A coherent framework for learning spatiotemporal piecewise-geodesic trajectories from longitudinal manifold-valued data
Texte intégral
Figure





Documents relatifs
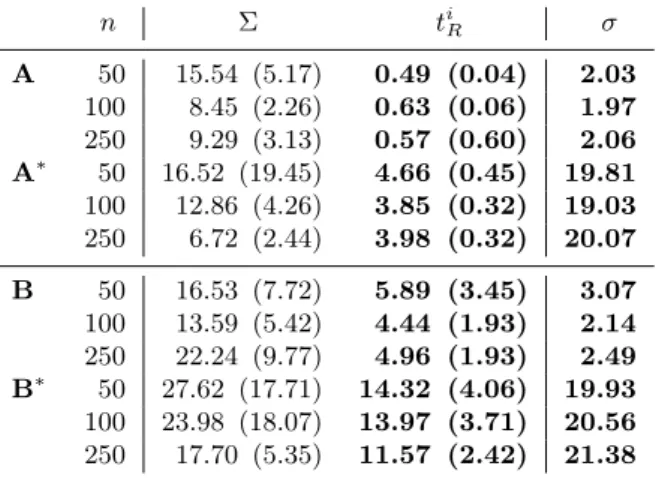
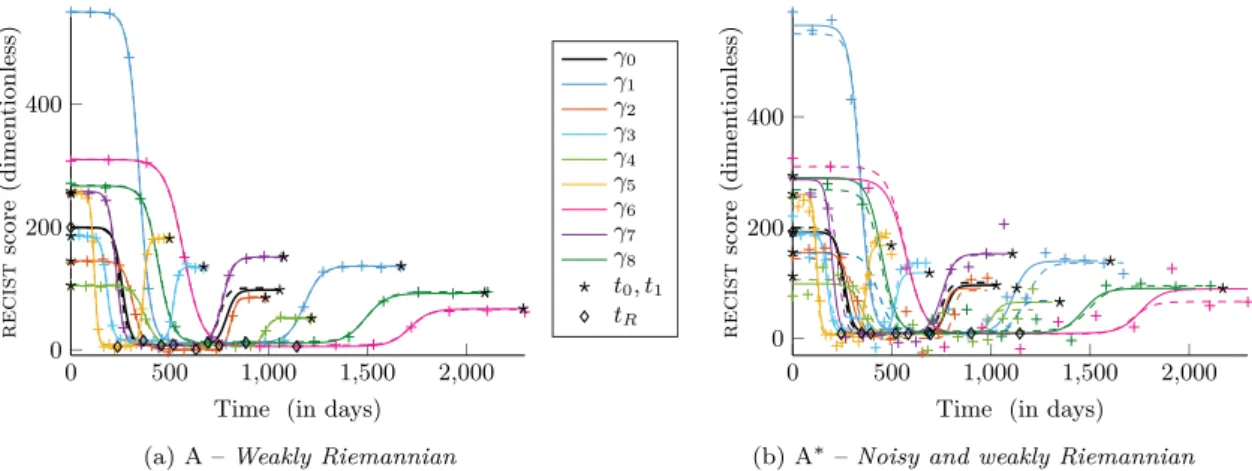
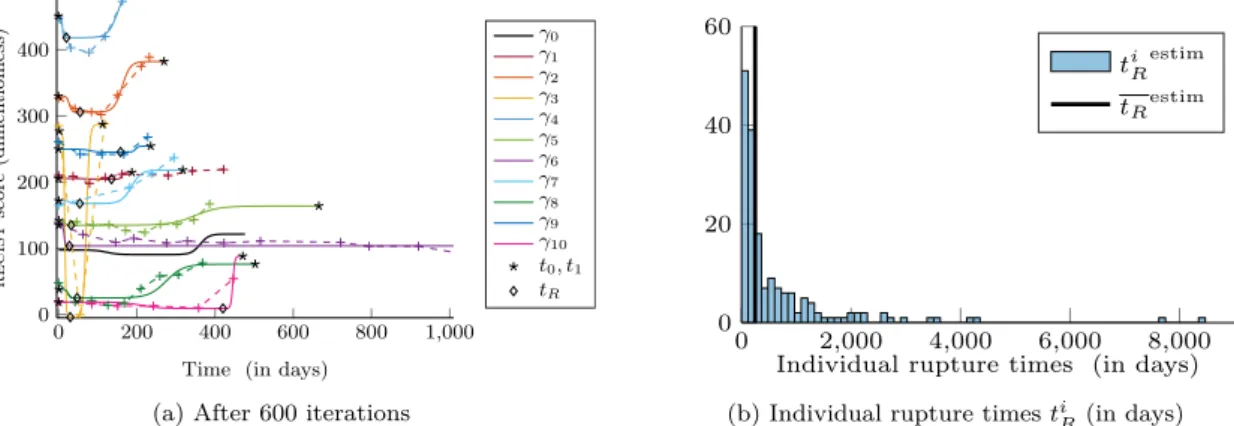
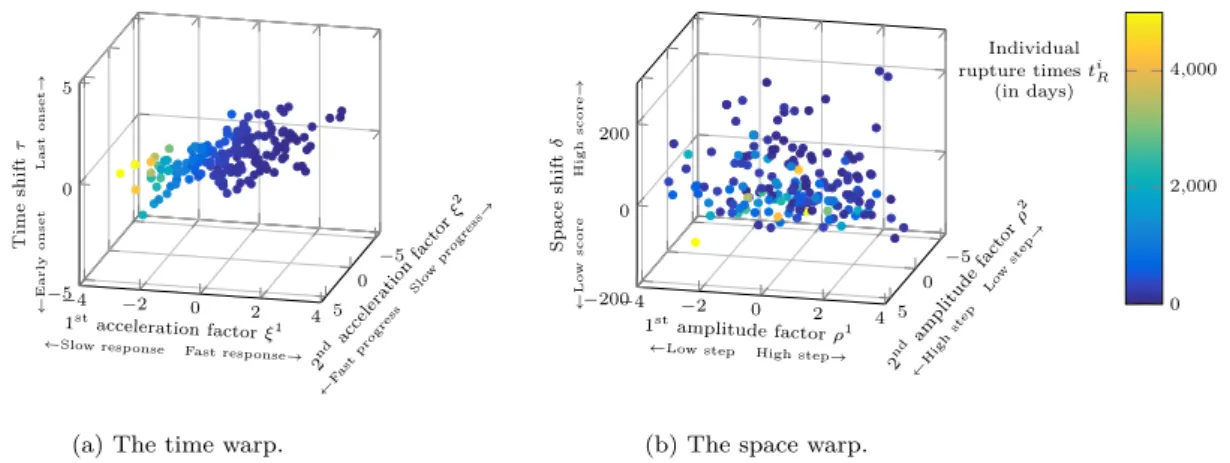
Due to the non-linearity of the model, we use the Stochastic Approximation Expectation- Maximization algorithm to estimate the model parameters.. Experiments on syn- thetic
De Vries makes a strong case for important structural changes in Europe during the ªrst half of the century, arguing persuasively for the existence, and importance, of crisis in
Numerically, due to the non-linearity of the proposed model, the estimation of the parameters is performed through a stochastic version of the EM algorithm, namely the Markov
34 Institute for Nuclear Research of the Russian Academy of Sciences (INR RAN), Moscow, Russia 35 Budker Institute of Nuclear Physics (SB RAS) and Novosibirsk State
9: (Colour online) Cross sections for the T0 and V0 processes measured in the first scan of the p–Pb (left) and Pb–p (right) sessions, as a function of the product of the intensities
The posterior distribution for three parameters in the case of a reconstruction considering uniform priors en dis- tances (except for 6dF data, see text): (left) the effective re-
To assess whether the human orthologues MCTS2, NAP1L5 and INPP5F_V2 are also associated with im- printed host genes, we analyzed the allelic expression of the host genes in a wide
Calculate P D from (2.π.Q.rps) and scale up for comparison with full-scale. Repeat for different values of ice thickness, strength, and ship speed. Tow force in overload tests in
