HAL Id: hal-01185361
https://hal.archives-ouvertes.fr/hal-01185361v2
Submitted on 6 May 2016
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Modélisation Hiérarchique de Données
Multidimensionnelles dans des Espaces Régulièrement
Décomposés
Olivier Guye
To cite this version:
Olivier Guye. Modélisation Hiérarchique de Données Multidimensionnelles dans des Espaces Régulièrement Décomposés : Tome 2 : Implémentation sur Calculateur (1988-1992). [Rapport de recherche] ADERSA. 1992. �hal-01185361v2�
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 1
MODELISATION HIÉRARCHIQUE
DE DONNÉES MULTIDIMENSIONNELLES
DANS DES ESPACES RÉGULIÈREMENT DÉCOMPOSÉS
TOME 2 : IMPLEMENTATION SUR CALCULATEUR
(1988 – 1992)
- 2015 -
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 2
Résumé du tome 2 :
Les travaux présentés ont été réalisés dans le cadre d'une étude à moyen terme initiée par le Centre Electronique de l'Armement, puis d'une étude amont lancée par la Direction de la Recherche et des Etudes Technologiques pour développer de nouvelles techniques en modélisation hiérarchique multidimensionnelle et pour les porter sur des architectures de calcul parallèle en vue du traitement futur de bases de données numériques massives. A la suite du premier tome présentant les principes de la modélisation, ce second tome détaille la manière de le logiciel de modélisation a été réalisé et porté sur différents calculateurs, notamment des calculateurs à architecture parallèle.
En complément à ces travaux, il détaille de nouveaux algorithmes qui ont été développés à la suite de ceux qui ont été présentés dans le tome précédent et qui sont décrits en pseudo-code en annexe du présent ouvrage:
− des opérateurs en géométrie constructive (construction de formes simples, opérations booléennes, manipulation de coupes);
− des transformées intégrales (épigraphe, hypographe, enveloppe convexe) ;
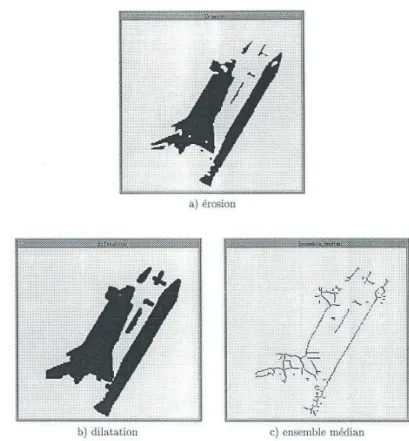
− transformations homotopiques (frontière, érosion, dilatation, ouverture, fermeture) ;
− transformations médianes (filtrage médian, amincissement, ensemble médian, dimension intrinsèque) ;
− des transformées de variétés (hyper-)surfaciques (filtrage médian, prolongement, ajustement polynomial d'une fonction étagée).
Le présent ouvrage se termine sur le portage du logiciel sur deux systèmes de calcul parallèle à mémoire répartie :
− un calculateur synchrone à petit grain ;
− un calculateur asynchrone à gros grain.
Mots-clés : modélisation hiérarchique multidimensionnelle, 2**k-arbres, géométrie
constructive, parallélotopes, polytopes, épigraphe et hypographe, enveloppe convexe, analyse topologique locale et régionale, variétés surfaciques, parallélisation, calculateurs parallèles synchrone et asynchrone à mémoire répartie
Domaines : Modélisation et simulation, Calcul parallèle, distribué et partagé, Algorithme et
structure de données, Géométrie algorithmique
Support : Conventions de recherche CELAR-ADERSA n°004/41/88 et DRET-ADERSA
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 3
Table des matières
Introduction ... 13
1. Présentation générale ... 15
2. Modèle de représentation ... 17
2.1. Nature des informations modélisées ... 17
2.2. Modèle de représentation des données ... 20
2.3. Paramétrisation des opérateurs de traitement ... 22
2.4. Enregistrement des modèles de représentation... 23
3. Gestion des données ... 27
3.1. Gestion mémoire ... 27 3.2. Session de travail ... 29 3.3. Structures de données ... 30 3.4. Opérateurs de base ... 31 4. Géométrie constructive ... 35 4.1. Modèle de programmation ... 35
4.2. Génération de l’arbre d’un ensemble de données ... 36
4.3. Opérations booléennes ... 37
4.4. Manipulation de coupes orthogonales aux axes ... 38
4.5. Hypercube de référence et calcul en limite inductive ... 40
5. Gestion de structures particulières ... 43
5.1. Vecteurs et génération de formes primitives... 43
5.2. Matrices de transformation géométrique ... 45
5.3. Parallélotopes et polytopes ... 47
6. Transformations géométriques ... 49
6.1. Transformé homographique d'un 2k-arbre ... 49
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 4 6.3. Transformations intégrales ... 52 6.3.1. Epigraphe et hypographe ... 52 6.3.2. Enveloppe convexe ... 53 6.4. Graphes d’intervisibilité ... 53 7. Analyse topologique ... 57 7.1. Voisinages ... 57
7.2. Recherche des adjacences ... 57
7.3. Analyse topologique locale ... 61
7.3.1. Frontière d'un ensemble ... 61
7.3.2. Transformations homotopiques ... 62
7.3.3. Transformations médianes ... 63
7.4. Analyse topologique régionale ... 65
7.4.1. Segmentation ... 65
7.4.2. Etiquetage des composantes connexes ... 66
7.4.3. Classification ... 68
8. Calcul d’attributs ... 71
8.1. Moments généralisés et représentation propre ... 71
8.2. Reconnaissance des formes et indice de similarité ... 74
9. Variétés surfaciques ... 77
9.1. Manipulation et transformation ... 77
9.2. Transformations médianes ... 78
9.3. Ajustement polynomial d’une fonction étagée ... 78
10. Implémentation sur calculateur parallèle ... 81
10.1. Compléments sur la structuration du logiciel sur calculateur séquentiel ... 81
10.1.1. Structure générale ... 81
10.1.2. Structure d'une commande ... 81
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 5
10.2. Méthodologie d'implantation ... 84
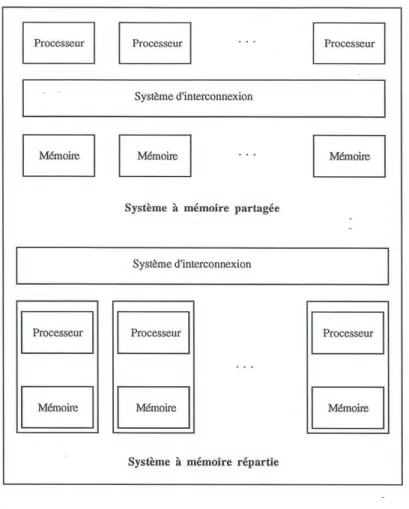
10.2.1. Architecture des calculateurs parallèles ... 84
10.2.2. Méthodologie suivie par la parallélisation ... 86
10.3. Calculateurs synchrones à mémoire répartie ... 88
10.3.1. Modèle de représentation des données en mémoire ... 88
10.3.2. Réécriture de l'algorithme général de résolution ... 89
10.4. Calculateurs asynchrones à mémoire répartie ... 90
10.4.1. Modèle de représentation des données en mémoire ... 90
10.4.2. Réécriture de l'algorithme général de résolution ... 92
10.5. Expérimentation sur deux calculateurs à mémoire répartie ... 94
10.5.1. Présentation des systèmes cibles ... 94
10.5.2. Spécificités d’implémentation ... 96
10.5.3. Conclusion sur ces expérimentations... 98
Annexes ... 101
A. Exemple de jeu de commandes ... 103
A.1. Description du jeu de commandes ... 103
A.2. Images affichées par le jeu de commandes ... 104
A.3. Liste des commandes appartenant au jeu ... 107
B. Liste des commandes du logiciel KDTREE... 115
C. Algorithmes complémentaires en modélisation hiérarchique ... 123
