République Algérienne Démocratique et Populaire
ﺓﺭﺍﺯﻭ ﻢﻴﻠﻌﺘﻟﺍ ﻲﻟﺎﻌﻟﺍ ﺚﺤﺒﻟﺍﻭ ﻲﻤﻠﻌﻟﺍ
Ministère de l’enseignement Supérieur et de la Recherche scientifique
Université d'Adrar – Algérie Faculté des sciences et de la Technologie Département des mathématiques et informatique
Mémoire
,Présenté au Département des mathématiques et informatique de l’Université d’Adrar
pour satisfaire partiellement aux exigences du diplôme de Master académique (LMD),
Option
:RSI
Thème :
Résolution du problème d’anaphore dans le texte arabe
Présenté par :
Rekia REGGANI
Président :
Mr.CHOGUEUR Djilali
Examinateur :
Mr.MEDIANI Mohamed
Examinateur :
Mr.KOHILI Mohamed
Encadreur :
Mr.CHERAGUI Mohamed Amine
Soutenu le : 07 Juin 2018
exÅxÜv|xÅxÇàá
Au terme de ce modeste travail, Nous tenons à remercier
en premier notre DIEU tout puissant de nous avoir
donné le courage, la patience, la fois et la volonté pour pouvoir
continuer et réaliser ce travail.
Un remerciement spécial à nos parents pour leur soutien indéfectible et de leur encouragement
permanent.
Nous tenons à exprimer notre profonde gratitude et notre
Respectueuse reconnaissance à notre encadreur :
Mr : CHERAGUI Mohamed Amine pour le temps important qu'il a bien voulu réserver pour
examiner notre petite expérience et porter des corrections à chaque fois qu'il est nécessaire. Nous
remercions infiniment Mademoiselle TIOURIRINE Noura pour nous avoir fourni des informations
importantes et combien profitables, Mademoiselle KEBIR Zohra pour le temps précieux qu'elle a
bien voulu consacrer pour nous
Nous n’oublierons pas de remercier
Mr : Dawadi
Nous remercions au passage tous les membres du jury, tous les enseignants du département
mathématiques et informatique. nos amis et tous ceux qui nous ont prêté mains fortes pour
la réalisation du projet
.
W°w|vtvx
C'est par un vif plaisir que je dédie ce modeste travail conçu comme fruit prés requis à:
A celle qui ma donnée la vie, qui ma bercée mes nuits, celle qui ma vécue qu'un jour réussir,
Ma très très mon père Alarbi, que dieu la protège.
A l'âme sainte de chère mère Kbira (lalla).
Pour tous mes frères et mes soeurs
A toutes les familles Reggani et Aboulhacene.
A Frère et le professeur HAMOUDA Masoud
A mes très chères amies, Chrifa, Fatima, Zohra, Noura, Maissa, Charefa
Et mes collègues de la promotion 2ème année master
M
elle
.
Rekia REGGANI
Si le concept d’anaphore en terme l’linguistique est considérée comme phénomène positifs évitant la redondance des termes dans un paragraphe ou un texte, il est toute à l’opposer en ce qui concerne le traitement automatique du langage naturel. Il faut préciser que la présence d’une anaphore dans une phrase rend le processus de compréhension difficile, pour élaborer une communication homme machine.
L’une des langues qui mis en valeur le phénomène anaphorique en valeur, est sans doute la langue arabe est cela est due à sa richesse morphologique. Qui constitue à la fois un point fort mais aussi un point faible dans le cas de l’automatisation.
L’objectif de ce travail, est de mettre en place une application informatique capable de proposer une résolution partielle (en touchant l’aspect pronominal et verbal) du phénomène anaphorique dans le texte arabe, ou notre idée de base consiste à exploité les traits morphosyntaxiques pour localiser l’anaphore à travers son étiquette pour faire un balayage en avant ou en arrière, pour situer le référent. Pour extraire ces traites morphosyntaxiques nous avons utilisé la boite l’outil AMIRA.
Mot clés : langue Arabe, Analyse Morpho-syntaxique, Anaphore pronominal, Anaphore verbal.
Abstract
If the concept of anaphora in terms of linguistics considered as a positive phenomenon avoiding the redundancy of terms in a paragraph or a text, it is quite the opposite with regard to the automatic natural language processing. It should be noted that the presence of an anaphor in a sentence makes the process of understanding difficult, to develop a man-machine communication.
One of the languages that highlighted the anaphoric phenomenon in value, is indisputably the Arabic language is that is due to its morphological richness. Which constitutes at the same time a strong point but also a weak point in the case of the automation.
The objective of this work is to set up a computer application capable of proposing a partial resolution (touching the pronominal and verbal aspect) of the anaphoric phenomenon in Arabic text, our basic idea consists in exploiting the morphosyntaxic traits to locate the anaphor through its label to scan forward or backward to locate the referent. To extract these morpho-syntaxic processes we used the AMIRA toolbox.
