Multiple languages and multiple methods : qualitative and quantitative ways of tapping into the multilingual repertoire
21
0
0
Texte intégral
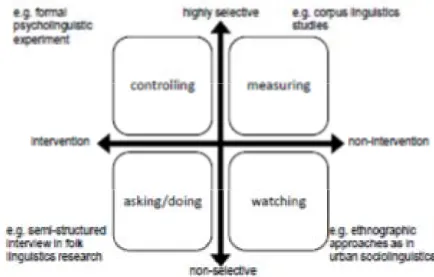
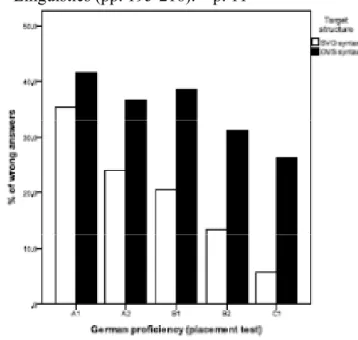
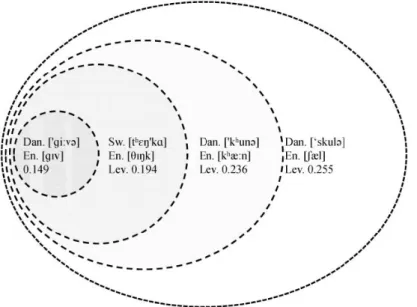
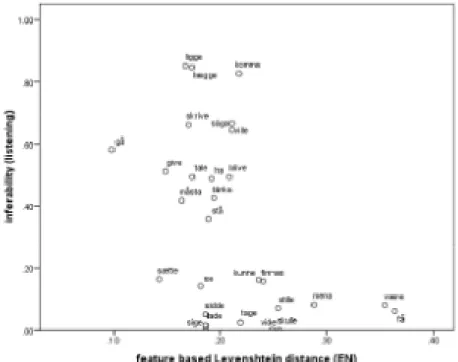
Figure
Documents relatifs