HAL Id: tel-00646236
https://tel.archives-ouvertes.fr/tel-00646236
Submitted on 29 Nov 2011
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires
Sopheap Seng
To cite this version:
Sopheap Seng. Vers une modélisation statistique multi-niveau du langage, application aux langues peu dotées. Informatique et langage [cs.CL]. Université de Grenoble, 2010. Français. �tel-00646236�
UNIVERSITÉ DE GRENOBLE
N◦ attribué par la bibliothèque
THÈSE
pour obtenir le grade de
Docteur de L’Université de Grenoble Spécialité : Informatique
préparée au Laboratoire Informatique de Grenoble dans le cadre de l’École Doctorale MSTII
présentée et soutenue publiquement par
Sopheap SENG
le 01/03/2010 Titre :
Vers une modélisation statistique multi-niveau du langage,
application aux langues peu dotées
Directeur de thèse : Laurent Besacier Co-directeur de thèse : Eric Castelli
Jury
M. Christian Boitet, Président du jury Mme Lori Lamel, Rapporteur du jury
M. Frédéric Béchet, Rapporteur du jury Mme Tanja Schultz, Membre du jury
M. Vincent Berment, Membre du jury Mme Brigitte Bigi, Membre du jury M. Laurent Besacier, Membre du jury M. Eric Castelli, Membre du jury
Remerciements
Je tiens tout d’abord à remercier Laurent Besacier et Eric Castelli pour avoir accepté d’encadrer cette thèse. Un grand remerciement à Laurent Besacier, qui m’a guidé tout au long de ces années de thèse, pour ses critiques, ses conseils sur mes travaux de recherche et pour avoir relu, corrigé et commenté ce manuscrit. Je voudrais remercier Brigitte Bigi pour son aide dévouée sur mes travaux de thèse, pour ses conseils très utiles et sa relecture de tout mon manuscrit.
J’adresse mes remerciements à Lori Lamel et Frédéric Béchet pour avoir ac-cepté d’être rapporteurs de ma thèse. Je voudrais remercier aussi Christian Boitet pour avoir accepté d’être le président du jury. Je remercie Tanja Schultz et Vincent Berment pour sa participation au jury de cette thèse.
Je tiens à remercier Pham Thi Ngoc Yen, la directrice du Centre MICA (Hanoi, Vietnam) pour m’avoir accueilli pour un stage de recherche à MICA.
J’adresse mes remerciements à Alex Waibel et Sebastian Stüker pour m’avoir accueilli dans le laboratoire Interactive Systems Labs (Université de Karlsruhe) et pour l’intérêt porté à mes travaux de recherche.
Je tiens à remercier également tous les membres de l’équipe GETALP pour leur accueil et leur sympathie. Un grand remerciement à mes amis à Grenoble avec qui j’ai partagé de grands moments au cours de ma thèse.
Enfin, je voudrais exprimer mes plus profonds remerciements à mes parents, à ma soeur, ma petite amie, pour leurs sentiments, leurs soutiens et leurs encoura-gements dans tout le temps où j’ai effectué cette thèse.
Résumé
Ce travail de thèse porte sur la reconnaissance automatique de la parole des langues peu dotées et ayant un système d’écriture sans séparation explicite entre les mots. La spécificité des langues traitées dans notre contexte d’étude nécessite la segmentation automatique en mots pour rendre la modélisation du langage n-gramme applicable. Alors que le manque de données textuelles a un impact sur la performance des modèles de langage, les erreurs introduites par la segmentation automatique peuvent rendre ces données encore moins exploitables. Pour tenter de pallier les problèmes, nos recherches sont axées principalement sur la modélisa-tion du langage, et en particulier sur le choix des unités lexicales et sous-lexicales, utilisées par les systèmes de reconnaissance. Nous expérimentons l’utilisation des multiples unités au niveau des modèles du langage et au niveau des sorties de systèmes de reconnaissance. Au niveau des modèles de langage, les modèles sont entraînés avec des vocabulaires hybrides créés en utilisant à la fois l’unité lexi-cale et l’unité sous-lexilexi-cale. Au niveau des sorties de systèmes, nous essayons de combiner les sorties de plusieurs systèmes de reconnaissance. Chaque système est fondé sur une unité de modélisation : lexicale ou sous-lexicale. Dans un objectif consistant à mieux exploiter les données textuelles en utilisant différentes vues sur données, nous proposons une méthode qui effectue des segmentations multiples sur le corpus d’apprentissage au lieu d’une segmentation unique classique. Cette mé-thode de segmentation multiple basée sur des automates d’état finis permet de générer toutes les segmentations possibles à partir d’une séquence de caractères et nous pouvons ensuite en extraire les n-grammes pour apprendre le modèle de
lidons ces approches de modélisation à base des multiples unités sur les systèmes de reconnaissance pour un groupe de langues peu dotées : le khmer, le vietnamien, le thaï et le laotien.
Mots-clés : reconnaissance automatique de la parole, langue peu dotée, mo-délisation statistique multi-niveau du langage.
Abstract
This PhD thesis focuses on the problems encountered when developing au-tomatic speech recognition for under-resourced languages with a writing system without explicit separation between words. The specificity of the languages co-vered in our work requires automatic segmentation of text corpus into words in order to make the n-gram language modeling applicable. While the lack of text data has an impact on the performance of language model, the errors introduced by automatic segmentation can make these data even less usable. To deal with these problems, our research focuses primarily on language modeling, and in par-ticular the choice of lexical and sub-lexical units, used by the recognition systems. We investigate the use of multiple units in speech recognition system. At language models level, the models are trained with hybrid vocabularies created using both the lexical and the sub-lexical unit. At the system output level, we try to combine the outputs of several recognition systems. Each system is based on a different modeling unit : lexical or sub-lexical. To better exploit the textual data using different views on the same data, we propose a method that performs multiple segmentations on the training corpus instead of a conventional single segmenta-tion. This method based on finite state machines allows generating all possible segmentations from a sequence of characters and then we can extract n-grams to train the language model. It allows finding the n-grams not found by unique seg-mentation method and adding new n-grams in the language model. We validate these modeling approaches based on multiple units in recognition systems for a group of languages : Khmer, Vietnamese, Thai and Laotian.
Table des matières
Introduction 1
1 Contexte d’étude et état de l’art 5
1.1 Contexte . . . 5
1.1.1 Motivations . . . 5
1.1.2 Projet en collaboration . . . 8
1.2 Reconnaissance automatique de la parole . . . 8
1.2.1 Historique . . . 8
1.2.2 Formulation statistique du problème de reconnaissance . . 9
1.2.3 Modélisation du langage . . . 10 1.2.4 Modélisation acoustique . . . 13 1.2.5 Dictionnaire de prononciation . . . 16 1.2.6 Décodage . . . 17 1.2.7 Evaluation . . . 17 1.3 Problématique de la thèse . . . 18
1.3.1 Reconnaissance automatique de la parole pour des langues peu dotées . . . 18
2 Reconnaissance automatique de la parole en langue khmère 27
2.1 Introduction . . . 27
2.2 Présentation de la langue khmère . . . 28
2.2.1 Le khmer, une langue peu dotée ? . . . 29
2.2.2 Traitement automatique de la langue khmère . . . 30
2.3 Recueil de ressources linguistiques . . . 32
2.3.1 Corpus de parole . . . 32
2.3.2 Vocabulaire . . . 33
2.3.3 Corpus de texte . . . 34
2.3.4 La segmentation automatique . . . 35
2.3.5 La segmentation automatique pour le khmer . . . 38
2.4 Modélisation de prononciation . . . 41
2.5 Modélisation acoustique . . . 44
2.6 Modélisation du langage . . . 45
2.7 Résultats d’expérimentation . . . 46
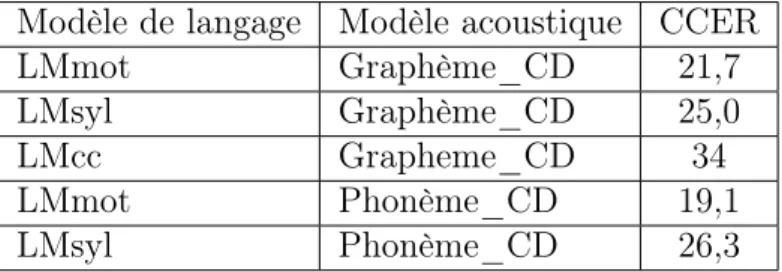
2.7.1 Modèle acoustique à base de Phonème Vs Graphème . . . 46
2.7.2 Modèles mot/sous-mot . . . 47
2.8 Conclusion . . . 47
3 Utilisation de multiples unités lexicales dans le système de RAP 49 3.1 Introduction . . . 49
3.2 Les unités utilisées dans la modélisation statistique du language . 50 3.2.1 Le mot : unité de base . . . 50
3.2.2 Sous-unités . . . 51
3.3 Modèle de langage hybride . . . 54
3.4 Combinaison de systèmes . . . 55
3.4.1 Combinaison par consensus : ROVER . . . 56
3.4.2 Combinaison des treillis . . . 58
3.5 Expérimentations . . . 62
3.5.1 Application à la langue khmère . . . 64
