Learning in games via reinforcement learning and regularization
Texte intégral
Figure


Documents relatifs
The method employed for learning from unlabeled data must not have been very effective because the results at the beginning of the learning curves are quite bad on some
Given such inconsistency, the delayed rewards strategy buffers the computed reward r at for action a t at time t; and provides an indication to the RL Agent-Policy (π) to try
On the other hand, both applications received high scores in perceived audio- visual adequacy, perceived feedback's adequacy, and perceived usability.. These results provided a
In this study the creation and learning within the game agent, which is able to control the tank in a three-dimensional video game, will be considered.. The agent’s tasks
The re- sults obtained on the Cart Pole Balancing problem suggest that the inertia of a dynamic system might impact badly the context quality, hence the learning performance. Tak-
Model-free algorithms (lower branch), bypass the model-learning step and learn the value function directly from the interactions, primarily using a family of algorithms called
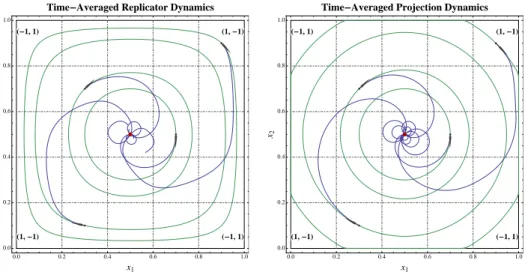
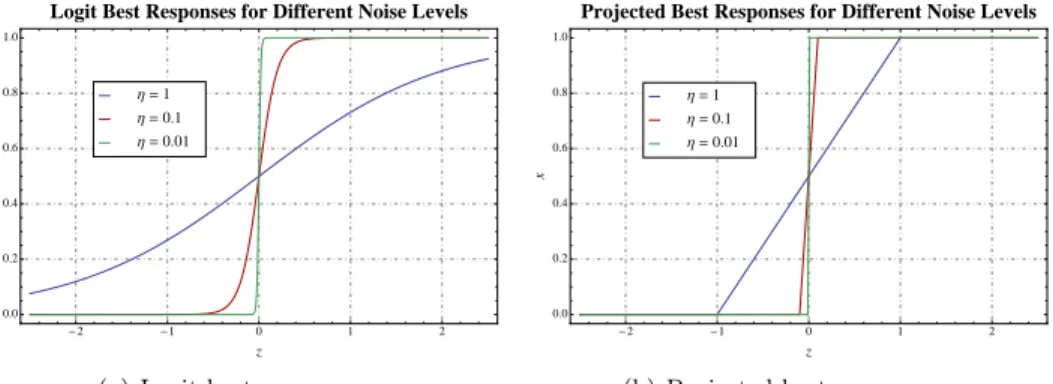
In a follow- up article (Viossat, 2005), we show that this occurs for an open set of games and for vast classes of dynamics, in particular, for the best-response dynamics (Gilboa
It is shown that convergence of the empirical frequencies of play to the set of correlated equilibria can also be achieved in this case, by playing internal