I
Tables des Matières
Introduction générale…..………1
Chapitre 1 : Traitement automatique de langage Natural Vs langage arabe………2
1. Introduction……….……...………..3
2. Définition du traitement automatique des langues naturelles…………....………..3
3. Objectifs du traitement automatique des langues naturelles………...…...……….….…3
4. Histoiredutraitement automatique du langage naturel………..………..…..4
5. Niveaux de traitement automatique d’une langue naturel………..………..…………5
5.1. Niveau morphologique……….6
5.2. Niveau syntaxique………6
5.3. Niveau sémantique………7
5.4. Niveau pragmatique………..7
6. Domaines d’Application du TALN………...7
6.1. Les applications en relation avec le traitement de texte………...7
6.2. Applications en relation avec le traitement du signal……….…..7
6.3. Les applications concernant l'extraction d'information………8
7. Traitement automatique de la langue arabe………..8
7.1. Histoire de la langue arabe………...8
7.2. Caractéristiques de la langue arabe……….………..9
7.2.1. L’écriture arabe.……… 9
7.2.2. Le lexique arabe………..……… 10
7.3. Morphologie arabe………..……10
7.3.1. Caractéristique morphologique de la langue arabe...…..……… 10
8. Problèmes du traitement automatique de la langue arabe………..11
8.1. Absence des voyelles………..11
8.2. Irrégularité de l’ordre des mots dans les phrases arabe………..12
8.3. Problème d’agglutination du mot………...12
8.4. Absence de majuscule dans les entités nommées………...12
Chapitre 2 : L’Anaphore………...……...13
1. Introduction………14
2. Notions de base………...14
3. Les types d’anaphores en langue arabe………..15
II
3.2. Anaphore lexicale………...15
3.3. Anaphore comparative………16
3.4. Anaphore pronominale………...16
3.4.1. Les pronoms personnels de troisième personne..……… 16
3.4. 2 Les pronoms relatifs……… 17
3.4.3Les pronoms démonstratifs……….……….………17
4. Résolution d’anaphores en arabe………18
5. Problèmes de résolution anaphoriques en arabe……….19
6. Méthode de résolution………20
7. Domaines d’applications de la résolution des anaphores………...21
8. Conclusion………..22
Chapitre 3 : Conception et architecture d’AraPhore……….…….…..23
1. Introduction………24
2. Conception et architecture générale d’AraPhore………24
3. Phase de prétraitement………26
3.1. Présentation d’AMIRA………...………26
3.2. Pourquoi AMIRA ?...26
3.3. Les phases de Pré traitement………..………26
4. Phase de résolution……….28
4.1. Résolution de l’anaphore pronominale………...28
4.1.1. Résolution des anaphores pronominales de Types démonstratifs(ﺓﺭﺎﺷﻷﺍ ءﺎﻤﺳﺃ) ...…28
4.1.2. Résolution des anaphores pronominales de types pronoms personnels(ﺐﺋﺎﻐﻟﺍ ﺮﺋﺎﻤﺿ) 29 4.1.3. Résolution des anaphores pronominales de Types pronoms relatifs (ﺔﻟﻮﺻﻮﻤﻟﺍ ءﺎﻤﺳﻷﺍ)31 4.2. Résolution de l’anaphore verbale………34
5. Conclusion………..36
Chapitre 4 : Application et Résultats………..37
1. Introduction………38
2. Environnement de développement……….38
2.1. Python en quelques lignes………...38
2.2. Caractéristiques techniques………39
3. Interface graphique du l’anaphore………..39
3.1. Barre d’outils………..40
3.2. Représentation des boutons d’accourses………41
3.3. Représentation de bouton« Analyze »………41
III
5. Résultats……….42
5.1. Résultat de l’anaphore pronominale………...42
5.1.1. Résultat du Corpus Contemporary Arabic»... ….42
5.1.2. Résultat du Corpus «WIKINews Evaluation »……… .……....………48
5.1.3. Résultat du Corpus Tashkeela« » ………….………49
5.1.4. Résultat du Corpus « Watan-2004».………..50
5.2. Résultats de l’anaphore verbale……….……….53
6. Analyse Critique………..54
7. Conclusion………..55
IV
Liste des Figures
Figure 01: marquants dans l’histoire du TALN………...…5
figure 02: Représentation des niveaux de traitement du langage naturel………..………6
figure 03:Les importantes étapes de développement de la langue arabe………...……...8
figure 04:La forme du mot Arabe………...…..10
figure 05:Exemple de dérivation de la racine "ﺝ َﺮَﺧ "………...….11
figure 06: Représentation des pronoms concernés par l’anaphore pronominale………...….18
figure 07: Architecture générale d’AraPhore. ... 25
figure 08: Traitement effectué par AMIRA. ... 27
figure 09: Exemple de traitement effectué par AMIRA. ... 27
figure 10: Exemple de résolution de pronoms démonstratifs. ... 29
figure 11: Exemple de résolution de pronoms personnels. ... 31
figure 12: Exemple de résolution de pronoms relatifs. ... 33
figure 13: Exemple de résolution d’anaphore verbal ... 35
figure 14: Icones du langage de développement "Python". ... 36
figure 15: Capture d’écran de l’interface graphique « AraPhore ». ... 40
figure 16: Les boutons des accourses. ... 40
figure 17: bouton de logicielle « AraPhore ». ... 41
figure 18: Résultat du bouton «Analyze » de logicielle «AraPhore ». ... 42
figure 19: Représentation graphique du résultat de la catégorie « Education». ... 44
figure 20: Représentation graphique du résultat de la catégorie « Health and medicine». ... 44
figure 21: Représentation graphique du résultat de la catégorie « Interviews». ... 45
figure 22: Représentation graphique du résultat de la catégorie « Short Stories». ... 45
figure 23: Représentation graphique du résultat de la catégorie « Sociology. ... 46
figure 24: Représentation graphique du résultat de la catégorie « Religion». ... 46
figure 25: Représentation graphique du résultat de la catégorie « Economics». ... 47
figure 26: Représentation graphique du résultat du corpus « Contemporary Arabic ». ... 47
figure 27: Représentation graphique du résultat du corpus « WIKINews Evaluation» pour tous les pronoms. ... 48
figure 28: Représentation graphique du résultat du corpus « WIKINews Evaluation». ... 49
figure 29: Représentation graphique du résultat du corpus « Tashkeela»pour tous les pronoms………...…50
figure 30: Représentation graphique du résultat du corpus « Tashkeela» ... 50
V
figure 32: Représentation graphique du résultat de la catégorie « International» ... 52
figure 33: Représentation graphique du résultat de la catégorie « Culture». ... 52
figure 34: Représentation graphique du résultat de corpus « Watan» ... 53
figure 35: Représentation graphique du résultat du corpus « Contemporary Arabic et Tachkeela». ... 53
VI
Liste de Tableaux
Tableau 01: Exemple sur les racines………...………10
Tableau 02: Inerprétation du mot "ﺐﺘﻛ"………..12
Tableau 03: Pronoms troisième personne(A)………..16
Tableau 03: Pronoms troisième personne(B)………..17
Tableau 04: Les pronoms démonstratifs(A)………17
Tableau 04: Les pronoms démonstratifs(B)………18
Tableau 05 : les pronoms démonstratifs, ses tags ainsi que les tags référents qui vont avec…………..29
Tableau 06 : les pronoms personnels et les référents………..30
Tableau 07 : les pronoms relatifs et les référents………32
Tableau 08: Le pronom relatif non reconnue par AMIRA et le référent………33
Tableau 09 : Le verbe et le référent(A)………...34
Tableau 09 : Le verbe et le référent(B)………...35
Tableau 10 : Résultat du Corpus « ContemporaryArabic » pour tous les pronoms ... 43
Tableau 11 : Résultat du Corpus « ContemporaryArabic ». ... 47
Tableau 12 : Résultat du Corpus « WIKINews Evaluation» pour tous les pronoms ... 48
Tableau 13: Résultat du Corpus « WIKINews Evaluation». ... 48
Tableau 14 : Résultat du Corpus « Tashkeela» pour tous les pronoms ... 49
Tableau 15 : Résultat du Corpus « Tshkeela»... 50
Tableau 16 : Résultat du Corpus « Watan » pour tous les pronoms ... 51
Tableau 17 : Résultat du Corpus « Watan »... 52
Tableau 18 : Résultat du Corpus « ContemporaryArabic et Tachkeela». ... 53
1
Introduction Générale
Il est primordial et même capital de mettre en valeur le rôle que joue l’informatique à se forger à travers son parcours depuis sa création. Ceci est traduit par son impact dans les différentes disciplines scientifiques et techniques. Cette situation est ressentie d’une manière très significative dans les recherches récentes, en particulier en traitement automatique de langues naturelles.
