Design of a Genetics Database for Gene Chips
and the Human Genome Database
by
Benson Fu
Submitted to the Department of Electrical Engineering and Computer Science
in partial fulfillment of the requirements for the degree of
Bachelor of Science in Electrical Engineering and Computer Science and Masters of Engineering in Electrical Engineering and Computer Science
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
May 22, 2001
@ 2001 Massachusetts Institute of Technology All rights reserved
A u th o r... . . Department of Electrical Engineering and Computer Science
May 22, 2001 Certified by... ... .. r. 7*TForbes'Dewey, *Jr. Professor Thesis Supervisor A ccep ted b y ... .. ... Arthur C. Smith Chairman, Department Committee on Graduate Students
BARKER OF TECHNOLOGY
Design of a Genetics Database for Gene Chips
and the Human Genome Database
by
Benson Fu
Submitted to the Department of Electrical Engineering and Computer Science on May 22, 2001 in partial fulfillment of the requirements for the degree of
Bachelor of Science in Electrical Engineering and Computer Science and Masters of Engineering in Electrical Engineering and Computer Science
Abstract
Human medical research has traditionally been limited to the analysis of disease symptoms. Although this research has produced many advancements in the medical field, the availability of human genetic sequence data will lead to further advances in diagnosis and treatment. With new sequencing technology and the near-completion of the Human Genome Project, the situation is rapidly changing. We have designed a database federation platform that manages gene chip experimental information and genetic data from the Genome Project. The combination of both sources will provide a powerful information system for medical research purposes. The integration of Affymetrix gene chip data and a schema of the Human Genome was used to test the design.
Keywords: Human Genome Project, Affymetrix, GATC, genetic databases, gene chips, database federation, federating databases, query mediation, heterogenous databases
Thesis Supervisor: C. Forbes Dewey
Contents
INTR O DU CTIO N ... 5 TERM IN O LO G Y ... 6 L BA CK G R O U N D ... 7 A . Past Projects ... 7 B. Current Projects ... 8C. The Problem at H and ... 9
Hum an G enom e D atabase ... 9
GATC D atabase ... 10
Querying Both D atabases ... 10
11. DESIG N G O A LS ... 12
111. TECHNOLOGY USED IN THE FEDERATION PLATFORM ... 15
A . Storage and Processing w ith a Local D atabase ... 15
Latency and Throughput ... 15
Storage M anagem ent and Scalability ... 15
Efficient Query Processing ... 16
Future Benefits ... 16
B. Interface and Transport w ith JDBC ... 16
Sim plicity and V ersatility ... 17
Object-Relational Support ... 18
ODBC Com parison ... 18
Current Im plem entation ... 18
C. ClassM apper Concept ... 19
IV. THE FEDERATION PLATFORM DESIGN ... 20
Starting the Federation Platform ... 20
H ow a Query Is Structured ... 20
W hen a Query Is Subm itted ... 21
V . AR CH ITECTU RE ... 23
ClassM apperRepository ... 23
DistributedQ uery (D ata Structure) ... 24
QueryD ecom poser ... 25
SQLQueryParser ... 26
DBD elegator ... 28
JDBCH andler ... 30
V I. IM PLEM EN TA TIO N ... 32
ClassM aps ... 32
V II. DISCU SSIO N ... 32 B u g s ... 3 2
M alfon-ned ClassM ap files ... 32
StringTokenizer Bug ... 32
Large D ata Sets ... 32
Dropping Tables ... 33
Future Im provem ents ... 33
Threading capabilities ... 33
S ec u rity ... 3 3 Query Optim ization ... 33
Deploying the Federation Platform ... 33
BIBLIO GR APHY ... 34
APPENDIX ... 37
FederationPlatfonnjava ... 37
ClassM apRepository.j ava ... 38
ClassM ap.java ... 41 DistributedQueryjava ... 43 SQLM onoDBQuery.java ... 46 SQLTableQuery.j'ava ... 47 QueryD ecomposerjava ... 51 SQLQueryParserjava ... 55 DBDelegatorjava ... 63 SQLJDBCHandlerjava ... 67 InfonnixJDBCHandlerjava ... 69
Introduction
The Human Genome project has expanded the horizons of both the biological and medical communities, the latter of which is the ultimate consumer of these advances. Medical research into human diseases has been mostly based on the analysis of symptoms, and more recently, the use of genetic sequences. Until several years ago sequencing was a prohibitively expensive endeavor. With current technological advances and the huge push of the Human Genome Project, it appears that the relevant sections will be sequenced within the next year. This wealth of data can be used for medical research, but the raw data must be organized into a coherent schema-one which links it to relevant information.
This thesis proposes an application design for handling Affymetrix Gene Chip databases and the Human Genome database (HGDB). This application can be used to access genetic data from a gene chip database and the Human Genome database as if both were combined into a single database. The application uses a query-mediated approach to create a database federation where both databases remain autonomous. The concept of the ClassMapper was implemented into the system to provide descriptions of the
underlying databases. As a proof-of-concept, sample data contributed by the Sorger Lab at MIT was used. The creation of this program will allow researchers to link their experimental data with the information held within the Human Genome database.
The Human Genome database is essentially a large distributed work-in-progress effort that acts as an "encyclopedia" for information about which genes are related, how they are related, where the gene is located, what research has been done for each gene, and other related information. Gene chips and DNA microarrays, on the other hand, are the commercial tools for high volume genetics testing of mRNA samples. The two are related in that they deal with genomic information. While one describes records of clinical DNA test the other describes biological behaviors of the DNA. To be able to leverage the information from both, a system must be able to seamlessly access the data contained in both databases.
The key benefit of implementing a system that can interpret the data from gene chips in conjunction with the Human Genome Database is that cross-realm queries are then possible. In the case of Affymetrix gene chips, the results are output to a database containing experimental data. This database was designed for experiment analyses and thus contains limited information. The Human Genome Database was designed for accumulating and distributing genetic data. Being able to tie the two together would enable the user to make queries that allow data-mining across the two domains. This would be especially useful since it would allow the user to easily perform compound and complex queries to obtain information that is not contained in the gene chip database
itself.
This document investigates a database federation approach to enable cross-realm queries. An application, referenced as the federation platform in this document, was implemented as a proof-of-concept to handle the gene chip database and the HGDB. The federation platform was written in Java and several new technologies were implemented to align the application with its design goals that are mentioned later in this document.
Terminology
This document uses certain terms that have different meanings from document to document. To clarify the way they are used later in this paper, the following terms are defined.
