the opposite one), and that the most commonly used corpus is the Government of Canada domain (77% of queries). The next language pair is English-Spanish, with 1.2% of queries (0.8% in that direction, and 0.4% in the opposite one).
Interestingly enough, a fair number of users have told us that they employ the English-French Government of Canada corpus (gc.ca) to help them translate from English to other Latin languages, such as Spanish and Portuguese, which are less data rich than French. When equivalents cannot be found directly in parallel corpora for the original target language, those translators turn to French as a pivot language. Because French is so similar to other Latin languages, equivalents found there often provide strong hints for the original target language. For example, say the translator is looking for a Spanish equivalent for low-bush blueberries, but cannot find it in an English-Spanish corpus. Searching on the Government of Canada corpus, he finds the French equivalent
bleuets cultivés (cultivated blueberries) which, to a Spanish
speaker, immediately suggests a potential equivalent: arándanos
cultivados. Googling for that Spanish term, the user finds several
hundreds of hits, which confirms the validity of this potential solution.
From our recent field interviews and interactions with translators, it seems that this use of pivot languages is not limited to Latin languages. Indeed, we have also witnessed or heard about the use of this technique for Germanic and Slavic languages (where German and Russian are the respective pivots). Some users have told us that pivot-language equivalents can provide useful inspiration, even when the pivot and target languages are not similar. In the case of low-bush blueberries for example, the French equivalent suggests that, in some languages at least, this type of blueberry is described as being “cultivated”, as opposed to “growing on low bushes”, and this may apply in other languages, even non Latin ones.
In the context of WeBiText, the fact that translators use this kind of technique is an interesting finding. It implies that the tool can be useful, even for languages for which there is not a lot of parallel data on the web, especially (but not only) if there is a similar language for which such data is available.
As Figure 5 shows, user queries are fairly short. Indeed, 79% of them have 3 words or less, for an average of 2.7 words per query. This is in the same range, but somewhat longer than what Simard and Macklovitch (2005) reported in their log analysis of TransSearch, a similar concordancer based on the Canadian Hansard (i.e., transcripts of debates at the Canadian Parliament). Indeed, these authors found that 85% of their queries had 2 words or less.
Figure 5: Histogram of query lengths. Figure 4: Provenance of queries
Macklovitch et al (2008) found that TransSearch was used almost exclusively for general language expressions such as “in a timely
manner”. This is understandable, given that the Canadian
Hansard is not a specialized corpus, and one would therefore not expect to find solutions to specialized problems there. In contrast, Désilets et al (2008) found that a larger and more varied corpus harvested from Canadian Government web sites was able to address more of these specialized problems than the Hansard. Therefore, an interesting question to ask is whether translators actually take advantage of this potential in WeBiText.
In order to answer this question, we generated a random sample of 100 queries taken from the log, and showed them to four experts in the field of translation. We asked each of them to independently categorize the query as being of a general or specialized nature. Table 2 shows the result of these assessments. Agreement between experts was 0.717, with a Fleiss' Kappa3 value of 0.433. The fact
that this number is higher than zero indicates that agreement was higher than would be expected by chance alone. Of those hundred queries, 18% were unanimously judged to be specialized, while 36% were judged to be specialized by at least three of the four
3 Fleiss' Kappa statistic:
http://en.wikipedia.org/wiki/Fleiss%27_kappa
experts. As can bee seen from Figure 6, the majority of those indeed seem to be of a specialized nature. Based on this, we conclude that translators do make significant use of WeBiText for specialized language problems, even though general language problems still seem to dominate with an estimated 64% of queries.
