Defining Scalable High Performance Programming
with DEF
by
William Mitchell Leiserson
Submitted to the Department of Electrical Engineering and Computer
Science
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy in Computer Science and Engineering
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
February 2020
©
Massachusetts Institute of Technology 2020. All rights reserved.
Signature redacted
A uthor
...
.
. ...Department of Electrical Engineering and Computer Science
Septembrl
2019
Certified by...Signature
redacted
Nir Shavit
Profesor of Computer Science
Thesis Supervisor
Signature redacted
Accepted by
EA
13 2020
Il9 A. Kolodziejski
Professor
of Electrical Engineering and Computer Science
1
Chair, Department Committee on Graduate Students
Defining Scalable High Performance Programming with DEF
by
William Mitchell Leiserson
Submitted to the Department of Electrical Engineering and Computer Science on September 11, 2019, in partial fulfillment of the
requirements for the degree of
Doctor of Philosophy in Computer Science and Engineering
Abstract
Performance engineering is performed in languages that are close to the machine, es-pecially C and C++, but these languages have little native support for concurrency. We're deep into the multicore era of computer hardware, however, meaning that scal-ability is dependent upon concurrent data structures. Contrast this with modern systems languages, like Go, that provide support for concurrency but incur invisible, sometimes unavoidable, overheads on basic operations. Many applications, particu-larly in scientific computing, require something in between. In this thesis, I present
DEF, a language that's close to the machine for the sake of performance engineering,
but which also has features that provide support for concurrency. These features are designed with costs that don't impede code that doesn't use them, and preserve the flexibility enjoyed by C programmers in organizing memory layout and operations.
DEF occupies the excluded middle between the two categories of languages and is
suitable for high performance, scalable applications. Thesis Supervisor: Nir Shavit
Acknowledgments
This thesis owes a great deal to my advisor, Nir Shavit, who's ability to frame prob-lems and craft narratives is unparalleled (so to speak). Nir has been extremely en-couraging, and I'm grateful for his guidance. I also want to thank my other committee members, Saman Amarasinghe and Maurice Herlihy, whose breadth of knowledge and careful attention to detail made this thesis a stronger (and better sourced) document. And, of course, I wouldn't have been in the Ph.D. program, let alone have completed it, if not for the support and encouragement of my wife, Erin. She has consistently motivated me through the easy times and the hard. Last, as a proud Papa, thanks to Walter, Freddy, and William, whose smiles and hugs gave me endless joy as I worked.
Contents
1 Introduction 19
1.1 Performance Engineering versus Scalability . . . . 19
1.2 Performance Engineering and Scalability . . . . 22
1.3 Research Contributions in This Thesis . . . . 24
1.4 Structure of This Thesis . . . . 25
2 Background 27 2.1 The Case For Performance Engineering . . . . 28
2.2 The Multicore Revolution . . . . 30
2.3 Parallelism . . . . 32
2.3.1 Theory Basics . . . . 32
2.3.2 Threaded Parallelism . . . . 35
2.3.3 Fork-Join Parallelism . . . . 36
2.4 Concurrency . . . . 38
2.5 Concurrent Memory Reclamation . . . . 40
2.5.1 Conservative Garbage Collection . . . . 43
2.5.2 Epoch-based . . . . 44 2.5.3 Reference Counting . . . . 46 2.5.4 Pointer-based . . . . 47 2.5.5 Ownership-based . . . . 48 2.5.6 StackTrack . . . . 49 2.6 Summary . . . . 50
3 Retire
3.1 ThreadScan . . . .. .. .. ... . .. . . . . .. . . . .
3.1.1 O verview . . . . 3.1.2 ThreadScan+ . . . . 3.1.3 M odel . . . .
3.1.4 The ThreadScan Algorithm . . . .
3.1.5 ThreadScan Correctness Properties . . . . 3.1.6 Experimental Results . . . . 3.1.7 Sum m ary . . . .
3.2 Forkscan . . . .. . . . .
3.2.1 O verview . . . . 3.2.2 The Forkscan Algorithm . . . . 3.2.3 Implementation Details . . . .
3.2.4 Forkscan Correctness Properties . . . .
3.2.5 Experimental Results . . . . 3.2.6 Sum m ary . . . . 3.3 D iscussion . . . . 4 DEF Overview 4.1 Introduction . . . . 4.2 Basic Syntax . . . . 4.2.1 Fibonacci . . . .