Le traitement automatique des langues dites naturelles, est une thématique de recherche qui vise à rendre et permettre à la machine (ordinateur) de pouvoir comprendre mais éventuellement de pouvoir communiquer avec un être humaine dans son propre langage. Pour atteindre cette faculté le processus d’automatisation passe par différents niveaux mais aussi par l’élaboration de différents modules qui peuvent contribuer à la compréhension, parmi ces modules nous citons la résolution du problème d’anaphore.
La résolution d’anaphore consiste principalement à trouver la référence d’un groupe nominal, pronominal ou même dans certain cas verbal qui doit être interprété par rapport à un élément apparaissant avant lui ou après dans le discours
Le travail que nous présentons dans ce mémoire vise à examiner le phénomène d’anaphore, de concevoir et construire un système de résolution des anaphores dédié à la langue arabe touchant l’aspect pronominal et verbal.
Pour cette raison le mémoire, s’articule autour de quatre chapitres, réparties comme suit :
Le premier chapitre : est une ouverture sur le traitement automatique des langues naturelles, ainsi que la langue arabe.
Le deuxième chapitre : touche le phénomène anaphorique, les différentes connexions établies et l’importance de cette tâche à travers les approches de résolution pour la langue arabe.
Le troisième chapitre : met l’accent sur « la conception et la réalisation », il présente l’architecture générale de l’outil à développer « AraPhore ».
Le quatrième chapitre : sera consacré à la présentation de notre outil, ainsi que différents tests et résultats obtenus.
Chapitre
Traitement automatique de langage
Natural Vs langage arabe
3
1.
Introduction
Le Traitement Automatique des Langues TAL est devenu dans ce monde actuel un domaine très vaste. Il se distingue par des recherches dans plusieurs disciplines qui font intervenir des linguistes, des informaticiens, des psychologues, des traducteurs. Il appartient au domaine de l’Intelligence Artificielle.
Actuellement, le champ de recherche du TALN est très actif et diversifié. De nombreuses applications industrielles (traduction automatique, recherche documentaire, interface en langue naturelle) qui ont déjà atteint le grand public sont là pour témoigner de l’importance des progrès et des avancées accomplies. Quant à notre premier chapitre, on va d’abord définir le TAL (son histoire, ses objectifs ainsi que les différents niveaux du TAL. On va aborder également les domaines d’application du TAL. Avant de clôturer ce chapitre, on va se focaliser sur le traitement automatique de la langue arabe (TALA), son histoire, ses caractéristiques, la morphologie de la Langue Arabe et enfin les problèmes qui résultent du TALA.
2.
Définition du traitement automatique des langues naturelles
On définit le traitement automatique de la langue naturelle (TALN) comme l’ensemble de recherche et développement visant à la conception de logiciels capables de traiter de façon automatique des données exprimées dans une langue, tel que les données linguistiques (texte écrit, ou oral).En d’autre terme, le TALN permettre de la mise en œuvre d'automatique du traitement sur des langages, par exemple, la traduction automatique, la correction grammaticale, l’extraction d’informations, la génération automatique de texte,…etc. [PAS, al, 09]
3.
Objectifs du traitement automatique des langues naturelles
L’objectif du TALN peut être résumé par deux (02) points souvent conjoints dans la réalité :
♦
sur un plan théorique : le TAL permet de vérifier les théories linguistiques ou de manipulationgénérale, de mieux comprendre comment les humains communiquent entre eux. Pour cette fin, il utilise l’ordinateur pour simuler les capacités humaines de compréhension et de production de la langue naturelle. Les résultats ainsi obtenus peuvent ensuite être comparés aux performances humaines et les théories sur lesquelles se fondent les simulations vérifiées [BOU, 98].
♦
sur le plan pratique : le TAL rend possible la construction de système opérationnels qui4
4.
Histoire du traitement automatique du langage naturel
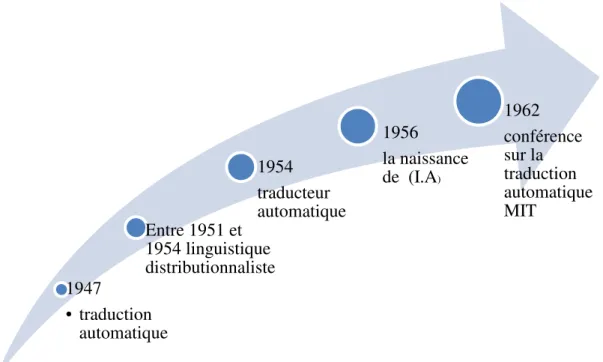
Le traitement automatique du langage naturel est né à la fin des années quarante dans un contexte scientifique imprimé par les premiers travaux sur la traduction mais aussi dans un contexte politique qui s’explique par la seconde guerre mondiale. Le but de ce point est de donner quelques dates marquantes dans le développement du traitement automatique du langage naturel à travers le monde. [LEO, 01], [DAH, 14].
♦ 1947 : Début des travaux sur la traduction automatique :
♦ Entre 1951 et 1954 :Zelling Harris publie ses travaux les plus importants de la linguistique(linguistique distributionnaliste) ;
♦ 1954 : La mise au point du premier traducteur automatique (très rudimentaire) qui traduit du Russeà l’Anglais (bien que le vocabulaire ne comptait que 250 mots et la grammaire 6 règles), cette expérience a déclenché de nombreux travaux dans ce domaine.
♦ 1956 : L’école de Dartmouth (au Etats-Unis) et la naissance de l’Intelligence Artificielle (I.A) sous l’influence de plusieurs figures marquantes de cette époque : J. McCarthy, Marvin Minsky, Allan Newell et Herbert Simon qui discutent sur les possibilités de créer des programmes d’ordinateurs qui se comportent intelligemment et en particulier qui soient capables d’utiliser le langage naturel. ♦ 1957 : Noam Chomsky publie ses premiers travaux sur la syntaxe des langues naturelles, et sur les
relations entre grammaire formelles et grammaire naturelles.
♦ 1962 : la première conférence sur la traduction automatique est organisée au MIT (Institut Technologique du Massachussetts) par Y. Bar-Hillel.
♦ Entre 1961 et 1966 : beaucoup d’applications ont été mis en place tel que : BASEBALL, SIR, STUDENT, ELIZA, …etc. Mettant en œuvre des mécanismes de traitement simple, à base de mots clés.
