Online active learning of decision trees with evidential data
Texte intégral
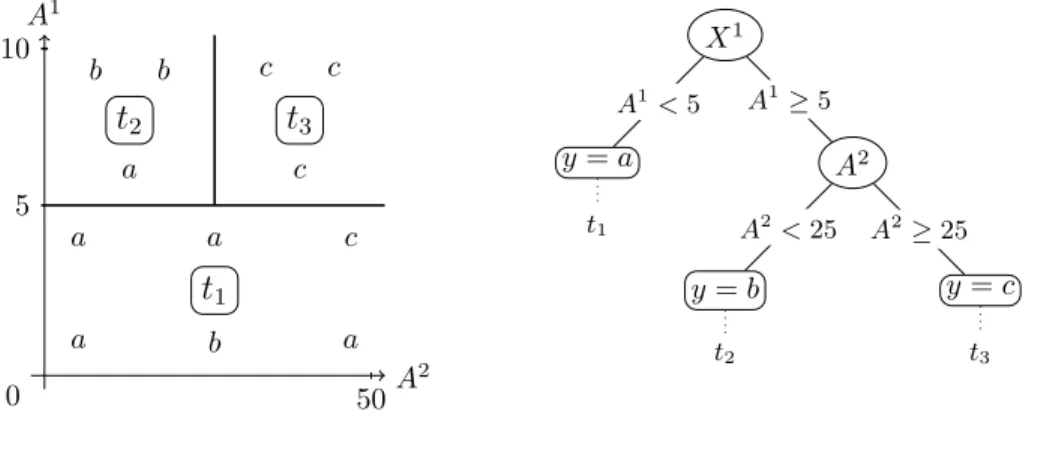
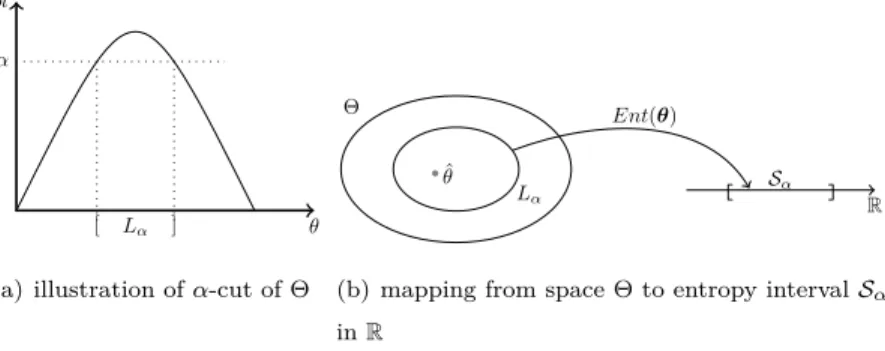
Figure

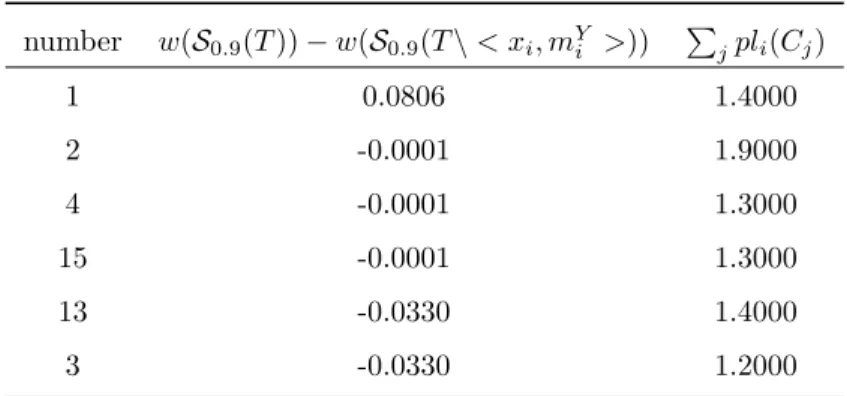
![Table 2: Intervals achieved under different values of α α=0.5 α=0.8 α=0.9 S α (T ) [1.2765, 1.5848] [1.4033 , 1.5831] [1.4522 , 1.5751] S α (T (A X = a)) [0.0000 , 0.7051] [0.0000 , 0.2864] [0.0000 , 0.1614] S α (T (A X = b)) [0.0000 , 1.4637] [0.0000 , 0.](https://thumb-eu.123doks.com/thumbv2/123doknet/14407795.511114/17.918.209.714.215.526/table-intervals-achieved-different-values-α-α-α.webp)


Documents relatifs
However, as the signal-to-background (in the sample of J/ψ candidates) is worse in the J/ψγγ sample, we use the same dimuon mass criteria for both J/ψπ − π + and J/ψγγ
Details of the design, fabrication, ground and flight calibration of the High Energy Trans- mission Grating, HETG, on the Chandra X-ray Observatory are presented after five years
Using this selection criterion (the subset criterion), the test chosen for the root of the decision tree uses the attribute and subset of its values that maximizes the
In the proposed method, the tree parameters are estimated through the maximization of an evidential likelihood function computed from belief functions, using the recently proposed E 2
The first one is the classical decision tree learning algorithm for which the gain function is now based on possibilistic cumulative entropy.. In the next subsection we show that
This article introduces a novel split method for de- cision tree generation algorithms aimed at improving the quality/readability ratio of generated decision trees.. We focus on
quality model will predict labels for each data instance, if the predicted label matches its original label, we believe this data instance is clean, and will pass it to
A large number of extensions of the decision tree algorithm have been proposed for overfitting avoidance, handling missing attributes, handling numerical attributes, etc..
