Frequency approach for detecting nonstationarity in dependent data
Texte intégral
Figure

Documents relatifs
Proportions of hits (for test-items T) and false alarms (for similar lures S and different lures D) presented as a function of version (expressive/mechanical) and test item (T),
We aim to use a Long Short Term Memory ensemble method with two input sequences, a sequence of daily features and a second sequence of annual features, in order to predict the next
The analysis results are shown in Fig.1. On average, 62% of used data are in a read-only state but they represent only 18% of the accesses made by the application. The propor- tions
SSN 1 The CLNN model used the given 33 layers of spatial feature maps to predict the taxonomic ranks of species.. Every layer of each tiff image was first center-cropped to a size
The Long Short-Term Memory Deep-Filer (LSTM-DF) was presented in this paper to filter rPPG signals as an al- ternative to conventional signal processing techniques that
We could imagine for instance passing the normalized disparity plane as an extra channel in the cell input and instead of learning features about the most probable color, let
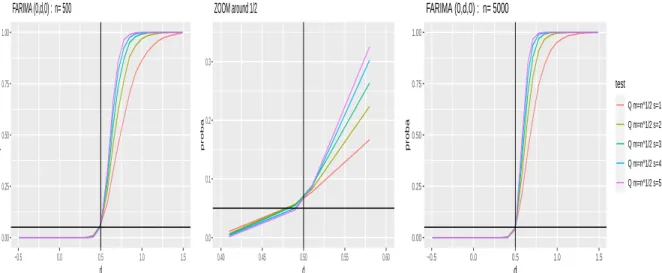
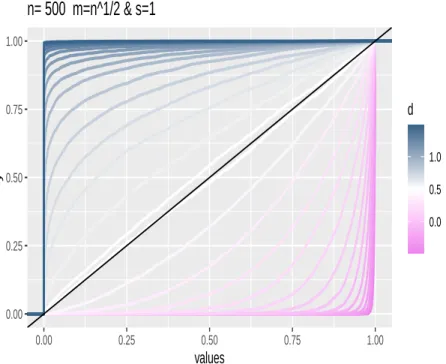
Among all wavelet estimators of the memory parameter d presented in this paper, for a given choice of wavelet and scales involved in the estimates, the estimator with optimal
Central or peripheral blocks allow the delivery of selective subarachnoid anesthesia with local normobaric and/or hyperbaric anesthetics; lipophilic opioids may be used with due