4.2.2 Tuples and Switch
4.2.3 Types . . . .
4.2.4 Summary . . . .
4.3 C API Compatibility . .
4.3.1 From C to DEF.
4.3.2 From DEF to C
4.4 Support for Concurrency
4.4.1 Retire . . . . Statements 53 54 54 55 58 60 66 68 73 74 74 76 78 85 86 94 97 101 101 102 102 104 106 108 108 108 109 112 112
4.4.2 Atomic Operations . . . . 113
4.4.3 Atomic Blocks . ... . . . . 115
4.5 Support for Parallelism . . . . 118
4.6 Interpreted Structural Macros . . . . 120
5 Practical DEF 123 5.1 Linked List . . . . 123
5.2 Serial B-Tree . . . . 130
5.3 Concurrent Multi Queue . . . . 134
6 Conclusions 143 6.1 Summary . . . . 143
6.2 Future Work . . . . 146
6.2.1 Concurrency Library . . . . 146
6.2.2 Scientific Computing or Machine Learning Application . . . . 147
6.2.3 Windows Port . . . . 147
List of Figures
2-1 The error in conflating Moore's Law with its popular formulation. Left:
Intel and AMD CPU clock speed over time. Right: Transistor density
over tim e. . . . . 28
2-2 Rising core count on high-end commercial CPUs by year. . . . . 30
2-3 The hidden cost of array bounds-checking can impede speedup
unex-pectedly. Here, multiple threads access their own objects in a shared array, but the bounds-checking causes cache thrashing if the array
di-mension is stored on the same cache line as the first object. . . . . 31
2-4 Node B is removed from a lock free linked list. Left: A's next pointer
is swung from B to C. Right: B can't be free'd, so its fate is left to the
im plem entation. . . . . 35
2-5 Garbage collection performance impact. Left: BDW scalability on a
lock free linked list with respect to core count. Right: BDW average
stop-the-world pause times on those executions. . . . . 43
3-1 ThreadScan protocol illustration. Thread 1 calls Free(P) and this
makes the delete buffer full. As a result, Thread 1 initiates a recla-mation process, that sends a signal to other threads, and makes each thread to scan its own stack and registers. After all threads are done, Thread 1 traverses the delete buffer and deallocates nodes that have
3-2 An example of reference exchange between threads via a shared mem-ory location. In the first step, Thread 1 sets S1 to address of ObjI and then sends a signal (or some indication) to Thread 2 that S1 is ready. In the next step, Thread 2 reads S1 and gets the address of Objl. . . 56
3-3 In ThreadScan+, the programmer defines a predefined exchange block,
and then uses this block to execute reference exchanges. Then, the ThreadScan+ protocol locks the pages of this block before the scan process and this allows to intercept any reference exchange that occurs
during the scan. . . . . 56
3-4 Reference types illustation for a linked-list data-structure and a
refer-ence exchange process between two threads. . . . . 58
3-5 Throughput results for the lock free linked list: X-axis shows the num-ber of threads, and Y-axis the total numnum-ber of completed operations. From left to right: No exchanges, simulated exchanges, and simulated
exchanges on an over-subscribed system (we use an 80-way machine). 69
3-6 Throughput results for the lock free hash-table (first and second) and
lock based skip-list (third and fourth). . . . . 70
3-7 Performance results on the linked list, skiplist, and hash table data structures. For each: total operations (threads x ops), memory usage of the application (threads x 4KB pages), and average latency per reclamation iteration (threads x time in ms; logscale for the first two
structures, to compare Forkscan with BDW-GC). . . . . 88
3-8 Performance results for a hash table with 40% update operations. The
axes are the same as above. . . . . 90
3-9 Forkscan memory usage and memory/latency vs. performance tradeoffs. 91
3-10 Histogram of overhead per allocation. . . . . 92
4-2 C (above) and DEF (below) declarations of a function returning a
function pointer that returns an integer. deci is used for function
declarations in DEF. . . . . 103
4-3 DEF toy example of a tuple and a switch statement, including wildcards.104
4-4 Ways in which elements of a tuple can be accessed. . . . . 106
4-5 Examples of defining named types. . . . . 106
4-6 Types in DEF along their corresponding C code. . . . . 107
4-7 Example of making printf available to programmers within a module
without including external files. . . . . 108
4-8 DEF can import C header files directly. . . . . 109
4-9 Listing for a complex numbers package. Above: The DEF source file.
Below: The automatically generated C header file. . . . . 110
4-10 Same example as above, but using the opaque keyword. The original
DEF file is truncated for brevity. . . . .111
4-11 Trivial example of using retire vs. delete. . . . . 112
4-12 DEF atomic operations and their C counterparts. . . . . 113
4-13 Two possible implementations of the atomic division operation as coded in C. Above: the C Atomics Library solution, below: a transactional
approach using Intel RTM. . . . . 114
4-14 Basic atomic block syntax. Above: trivial atomic block executes until it succeeds, below: transaction with abort condition detection and error
handling . . . . 116
4-15 Equivalent explicit code from the bottom example in fig. 4-14 as
im-plemented for Intel RTM . . . . . 117
4-16 Fibonacci code in DEF. . . . . 118
4-17 Histogram example using a parallel for loop. . . . . 119
4-18 Two ways of dividing a parallel loop. P-nodes represent parallel work, and S-nodes represent serial work. Left: spawn individual iterations,
right: divide-and-conquer. . . . . 119
4-20 Mapping a DEFISM function... .121
5-1 List types and initialization functions . . . . 124
5-2 The window_f ind function for getting the requested value (or where it
would be if it existed. . . . . 125
5-3 The find-function that returns whether the specified value is in the list. 126
5-4 Code for inserting a new value into the linked list. . . . . 127
5-5 Code that removes a node from the list, highlighting the retire keyword.128
5-6 The destroy function, and functions for handling pointers with the low
bit overloaded for marking. . . . . 129
5-7 Performance of the DEF linked list versus C. Left: Execution with 10%
update operations. Right: Same with 25% updates. . . . . 130
5-8 Macro for making custom parameterized B-Trees. . . . . 131
5-9 Macro for creating a variety of B-Trees of different sizes and types. . . 132
5-10 Macro for generating if-statements over the key types and dimensions
of the B-Tree. . . . . 133
5-11 Performance comparison of the B-Tree for various widths. Left:
Inte-ger operations over a 10 second execution with 25% updates. Right:
Floating point operations. . . . . 133
5-12 Macro code for the locked (blocking) MQ types. Some of the variable
definitions have been omitted for brevity. . . . . 135
5-13 NaYve insertion code for the MQ, both for locked and transactional
versions of the structure. . . . . 136
5-14 Smarter insertion code for the transactional MQ. This is an alternative
to the code presented in lines 13-17 above. . . . . 137
5-15 Pop-min boilerplate for the MQ. . . . 138
5-16 The "business" part of the code. Peek both B-Trees and pop from the
5-17 release-locks is defined as releasing the locks if and only if this MQ
is a locked data structure. This let* performs all of the bindings in
the make-mq function . . . . 139
5-18 The new "business" part of the function with both locked and
transac-tional versions of the code. . . . . 140
5-19 Performance comparison of the MQ using locks vs. atomic
transac-tions. Left: Performance results versus c-value, and Right: the
fre-quency with which transactions fell back to the STM slow path. . . . 140
6-1 Visualization of the solution to the question: performance engineering
List of Tables
2.1 A qualitative comparison of conventional concurrent memory
reclama-tion techniques. . . . . 50
3.1 memcached performance in operations
/second.
. . . . 94Chapter 1
Introduction
1.1
Performance Engineering versus Scalability
Inasmuch as a new class of systems languages that use garbage collection (GC) have emerged at the forefront of high performance programming, the C and C++
pro-gramming languages, which lack GC, maintain a position of prominence. Part of
this, naturally, is due to the sheer volume of legacy code. Applications and operating systems are implemented in C, and rewriting them in a higher level language may be impractical, undesirable, or even impossible. But new applications continue to be written in these languages. Of the popular languages, today, C and C++ are unique because they permit performance engineering, the ability to leverage knowledge of the specific hardware to optimize source code. Performance engineering is a prac-tice that's only available to programmers of languages that are close to the machine, with data types and operations that intuitively and directly correspond to hardware primitives.[81]
A language that's close to the machine doesn't merely run fast in the common
case - it provides the programmer with the tools necessary to organize data layout
in memory, taking into account alignment, packing, and location on the stack or on the heap. It also doesn't insert hidden operations such as array bounds-checking, pointer liveness checking, or checking a divisor for zero. In higher level languages all of these features are provided for the safety of the programmer, but a language that's
close to the machine eschews them in order to provide the programmer with the tools necessary to maximize performance.
