T
T
H
H
È
È
S
S
E
E
En vue de l'obtention du
D
D
O
O
C
C
T
T
O
O
R
R
A
A
T
T
D
D
E
E
L
L
’
’
U
U
N
N
I
I
V
V
E
E
R
R
S
S
I
I
T
T
É
É
D
D
E
E
T
T
O
O
U
U
L
L
O
O
U
U
S
S
E
E
Délivré par l'Université Toulouse III - Paul Sabatier Discipline ou spécialité : Radiophysique et imagerie médicales
JURY
Mr. Ramesh Agrawal, Professeur à l'Université Jawaharlal Nehru, New Delhi M. Isabelle Berry, Professeur à l'Université Paul Sabatier, Toulouse Mr. Amar Djeradi, Professeur à l'Université de Houari Boumediene, Alger
M. Rachida Djeradi, Professeur à l'Université de Houari Boumediene, Alger Mr. Eric Gonneau, Maître de conférence à l'Université Paul Sabatier, Toulouse
Ecole doctorale : Génie Electrique, Electronique, Télécommunications: du système au
nanosystème
Unité de recherche : Laboratoire d'Etude et de Recherche en Imagerie Spatiale et Médicale Directeur(s) de Thèse : Guy Flouzat, Eric Gonneau
Rapporteurs : Ramesh Agrawal et Amar Djeradi
Présentée et soutenue par Sarah GHANDOUR Le 12 juillet 2010
Titre : Segmentation d'images couleurs par morphologie mathématique: application aux
À mes parents
Remerciements
Cette thèse a été préparée à l’Université Paul Sabatier de Toulouse au sein du Laboratoire d’Etude et de Recherche d’Imagerie Spatiale et Médicale (LERISM).
Tout d’abord, je tiens à rendre hommage à mon directeur de thèse Guy Flouzat et à mon co-directeur Patrick Vannoorenberghe, qui nous ont quitté en juin 2009 et en janvier 2007 respectivement. Leur disparition soudaine m’a laissé dans la peine de perdre non seulement des directeurs, mais surtout les amis qu’ils étaient devenus. Ils resteront toujours présents et bien vivants dans mon esprit.
J’adresse mes sincères remerciements à madame Isabelle Berry, Professeur à l’Université Paul Sabatier et responsable du Master RIM pour m’avoir initié à effectuer ce travail de recherche.
Je remercie également Eric Gonneau pour son aide et sa disponibilité ainsi que son soutien durant mes années de thèse.
Merci également à tous les membres de jury qui se sont déplacés pour me faire l’honneur de prendre part à mon jury.
Merci à Catherine Molacek pour son support et son encouragement infini tout au long de mes années de thèse.
Merci également à Nathalie Authié pour sa grande sympathie qui a été pour moi un soutien immense.
Merci à tous mes copains libanais: Elie, Joseph, Elias, Pierre, Ziad, Charbel, Kamil, Toufic, Nemer, Marie, Nada, Léna, Julie et Bouchra, qui ont participé d’une façon ou d’une autre à la finalisation de ce travail.
Je tiens à remercier les amis du Cesbio: Arnaud, Patrick, Vincent.
Un immense merci à Philippe Richaume pour tout ce qu’il m’a appris et fait découvrir ainsi que les discussions très intéressantes que j’ai partagées avec lui.
Je n’oublie pas de remercier Ludovic et Ion pour tous les bons moments que j’ai passés et que je passe avec eux depuis qu’on se connait.
Finalement un grand merci à Patrick Sharrock qui sans son soutien et sa présence, ce travail n’aurait pas pu aboutir.
Je remercie également toute l’équipe du LERISM : Marina, Véronique, Yan et Rasto pour leur implication dans la réussite de ce travail, leurs conseils et leurs encouragements tout au long de mon séjour dans leurs locaux.
"Vous ne donnez que peu lorsque vous donnez vos biens. C'est lorsque vous donnez de vous-mêmes que vous donnez réellement"
Table des matières
Chapitre 1 ... 18
Introduction ... 18
1. Contexte ... 18
2. Problématique ... 19
2.1 Choix des opérateurs ... 19
2.2 Choix de paramètres ... 19
3. Notre Contribution ... 20
4. Organisation du mémoire ... 21
Chapitre 2 ... 23
Etat de l’art de la segmentation d’images en régions ... 23
1. Introduction ... 23
2. L’image numérique ... 23
3. La chaîne de traitement d’images ... 24
4. La segmentation d’images en régions ... 25
4.1 La segmentation basée sur la classification des pixels ... 26
4.1.1 Clustering ... 27
4.1.2 Seuillage d’histogramme ... 28
A. Seuillage d’histogramme tridimensionnel (3D) ... 28
B. Seuillage d’histogramme bidimensionnel (2D) ... 29
C. Seuillage d’histogramme monodimensionnel (1D) ... 29
4.2 La segmentation basée sur l’analyse des caractéristiques spatiales ... 30
4.2.1 La segmentation par croissance de régions ... 31
4.2.2 La segmentation par division fusion... 32
4.2.2.1 Le tétra-arbre... 33
4.2.2.2 Le diagramme de Voronoï ... 34
4.2.2.3 Le graphe d’adjacence des régions ... 35
4.2.3 Autres approches ... 36
4.2.3.1 Les méthodes utilisant les champs de Markov ... 36
4.2.3.2 Réseaux de neurones ... 37
4.3 La segmentation basée sur la morphologie mathématique ... 37
4.3.1 Opérateurs basiques ... 38
4.3.2 La ligne de partage des eaux ... 40
4.3.2.1 La LPE par immersion : algorithme de Vincent-Soille ... 42
4.3.3.1 Gradient marginal ... 47
4.3.3.2 Gradient vectoriel ... 48
4.3.4 La sur segmentation ... 49
4.3.4.1 La LPE contrainte par les marqueurs ... 49
A. filtrage des minima ... 50
B. recherche des marqueurs utilisant des connaissances a priori ... 50
4.3.4.2 Les algorithmes de fusion des régions ... 52
4.4 La segmentation spatio-colorimétrique ... 53
5 Conclusion ... 54
Chapitre 3 ... 57
Segmentation par morphologie mathématique ... 57
1. Introduction ... 57
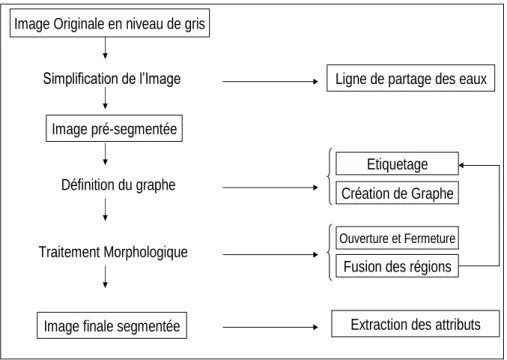
2. Principe du système de segmentation ... 57
2.1 Simplification de l’image par LPE ... 58
2.1.1 Image gradient ... 59
2.2 Définition du graphe ... 60
2.2.1 Etiquetage des régions ... 60
2.2.2 Création du graphe d’adjacence des régions ... 61
2.2.3 Partitionnement du graphe d’adjacence des régions ... 61
2.3 Traitement morphologique ... 63
2.3.1 Algorithme de croissance des régions ... 63
3. Classification des pixels ... 66
3.1 Rapport de vraisemblance généralisé GLR... 66
3.2 Critère d’information bayésienne BIC ... 68
3.3 Classification GLR-BIC ... 69
4. Fusion des composantes couleurs segmentées ... 72
4.1 Concordance des étiquettes... 73
5. Traitement complémentaire... 73
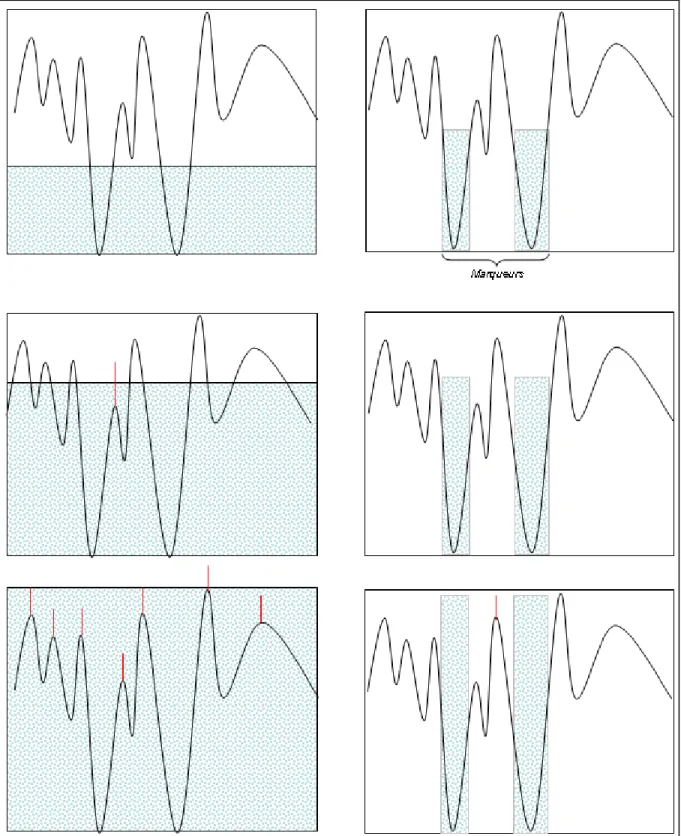