Aggregate query - The query used after all of the data is aggregated on the local database.
Database federation - A system that accesses heterogeneous databases into a loosely coupled manner. For most database federations, site autonomy is preserved. Distributed database - A system that accesses homogeneous databases in a tightly coupled manner. Distributed databases usually have limited site autonomy. Currently, several major database vendors support distributed databases.
Data warehousing - The concept of storing information from data sources or databases into a central repository. This repository is then used as the access point for retrieving information.
DBMS - DataBase Management System.
DBPath - A qualifier used in the query syntax to indicate in which database the table resides. The syntax for a DBPath is [DatabaseName]->[TableName]. More
information about DBPaths is mentioned later in this document.
End-database - An individual database that is contained in the database federation. Federated query - A query sent to the federation platform that might access multiple
databases.
Federation Platform - The federated database system that this document describes. Local Database - The database on the server or intranet used to store tables from
end-databases.
I. Background
Prior to designing the system, many multidatabase system designs were investigated. Pre-existing databases, existing software, existing hardware, user
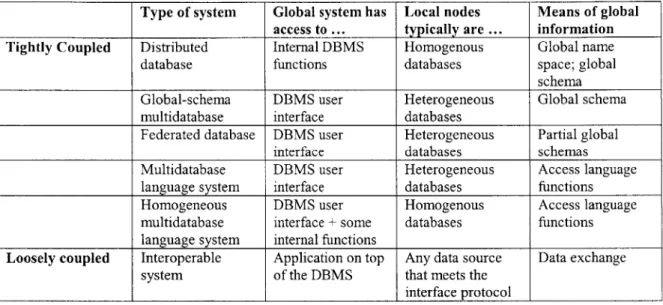
requirements, and bandwidth requirements are the determining factors in deciding which system is optimal. The table below shows the distinctions among different multidatabase systems. The classification of each system is based according to how closely the global system integrates with the local database management system.
Type of system Global system has Local nodes Means of global
access to ... typically are ... information
Tightly Coupled Distributed Internal DBMS Homogenous Global name database functions databases space; global
schema Global-schema DBMS user Heterogeneous Global schema
multidatabase interface databases
Federated database DBMS user Heterogeneous Partial global
interface databases schemas
Multidatabase DBMS user Heterogeneous Access language
language system interface databases functions
Homogeneous DBMS user Homogenous Access language
multidatabase interface + some databases functions language system internal functions
Loosely coupled Interoperable Application on top Any data source Data exchange
system of the DBMS that meets the
interface protocol
Table 1. Taxonomy of information-sharing systems.
After the investigation of multidatabase systems, it was decided that the federated database system design was to be used. While making it appear as if all of the end-databases are merged into one, a database federation keeps each end-database
autonomous such that they are affected as little as possible. In addition, the nature of the database federation allows for heterogeneity among its end-databases-an important benefit when dealing with biological databases. The concept of the ClassMapper [See Technology Used section later] was also investigated since its utilization aids in
homogenizing various heterogeneous data sources. Since many biological databases are very heterogeneous, this was an important issue for the system design.
Past and present projects in the field of federated database systems were
researched. Specifically, the historical aspects of past projects and the designs of many current systems were studied. The tradeoffs for each system helped in determining the design of the system this document describes. The major projects that were most relevant to the problem at hand are discussed below.
A. Past Projects
During 1994, there were many ongoing projects involved in global-schema multidatabase systems and federated database projects. At the time, each global-schema multidatabase project was either in the research or prototype stage. Many of these projects have since vanished. Of the federated database projects that were in existence
during 1994, many seem to have disappeared as well. Two noteworthy examples are discussed below.
Mermaid, a global-schema multidatabase prototype made by Unisys, showed great promise in the late 1980's [38]. Mermaid's hope was to become a front-end to distributed heterogeneous databases. The plans were to allow the user of multiple databases stored under various relational DBMS's to manipulate data using SQL or ARIEL (ARIEL is a proprietary query language). The complexity of the distributed, heterogeneous data processing was to be transparent to the user. Mermaid's main emphasis was in query-processing performance: the internal language DIL (Distributed Intermediate Language) was optimized for interdatabase processing. Mermaid evolved into Inter Viso, a commercial product sold by Data Integration, Inc. Ultimately the commercial product was discontinued and little information is known about its last developments.
Pegasus was designed as a federated object-oriented multidatabase at the Hewlett-Packard Laboratories [38]. The attempt was to become a full DMBS that could integrate heterogeneous, remote databases. The hope was to have global users add remote
schemas to be imported into the Pegasus database, thus making it a dynamic federated database. Nonobject-oriented schemas were mapped to object-oriented representations within the global database. The global access language HOSQL (Heterogeneous Object SQL) had features of a multidatabase language system; however, local users were responsible for integrating imported schemas. Although the system gained quite a bit of publicity, Hewlett-Packard eventually discontinued its work on Pegasus. There is little documentation as to why HP stopped further development, but it is known that its publications ceased in 1993 when the system was still in its research phase.
B. Current Projects
One can only speculated as to why the former systems stopped being developed. Perhaps it was more difficult than the companies first anticipated to create a generalized federated system. It is also possible that the companies just shifted their focus away from federated database systems. Regardless, the problem to conquer database heterogeneity still exists today. Current federated database systems in the biological realm are still being developed. Several ongoing projects that are tackling the same type of problem that the federation platform is dealing with are as follows.
One tool was built by several researchers at the University of Pennsylvania in Philadelphia [41]. These researchers in the Kleisli Project built the tool that allowed
scientists to use a single query interface to compare their data against a variety of collections. Kleisli currently is a tool for the broad-scale integration of databanks that supposedly offers "flexible access to biological sources that are highly heterogeneous, geographically scattered, highly complex, constantly evolving, and high in volume". The tool does handle a wide variety of data sources but at the expense of ease-of-use. Since the system was meant to handle nearly any type of data source, the query language of the
system is very complicated and difficult to use. The system overcomes heterogeneity by expanding the language set for each different data source. Obviously, the language set becomes more complicated as more data sources are supported. This is where the
ClassMapper concept could come into play to condense the query language by homogenizing the databases or data sources. As a last note, the Kleisli product was
continued into the commercial world as the product named "gX-Engine" that is now owned by the company GeneticXchange Inc. [42].