Paradoxically, however, it's runtime support and the abstraction of a language that contribute most significantly to scalability through concurrency. Two broad cat-egories of concurrency are relevant: concurrent data structures and task distribution. As regards concurrent data structures, when multiple threads traverse a concurrent object, if one of them removes a node it must regard the other threads as invisible
readers that may be holding references to the node it's trying to remove. In the presence of a garbage collector, every reachable object is tracked and the thread may simply drop its reference to the removed node. Not so in the absence of a garbage col-lector. Merely dropping the reference leaks memory and would eventually cause the program to crash with enough use. However, garbage collection represents an unac-ceptable performance cost for certain applications, and it's intentionally disincluded from languages like C, C++, and Rust. The naive solution in one of these languages is to lock the data structure, but this is slow because it causes threads to queue up on the lock, and even reader/writer locks introduce contention on read-heavy workloads. To the second point, task distribution is a commonly achieved through language
or library extensions like Cilk, OpenMP, TBB, and others.[10, 13, 78] Even here,
however, there is a scalability problem in the way of contention created by commu-nication between threads. Concurrent memory reclamation hints at this problem, as solutions for low level languages largely run into this space. But the degree of contention in a shared object is typically the make-or-break property in any prac-tical test; memory reclamation notwithstanding. How ever well the load balancer distributes tasks, if they thrash in the cache, their "communication" is a performance bottleneck. Modern commercial CPUs include hardware transactional memory, which is an exceedingly low-contention feature where updates to commonly read memory are rare. A language may even employ hybrid transactional memory to supplement hardware transactions when the latter don't provide a forward progress guarantee. This includes invisible counters, branches, and instructions (in the slow path). But, whereas a high level language may include synchronization abstractions that are (or
could be) implemented using transactions, C and C++ support nothing more than intrinsics for the hardware. Roll your own hybrid transactions. Every time.
To sum up: the problem for a low level language is two-fold: memory reclama-tion and contenreclama-tion, and the high level language can easily address both. Memory reclamation is achieved through GC, and contention can often be addressed with transactions. A programmer who's willing to accept the cost of these features has a general solution to concurrency, but these costs are antithetical to the design philoso-phies of contemporary close to the machine languages.
It is the space in which performance engineering and concurrency meet that I'm primarily concerned. Languages exist on a spectrum between safety and ease of use (high level), and closeness to the machine (low level). The distinctions are quantized in that the difference between the levels comes down to particular features that appear in runtimes or in the compiled code. But in practice there's an excluded middle. Even the aforementioned modern systems languages tend not to provide programmers with fine-grained control over, e.g., memory layout, instead making a best effort to be fast in the common case. They are highly successful, as evidenced by the widespread adoption of languages like Go, but applications in which performance engineering is required could never make the transition.
Contrast this with concurrent data structures implemented in C or C++: the mere problem of invisible readers has generated an enormous amount of research with numerous memory reclamation techniques. Even the literature presenting the concurrent data structures, themselves, tends to paper over the memory reclamation question. Implementing such a structure in C or C++ directly from a published
research paper is non-trivial for this reason, alone. Not that it isn't done - many
applications use concurrent data structures - merely, the languages provide no native
support for it. Every implementation reinvents the wheel of memory reclamation, and programming hybrid transactions to deal with contention is a perilous undertaking, not only difficult to get right, but it's also difficult to debug.
The problem of scalability in low level languages compounds as new features, like hardware transactional memory, begin to appear in commercial CPUs. Again,
reimplementing hybrid transactions for each use is a fraught exercise. And as new and faster techniques for software transactions are developed, source code requires reimplementation rather than a simple recompile. It's worth observing, here, that the code transformations for hybrid transactions are fairly rote; merely, it's easy to make a mistake when done by hand, and acts as the quintessential example of duplicated code (for the two or more paths) that make such code difficult to maintain at a correctness level.
1.2
Performance Engineering and Scalability
C and C++ aren't bad languages for making scalability difficult any more than Go is a bad language for making performance engineering impossible. These are design decisions. The languages are well suited for the purposes for which they were designed. But none of these were designed for implementing performance engineered concurrent data structures.
DEF, introduced in this thesis, is a new programming language with high level abstractions for concurrency-related features, but it also allows programmers to per-formance engineer their code. Runtimes and abstractions impose unavoidable over-heads only insofar as they're explicitly used by applications, and don't impose hidden costs or impede a programmer's ability to performance engineer their code. The goal of DEF is to provide high level support for concurrency, particularly in the imple-mentation of concurrent data structures, in applications that are otherwise geared towards maximum performance on each CPU core.
DEF provides native support for on demand automatic memory reclamation for concurrent data structures by way of the retire keyword that stands in where free would in a serial application. This is an approach to concurrent memory reclamation that provides some of the benefits of GC without requiring an entire application to pay the cost of generalized GC. Moreover, the cost of the runtime handing retired memory is borne by an application only to the degree it's actually used by the application's concurrent data structures.
Atomic operations are also natively supported, including atomic blocks of code implemented as hybrid transactions. As in any low level language, primitives are available, and nothing prevents a user from specifying specific Read-Modify-Write (RMW) instructions through intrinsics or manually implementing hybrid transactions using hardware transaction intrinsics. But the syntax is provided for these atomics in a way that keeps the code simple, and hybrid transactions as correct as the hardware fast path written by the programmer.
This thesis includes sample source code and micro-benchmark results for various concurrent data structures implemented in DEF as compared with C counterparts. As such, some space is also devoted to the DEF macro language, Interpreted Structural Macros (ISM), which was crucial for implementing the benchmarks and duplicating code with minor variations in ways that are difficult to accomplish in C or C++.