5.1 Extraction des pics ... 76
5.2 Croissance des régions à partir des marqueurs ... 77
6. Extraction des connaissances ... 79
6.1 Les attributs intrinsèques ... 79
6.2 Les attributs extrinsèques ... 81
6.2.1 Relation topologique ... 82
6.2.2 Relation métrique ... 83
7. Conclusion ... 85
Chapitre 4 ... 87
1. Introduction ... 87
2. Généralités sur l’anatomie et la cytologie pathologique ... 87
2.1 Description d’images ... 88
3. Résultats de la LPE ... 88
4. Résultats de GLR-BIC ... 93
5. Résultats de l’algorithme de segmentation morphologique proposé ... 94
6. Fusion des composantes couleurs segmentées ... 96
7. Extraction des attributs ... 96
8. Conclusion ... 101
Chapitre 5 ... 103
Optimisation et évaluation de l’algorithme de segmentation ... 103
1. Introduction ... 103
2. L’Analyse en Composante Principale ... 104
3. Application de l’algorithme de segmentation sur la PCI1 ... 105
4. Évaluation des résultats ... 108
4.1 Évaluation supervisée ... 110
4.1.1 Critère de Lezoray ... 110
4.1.2 Critère de Vinet ... 111
4.1.3 Discussion sur les critères supervisés ... 113
4.2 Évaluation non supervisée ... 113
4.2.1 Critère d’uniformité intra-région de Levine et Nazif ... 113
4.2.2 Contraste inter-région de Levine et Nazif ... 114
4.2.3 Contraste intra-inter régions de Zéboudj ... 115
4.2.5 Critère adaptatif de Rosenberger ... 117
4.2.6 Discussion sur les critères non supervisés ... 118
5. Études comparatives des méthodes de segmentation proposées ... 118
5.1 Image de référence ... 118
6. Résultats d’évaluation ... 119
6.1 Évaluation supervisée des résultats ... 119
6.1.1 Évaluation de l’algorithme GLR-BIC par rapport à K-means ... 121
6.2 Évaluation non supervisée des résultats ... 121
7. Conclusion ... 125
Chapitre 6 ... 127
Conclusion ... 127
Annexes... 131
Annexe A ... 132
Annexe B ... 135 La Morphologie Mathématique ... 135 Bibliographie ... 141
Liste de Figures
Figure 1: (a) l’image originale, (b) l’image classée par K-means avec K=3, (c) l’image classée par
k-means avec K=5 et (d) l’image classée par Isodata. ... 28
Figure 2: processus de division de l’image I utilsant le téra-arbre ... 33
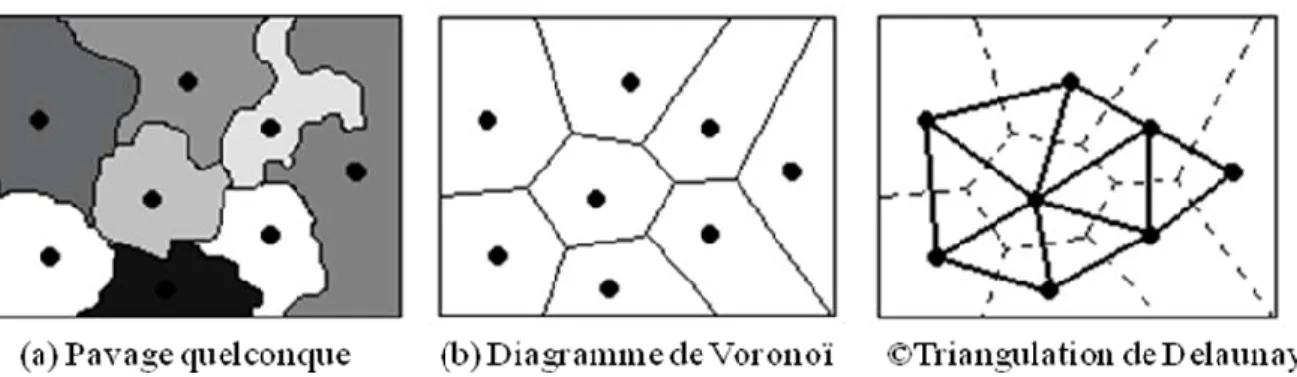
Figure 3: (a) l’image test, (b) diagramme de Voronoi et (c) la triangulation de Delaunay. ... 35
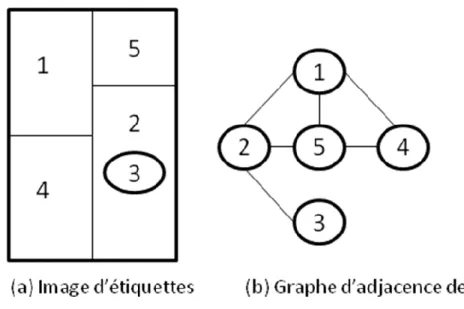
Figure 4: (a) image d’étiquettes et (b) graphe d’adjacence de régions ... 36
Figure 5: l’image de cytologie et l’image d’altitude correspondante. ... 40
Figure 6: minima, bassins versants et ligne de partage des eaux. ... 41
Figure 7: construction des barrages aux endroits où les eaux provenant de deux minima se mélangeraient [41]. ... 42
Figure 8 : la distance géodésique entre x et y à l’intérieur de A est le plus petit chemin entre ces deux points qui est totalement inclus dans A [41]. ... 43
Figure 9: la zone d’influence géodésique de composantes connectées Bi à l’intérieur d’un ensemble A [41]. ... 44
Figure 10: itération entre Xh et Xh+1 [41]. ... 45
Figure 11: deux régions plates séparées par une marche d’escalier. ... 47
Figure 12: processus de fusion de gradient. ... 47
Figure 13: processus de la LPE contrainte par les marqueurs. ... 51
Figure 14: segmentation marginale. ... 58
Figure 15: processus de segmentation. ... 59
Figure 16: exemple d’étiquetage. ... 60
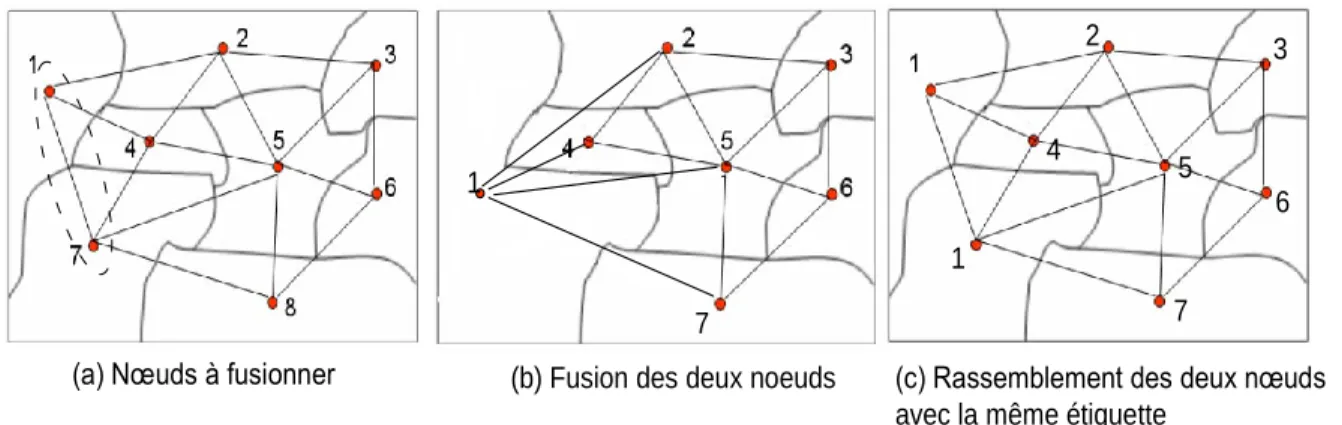
Figure 17: exemple de construction du graphe d’adjacence de régions. (a) L’image constituée par une ensemble de régions ; (b) les cellules de Voronoï correspondantes à (a) ; (c) la triangulation de Delaunay obtenue de (b) et (d) le graphe d’adjacence obtenu de (c). ... 62
Figure 18: simplification du RAG après avoir fusionné deux nœuds adjacents ... 62
Figure 19: (a) graphe quelconque sélectionné et l’ensemble des régions correspondant, (b) érosion sur le graphe, et (c) dilatation sur le graphe érodé [73]. ... 65
Figure 20: (a) graphe quelconque sélectionné et l’ensemble des régions correspondant, (b) ouverture sur le graphe, et (c) fermeture sur l’ouverture du graphe [73]. ... 65
Figure 21: classification GLR-BIC appliquée sur l’histogramme de l’image ... 71
Figure 22: segmentation marginale ... 72
Figure 23: exemple de segmentation des composantes couleurs et l’image de la concordance d’étiquettes obtenue ... 74
Figure 24: image test couleur originale et l’image segmentée correspondante ... 75
Figure 25: logarithme de l’histogramme de l’image étiquette 23 (d). ... 75
Figure 26: image des étiquettes et l’image filtrée correspondante ... 78
Figure 27: présentation des relations topologiques du modèle RCC-8 [73]. ... 82
Figure 28: distance entre les Rectangles englobant minimum [73]. ... 84
Figure 29: exemple d’images de cytologie. ... 89
Figure 31: exemples d’histogrammes des trois composantes rouge, vert et bleu. ... 93
Figure 32: résultat de l’application de l’algorithme GLR-BIC ... 94
Figure 33: résultats de segmentation sur l’image type 1. ... 95
Figure 34: résultats de segmentation sur l’image type 2. ... 95
Figure 35: exemple de superposition d’étiquettes. ... 97
Figure 36: résultats d’images couleurs segmentées obtenus avant et après post traitement. ... 98
Figure 37: exemple de sauvegarde d’attributs de régions extraits. ... 99
Figure 38: exemple d’extraction des noyaux. ... 100
Figure 39: exemple d’application de la LPE sur laPCI : (a) la composante1 PCI et (b) l’image 1 obtenue par la LPE. ... 107
Figure 40: exemple de résultats de segmentation avec couleur appariées : (a) l’image originale, (b) la vérité terrain, (c) classification marginale et (d) classification de la composante PCI1. .... 120
Figure 41: exemple 1 de l’application de l’algorithme GLR-BIC et K-means sur les différentes composantes de l’image couleur. ... 123
Figure 42: exemple 2 de l’application de l’algorithme GLR-BIC et K-means sur les différentes composantes de l’image couleur. ... 124
Liste des Tableaux
Tableau 1 Résultat des quelques opérateurs morphologiques ... 39
