Time Series Forecasting: Obtaining Long Term Trends with Self-Organizing Maps
Texte intégral
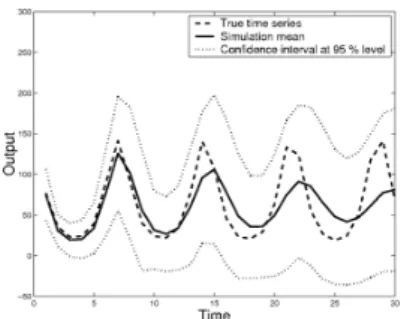
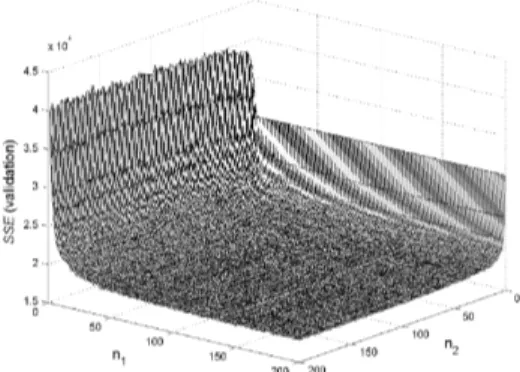
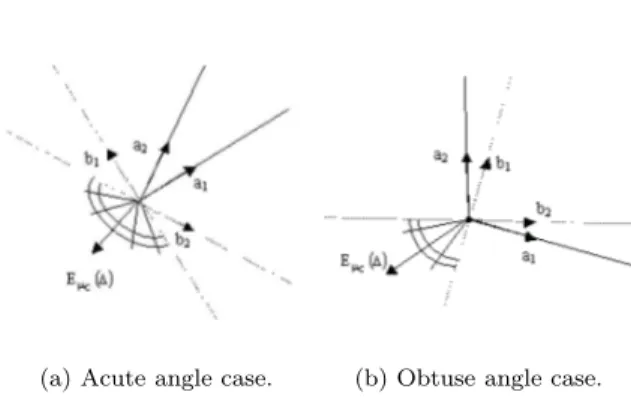
Figure



Documents relatifs
In the event other encodings are defined in the future, and the mail reader does not support the encoding used, it may either (a) display the ’encoded-word’ as ordinary text,
When the ETE processes the IPv4 first fragment (i.e, one with DF=1 and Offset=0 in the IPv4 header) of a SEAL protocol IPv4 packet with (R=1; SEG=0) in the SEAL header,
EBRs are ERs that configure VET interfaces over distinct sets of underlying interfaces belonging to the same enterprise; an EBR can connect to multiple enterprises, in which
After a little time, less than the ’end user to server’ Round-trip time (RTT), the real end user datagram will reach the ingress side of the ESP-based router, since the
This document is a guideline for registries and registrars on registering internationalized domain names (IDNs) based on (in alphabetical order) Bosnian, Bulgarian,
If an update is for a route injected into the Babel domain by the local node (e.g., the address of a local interface, the prefix of a directly attached network, or
The AR (DHCP client and relay agent) and the DHCP server use the IA_PD Prefix option to exchange information about prefixes in much the same way as IA
In response to the Control-Request message, the network element designated the Responder sends back a Control-Response message that reflects the Command-Header with an