DEFISMs are Lisp-like and permit various DEF constructs to be treated as data
-not merely text to be substituted. They also operate at many levels of the parser, not just at the function or data structure level as C++ templates do.
Last, acknowledgment must to be given to the fact that a tremendous amount of legacy code is already written in C and C++, and it's unreasonable to expect it to be rewritten. DEF, therefore, is designed with the goal of transparent C integration, such that a module written in DEF can be dropped seemlessly into a C application.
C types and functions defined in header files are available to DEF modules, and DEF
types and functions can be made available to C modules as easily as they are to other
DEF modules. The same utility, defghi, that generates DEF interface files (.def i)
from DEF source files (. def ) can generate C header files. This was helpful not only in the implementation of the micro-benchmarks, but also acts as a principled approach to language integration in general, as most languages work hard to integrate with
C. DEF is available, not merely as a tool for writing fast concurrent data structures
for itself, nor even just C and C++ as well, but for any language that requires performance engineered concurrent data structures.
1.3
Research Contributions in This Thesis
Ample acknowledgement is due to my coauthors, and certainly to Nir Shavit, my advisor, in the undertaking of the work presented in this document. But the following is an itemized account of my specific work and the contribution it makes to the field. To the best of my knowledge, these contributions are new or meaningful improvements over existing work.
" ThreadScan: I wrote the ThreadScan library, in its entirety, and benchmarked
it. ThreadScan is the first automatic
/semi-automatic
approach to memoryreclamation for C, apart from general-purpose garbage collection. As with a garbage collector, it imposes no burden on data structure traversals, no addi-tional per-node memory requirements in the way that, e.g., reference count-ing does, and (because of its limited scope) performs at the rate of a "leaky" implementation. Versus reference counters or hazard pointers, which burden traversals, ThreadScan is light-weight and low contention for read-heavy work-loads. Epoch-based mechanisms, which impose strict rules on pointer validity, don't allow the pointer freedom ThreadScan provides. As against any of these, ThreadScan is automatic or semi-automatic (depending on how it's used). • Forkscan: Like ThreadScan, I did the complete implementation of Forkscan
and benchmarked it. Forkscan is an incremental improvement on ThreadScan in that it maintains the theoretical lock free property of a data structure that uses it.' Moreover, it solves the general problem of references that escape the stack. Forkscan provides the same guarantees as a conservative garbage col-lector, but unlike the latter, tracks only objects flagged by the programmer. Again, the limited set of objects being tracked creates a multitude of opportuni-ties for optimizations unavailable to general purpose garbage collectors. Besides ThreadScan and Forkscan, I am not aware of any prior work with this set of properties.
'Caveat: From a systems perspective, it's important to note that Forkscan contains a lock, but Forkscan's lock is not practically different from an allocator's lock - a lock that is generally accepted as not infringing on the theoretical lock freedom of a data structure.
* The DEF Programming Language: I designed and implemented the DEF
language and compiler, as well as the defghi utility. I also implemented some of the concurrent data structures used in the benchmarks. DEF is the only language, of which I am aware, that exists at the intersection of languages that are close to the machine (and, therefore, enable performance engineering of code), and languages with high level native support for the implementation of concurrent data structures. Existing in this intersection means integration of concurrent memory reclamation through a retire interface into a close to the machine language, a technical barrier, and the inclusion of native atomic blocks into the same, a philosophical barrier. Since these features are inherently high level, C has neither of them and, as a matter of its design goals, never will. The Go language, designed for high performance concurrent programming, is not close to the machine and therefore does not permit performance engineering, by design. It also has a garbage collector, which is fast but unacceptable for close to the machine programmers. Rust, the other language typically cited in these contexts, is designed for safe concurrent computation with no overhead, but is not designed for implementing concurrent data structures. Its safety features, on the contrary, prohibit sharing pointers to objects among threads.
1.4
Structure of This Thesis
The chapter on Background is provided as justification of the need for a language in this space, including relative performance characteristics of C and Go. Go is treated as the architypal modern systems language designed for performance, since it advertises comparable speed to C in similar applications, but which trades safety for flexibility in performance engineering. Additionally, since a good deal of the work that went into the development of DEF was bound up in addressing the question of concurrent memory reclamation, space is allotted to explanations of conventional approaches to this problem.
reclamation are laid out, and my work on ThreadScan and Forkscan are described. As published, neither work quite fits the required semantics for the retire abstraction, but Forkscan was adapted to implement that feature in DEF, so an explanation of the changes that were made (as well as some optimizations to the original implementation) is necessary.
The language, itself, is described in the DEF Overview chapter. This includes syntax, the relationship between operations, data, and hardware, and the high level features that facilitate the development of concurrent data structures. As mentioned above, it also lays out ISM and compares it to other macro languages. Since the fundamental contribution of DEF is the synthesis of high level abstractions into a language that's close to the machine, special attention is given to how they interact so as not to impose invisible (let alone unavoidable) overheads. One is particularly interested in the principle of least surprise regarding performance characteristics of a DEF application.
Examples and empirical microbenchmark results are presented in the Practical DEF chapter. DEF is designed to be as readable as, e.g., the concurrent data struc-tures expressed in the literature, and also to provide syntactic strucstruc-tures that could be ported back into the literature, itself. A couple of specific data structures are developed and benchmarked, and a wider suite of benchmark results are provided to demonstrate DEF's performance and ease of development.
Last, although the language is already sufficiently developed for common use in many applications, there's more work to be done - both in the design of the language and in the implementation of the compiler. DEF takes a step out into a space that isn't well-explored, at the intersection of low level and scalable groups of languages, and opportunities abound for advancement. The Conclusions chapter describes some of these opportunities and challenges, and summarizes what I believe are the core contributions DEF makes to the field.
Chapter 2
Background
Tension exists between a language's ability to do low level manipulations of memory, and the presence of high level abstractions. To appropriate a Twain-ism, "reports of C's death have been greatly exaggerated." C hangs on, not just because of legacy code, but because of its ability to operate in a space ignored by high level languages, even systems languages. Yet it's missing crucial support for multicore programming the latter provide.