Tableau 2 Le nombre de régions pour les différentes composantes couleurs ... 73
Tableau 3 Les relations topologiques du modèle RCC-8 ... 82
Tableau 4 Nombre de régions obtenu après LPE ... 90
Tableau 5 nombre de régions obtenu avec le gradient morphologique Sup et le gradient vectoriel ... 92
Tableau 6 Exemple de résultats d’évaluation de la classification sur deux images différentes. .. 119
Tableau 7 Résultats de calcul des critères non supervisés sur la base de données de la Figure 45. ... 122
Résumé
La segmentation est une étape nécessaire dans le processus de traitement et d’analyse d’images. Elle correspond au partitionnement de l’image en un ensemble de classes ou de régions en se basant sur des critères spectraux ou spatiaux (comme l’information couleur, les relations de voisinage entre les pixels dans l’image...). Ces dernières années ont été marquées par la publication d’un grand nombre d’articles dans cette thématique. Les domaines d’application sont très variées : la télédétection, les applications militaires, l’imagerie médicale etc.
Nous proposons dans un premier temps une étude focalisée sur les différentes méthodes de segmentation en régions que l’on peut trouver dans la littérature. Ensuite, Nous développons une chaîne complète de segmentation d’images couleurs basée sur la théorie de la morphologie mathématique.
Cette méthode de segmentation consiste d’abord à simplifier l’image en utilisant la ligne de partage des eaux (LPE). Celle-ci transforme l’image en un ensemble de régions qui seront modélisées par un graphe d’adjacence de régions. Sur ce dernier, des opérations morphologiques sont appliquées afin de fusionner les régions candidates entre elles. Ce processus de fusion est contrôlé par un critère spectral calculé par une méthode de classification statistique.
Cette chaine de segmentation est appliquée à des images couleurs microscopiques afin de délimiter et d’extraire ses différents constituants tels que : les cytoplasmes et les noyaux.
L’originalité de l’algorithme proposé est qu’il possède des capacités de généricité, de flexibilité et d’adaptabilité à la variabilité des contextes. En effet, il combine l’information spatiale et spectrale contenue dans l’image en réduisant au minimum le nombre de paramètres à calculer. Ceci rend l’approche non supervisée et automatique.
Chapitre 1
Introduction
1. Contexte
La dernière décennie a été marquée par la publication d’un grand nombre d’articles dans le domaine de la recherche de traitement d’images. En effet, la mise à portée des systèmes d’acquisitions numériques de haute précision ainsi que la montée en puissance et en capacité de stockage des ordinateurs ont contribué au développement des systèmes d’aide à la décision dans le domaine de traitement d’images.
Le principal objectif de ces derniers consiste à obtenir une interprétation de l’image au niveau sémantique répondant aux différentes attentes des utilisateurs humains. Pour cela, de nombreux travaux ont été consacrés au développement de chaînes de traitement d’images basées essentiellement sur la segmentation. Un des plus grands domaines d’application de la segmentation est la médecine. Bien évidemment, il en existe d’autres parmi lesquels nous pouvons citer la télédétection qui est utilisée dans les domaines de la météo, la cartographie, l’analyse des ressources terrestres et encore dans quelques applications militaires.
Dans ce contexte, nous sommes intéressés au traitement d’images dans le domaine médical où l’image numérique s’est imposée comme un support et une source d’information privilégiée. La multiplication des dispositifs d’acquisition d’images médicales ainsi que leur perfectionnement en termes de qualité d’image et de précision ont conduit à la production d’une quantité d’information de plus en plus volumineuse. Ceci a rendu difficile son exploitation manuellement et a nécessité de plus en plus de temps pour la traiter. D’où la nécessité du traitement d’images pour automatiser certaines tâches d’analyse.
Le traitement d’images s’inscrit alors dans un processus préliminaire destiné à préparer les images numériques à leur interprétation. Ceci revient à améliorer la qualité de l’image d’abord en se débarrassant des défauts provenant des capteurs lors de l’acquisition ou des conditions d’acquisition. Ensuite l’image est segmentée afin de d’identifier les objets d’intérêts nécessaires à
son interprétation. Ceci permet d’extraire l’information sémantique contenue dans l’image qui servira ultérieurement à son exploitation par l’utilisateur.
Par conséquent, si l’on considère des images médicales formées des cellules différentes, l’amélioration de la qualité d’images revient à réaliser un filtrage pour éliminer le bruit provenant des imageurs ou de la numérisation. Le but de cette étape est de simplifier l’image de départ en fournissant une nouvelle image sur laquelle la segmentation sera appliquée. Cette dernière aura pour but de délimiter et de différencier les cellules présentes dans l’image. L’interprétation sera faite en se basant sur des connaissances a priori sur les cellules d’intérêts à extraire.
2. Problématique
La segmentation d’images est une étape primordiale en traitement d’images puisqu’elle conditionne la qualité de l’interprétation. Dans le domaine médical, son but est de délimiter les structures anatomiques et pathologiques chez un patient d’une façon automatique. La segmentation automatique des cellules tumorales dans une grande base d’images est d’un grand intérêt: elle permet d’aider le médecin dans son diagnostic, en accélérant le processus d’analyse en détectant les cellules tumorales éventuellement oubliées. La segmentation automatique des cellules est aussi très utile pour l’extraction des caractéristiques de ces dernières telle que leur dimension permettant ainsi aux praticiens de déterminer le degré de gravité de la maladie.