3.5.2 Application à la langue vietnamienne . . . 67
3.6 Conclusion . . . 70
4 Segmentation multiple pour la modélisation statistique du lan-gage 71 4.1 Introduction . . . 71
4.2 Segmentation multiple . . . 72
4.2.1 Motivations . . . 72
4.2.2 Estimer les trigrammes avec la segmentation multiple . . . 75
4.2.3 Génération des segmentations multiples par automates d’état fini . . . 77
4.2.4 Les travaux liés . . . 79
4.3 Expérimentations . . . 80
4.3.1 Application à la langue khmère . . . 81
4.3.2 Application à la langue vietnamienne . . . 82
4.3.3 Application à la langue laotienne . . . 83
4.3.4 Application à la langue thaïe . . . 85
4.3.5 Discussion . . . 86
Annexe 1 : Implémentation de segmentation multiple par automates
d’états finis 95
Table des figures
1.1 Architecture globale d’un Système de Reconnaissance . . . 10 2.1 Exemple d’une phrase en khmer. . . 28 2.2 Exemple de segmentation d’une phrase khmer en différentes unités 36 2.3 Taux des mots corrects pour les 3 méthodes de segmentation à base
de vocabulaire en fonction du taux de mots hors-vocabulaire . . . 39 2.4 Exemple de règle de segmentation en cluster de caractères . . . . 41 2.5 Les phonèmes khmers . . . 42 2.6 Règles pour les syllabes khmères . . . 43 2.7 Dictionnaire de prononciation en khmer à base de graphèmes . . . 44 3.1 Principe de combinaison via ROVER . . . 56 3.2 Combinaison des treillis de sous-unités et le réseau de confusion
obtenu . . . 59 3.3 Exemple de notre décomposition en treillis . . . 60 3.4 Exemple de décomposition en treillis de lattice-tool . . . 63 3.5 Performance de modèles hybrides CC + n Mots les plus fréquents
3.7 Performance de modèles hybrides : Syllabes + N Mots les plus fré-quents en Vietnamien . . . 68 3.8 Comparaison de performance de méthodes de combinaison . . . . 70 4.1 Exemple de segmentation multiple sur une phrase en khmer. . . . 75
Liste des tableaux
2.1 Tableau d’évaluation du niveau d’informatisation pour le khmer . . 30 2.2 Répartition du corpus d’apprentissage et corpus de test . . . 33 2.3 Taille de vocabulaire et de corpus d’apprentissage resegmenté. . . . 46 2.4 Modèle acoustique à base de Phonème Vs Graphème . . . 46 2.5 Performance des modèles mots/sous-mots . . . 47 3.1 Combinaison des N-meilleurs hypothèse par ROVER sur evalKh1
du khmer. . . 66 3.2 Combinaison des treillis. . . 67 3.3 Combinaison des N-meilleurs hypothèse par ROVER (vietnamien). 69 4.1 Comparaison de différentes technique de comptage des trigrammes. 74 4.2 Résultats de la segmentation multiple sur la langue khmère. . . 81 4.3 Impact du nombre de segmentations sur les différentes tailles de
corpus en khmer. . . 82 4.4 Résultats de la segmentation multiple sur la langue vietnamienne. 83 4.5 Impact du nombre de segmentations sur les différentes tailles de
corpus en vietnamien. . . 83 4.6 Résultats d’expérimentations sur la langue laotienne. . . 85
Introduction
La reconnaissance automatique de la parole consiste à extraire, à l’aide d’un ordinateur, l’information lexicale contenue dans un signal de parole. Les applica-tions de cette technologie sont nombreuses. Il existe des logiciels de dictée, des systèmes d’indexation automatique de documents audiovisuels ou des systèmes de dialogue. Les sorties du système de reconnaissance automatique de la parole peuvent également servir d’entrée à d’autres systèmes, par exemple pour la tra-duction dans le but construire un système de tratra-duction automatique de la parole. Parmi les 6000 langues parlées dans le monde, seul un tout petit nombre d’entre-elles possède les ressources nécessaires pour implémenter des technologies issues du traitement du langage naturel. Il s’agit des langues des pays dévelop-pés ou des langues qui présentent un intérêt stratégique ou politique, comme par exemple l’anglais, le français, l’allemand, le mandarin, le japonais, l’arabe. Depuis plus de deux décennies, des recherches intensives dans ce domaine ont été accom-plies par de nombreux laboratoires internationaux. Des progrès importants ont été accomplis grâce notamment aux efforts de collecte des données linguistiques nécessaires pour la modélisation statistique de la parole.
En reconnaissance automatique de la parole, il subsiste un certain nombre de verrous, notamment en ce qui concerne la généricité des méthodes utilisées et leur portabilité vers de nouvelles langues. Premièrement, les approches statistiques utilisées dans la modélisation de la parole nécessitent de très grands corpus de données pour construire des modèles performants. Pour les langues parlées dans les pays en voie de développement ou pour les langues qui ne suscitent pas
d’in-térêt économique ou politique, ces ressources sont généralement disponibles en quantité insuffisante pour le développement d’un tel système. Ces langues sont appelées des langues “peu dotées” dans plusieurs études, notamment dans la thèse de V. Berment intitulée “Méthodes pour informatiser des langues et des groupes de langues peu dotées” [Berment, 2004] et dans la thèse de V-B. Le intitulée “Re-connaissance Automatique de la parole des langues peu dotées” [Le, 2006], des travaux réalisés ces dernières années au LIG. Deuxièmement, les méthodes de mo-délisation qui ont été initialement étudiées pour les langues comme l’anglais ou le français ne sont pas directement applicables sur les autres langues qui possèdent des caractéristiques différentes. Par exemple, pour beaucoup de langues, déter-miner la frontière des mots dans le texte est une tâche particulièrement difficile comparativement à une langue comme l’anglais et la méthode de modélisation statistique du langage par n-grammes ne peut pas s’appliquer directement sur le corpus de texte comme dans le cas de l’anglais ou du français.
Ce travail de thèse porte sur la reconnaissance automatique de la parole des langues peu dotées et ayant un système d’écriture sans séparation explicite entre les mots. La spécificité des langues traitées dans notre contexte d’étude néces-site la segmentation automatique en mots pour rendre la modélisation du langage n-gramme applicable. Alors que le manque de données textuelles a un impact sur la performance des modèles de langage, les erreurs introduites par la segmen-tation automatique peuvent rendre ces données encore moins exploitables. Pour tenter de pallier les problèmes, à savoir des taux de mots inconnus élevés et des modèles de langage peu fiables conséquence du manque de données textuelles et des erreurs de segmentation automatique en mots, nos recherches sont axées principalement sur la modélisation du langage, et en particulier sur le choix des unités lexicales et sous-lexicales, utilisées par les systèmes de reconnaissance. Le problème de la faible quantité de données textuelles implique de réfléchir à des techniques de modélisation lexicale et sous-lexicale permettant ainsi de réduire la taille du vocabulaire de l’application, tout en essayant d’exploiter au mieux les données. Nous proposons de traiter ce problème en exploitant plusieurs vues sur les données textuelles dans la modélisation du langage. Nous expérimentons l’utilisation des multiples unités au niveau des modèles du langage et au niveau des sorties de systèmes de reconnaissance. Au niveau des modèles de langage, les
INTRODUCTION modèles sont entraînés avec des vocabulaires hybrides créés en utilisant à la fois l’unité lexicale et l’unité sous-lexicale. Au niveau des sorties de systèmes, nous essayons de combiner les sorties de plusieurs systèmes de reconnaissance. Chaque système est fondé sur une unité de modélisation : lexicale ou sous-lexicale. Nous cherchons à valider ces approches de modélisation à base des multiples unités sur les systèmes de reconnaissance pour un groupe de langues peu dotées : le khmer, le vietnamien, le thaï et le laotien.
D’un point de vue plus opérationnel, nous développons dans le cadre de ce travail de thèse, les systèmes de reconnaissance automatique de la parole pour deux langues peu dotées parlées en Asie du sud-est : le khmer et le laotien. Nous développons donc un système de reconnaissance automatique de la parole de l’état de l’art pour ces deux langues (broadcast news) à partir des ressources collectées. Ce travail permet ainsi de revisiter les méthodes et les outils de l’état de l’art proposées pour la collecte rapide de données et le développement rapide d’un système de reconnaissance pour une nouvelle langue peu dotée.