♦ 1966 : L’histoire du TAL fait souvent celle des rendez-vous manqués et des désillusions cruelles Parmi ces faits marquants, on peut citer le rapport de la commission ALPAC (Automatic Language Processing Advisory Committee) qui s’interroge sur l’utilité de poursuivre les recherches dans ce domaine. Dès lors, les crédits sont considérablement réduits et la recherche stagne jusqu'au début des années 70.
♦ Depuis 1970 : la plupart des recherches visent surtout la sémantique dans le cadre de la compréhension, mais aussi en parallèle les modèles syntaxiques connaissent en informatique des développements et des raffinements continus, et des algorithmes de plus en plus performants sont proposées pour analyser les grammaires les plus simples.
5
♦ 1972 : Terry Winogard, réalise le premier logiciel appelé SHRDLU capable de dialoguer en anglais avec un robot, dans le cadre d’un micro-monde (quelques blocs de couleurs et des formes variées, posés sur une table).
♦ 1976 : L’installation d’un système de traduction automatique commercial nommé SYSTRAN, la traduction automatique se fait connaître du grand public et suscite à nouveau l’intérêt des firmes privés que se soit au Etats Unis ou au Japon.
♦ Entre 1980 jusqu'à aujourd’hui : La recherche en traitement automatique du langage naturel a connu depuis les années 80 jusqu'à nos jours une véritable progression, en terme de performance qui se traduit d’un côté par la diversification des applications industriels, mais aussi d’un autre côté par la création de plusieurs conférences internationales de renommée set de laboratoires de recherches à travers le monde.
Figure 01 : Les événements marquants dans l’histoire du TALN.
5.
Niveaux de traitement automatique d’une langue naturel
Pour traiter le langage naturel, on a besoin d’informations coordonnées et pertinentes sur la langue à des niveaux divers. Nous introduisons dans cette section les différents niveaux de traitement nécessaires pour parvenir à une compréhension (analyse linguistique) complète d’un énoncé en langage naturel.
Du point de vue des TALIST’s, ces niveaux correspondent à des modules qu’il faudrait développer et faire coopérer dans le cadre d’une application complète de traitement de langage
1947 • traduction automatique Entre 1951 et 1954 linguistique distributionnaliste 1954 traducteur automatique 1956 la naissance de (I.A) 1962 conférence sur la traduction automatique MIT
6
naturel. Pour cela, on distingue quatre (04) modules (respectivement niveaux) de traitement où chaque module (respectivement niveau) a une tâche bien précise [DAH, 14].
Un module de reconnaissance (morphologique). Un module de structuration (niveau syntaxique). Un module de compréhension (niveau sémantique). Un module de conceptualisation (niveau pragmatique).
Figure 02 : Représentation des niveaux de traitement du langage naturel
5.1.
Niveau morphologique
Le niveau de traitement morpho-lexical selon [MAR, 69] est l’étude de la forme des mots (de leur flexion : indications de cas, genre, nombre, mode, temps, etc. De leur dérivation (proclitiques, préfixes, base, suffixes, enclitique) et de leur compositions). Sous l'appellation de morphosyntaxe, elle représente également l'étude des règles de combinaison des morphèmes (unités minimales de sens) selon la configuration syntaxique de l'énoncé [NEV, 04].
En pratique, dans le cadre du traitement automatique de la langue, l'analyse morphologique consiste à segmenter le texte en unité élémentaires (tokenisation) et de de vérifier l’appartenance d’un mot donné au domaine linguistique choisi (ou bien à la langue étudié) et à déterminer les différentes caractéristiques de ces unités[DAH, 14].
5.2.
Niveau syntaxique
Le niveau de traitement syntaxique permet d’associer à un énoncé (mot) sa ou ses structures syntaxiques possibles, en identifiant ses différents constituants et les rôles que ces derniers entretiennent entre eux. Cette phase reçoit au fur et à mesure de la phase ‘Morphologie’ les résultats de traitement des mots de la phrase indépendamment du contexte, commence à faire l’analyse du
Morpho-lexical • L'étude de la formation de mot Syntaxique • s'interesse à la structure des phrases sémantique • se consacre au sens des mot en dehors du context pragmatique • concerne le sens des mot dans context
7
premier mot reçu de la phrase, et entre en communication avec les autres phases d’analyse, si nécessaire[NEV,04] .
5.3.
Niveau sémantique
L’analyse sémantique joue un rôle important dans l’étude du langage naturel, dans le sens où elle consiste à extraire la signification des structures de surface (l’étude du sens du mot hors contexte de la phrase ou du texte), et vise aussi à enlever les ambiguïtés qui restent après le traitement syntaxique et ainsi traiter les problèmes relatifs à la correspondance structure sens[DAG ,al ,05].
5.4.
Niveau pragmatique
Ce type de traitement permet de lever les ambiguïtés qui ne peuvent pas être éliminées par le traitement sémantique, à cause de certains problèmes ayant un lien avec le contexte dans lequel la phrase est prononcé(donner un sens au mot par rapport au contexte dans lequel il se trouve), c'est-à-dire, il se charge de placer le mot dans le contexte de l’ensemble des connaissances en faisant recours à des informations hors-contexte(géographie, sport, travail, …etc.)[YVO, 07].
6.
Domaines d’Application du TALN
Pour les applications du TALN, on peut distingue plusieurs disciplines, parmi celle [TIU, 15] :
6.1. Les applications en relation avec le traitement de texte
En ce sens, nous trouvons plusieurs applications :
• Traduction automatique : elle est la première application, et considéré le premier effort de recherche en TALN.
• La correction orthographie. • Le résume du texte.
6.2. Applications en relation avec le traitement du signal
Parmi ce type d'application, on trouve :• Traitement de la parole.
• Reconnaissance automatique de la parole. • Synthèse de la parole.
8
6.3. Les applications concernant l'extraction d'information
• La recherche d'information.• L'annotation sémantique.
• la reconnaissance d'entités nommées.
• La classification et la catégorisions de document.
7.
Traitement automatique de la langue arabe
Par ses propriétés morphologiques et syntaxiques la langue arabe est considérée comme une langue difficile à maîtriser dans le domaine du traitement automatique de la langue.
7.1.
Histoire de la langue arabe
Il est difficile d’aborder l’étude d’une langue sans se référer à l’histoire qu’elle véhicule [SAY, 09]. L’arabe littéral est l’une des rares langues anciennes à avoir survécu, parallèlement à ses dialectes, en évoluant dans une forme de distribution complémentaire [BAC, 09].