La segmentation automatique d’images est cependant une tâche difficile, du fait de la variabilité des images. Beaucoup de méthodes existantes dans la littérature donnent de bons résultats mais elles nécessitent des connaissances a priori qui sont généralement difficilement accessibles. En outre, les algorithmes de segmentation proposés dans la littérature nécessitent un choix délicat d’opérateurs à utiliser et un calcul compliqué de paramètres.
2.1
Choix des opérateurs
Afin de rendre la méthode la plus générale possible et qui s’adapte à différentes applications, une chaîne de traitement doit être mise en place. Cette dernière est évidemment composée d’un certain nombre d’opérateurs de traitement d’images choisi soigneusement en fonction de la qualité de l’image et de l’information recherchée dans celle ci. En effet, la difficulté de choix des opérateurs demeure dans l’adaptation du comportement théorique de ces derniers et leur comportement sur des cas réel afin de les rendre exploitable en routine clinique.
2.2
Choix de paramètres
En général, les opérateurs d’une chaîne de traitement ne peuvent fonctionner que par des paramètres. Le problème est donc de choisir une valeur optimale pour ces derniers afin de séparer
les différents constituants de l’image. La majorité des algorithmes existante dans la littérature font introduire une étape de calcul de paramètres assez compliquée ou exigent de les fixer manuellement.
3. Notre Contribution
Les méthodes de segmentation proposées dans la littérature sont basées sur l’estimation ou le calcul de paramètres des opérateurs pour une application précise. Nous trouvons en générale des méthodes qui reposent sur des études statistiques, sur la morphologie mathématique ou sur des méthodes combinant les deux approches. Ces approches mixtes tendent à résoudre le problème de calcul de paramètres ou à le minimiser le plus possible. Ceci permet de constater qu’il n’existe pas une seule méthode de segmentation universelle applicable à tous les domaines.
Le but de ce travail est de trouver une méthode de segmentation qui permet de résoudre les problèmes du choix des opérateurs et des paramètres. Notre méthode est appliquée aux images de cytologie: ses principes généraux cependant restent valables pour d’autres types d’images si ces derniers vérifient les mêmes conditions statistiques.
Dans cette thèse, nous étudions les possibilités offertes par la morphologie mathématique. Des outils théoriques très puissants ont été mis au point dans ce domaine. Tout au long de ce travail nous essayons de n’utiliser que des opérateurs ne nécessitants que peu de paramètres afin de rendre l’algorithme le plus automatique possible.
La méthode de segmentation proposée est basée sur la modélisation de l’image par un graphe d’adjacence de régions (RAG) sur lequel des opérations d’ouverture et de fermeture morphologiques sont appliquées. Or, afin d’accélérer le processus de segmentation, nous choisissons d’abord de simplifier l’image en utilisant la ligne de partage des eaux (LPE) qui constitue un des opérateurs basiques de la morphologie mathématique. Cet opérateur permet de donner la première partition de l’image en régions distinctes qui seront modélisées par le RAG. Sur ce dernier les régions candidates sont fusionnées afin de former les objets d’intérêts recherchés dans l’image.
Ainsi, nous combinons les différents opérateurs de la morphologie mathématique pour les adapter au domaine particulier que l’on souhaite étudier. Par conséquent, cette combinaison donne à la segmentation une définition légèrement différente de celle que l’on trouve dans la littérature et qui consiste à obtenir une partition de l’image en région seulement.
Dans ce travail, nous adoptons d’abord l’approche de segmentation marginale qui consiste à segmenter les composantes de l’image couleur indépendamment et séparément. Les résultats obtenus sont quantifiés en utilisant des opérateurs d’évaluation supervisée et non supervisée. Afin d’accélérer l’algorithme de segmentation proposé, nous proposons de réduire la dimension de
l’image couleur en utilisant l’analyse en composante principale (ACP). Cette dernière permet d’obtenir des composantes images dont une contient la quasi totalité de l’information. Les résultats obtenus sur cette composante image permettent de valider l’utilisation de l’ACP à la place de la segmentation marginale.
4. Organisation du mémoire
Ce mémoire de thèse est divisé en cinq chapitres:
1. Le chapitre 2 concerne un travail de synthèse portant sur la segmentation d’images en régions. Les avantages et les inconvénients de ces méthodes sont présentés afin de situer la méthode proposée par rapport à celles ci.
2. Le chapitre 3 présente l’algorithme de segmentation que nous proposons. Nous détaillons les trois modules le constituant, sa réalisation et sa validation au travers d’images tests:
a. le premier module concerne la simplification de l’image en la transformant en une partition de régions disjointes.
b. le deuxième module montre la modélisation des régions obtenues, suite à l’application du module précédent, par un graphe d’adjacence de régions. Sur ce dernier, un algorithme de croissance des régions basé sur des opérations morphologiques est appliqué où la fusion des régions est faite en respectant un critère spectral donné. Afin de calculer ce dernier d’une façon automatique, nous présentons une nouvelle méthode de classification non supervisée dont le but sera de contrôler les opérations morphologiques.
c. le troisième module présente l’extraction des attributs des différents constituants de l’image.
3. Le chapitre 4 montre les résultats d’application de l’algorithme de segmentation morphologique présenté dans le chapitre 3. Nous choisissons de l’appliquer sur des images microscopiques notamment les images de cytologie.
4. Dans le chapitre 5, nous proposons d’utiliser l’Analyse en Composante Principale afin d’optimiser notre algorithme de segmentation. Nous évaluons les résultats obtenus afin de conclure sur la meilleure stratégie à adopter pour la segmentation d’images.
Chapitre 2
Etat de l’art de la segmentation
d’images en régions
1. Introduction
La segmentation d’images est une étape essentielle dans les sujets de recherche en traitement d’images. Les applications sont nombreuses et font intervenir deux principales approches de segmentations; il s’agit de l’approche frontière et de l’approche région [1].
L’approche frontière se distingue par la mesure des variations locales d’intensités représentantes des changements de propriétés physiques ou géométriques de l’objet dans l’image. Ces variations correspondent aux contours d’objets séparant les différentes composantes d’une scène dans l’image.
L’approche région se caractérise par la mesure d’uniformité entre des surfaces construites dans l’image. Elle part d’une première partition de l’image qui sera modifiée en divisant ou en regroupant des régions.
Dans ce chapitre nous présentons dans un premier temps la définition de l’«image numérique» qui correspond au support sur lequel nous avons travaillé. Puis, dans un deuxième temps nous montrons en quoi consiste une chaîne de traitement d’images. Ensuite, nous nous intéressons à la deuxième approche de segmentation qui est l’approche région en détaillant les différentes techniques de cette dernière proposées dans la littérature.
2. L’image numérique
Une image est un signal bidimensionnel ou tridimensionnel. Or, afin de pouvoir réaliser des traitements informatiques sur une image, celle-ci doit être absolument numérique ou numérisée. La numérisation d’une image consiste à convertir les valeurs continues du signal de cette dernière
i (son état analogique) en des valeurs discontinues I qui correspond à une structure de données informatiques. Par exemple, pour un objet plan, carré, de 3x3 cm de côté, nous considérons sa décomposition en 9 petits carrées élémentaires de 1 2
derniers une valeur entière n est déterminée. Les 9 valeurs de I obtenues sont disposées en une structure finie appelée matrice, repérée par leur position à l’intersection d’une ligne et d’une colonne formant une image. Ainsi, une image numérique est définie par:
le nombre de pixels qui la composent en largeur et en hauteur.
la valeur que peut prendre chaque pixel. Elle est représentée par un scalaire dans le cas d’images en niveau de gris et par un vecteur à trois composantes Rouge, Vert et Bleu dans le cas d’images couleur. Ces valeurs sont incluses dans N.
Cette représentation est certes approchée mais parfaitement adaptée aux possibilités de traitement mathématique qu’apportent les ordinateurs. En ce qui concerne le présent travail, nous nous intéressons aux images numériques couleurs dans l’espace RVB1 2D qui sont le résultat d’une acquisition numérique avec une caméra CCD2
.
3. La chaîne de traitement d’images
Une chaîne de traitement commence par l’acquisition de données physiques sous la forme d’une image. Cette image peut être:
- soit numérique obtenue par des systèmes d’acquisition numériques (caméra CCD, capteur CMOS…),
- soit analogique d’où la nécessité de passer par l’étape de numérisation avant tout traitement.