Ce mémoire se compose de 4 chapitres :
– dans le chapitre 1, après une brève présentation de la motivation et du contexte de ces travaux de thèse, nous présentons le principe général de la reconnaissance automatique de la parole par modèles statistiques et ci-tons les problèmes spécifiques aux langues peu dotées et ayant un système d’écriture sans séparation explicite entre les mots. L’accent est mis sur les problèmes posés par le manque de ressources numériques et les erreurs dues à la segmentation automatique en mots ;
– le chapitre 2 décrit les différentes étapes de développement d’un système de reconnaissance de la parole pour une langue peu dotée, le khmer, langue offi-cielle du Cambodge. Nous décrivons tout d’abord notre méthode de collecte de données linguistiques pour le développement rapide d’un nouveau sys-tème de reconnaissance pour une langue peu dotée. Le problème du manque de données textuelles et de la présence des erreurs lors de la segmentation en mots en fonction du taux des mots hors vocabulaire est abordé. Plusieurs unités de modélisations sont proposées dans la modélisation statistique du langage pour le khmer. Nous utilisons en plus de l’unité classique “mot”,
les sous-unités “syllabe” et “groupe de caractères” pour modéliser le khmer. Pour la modélisation acoustique, nous présentons et comparons des mé-thodes de génération automatique de dictionnaires de prononciation à base de graphèmes et à base de règles de conversion graphèmes-phonèmes pour le khmer. Enfin, des expérimentations sont menées pour tester et comparer les approches proposées ;
– dans le chapitre 3, nous souhaitons analyser comment les différentes unités lexicales et sous-lexicales peuvent être exploitées au mieux dans la reconnais-sance automatique de la parole des langues peu dotées et non-segmentées. Nous essayons de traiter le problème en exploitant plusieurs vues sur les données textuelles dans la modélisation. Nous travaillons au niveau du mo-dèle de langage en créant des momo-dèles à partir de vocabulaires hybrides qui utilisent à la fois des unités lexicales et sous-lexicales. Au niveau du système, nous proposons de combiner des sorties de différents systèmes fondés sur ces différentes unités pour décoder une meilleure hypothèse. Nous appliquons ces deux méthodes à la reconnaissance automatique de la parole de deux langues peu dotées, le vietnamien et le khmer.
– dans un objectif consistant à mieux exploiter les données textuelles en uti-lisant différentes vues sur les mêmes données, le chapitre 4 propose une mé-thode qui effectue des segmentations multiples sur le corpus d’apprentissage au lieu d’une segmentation unique classique. Cette méthode de segmenta-tion multiple basée sur des automates d’état finis permet de générer toutes les segmentations possibles à partir d’une séquence de caractères et nous pouvons ensuite en extraire les n-grammes pour apprendre le modèle de langage. Elle permet de retrouver les n-grammes non trouvés par la seg-mentation unique et d’ajouter de nouveaux n-grammes dans le modèle de langage. Ce dernier peut être vu comme une sorte de sur-génération des n-grammes à partir d’un corpus de texte. Cette approche par segmentation multiple est comparée avec la méthode classique de segmentation unique dans l’apprentissage des modèles de langage pour les systèmes de recon-naissance automatique de la parole en langue khmère, laotienne, thaïe et vietnamienne.
Chapitre
1
Contexte d’étude et état de l’art
1.1 Contexte
1.1.1 Motivations
Idéalement, informatiser une langue consiste à mettre à la disposition de l’uti-lisateur humain tous les moyens dont il a besoin dans sa langue, qu’elle soit écrite ou non : dialogue avec la machine, outils pour écrire ou lire un texte, reconais-sance automatique de la parole, synthèse vocale, traduction informatisée dans une autre langue, etc. L’absence des outils informatiques élémentaires dans la langue d’un pays rend l’accès aux informations difficile voir impossible et cela renforce la fracture numérique entre les pays. La fracture numérique peut être définie comme une inégalité face aux possibilités d’accéder et de contribuer à l’information, à la connaissance, ainsi que de bénéficier des capacités majeures de développement offertes par les nouvelles technologies de information et de la communication (NTIC).
Pour entrer dans le monde numérique d’aujourd’hui sans renier sa culture, une nation doit le faire en utilisant des logiciels dans sa propre langue. Les logiciels en langue étrangère exacerbent la fracture numérique, rendent les formations de base en informatique difficiles et coûteuses, appauvrit la culture, et bloque la plupart des traitements informatiques de base pour la gouvernance du pays.
Parmi les 6000 langues parlées dans le monde, seul un tout petit nombre d’entre-elles possède les ressources nécessaires pour implémenter des technolo-gies issues du traitement du langage naturel. Pour ces langues dites bien dotées, un certain nombre de ressources est disponible en grande quantité, à savoir : une orthographe stable dans un système d’écriture donné, des ouvrages de référence (grammaires, dictionnaires), des œuvres de diffusion massive (presse écrite et au-diovisuelle, films, chansons et musique), des ouvrages techniques et d’apprentis-sage (publications techniques et scientifiques, ouvrages didactiques) et un nombre abondant d’applications informatiques dans cette langue. D’un autre côté, un très grand nombre de langues dites peu dotées, parlées généralement dans les pays en voie de développement, ne dispose pas suffisamment, voire pas du tout, des res-sources dont sont généralement dotées les grandes langues. Une langue peut être majoritaire, écrite, enseignée à l’école, mais manquer cruellement de ressources informatiques ou même de ressources linguistiques en quantité et en qualité suf-fisantes. Les langues dites peu dotées peuvent être en effet des langues en grand danger de disparition ou bien des langues émergentes qui possèdent déjà une bonne partie de ces ressources mais en nombre estimé insuffisant et incomplet.
D’une manière générale, pour les langues peu dotées, les technologies vocales ne sont peut-être pas la première lacune à combler, les outils de traitement infor-matique de bases comme la saisie, l’affichage, l’impression et le tri lexicographique sont des applications plus critiques et plus demandées. Mais la recherche et le dé-veloppement sur ce thème, génère des outils et des corpus qui peuvent servir à d’autres tâches et d’autres applications. L’intérêt des technologies vocales est mis en évidence dans le contexte du projet Spoken-Web [Kumar et al., 2007] initié par IBM Research qui vise à imiter le Web en proposant l’accès aux informations vocales aux habitants dans les villages en Inde via le téléphone. Le Web est une révolution et représente une source d’informations très importante mais seulement 17% de la population mondiale bénéficie d’un accès à ces ressources1. Il y
plu-sieurs raisons qui empêchent les autres 83% de la population de bénéficier de cette nouvelle technologie. Une première cause est le coût très élevé des ordinateurs par rapport au niveau de vie local et le manque d’infrastructure : l’électricité, le ré-seaux Internet. Deuxièmement, une grande partie de la population mondiale est
1.1. CONTEXTE
encore illettrée et ne sait pas utiliser un ordinateur. Troisièmement, les contenus disponibles sur le Web sont généralement dans une langue étrangère dominante comme l’anglais et ne sont pas adaptés aux besoins quotidiens de ce groupe de population. En revanche, le développement du réseau téléphonique n’a pas ren-contré le même handicap que le réseau Internet. Le coût du téléphone, les frais de communication et la complexité d’utilisation sont plus faibles que ceux de l’Internet, ce qui fait que le taux de pénétration du téléphone portable est très élevé dans beaucoup de pays. La vision du projet Spoken-Web est de créer un réseau similaire au Web mais avec des sites vocaux accessibles par le téléphone en utilisant la voix humaine comme vecteur de communication. La mise en place de ce concept a besoin intensivement de technologies vocales très avancées, en particulier la reconnaissance automatique de la parole.
Ce travail de thèse s’inscrit dans les efforts d’informatisation de la langue khmère, langue officielle du Cambodge. Classée comme une langue peu dotée [Berment, 2004], la disponibilité des ressources et des outils de traitement auto-matique de base pour la langue khmère reste encore très limitée. Pendant que les outils informatiques de base comme le traitement de texte, la saisie simple, l’affichage et l’impression du texte en unicode viennent d’être mis en service par les organisations comme KhmerOS2 et PAN Localization3, les outils plus
avan-cés comme le traitement de l’oral, la reconnaissance vocale, la synthèse vocale ne sont pas encore disponibles. Ainsi, dans une perspective de développement in-formatique plus avancé, la qualité d’un outil inin-formatique doit tenir compte de nouveaux critères qui définissent son utilisabilité : interaction entre la machine et l’homme, facilité et rapidité d’apprentissage. La maîtrise des technologies vocales est nécessaire pour développer des technologies de communication et les télé-communications : la parole reste le premier médium de communication entre les hommes et de ce fait est le signal d’information le plus communément transmis. Une bonne maîtrise des technologies vocales dans la langue du pays est indis-pensable pour mettre en place des moyens de télécommunications performants et adaptés au pays et à ses ressortissants.