1. Calcul en limite inductive de l’arbre d’un ensemble de données ... 125
1.1. Création d'un arbre en limite inductive ... 126
1.2. Addition d’un vecteur non normalisé à un arbre ... 126
1.3. Calcul des nouvelles limites de l'espace ... 127
1.4. Extension de l'arbre aux nouvelles limites de l'espace ... 128
1.5. Test de l'inclusion du vecteur dans l'espace ... 129
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 6
1.7. Calcul de la diagonale de l'espace ... 130
1.8. Réunion de deux arbres en limite inductive... 131
1.9. Intersection de deux arbres en limite inductive ... 133
1.10. Exclusion de deux arbres en limite inductive ... 133
1.11. Différence de deux arbres en limite inductive ... 133
1.12. Calcul des nouvelles limites de l'espace ... 134
2. Intégration et dérivation d’ensembles ... 135
2.1. Calcul de l'hypographe d'un arbre le long d'une des dimensions de l'espace de modélisation 136 2.2. Parcours d'un arbre avec régénération des nœuds minimaux selon la direction de génération ... 137
2.3. Calcul de l'épigraphe d'un arbre le long d'une des dimensions de l'espace de modélisation ... 139
2.4. Parcours d'un arbre avec régénération des nœuds maximaux selon la direction de génération ... 140
2.5. Remplissage de la frontière d'un objet ... 142
3. Enveloppe convexe d’un ensemble ... 143
3.1. Calcul de l'enveloppe convexe d'un ensemble... 144
3.2. Initialisation de la recherche des enveloppes inférieure et supérieure relativement à une direction donnée ... 146
3.3. Recherche des points appartenant à l'enveloppe inférieure ou supérieure d'un ensemble, orthogonalement à une direction de l'espace ... 147
3.4. Calcul du recouvrement des enveloppes inférieure et supérieure par des segments convexes ... 149
3.5. Digitalisation d'un segment convexe... 151
3.6. Evaluation de la position d'un segment par rapport à un bloc ... 153
3.7. Calcul des centres et du diamètre des fils de la racine ... 154
3.8. Division d'un bloc en deux ... 155
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 7
4. Analyse des adjacences ... 157
4.1. Recherche des
d
1-adjacences sur les objets de l'espace... 1584.2. Recherche des
d
1-adjacences selon un vecteur de symétrie donné... 1594.3. Recherche des
d
∞-adjacences sur les objets de l'espace ... 1614.4. Recherche des
d
∞-adjacences selon un vecteur de symétrie donné ... 1625. Transformées homotopiques ... 165
5.1. Mise à blanc des faces de l'hypercube unitaire ... 165
5.2. Mise à blanc des points appartenant à l'une des faces de l'hypercube unitaire ... 166
5.3. Calcul de la
d
1-frontière d'un ensemble ... 1675.4. Recherche et marquage des nœuds
d
1-frontière de l'ensemble ... 1685.5. Calcul de la
d
∞-frontière d'un ensemble... 1695.6. Recherche et marquage des nœuds
d
∞-frontière de l'ensemble ... 1695.7. Erosion selon
d
1 des objets de l'espace ... 1705.8. Recherche et marquage des nœuds
d
1-frontière à supprimer ... 1715.9. Changement de couleur des nœuds marqués dans un arbre ... 173
5.10. Erosion selon
d
∞des objets de l'espace ... 1745.11. Recherche et marquage des nœuds
d
∞-frontière à supprimer ... 1745.12. Dilatation selon
d
1 des objets de l'espace ... 1755.13. Recherche et marquage des nœuds
d
1-exo-frontière à créer ... 1765.14. Dilatation selon
d
∞des objets de l'espace ... 1775.15. Recherche et marquage des nœuds
d
∞-exo-frontière à créer ... 1775.16. Ouverture selon
d
1 des objets de l'espace ... 1785.17. Fermeture selon
d
1 des objets de l'espace ... 178Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 8
5.19. Fermeture selon
d
∞des objets de l'espace ... 1786. Transformées médianes ... 179
6.1. Filtrage médian selon
d
1des objets de l'espace ... 1806.2. Morcellement de la
d
1-frontière et de lad
1-exo-frontière d'un ensemble ... 1806.3. Recherche et morcellement des nœuds
d
1-frontière etd
1-exo-frontière de l'ensemble 182 6.4. Marquage des nœuds à modifier pour le filtrage médian selond
1 ... 1836.5. Recherche et comptage des
d
1-adjacences sur les nœuds à filtrer ... 1846.6. Changement de la couleur de la frontière et de l'exo-frontière, en fonction de la couleur majoritaire de leurs voisins ... 186
6.7. Filtrage médian selon
d
∞des objets de l'espace ... 1876.8. Morcellement de la
d
∞-frontière et de lad
∞-exo-frontière d'un ensemble ... 1876.9. Recherche et morcellement des nœuds
d
∞-frontière etd
∞-exo- frontière de l'ensemble 187 6.10. Marquage des nœuds à modifier pour le filtrage médian selond
∞ ... 1876.11. Recherche et comptage des
d
∞-adjacences sur les nœuds à filtrer ... 1876.12. Calcul de l'ensemble médian d'un objet ... 188
6.13. Amincissement d'un objet de l'espace ... 188
6.14. Evaluation du degré de connexité des points frontière avec le fond... 189
6.15. Evaluation du degré de connexité des points frontière selon une direction ... 190
6.16. Suppression des points frontière à gauche faiblement connexes avec le fond ... 192
6.17. Suppression des points frontière à droite faiblement connexes avec le fond ... 193
6.18. Calcul de la dimension intrinsèque d'un ensemble ... 194
6.19. Evaluation de la dimension intrinsèque des points de l'ensemble ... 194
6.20. Evaluation du degré de connexité des points de l'ensemble ... 195
6.21. Calcul de la dimension intrinsèque des points de l'ensemble ... 197
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 9
7.1. Conversion d'un 2K-arbre en pyramide ... 200
7.2. Conversion d'une pyramide en 2K-arbre ... 202
7.3. Extraction du support d'une pyramide ... 203
7.4. Coloriage d'un 2K-arbre ... 204
8. Transformées appliquées aux fonctionnelles d’une pyramide ... 205
8.1. Minimum d'une pyramide ... 206
8.2. Maximum d'une pyramide ... 207
8.3. Calcul du centre et de la dispersion d'une pyramide ... 208
8.4. Mise à l'échelle d'une pyramide ... 209
9. Transformées médianes d’une pyramide ... 211
9.1.
d
1-prolongement d'un ensemble discret ... 2129.2.
d
1-expansion d'un ensemble discret par filtrage médian ... 2129.3. Recherche des couleurs des
d
1-voisins de la frontière ... 2129.4. Recherche des couleurs des
d
1-voisins de la frontière selon un vecteur de symétrie donné 213 9.5. Affectation aux points de la couleur de leur voisin majoritaire ... 2149.6. Calcul de la valeur présentant le maximum d'occurrences dans une liste ... 215
9.7.
d
∞-prolongement d'un ensemble discret ... 2169.8.