La chaîne de traitement est composée de trois étapes essentielles:
1. l’étape de prétraitement qui consiste à améliorer la qualité de l’image acquise. Il peut s’agir d’éliminer le bruit ou de rehausser le contraste.
2. l’étape de segmentation qui sera détaillée dans la suite de ce travail. Cette étape peut être suivie par une étape de post traitement (étape facultative) qui consiste à raffiner la segmentation afin d’améliorer les résultats obtenus.
3. l’étape d’interprétation qui consiste à extraire l’information sémantique de l’image en identifiant les différents objets qui la constituent.
Il faut noter que les résultats de la deuxième étape (la segmentation) conditionnent très
1
http://fr.wikipedia.org/wiki/Espace_colorimétrique 2 http://fr.wikipedia.org/wiki/Capteur_photographique
fortement le résultat de la troisième étape (l’interprétation). Ceci peut engendrer parfois des erreurs. Par conséquent, des méthodes d’évaluation de la segmentation sont généralement utilisées afin de quantifier les résultats obtenus pour une meilleure interprétation de l’image.
4. La segmentation d’images en régions
La segmentation consiste à faciliter l’interprétation automatique d’une image de façon similaire à une interprétation humaine. Historiquement, elle a été inspirée du système de perception visuel humain qui utilise les notions de similarité et de différence afin de localiser et délimiter les objets d’une scène.
En général, la segmentation est considérée comme une étape de traitement « bas niveau » de l’image. Elle consiste à partitionner cette dernière en un ensemble de régions homogènes ou à détecter les contours (recherche des discontinuités locales) en se basant sur un calcul de statistiques sur l’image. Une grande variété de techniques existante dans la littérature permet de réaliser ces tâches. Dans ce travail nous nous intéressons à la segmentation d’images en régions qui fait intervenir les quatre approches principales suivantes:
- la segmentation basée sur la classification des pixels.
- la segmentation basée sur l’analyse des caractéristiques spatiales. - la segmentation basée sur la morphologie mathématique.
- La segmentation spatio-colorimétrique.
La première approche de segmentation se distingue par la création de classes qui obéissent essentiellement à des propriétés spectrales. La deuxième approche s’appuie sur la notion de connexité. La troisième approche se base sur l’utilisation de l’algorithme de la ligne de partage des eaux. Et la dernière approche se base sur la combinaison des approches de classification des pixels et d’une part des approches basées sur l’analyse des caractéristiques spatiales et d’autre part la morphologie mathématique.
Dans ce chapitre, nous détaillerons ces quatre grandes catégories en présentant les principales méthodes de segmentation d’images en régions que l’on peut trouver dans la littérature. Nous présentons leurs différentes applications ainsi que les points faibles de chacune d’elles. Nous concluons cette partie par un résumé des principaux points abordés et nous introduisons l’approche de segmentation que nous avons développée.
4.1
La segmentation basée sur la classification des pixels
Cette technique consiste à détecter des classes sur l’image en se basant sur l’information spectrale des pixels. Nous appelons une classe un ensemble de pixels p partageant un même i
ensemble de propriétés statistiques. Un résultat de classification peut être défini comme suit: Soit L le partitionnement de l’image I en NL classes L : i
NL
L L
L 1,..., (1) nous admettons que les classes ne sont pas vides :
j
L NL
j 1,...., , (2)
et que l’intersection de deux classes doit être vide c-à-d que les deux classes sont distinctes:
j i L L NL j i j i , , 1,...., 2, (3)
l’union de ces classes doit constituer l’image entière avec :
NL i i L I 1 (4) iL est une classe de l’image qui est composée de
j L p N pixels où Lj p j j J N L L K L
p
p
p
1,...,
(5)correspond à l’ensemble de pixels de la classe L : j
Lj p j N k k L jp
L
NL
j
1,
,...,
1
(6)La classification est divisée en deux grandes catégories:
les méthodes de « Clustering » qui consistent à regrouper tous les pixels ayant des couleurs similaires et qui forment un nuage de points bien identifiable dans l’espace couleur 3D
ou dans l’espace 2D.
les méthodes de « seuillage d’histogramme » qui se basent sur l’extraction des pics sur l’histogramme de l’image définissant ainsi une classe.
4.1.1
Clustering
Le « clustering » est une opération qui tend à séparer différentes zones vérifiant des critères d’homogénéité donnés dans l’image afin d’organiser les pixels en groupes appelés « clusters ». Ces critères peuvent être représentés par un degré de similarité de couleur, d’intensité ou de texture élevé.
L’un des algorithmes les plus connu, pour la classification est l’algorithme K-means [2] largement adopté en traitement d’images vu sa simplicité de mise en œuvre et sa capacité à fournir une bonne approximation de la segmentation recherchée. C’est un algorithme itératif qui minimise la somme des distances entre chaque pixel et le centroïde de son « cluster ». Ces centroïdes sont initialement placés le plus loin possible les uns des autres afin d’optimiser la qualité des résultats obtenus. Le principe de cet algorithme consiste à échanger des pixels entre deux classes jusqu'à ce que la somme des distances intra classes ne puisse plus diminuer. Le résultat idéal serait un ensemble de « clusters » compacts et clairement séparés. Néanmoins cette méthode nécessite comme unique paramètre un nombre de classes K prédéfini a priori par l’utilisateur.
Un deuxième algorithme proposé dans la littérature et qui est issu de l’algorithme K-means est l’algorithme Isodata [3]. L’avantage de ce dernier est qu’il permet de regrouper les pixels sans connaître a priori le nombre exact de classes présentes dans l’image. Ce nombre pourra être modifié au cours des itérations et pouvant aller au delà du nombre introduit par l’utilisateur.
La Figure 1 présente le résultat obtenu de l’application de l’algorithme K-means et Isodata sur une image test où le nombre de classe K a été choisi arbitrairement. Sur cette image, nous remarquons qu’un mauvais choix de la valeur de K conduira à un résultat qui n’a pas de rapport avec l’image originale.
Figure 1: (a) l’image originale, (b) l’image classée par K-means avec K=3, (c) l’image classée par k-means avec K=5 et (d) l’image classée par Isodata.
D’autres algorithmes de « clustering » utilisants des approches de classification statistiques, expriment le problème de la classification en termes probabilistes, où la classe est supposée suivre une distribution spécifique dans l’espace.
Parmi ces différents algorithmes nous présentons :
1. l’algorithme EM (Expectation-Maximisation algorithm) permettant de trouver le maximum de vraisemblance des paramètres probabilistes lorsque le modèle dépend de variables latentes non observables. Les approches de segmentation couleur utilisant l’algorithme EM sont les premiers travaux de Yamazaki [4] et ceux de Carson et al. [5], où EM utilise l’information couleur et texture pour la recherche d’images dans une collection large et variée selon leur contenu. Wu et al. [6] utilisent l’algorithme EM pour déterminer les paramètres d’un modèle de mélange gaussien.
2. les approches basées sur la sélection des modèles comme le rapport de vraisemblance généralisé GLR (Generalized Likelihood Ratio). Le GLR est défini comme étant une approche à la résolution de problèmes de décision. Cette procédure consiste à associer à chaque hypothèse H une densité unique, parmi toutes les densités possibles, en prenant celle qui i
maximise la vraisemblance des données. El-Khoury et al. proposent une méthode de segmentation générique, qu’ils ont appliquées par la suite sur des contenus audio [7] et vidéo [8], basée sur le GLR en supposant que les densités de probabilité sont gaussiennes.
Récemment, l’approche bayésienne considérée aussi comme une approche de classification statistique est devenue l’approche la plus répandue et la plus exploitée dans la segmentation d’images microscopiques. Lezoray et al. [9] proposent une méthode de classification d’images couleurs qui combine l’algorithme K-means et la classification bayésienne.
4.1.2
Seuillage d’histogramme
Les méthodes de seuillage d’histogramme reposent sur l’exploitation de l’histogramme caractérisant la distribution spectrale de l’image. Elles ont pour objectif de segmenter une image en plusieurs classes différentes où chaque pic de l’histogramme est associé à une classe. Les approches existantes dans la littérature utilisent l’histogramme dans ces trois versions :
A. Seuillage d’histogramme tridimensionnel (3D)
Ces méthodes d’analyses d’histogramme se basent uniquement sur l’aspect vectoriel de la couleur. Généralement l’extraction des modes d’histogrammes 3D se fait à l’aide des techniques
issues de la morphologie mathématique qui sera présentée ultérieurement. Ces techniques de seuillage sont assez rares dans la littérature à cause du fort coût en temps de calcul et la complexité algorithmique qu’elles représentent.