Another company, LION Bioscience AG in Heidelberg, Germany, markets a tool called SRS [43]. This tool helps the integration of databases for many pharmaceutical firms. The system handles quite a variety of databases, however, attaching an new database requires a decent amount of work. Each database type added to the system must have a specialized interface that must be programmed into SRS. Again, to overcome this non-generalizable approach is where the ClassMapper concept would come into use. Transforming a number of heterogeneous databases into a set of homogeneous databases would allow the federated system to manage its data without the hassle of being limited by the interfaces of the individual databases. Having a ClassMapper for each database could provide this homogeneity.
MARGBench is a system which enables querying several databases in SQL by translating SQL queries into a source database specific interface [24] [44]. Developed at the Otto-von-Guericke-University in Magdeburg, Germany, MARGBench is a database
federation that simultaneously queries biological source databases online. The
architecture of the system is similar to the architecture of the federation platform in many ways. MARGBench is a database federation that has a SQL interface, uses the concept of Adapters instead of Handlers (mentioned in the paper), takes advantage of JDBC connections to end-databases, and is able to make cross-realm queries across a number of heterogeneous databases. The system even has a local database to handle caching of the data. Where MARGBench and the federation platform differ is in the way the end-database table information is revealed. In the federation platform, ClassMaps reveal the table information of the end-databases before queries are handled. In MARGBench, the concept of an ontology is used. The ontology is effectively a list of connections that link the data between the end-databases. While this concept is useful in connecting data, it does not help to overcome heterogeneity issues. Custom-made adapters must still be built for each type of database in its federation. Similar to the federation systems
previously mentioned, this non-generalizable approach does not scale well when there is a large amount of heterogeneity. For the federation platform, the evolution of the ClassMapper will eventually consolidate database communication into a single interface no matter how heterogeneous the underlying databases are.
C. The Problem at Hand
Human Genome Database
The Human Genome Database (HGDB) has literally terabytes of information that includes genetic sequences and related metadata. When the Human Genome database was first designed, it made sense to order the data in an object-oriented fashion. Because the nature of the data had fixed associations such that genome data could be treated as objects, the system was built to handle genomic segments as objects that contained names, descriptions, and associated links to other objects. In addition, the requirement of managing such large amounts of data lent itself to an object-oriented design which is relatively scalable.
The information contained in the Human Genome Database can be broken down into three main object types. The types are as follows:
* Regions of the human genome, including genes, clones, amplimers (PCR markers), breakpoints, cytogenetic markers, fragile sites, ESTs, syndromic regions, contigs and repeats.
" Maps of the human genome, including cytogenetic maps, linkage maps, radiation hybrid maps, content contig maps, and integrated maps. These maps can be displayed graphically via the Web.
* Variations within the human genome including mutations and polymorphisms, plus allele frequency data.
The database contains a huge wealth of information that can be used to reveal large amounts of genomic information about a gene sequence or gene fragment.
However, the interface to the database is designed for inserting and extracting the data, not for data mining or complex querying. Thus the information contained in the Human Genome Database is not being fully utilized to its potential.
William Chuang's work with the HGDB was used as an example database in the federation platform. In his project, an object-relational implementation and ClassMap for the HGDB was created. The schema was implemented as an end-database in the
federation and the ClassMap was extended to also describe connectivity information.
GA TC Database
The companies Affymetrix and Molecular Dynamics teamed up to form the Genetic Analysis Technology Consortium (GATC) to build a platform to design, process, read and analyze DNA-chip arrays [10]. One product that came out of the GATC was a specification for a database to handle the data of DNA-chip experiments. The
information contained in the GATC databases are recorded intensities that correspond to the amount of targeted DNA that the sample has. These DNA targets correspond to specific DNA segments that are characterized by certain biological behaviors. For more information about how DNA-chip arrays work, see [45].
The GATC database specification has a basic relational architecture that is geared to store experimental data. In William Chuang's work, an object-relational
implementation of the GATC database was created. It was decided that the database needed to be object-relational to give researchers the ability to easily import their experimental data directly into the new ORDBMS without requiring additional messaging.
William Chuang's GATC database was used as an additional example database in the federation platform. Its schema was implemented as an end-database in the
federation and the ClassMap was extended to also describe connectivity information.
Querying Both Databases
To truly leverage the experimental data in the GATC database and the genomic characteristic information in the HGDB, the two must be utilized together. The DNA identifiers (called AccessionID's) in the GATC database correspond to DNA segments with genomic characteristics. However, these characteristics are stored in the tables and
connections of the HGDB. In order to associate a particular DNA segment from an experiment with its genomic characteristics, both databases must be used in conjunction
with each other. The problem then becomes the task of querying data across two database domains.
Merging the two databases into a feasible solution to the problem, but this is not necessarily the best route. Updating the table information from both sources can be a cumbersome task especially if there is no mechanism to tell whether a table needs to be updated. Plus, the HGDB literally contains terabytes of information. Managing massive amounts of data could be a challenging task in and of itself.
The federation platform that this document describes is a solution to this problem. The two databases are left autonomous as end-databases of the system. The
information retrieved from both are performed ad hoc so that the data are fresh. The system also allows cross-queries across both domains without having to merge the two schemas. The next section describes the design of the federation platform.
II. Design Goals
The architecture of the system was designed to be a federated platform with the following design goals in mind.
Data Freshness
Since biological databases are constantly being updated, having the most up-to-date information is often times important to the work of the researcher. Working against old data can sometimes mean the difference between a success and a failure of an
experiment. As mentioned before, data warehousing has many of its own advantages, but it lacks freshness from its databases since its data fetching is not performed when tables are accessed by the system. In the proposed architecture, the user of the system is guaranteed fresh data since all of the data fetching is performed on an ad hoc basis.
The tradeoff of this design goal is that if a database in the group is down, the query will fail [See Figure 2]. In addition, without optimizations, the guarantee of fresh data comes with the sacrifice of speed, especially if the network connection is at a low speed.
Site Autonomy
Many of the existing biological databases were designed to serve the purpose of receiving and hosting biological information. For nearly all of these databases, the database structures were not intended to be changed. Thus, to modify the underlying structure of each database, a great amount of work would have to be done. What the federation platform allows is site autonomy of existing databases. That is, the platform does not require modifications to the end-databases for them to be used in the system. The federation platform only requires that it have query access to the end-databases.
In addition to not touching the underlying structure, the database federation requires no special maintenance at its end-databases. This is especially useful since most biological databases are maintained by specialized groups that do not have the time or resources to make modifications for non-critical components of their system. Again, the federation architecture allows for site autonomy that is often times required for adding certain databases.