3.3
Performance
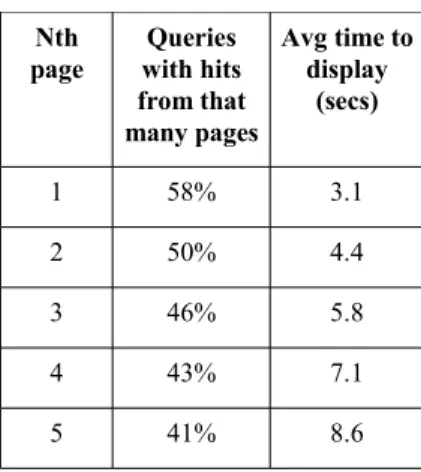
Table 3 provides statistics on the system's performance, for those queries contained in the custom WeBiText log. We see that the system displays at least one hit for 58% of queries, and in 41% of the cases, it displays hits from at least five distinct pages. This is excellent coverage, considering that WeBiText is not a custom Translation Memory built for a specific domain or customer. The average time required to process and display a first hit is 3.1 seconds, while it takes an average of 8.6 seconds to process and display hits of the first five pages. While this may seem slow compared to a conventional Translation Memory or a web search engine like Google, remember that WeBiText does not pre-process the content of web sites, and that content must be downloaded and aligned on the fly, based on the user's query. In any case, user feedback indicates that this response time is acceptable, certainly compared to the two minutes or more that are required to perform this operation manually with conventional web search engines. Note however that this has not always been the case. Early versions of the system displayed results in bulk, only after all potential results had been found or the maximum of 90 seconds had been exhausted. This meant that users often had to wait the full 90 seconds allotted by WeBiText, before they could see a first hit. Understandably, the most common user request at the time was to increase the system's speed. Since then, we modified the system so that it displays individual hits as soon as it finds them, and we now seldom receive complaints about speed.
4.
ECONOMIC IMPACT
While the number of queries may seem low (~3.5 thousand per day), remember that each of them can potentially save two or more minutes for some translator. But what does this kind of traffic actually represent in terms of economic impact? In this
Nth page Queries with hits from that many pages Avg time to display (secs) 1 58% 3.1 2 50% 4.4 3 46% 5.8 4 43% 7.1 5 41% 8.6
Table 3: Performance statistics for WeBiText. First column represents the percentage of queries that display hits from at least N pages (N=1,...,5). Second column gives the average time required to display hits from that many pages.
4 out of 4
Social Protection; activation of a switch; R.S.; primary hypercholesterolemia; CHRC Synopsis; Building Emergency Organization; RCMP Commissioner; Respiratory Services; petagron; paper session; Gateway to the European Union; sexual health; cyber capability; youth law; Leopard 1 tank; mechanical sleeve; Section 1535 Capital Disclosures establishes standards for disclosing information about an entity capital and how it is managed;
3 out of 4
IP properties; devolution of management; preferential shelf space; accord national interprofessionnel; employment equity representation; candidate limitations; table skills; Tsawwasse; final agreement; apprenticeship program; sphere core; packaging labeling system; representations and warranties; ratification draft; complementary and equally crucial supports; benefit of investment; risk-based internal audit plan; public health significance; green energy; I consent to the use and disclosure of;
Figure 6: List of queries from our sample, which were deemed to be specialized by three experts or more.
Number of queries in sample 100
Number of experts 4
Percentage overall agreement 0.717
Free marginal Kappa statistic 0.433
Unanimously categorized as specialized 18%
Categorized as specialized by at least 3 out of 4 experts
36%
Table 2: Classification of WeBiText query expressions into general versus specialized language by four experts.
section we present a back of the envelope calculation which provides a tentative answer to this question.
As of this writing, in the most recent week (July 5th to 11th, 2010) WeBiText answered a total of 17,016 queries, with an average of 3,500 queries per work day. However, not all of those end up saving time for the translator. Indeed, in cases where the query expression is not present at all on the bilingual web domain being searched, it takes the same short amount of time to find out, whether the translator is searching with WeBiText or manually with Google. As pointed earlier, WeBiText produces at least one hit in 58% of cases, therefore we estimate the average time saved per query to be 1.16 minutes (i.e., 2 mins * 0.58). Multiplying the weekly number of queries by these 1.16 minutes, we find that the system is currently responsible for productivity gains of 329 hours per week. Assuming that translators work 37.5 hours per week, these productivity gains currently amount to 8.8 Full Time Equivalents (FTEs). Assuming an average annual salary of $58,000 per translator4, and multiplying it by two for benefits and
overhead, we get an average annual cost of $116 000 per FTE. Multiplying the 8.8 FTEs by that figure, the current worldwide productivity gains attributable to WeBiText can be valued at $1 million per year.