2. www.khmeros.info
1.1.2 Projet en collaboration
L’Institut de Technologie du Cambodge (ITC) est une école d’ingénieurs de haut niveau qui forme les cadres techniques nécessaires au développement du pays. Dans sa stratégie de développement, l’ITC souhaite initier des activités de recherche, et dès que les conditions le permettront, ouvrir un troisième cycle destiné à la formation par la recherche des spécialistes dans le domaine des sciences de l’ingénieur. Le Département Génie Informatique et Communication a été créé en 1999. La première promotion d’ingénieurs est sortie en 2002. De gros efforts ont été faits pour former un personnel enseignant qualifié : chaque année les meilleurs étudiants de dernière année bénéficient de bourses d’études en Europe pour ensuite devenir enseignants dans le département. Des bourses de Master et de thèse sont attribuées aux jeunes enseignants pour se perfectionner et s’initier à la recherche. Ce travail de thèse s’incrit dans cette stratégie de développement du Départe-ment Génie Informatique et Communication de l’ITC. Grâce à une collaboration avec le laboratoire LIG/GETALP (Grenoble, France) et le centre MICA (Hanoï, Vietnam), le projet de recherche TALK "Traitement Automatique de la Langue Khmère" a démarré en 2004 soutenu par l’AUF (Agence Universitaire pour la Francophonie). L’objectif du projet TALK était de mettre en place au sein du Département Génie Informatique et Communication, un groupe de recherche spé-cialisé dans le domaine du traitement automatique de la parole en langue khmère, pour assurer le transfert des technologies et pour concevoir des applications d’in-teraction et de communication parlée.
1.2 Reconnaissance automatique de la parole
1.2.1 Historique
La reconnaissance automatique de la parole (RAP) consiste à extraire, à l’aide d’un ordinateur, l’information lexicale contenue dans un signal de parole. Depuis plus de trois décennies, des recherches intensives dans ce domaine ont été accom-plies par de nombreux laboratoires internationaux. Des progrès importants ont
1.2. RECONNAISSANCE AUTOMATIQUE DE LA PAROLE
été réalisés grâce au développement d’algorithmes puissants et grâce aux avancées en traitement du signal.
Les fondements de la technologie récente en reconnaissance de la parole ont été élaborés par F. Jelinek et son équipe à IBM dans les années 70 [Jelinek, 1970]. Les premiers travaux (années 80) se sont intéressés aux mots, et ce, pour des applica-tions à vocabulaire réduit. Au début des années 90, les systèmes de reconnaissance automatique de la parole continue gande vocabulaire et indépendants du locuteur ont vu le jour. La technologie s’est développée rapidement et déjà vers le milieu des années 90, une précision raisonnable est atteinte pour une tâche de dictée vo-cale . Une partie de ce développement a été réalisée dans le cadre de programmes d’évaluation de la DARPA (Defense Advanced Research Projects Agency).
Différents systèmes de reconnaissance de la parole ont été développés, cou-vrant des domaines variés : reconnaissance de quelques mots clés sur lignes télé-phoniques, systèmes de dictée vocale, systèmes de commande et contrôle sur PC, systèmes de compréhension en langage naturel.
1.2.2 Formulation statistique du problème de reconnaissance
Les premiers travaux de reconnaissance de la parole ont essayé d’appliquer des connaissances expertes en production et en perception. De nos jours, les techniques de modélisation statistique apportent les meilleures performances.
La formulation statistique du problème de reconnaissance suppose que la parole est représentée par une séquence de vecteurs acoustiques O = o1...oT et que cette
séquence encode la suite de mots : M = m1...mK.
La transcription orthographique de la parole se ramène alors à un problème de décodage où on cherche à trouver la séquence de mots M� tel que :
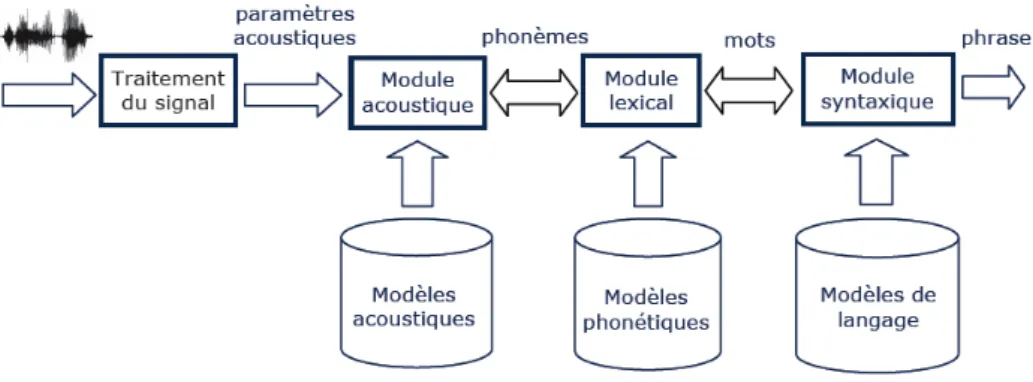
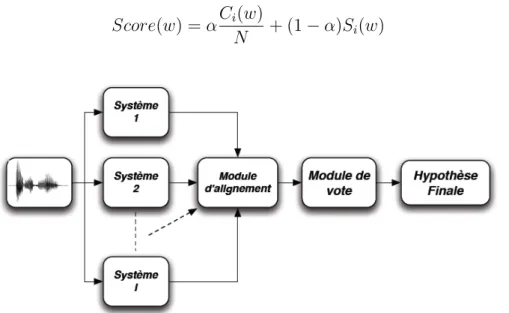
M� = argmaxP (M|O) = argmaxP (O|M)P (M) (1.1) P (O/M )est déterminée par un modèle acoustique et P (M) par un modèle de langage. L’architecture globale d’un Système de Reconnaissance Automatique de la Parole peut être représentée comme dans le figure 1.1.
Figure 1.1 – Architecture globale d’un Système de Reconnaissance
1.2.3 Modélisation du langage
Pour la reconnaissance de la parole continue, la seule information acoustique ne suffit pas pour transcrire correctement les suites de mots. Les modèles de lan-gage représentent une composante majeure du système de reconnaissance auto-matique de la parole. Ils introduisent les contraintes linguistiques dans le système. Le modèle de langage modélise les contraintes liées à une langue, afin d’estimer la probabilité d’une suite de mots :
P (W1k) = P (w1) k
�
i=2
P (wi|hi) (1.2)
où hi correspond à l’historique du mot wi.
De nombreux systèmes de seconnaissance automatique de la parole utilisent des modèles de langage n-grammes. Les modèles n-grammes correspondent à une modélisation stochastique du langage où l’historique d’un mot est représentée par les n − 1 mots qui le précèdent :
P (W1k) = P (w1) n−1 � i=2 P (wi|w1, ..., wi−1) k � i=n P (wi|wi−n+1, ..., wi−1) (1.3)
Les modèles de langage n-grammes sont assez souples car ils permettent de modéliser des phrases grammaticalement incorrectes mais ils n’interdisent pas
1.2. RECONNAISSANCE AUTOMATIQUE DE LA PAROLE
non plus de produire des phrases totalement incohérentes. Les modèles les plus couramment utilisés en RAP sont les modèles d’ordre 3 à 5. Dans le cas d’un modèle tri-gramme, l’équation précédente s’écrit :
P (W1k) = P (w1)P (w2|w1) k
�
i=3
P (wi|wi−2, ..., wi−1) (1.4)
Estimation des modèles de langage
L’estimation des paramètres d’un modèle de langage n-grammes s’effectue en deux opérations : une opération de décompte et une opération de redistribution des probabilités. La méthode d’estimation effectue un décompte des suites de mots observés afin d’en extraire une probabilité d’apparition. Le principe est d’estimer toutes probabilités issues d’événements observés, puis de les redistribuer à des événements non vus. Cette seconde étape, qui correspond au lissage, permet d’as-socier une probabilité non nulle à des événements jamais observés sur le corpus d’apprentissage. Les méthodes de lissage classiques calculent une probabilité non nulle en réduisant la fenêtre d’observation.
Les modèles n-grammes sont donc très dépendants du corpus d’apprentissage, et ont un champ de vision limité à la taille du n-gramme (qui est comprise entre 3 et 5 généralement). Même pour les langues bien dotées, les quantités disponibles de textes pour estimer les probabilités des n-grammes ne sont pas suffisantes pour les n-grammes d’ordre plus élevé. De nombreuses techniques de lissage ont été proposées pour pallier ce problème. Le lissage consiste à prendre une partie de la masse de probabilité des n-grammes observés, pour donner une valeur non-nulle aux probabilités des n-grammes non-observés ou peu observés. L’une des tech-niques de lissage les plus utilisées est la technique dite de Kneser-Ney [Kneser et Ney, 1995]. Avec cette technique, les probabilités des n-grammes peu observés sont estimées comme avec les autres techniques de lissage, en faisant un replie-ment (backoff) sur un historique d’ordre moins grand. Pour un trigramme par exemple, le bigramme puis l’unigramme si nécessaire sont utilisés. L’originalité de la technique Kneser-Ney modifiée est de ne pas prendre la même distribution de probabilités pour les ordres plus petits que n. Au lieu de prendre la fréquence de
l’historique d’ordre n − 1 à savoir hi−1
i−n+1, c’est le nombre de contextes différents
dans lesquels se produit hi−1
i−n+1 qui est consulté. L’idée est que si ce nombre est
faible alors la probabilité accordée au modèle d’ordre (n − 1) doit être petite et ce, même si hi−1
i−n+1 est fréquent. Ainsi le biais potentiel introduit par la fréquence
de l’historique est évité.