Flexibility/Expandability
To be able to handle additional end-databases with different means of connectivity or querying interfaces, the system must have a flexible and expandable architecture. This thesis seeks a partial solution with an expandable architecture.
Since the architecture was designed so that a new handler object is instantiated for each database registered in the federation, the system can simultaneously use different database interfaces. This means that as new database interfaces are created for the platform, old ones do not have to be upgraded or sacrificed since all can be used
concurrently. This functionality allows future support for a large variety of databases in the database federation.
Ideally, the system will increase its expandability with the evolution of the ClassMapper concept. The current system utilizes the ClassMapper concept with ClassMaps of each database. As mentioned in the Technology Used section, the
ClassMapper concept hopes to reduce heterogeneity by providing the database or data source with a homogeneous presentation to the outside world. An evolved ClassMapper would provide this to allow universal flexibility and expandability for practically all systems that access multiple databases.
Scalability
In order to completely leverage the power of a database federation, the system must be able to support many databases simultaneously. If it is the case that only a small number of databases can be queried against during a single federated query, then the utility of the system drops dramatically. Especially in the realm of biological research, multiple databases must be used at the same time or otherwise data could be incomplete. The design of the federation platform theoretically scales to an unlimited number of end-databases. This is primarily because of how the local database is used.
As is mentioned later in the thesis [See The Federation Platform Design], when a federated query is submitted, the federation platform copies the vital data of the
accessed tables to local database. This is performed one table at a time until all required table information is transferred to the local database. Once all of the information is aggregated, the federation platform finally runs a query on the local database. The results returned are returned to the user.
In some sense, the local database effectively acts as a buffer between the end-databases and the user [See Figure 2]. By looking at the system in this framework, the table information from the end-databases is collected in local database until all of the required data is transferred. Each transaction of copying a partial table from an end-database to the local end-database is done separately so that transfers do not consume large amounts of system resources. The system can delegate how much resources can be used for copying to ensure that the system does not become overloaded. Even if there is a large number of tables that need to be copied, the system can transfer the data as fast or as slow as it possibly can, depending on the amount of system resources available. Once all of the tables are inserted into the local database, the local database can be queried for the results to be returned back to the user.
This approach allows the system to scale to a relatively limitless number of table transfers since the local database is used as a buffer for table information. The tables are added piece by piece into the local database until all of the tables are collected. In addition, since the platform can regulate the transfers by system resources, the size of transactions does not matter. Ultimately, this design allows the system to scale as more tables and databases are added to the database federation.
Transparency
Transparency of the accesses to end-databases is important because the potential complexity of the database federation. Since the users of the system could get confused handling the database operations, all database accesses were managed by the federation platform. The targeted users of the system are researchers who may have little or no experience with database management. By hiding this from the users, the database federation appears to act as one large, single database to the user. This transparency adds to the ease-of-use of the entire system.
In addition to the added ease-of-use benefit, hiding the transactions of the underlying databases increases the overall security of the system. If the transactions of the end-database were observable, potential hackers could trace extra data about each
end-database. This extra data could contain information that could help the hacker discover the location of the database and exploit holes in the system. This transparency helps to avoid security problems by removing the user from the entire transaction process.
Portability
Since the federation platform was written in Java and uses JDBC for connectivity to the local database, it can be run on any up-to-date Java VM. With the support of Java VMs on MacOS, many flavors of Unix, and Windows operating systems, the platform can be run on a wide variety of machines with practically no modifications to the code. In addition, JDBC is platform neutral as well, thus requiring no main connectivity
changes in the code.
Although JDBC allows the server and application to be on different platforms, Informix is also written for a variety of operating systems as well. This also increases portability of the system since even the local database can easily be ported to different machines.
Usability
Because many of the database federation system attempt to accommodate for so many heterogeneous data sources, the querying language for the system is difficult to
learn and use. Because researchers who use biological databases do not usually come from a strong computer science background, they find learning a new computer language often times very daunting and difficult.
This federation platform is rather useable when compared against other systems that use a cumbersome querying language. This is because queries in the federation platform are similar to standard SQL queries in that they follow a "SELECT-FROM-WHERE" clause format. By using queries similar to SQL, users who already know SQL can immediately begin using the federation platform since they are familiar with how queries are formed. For those users who are not familiar with the SQL querying language, it can be learned very quickly since it has a low learning curve. Overall, the design decision to use this querying language format makes the system more useable to those who are unfamiliar with standard SQL as well as those who are.
III. Technology Used in the Federation Platform
A. Storage and Processing with a Local DatabaseTo utilize the functionality built into database management systems, a decision was made to implement a localized database in the system. This was done for several improvements in design and performance. They are as follows:
Latency and Throughput
By storing the table information on a system near the federated platform, the table information can be obtained with a low latency (low access time) and a high throughput (large bandwidth). Ideally, the database will run on the same server as the federation platform so that network interfaces will not hinder the overall performance of the system. However, even if the database resides on another server in the intranet, current network
speeds of 1 ObaseT or 1 00baseT (a maximum of 1.2MB/sec and 12MB/sec theoretical throughputs, respectively) are adequate to serve the information flowing between the database and the platform effectively.
If caching of the tables is used in future implementations, then the federation platform must access the data multiple times. In order to make the remote database tables
available to the system for multiple accesses, the data needs to be stored in a location where it can be accessed quickly. Accesses to a "local" copy of the tables will reduce the
amount of time it takes to process a federated query since the data would not need to be fetched again. For a caching system in the future, it would be ideal to cache large
amounts of data in the local database and have the federation platform check its freshness before it is retrieved from the cache. This may be necessary, especially for the Human
Genome Database and other large databases, where the lack of a caching component would potentially require gigabyte-sized fetches.
Storage Management and Scalability
The fetched table data from separate end-databases must be stored before they are processed and sent back to the user. If the tables are stored as JDBC Java objects, large amounts of memory are consumed unless the objects are written to disk. However, even if the tables are written to disk, to efficiently process the table information, all table objects must be loaded into the memory of the system. Thus, using a local database helps to overcome these problems in managing the database information. Utilizing a local database simplifies the information management and efficiently handles storage since databases are built with these goals in mind.
Storage scalability is another advantage that comes when using a local database. The databases and system resources of today can handle information sizes that are on the order of many gigabytes. Storing large amounts of data from end-database tables is not a problem with a local database. If the user of the federation platform anticipates that a query will require huge amounts of table data to be accessed, then the space of the local database can be adjusted accordingly.