I argue this excluded middle isn't inherent, but speculate that the philosophies
have generally kept them apart; low level languages don't include high level abstrac-tions for anything because the abstracabstrac-tions don't give programmers tight control over sequences of instructions and memory layout. But if the low level primitives exist that give programmers control, there's no contradiction in providing the abstractions, too, unless they infringe on the former by design. Paradoxically, actually engineering scalable code is typically better handled by abstractions than individual programmers (the case for this, below). DEF is designed to do both, and there have been (and remain) clear hurdles to this kind of integration.
This chapter is primarily about the state of these two dimensions, and why both are relevant to modern software development. I want to tell a story, here, about why the state of programming languages is what it is today, why there's an excluded middle between these two philosophies, and why anybody cares about that middle. The answer to these questions provides motivation for thinking about a new kind of
50002 r4 20000 4000 . -1 • 15000 3000 - -0- 2000-1000- 0 5000 0 0 1977 1987 1997 2007 2017 1977 1987 1997 2007 2017 Date Date
Figure 2-1: The error in conflating Moore's Law with its popular formulation. Left: Intel and AMD CPU clock speed over time. Right: Transistor density over time.
progranuning language - not one that tries to be everything for everybody, but merely
tries to fit the excluded niche in which people care about performance engineering and scalability for their code. The story begins with the traditional way in which programs attained performance: "free" (from the perspective of the programmer) increases in hardware clock speed, and non-free tailoring of code to specific architectures.
2.1
The Case For Performance Engineering
For decades, Moore's Law was popularly understood as the idea that the clock speed of CPU's doubled every year or two. What Moore actually stated was that the number of components per integrated circuit doubled every year.[74] The erroneous conflation of the popular notion with the actual statement became apparent as the rate of increase in CPU clock speeds declined, even as transistor density maintained its trajectory
(fig. 2-1; although even Moore's actual Law appears to be flagging).1 Increasing clock speed along with reduction in transistor size led to material limitations in the silicon. In short, the silicon in which transistors are laid out has a maximum energy density before it melts.
Note, here, that clock rate is not equivalent to performance, even though the one could safely be used as a stand-in for the other in days of yore. Increased
tran-'Data up until 2014 acquired from [33]. Subsequent data (2015 and later) was gathered from [27] and the Intel website. Transistor density is estimated based on limited released data from Intel.
sistor density continued to allow for performance improvement - just not in the "free lunch" sense that software developers had come to rely on. As clock speed leveled off, developers and compiler writers, alike, had to take into consideration new and ever-increasing-length vector instructions with Single-Instruction-Multiple-Destination (SIMD) semantics. Memory hierarchies, a perennial double-edged sword in performance, similarly enjoyed more widespread focus. Knowing something about the size of a cache line, or the behavior of a branch predictor can make or break the performance of an application. Before even getting into discussion of the multicore explosion, there is an increasing potential to exploit architectural subtleties even on a single core.
This is the grounds for taking performance engineering seriously as a practice in the modern era. Inasmuch as modern systems languages are optimized for the common case to be competitive with low level languages, C and C++ provide a degree of control over the instructions that will be executed and the layout of memory that these languages don't. C, designed in 1972, was tasked with implementing the AT&T Unix kernel.[81] Close to the machine, as a design goal, was necessary because an
OS has to be fast, and hiding implementation details presents a hazard to that goal. C++, in the early 1980's, was designed to fit the same niche, but also provide greater
flexibility for application development by adding classes and other features.[87] As with C, C++ provides maximal control over instruction sequences and memory layout for end programmers, but avoids any native abstractions for which programmers don't have this kind of control.
By contrast, modern systems languages like Go, hide implementation details for
common operations. In Go the location of a newly allocated object, whether on the stack or heap, is undefined.[43] As an implementation, Go will allocate an object on the stack unless it can't prove that no references escape. This balances performance with abstraction in a way that's useful to some kinds of applications. But choosing where to allocate memory is an incredibly powerful tool for handling performance: an MCS lock implementation, for example, might allocate a node on a thread's stack even though other threads will definitely access it.[69] Allocating it on the stack means
so- Core Count By Year 70-70 -. - -- - 40- 30-20 .. 10 1977 1987 1997 2007 2017 Date
Figure 2-2: Rising core count on high-end commercial CPUs by year.
that cleanup is as simple as popping the stack frame. Go doesn't define where neinory
is allocated, or let programmers perform explicit pointer arithmetic, or any number of other things that are common in high performance C code.
C and C++ offer a degree of control over the generated assembly code that is missing from modern languages. Abstractions are the conventional approach to lan-guage design, leading to hidden costs that are neither avoidable, nor consistent across versions of the compiler. Clearly, low level languages not only have life left in them, but aren't going to go anywhere unless and until they're displaced by another low level language. But this story gets more interesting when multicore systems come into play, as they do since the aforementioned "free lunch" of hardware speedup has diminished.
2.2
The Multicore Revolution
Go is successful, not in spite of the abstraction it provides to programmers, but because of it. Abstract representation of common concepts lowers the bar for imple-menting big programs, and reduces the complexity of the code, reducing bugs. The obvious question is how one tunes the performance of a program that doesn't give the programmer access to the nitty-gritty details? But this question is obviated by the fact that the real increase in performance potential brought about by Moore's Law (the real one, not the popular one) is multicore CPUs (fig. 2-2). Scalability is
T1
wie
oObject
wrae
Object
write
Object
writ ,
T4
wi
Obj ect
intuitively, threads can write to a shared array without conflict if objects are padded to cache.
Size
write. ET1
Object
_
/
object
Object
T4
wrt-Object
But in many languages animplicit array bound
safety-check can lead to conflict.
Figure 2-3: The hidden cost of array bounds-checking can impede speedup unex-pectedly. Here, multiple threads access their own objects in a shared array, but the bounds-checking causes cache thrashing if the array dimension is stored on the same cache line as the first object.
the name of the game in modern performance brought about, not by making indi-vidual cores faster, but by increasing the number of shared memory cores in a single computer. Of course, such systems are harder to program.
Scalability is a non-trivial problem, but well-studied, and language abstractions that facilitate scalable code are in demand. There are two ways of thinking about scalability that each warrant discussion: parallelism and concurrency. Parallelism, for the purposes of this thesis, is concerned with the maximum speedup over sequential execution that can be achieved, no matter how many cores, floating point units, or other hardware features are provided. Concurrency is a property of a program: it's the interaction of independent operations occurring simultaneously, particularly as many operations are performed on common objects by different threads.