Les modèles n-grammes sont extrêmement simples, mais ont prouvé leur effi-cacité et leur souplesse. Ils se sont imposés dans les systèmes état de l’art bien que diverses alternatives efficaces aient été proposées dans la littérature [Schwenk et Gauvain, 2002] et [Schwenk, 2007], ils continuent d’être quasi systématiquement intégrés aux systèmes de RAP état de l’art.
En pratique, pour construire les modèles de langage, nous avons utilisé la li-brairie SRILM [Stolcke, 2002]. Il existe cependant d’autres boîtes à outils, comme par exemple CMU SLM, pour Carnegie Mellon Statistical Language Modeling-Toolkit.
Évaluation des modèles de langage
La qualité d’un modèle de langage dépend de sa capacité à influencer le système de reconnaissance automatique de la parole afin d’en augmenter la performance. Une question primordiale est de savoir comment deux modèles de langage peuvent être comparés en termes de performances dans un système de reconnaissance. La façon correcte de procéder consiste à incorporer chaque modèle dans un système complet et d’évaluer quelle est la meilleure transcription en sortie du système. Cette méthode permet d’évaluer concrètement la performance d’un modèle de langage mais nécessite de disposer d’un système complet.
La mesure la plus couramment utilisée consiste à estimer la perplexité de cha-cun des modèles. La perplexité d’un modèle de langage correspond à sa capacité de prédiction. Plus la valeur de perplexité est petite, plus le modèle de langage possède des capacités de prédiction. La perplexité s’estime sur le corpus d’appren-tissage pour définir si les modèles choisis modélisent correctement le corpus. Elle est calculée sur un corpus de test ou de développement, pour estimer le degré de généralisation du modèle. Cependant, bien que la perplexité permette d’estimer
1.2. RECONNAISSANCE AUTOMATIQUE DE LA PAROLE
la capacité de représentation d’un modèle de langage, elle n’est pas systémati-quement corrélée avec la qualité du décodage. Pour des modèles n-grammes, la perplexité se définit ainsi :
P P = 2−N1
Pn
t=1log2P (wt|h) (1.5)
où P (wt|h) est la probabilité associée au n-gramme (wt|h).
Deux remarques importantes sont à prendre en considération lorsque l’on com-pare des modèles de langage :
– une réduction de perplexité n’implique pas toujours un gain de performances d’un système de reconnaissance,
– en général, la perplexité de deux modèles n’est comparable que s’ils utilisent le même vocabulaire. Sinon, il faut utiliser une perplexité normalisée qui simule un nombre de mots identique.
Bien que des modèles de langage avec des mesures de perplexité qui diminuent tendent à améliorer les performances d’un système de reconnaissance, il existe dans la littérature des études qui reportent des diminutions importantes de perplexité n’ayant peu ou pas apporté de gain de performance [S.C. Martin et Ney, 1997] et [R. Iyer et Meteer., 1997].
1.2.4 Modélisation acoustique
Vecteurs acoustiques
Le signal de parole ne peut être exploité directement. En effet, le signal contient de nombreux autres éléments que le message linguistique : des informations liées au locuteur, aux conditions d’enregistrement, etc. Toutes ces informations ne sont pas nécessaires lors du décodage de parole et rajoutent même du bruit. De plus, la variabilité et la redondance du signal de la parole le rendent difficilement ex-ploitable tel quel. Il est donc nécessaire d’en extraire uniquement les paramètres qui seront dépendants du message linguistique.
Généralement, ces paramètres sont estimés via des fenêtres glissantes sur le signal. Cette analyse par fenêtrage permet d’estimer le signal sur une portion
ju-gée stationnaire : généralement 10 à 30 ms en limitant les effets de bord et les discontinuités du signal via une fenêtre de Hamming. La majorité des paramètres représentent le spectre fréquentiel et son évolution sur une fenêtre de taille donnée. Les techniques de paramétrisation les plus utilisées sont : PLP (Perceptual Linear Prediction : domaine spectral) [Hermansky et Cox, 1991], LPCC (Linear Predic-tion Cepstral Coefficients : domaine temporel) [Markel et JR., 1976] et MFCC (Mel Frequency Cepstral Coefficients : domaine cepstral) .
Modèles de Markov Cachés (MMC)
Le signal acoustique de parole est modélisable par un ensemble réduit d’uni-tés acoustiques, qui peuvent être considérées comme des sons élémentaires de la langue.
Classiquement, l’unité choisie est le phonème : un mot étant formé par la conca-ténation de phonèmes. Des unités plus précises peuvent être employées comme les syllabes, les di-syllabes, les phonèmes en contexte, permettant ainsi de rendre la modélisation plus fine, mais cette amélioration théorique est limitée dans la pratique par la complexité induite et les problèmes d’estimation. Un compromis souvent employé est l’utilisation de phonèmes contextuels avec partage d’états. Le signal de parole peut être assimilé à une succession d’unités. Dans le cadre des systèmes de RAP Markoviens, les unités acoustiques sont modélisées par des Modèles de Markov Cachés (MMC), typiquement des MMC gauche-droite à trois états.
A chaque état du modèle de Markov est associée une distribution de probabi-lité modélisant la génération des vecteurs acoustiques via cet état. Un MMC est caractérisé par plusieurs paramètres :
– son nombre d’états N,
– l’ensemble des états du modèle e = (ei)(1≤i≤N),
– une matrice de transition entre les états : A = (aij)(1≤i,j≤N) de taille N × N,
– la probabilité d’occupation d’un état à l’instant initial : (πi)(1≤i≤N) : πi =
P (e1 = ei),
1.2. RECONNAISSANCE AUTOMATIQUE DE LA PAROLE
Un MMC est donc représenté par un ensemble de paramètres :
M M C = (N, A,{π}, {b}) (1.6)
Les paramètres du MMC sont estimés empiriquement sur de grands corpus de parole annotés.
Apprentissage des modèles
Les paramètres des MMC qui comprennent les probabilités de transition entre états, les moyennes, les variances et les poids des mélanges de gaussiennes, sont es-timés sur des alignements de transcriptions de données audio d’apprentissage. Au cours de l’opération appelée alignement, le signal audio est découpé en tronçons, associés chacun à une seule unité acoustique (phone par exemple).
Pour réaliser les premiers alignements, plusieurs techniques sont utilisées, soit des techniques de flat start, soit des techniques de bootstrap (amorçage) qui uti-lisent des modèles pré-existants d’une ou plusieurs autres langues.
Approches flat start
L’approche communément appelée flat start, est la technique la plus simple pour initialiser les paramètres des MMC. Elle consiste à mettre à zéro les proba-bilités de transition que l’on veut interdire, par exemple les transitions d’un état vers un état antérieur (modèles gauche-droite). Toutes les autres probabilités de transition entre états sont considérées comme équiprobables. Pour les probabilités d’observation, les moyennes et les variances des gaussiennes sont toutes initiali-sées aux mêmes valeurs, à savoir la moyenne et la variance estimées sur toutes les données d’apprentissage.
Approches bootstrap
Deux approches principales dites de bootstrap (amorçage) existent pour ini-tialiser les modèles acoustiques [Schultz et Waibel, 2001]. La première approche consiste à choisir des modèles acoustiques de systèmes de reconnaissance exis-tants pour segmenter les données transcrites manuellement dans la langue cible. Cette méthode est fréquemment utilisée mais est rarement explicitement
men-tionnée dans la littérature. La deuxième approche consiste à prendre un jeu de modèles acoustiques multilingues génériques qui couvrent un grand nombre de phonèmes [Schultz, 2002]. Cette dernière technique peut être utile pour réaliser un système pour une langue avec très peu de données, typiquement moins de 10h de transcriptions audio. Chaque segment de parole est aligné soit de ma-nière itérative avec l’algorithme de Baum-Welch [Baum et al., 1970], qui prend en compte tous les chemins qui passent par un état, soit uniquement avec la meilleure séquence d’états possible (alignement de type Viterbi). Après l’alignement, les paramètres des MMC sont estimés à l’aide d’une procédure EM (Expectation/-Maximization) en partant d’une seule gaussienne par état, qui est divisée jusqu’à obtenir le nombre maximal de gaussiennes voulu, pris typiquement entre 8 et 128 gaussiennes [JL. Gauvain et Adda, 2002]. Cette technique d’amorçage a été utili-sée avec succès dans [Le, 2006] pour le développement d’un système de RAP pour la langue vietnamienne.
1.2.5 Dictionnaire de prononciation
Le dictionnaire de prononciation fournit le lien entre les séquences des unités acoustiques et les mots représentés dans le modèle de langage. Alors que les corpus de texte et de parole peuvent être collectés, le dictionnaire de prononciation n’est généralement pas directement disponible. Bien qu’un dictionnaire de prononcia-tion créé manuellement donne une bonne performance, la tâche est très lourde à réaliser et demande des connaissances approfondies sur la langue en question. La littérature propose des approches qui permettent de générer automatiquement le dictionnaire de prononciation. L’approche, simple et totalement automatique, qui utilise des graphèmes comme unités de modélisation a été validée dans [Billa et al, 2002] et [Bisani et Ney, 2003].