In addition, the local database provides the added benefits of security, recovery, and data integrity that are already built into the Database Management System (DBMS). Although these features are not part of the design goals, they could come into use for future goals of the federation platform.
Efficient Query Processing
Before results can be sent back to the user, tables from separate end-database must be fetched and processed according to the conditions of the query. Since it is partial table results that are returned from the end-databases, it seems natural to store these tables in a database and process the information from there. Building a module that could process the data based on the SQL conditions of a federated query would basically be reinventing the query engine of a standard database management system. Therefore, it was decided that it would be more efficient to use the query engine of a database instead of a self-made data processing module. The most practical way of using a pre-existing
query engine was to implement a local database into the system. By adopting the query engine of the local database, the processing capabilities of the federation platform became as scalable and efficient as the local database itself.
Future Benefits
To deal with more complex queries in the future, the federation platform can use the built-in functionality of the local database to aid in processing. For instance, many
databases have object-relational schemas. To be able to have these schemas be supported by the federation platform, the system must be able to handle obj ect-relational
processing. In future versions, the system could be tailored to support object-relational operations by using the preexisting processing capabilities of the local (object-relational) database.
With the local database, caching of table data is a feature that could be added to the federation platform. Table data fetched from end-databases could be stored in the local database and reused until the information expires. The caching scheme would have to incorporate a time stamp to calculate the "freshness" of the data in the tables since there would be no guarantee that the cached data would be up-to-date. Further details would be determined later when this functionality is implemented into the system.
Regardless, having the local database could tremendously reduce the amount of code needed to add a caching feature.
B. Interface and Transport with JDBC
Java DataBase Connectivity (JDBC) has recently emerged as a growing standard for database connectivity. With the explosion in adopters of Java, Java-based standards have emerged. What JDBC provides Java developers is a standard API that is used to
access databases, regardless of the driver and database product. That means that any Java application can connect to nearly any database no matter what platform the application runs on or where the database resides. This is possible in part by the acceptance of the JDBC standard by both Sun, the creators of Java, and all major database vendors
including Oracle, Informix, and IBM. This portability makes JDBC ideal for applications that need to access databases over networks. For the design of this system, JDBC is used for database connectivity for the end-databases as well as the local database. This
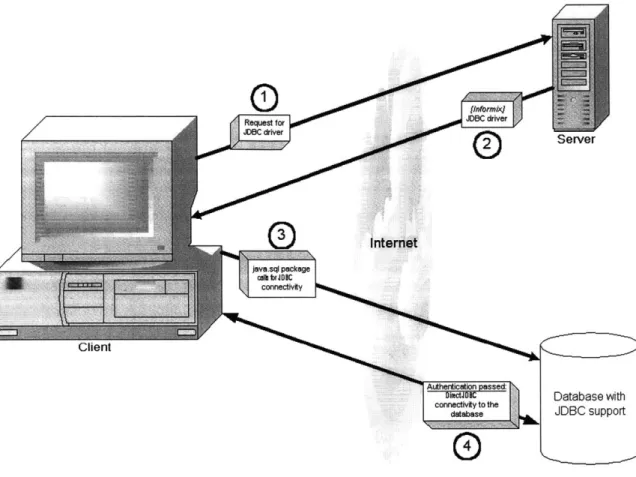
Fgr 1. cle t o nriJDBC driver
Simplicity Sever
internet
Client
Aatio ed:authentication corFr b e t h to the onnc s
databas JDBC support
Figure 1. A client connecting to a database via JDBC.
Simplicity and Versatility
A large amount of value is gained by using JDBC because of the simplicity of
data access and data manipulation. In JDBC, the lower level connectivity layers are hidden from the developer to allow easier data access. The user has to only specify a valid TCP/IP location of the server running the database and the correct authentication for a connection. Figure 1 above demonstrates how a client machine connects to a database via JDBC.
During JDBC operations, database queries are returned as ResultSet Java objects from the java.sql package. A single ResultSet object contains the complete information that is normally returned from the query. The data contained in the object can then be accessed programmatically by traversing through the rows and columns. Field types and values are easily extracted and turned into Java objects or primitives through the standard methods in the ResultSet object. JDBC allows scrolling through the ResultSet object so that the programmer can quickly jump to any row, column, or field. Even inserting data is made easy by using methods in the package that allow for inserting rows
programmatically (as opposed to sending database-specific text insert statement to the database). Support for batch updates is another key feature that makes JDBC very
Object-Relational Support
JDBC also goes beyond relational processing. The movement for better object-relational databases connectivity has pushed JDBC to support object-object-relational features. The support for various data types already exists with limitations on handling large objects, however, the scalability and the expanding number of supported data types will make JDBC the preferred approach to handling object-relational data accesses. As mentioned in previous sections, strong object-relational support is key for biological databases since much of the information associated is metadata that must be stored as objects. JDBC's continuing support to move this direction will ultimately help in being a tool to manage biological information.
ODBC Comparison
Currently, other forms of connectivity such as Open DataBase Connectivity (ODBC) and ODBC <-> JDBC bridges still exist since they are connectivity standards still used today. However, the major database vendors have recognized the growing demand for Java applications and have shifted their focus from developing ODBC to JDBC. With this progression into a more Java-centric slant, ODBC is slowly getting outdated.
Since ODBC is accessed via C or C++, client software must be written in C or C++. While this is appropriate for many scenarios (where the point of database access is a C or C++ program), to use Java with a database that only connects via ODBC, an ODBC <-> JDBC bridge has to be used. While this conversion mechanism works for most cases, the bridge increases the number of inter-operating parts and potential sources of failure for the system. When a Java program is being used to communicate with a database, it is best to use pure JDBC.
Current Implementation
Informix uses a type 4 JDBC driver. A type 4 driver is a pure Java driver that uses a native protocol to convert JDBC calls into the database server network protocol. Using this type of driver, the Java application can make direct calls from a Java client to the database. A type 4 driver, such as Informix JDBC Driver, is typically offered by the database vendor. Because the driver is written purely in Java, it requires no configuration on the client machine other than telling the application where to find the driver. Once the driver is loaded, the application can access the database via the JDBC interfaces.