Both of these paradigms have important implications for performance engineering, especially since the presence of other abstractions representing, e.g., safety features, can require performance trade-offs that might inhibit scalability. Consider the exam-ple of a program in which many threads are accessing a shared array, as in fig. 2-3. In this example, threads write to their own objects in the array and only look at others on rare occasions. Intuitively, provided each object has its own cache line, perfor-mance should scale with the number of cores on the system. However, a language that does array bounds checking may cause cache thrashing by placing the size of
the array - a value each thread must read on every access - on the same line as the object belonging to Thread 1. As threads read the array length, they force Thread 1 to flush its writes, and the other threads have to wait for the cache line to be fetched. We can imagine any number of scenarios in which this case (or something very much like it) becomes relevant. The natural implementation of hazard pointers uses this kind of shared array, applications may give threads scratch space for which inter-mediate values during execution are occasionally needed, histograms, etc. Is this an implementation bug on the part of the language? Unclear. It represents a trade-off, since putting the size on a different cache line from any of the objects means increased space consumption, even for serial applications. Can a programmer work around it? Sure. But we must acknowledge that a "work around" is precisely what this is, and that none of this is hidden (let alone subject to change) in a low level language.
We deal with the parallelism and concurrency-related abstractions each in turn to understand how, and to what degree, they impede performance engineering. For DEF's purposes, it's important to think about where unavoidable overheads become visible, particularly if a feature isn't being used. In the shared array example, the programmer may have known that no access would ever occur out of bounds, so the safety feature is unnecessary. Nevertheless, the performance cost to the application is quite high.
2.3
Parallelism
2.3.1
Theory Basics
We are here concerned with the ability to divide an algorithm in such a way as to al-low parts to execute in parallel. The most intuitive parallelism is the instruction-level parallelism provided by modern CPUs in the form of vector operations. An instruc-tion can be applied to an array of values, for example, and since none of the resulting values depend on one another there's no need to perform them sequentially. There-fore, hardware exists to process them simultaneously, even on a single core. Modern
compilers are so good at exploiting this kind of parallelism, they emit vector opera-tions for programs written in languages that have no special syntax for representing instruction-level parallelism.
More challenging for programmers is the kind of parallelism that allows instruc-tions or blocks of code to execute in parallel on different cores, when data dependencies aren't as obvious. In particular, it isn't always clear how parallelizable an algorithm truly is. The limitation on parallelism was first clearly articulated by Amdahl, who observed that the maximum theoretical speedup was limited by the percent of code that was inherently sequential.[5] Although Amdahl intended this as a critique of par-allelization, it's since been interpreted and re-expressed as a mathematical property:
Speedup =
ws + W
n
Where w, is the part of the computation that's inherently sequential, wp is the
part that's parallel, and n is the number of cores across which the parallel part of the code is divided. This doesn't take into account memory hierarchies or other hardware features that might impact performance, but it's a theoretical upper-bound on what
an algorithm can achieve on n cores. Note that as n -+ oc, the cost of the parallel
part of the program approaches zero, leaving only the serial part. Thus, we can infer a maximum theoretical speedup, or total parallelism based on how much of the code is sequential:
.ws
+
wpParallelism = +
Even if much of this serial portion is technically in parallel with everything else, it's still the limiting factor in attaining speedup. The basis for this is well-explored, and in the literature w, is sometimes called the critical path or the span of the
computation.[46, 36, 28, 11, 60]
Granularity is the path to parallelism; lots of small tasks that don't depend on each other lead to low theoretical barriers to speedup. Practical barriers to speedup are another matter. "Sequential" code, according to Amdahl's Law, is a matter of
a happens before dependency between tasks. Parallelism, on the other hand, is the non-imposition of that relation. But as a practial matter, code can serialize itself without that explicit dependency.
Mutual exclusion, for example, can limit speedup by forcing threads to wait for each other, even if the tasks they want to perform have no predetermined order - the operations may not even actually conflict, but use of the mutex is too coarse or the operations couldn't have been predetermined not to conflict. The obvious example is memory management: even if knowing when to deallocate memory is a trivial matter that requires no inter-thread communication, a bad allocator might undo all of the careful division of tasks that went into development of the algorithm. More broadly, access to shared resources and the requisite communication (implicit and explicit) can reduce the scalability of an algorithm.
Time spent holding a lock is factored into consideration of the parallelism of an algorithm by treating all such critical sections with a particular lock in common as inherently sequential. Naturally, the less time spent holding locks, the shorter those sequences. But with the advent of commercially available hardware that supports transactions, the possibility of lock elision arises.
Transactional memory makes it possible to maximize the granularity of an algo-rithm in spite of shared (and updated) resources. Tasks that don't actually conflict don't need to be executed sequentially. More complete discussion of this is presented in the section on Concurrency, but it's important to recognize that even insofar as par-allelism primitives have been implemented in low level languages, the matter of hybrid transactions remains squarely within the purview of high level languages. Therefore, so does the general realization of maximum granularity.
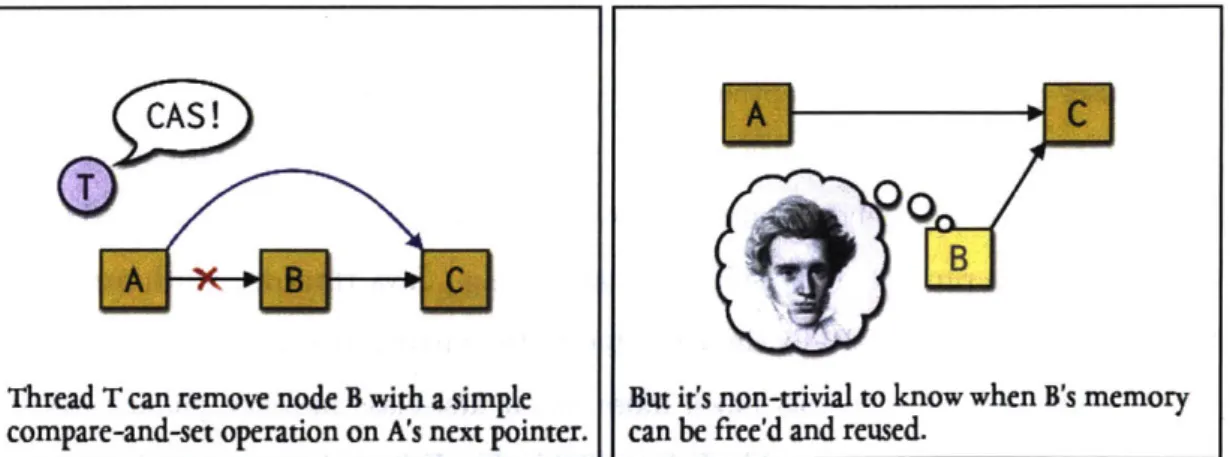
Compound this with the problem of concurrent memory reclamation, wherein many conventional methods a thread has of alerting its peers that it's looking at a particular node require synchronization. Fig. 2-4 shows removal of a node from a linked list. The removing thread uses a compare-and-set (CAS) RMW operation to swing A's next pointer from B to C, but whether an invisible reader is looking at B is unknown. Therefore, B can't be free'd, as it would be in a serial data structure, until
CAS!