Note that this level of impact was achieved in spite of very little promotion. Although the tool has been freely available on the web since July 2008, it was not actively promoted in translator oriented venues until December of 2009, when it was presented at the annual meeting of the Canadian Language Industry Alliance (AILIA). Since then, the system has seen fast and steady growth (see Figure 1). Therefore, we can expect the economic impact of WeBiText to continue growing for some time. Of course, this growth is bound to slow down at some point, and we cannot predict the height of the ceiling it will eventually reach. However, two factors lead us to think that it may be high.
Firstly, WeBiText automates a search process which, according to our field observations, is frequently done manually by translators of all types. Indeed, most of the translators we observed carried out at least one manual search on a bilingual web site during the hour where we observed them, and this included translators from a wide variety of work environments (home-based translators, employees of the Translation Bureau of Canada, employees of large private translation companies, translators in Canada and Europe, translators working on English-French, as well as other language pairs). Therefore, we think that WeBiText presents value to virtually all translators in the world, which means that the ceiling for the growth curve is probably much higher than the current level of traffic.
Secondly, WeBiText is a very lightweight tool which translators can adopt quickly and without having to change much in the way they currently work. If they hear about it from a colleague, they can go to the site, try it, and decide to integrate it into their own work practice, without additional investment in time, and without requiring buyin from the top of their organization. This ease of adoption of WeBiText means that it can spread virally through
4This is the midpoint between the average salaries quoted in the
following two Canadian studies: (a) Étude sur le cheminement de carrière dans l'industrie de la langue, AILIA, June 2007 ($53,800, page 8), (b) Sondage de 2008 sur la tarification et les salaires, François Gauthier, OTTIAQ ($62,212, page 8).
word of mouth, and gain acceptance even in small outfits. Even in large outfits, the tool can spread from the grassroots level, without requiring that it be mandated from the top (something which cannot happen with heavier technologies like Statistical Machine Translation, which needs to be trained by specialized personnel on large amounts of customer or domain specific data, using clusters of powerful machines).
5.
CONCLUSIONS AND FUTURE
DIRECTIONS
The rapid growth of the traffic on WeBiText is a clear indication that it is meeting a need in the translation industry. It seems to be a good source of solutions, for both general language and specialized translation problems. The system offers excellent coverage (58% of all queries), considering that it is not custom built for a specific domain or customer.
In the coming months we plan to do some engineering work to ensure that the system can scale up and deal gracefully with the fast growing traffic. This may involve parallelizing the processing, so that it can be distributed among a cluster of machines.
We also plan to implement several new features that have been requested by our users. Firstly, we plan to use translation spotting (Simard, 2003; Huet et al, 2009) algorithms to highlight the equivalents so that users can easily locate them without having to visually scan the target language sentences. Secondly, we plan to support advanced and more flexible query syntax so that users can search for variations of a given expression with a single query (at the moment, WeBiText only searches for the exact expression entered by the user).
Thirdly, we would like to provide the user with a more open-ended way of specifying the bilingual site that they want to search. At the moment, users can only pick among a list of 26 web domains that have been manually vetted by the WeBiText team, in order to ensure the system can actually deal with them. It would be nice if the user could enter the URL of any web domain to direct the search towards those sites. However, there is a danger that the user experience would be significantly reduced, because not all multilingual sites are amenable to searching by our system. Currently, WeBiText can only deal with sites that provide an “easy” way of getting from a page in source language, to its corresponding page in the target language. For example, a convention used on many sites is to have pages in one language point to their translations in other languages, through interlingual links whose anchor text is the name of those language (ex:
Français for the link to the French version). Surprisingly though,
there are many high profile sites where many of these interlingual links are actually faulty. A common type of fault is to have say, the
Français link of an English page P point to the French home page
for the web site, instead of the actual French translation of P. At the moment, each new web domain must be manually checked by the WeBiText team, to ensure that it does not present too many of these flaws. This vetting process could however be automated, by having the system perform a basic sanity check on a small sample of pages crawled on-the-fly from the new site. Note that this would mean that the very first user to submit a search for a new site would have to wait a few minutes while this vetting process is being performed.