d
∞-expansion d'un ensemble discret par filtrage médian ... 2169.9. Recherche des couleurs des
d
∞-voisins de la frontière ... 2169.10. Recherche des couleurs des
d
∞-voisins de la frontière selon un vecteur de symétrie donné 216 9.11. Filtrage médian selond
1 d'une pyramide ... 2179.12. Recherche des couleurs des
d
1-voisins de l'intérieur ... 217 9.13. Recherche des couleurs desd
1-voisins de l'intérieur selon un vecteur de symétrie donnéModélisation Hiérarchique Multidimensionnelle : Tome 2 Page 11
Table des illustrations
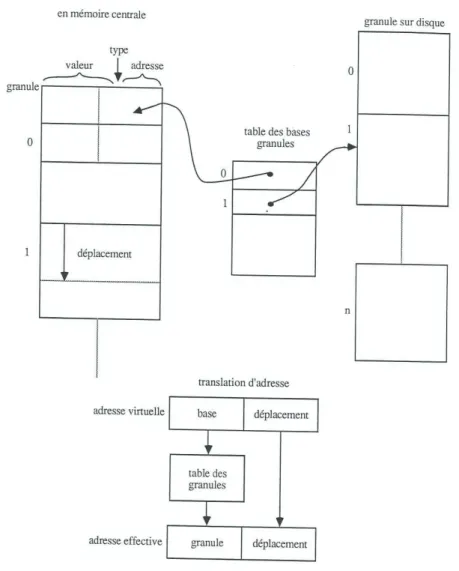
Figure 1 : Gestion de doublets en mémoire virtuelle ... 27
Figure 2 : Image tridimensionnelle d’un relief numérique ... 40
Figure 3 : Coupes parallèles réassemblées par opérations booléennes ... 40
Figure 4 : Projections extraites d’un relief décoré avec sa planimétrie ... 54
Figure 5 : Vecteur de coupe et visibilité au-dessus d’une ligne de visée ... 54
Figure 6 : Transformées homotopiques d’une image binaire ... 64
Figure 7 : Image multispectrale ... 68
Figure 8 : Arbre radiométrique et image pseudo-colorée ... 68
Figure 9 : Image d’une composante connexe ... 74
Figure 10 : Arbre des composantes propres et son enveloppe convexe ... 74
Figure 11 : Structure en anneau de la bibliothèque de traitements ... 83
Figure 12 : Architectures de calcul parallèle ... 85
Figure 13 : Méthodologie de parallélisation ... 87
Figure 14 : Implémentation du logiciel sur architecture asynchrone à mémoire répartie ... 91
Figure 15 : Adaptation de la mémoire virtuelle dans un système à mémoire répartie ... 92
Figure 16 : Tâches actives sur un processeur d’une architecture asynchrone ... 92
Figure 17 : Réseau Oméga réentrant connectant 8 processeurs ... 97
Figure 18 : Comparaison des approches utilisées sur les deux systèmes à mémoire répartie ... 99
Figure 19 : Image originale ... 104
Figure 20 : Filtrages ... 105
Figure 21 : Image d’une composante ... 106
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 13
Introduction
Ce document présente la manière avec laquelle le logiciel de modélisation hiérarchique de données multidimensionnelles a été réalisé et porté sur différents calculateurs, notamment des calculateurs à architecture de calcul parallèle.
Il décrit comment ont été implémentées les opérations décrites dans le tome précédent et quels sont les opérateurs complémentaires qui ont été conçus pour disposer d’un ensemble cohérent de fonctions permettant de prétraiter, d’analyser et de résoudre des problèmes par raisonnement géométrique.
En prétraitement de données, un effort particulier a été porté sur l’analyse topologique dans le but de généraliser les fonctions de filtrage proposées en morphologie mathématique. La première version du logiciel a été écrite en langage de programmation Fortran IV pour pouvoir être employée sur les calculateurs scientifiques disponibles à l’époque: il a été nécessaire de simuler dans ce langage les mécanismes permettant de créer des appels récursifs de fonctions et de procédures ainsi que des structures de données à simple ou double chainage pour manipuler des listes, des piles, des files et des arbres binaires. Ces mécanismes sont décrits en partie ci-dessous car ils sont indispensables à l’implémentation des algorithmes décrits en annexe de ces documents.
Enfin, il est exposé comment le logiciel a été porté sur calculateur parallèle pour prendre en compte les besoins en matière de traitement de bases de données numériques massives. Les travaux de parallélisation du logiciel ont été réalisés avec le support de la Direction de la Recherche et des Etudes Technologiques (convention DRET-ADERSA n°90/34/106) et ont été menés sur deux systèmes de calcul :
− un calculateur synchrone à mémoire répartie, la CONNECTION MACHINE 2 du constructeur THINKING MACHINES;
− un calculateur asynchrone à mémoire répartie, le T.NODE du fabricant TELMAT INFORMATIQUE.
En effet, depuis sa création ADERSA a créé et développé des compétences en matière de calcul parallèle ; notamment avec le Pr Claude Timsit qui fut un pionnier dans le domaine avec la mise au point du premier calculateur parallèle synchrone en France, nommé PROPAL, et qui a reçu pour ses travaux la médaille de bronze du CNRS en 1978.
Il faut conserver à l’esprit que si le logiciel a été dénommé KDTREE, il diffère de celui développé par J. L. Bentley par le fait que l’espace est régulièrement décomposé et que si le terme de pyramide est employé pour désigner un arbre valué, cela ne correspond pas au sens classique d’un pyramide où toutes les branches sont complètement développées jusqu’à leur précision de construction.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 14 Si ce logiciel a subi plusieurs migrations d’écriture allant du Fortran IV au langage C ANSI, il n’existe plus aujourd’hui : seuls demeurent les algorithmes rédigés en pseudo-code que l’on retrouve en annexe de ces deux premiers tomes. Dans leur rédaction il a été utilisé une terminologie tridimensionnelle pour alléger l’écriture de ces algorithmes ; mais il faut bien conserver à l’esprit que ceux-ci s’applique à des ensembles de données appartenant à des espaces de dimension quelconque (mais entière et finie). Le lecteur trouvera dans cette première partie un glossaire qui réunit et décrit l’ensemble des termes qui sont employés dans les trois tomes du présent ouvrage.
[1] O. Guye, K. Mouton. Recursive Parallel Computing with Hierarchical Structured Data on T.Node Computer. Euro Courses – Computer and Information Science, Vol. 3, Eds : D. Hiedrich and J. C. Grossetie. KLUWER Academic Publishers, 1991.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 15
1. Présentation générale
Le logiciel KDTREE est un logiciel de modélisation multidimensionnelle de données de nature volumique (ou hyper-volumique). Sa conception et son développement ont bénéficié du soutien de la Délégation Générale à l'Armement.
Il vise un large éventail de domaines d'application et repose sur un principe de résolution de problèmes : le paradigme "diviser pour conquérir" dont on sait qu'il fournit une borne optimale en temps de traitement et en encombrement mémoire pour une certaine classe de problèmes. Le paradigme est le suivant : il consiste à diviser un problème qu'on ne peut résoudre directement en sous-problèmes et à itérer cette démarche jusqu'à ce que tous les problèmes soient résolus. Des auteurs prestigieux ont attachés leurs noms à ces recherches, notamment en géométrie algorithmique et les résultats de certains de leurs travaux sont quotidiennement utilisés dans des systèmes de visualisation ou de reprographie.
En effet, le logiciel KDTREE a existé sous différentes versions, dont plusieurs ont fonctionné sur des calculateurs à architecture parallèle et ont permis de mettre en œuvre un parallélisme massif.
Dans ce document, on parlera de pyramides pour les arbres modélisant l'évolution d'une fonctionnelle relativement à son support : ce terme est impropre mais permet rapidement de dissocier :
− les arbres permettant de modéliser des ensembles de données volumiques (les 2k
-arbres au sens propre) ;
− les arbres servant à modéliser des variétés surfaciques (les pyramides improprement dénommées, car ce sont chez d’autres auteurs des arbres complets aux branches entièrement développées et que l'on abordera lors du chapitre consacré au parallélisme).
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 17
2. Modèle de représentation
2.1. Nature des informations modélisées
Le logiciel KDTREE permet de représenter des informations décrites dans un espace de dimension quelconque :
− le long d'une droite (informations monodimensionnelles) ;
− dans le plan (informations bidimensionnelles) ;
− dans l'espace (informations tridimensionnelles) ;
− dans un hyperespace de dimension supérieure.