Postaire et Zhang [10] développent une méthode de seuillage d’histogramme 3D, basée sur la morphologie mathématique, permettant d’obtenir une image binaire dans laquelle les centres des classes apparaissent. Dans [11] ils proposent d’augmenter la différence entre les classes en procédant par une étape de prétraitement de l’histogramme 3D basée sur un filtrage morphologique. Shafarenko et al. [12] utilisent l’algorithme de la ligne de partage des eaux pour segmenter des histogrammes 2D et 3D d’une image couleur suivie par une étape de post traitement.
B. Seuillage d’histogramme bidimensionnel (2D)
Afin de réduire la complexité d’analyse d’images couleurs dans l’espace 3D, de nombreux auteurs n’hésitent pas à ignorer l’un des trois plans chromatiques et procèdent de façon à avoir une vue partielle de la corrélation entre les différentes composantes de l’espace mesuré.
Lezoray et al. [13], proposent une méthode de seuillage 2D dans l’espace couleur RVB, en combinant deux composantes telles que RV, RB, VB. L’histogramme de chaque composante est simplifié par des opérations d’érosion morphologique pour extraire les pics significatifs de l’histogramme 2D. Dans [14], ils proposent de filtrer l’histogramme 2D qui sera ensuite reconstruit par un processus de reconstruction morphologique. À partir de cet histogramme régularisé, les classes dominantes sont recherchées par l’intermédiaire de l’algorithme K-means.
C. Seuillage d’histogramme monodimensionnel (1D)
Les méthodes d’analyse d’histogramme monodimensionnel sont les méthodes les plus utilisées en raison de leur capacité à réduire la complexité d’un traitement dans l’espace couleur 3D ou dans l’espace 2D. Cette approche est une approche marginale qui considère l’histogramme de chaque composante couleur séparément sur lequel des seuils sont calculés. Les résultats sont combinés pour obtenir l’image finale classifiée selon plusieurs méthodes comme l’intersection, la théorie de l’évidence [15] ou la théorie bayésienne3
.
Lezoray et al. [16] procèdent à une approche marginale qui tend à calculer les valeurs des seuils en divisant l’histogramme de chaque composante en différentes classes. Ces seuils sont obtenus par l’application de l’algorithme de la ligne de partages des eaux qui sera détaillé dans la suite de ce travail. Busin et al. [17] proposent une méthode de seuillage multidimensionnelle qui agit en sélectionnant différents espaces couleurs dans lesquels les modes de l’histogramme 1D correspondent effectivement à des régions dans l’image.
L’avantage de ces différentes approches de classification des pixels est qu’elles sont non supervisées et qu’elles sont largement exploitées en littérature. En revanche, elles souffrent du fait que l’information spatiale est négligée ainsi que la non prise en compte de la corrélation entre les différentes composantes de l’espace couleur dans le cas de segmentation marginale. Par conséquent, des étapes de réajustement suivent souvent ces méthodes de classification.
4.2
La segmentation basée sur l’analyse des caractéristiques
spatiales
Toutes les méthodes de segmentation qui ont été présentées ci-dessus agissent selon l’information spectrale. Cependant une deuxième information spatiale semble être un critère indispensable pour améliorer la qualité de la segmentation.
Parmi les diverses définitions que l’on peut trouver dans la littérature, on peut retenir que la segmentation basée sur l’analyse des caractéristiques spatiales ou segmentation en régions s’exprime de la manière suivante [18] :
N n 1Rn I , , , ,..., 1 N pxy1 pxy2 n n n un chemin de pxy1 à pxy2 dans n vrai R P N n 1,..., , R n n R m n , voisin de Rm PR Rn Rm fauxLa première condition spécifie d’abord que l’ensemble de régions segmentées
N n n R 1 doit constituer l’image entière I. La deuxième condition implique que l’ensemble des pixels
constituants une même région segmentée doit rester toujours connexe. L’hypothèse de connexité des régions fait que les algorithmes prennent généralement en considération le voisinage des points. La troisième et la quatrième condition montrent que chaque région doit être homogène en ce qui concerne un prédicat d’uniformité noté P et que deux régions adjacentes ne peuvent pas R
être fusionnées en une seule vérifiant ce même prédicat P . La vérification de ces conditions est R
une étape nécessaire pour qu’une partition d’une image I soit une segmentation.
Le résultat de cette segmentation est une image « d’étiquettes » dans laquelle chaque pixel est affecté d’un numéro correspondant au numéro de la région à laquelle il appartient dans l’image
initiale. À partir de cette image « d’étiquettes » et de l’image originale il est possible de déterminer les divers attributs photométriques et géométriques de chaque région.
Les algorithmes de segmentation basés sur l’analyse des caractéristiques spatiales existants dans la littérature sont divisés en trois grandes catégories :
- la segmentation par croissance de régions. - la segmentation par division-fusion. - autres approches.
4.2.1
La segmentation par croissance de régions
Ce type de segmentation consiste à sélectionner en premier les germes des régions qui correspondent généralement à des pixels. Ensuite, des régions sont construites en ajoutant successivement à chaque germe les pixels qui lui sont connexes et qui vérifient un critère de similarité colorimétrique. La littérature en traitement d’images en niveau de gris est riche en méthodes de segmentation par croissance de régions [19] [20]. Pour les images couleurs, la plupart des stratégies sont extensibles des méthodes d’images en niveau de gris.
Chassery et Garbay [21] isolent les régions de l’image selon des critères de forme et de couleur. Un pixel est fusionné avec une région candidate si la mesure de différence colorimétrique est inférieure à un certain seuil. Carron et al [22] proposent des critères de fusion des pixels aux régions fondés sur des règles floues4. Tremeau et Borel [23] proposent différents critères d’homogénéité dans l’espace RVB. D’abord, ils génèrent un certain nombre de régions par le processus de croissance de régions et ensuite ils fusionnent toutes les régions qui ont la même distribution colorimétrique. Par conséquent, les régions ont des couleurs homogènes mais elles sont disconnectées.
De nombreux algorithmes de segmentation existants dans la littérature combinent le processus de croissance de régions avec la morphologie mathématique [24] [25] [26]. Ils procèdent d’abord à l’extraction des marqueurs par des opérations de morphologie mathématique (sélection des minima du gradient couleur, ouverture et fermeture morphologique…). Ensuite, un processus de croissance de régions basé sur la ligne de partage des eaux prend lieu à partir de ces marqueurs diminuant ainsi le nombre des régions segmentées.
Meyer [25] propose un algorithme de segmentation d’images couleurs qui consiste en une croissance de régions à partir de marqueurs identifiant l’intérieur des régions. Ainsi un pixel est fusionné avec la région la plus proche (i.e. similaire) en se basant sur le calcul d’une distance qui représente la différence de couleur entre ce pixel et les régions voisines. D’autres recherches se
basant sur le choix de cette distance ont été menées ultérieurement. Belhomme et al. [27] modélisent cette distance de similarité entre le pixel et la région voisine de la manière suivante :
R p p R p i i i i i. . , , 1 (7)
où les i p représentent critères locaux extraits de l’image et i p,R représentent m critères globaux résultants des comparaisons statistiques entre un point pet une de ses régions voisinesR. Avec i coefficient de pondération qui vérifie :
1 1 m i i (8)
Lezoray et al. [9] modifient cette fonction de distance en introduisant l’information locale donnée par le gradient couleur représentant les transitions entre les couleurs, et l’information globale donnée par une mesure de la couleur moyenne des régions traduisant l’homogénéité globale des ces dernières. Cette distance est modélisée par :
p
I
p
I
R
I
R
p
CCC ccc ccc 3 2 1 3 2 1 3 2 11
,
(9)avec
I
C1C2C3R
le vecteur qui donne la couleur moyenne de la région R pour l’image I dansl’espace C1C2C3, IC1C2C3 p le vecteur qui donne la couleur du point p dans l’image I et
p ICCC
3 2
1 le gradient couleur au point p.
est un coefficient de pondération qui permet de modifier la relation et l’influence des critères globaux et locaux durant le processus de croissance.