Une autre approche de génération automatique de dictionnaire de prononcia-tion consiste à utiliser des règles de conversion graphème-phonème. Cette construc-tion nécessite une bonne connaissance de la langue et de ses règles de phonéti-sation, qui par ailleurs ne doivent pas contenir trop d’exceptions. Cependant, ce type d’approche est assez coûteux en temps (écriture d’un analyseur phonétique), mais donnera des dictionnaires de prononciation de qualité très correcte pouvant
1.2. RECONNAISSANCE AUTOMATIQUE DE LA PAROLE
ensuite être révisés manuellement relativement rapidement. Il existe également certaines approches utilisant un système de reconnaissance phonémique appliqué sur des enregistrements des mots à phonétiser, permettant un premier étiquetage automatique en phonèmes d’une liste de mots, qui peut être alors révisé par un opérateur humain.
Il est important de noter que les performances du système de reconnaissance sont directement liées au taux de mots hors vocabulaire. La taille et la qualité (couverture) de dictionnaire joue ainsi un rôle très important dans les système de reconnaissance de la parole.
1.2.6 Décodage
L’objectif du décodage est de trouver la séquence de mots la plus probable sachant le dictionnaire et les modèles acoustiques et de langage. En pratique, il s’agit de trouver la suite d’états la plus probable dans un treillis de mots (espace de recherche) où chaque nœud représente un état de phone donné à un temps t. Pour ce faire, deux algorithmes sont fréquemment utilisés : l’algorithme de Viterbi et l’algorithme A∗ qui est asynchrone.
Vue la taille de l’espace de recherche, la détermination du meilleur chemin peut devenir compliquée. Une approche multi-passes peut être utilisée pour réduire la complexité du décodage. Par exemple, pour la première passe on peut utiliser un bigramme et des modèles acoustiques simples et dans la seconde un trigramme et des modèles acoustiques plus fins. L’information entre les passes est transmise via un treillis de mots ou les N meilleures hypothèses. Le treillis est un graphe où les nœuds correspondent à des instants et les arcs correspondent aux hypothèses de mots. Les N meilleures hypothèses correspondent à une liste des meilleures séquences de mots et de leurs scores respectifs.
1.2.7 Evaluation
Les systèmes de reconnaissance de la parole sont évalués en termes de taux de mots erronés (ou WER pour Word Error Rate).
W ER = S + D + I
N × 100 (1.7)
où S correspond aux substitutions, D aux suppressions (ou élisons), I aux insertions et N est le nombre de termes dans la référence.
Ce taux est calculé après alignement dynamique de l’hypothèse du décodeur avec une transcription de référence, à l’aide d’un calcul de distance d’édition mini-male entre mots. Le résultat sera le nombre minimal d’insertions, de substitutions et d’élisions de mots, pour pouvoir faire correspondre les séquences de mots de l’hypothèse et de la référence. D’après sa définition, le WER peut être supérieur à 100% à cause des insertions.
La boîte à outils SCTK4 (Scoring Toolkit) du National Institute of Standards and Technologies (NIST) fournit le programme sclite pour aligner les hypothèses et les références, calculer les WER et faire des analyses fines des erreurs. Cet outil peut fournir des informations très utiles comme les mots les plus substitués, insérés ou élidés ; des taux d’erreurs par locuteur peuvent être également obtenus (si les segments possèdent une étiquette de locuteur).
1.3 Problématique de la thèse
1.3.1 Reconnaissance automatique de la parole pour des
langues peu dotées
En laissant de côté les problèmes liés aux critères qui définissent une langue et en particulier la délicate distinction entre langue et dialecte, le nombre de langues dans le monde est en général estimé à 6000 [Amorrortu et al., 2004]. La distribution géographique des langues est très inégale selon les continents. Pour un total estimé à 6000 langues, presque deux tiers proviennent des continents africains et asiatiques (un tiers pour chaque continent), alors que seulement 3% sont des langues européennes. Enfin, les langues des continents américains et de la zone pacifique représentent respectivement 15% et 18% des langues du monde [Grimes, 2000]. Selon [Crystal, 2000], 82% des langues du monde ont moins de
1.3. PROBLÉMATIQUE DE LA THÈSE
100,000 locuteurs, et 56% moins de 10,000 locuteurs. Un faible nombre de locuteurs n’est pas le facteur unique déterminant le rayonnement d’une langue, néanmoins ces pourcentages montrent qu’une majorité de langues risque de disparaître au profit d’autres langues dominantes [Hagège, 2002]. Pour des institutions comme l’UNESCO, le développement de ressources et d’outils numériques pour de telles langues est une étape nécessaire pour tenter de préserver une diversité linguistique menacée.
Les technologies de reconnaissance automatique de la parole sont réservées, pour l’instant, à un très petit nombre de langues. Il s’agit des langues des pays dits développés, ou de langues qui suscitent un intérêt économique ou politique. Les langues minoritaires ou les langues venant de pays en voie de développe-ment sont moins abordées par la communauté du traitedéveloppe-ment automatique de la langue naturelle. Mais au cours des dernières années, les langues minoritaires et les langues peu dotées ont attiré une attention croissante dans la communauté du traitement automatique de la langue naturelle. Des projets qui visent à la revita-lisation, la standardisation et à la normalisation linguistique ont été lancés pour favoriser l’usage de ces langues et pour contribuer à leur survie. L’augmentation du nombre de pages sur l’Internet en langues minoritaires en est une illustration. Le développement d’un système de reconnaissance automatique de la parole continue à grand vocabulaire dans une nouvelle langue nécessite de rassembler une grande quantité de corpus de parole, contenant des signaux de parole pour l’apprentissage des modèles acoustiques du système. De tels corpus et systèmes sont désormais disponibles pour la plupart des langues occidentales comme l’an-glais, le français, l’espagnol, et pour quelques langues asiatiques comme le chinois, le japonais, le coréen ainsi que pour l’arabe. Pour beaucoup d’autres langues, ces ressources ne sont pas encore disponibles ou elles sont disponibles en quantité très limitée. De nombreux termes plus ou moins équivalents existent dans la littéra-ture pour désigner les langues, qui sont pour certaines, parlées par des millions de personnes, mais qui ne disposent pas d’une activité et de ressources numériques importantes. Une qualification semble être plus utilisée, il s’agit de l’expression langues peu dotées en français, et under-resourced languages en anglais. L’infor-matisation des langues peu dotées a été étudiée dans la thèse de V. Berment
intitulée “Méthodes pour informatiser des langues et des groupes de langues peu dotées” [Berment, 2004]. Dans la thèse “Reconnaissance automatique de la pa-role pour des langues peu dotées” [Le, 2006], les langues bien dotées qui sont les quelques langues qui possèdent des ressources en quantité importante, sont op-posées aux langues peu dotées qui disposent de peu de ressources linguistiques servant à élaborer les systèmes de reconnaissance ou de TALN.
Les progrès considérables qui ont été réalisés depuis les années 1990, ont per-mis l’émergence de recherches et de nombreux projets sur l’adaptation rapide des systèmes à des langues qui ne disposeraient pas, a priori, de quantités de données suffisantes. Les trois types de données nécessaires à l’élaboration d’un système de reconnaissance de la parole actuel sont de grands corpus de textes (typique-ment entre quelques dizaines et quelques centaines de millions de mots), un corpus audio de parole transcrite (typiquement entre quelques dizaines et quelques cen-taines d’heures), ainsi qu’un lexique de mots donnés avec leur prononciation et des variantes éventuelles. Le projet actuel SPICE (Speech Processing : Interactive Creation and Evaluation Toolkit), par exemple, de l’université Carnegie Mellon, s’est intéressé entre autres à l’afrikaans, au bulgare, au vietnamien, à l’hindi, au konkani, au telugu et au turc [Schultz et al., 2007]. Des projets plus anciens vi-saient à collecter des ressources pour des langues peu dotées, comme par exemple le projet Babel sur cinq langues est-européennes (bulgare, estonien, hongrois, rou-main et polonais) [Roach et al., 1996].
Des travaux récents ont principalement cherché à limiter le temps et les moyens nécessaires à la constitution des corpus d’apprentissage audio et textes, et ont mis l’accent sur la modélisation acoustique en étudiant la portabilité rapide des modèles acoustiques d’une langue (ou multilingues) vers une autre. Dans le projet mentionné SPICE [Schultz et al., 2007], des modèles multilingues sont utilisés pour initialiser les modèles acoustiques (technique dite de bootstrap, présentée dans la section 1.2.4 ), et sont entraînés de manière itérative pour devenir dépendants de la langue cible. Dans [Le, 2006], des mesures de proximité entre modèles acoustiques de phones sont proposées pour sélectionner les meilleurs modèles d’initialisation multilingues. Ces travaux ont montré qu’avec un petit corpus audio de parole transcrite (quelques heures de données) collecté pour une nouvelle langue, un
1.3. PROBLÉMATIQUE DE LA THÈSE
modèle acoustique d’une performance acceptable peut être construit à partir des modèles acoustiques multilingues pré-existants.