Il permet de modéliser des informations numériques de deux natures différentes :
− des informations volumiques, en représentant la fonction caractéristique d'un jeu de données ;
− des informations surfaciques, en représentant la fonction étagée (constante par morceaux) associée à un jeu de données.
Supposons que l'on dispose d'un jeu de données appartenant à un espace de dimension k:
{
v j N}
V = j, =1,L, , où vjest un vecteur de coordonnées
(
kj)
j i j v v v1,L, ,L,
alors la fonction caractéristique de cet ensemble est la fonction d'appartenance :
{ } { }
0
,
1
:
v
→
δ
, telle queS
=
{
v
/
δ
( )
v
=
1
}
,c'est-à-dire, la fonction qui est vraie pour tous les points de l'ensemble V et fausse pour son complémentaire (encore appelé fond de l'espace) :
{
/ ( )=0}
= v v
S
δ
Ce mode de description correspond tout particulièrement aux données de nature volumique.
Tentons de définir maintenant une droite dans le plan, une surface dans l'espace, une hypersurface dans un hyperespace.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 18
{ } { }
(
)
:
v
f
v
f
→
,où
v
décrit le support de f et f(v)prend ses valeurs sur un ensemble de valeurs scalaires. Dans un second temps, on peut encore la représenter par sa fonction caractéristique :{
,
(
)
} { }
0
,
1
:
v
f
v
→
δ
décrivant un ensemble k+1 dimensionnel composé du support de la fonctionnelle auquel
v
appartient et de l'ensemble de valeurs scalaires sur lequel la fonctionnelle f(v) s'exprime.On revient alors à une représentation volumique pour des données de nature surfacique. Pour représenter de tels jeux de données, KDTREE se fonde sur une structure de description des données arborescente, dont chaque branche, encode un trajet particulier permettant d'atteindre un jeu de coordonnées dans l'espace de représentation.
Ce trajet permet d'atteindre un point particulier ou un sous-ensemble dans l'espace.
Lorsque celui-ci appartient à l'objet modélisé, ou au support de la fonctionnelle, le nœud terminal correspondant est colorié en noir, sinon en blanc pour le fond de l'espace.
Lorsque l'on modélise une fonction caractéristique, les nœuds ne sont pas valués.
A l'inverse, lorsqu'on représente une fonctionnelle, les nœuds sont valués avec la valeur prise localement par cette fonctionnelle.
Pour des données de nature surfacique, il est possible de passer d'un mode de représentation à l'autre, puis de revenir au mode antérieur.
Illustrons ces notions sur un exemple concret. Supposons que nous disposions d'un modèle numérique de terrain, celui-ci est couramment représenté par une matrice de données altimétriques régulièrement échantillonnées sur un réseau plan de coordonnées.
Par exemple, un modèle numérique terrestre est généralement représenté par une matrice d'altimétries calculées à partir du niveau de la mer et échantillonnées en latitude et longitude, c'est-à-dire dans un repère planisphérique (la Terre est sphérique, mais les coordonnées sont décrites de manière plane). C'est une représentation surfacique qui décrit la position de l'interface terre-atmosphère par rapport au niveau de la mer. La fonctionnelle est ici l'altimétrie.
Si nous nous intéressons qu'à ce seul interface où la fonctionnelle reste positive, le support de la fonctionnelle représente les terres émergées et le fond du planisphère les terres immergées. Ce sont des données de nature surfacique, car en un point du support, il n'existe qu'une donnée et une seule. Cette matrice d'altimétries se représente par un arbre bidimensionnel multivalué dont les nœuds seront colorés en noir pour les valeurs définies positives, c'est-à-dire les terres émergées et le fond en blanc pour décrire l'absence
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 19 d'informations au-dessus des mers et océans. Visualisée graphiquement, cette matrice se présenterait sous la forme d'une carte dont la coloration locale sera modulée par l'altitude du point courant sur le réseau de coordonnées planes (hypsométrie).
En ajoutant l'axe de la fonctionnelle aux deux premiers axes du support, on obtiendra une représentation volumique de la surface terrestre au-dessus des terres émergées. Visualisée graphiquement, la surface terrestre se présente alors sous la forme d'une nappe de couleur uniforme en sustentation à une altitude fixée, variant en fonction de la position du point observé. Il s'agit alors de la fonction caractéristique de la surface des terres émergées : un arbre tridimensionnel non valué permet de modéliser ces données.
Dans ce mode de représentation, on verra par la suite qu'il sera possible de reconstruire le relief présent sous cette surface, pour disposer du relief terrestre sous forme solide, puis comment réaliser l'opération inverse pour revenir à la représentation initiale. Ce relief pourra être lui-même colorié avec des informations auxiliaires, comme par exemple la nature des objets occupant le sol grâce aux données planimétriques associées aux données altimétriques.
Ainsi, le modèle de représentation que nous allons décrire s'intéresse à la modélisation d'ensembles de données numériques provenant d'une grande variété de problèmes scientifiques et techniques :
− analyse d'images planes (monospectrales, multispectrales) ;
− analyse d'images tomographiques ;
− reconstruction d'objets à partir de relevés tridimensionnels ;
− modélisation d'objets solides tridimensionnels ;
− modélisation d'environnements ;
− observation de systèmes évolutifs (en intégrant le temps comme une dimension de l'espace de représentation) ;
− cartographie ;
− observation de ressources terrestres ;
− analyse statistique de données ;
− gestion de bases de données numériques ;
− raisonnement géométrique;
− aide à la décision.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 20
Nom Fonction
KDCLAL KDDETZ
Coloriage d'un arbre altimétrique par un arbre planimétrique Détermination de l'altitude d'un point dans un arbre
2.2. Modèle de représentation des données
Le modèle de représentation est issu du principe de décomposition induit par le paradigme "diviser pour conquérir". Pour un ensemble de données numériques, on définit une boîte de forme donnée incluant cette population, puis on définit une procédure régulière de découpage permettant de diviser les boîtes en sous-boîtes et celles-ci à nouveau de manière itérative jusqu'à ce qu'on obtienne un résultat uniforme dans chacune des boîtes :
− soit la boîte est vide ou pleine pour une fonction caractéristique ;
− soit toutes les fonctionnelles sont définies et égales, ou aucune ne l'est pour une fonction étagée.
Comparé à un modèle de représentation cellulaire qui décrit exhaustivement l'espace contenant les données, dans un tel modèle, pouvoir conserver en paquets les données homogènes, permet d'introduire une fonction de compression dans le modèle de représentation.
D'autre part, le fait de diviser régulièrement une collection de données en sous-collections et d'itérer sur ce principe va produire une structure arborescente pour l'organisation des données : il s'agit donc d'un modèle hiérarchique de représentation.
Conserver de manière agrégée les sous-ensembles de données homogènes a pour conséquence le fait que les différentes branches de cette structure seront irrégulièrement développées : on parle alors d'arbres incomplets, mais la compression de l'information est à ce prix.
Considérons un ensemble de données scalaires réparties le long d'un axe et borné par un intervalle de valeurs. Observons le contenu de cet intervalle et si celui-ci n'est pas homogène, décomposons-le par le milieu en deux. Examinons à nouveau chacun des deux demi-intervalles et procédons à nouveau à une division en deux des intervalles qui n'apparaîtraient pas homogènes. Poursuivons ainsi, jusqu'à atteindre des données élémentaires s'il le faut. A l'issue de ce traitement, la collection de données scalaires sera représentée par un arbre binaire, c'est-à-dire dont tous les nœuds non terminaux auront deux fils.
Considérons maintenant une image binaire plane, elle peut être divisée régulièrement moitié par moitié selon les deux dimensions de son support, c'est-à-dire en quatre quadrants :
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 21
− nord-ouest ;
− nord-est ;
− sud-est ;
− sud-ouest.