Avant de se développer, la langue arabe est passée par trois étapes comme montre le schéma suivant :
De l’antiquité jusqu’au Moyen-âge, l'arabe ancien
La littérature qu’il véhicule est essentiellement orale (poèmes, chroniques, proverbes,…etc.). Cet arabe littéraire était aussi une langue parlée et usuelle de ces populations, considérablement enrichi par la production islamique liée au texte sacré, le Coran[BAC, 09].
l'arabe ancienne (de l’antiquité jusqu’au Moyen-âge)
l'arabe classique (du 7
èmeau 18
èmesiècle)
l'arabe moderne (à partir du 19
èmesiècle)
9
Du 7ème au 18ème siècle, l'arabe classique
C'est la langue du Coran qui a bénéficiée effectivement d'autres formes d'enrichissement grâce à la traduction notamment du grec, du persan et de l’araméen [BAC, 09], si on considère l’arabe standard moderne comme l'une des formes un peu différenciée de l’arabe classique, et qui constitue la langue écrite de tous les pays arabophones. L’ASM reste le langage de la presse, de la littérature et de la correspondance formelle [BOU, 08].
C’est à partir du8ème.s.j1 que les premiers traités et dictionnaires ont commencé à voir le jour. Cette
codification qui a fixé la langue dans sa forme classique, a facilité la diffusion de l’arabe par l’enseignement partout où la nouvelle religion a pu pénétrer.
A partir du 19ème siècle, l'arabe modern
Il faut mentionner enfin le 19èmesiècle considéré comme la renaissance des lettres et de la langue arabe.
Des formes nouvelles sont créées : le roman, la nouvelle, le théâtre, le cinéma, le journal et les revues...etc. et les multiples productions scientifiques exigeant un véritable renouvellement du vocabulaire et imposant parfois une évolution même de la syntaxe. La langue arabe moderne, le littéraire moderne, celle que répandent le livre, la télévision, les discours officiels,...etc. sont communs aux trois grandes aires dans lesquelles la langue quotidienne (dite dialectale) connaît de nombreuses variantes [SAY, 09].
Pour ce qui est de la dimension sociolinguistique de l’arabe moderne, la complémentarité entre le littéral et le dialectal s’observe à travers la spécialisation du premier dans l’écrit et le second dans l’oral [BAC, 09].
7.2.
Caractéristiques de la langue arabe
7.2.1.
L’écriture arabe
L’alphabet de la langue arabe compte 28 consonnes. L'arabe s’écrit et se lit de droite à gauche les lettres changent de forme de présentation selon leur position (au début, au milieu ou à la fin du mot). [DOU.04].
Un mot arabe s’écrit avec des consonnes et des voyelles. Les voyelles sont ajoutée dessus ou au-dessous des lettres.
1Avant la naissance de Jésus Christian
10 Exemple :
7.2.2.
Le lexique arabe
Le lexique arabe comprend trois catégories de mots : verbes, noms et particules. Les verbes et noms sont le plus souvent dérivés d’une racine à trois ou quatre consonnes radicales.
Exemple :
7.3.
Morphologie arabe
La morphologie est un domaine de la langue qui permet la description des règles régissant la structure interne des mots (unités lexicales), chez les grammairiens la morphologie est l’étude des formes des mots (flexion et dérivations) [CHE, 12].
7.3.1. Caractéristique morphologique de la langue arabe
L'analyse morphologique est construire par l'assemblage des unités lexicales. C'est-à-dire, le traitement morphologie nécessite que l'unité lexicale élémentaire obtenue par le découpage de mot soit connue dans lexique de la langue étudiée [SAG, 03]. Cependant la morphologie de la langue arabe est constituée de :
a. Le mot
Le lexique arabe comprend trois (03) catégories de mots : verbes, noms et particules [DOU, 04] : • Verbe : entité exprimant un sens dépendant du temps, c’est un élément fondamental auquel se
rattachent directement ou indirectement les divers mots qui constituent l’ensemble.
Schème ﻞــ ــــﻌـ ــــﻔـ ــــﺘــ ـﺳ ﺍ Mot ﺮــــ ــــﻔــ ـــ ـﻐ ـــﺘــ ـﺳ ﺍ Racine ﺮــــ ـــﻔــ ـــﻏ / / /
Tableau 01 : Exemples sur les racines. Figure 04 : La forme du mot Arabe.
ْﻟﺍ
ِﺮَﻜْﺴَﻌ
ﱡﻱ
Aldamm Alchadd a Alkasr Soukoun Alfath11
• Nom : l’élément désignant un être ou un objet qui exprime un sens indépendamment du temps.
• Particule : entités qui servent à situer les événements et les objets par rapport au temps et l'espace, et permettent un enchaînement cohérent du texte.
b. La Racine
La racine est formée par une suite de trois ou quatre consonnes formant la base du mot. En effet, à chaque racine correspond un champ sémantique et à l’aide de différents schèmes, on peut générer une famille de mots appartenant à ce champ sémantique [KHE, 06].Par exemple la racine « ﺐﺘﻛ » peut engendrer quinze mots tel que : « ٌﺏﺎﺘِﻛ , ٌﺐـﺗﺎﻛ , ٌﺐـﺘـﻜﻣ ,ٌﺔﺒـﺘﻜَﻣ».
c. Le Schème
Le schème est un mot composé de trois consonnes radica les (« ﻑ » « ﻉ » « ﻝ ») qui sont vocalisées et qui peuvent être augmentées par d’autres lettres (préfixe, suffixe et infixe).Le schème joue un rôle très important dans le processus de génération des formes dérivées à partir d’une racine [KHE, 06]. Il consiste à remplacer les lettres radicales du schème par les consonnes de la racine en question.
Exemple :
8.
Problèmes du traitement automatique de la langue arabe
Parmi les problèmes que rencontre le processus d’automatisation de la l langue arabe, on peut citer :
8.1.
Absence des voyelles
La plupart des documents arabes sont non voyelles. En effet, les voyelles ne sont utilisées que dans certains ouvrages scolaires pour débutants et dans le Coran [BEL, al, 0 ].Un texte arabe dont lequel 7 n’apparaissent pas des signes diacritiques tel que(les voyelles courtes le redoublement) est fortement ambigu. Cette ambiguïté peut être levée par l’association de la forme avec le sens et le contexte.
Figure 05 : Exemple de dérivation de la racine "
َﺝ َﺮَﺧ
"Racine ﺝ ﺭ ﺥ
Schème ﻝ ﻉ ﻑ
12
L’absence des voyelles génère une ambiguïté au niveau sémantique. Le Tableau 4donne un exemple pour le mot « ﺐﺘﻛ ».
Tableau 02 : Interprétation du mot« ﺐﺘﻛ » sans voyelles.