L’avantage de la méthode de croissance de régions est de préserver la forme de chaque région de l’image. Cependant une mauvaise sélection des pixels de départ, un choix de critère de similarité, aussi qu’un ordre mal adapté selon lequel les pixels voisins sont examinés, peuvent entraîner des phénomènes de sous segmentation ou de sur segmentation.
4.2.2
La segmentation par division fusion
Cette méthode est caractérisée par la division au préalable de l’image en régions homogènes disjointes qui respectent des critères globaux. Puis elle consiste à fusionner des régions adjacentes qui vérifient des critères locaux (exemple le critère d’homogénéité colorimétrique).
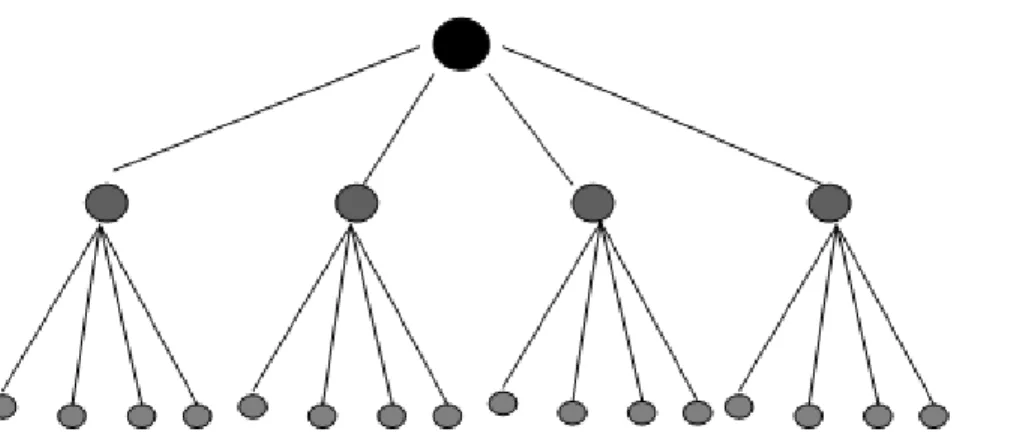
Nous détaillons trois structures de données permettant d’effectuer cette approche : 1. Le tétra-arbre
2. Le diagramme de Voronoï
3. Le graphe d’adjacence des régions
4.2.2.1 Le tétra-arbre
Le tétra-arbre [28] est une structure de données très commune de part sa simplicité et d’autre part son faible temps de calcul. Il est une arborescence dont la racine est l’image toute entière et dont chaque nœud parent (sauf les nœuds terminaux) possède exactement 4 fils. Il est défini de manière récursive: l’image est partagée d’abord en quatre blocs. À chacun de ces blocs est ensuite associé un nœud fils de la racine. Puis le processus de découpage en quatre quarts est itéré pour chacun des fils sans chevauchement des blocs. L’analyse récursive s’arrête lorsque chaque sous-bloc respecte un prédicat d’homogénéité. Après cette phase de division des petites régions, certains blocs adjacents présentent des caractéristiques colorimétriques identiques d’où la nécessité de les fusionner. Cette fusion s’arrête lorsqu’il n’existe plus de couple qui respecte le prédicat de fusion. Ce processus est représenté sur la Figure 2.
Figure 2: processus de division de l’image I utilsant le téra-arbre
Coutance [29] segmente les images couleurs en régions par l’analyse du tétra-arbre, proposée par Horowitz et Pavlidis [28] dans le cadre de la segmentation d’images en niveaux de gris. Il calcule la somme des variances des composantes Rouge, Vert, et Bleu des pixels d’un bloc, si cette somme est supérieure à un seuil le processus de division d’un bloc en quatre est entamé. Deux blocs adjacents sont fusionnés si la distance entre les couleurs moyennes des pixels de
chacun de ces blocs est inférieure à un seuil. Après la phase de fusion, les blocs qui ont une petite taille sont fusionnés avec le bloc voisin le plus proche au sens colorimétrique.
L’inconvénient majeur du tétra-arbre réside dans la rigidité du découpage carré qu’il impose. Il s’avère incapable à s’ajuster aux structures réelles des régions présentes dans l’image.
4.2.2.2 Le diagramme de Voronoï
L’approche par diagramme de Voronoї s’inscrit dans un processus itératif de divisions et de fusions et peut être considérée comme une amélioration de la segmentation par analyse du tétra-arbre. Cette approche génère une partition de l’image à partir de germes. À chaque germe est associé une région de Voronoï constituée par l’ensemble de pixels les plus proches de ce germe. La décomposition de l’espace ainsi obtenue est connue sous le nom de partition de Voronoï.
Le diagramme de Voronoï peut être défini de la manière suivante :
1. Points, sites ou germes : c’est un ensemble, P composé de n points pide l’espace 2 , n i p P i , 1... 2 (10) 2. Arête : repérée par deux points d’appui x et y ;
3. Région de Voronoï : on appelle polygone de Voronoï associé au siteP , la région i vor Pi
(chaque région étant l’ensemble de points x,y les plus proches à un point deP) telle que chaque point de P a pour plus proche siteP : i
4. Vor Pi x R ,d x,Pi d x,Pj Pj P Pi 2
(11) où d représente la distance Euclidienne.
L’union de toutes les régions de Voronoï sur le support image définit le diagramme de Voronoï. Il possède les propriétés suivantes :
- chaque sommet dans le diagramme est le point de rencontre de trois arêtes de Voronoï;
- pour chaque sommet S du diagramme de Voronoï, le cercle passant par les trois points voisins à ce sommet, ne contient aucun autre point de P;
Nous définissons aussi la triangulation de Delaunay qui représente le dual du digramme de Voronoï (Figure 3). Ceci est obtenu en reliant par un segment toutes les paires des sites dont les cellules de Voronoï correspondantes sont adjacentes, c’est-à-dire séparées par une arête de Voronoï.
Cette triangulation est caractérisée par le fait : a. qu’elle est unique,
b. qu’elle est complète,
c. et que le cercle passant par les trois sommets d’un même triangle ne doit contenir aucun site.
Figure 3: (a) l’image test, (b) diagramme de Voronoi et (c) la triangulation de Delaunay. Arbeláez et Cohen [30] proposent une méthode de segmentation d’images couleurs qui consiste à modéliser la segmentation comme une partition de Voronoї généralisée de son domaine. Dans ce contexte, ils cherchent à définir une distance appropriée entre points de l’image en considérant l’information fournie par la couleur, et à choisir un ensemble des germes adéquats pour cette tâche.
4.2.2.3 Le graphe d’adjacence des régions
La fusion des régions ne s’opère pas nécessairement après un algorithme de division de l’image, mais peut être accomplie après un algorithme de segmentation ayant provoqué une sur segmentation. Ces approches de fusion se basent généralement sur l’analyse du graphe d’adjacence des régions ou RAG (Region Adjacency Graph). Les régions y sont représentées par les nœuds du graphe et l’information d’adjacence entre régions est symbolisée par les arêtes.
Un graphe G est un couple G N,A où N est un ensemble fini de nœuds, A l’ensemble
des arêtes inclus dans un sous-ensemble N N et A Ni est l’ensemble de tous les nœuds
Définition 1: si G N,A est un graphe d’adjacence, deux nœuds N et i Nj de N sont dits
adjacents (NiANj où Ni,Nj A) si A(Ni) Nj ).
Définition 2: soit R une partition de N formant une région. Le graphe non orienté R,A est le graphe d’adjacence des régions deR modélisant les propriétés de voisinage entre celles ci.
Ce processus est représenté dans la Figure 4. Sur ce graphe, des régions adjacentes vérifiant certains critères de similarité spatiale ou spectrale peuvent fusionner afin de résoudre le problème de la sur segmentation. Une description plus précise sur la théorie des graphes est donnée en annexe A.
Figure 4: (a) image d’étiquettes et (b) graphe d’adjacence de régions
4.2.3
Autres approches
On trouve également différentes autres méthodes dans la littérature :
4.2.3.1 Les méthodes utilisant les champs de Markov
Ces méthodes considèrent une image comme une réalisation d’un champ de variables aléatoires. C’est un processus stochastiques [31] qui permet de prendre en compte les relations de voisinage entre les pixels. Il est caractérisé par la propriété suivante: La probabilité conditionnelle d’un pixel donné est fonction de son voisinage et non pas de l’image entière.