En ce qui concerne la création d’un lexique de prononciation, l’approche la plus couramment utilisée lorsque peu de connaissances linguistiques sont accessibles sur la langue étudiée pour générer des prononciations, est d’associer un phone à chaque graphème. Cette approche est appelée modélisation acoustique à base de graphèmes. Elle a le double avantage de permettre la génération d’un lexique très simplement et très rapidement. Cette méthode a été étudiée pour différentes langues peu dotées ou moyennement dotées : arabe [Abdou, 2004], russe [Stücker et Schultz, 2004], vietnamien et khmer [Le, 2006], mais également pour des langues bien dotées : allemand, anglais, espagnol [Killer et al., 2003], allemand, anglais, italien, néerlandais [Kanthak et Ney, 2002].
Des efforts sont également concentrés sur le développement d’outils destinés à collecter des données afin de rendre les langues concernées un peu mieux dotées. Le recueil de signaux de parole est une tâche lourde. Les campagnes d’enregis-trement mobilisent d’importantes ressources humaines pour guider ou assister les locuteurs dans leur tâche de diction, pour organiser l’enregistrement, pour prépa-rer les scénarios et les données, etc. Les outils comme EMACOP (Environnement Multimédia pour l’Acquisition et la gestion de Corpus Parole) [Vaufreydaz et al., 1998] dévelopé au laboratoire LIG/GETALP (ex CLIPS) permettent d’organiser la campagne d’enregistrement sur le réseau, en mode client-serveur, de plusieurs locuteurs en même temps. Ce type de logiciel permet d’accélérer le recueil de si-gnaux de parole pour la modélisation acoustique. En effet, le manque de données acoustiques peut être en partie résolu par une méthodologie efficace de collecte de données ou d’adaptation de modèles acoustiques existants (méthodes trans-lingues).
Concernant le recueil de données textuelles en grande quantité, une approche intéressante consiste à « aspirer » un grand nombre de sites Web dans la langue donnée et à filtrer les données récupérées pour les rendre exploitables. Une telle approche a déjà été validée pour une langue bien dotée telle que le français [Vau-freydaz, 2002]. Les problèmes spécifiques pour les langues peu dotées concernent le nombre de sites Web qui peut être peu important, la vitesse de transmission, et la
faible qualité des documents qui nécessite plus d’outils de traitement. Dans [Pelli-grini, 2008], les expérimentations montrent que le manque de textes est le facteur le plus limitant lors de l’élaboration d’un système de RAP pour une langue peu dotée dans la mesure où il n’est pas possible de remédier, de quelque façon que ce soit, à l’absence de textes disponibles, due en particulier à un très petit nombre de sites Internet dans la langue étudiée.
Plusieurs travaux ont tenté de pallier les problèmes liés à la modélisation du langage pour les langues peu dotées, à savoir des taux de mots inconnus élevés et des modèles de langage peu fiables à cause du manque de données d’appren-tissage. Dans la thèse « Transcription automatique de langues peu dotées » [Pel-ligrini, 2008], les recherches portent principalement sur la modélisation lexicale, et en particulier sur la sélection des unités lexicales, mots et sous-unités, utilisés par les systèmes de reconnaissance automatique pour les langues comme l’am-harique et le turc. Des stratégies similaires ont été utilisées également dans la thèse « Sauvegarde du patrimoine oral africain : conception de système de trans-cription automatique de langues peu dotées pour l’indexation des archives audio » [Nimaan, 2007] pour modéliser une autre langue africaine : le somali.
Les systèmes de reconnaissance automatique de la parole sont pour la plupart des systèmes à vocabulaire fermé, c’est-à-dire que seuls les mots du lexique de prononciations peuvent être reconnus. Ainsi, le manque de textes fait que les taux de mots hors-vocabulaire peuvent être très élevés, typiquement au dessus de 5%. D’autre part, les modèles de langage sont estimés sur très peu d’occurrences des différents n-grammes, et sont pour cette raison peu fiables (nombreux replis sur des n-grammes d’ordre inférieur). Ce phénomène de taux de mots hors-vocabulaire élevé est encore plus prononcé pour les langues avec un système d’écriture sans séparation explicite entre les mots ou les langues ayant une grande richesse au niveau de la morphologie. Nous allons présenter dans la section suivante ces pro-blèmes, en particulier les problèmes liés aux langues ayant un système d’écriture sans séparation explicite entre les mots.
1.3. PROBLÉMATIQUE DE LA THÈSE
1.3.2 Langues non segmentées
La description très générique de méthode de modélisation statistique du lan-gage dans la section 1.2.3 pourrait nous amener à conclure que ces techniques de modélisation développées initialement pour les langues comme le français ou l’anglais peuvent être appliquées sans spécialisation à n’importe quelles autres langues. Théoriquement, il est vrai que l’estimation de modèles de langage n-gramme a besoin tout simplement d’une quantité suffisante de corpus de texte de la langue en question pour calculer les probabilités des séquences des mots (3-grammes des mots par exemple). Le mot qui est généralement l’unité de base dans la modélisation statistique du langage est naturellement définie comme une séquence de caractères séparée par les espaces pour les langues comme le français ou l’anglais. Mais pour beaucoup d’autres langues comme le chinois ou les langues dans notre contexte d’étude : khmer, vietnamien, laotien et thai , cette définition n’est pas aussi naturelle et adéquate.
Tandis que le mot est généralement l’unité de base dans la modélisation statis-tique du langage, l’identification de mots dans un texte n’est pas une tâche simple même pour les langues qui séparent les mots par un caractère (un espace en gé-néral). Pour les langues dites non segmentées qui possèdent un système d’écriture sans séparation évidente entre les mots, les n-grammes de mots sont estimés à par-tir de corpus d’apprentissage segmentés en mots. La segmentation automatique n’est pas une tâche triviale et introduit des erreurs à cause des ambigüités de la langue naturelle et la présence de mots inconnus dans le texte à segmenter.
Alors que le manque de données textuelles a un impact sur la performance des modèles de langage, les erreurs introduites par la segmentation automatique peuvent rendre ces données encore moins exploitables. Une alternative possible consiste à calculer les probabilités à partir d’unités sous-lexicales. Parmi les tra-vaux existants qui utilisent des unités sous-lexicales pour la modélisation du lan-gage, nous pouvons citer [Kurimo et al., 2006], [Abdillahi et al., 2006] et [Afify et al., 2006] qui utilisent les morphèmes respectivement pour la modélisation de l’arabe, du finnois, et du somali. Pour une langue non-segmentée comme le japo-nais, le caractère (idéogramme) est utilisé dans [Denoual et Lepage, 2006].
1.3.3 Sujet de thèse
Ce travail de thèse fait partie du projet de développement des activités de recherche dans le Département Génie Informatique et Communication (GIC) de L’Institut de Technologie du Cambodge (ITC). Plusieurs résultats sont attendus à la fin de cette thèse. Premièrement, du point de vue du développement de l’acti-vité de recherche au GIC, le choix du sujet de thèse dans le domaine du traitement automatique de la parole en langue khmère, langue officielle du pays, est un cré-neau à saisir pour afficher la spécificité de notre future équipe de recherche et pour contribuer de manière concrète au développement informatique de la langue khmère.
L’aspect opérationnel de ce travail de thèse consiste dans un premier temps à constituer les ressources linguistiques nécessaires : le corpus de parole, le corpus de texte, le dictionnaire de prononciation et à développer les outils de base pour traiter ces données. Ensuite, il consiste à développer un système de reconnaissance automatique de la parole de l’état de l’art pour la langue khmère (broadcast news) à partir de ces ressources. Cette contribution permet de doter la langue khmère de ressources linguistiques numériques qui sont indispensables pour développer des outils de traitement automatique de la langue et pour poursuivre des travaux de recherche plus avancés dans le domaine. Ce travail permet également de revisiter les méthodes et les outils de l’état de l’art proposés pour la collecte rapide de données et le développement rapide d’un système de RAP pour une nouvelle langue peu dotée.
La contribution scientifique de cette thèse concerne la spécificité des langues traitées dans notre contexte d’étude : les langues peu dotées et ayant un système d’écriture sans séparation explicite entre les mots qui nécessite la segmentation au-tomatique en mots pour rendre la modélisation de langage n-gramme applicable. Pour tenter de pallier les problèmes, à savoir des taux de mots inconnus élevés et des modèles de langage peu fiables à cause de manque de données textuelles et les erreurs de segmentations, nous avons axé nos recherches principalement sur la modélisation lexicale, et en particulier sur le choix des unités lexicales efficaces, mots et sous-unités, utilisées par les systèmes de reconnaissance. Le problème de la faible quantité de données textuelles implique de réfléchir à des techniques
1.4. CONCLUSION
de modélisation lexicale et sous-lexicale (mots, groupe de caractères, caractères), permettant ainsi de réduire la taille du vocabulaire de l’application, tout en es-sayant d’exploiter au mieux les données. Nous proposons de traiter ce problème en exploitant plusieurs vues sur les données textuelles dans la modélisation du langage. Nous travaillons à la fois au niveau du modèle de langage en créant des vocabulaires hybrides à partir d’unités lexicales et sous-lexicales, et au niveau du système en combinant des sorties de différents systèmes de RAP pour décoder une meilleure hypothèse. Ces méthodes de modélisation multi-unités sont appliquées et validées dans les systèmes de RAP pour les langues suivantes : le khmer, le vietnamien, le thai et le laotien.