Si les données de cette image ne sont pas homogènes pour tous les quadrants, il est possible de recommencer cette opération de division en quatre pour chaque quadrant mis en cause. En poursuivant jusqu'à la résolution de digitalisation de l'image, on produira un arbre quaternaire, c'est-à-dire dont tous les nœuds non terminaux auront quatre fils, pour représenter cette image.
Si la distance qui sépare les bornes selon chaque axe est la même, la boîte initiale et toutes ses divisées sont des ensembles carrés. C'est ce qui se produit lorsque les coordonnées des jeux de données, ont été normalisées.
Le même processus de construction peut s'appliquer à un objet tridimensionnel. Les quadrants se transforment en octants pour prendre en compte la dimension complémentaire et la structure produite est un arbre octernaire.
Ce processus de découpage se généralise à des ensembles de données de dimension quelconque k. Si les coordonnées sont normalisées, le cube initial se transforme en hypercube unitaire, celui-ci est divisé en 2k-ants et l'arbre est un 2k-arbre.
Le nombre de niveaux de découpage r fixe la précision de représentation, chacune des k
dimensions aura été discrétisée :
− si les données sont entières sur le sous-ensemble de N suivant
{
0,1,..., 2r −1}
;− si les données sont normalisées sur le sous-ensemble de Q ou R suivant
−
r r r2
1
2
...,
,
2
1
,
0
.Les données sont alors référencées :
− dans l'hypercube entier
{
r}
k 1 2 ..., , 1 , 0 − ;− dans l'hypercube unitaire
k r r r − 2 1 2 ..., , 2 1 , 0 .
En pratique, pour n'employer qu'une seule structure quelque soit la dimension de l'espace de modélisation, la procédure de découpage a été modifiée de manière à ne produire que des arbres binaires. On y parvient en découpant séquentiellement moitié par moitié les intervalles selon chaque dimension de l'espace.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 22 Ainsi, l'image binaire précédente est divisée en deux sous-images rectangulaires selon le premier axe, puis ces deux rectangles retrouvent leur forme de quadrants en divisant selon le second axe.
En trois dimensions les cubes se présentent alors de manière intermédiaire sous la forme de parallélépipèdes rectangles lors du processus de division séquentiel.
Cette opération revient à paginer l’hypercube unitaire
k r r r − 2 1 2 ..., , 2 1 , 0 sur le segment unitaire
−
kr kr kr2
1
2
...,
,
2
1
,
0
.On remarque alors que le volume de données manipulées sera directement proportionnel au produit de la dimension k de l'espace avec la précision d'analyse r le long de chaque axe.
Le temps de réponse des opérateurs de traitement sera directement affecté par la valeur de ce produit ; ainsi on ne pourra conserver un temps de réponse acceptable que sur des espaces de faible dimension à moyenne résolution et recourir à une faible résolution pour des espaces de moyenne dimension. Il serait délicat de modéliser des espaces de forte dimensionnalité par cette approche.
Ainsi selon la dimension de l'espace, un ensemble de données modélisé à la précision 8 comprendra au plus :
− 28, soit 256 éléments en dimension 1 ; − 216, soit 65 536 éléments en dimension 2 ; − 224, soit 16 777 216 éléments en dimension 3 ; − 232, soit 4 294 967 296 éléments en dimension 4.
Par contre 218, soit 262 144 éléments représentent un espace analysé à la précision: − 18 en dimension 1 ;
− 9 en dimension 2, soit encore un maillage 512 x 512 ;
− 6 en dimension 3, soit encore un maillage 64 x 64 x 64.
2.3. Paramétrisation des opérateurs de traitement
L'exécution des opérateurs de traitement est conditionnée par ces deux paramètres : la dimension et la précision.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 23 Il est possible de répartir ces opérateurs en deux classes :
− ceux qui permettent de construire des arbres modélisant des jeux de données ;
− ceux qui transforment ces arbres.
Il n'est pas nécessaire d'appliquer ces derniers à la même précision que celle qui a été employée pour générer les modèles de représentation initiaux.
Lorsqu'un opérateur est appliqué à une précision plus grossière que la précision de construction, le résultat est livré au sens de l'enveloppe supérieure : si l'on rencontre un nœud non terminal dans l'analyse de cet arbre, il sera traité comme un nœud terminal noir à cette précision. Ainsi en cas d'indéterminée, on prendra en compte la boîte englobante, à la précision de calcul demandée.
On procédera de la même façon pour un arbre valué : à chaque nœud non terminal, la valeur maximale des fonctionnelles des fils est enregistrée au niveau du nœud et ce sera cette valeur particulière qui sera prise en compte si l'on examine l'arbre à une précision intermédiaire. De cette manière, la fonctionnelle est approchée à cette précision par sa fonction semi-continue supérieure majorante.
A précision variable, les données de nature volumique sont modélisées par l'emboîtement des structures volumiques qui contiennent l'ensemble initial, et les données surfaciques par l'ensemble des fonctions étagées qui majorent le jeu de données initiales. Cette approche permet de préserver les ensembles compacts.
Parmi les opérateurs qui transforment les arbres, on trouvera un cas d'application un peu plus particulier, les transformations géométriques où l'on examine un arbre initial pour en générer un nouvel arbre ; dans ce cas on devra spécifier à la fois la précision à laquelle on analyse l'arbre d'origine et à quelle précision on souhaite construire l'arbre résultant. Le calcul à précision variable permet de mettre au point une application en expérimentant à précision grossière, à tester l'application à précision plus fine et à exploiter celle-ci de manière terminale à pleine précision sans remettre en cause les jeux de données acquises. On remarque aussi que si l'application doit être utilisée en temps contraint, on pourra trouver la valeur à fixer pour la précision de calcul afin de respecter de telle condition d'exploitation.
2.4. Enregistrement des modèles de représentation
Deux techniques sont employées sous le logiciel KDTREE pour enregistrer des arbres binaires valués ou non.
La première technique est fondée sur un système d'allocation séquentielle de données : les listes linéaires. Il s'agit d'un codage de l'arbre sur un alphabet constitué par les trois couleurs de base permettant de caractériser les nœuds :
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 24
− 2 pour les nœuds non terminaux (gris).
Si l'on visite l'arbre selon un parcours exhaustif, on produira un code d'arbre constitué par une séquence de 2, 1 et 0 qui suivront séquentiellement dans l'ordre selon lequel on aura rencontré chacun des nœuds appartenant à l'arbre.
Pour un même arbre, différente parcours sont envisageables selon que l'on privilégie ou non :
− l'ordre de filiation sur l'ordre d'aînesse des nœuds (en profondeur ou en largeur d'abord) ;
− l'ascendance sur la descendance (en montant ou en descendant).
Quelque soit le parcours employé, le nombre de nœuds visités reste le même. Les nœuds sont codés sur deux bits pour pouvoir produire des codes d'arbre compacts. En complément, les fonctionnelles sont enregistrées séparément pour les arbres valués, selon le même parcours mais uniquement pour les nœuds terminaux noirs.
Cette technique d'enregistrement des données n'est employée qu'en archivage de données sous le logiciel KDTREE : bien que les codes produits soient très compacts, il s'agit d'une structure de données à accès séquentiel pour laquelle il est nécessaire de parcourir l'ensemble de l'information pour accéder à une donnée isolée.
En phase de traitement, le logiciel KDTREE emploie une structure de données à accès plus rapide fondée sur l'allocation indexée des données : les listes chaînées. Celle-ci repose sur un système d'allocation dynamique et comporte une information de chaînage qui permet de lier les données les unes aux autres selon un ordre déterminé à l'avance.
Il aurait pu être envisagé de disposer d'un double système d'indexation permettant de gérer simultanément les deux principaux ordres de parcours d'un arbre. Seul l'ordre de filiation est explicitement géré sous le logiciel KDTREE grâce à des listes à simple chaînage, privilégiant ainsi les parcours en profondeur d'abord.