8.2.
Irrégularité de l’ordre des mots dans les phrases arabe
L’ordre des mots en arabe est relativement libre. D’une manière générale, on met au début de la phrase le mot sur lequel on veut attirer l’attention et l’on termine sur le terme le plus long ou le plus riche en sens ou en sonorité. Cet ordre provoque des ambiguïtés syntaxiques artificielles dans la mesure où il faut prévoir dans la grammaire toutes les règles de combinaisons possibles d’inversion de l’ordre des mots dans la phrase [BEL
, al
, 07].Exemple, on peut changer l’ordre des mots dans la phrase suivante :
ُﺗ ﻲﻓﻮ ﺔﻤﺻﺎﻌﻟﺍ ﺮﺋﺍﺰﺠﻟﺍ ﻲﻓ ﺔﻳﺍﺭﺩ ﺪﻤﺣﺃ ﺔﻳﺍﺭﺩ ﺪﻤﺣﺃ ُﺗ ﻲﻓ ﻲﻓﻮ ﺔﻤﺻﺎﻌﻟﺍ ﺮﺋﺍﺰﺠﻟﺍ ُﺗ ﺔﻤﺻﺎﻌﻟﺍ ﺮﺋﺍﺰﺠﻟﺍ ﻲﻓ ﺔﻳﺍﺭﺩ ﺪﻤﺣﺃ ﻲﻓﻮ
Les trois phrases ont le même sens malgré le changement dans l’ordre de ces mots.
8.3.
Problème d’agglutination du mot
Contrairement aux langues latines, l’arabe est une langue agglutinante, les articles, les prépositions et les pronoms …etc. se collent aux adjectifs, noms, verbes et particules auxquels ils se rapportent ; ce qui engendre une ambiguïté morphologique au cours de l’analyse des mots [BOU, XX].
Exemple : le mot arabe «ﺎﻨﻧﻭﺮﻛﺬﺘﺗﺃ » correspond en français à la phrase "Est-ce que vous vous souvenez
de nous ?".
8.4.
Absence de majuscule dans les entités nommées
L’absence des lettres majuscules en arabe génère également une forte ambigüité, en particulier pour les prénoms qui portent aussi un sens d’adjectif. Si on prend le mot "ﻢﻳﺮﻛ", il signifier généreux ou un nom propre [CHA, 12].
Mot sans voyelles 1ére Interprétation 2émeInterprétation 3èmeInterprétation
ﺐﺘﻛ َﺐَﺘَﻛ il a écrit َﺐِﺘُﻛ Il a été écrit
ٌﺐُﺘُﻛ des livres
Chapitre
14
1.
Introduction
L’aspect central et essentiel dont la compréhension de textes consiste à établir des connexions entre les différentes entités du texte à partir d’autre dans le discours. Ces connexions signalées généralement par les anaphores.
L’anaphore est un phénomène abstrait qui utilise une forme abstraite liés à une langue, c’est une relation linguistique entre deux entités textuelles qui est définie quand une entité textuelle (l'anaphore) se réfère à une autre entité du texte qui se produit habituellement avant (l’antécédent) [HAM, al, 09]. La détermination et l’identification des entités référés par les pronoms et les verbes, est l’une des challenges du TLAN. En effet, la résolution des anaphores est considéré comme une tâche importante dans plusieurs applications de TLAN telles que l’extraction d’information, résumé des textes, les systèmes question-réponse et autres. La plupart des travaux sur l’anaphore ont été réalisés pour l’anglais et le français, mais malheureusement restent insuffisants pour notre langue arabe.
Dans ce chapitre, nous abordons l’anaphore en termes de notions de base, ainsi que les différents types d’anaphores dans la langue arabe.
2.
Notions de base
Les définitions dans le domaine des anaphores ne sont pas aussi figées que l’on pourrait le croire. Il est en effet difficile de bien cerner la nature des éléments qui participent à une relation anaphorique, ainsi que la nature de la relation elle-même. Le flou terminologique qui en résulte a des conséquences sur la définition des tâches de traitement automatique de ces phénomènes.
Les mots, ou plus précisément les unités lexicales, des langues naturelles sont classifiés selon leur catégorie syntaxique. Les unités lexicales se combinent (en fonction de leurs catégories) pour former des groupes syntaxiques (ou syntagmes). Les groupes de types différents ne font pas référence au monde de la même façon. Par exemple, les groupes verbaux ne représentent pas le même type d'entités que les groupes nominaux. Ces deux sortes de référence sont distinctes.
Le référent d'une unité lexicale est la partie du monde ou l'entité à laquelle cette unité est associée. Celui-ci peut être de nature abstraite ou concrète [SAH, 11].
Les unités lexicales de la langue ne peuvent avoir pour référent n'importe quelle entité du monde : les groupes nominaux un homme et une femme, par exemple, désignent des entités différentes. La langue impose des contraintes sur la référence de ses unités lexicales et les distingue en spécifiant le type d'entité que chacune peut désigner. Un type correspond à l'ensemble des propriétés qu'une entité doit représenter pour être le référent d'une unité lexicale donnée. Par exemple, pour être le référent de
15
l'unité lexicale homme, une entité doit posséder un ensemble de propriétés, parmi lesquelles se trouvent être humain et de sexe masculin [SAH, 11].
Avec cette définition de la notion de référence à l'esprit on procédera à une considération de deux relations qui en dépendent : la coréférence et l'anaphore. La coréférence est une relation linguistique qui s'établit entre deux unités lexicales qui ont la même référence. Dans ce suit on discute la relation qui nous intéresse, l’anaphore [SAH, 11].
La définition classique des anaphores est donnée par Halliday et Hasan [HAL, al, 76] basé sur la notion de la cohésion : « l'anaphore est une cohésion (présupposition) qui se dirige de nouveau à un certain élément précédent ».Dans un discours, à l'oral ou à l'écrit, on fait souvent référence à un même objet, fait, action ou événement de façon répétitive. Mais on ne l'évoque pas toujours de la même façon. Ceci évite la répétition inutile d'informations et assure la cohérence de notre discours. L'usage de pronoms pour la reprise d'éléments mentionnés précédemment dans un discours met en jeu la relation d'anaphore.
L'anaphore existe entre deux unités lexicales quand l'interprétation de l'une nécessite la présence de l'autre. Milner considère que les pronoms sont dépourvus de référence virtuelle propre, qu'ils ne sont pas référentiellement autonomes. Cela veut dire qu'ils ne sont pas capables de déterminer leur propre référent. [SAH, 11].
3.
Les types d’anaphores en langue arabe
L’expression anaphorique peut être une des catégories linguistiques suivante : pronoms, verbes, noms ou description. Par conséquent dans la langue arabe, on distingue [HAM, al, 09].