In the Federation platform implementation proposed in this document, JDBC database adapters were constructed as part of the platform. The reading adapter interface that was created fetches database information via JDBC and passes the table information back to the platform. For the local database that is located on the intranet (for low latency and high bandwidth), an additional JDBC adapter was made with database
writing capabilities. Using JDBC for reading from the database federation and writing to the intranet database allows for very clean and compact code for table transfers. (See Appendices SQLJDBCHandler.java and InformixJDBCHandler.java).
C. ClassMapper Concept
In the world of biological databases, the databases and data sources are very heterogeneous. The way the systems are accessed range in different interface types and their underlying database structures vary greatly as well. A query for one database may have a completely different syntax or semantic structure than a query for another. Many of these biological databases have query languages that were designed without the goal of using pre-existing semantics. Therefore, many of these databases have very different interfaces. In order to access a variety of these databases, the user must learn how to use each one of them. In addition, if a programmer wishes to build an application that accesses the databases, he must build a special interface for each heterogeneous database. Thus, there is a need for standards when it comes to biological data sources [22].
Patrick McCormick's document [2] details the concept of a ClassMapper. The main motivation for this concept is to conquer the heterogeneity of data sources that is so prevalent across medical and biological databases. A ClassMapper is an application that "sits on top" of a database (or data source) to standardize its presentation to the outside world. All communication between the ClassMapper and the database are hidden since the ClassMapper serves all information requests from the user. The added benefit is that the user can interact with each ClassMapper in the same way since the interface is standardized across every ClassMapper. Therefore, in some sense, each database "looks the same" to the user since obtaining information is performed in the same manner. With a ClassMapper residing on each database, all appear to be homogeneous. This concept is still being refined; however, it is apparent that standards need to be put in place to overcome heterogeneity.
The concept of the ClassMapper was used as part of the federation platform. Since the standards for ClassMappers are still undefined for the most part, descriptions of the HGDB and the GATC database were used. These descriptions are called ClassMaps since they are standardized descriptions of the databases. These ClassMaps were
obtained from William Chuang's work described in [21]. In this implementation, the ClassMaps were extended to include connectivity information to the end-databases. They were used by the federation platform to build a map of the tables contained in each database.
IV. The Federation Platform Design
Starting the Federation PlatformBefore the system can be used to query across the system, the accessible
databases must be properly registered with the federation platform. For each database in the federation, the ClassMap must be registered. The ClassMaps in the current
implementation contain not only the table information about the databases, but also the network location and authentication keys. These ClassMaps are stored as local files on the server running the federation platform and are automatically loaded when the application is loaded. Once the platform is loaded, it is ready to accept queries from the user.
How a Query Is Structured
A distributed query is similar to the standard SQL format [39]. The queries are structured with "SELECT", "FROM" and "WHERE" clauses. These clauses must be ordered correctly or else the system will not function properly. The order must start with "SELECT", followed by "FROM" and then followed by "WHERE". This restriction in clause order is similar to the rules in standard SQL.
In standard SQL, the column or columns specified in the "SELECT" clause are the columns that will return their results to the user. The "FROM" clause contains the table or the list of tables that are accessed by the query. If another clause in the query attempts to access a table that isn't explicitly declared in the "FROM" clause, the query is not processed. Therefore, all tables used in a query must be declared in the "FROM" clause. The "WHERE" clause contains an optional list of conditions to restrict the information returned back to the user. These conditions can be set as equalities or inequalities, comparing columns against values or columns against other columns. See [39] for more details about SQL.
In the federation platform, SQL queries are structured in practically the same way as standard SQL. A federated query has "SELECT", "FROM", and "WHERE" clauses that must be placed in the same order as a standard SQL query. Since all tables in the database federation are registered when the ClassMaps are loaded, when a table is referenced in any of the clauses, the federation platform knows if the table exists and on which database the table resides. Therefore, the user needs only to specify table names and columns in the clauses-the platform takes care of the rest. By hiding to the user where the table is located, the user can observe the database federation as one large, single database. The user query can then query against the federation as if it had all of the end-databases combined into one database. This functionality meets the design goal of creating transparency for the user.
Within the federation platform, the query is transformed internally into a query called a DBPath query. This type of query contains end-database names as prefixes to each table in the form [DatabaseName]
+
[TableName] or[DatabaseName] [TableName].[ColumnName] if a column is specified. This syntax makes explicit references to specific end-database instead of relying on ClassMaps. The system has the capability to accept DBPath queries directly from the user if he chooses to use this format. This feature is useful when the user wants to specify exactly where the
table is being retrieved. More details about the DBPath format are explained in the Architecture section.
When a Query Is Submitted
After a query is passed into the federation platform, the text of the query is passed into a decomposer module. The query is decomposed into end-database queries based on rules that are coded into the platform. In several other federated database systems such as those in [24] [26] [43], the systems decompose queries according to rules that are stored in a separate knowledge base that is adjacent to the system. These systems have their rules detached from the main system and read in by a module before processing any queries. By having a rule reader as part of the main implementation, this reduces the amount of work needed to be done when upgrading the rule set. Plus, this makes it easier to read how the system decomposes queries for users that are not familiar with the source code. However, to build a rule reader module, a flexible and upgradeable syntax must be created. Building this module will also take a considerable amount of extra work beyond building a single module with the rules hard-coded. This separation of rules from the main system should be investigated in the future to see whether this design decision is appropriate for the federation platform.
The logic of the current implementation is to copy table information from the end-databases into the local database. The federation platform does this systematically by parsing the federated query to determine each table that is accessed by the query. Once the all of the tables are determined, the platform constructs end-database queries to retrieve those tables. Several optimizations are put into the end-database queries to
download only certain parts of the tables. Specifically, the "WHERE" conditions are inserted into certain end-database queries when possible to narrow down the information returned by the end-databases. This reduction in data transfer decreases the amount of time it takes to retrieve all of the table information from the databases for the federated query.
Once all of the table information is retrieved, it is programmatically inserted into temporary tables on the local database. The original federated query is transformed into a query that is usable by the local database to query across all of the new tables. This query is called the "aggregate query" since it is performed after all of the table
information is aggregated on the local database. From there, the federated architecture lets the local database handle the query processing for the federated query. The results from the local database are then returned to the user. The results that are sent back to the user appear as if they came from a single database that contains all of the combined information across the entire database federation.
Once the results are sent back to the user, the local database no longer needs to store the retrieved table information. The tables are subsequently dropped to make sure the local database is not congested with old table data. This completes the federation platform's execution of a federated query. The following figure demonstrates the transactions that occur for a federated query.