Ainsi pour coder un nœud non terminal sous forme indexée, il faudra :
− deux double-mots, comportant des informations de travail et les pointeurs vers les fils gauche et droit, pour un arbre binaire non valué ;
− trois double-mots pour gérer la fonctionnelle associée au nœud courant pour un arbre valué.
Grâce à l'emploi d'adresses auto-référentes pour les nœuds blanc et noir, pour coder un nœud terminal seul est nécessaire :
− un double-mot pour un arbre non valué ;
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 25 Nom Fonction KDWRAB KDRDAB KDWRPY KDRDPY
Transfert sur disque d'un arbre Récupération sur disque d'un arbre Transfert sur disque d'une pyramide Récupération sur disque d'une pyramide
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 27
3. Gestion des données
3.1. Gestion mémoire
Le logiciel KDTREE inclut ses propres fonctions de gestion de son espace mémoire. Celui-ci repose sur deux mécanismes de base :
− un système d'adressage virtuel ;
− un système d'allocation dynamique.
Le système d'adressage virtuel est construit sur un système de mémoire paginée. L'unité d'allocation mémoire est le double-mot, couple composé d'un poste valeur et d'un poste lien permettant de gérer l'ensemble de la mémoire libre sous la forme de liste chaînée.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 28 C'est un système d'allocation mémoire de longueur fixe, fonctionnant sans mécanisme de réorganisation des données («ramasse-miettes»). Les double-mots sont regroupés en granule-mémoire ou pages mémoire de longueur fixe, représentant l'unité d'extension de la mémoire permettant de satisfaire les demandes d'allocation qui ne peuvent être directement servies et l'unité d'échange mémoire - support de masse, lorsque la mémoire virtuelle est activée.
Celle-ci permet de gérer des ensembles de données qui ne tiendraient pas directement en mémoire physique du processeur, en s'aidant du support de masse présent sur le calculateur. Dans ce cas, les données en mémoire permanente sur disque représentent l'espace adressable par le logiciel et seul un sous-ensemble de ces données est présent à un instant en mémoire volatile du processeur de traitement.
Mémoire volatile et mémoire permanente échangent leurs informations en fonction des besoins du traitement.
La localisation des données en machine est réalisée par l'entretien d'une table de présence des granules en mémoire. Un mécanisme de translation d'adresse permet de substituer dans le champ d'adressage des granules une information virtuelle par une information réelle pour connaître leurs localisations effectives.
La réécriture en mémoire permanente est différée jusqu'à la fin de l'exécution d'un traitement, quand celle-ci n'est pas nécessaire, afin de conserver la cohérence des données en mémoire volatile avec celles présentes sur le support permanent.
Pour des applications critiques devant s'exécuter dans des conditions de sûreté de fonctionnement avancées, le mécanisme de gestion en mémoire virtuelle est doublé d'un système d'enregistrement miroir permettant de doubler la copie des données en mémoire permanente.
L'activation du système mémoire est mise en place en fin de traitement après vérification qu'aucune erreur de traitement n'ait pu apparaître. Dans ce cas la sauvegarde s'applique à l'ensemble des granules en mémoire permanente qui auront été modifiés durant le traitement. En cas de reprise d'une exploitation, alors les données en sauvegarde miroir sont automatiquement recopiées avant la reprise effective des traitements.
De cette manière, le logiciel redémarre toujours sur le dernier état mémoire valide :
− avant détection d'erreur ;
− avant panne du calculateur.
Trois modes de fonctionnement sont donc disponibles sous le logiciel KDTREE :
− gestion directe des données en mémoire volatile ;
− gestion des données en mémoire virtuelle au-delà des capacités de mémorisation disponible en mémoire volatile ;
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 29
− gestion des données en mémoire virtuelle avec système d'enregistrement miroir de protection.
Il est aussi possible de spécifier au logiciel le nombre maximal de granules que l'on souhaite exploiter dans une session de travail.
Nom Fonction
KDMDWK Définition du mode de gestion de la zone de travail KDINWK Réservation de l'espace de travail pour la zone de travail KDALLO Allocation d'un double mot en mémoire
KDFREE Libération d'un double mot en mémoire KDWTYP Modification du type d'un double-mot KDRTYP Lecture du type d'un double-mot
KDWVAL Ecriture d'une valeur dans un double-mot KDWLNK Modification du lien d'un double-mot KDRVAL Lecture de la valeur d'un double-mot KDRLNK Lecture du lien d'un double-mot
3.2.
Session de travail
Lorsque les données résident seulement en mémoire centrale, leur durée de vie ne dépasse pas le temps d'exécution du programme. Il est nécessaire d'archiver les arbres qui ont pu être créées si l'on souhaite pouvoir les utiliser à nouveau dans l'avenir.
Par contre si celles-ci sont gérées en mémoire virtuelle, avec ou sans copie miroir, leur durée de vie dépasse le temps d'exécution du programme. Cette durée est celle d'une session de travail :
− elle débute avec la création de la session ;
− elle s'interrompt momentanément avec la suspension de session ;
− elle recommence avec la reprise de session ;
− elle se termine avec la suppression de session.
Chaque session requière de spécifier un nom qui servira de préfixe aux jeux de fichiers qui mémoriseront les données associées. La portée d'une session correspondra à la durée de vie de ces fichiers.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 30 Nom Fonction KDCRWK KDRSWK KDSUWK KDDEWK
Création d'une session de travail Reprise d'une session de travail Suspension d'une session de travail Destruction d'une session de travail
3.3. Structures de données
Trois adresses ont un statut particulier en mémoire des doublets : les adresses NIL, BLANC et NOIR. Elles sont auto-référentes et servent d'adresses de terminaison aux structures de données de type liste ou arbre.
Sous le logiciel KDTREE, la structure de base est la liste à simple chaînage : à l'initialisation d'une session la mémoire des doublets est seulement occupée par les trois adresses auto-référentes et la liste des mots libres du système d'allocation mémoire.
Toute liste dispose d'une tête, sauf les arbres dont la racine est un nœud particulier de la structure, son sommet. Une tête est un doublet réservé pour connaître l'adresse du premier élément de la liste, et pour certaine structure l'adresse du dernier élément (la queue). Les listes sont classées en quatre variantes :
− les listes que l'on peut gérer élément à élément ;
− les files où l'on extrait les éléments par la tête et où on les insère par la queue ;
− les piles où l'on extrait et insère les éléments par la tête ;
− les listes circulaires, qui ont la particularité de disposer d'élément de queue pointant directement sur la tête.
En dehors de celles-ci, le dernier élément d'une liste réfère la terminaison de liste NIL. Les listes circulaires, gérées sous forme de file, sont employées pour modéliser des vecteurs de coordonnées et des matrices sous le logiciel KDTREE.
Comme nous l'avons vu les arbres sont de deux types distincts : arbres binaires non valués et arbres values.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 31 Chaque mot de la mémoire des doublets est marqué avec le type de la structure à laquelle il appartient à un moment donné. Ce mécanisme permet de créer des structures de structures:
− des listes de listes pour gérer une matrice par exemple ;
− des arbres aux nœuds desquels des listes sont raccrochées ;
− des listes d'arbres pour gérer une forêt de composantes connexes par exemple. Certaines fonctions permettent de gérer globalement ces structures sans se préoccuper de leur architecture propre.
Nom Fonction
KDNIL KDBLAN KDNOIR
Comparaison d'une adresse avec la valeur NIL Comparaison d'une adresse avec la valeur BLANC Comparaison d'une adresse avec la valeur NOIR
Nom Fonction KDCRLS KDVDLS KDDTLS KDINLS KDSULS KDDELS
Création d'une liste
Test de l'état vide d'une liste Destruction de la tête d'une liste Insertion d'un élément dans une liste Suppression d'un élément dans une liste Destruction d'une liste
3.4. Opérateurs de base
Si les listes ont une tête permettant de pointer sur un élément, elles permettent de gérer un état de base qui est la liste vide. Il se caractérise par le fait, que la tête ne pointe sur rien, c'est-à-dire sur l'adresse NIL.