A
BC
Thread T can remove node B with a simple compare-and-set operation on A's next pointer.
AC
But it's non-trivial to know when B's memory
can be free'd and reused.
Figure 2-4: Node B is removed from a lock free linked list. Left: A's next pointer is swung from B to C. Right: B can't be free'd, so its fate is left to the implementation.
it can be proved that no thread holds a reference to B anymore. This is the problem of invisible readers, threads that read but don't write in the global state, and are therefore invisible to other threads. Again, locks are a powerful tool, but they have a tendency to serialize an algorithm.
Atomic operations are covered in sec. 2.4, and concurrent memory reclamation is discussed in greater detail in section 2.5, but a more complete analysis of the state of parallelism is beyond the scope of this thesis. The takeaway is that programmers are concerned with the ability to express parallelism within their code to achieve speedup, and it's crucial that languages provide enabling tools. If parallel units of work are necessarily coarse by virtue of the way they act on data, it doesn't matter how easy it is to express them.
Nevertheless, expressing parallelism is its own can of worms that requires dis-cussion. Actually approaching the theoretical speedup for the given work is often a matter of scheduling the work efficiency, and there are two main models used by programming languages: the threading model, and the fork-join model.
2.3.2
Threaded Parallelism
Many parallel languages and extensions tend to encourage thinking about their parallelism-related features as threads. In general, these features aren't actually as primitive as, e.g., pthreads, Windows threads, or even Java threads, and they provide services that
make it easier to distribute work across cores.
Go uses goroutines - conceptually cheap threads implemented as mini-stacks that
the Go scheduler multiplexes over a thread pool - that communicate with one another
through channels.[43] Each goroutine is a work unit, and a mini-stack is created in the process for it to run on. This isn't as coarse as, e.g., Java threads, which are literal heavy-weight threads typically implemented in the virtual machine on top of system threads,[45] and instead looks much more like a first-class message passing system from a very high level language like Erlang.[89] Unlike Erlang, however, load balancing is performed by the runtime, and every goroutine is running in the same address space and has access to global variables. The routines, themselves, are multiplexed across the threads like Windows fibers,[23] except the scheduling is done by Go.
2.3.3
Fork-Join Parallelism
An alternative model is to identify work that can be performed in parallel by con-ceptually forking some code, and then identifying a join point that defines a prior-to relationship between the parallel work and what comes after. Cilk, a language exten-sion to C/C++ (but has also been applied to Java as JCilk[32]), expresses parallelism using spawn, which identifies a function that may be executed in parallel with its con-tinuation, and sync, which acts as a barrier until all parallel work in the function has completed.[10] Work is distributed by the runtime according to a work-stealing scheduler in which a pool of workers, threads that execute Cilk-augmented code, cre-ate work and push it onto one end of a deque to be popped off the other end (stolen)
by other workers that have run out of work to do.[12]
As originally implemented, Cilk used a cactus stack in which function frames were allocated from the heap, much like the mini-stacks used by goroutines; even more expensive, since mini-stacks are only allocated when a goroutine is spawned, and every function instantiation was heap allocated in Cilk. But with the relative infrequency of steals, subsequent Cilk runtimes were implemented by allocating full stacks at the point of steal, rather than individual frames at the point of spawn
allocations - and the slow path only comes in the infrequent case.
Similarly, OpenMP is a popular extension available in C/C++ (among other languages) that provides a programmer with compiler directives and library func-tions that allow a programmer to identify regions of code that can be executed in parallel.[13] Traditionally, OpenMP required programmers to identify a block and
manually distribute the work among threads using a thread ID - a system somewhat
less advanced and convenient than a goroutine. As the system evolved, however, OpenMP added a more dynamic scheduler that allowed programmers to identify blocks that could, but were not required to, execute in parallel (much like Cilk) and may (depending on implementation) even use work stealing.
Threading Building Blocks (TBB) uses this same technique in library form for
C++.[78] As a library, no language extension is required and facilities have been
created for expressing advanced parallel techniques like pipelining.
The difference between the two conceptual models is important. The former re-quires programmers to think about threads, no matter how light-weight, if not the actual scheduling of work. The latter merely identifies computations that may exe-cute in parallel. Neither can be called "close to the machine," but the abstractions actually provide the flexibility to expressing parallelism without imposing guaranteed space, cycle, and scheduling overhead versus the threaded model.
The fork-join model (as implemented in Cilk and TBB) is also more rigidly structured, computationally, allowing the existence of tools like provably good race detectors,[38, 59] scalability analyzers that compute work and span, objectively,[50] and parallelism profilers.[82] In terms of parallelism, at any rate, the problem has been addressed in satisfactory ways that are applicable to low level languages (or at least their extensions).
The cost to a program that doesn't need the feature is negligible since even if the runtime is present, a conventional implementation will park the threads in the thread
pool until there's work to do - whether in fork-join parallelism or threaded parallelism.
The wide availability and use of OpenMP, TBB, and Cilk is a testament to this. At some level, independent of the readability or expressibility of the syntax (which varies
from system to system), the problem of parallelism in low level languages has achieved a measure of success. In spite of the volume of work done on concurrency, however, the same cannot be said of it.