Tupin et al. [32] développent une méthode de segmentation markovienne supervisée d’images radar à haute résolution. Cette méthode utilise les distributions de Fisher [33] dont les paramètres
ont été calculés sur des échantillons où les classes sont sélectionnées manuellement. Dans [34], ils mettent en place une méthode de classification non supervisée en utilisant une méthode d’estimation des paramètres.
L’intérêt de l’utilisation des champs de Markov en segmentation d’images est de mieux modéliser l’image. Cependant les enjeux majeurs en analyse d’images, fondée sur un modèle probabiliste tel que les champs Markoviens, figurent dans le choix du modèle et l’estimation des paramètres d’optimisation.
4.2.3.2 Réseaux de neurones
Les réseaux de neurones sont souvent utilisés pour la segmentation d’images couleurs. Les différences entre les travaux se situent généralement au niveau des réseaux utilisés et des paramètres d’entrée.
Moudache et al. [35] proposent une méthode de segmentation d’images couleurs microscopiques en combinant les approches de morphologie mathématique et de réseaux de neurones. Nguyen [36] présente une méthode de segmentation utilisant une caractéristique invariante (couleur de la peau) pour accélérer la vitesse du système de détection de visage basée sur les réseaux de neurones.
Ces méthodes peuvent ne pas être robustes pour certaines applications. D’une part, elles sont basées sur une phase nécessaire d’apprentissage pour identifier l’extraction des caractéristiques. D’autre part elles souffrent d’un manque de tests statistiques rigoureux pour justifier l’ajout ou le rejet de certaines caractéristiques.
4.3
La segmentation basée sur la morphologie mathématique
La morphologie mathématique est une théorie d’analyse des structures spatiales dont les premiers concepts ont été introduits par Serra [40] pour étudier la forme et la structure des objets dans l’image. Les outils de morphologie mathématique proposés ont été développés au départ pour le traitement d’images binaires en faisant appel à la morphologie mathématique ensembliste. Leur utilisation a été ensuite étendue aux images en niveaux de gris : on parle à ce moment, de morphologie mathématique fonctionnelle. Désormais, certains opérateurs fonctionnent sur les images couleurs comme la ligne de partage des eaux.
La ligne de partage des eaux (LPE) constitue un des outils de base pour la segmentation d’images par morphologie mathématique. En premier temps, cette technique a été utilisée pour segmenter les images en niveau de gris5. Puis, son utilisation a été étendue aux images couleurs avec les travaux de Meyer [25] ouvrant ainsi une nouvelle voie dans le traitement d’images
couleurs. Dans ce paragraphe, nous allons d’abord présenter quelques opérateurs basiques de la morphologie mathématique. Ensuite nous décrivons la méthode de segmentation par la ligne de partage des eaux. Une description plus détaillée sur la morphologie mathématique sera présentée en annexe B.
4.3.1
Opérateurs basiques
Soit f une fonction f :E T qui décrit l’image où E est l’espace des points Rn , et T est l’échelle des niveaux de gris. L’ensemble des fonctions E T est écrit TE. Cet ensemble est ordonné par la relation , où f1 f2 signifie que pour tout p E nous avons f1 p f2 p .
Définition 3 (Dilatation): la dilatation d’une image f par une fonction structurante B:
E B T
B , est définie par :
q B q p f p B f B q (12)
Définition 4 (Erosion): l’érosion d’une image f par une fonction structurante B:
E B T
B , est définie par :
q B q p f p B f B q (13)
Définition 5 (Ouverture): l’ouverture d’une image f par un élément structurant B E est définie par :
B
B
f
B
f
(14)Cette opération supprime les parties claires de l’image qui ne peuvent pas contenir totalement l’élément structurant B.
Définition 6 (Fermeture): la fermeture d’une image f par un élément structurant B E est définie par :
B
B
f
B
f
(15)Dualement, cette opération supprime les parties sombres de l’image qui ne peuvent contenir totalement l’élément structurant symétrique.
Le Tableau 1 montre un exemple du processus d’application de ces opérations morphologiques sur une image test en niveau de gris. L’élément structurant est un disque de rayon 3.
Tableau 1 Résultat des quelques opérateurs morphologiques
Opérateur Fonction Résultat
Devient Erosion Calcule le minimum
des voisins de chaque pixel
Supprime les éléments qui sont plus petit que l’élément structurant.
Rétrécie les frontières.
Dilatation Calcule le maximum des voisins de chaque pixel
Supprime les trous à l’intérieur de l’objet qui ont une taille inférieure à l’élément structurant.
Elargir les frontières.
Ouverture Erosion suivie par une dilatation
Supprime les éléments qui sont plus petit que l’élément structurant.
Les frontières sont un peu modifiées à cause de la reconstruction.
Fermeture Dilatation suivie par une érosion
Supprime les trous dont la taille est inférieure à l’élément structurant.
Les frontières sont un peu modifiées à cause de la reconstruction.
Ouverture-Fermeture Ouverture suivie par une Fermeture
Supprime tous les éléments et les trous qui sont plus petits que l’élément structurant.
Les frontières sont un peu modifiées à cause de la reconstruction.
4.3.2
La ligne de partage des eaux
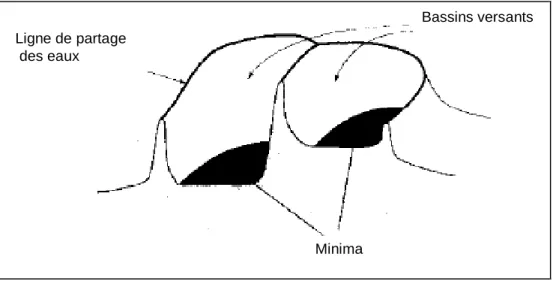
La ligne de partage des eaux utilise la description de l’image en terme géographique. L'idée de base est de considérer l’image comme un relief topographique, où la valeur du niveau de gris représente l’altitude. Ensuite, elle cherche les lignes qui séparent les différentes zones de l’image. La Figure 5 montre une image de cytologie et l’image d’altitude correspondante.
Figure 5: l’image de cytologie et l’image d’altitude correspondante.
Pour bien comprendre le fonctionnement de l’algorithme de ligne de partage des eaux, quelques définitions nous paraissent indispensables [41] :
Considérons une image I en niveau de gris dont le domaine de définition est 2
R
DI . I est
supposé prendre des valeurs discrètes (valeurs des niveaux de gris) dans l’intervalle 0,N ,N
étant un entier positif arbitraire.
p I p N R D I I 0,1,..., 2 (16)
Considérons G la trame qui peut être de n’importe quel type: une trame carrée en quatre ou
huit voisinages, ou bien une trame hexagonale en six voisinages. G est un sous ensemble deR2 R2.
Définition 7 : un chemin P de longueur entre deux pixels pet q dans une image I est un ensemble de 1 pixels p0,p1,...,p1,p tel que p0 p,p1 q,et i 1,, pi1,pi G.
Par la suite nous noterons P la longueur d’un chemin donné P ainsi que NG p
l’ensemble des voisins du pixel psuivant la trame G : NG P p 2, p,p G
.
Définition 8: un minimum M d’une image I d’altitude h est un plateau de pixels connectés
de valeur h à partir duquel il est impossible d’atteindre un point de moindre altitude sans avoir à
remonter (Figure 6): M q M p , tel que I q I p (17) p p p P 0, 1,..., tel que p0 p et p q (18) , 1 i tel que I pi I p0 (19)
Définition 9: Le bassin versant associé à un minimum M est l’ensemble des pixels pde D I
tel qu’une goutte d’eau tombant au point p suit le relief suivant la ligne de plus grande pente pour arriver enM (Figure 6).
Ligne de partage des eaux
Bassins versants
Minima
![Figure 7: construction des barrages aux endroits où les eaux provenant de deux minima se mélangeraient [41]](https://thumb-eu.123doks.com/thumbv2/123doknet/2123738.8331/43.918.176.741.598.872/figure-construction-barrages-endroits-eaux-provenant-melangeraient.webp)
![Figure 9: la zone d’influence géodésique de composantes connectées Bi à l’intérieur d’un ensemble A [41]](https://thumb-eu.123doks.com/thumbv2/123doknet/2123738.8331/45.918.264.682.296.751/figure-zone-influence-geodesique-composantes-connectees-bi-interieur.webp)
![Figure 10: itération entre Xh et Xh+1 [41]. 4.3.3 Image gradient](https://thumb-eu.123doks.com/thumbv2/123doknet/2123738.8331/46.918.240.705.276.508/figure-iteration-xh-xh-image-gradient.webp)