1.4 Conclusion
Dans ce chapitre, nous avons présenté le contexte et la motivation de notre thèse. Nous avons par la suite abordé le principe de la reconnaissance de la parole par l’approche statistique, et décrit les différentes composantes d’un système de RAP standard : modèles acoustiques, modèles de langage, dictionnaire de pronon-ciation, et présenté très brièvement le principe des décodeurs. En fin de chapitre, nous avons présenté la problématique principale du travail de thèse : les problèmes liés au développement d’un système de RAP pour les langues peu dotées et ayant un système d’écriture non segmenté.
Chapitre
2
Reconnaissance automatique de la parole
en langue khmère
2.1 Introduction
Le développement d’un système de Reconnaissance Automatique de la Parole continue grand vocabulaire (RAP) pour une langue peu dotée comme le khmer est une tâche qui conduit à trois challenges : (1) le manque de ressources linguistiques sous forme numérique (corpus de texte et de parole), (2) le système d’écriture sans séparation explicite entre les mots, qui nécessite une segmentation automatique pour que la modélisation statistique du langage soit applicable et (3) les carac-téristiques acoustiques et phonologiques de la langue qui sont encore assez peu étudiées.
Ce chapitre présente une vue d’ensemble concernant le développement d’un système RAP pour le khmer. Nous décrivons tout d’abord notre méthode de col-lecte de données linguistiques pour le développement rapide d’un nouveau système de RAP pour une langue peu dotée. Le problème du manque de données textuelles et de la présence d’erreurs lors de la segmentation en mots est abordé. Nous trai-tons ce problème en exploitant plusieurs vues sur les données textuelles dans la modélisation du langage. Pour la modélisation acoustique, nous présentons et com-parons des méthodes de génération automatique de dictionnaires de prononciation
à base de graphèmes et à base de règles de conversion graphème-phonèmes pour le khmer. Enfin, des expérimentations sont menées pour tester et comparer les approches proposées.
2.2 Présentation de la langue khmère
Le khmer est la langue officielle du Cambodge parlée par plus de 16 millions d’habitants. C’est une langue appartenant au groupe des langues môn-khmères de la famille des langues austro-asiatiques. Le khmer est principalement parlé au Cambodge et dans certaines régions de la Thaïlande ( les khmers surin ) et du Viêt-Nam (delta du Mékong, les khmers Krom).
Le système d’écriture du khmer est alphasyllabique. L’alphabet khmer mo-derne possède 33 consonnes, 23 voyelles dépendantes et 14 voyelles indépendantes, sans compter les ligatures, les diacritiques et la ponctuation. Chaque consonne ap-partient à l’une des deux séries. Si une voyelle est associée à la première série (ou 1erregistre) elle produit un certain son et si elle est associée à la deuxième série (ou
2eme registre) elle produit un autre son. Ainsi les voyelles ont deux prononciations
possibles.
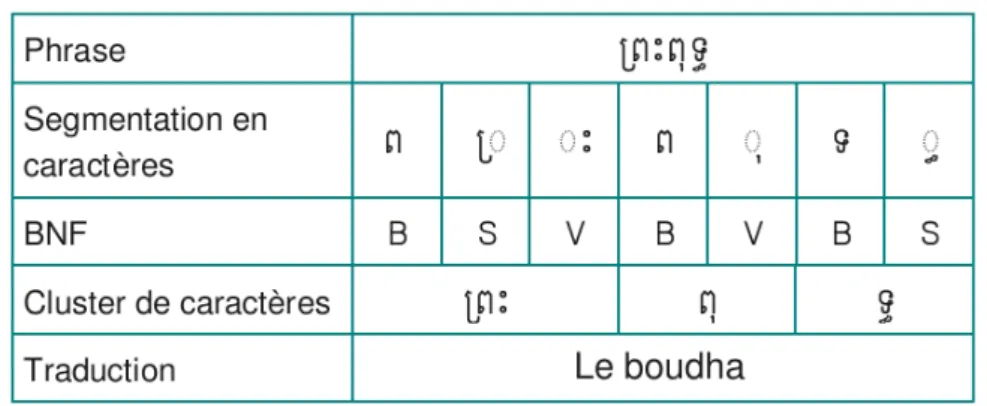
L’écriture du khmer est sans séparation entre les mots. On place un espace entre des groupes de mots pour marquer une pause (équivalent à une virgule ou un point-virgule en français). Ceci pose des problèmes en traitement automatique qui devront être résolus. A titre d’exemple, la figure 2.1 présente une phrase khmère et la segmentation en mots de cette phrase.
Figure2.1 – Exemple d’une phrase en khmer.
Le khmer est une langue atonale, contrairement à ses voisines thaïes, laotiennes ou vietnamiennes. Cependant, le khmer possède comme ses cousines austro-asiatiques
2.2. PRÉSENTATION DE LA LANGUE KHMÈRE
plusieurs registres vocaliques : les voyelles peuvent être allongées (dites voyelles longues), raccourcies (dites voyelles brèves), diphtonguées, reposer sur des consonnes aspirées ou non aspirées, ce qui en modifie complètement le sens.
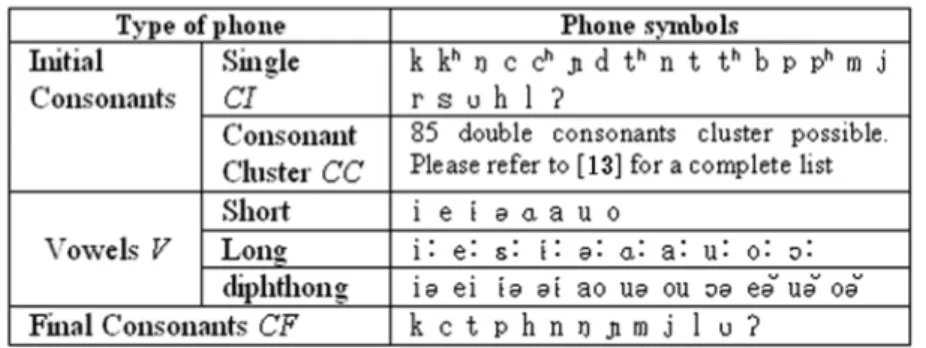
Cette particularité fait du khmer l’un des plus riches systèmes vocaliques au monde. Au niveau de la phonétique, il y a 29 phonèmes vocaliques : 10 phonèmes longs, 7 phonèmes brefs et 12 diphtongues. Une analyse phonétique détaillée de la langue khmère a été effectuée dans le cadre de notre projet TALK [Seng et Sam, 2005]. La langue khmère se compose de monosyllabes et polysyllabes. Les poly-syllabes sont courantes surtout dans leur forme bi- et tri-syllabique. La structure syllabique générale du khmer se retrouve sous la forme suivante :
C1(C2)(C3)V (C4) (2.1)
avec Ci consonne et V voyelle [Huffman, 1970]. Nous notons que la consonne
initiale et la voyelle du noyau sont obligatoires et les autres consonnes sont facul-tatives. Cependant, pour les voyelles courtes, la consonne finale est obligatoire. La consonne C3 est rarement présente dans les mots khmers.
La langue khmère a bénéficié d’un grand nombre d’emprunts au sanskrit, au pali et au français ainsi que, dans les milieux urbanisés, au chinois. La plus grande partie du vocabulaire administratif, militaire et littéraire est empruntée au sans-krit. Avec l’introduction du bouddhisme au début de XVme siècle, le pali devient
une source d’emprunts lexicaux très importante. Plus récemment, du fait de l’oc-cupation française en Indochine, certains mots ont été empruntés au français, mais orthographiés en khmer.
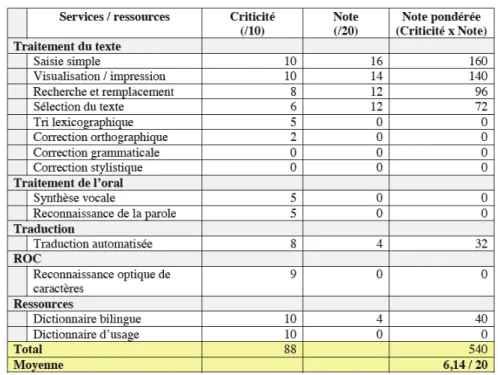
2.2.1 Le khmer, une langue peu dotée ?
En utilisant la méthode proposée dans [Berment, 2004], nous pouvons évaluer de manière quantitative le degré d’informatisation d’une langue en utilisant le protocole suivant : pour chaque service ou ressource informatique de la langue en question, un groupe d’utilisateurs représentatifs des locuteurs de la langue attribue un niveau de criticité et une note. La moyenne pondérée des notes reflète