Au contraire, pour les arbres la racine d'un arbre n'est pas gérée distinctement des autres nœuds dans l'arbre : un arbre n'a pas de tête. Cela nous permet d'adopter une définition récursive de l'arbre où aucun nœud ne se distingue fondamentalement des autres.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 32 Un arbre vide n'aura pas de signification, par contre :
− un nœud blanc représentera toujours un ensemble vide à une dimension et une précision quelconque ;
− un nœud noir, l'espace entier (ensemble plein) à une dimension et une précision quelconque.
C'est donc l'état terminal ou non terminal qui primera dans un arbre. Cette définition récursive permet de transformer un arbre lors du parcours permettant de visiter l'ensemble de ses nœuds.
Lors de ce parcours, deux transformations sont possibles sur un nœud sans remettre en cause globalement la structure des données :
− la fusion de ses nœuds filiaux, s'il est non terminal ;
− la fission de lui-même, s'il est terminal, en deux nouveaux nœuds.
La fission produit par décomposition deux nouveaux éléments dans la structure arborescente. La fusion supprime par agrégation ces mêmes éléments.
Il s'établit alors une correspondance directe entre les opérations de base s'appliquant à une liste et celles employées sur un arbre binaire :
− création d'une liste/création d'un nœud terminal d'une couleur donnée (blanc/noir) ;
− test à vide d'une liste/test à l'état terminal d'un nœud ;
− succession d'un élément/adresse du fils d'un côté donné (gauche/droite) ;
− insertion d'un élément/fission d'un nœud ou union de deux sous-arbres ;
− suppression d'un élément/fusion d'un nœud non terminal ;
− destruction d'une liste/destruction d'un arbre.
Les opérations de destruction se résument à la suppression d'une tête de liste ou d'un nœud terminal. Par combinaison avec les opérations de suppression et de fusion, des structures entières peuvent être détruites.
Au niveau de l'insertion d'un nouvel élément dans la structure, nous avons distingué deux modes d'action possibles pour un arbre : la fission d'un nœud préexistant ou l'union de deux sous-arbres.
La fission d'un nœud en deux intervient lors d'un traitement dont l'objectif est la modification d'un arbre préexistant.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 33 L'union de deux sous-arbres apparaît au contraire lorsque le traitement génère par analyse d'un premier arbre, un nouvel arbre, transformé du premier.
La fission d'un nœud est un opérateur propre aux phases de descente dans l'analyse d'un arbre, alors que l'union de deux sous-arbres se produit plus particulièrement sur le retour ascendant du même parcours, lors de la phase de synthèse d'un arbre.
Nom Fonction
KDCRAB Création de la racine d'un arbre KDTABT Test si un nœud est terminal
KDFILS Lecture de l'adresse d'un fils d'un nœud KDFIAB Fission d'un nœud terminal
KDFUAB Fusion de deux nœuds terminaux KDUNAB Réunion de deux sous-arbres KDDEAB Destruction d'un arbre non valué
Nom Fonction KDCPYR KDISOC KDWFCT KDRFCT KDWCOL KDRCOL
Création de la racine d'une pyramide Test si deux nœuds sont isocolores
Ecriture d'une fonctionnelle dans un nœud Lecture d'une fonctionnelle dans un nœud Modification de la couleur d'un nœud Acquisition de la couleur d'un nœud
Nom Fonction
KD2KPY KDPY2K
Conversion d'un arbre en une pyramide Conversion d'une pyramide en un arbre
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 34 KDDSST
KDCPST KDLGST KDLSST
Destruction d'une structure Copie d'une structure Longueur d'une structure Edition d'une structure
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 35
4. Géométrie constructive
4.1. Modèle de programmation
Les fonctions de traitement suivent le méta-algorithme suivant sous le logiciel KDTREE : PROCEDURE traiter (arbre, niveau, profondeur)
DEBUT
SI (terminal (arbre) OU (niveau = profondeur)) ALORS traitement terminal
SINON FAIRE
pré-traitement descendant
APPEL traiter (fils gauche (arbre), niveau +1, profondeur) APPEL traiter (fils droit (arbre), niveau +1, profondeur) post-traitement ascendant
FIN FIN
Ce méta-algorithme produit un parcours en profondeur pour la structure visitée et enchaîne les phases suivantes sur les nœuds rencontrés :
− pré-traitement descendant des nœuds non terminaux ;
− traitement terminal d'un nœud terminal ou non (si l'on limite le parcours par l'emploi d'une précision intermédiaire)
− post-traitement ascendant des nœuds non terminaux.
Lors de traitement réalisé en précision intermédiaire, celle-ci s'effectue au sens de l'«enveloppe supérieure».
Les créations de nœuds sont l'apanage du traitement terminal.
La fission de nœud s'effectue lors de la phase descendante du parcours. L'union et la fusion de nœuds lors du retour ascendant.
Le traitement d'un arbre est effectué en lançant l'ordre :
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 36 Certains traitements sont le produit de l'examen simultané de deux arbres, la procédure générale se transforme alors ainsi :
PROCEDURE comparer (arbre 1, arbre 2, niveau, profondeur) DEBUT
SI (isocolore (arbre 1, arbre 2) OU (niveau = profondeur)) ALORS traitement terminal
SINON FAIRE
pré-traitement descendant
APPEL comparer (fils gauche (arbre 1), fils gauche (arbre 2), niveau+1, profondeur)
APPEL comparer (fils droit (arbre 1), fils droit (arbre 2), niveau+1, profondeur)
post-traitement ascendant F I N
FIN
Dans cette procédure, le contrôle du parcours ne se réalise plus sur un test de terminalité d'une branche, mais sur un test d'identité, l’isocoloration des nœuds.
Pour des arbres valués, ce test s'étend au contrôle de l'égalité des fonctionnelles pour deux nœuds noirs à comparer.
L'approche par récursion pour le traitement d'une structure arborescente permet de mémoriser le nœud par lequel ont est passé et de ne pas avoir à gérer explicitement un lien amont pour revenir sur la racine. Ainsi la récursion permet d'employer une structure à simple chaînage pour implémenter un arbre.
4.2. Génération de l’arbre d’un ensemble de données
Plusieurs méthodes sont envisageables pour construire l'arbre d'un ensemble de données. La méthode la plus générale proposée par le logiciel procède par enrichissement d'un ensemble préexistant.
Celui-ci est créé à vide (nœud terminal blanc). Puis, élément par élément, on ajoute à l'ensemble le point représenté par un vecteur de coordonnées :
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 37
− pour un arbre binaire non valué, soit par un vecteur de coordonnées à valeurs entières comprises entre 0 et 2r-1, soit par un vecteur de coordonnées à valeurs
flottantes normalisées entre 0 et 1 ;
− pour un arbre valué, la fonctionnelle est donnée en paramètre en même temps que le vecteur de coordonnées flottantes.
Cette opération est dénommée addition d'un vecteur à un arbre.
Lorsque tous les points de l'ensemble ont été ainsi introduits dans l'ensemble initialement vide, on a construit l'arbre de l'ensemble.
Cette procédure est suffisamment générale pour s'adapter :
− à des ensembles discrets, irrégulièrement échantillonnés et non ordonnés ;
− à des ensembles de données surabondants où plusieurs occurrences peuvent apparaître en un même point de l'espace.
Nom Fonction KDVICI KDVRCI KDAVAB KDADVA KDADVP
Génération d'un vecteur de données entières Génération d'un vecteur de données réelles Addition d'un vecteur entier à un arbre Addition d'un vecteur réel à un arbre Addition d'un vecteur réel à une pyramide
4.3. Opérations booléennes
Les opérations booléennes permettent de réaliser les opérations ensemblistes de l'algèbre de Boole sur les ensembles de données modélisés par des arbres :
− l'assertion d'un ensemble ;
− la négation d'un ensemble ;
− la réunion de deux ensembles ;
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 38
− l'exclusion de deux ensembles ;
− la différence de deux ensembles.