0
Federated Query (String)
%t:)
Queries for Tables
o ATC C[TABLE G Federated Results D Local Database I uery
Ptial Queries for Tables
HGDB TABLE C
TABL 1
Figure 2. The transactions during a federated query.
0D
Federation Platform
V. Architecture
ClassMapperRepositoryBefore the federation platform can be used, the platform must have access to the ClassMaps of each respective database in the federation. As mentioned earlier, the ClassMaps provide a high level description of the database and the means of connectivity to the database. As the architecture stands, the ClassMaps are read from local files on the
same machine as the application, but it has the capability to read the ClassMaps from practically any source whether it be passed as Java String object or fetched from a remote
server. This ability comes from Java's built-in connectivity libraries.
When the ClassMaps are loaded into the ClassMapRepository object, the header that contains the connectivity information is first read. The header is written such that the federation platform knows everything it needs to connect to the database. An example of one of the headers is as follows:
-- CLASSMAPPER INFO ---- DATABASEALIAS: GATC ---- CONNECTIVITY: InformixJDBC ---- DATABASEIP: 18.999.0.156 ---- PORT: 1013 ---- DATABASENAME: gatc ---- ADDITIONALPARAMETERS: INFORMIXSERVER=BENFU --AUTHENTICATION(user) : informix ---- AUTHENTICATION(password): F43m2#lm.y
Figure 3. An example connectivity header for the GATC ClassMap.
After the header information is read, the repository continues to read the file and begins associating tables with its database name. The table names are stored with their corresponding database names in a hash table. In a hash table, the structure holds a list of keys with one corresponding value object per key. Hash tables are used for looking up values based on key values. The structure does not allow there to be identical keys so that it is guaranteed to have only one value for a single key. An identical value, however, can be associated with multiple keys. The structure for a hash table is set up in such a way that key-value lookups are linear in time [46]. That is, as the list of values grow, the hash table lookup times grow incrementally (with time increments that stay the same size). Another added benefit is that memory space also grows incrementally as more values are added. The linear growth behavior makes hash tables ideal for scaling fast lookups on large data sets.
Since one of the design goals was to scale to a high number of databases, the use of a hash table was natural. In the ClassMapRepository object, the designated hash table is used for fast lookups of table-to-database mappings and conflict notification in the event that more than one database has the same table name. As each ClassMap is loaded, it adds each table to the hash table and associates it with a mapping to the database that contains it. ClassMap objects are instantiated per ClassMap loaded to hold its connection and authentication information. This continues until all tables are mapped from each of the processed ClassMaps.
Once all of the tables are processed into the ClassMapRepository, the system moves on to constructing a DistributedQuery object. The repository is retained within the federated platform since it is referenced several times to find the mappings between tables during the execution of the federated query. However, the ClassMapRepository object is not modified later-it is only accessed to pull out database-table mappings.
DistributedQuery (Data Structure)
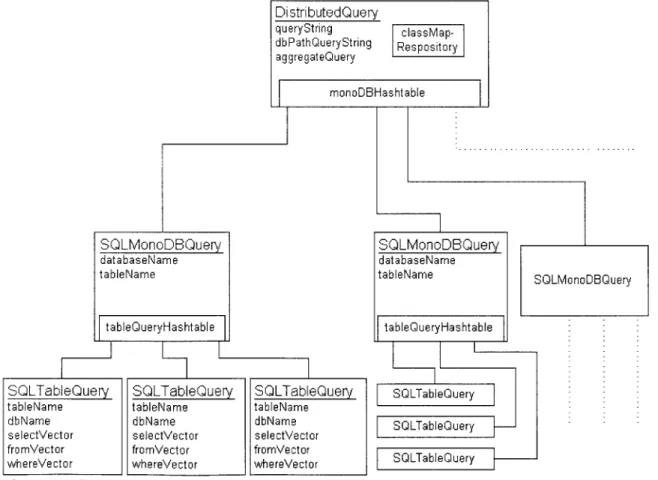
Once the repository has been established, the platform begins to construct its main data structure, a DistributedQuery object. At the creation of the object, only the
federated query (in String form) is set in the object. In addition, the DistributedQuery data structure is used throughout the architecture to store the ClassMapRepository object, the transformed federated queries, and the decomposed database queries. Detailed descriptions of when the different members are used will be mentioned later in the following sections. The structure of the DistributedQuery object can be seen in the following figure: DistributedQuery queryString classMap-dbPathQueryString Respository aggregateQuery monoDBHashtable SQLMonoDBQuey databaseName tableName table~ueryHashtable
SQLTableQuery SQLTableQuery SQLTableQuery
tableName tableName tableName
dbName dbName dbName
selectVector selectVector selectVector
fromVector fromVector fromVector
whereVector whereVector whereVector
Figure 4. DistributedQuery data structure object.
SQLMonoDBQuery databaseName tableName SQLMonoDBQuery tableQueryHashtable SOLTableQuery SQLTableQuery SOLTableQuery
The DistributedQuery object contains three String versions of the query: the original federated query, the federated query mapped with its database paths (DBPath), and the "aggregate query" or the final query that is used against the local database. The different modules in the system that set these last two members are mentioned later in
this section. In addition to the transformed queries, the DistributedQuery object contains an object oriented structure for decomposed queries.
It was decided that for an acceptable object oriented design, the hash table data structure would be used. As mentioned above in the ClassMapRespository section, using a hash table allows the system to scale appropriately as more values are added. This scalability is applicable to decomposed queries since in theory, as more databases are connected to the federation, the number and complexity of the decomposed queries will grow.
In designing how the data structures would be used in the system, it was
determined that each table query should be its own object. Since each table accessed by a federated query has to be partially reconstructed on the local database as a new table, it seemed logical to handle each transaction on a "per-Table" basis. Thus, the
SQL TableQuery object was used to encapsulated this abstraction. Each SQL TableQuery object contains a list of SELECT, FROM, and WHERE arguments as well as methods to modify the lists. The current state of the architecture only accepts these three SQL clauses. However, since the design of the system is modulated such that each clause is
stored as a list of arguments, adding more SQL vocabulary to the SQL TableQuery only requires adding another list of arguments. This design provides relatively quick data
structure upgrades for expanding the querying capabilities to the end-databases in the federation. In the event of an upgrade, more logic will have to be programmed into the query processor(s) of the architecture to accommodate for the expanded features in the SQL vocabulary.