3.1.
Anaphore verbale
Elle dépende de l’utilisation du verbe (faire – ﺍﻮﻠﻌﻔﻳ ﻞﻌﻓ- ) qui représente un verbe dénotant un processus, pour minimiser l’écriture et éviter les répétitions.
Exemple :
ﺍ ﻢﻫﺪﺣﻭ ﻢﻬﻓ (ﺍﻮﻠﻌﻔﻳ) ﻢﻟ ﻥﺈﻓ ﺩﺪﺤﻤﻟﺍ ﺪﻋﻮﻤﻟﺍ ﻲﻓ ﻢﻬﺗﺎﺒﺟﺍﻭ ﻢﻴﻠﺴﺗ (ﺏﻼﻄﻟﺍ) ﻰﻠﻋ ﺐﺠﻳ
ﻥﻮﻣﻮﻠﻤﻟ
•
Anaphore : ﺍﻮﻠﻌﻔﻳ
•
Référent : ﺏﻼﻄﻟﺍ
3.2.
Anaphore lexicale
Est réalisé quand les expressions référés sont des descriptions définies ou des noms propres, d’après [HAM, al, 09], « ces expressions sont utilisées pour incrémenter la cohésion du texte et donner extra informations.
16 Exemple :
ﺮﺟﺎﻫ ﻢﺛ ﺲﻧﻮﺗ ﻲﻓ (ﻥﻭﺪﻠﺧ ﻦﺑﺍ) ﺪﻟﻭ
)
ﺮﺼﻣ ﻰﻟﺇ(ﺔﻣﻼﻌﻟﺍ
•
Anaphore : ﺔﻣﻼﻌﻟﺍ
•
Référent : ﻥﻭﺪﻠﺧ ﻦﺑﺍ
3.3.
Anaphore comparative
Elle se base sur une relation de tout à partie. Elle se réalise par utilisation de termes ""ﻯﺮﺧﺃ ,ﺮﺧﺁpour se réfère aux unités précédemment mentionnées dans le texte.
Exemple : ﻰﻟﺎﻌﺗ ﻝﺎﻗ
"
ٌﺔَﻳﺁ ْﻢُﻜَﻟ َﻥﺎَﻛ ْﺪﻗ
ﻯ َﺮْﺧُﺃَ) ﻭ ِ ّO ِﻞﻴِﺒَﺳ ﻲِﻓ ُﻞِﺗﺎَﻘُﺗ ٌﺔَﺌِﻓ ﺎَﺘَﻘَﺘْﻟﺍ ِﻦْﻴَﺘَﺌِﻓ ﻲِﻓ
(
ﺓ َﺮِﻓﺎَﻛ
2
"
•
Anaphore : ﻯ َﺮْﺧُﺃ
•
Référent : ٌﺔَﺌِﻓ
3.4.
Anaphore pronominale
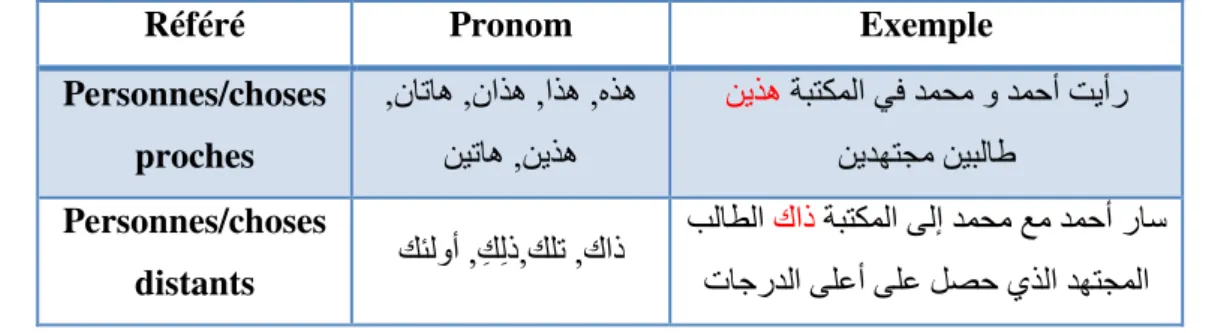
C’est l’anaphore le plus utilisé en arabe, C'est une reprise d'un terme à travers différents types des pronoms tels que pronoms. D’après [HAM, al, 09] « les pronoms forment une classe spéciale d’anaphore en raison de leur structure sémantique vide ; elles ont une signification indépendante de ses antécédents», ces pronoms peuvent êtres : les pronoms personnels de troisième personne (ﺐﺋﺎﻐﻟﺍ ﺮﺋﺎﻤﺿ), pronoms démonstratifs (ﺓﺭﺎﺷﻹﺍ ءﺎﻤﺳﺃ) ou pronoms relatifs (ﺔﻟﻮﺻﻮﻤﻟﺍءﺎﻤﺳﻷﺍ).