L'assertion d'un ensemble permet de produire une copie de l'ensemble mais à une précision différente de sa précision de construction.
La négation d'un ensemble est l'arbre de son ensemble complémentaire.
La réunion de deux ensembles est l'ensemble de leurs parties communes et de leurs parties distinctes.
L'intersection est restreinte à l'ensemble des parties communes de ces ensembles. L'exclusion est l'ensemble des parties non communes aux deux ensembles.
La différence est une copie du premier ensemble réduit de ses parties communes avec le second ensemble.
Lorsque l'arbre est valué :
− son complémentaire est un arbre non valué ;
− le maximum des fonctionnelles est conservé sur les parties communes de la réunion et de l'intersection. Nom Fonction KDASS KDNON KDREUN KDINTR KDEXCL KDDIFF
Assertion d'un arbre Négation d'un arbre Réunion de deux arbres Intersection de deux arbres Exclusion de deux arbres Différence de deux arbres
4.4. Manipulation de coupes orthogonales aux axes
Deux fonctions permettent de manipuler des coupes orthogonales aux axes du référentiel de l'espace dans lequel sont représentées les données : il s'agit d'insertion et d'extraction de coupes.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 39 L'insertion de coupe permet de reconstruire des objets dans un espace de dimension donnée à partir d'observations parallèles entre elles exprimées dans un espace de dimension inférieure.
L'extraction de coupe permet d'extraire un tel sous-ensemble à un groupe de coordonnées précises sans procéder à une projection sur un sous-espace qui mélangerait tous les individus présents dans le nuage de données.
La première situation se présente en tomographie lorsqu'on cherche à cumuler des coupes planes parallèles orthogonalement à un troisième axe afin de reconstruire un modèle tridimensionnel d'un objet physique dont on souhaite conserver une représentation pour l'observer sous différents points de vue et la mesurer.
La seconde situation se présente plutôt en analyse de données statistiques, en sélection multicritère ou en aide à la décision lorsqu'on tente d'analyser des données dans un plan précis situé à une localisation précise.
Lors des transformations géométriques, il sera précisé comment se déplacer, s'orienter et réaliser des projections de l'espace entier sur des sous-espaces pour conserver l'exhaustivité de description du jeu de données.
Soit Ek, l'espace de dimension k dans lequel l'on insère ou l'on prélève des coupes Cm de
dimension m, il nous faut pouvoir spécifier un point P appartenant à cette coupe pour réaliser cette opération : seules les k-m coordonnées appartenant aux axes orthogonaux à la coupe suffisent pour définir P.
C'est ainsi que pour insérer ou extraire une coupe il faut pouvoir spécifier ou déduire :
− l'ensemble des données et la dimension de son espace sur lequel on agit ;
− la coupe et la dimension de la coupe que l'on insère ou extrait ;
− le point et le nombre de ses coordonnées significatives (codimension de la coupe). Le point peut être spécifié sous la forme :
− d'une liste de coordonnées (un vecteur) ;
− d'un arbre (l'arbre du point dans l'espace complémentaire de la coupe).
Nom Fonction
KDEXCP KDINCP
Extraction d'une coupe parallèle aux axes Insertion d'une coupe parallèle aux axes
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 40 Figure 2 : Image tridimensionnelle
d’un relief numérique
Figure 3 : Coupes parallèles réassemblées par opérations booléennes
4.5. Hypercube de référence et calcul en limite inductive
Revenons quelques instants sur la description initiale des ensembles de données modélisés par un 2k-arbre, pour tenter d'enrichir les notions associées à ce modèle de représentation.
Dans le paragraphe qui lui a été consacré, nous nous sommes principalement intéressés à des ensembles de données multidimensionnelles discrétisées sur N ou Q et R
lorsqu'elles sont normalisées.
De manière plus générale, la modélisation par 2k-arbre s'applique à des ensembles de
données multidimensionnelles bornées pour lesquelles il existe une relation d'ordre partielle selon chacun des axes de l'espace.
Si ces diverses relations d'ordre sont quantifiables, l'espace devient mesurable. Dans ce cas précis, il n'est pas nécessaire de connaître explicitement les bornes inférieure et supérieure de l'espace de modélisation pour être en capacité de construire l'arbre de représentation d'un ensemble de données.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 41 Les espaces multidimensionnels régulièrement échantillonnés ont une structure d'algèbre borélienne qui peut être étendue à l'infini inductivement par emboîtements des espaces les uns dans les autres à l'image de "poupées russes".
Dans cette structuration, chaque hypercube s'emboîte dans un autre et en contient autant d'autres que l'on peut en définir par division récursive. Chacun des hypercubes qui peuplent de tels espaces, ne se distingue de ses voisins que par sa position ou son diamètre, tout en conservant leurs faces parallèles. C'est-à-dire, qu'ils sont semblables les uns aux autres à une translation et une homothétie près.
En employant N, Q ou Rcomme corps de quantification, il est possible en partant de l'hypercube unitaire de dimension k d'induire une structuration topologique à tout l'espace mesuré, qui permette de rendre comparable deux mesures réalisées sur deux ensembles de mesures ou de multiples ensembles de mesures effectuées à des instants différents.
L'hypercube englobant le jeu de données et appartenant à cette structuration de l'espace de mesure sera alors l'information nécessaire qui permettra dans l'avenir de confronter cet ensemble de réalisations avec toute nouvelle collection de données : on parle alors d'hypercube de référence.
Alors pour comparer deux ensembles distincts de réalisations, il suffit de repositionner chacun de ceux-ci dans l'hypercube englobant les deux hypercubes de référence associés aux jeux de données.
Ainsi en attribuant une structuration implicite de l'espace de modélisation compatible avec l'organisation hiérarchique des données, on rend comparable deux jeux de données acquis dans des conditions distinctes.
Cela ne sera pas possible, si l'opération s'effectuait en bornant les jeux de données par leur enveloppe exinscrite, c'est-à-dire par le parallélotope (hyperparaléllogramme) défini par les valeurs minimale et maximale d'un ensemble de données selon chacun des axes de quantification de l'espace.
Il serait alors nécessaire de discrétiser les ensembles de données à chaque tentative de comparaison, car l'organisation hiérarchique des structures dépend directement des données constitutives des ensembles qu'elles doivent décrire. En d'autres termes, en fonction du jeu de bornes inférieure et supérieure choisi pour chaque axe de l'espace, il est possible de produire des arbres dissemblables pour représenter un jeu de données.
Par contre, si l'on se restreint à utiliser des hypercubes de référence homothétiques par puissance de 2 les uns des autres à une translation près, tous les arbres produits seront comparables car ils ne décrivent qu'une branche particulière dans un arbre bien plus vaste dans lequel tout jeu de données pourra trouver à se loger.
Disposant des informations suffisantes permettant de décrire les hypercubes de référence associés à deux jeux de données différents, l'hypercube associé au volume d'espace permettant de comparer les deux arbres se déduit des deux premiers par un calcul en limite inductive.
Modélisation Hiérarchique Multidimensionnelle : Tome 2 Page 42 Les opérations booléennes ont été adaptées pour fonctionner en limite inductive : les hypercubes de références des opérandes sont passés en paramètres et le résultat du traitement est livré avec l'hypercube qui y est associé.
Nom Fonction
KDCALI Création d'un arbre en limite inductive KDAVLI Addition d'un vecteur à un arbre en limite KDCPLI Création d'une pyramide en limite inductive KDVPLI Addition d'un vecteur à une pyramide en limite KDRNLI Réunion de deux arbres en limite inductive KDINLI Intersection de deux arbres en limite inductive KDEXLI Exclusion de deux arbres en limite inductive KDDFLI Différence de deux arbres en limite inductive