Moving to a higher level of abstraction is the SQLMonoDBQuery object. Each end-database in the database federation is designated a SQLMonoDBQuery object which contains the all of the SQL TableQuery objects used to query against that specific
database. Grouping queries by database allows for easier management, navigation, and lookup of queries. Every SQLMonoDBQuery object stores each of its SQL TableQuery objects as values in a hash table with the corresponding key being the table name retrieved. By using the table name as a key to the hash table, this allows for fast lookup
of the SQL TableQuery object that is used to retrieve the file.
Moving higher up in the abstraction level brings us to the DistributedQuery object. Similar to the SQLMonoDBQuery-to-SQL TableQuery relationship, the
DistributedQuery object contains a hash table with database names as the keys and the SQLMonoDBQuery objects as the values. This again allows for fast lookups of
SQLMonoDBQuery objects.
By using this design for the data structure, the federation platform can quickly access all SQL TableQuery objects with logical groupings. As will be seen later in the explanation of the architecture, parts of the federation platform utilize these groupings to simplify the end-database query processing.
QueryDecomposer
After the ClassMaps have been processed, the system is ready to accept federated queries. When the client submits a federated query, the platform begins by first
instantiating a QueryDecomposer object and passing the query (in String form) to it. The QueryDecomposer object then constructs a DistributedQuery object and immediately
stores the federated query into the data structure. From this point on, only the DistributedQuery is passed between the different modules.
Before the DistributedQuery object is passed to the next module, the
QueryDecomposer makes a transformed copy of the federated query and stores this in the DistributedQuery object. More specifically, the decomposer object transforms the query such that each table is prefixed with a path to its respective database (DBPath query). The DBPath prefix is just the database followed by the "dash-greater-than" characters that look similar to an arrow. For each table referenced in the query statement, the
QueryDecomposer performs a lookup on the ClassMapRepository to determine which database the table belongs to.
As mentioned in the previous section, transforms for each table have the form of [DatabaseName] 4 [TableName] or [DatabaseName]
+
[TableName]. [ColumnName] in the query with DBPaths. For example, the table CHIPDESIGN stored in the GATC database would be transformed into GATC4CHIP_DESIGN in the new query. If the query is referencing a specific column in the database, the prefix stays the same. Therefore, the reference to the column CHIP_DESIGN.NAME in the GATC database would turn into GATC4 CHIPDESIGN.NAME in the DBPath query.If the transformation is successful, the DBPath query is stored in the DistributedQuery object. In the event that a table cannot be found in the
ClassMapRepository, the table name in the DBPath query is replaced with the string [NOT IN CLASSMAP]. Malformed references are also flagged with a [MALFORMED] string. This allows the user of the platform to identify syntax and spelling mistakes for references in the query.
SQLQueryParser
After the QueryDecomposer has finished inserting the DBPath query into the DistributedQuery object, it passes the data structure to an instantiated SQLQueryParser object. The SQLQueryParser begins the task of parsing the DBPath query. The decision was made to have the QueryDecomposer object parse the DBPath query for two reasons:
1) to decrease the dependency on the specifications ClassMapRepository by classes in the federation platform and 2) to give the user the option to manually query the federated platform with a DBPath query instead of a normal query. The first reason was for a "cleaner" design while the second was for access versatility for the user of the system.
Once the SQLQueryParser receives the DistributedQuery containing the DBPath query, the object runs through several steps to break apart the query into end-database queries. The SQLQueryParser object first breaks apart the DBPath query by its SQL clauses. In the current implementation, the SELECT, FROM and WHERE clauses are separated. Once the clauses are separated, table names are extracted from each clause. If a DBPath for a table or column is malformed in a query, the class recognizes the syntax errors and prints the errors to the system console.
The table names from the FROM clause are first extracted since in proper SQL queries, all of the tables accessed by the query must be given in the FROM clause. All tables accessed by the query must be specified in the FROM clause or else the system produces an error and does not attempt to execute the query. The query form for the federated platform is the same. The SQLQueryParser produces an error and does not
process the DBPath query if it finds tables in other clauses that are not explicitly declared in the FROM clause.
Since the queries conform to this standard format, the list of tables that follow the FROM clause are first used to enumerate all of the tables to be accessed for the federated
query. For each table in the enumeration, the SQLQueryParser object instantiates a new SQL TableQuery object designated to handle the query that will return all of the required results from the table specified. That is, each constructed SQL TableQuery object
effectively stores a query that returns results that are all from one table-a table chosen from the enumeration. As each table in the enumeration is given a SQL TableQuery, the parser uses the DBPaths to correctly sort where each object goes. The parser object navigates through the DistributedQuery data structure to correctly insert the
SQL TableQuery object into its appropriate SQLMonoDBQuery. At the time of insertion, only the FROM clauses of the SQL TableQuery objects are set: the SELECT and WHERE clauses are next to be initialized.
The parsing of the SELECT clause immediately follows parsing the FROM clause. The tables are again enumerated and processed individually until all table
SELECT's are accounted for. During this process, the system checks to make sure that all tables accessed are declared in the FROM clause. As each SELECT column is processed, the SQLQueryParser object extracts the DBPath and table name of each column to search through the DistributedQuery data structure for the appropriate
SQL TableQuery object. The parser searches for the specific SQL TableQuery object that is designated to return all of the results from that one table. Once the SQL TableQuery object is found, the column is inserted into the SELECT clause of the object (with the DBPath prefix removed). This assures that no columns are missed for the aggregate query at the end of the platform's execution of the federated query.
Following the parsing of the SELECT clause comes the WHERE clause. The SQL vocabulary of the current implementation only allows multiple equality or
inequality conditions. Sub-queries and table aliases cannot be used as of yet. In addition, the order of evaluation goes from left-to-right instead of the SQL's normal AND-then-OR order [39].
The logic of the parser as to how to decompose the WHERE conditions can be simplified into three different rules. The action that the SQLQueryParser takes depends on the type of condition. The rules are as follows:
1) If the WHERE condition involves only one table, insert the condition into the WHERE clause of the SQL TableQuery object that handles the results of the column's table. Additionally, insert the specified column into the SELECT clause of the object. The inserted condition has its DBPath's stripped before it is
inserted. [Example:
condition HGDB->AccessObject.submitter = "Ben Fu" is stripped to AccessObject.name = "Ben Fu"
then inserted into the AccessObject SQL TableQuery object in its WHERE as AccessObject.name = "Ben Fu" and SELECT as AccessObject.submitter]
2) If the WHERE condition involves two different tables both in a single database, insert the condition into each WHERE clause of both SQL TableQuery objects that