2.4
Concurrency
Speedup, in a concurrency-sense, of a program depends on design of the common objects being accessed by threads. Most intuitive methods for synchronization that avoid data races have performance-inhibiting side effects. For example, merely locking an object before operating on it doesn't scale if it's being touched by lots of threads simultaneously because the accesses are serialized. As a consequence, mechanisms have been devised that avoid locks as much as possible, typically in favor of RMW hardware primitives that make changes visible to other threads atomically. This atomicity is crucial, in that it prevents any thread from reading a partial state.
Concurrent data structures are a hot area of research, and concurrent versions of most popular data structures are known.{40, 49, 52, 86, 76, 70, 61, 2] To go into any of them in detail is beyond the scope of this thesis, but it suffices to say that many of them scale linearly with the number of cores in all but the most write-heavy applications. Naturally, since the data structures themselves are often complicated to implement, languages designed for scalability will implement their own concurrency libraries. Go has a synchronized map in its library, and Java's concurrency package is popular with that community and provides numerous data structures and primitives
that allow programmers to implement their own.[44, 77]
It's worth noting, however, that there's very little work in the way of concurrency libraries for C or even C++. Although both languages have intrinsics for the hardware RMW operations,[25, 26] the data structures themselves are in short supply. Even Boost, which is typically ahead of the curve in terms of C++ functionality, contains exactly three concurrent data structures (a stack and two queues) in its Lockfree package.[9] This is not to say that concurrent data structures aren't popular in C
structure benchmarks in C and C++ are popular for testing performance of one
versus another.[47, 48] But there's a catch, here: the applications modify the data
structures, as presented in the literature, and even though the benchmarks typically don't, they leak memory and will crash if executed for long enough. Extensive research has been performed in resolving this dilemma such that it deserves its own section: Concurrent Memory Reclamation. The point, here, is that conventional close to the machine languages lack some of the basic infrastructure of high level languages, and that makes concurrent data structure implementation difficult to generalize across applications. Such structures tend to be reimplemented, even in C++, from scratch for each use. Whereas high level languages have resolved this problem, low level languages haven't.
Sychronization and Atomics A second barrier to implementation in low level
languages is the lack of a symbolic approach to atomicity employed by high level languages. Languages that represent complex concurrency features symbolically, just as in parallelism, avoid reinvention of the wheel on the part of programmers and allow the implementation of those features to improve along with the newest theory.
Java provides the synchronized keyword that can be applied to methods or blocks of code (See [45], sections 8.4.3.6 and 14.19). When applied it guarantees atomicity within that method or block against other synchronized operations on the object (either this in the case of a method, or a specified object in the block case). As of the writing of this thesis, synchronization is achieved through per-object monitors. Any programmer who uses it needs to be aware of the possibility of deadlock, wherein one thread tries to acquire the monitor locks on two objects, and another thread tries to acquire them in the opposite order. The semantics specify a particular implementation that imposes these constraints.
But that implementation could change and be replaced by, say, transactions, and the only change in semantics would be to release the programmer from the burden of ordering the objects. Such a change would be a simple case of lock elision, and it would improve performance in cases where simple read, or mostly read, operations were
allowed to overlap. Moreover, when primitive hardware transactions don't guarantee forward progress, synchronized code could be implemented with hybrid transactions. And, again, as the theory around software transactions advances, so too could the implementation of synchronized.
Clearly, it would be contradictory for a low level language not to provide the primitives for implementing either a monitor/mutex or intrinsics for hardware trans-actions. Nevertheless, implementing hybrid transactions by hand is both tedious and hard to get right, and it makes code difficult to reason about and maintain. More-over, the presence of such a feature wouldn't adversely impact the performance of any application that didn't explicitly use it, meaning low level languages don't ben-efit from its absence. On the contrary, requiring programmers to use the primitives for such a feature requires reinventing the wheel for every case, making it a barrier to implementing concurrent data structures in C and C++.
2.5
Concurrent Memory Reclamation
To recap: Concurrent data structures exist in high performance applications and benchmarks written in low level languages... but they're modified from what's pre-sented in the literature in the applications, and typically leak memory in the
micro-benchmarks.[47, 48] The dilemma of modifying data structures versus leaking memory
in low level languages is, at its core, the aforementioned problem of invisible readers. This is a non-issue in high level languages, which clean up their memory through garbage collection (GC). Detecting that no thread holds a reference to an object is just another day at the job for GC, and high level languages (especially high level systems languages) solve this problem trivially.
In low level programming languages, the issue is decidedly non-trivial. The con-ventional solutions can be classified in the following groups: Conservative GC[34,
721, epoch-based[67, 66], reference counting[35, 42], pointer-based[71, 80, 17], and
Rust[64]. Each of these are described in turn, followed by a section on StackTrack[1] which makes a significant step towards a principle that's relevant to the research
presented in this thesis. But I'd be remiss not to observe that the proliferation of so-lutions draws attention to the complexity of the problem. Unsurprisingly, concurrent data structures, as presented in the literature, typically drop pointers to removed
objects and leave memory cleanup to the implementation - they avoid the matter
altogether. This works well enough for high level languages that use GC, but we'll see that even GC isn't without its pitfalls; points that make it unpopular in low level languages. To speak precisely about this problem, let us establish a few definitions.
Consider a set of n threads, communicating through shared memory via primitive memory access operations: These operations are applied to shared objects, where each object occupies a set of (shared) memory locations. A node is a set of memory locations that can be viewed as a single logical entity by a thread. A node can be in one of several states [71]:
1. Allocated. The node has been allocated, but not yet inserted in the object. 2. Reachable. The node is reachable by following valid pointers from shared
ob-jects.
3. Removed. The node is no longer reachable, but may still be accessed by some thread.
4. Retired. The node is removed, and cannot be accessed by any thread, but it has not yet been freed.
5. Free. The node's memory is available for allocation.
Concurrent memory reclamation is defined as follows [51, 711. We are given a
node (or a set of nodes) which are removed, and we are asked to move them first to state retired, then to state free. Once in state retired, nodes are no longer accessible by any thread besides the reclaimer, and therefore cannot lead to access violations. The key step in the problem is deciding when a node can be retired, i.e., when it is no longer accessible by concurrent threads.
The properties concerning developers are intuitively all related to performance, but although such techniques are available, the difficulty in implementing or deploying