Another way to deal with faulty interlingual links would be to use more sophisticated algorithms for matching source and target language pages based on the similarity of their actual content (Resnick and Noah, 2003; Espla-Gomis, 2009). The downside of these methods is that the content of the whole site must be downloaded and processed ahead of time, whereas the simple heuristics currently employed by WeBiText enable an on-the-fly approach which avoids the overhead of pre-crawling and indexing. Nevertheless, this approach could be applied selectively to certain large web domains (ex: Government of Ontario, United Nations) which present a lot of faulty nterlingual links.
We also plan to investigate methods for assisting users who, as described in Section 3.2, may need to go through a pivot
language to find equivalents for their target language. This could
help make the tool more useful for languages that are not as data rich as English and French. Languages in the system would be grouped into families of similar ones, each family having a pivot language that is relatively rich in parallel data. Examples of families could be Latin, Germanic and Slavic languages, with French, German and Russian as their respective pivots. When no hits are found in a given target language, the system would proactively search for equivalents in its pivot language, in the hope that hits will be found there, and that they will allow the translator to guess the equivalent in the original source language. The system might go a step further and try to automate the manual process that some of our users employ in order to guess the target language equivalent, based on the pivot language one. Taking the example presented in Section 3.2, when the system fails to directly find a Spanish equivalent for low-bush blueberries, it would look in an English-French corpus and find bleuets cultivés. It would then generate Spanish candidates by looking for translations of sub-expressions of this French equivalent (in this case, bleuets and cultivés). These sub-expression equivalents could be obtained by looking in a dictionary or terminology database, or by performing translation spotting on a French-Spanish corpus. In this case, the system might be able to find that
bleuets translates to arándanos and that cultivés translates to cultivados. Combining these two sub-expressions, the system
would get a single Spanish candidate arándanos cultivados for the complete expression. In cases where more than one equivalents are found for a given sub-expression, the system might generate more than one candidates for the complete expression, by enumerating all possible combinations of the sub-expression equivalents. Once the system has one or more Spanish candidates for the complete expression, it would then validate them by doing Yahoo searches, and retaining any candidate that has sufficient hits.
6.
ACKNOWLEDGMENTS
The authors are indebted to the following people who helped with the WeBiText project. Firstly, the hundreds of users who tried the system, and in particular, the few dozens who took the time to provide us with explicit feedback. Also, our lead users at the Translation Bureau of Canada: Sylvie Gajevic and Marc Pichard, as well as their supervisor, Rafael Solis, who allowed them (and one of the co-authors) to collaborate on this effort. Finally, Michel Simard, Caroline Barrière and Patrick Paul of the National Research Council of Canada, whose technical advice helped us improve the system.
7.
REFERENCES
Désilets, A., Farley, B., Stojanovic, M., Patenaude, G. (2008)
WeBiText: Building Large Heterogeneous Translation Memories from Parallel Web Content. Proceedings of
Translating and the Computer (30), London, UK. 23-28 November 23-25, 2008.
Espla-Gomis, M. Bitextor, a free/open-source software to harvest
translation memories from multilingual websites. In Proc.
Beyond Translation Memories Workshop, MT Summit XII, Ottawa, Canada, August 26-30, 2009.
Huet, S., Bourdaillet, J., Langlais, P., Lapalme G. Harnessing the
Redundant Results of Translation Spotting. In proc. MT
Summit XII, Ottawa, Canada, August 26-30, 2009.
Macklovitch, A., Lapalme, G. and Gotti, F. TransSearch: What
are translators looking for ?. AMTA'2008- The Eighth
Conference of the Association for Machine Translation in the Americas, p. p 1-10, Waikiki, Hawai'i, oct 2008.
Resnick, P., Noah, A., S., (2003), The Web as a parallel corpus., Computational Linguistics”, Volume 29 , Issue 3, 2003. Simard, M., Translation spotting for translation memories.
HLT-NAACL 2003 Workshop on Building and Using Parallel Texts: Data Driven Machine Translation and beyond, pages 65-72, Edmonton, Canada.
Simard, M., Macklovitch, E., (2005). Studying the Human
Translation Process Through the TransSearch Log-Files. In
Proc. AAAI Symposium on Knowledge Collection from Volunteer Contributors, Stanford, USA, March 2005.