L’anaphore pronominale comprend trois types de pronoms :
3.4.1
Les pronoms personnels de troisième personne (ﺐﺋﺎﻐﻟﺍ ﺮﺋﺎﻤﺿ)
Constituent de deux types, disjoint et joints pronoms personnels, le tableau ci-dessous illustre ces types
Exemple :
Pronoms disjoints
Type Description Exemple
Nominative ،ﻮﻫ) ﻊﻓﺭ ﻞﺤﻣ ﻲﻓ ﻞﺼﻔﻨﻣ ﺮﻴﻤﺿ ،ﻲﻫ ،ﻦﻫ ،ﺎﻤﻫ ﻢﻫ ( ﻚﻠﺳ ﺚﻴﺣ ﺍﺮﻜﺒﻣ ﺔﺳﺭﺪﻤﻟﺍ ﻰﻟﺇ ﺪﻤﺣﺃ ﺐﻫﺫ ﻮﻫ ﻪﻠﻴﻣﺯ ﻭ ﻖﻳﺮﻄﻟﺍ ﺪﻤﺤﻣ ﺮﺴﻳﻷﺍ Accusative ﺐﺼﻧ ﻞﺤﻣ ﻲﻓ ﻞﺼﻔﻨﻣ ﺮﻴﻤﺿ ،ﻩﺎﻳﺇ) ،ﺎﻫﺎﻳﺇ ﺎﻤﻫﺎﻳﺇ ، ،ﻢﻫﺎﻳﺇ (ﻦﻫﺎﻳﺇ ﺎﻫﺎﻳﺇﻪﺘﻳﺪﻫﺄﻓ ﺎﻬﺘﻤﺳﺭ ﻲﺘﻟﺍ ﺔﺣﻮﻠﻟﺎﺑ ﺪﻤﺣﺃ ﺐﺠﻋﺃ
Tableau 03 :Pronoms troisième personne(A)
17
Pronoms joints
Type Description Exemple
Nominative ﻒﻟﺃ) ﻊﻓﺭ ﻞﺤﻣ ﻲﻓ ﻞﺼﺘﻣ ﺮﻴﻤﺿ ﻋﺎﻤﺠﻟﺍ ﻭﺍﻭ ،ﻦﻴﻨﺛﻻﺍ ﺔ ، (ﺓﻮﺴﻨﻟﺍ ﻥﻮﻧ ﺍﺮﻜﺒﻣ ﺔﺳﺭﺪﻤﻟﺍ ﻰﻟﺇﺎﺒﻫﺫ ﺪﻤﺤﻣ ﻭ ﺪﻤﺣﺃ Accusative ﺐﺼﻧ ﻞﺤﻣ ﻲﻓ ﻞﺼﺘﻣ ﺮﻴﻤﺿ ﺪﻤﺤﻣ ﻪﻠﻴﻣﺯﻪﻠﺑﺎﻗ ﺚﻴﺣ ﺔﺳﺭﺪﻤﻟﺍ ﻰﻟﺇ ﺪﻤﺣﺃ ﺭﺎﺳ Génitif ﺮﺟ ﻞﺤﻣ ﻲﻓ ﻞﺼﺘﻣ ﺮﻴﻤﺿ ،ﻩ) ،ﺎﻫ ،ﺎﻤﻫ ،ﻢﻫ ،ﻦﻫ ءﺎﻳ ،ﻢﻠﻜﺘﻤﻟﺍ ﻑﺎﻛ (ﺔﺒﻁﺎﺨﻤﻟﺍ ﺑ ﻖﺤﻟ ﻭ ﺔﺳﺭﺪﻤﻟﺍ ﻰﻟﺇ ﺪﻤﺣﺃ ﺭﺎﺳ ﻪ ﻪﻠﻴﻣﺯ ﺪﻤﺤﻣ
Tableau 03 : Pronoms troisième personne(B)
3.4.2
Les pronoms relatifs (
ﺔﻟﻮﺻﻮﻤﻟﺍ
ءﺎﻤﺳﻷﺍ
)
Hammami, Belguith et Hamadou dans [HAM, al, 09] commentent : « les pronoms relatifs en arabe sont toujours anaphorique et désignent immédiatement le nom de phrase mentionné en avant». Ils sont classifiés en singulier (ﻱﺬﻟﺍ,ﻲﺘﻟﺍ), duel (ﻦﻳﺬﻠﻟﺍ, ﻦﻴﺘﻠﻟﺍ ,ﻥﺍﺬﻠﻟﺍ ,ﻥﺎﺘﻠﻟﺍ) ou pluriel (ﻲﺗﺍﻮﻠﻟﺍ, ﻲﺋﻼﻟﺍ ,ﻲﺗﻼﻟﺍ ,ﻦﻳﺬﻟﺍ).
Exemple : Les phrases suivantes montrent des exemples sur ces pronoms
ﻲﺘﻟﺍ)(ﺔﺳﺭﺪﻤﻟﺍ) ﻰﻟﺇ ﺪﻤﺣﺃ ﺐﻫﺫ
(
ﺭﻭﺎﺠﺗ
ﻪﻟﺰﻨﻣ
ﻩﺪﻋﺎﺳ (ﻱﺬﻟﺍ)(ﻞﺟﺮﻟﺍ) ﺪﻤﺣﺃ ﺮﻜﺷ
• Anaphore :ﻲﺘﻟﺍ
•Référent :
ﺔﺳﺭﺪﻤﻟﺍ
• Anaphore :ﻱﺬﻟﺍ
•Référent :
ﻞ
ﺟﺮﻟﺍ
3.4.3
Les pronoms démonstratifs (ﺓﺭﺎﺷﻹﺍ ءﺎﻤﺳﺃ)
L’utilisation de pronoms relatifs est possible si l’antécédent dénote un processus ou une situation, et ici l’anaphore désigne une partie de ces significations lexicales. Ils se référant aux personnes, places ou choses proches distants, le tableau ci-après illustre ce type de pronoms.
Exemple : Référé Pronom Exemple Personnes/choses proches ,ﻥﺎﺗﺎﻫ ,ﻥﺍﺬﻫ ,ﺍﺬﻫ ,ﻩﺬﻫ ﻦﻴﺗﺎﻫ ,ﻦﻳﺬﻫ ﺔﺒﺘﻜﻤﻟﺍ ﻲﻓ ﺪﻤﺤﻣ ﻭ ﺪﻤﺣﺃ ﺖﻳﺃﺭ ﻦﻳﺬﻫ ﻦﻳﺪﻬﺘﺠﻣ ﻦﻴﺒﻟﺎﻁ Personnes/choses distants ﻚﺌﻟﻭﺃ , ِﻚِﻟﺫ,ﻚﻠﺗ ,ﻙﺍﺫ ﺔﺒﺘﻜﻤﻟﺍ ﻰﻟﺇ ﺪﻤﺤﻣ ﻊﻣ ﺪﻤﺣﺃ ﺭﺎﺳ ﻙﺍﺫ ﺐﻟﺎﻄﻟﺍ ﺕﺎﺟﺭﺪﻟﺍ ﻰﻠﻋﺃ ﻰﻠﻋ ﻞﺼﺣ ﻱﺬﻟﺍ ﺪﻬﺘﺠﻤﻟﺍ
18 Référé Pronom Exemple Places proches ﺎﻨﻫ ﺍﻭﺪﻋﺃ ﻭ ﺔﺒﺘﻜﻤﻟﺍ ﻲﻓ ﺏﻼﻄﻟﺍ ﺎﻧﺭﺍﺯ ﺔﺑﻮﻠﻄﻤﻟﺍ ﺮﻳﺭﺎﻘﺘﻟﺍ ﺎﻨﻫ Places distants ﻚﻟﺎﻨﻫ , ﻙﺎﻨﻫ ﻞﺑﺎﻗ ﻙﺎﻨﻫ ﻭ ﺔﺳﺭﺪﻤﻟﺍ ﻰﻟﺇ ﺪﻤﺣﺃ ﺐﻫﺫ ﺪﻤﺤﻣ ﻪﻠﻴﻣﺯ
Tableau 04 : Les pronoms démonstratifs(B)
Figure 6 : Représentation des pronoms concernés par l’anaphore pronominale
4.
Résolution d’anaphores en arabe
La résolution d’anaphore est considérée comme une des tâches principale du TLAN. Ce processus est concerné par la recherche de référence d'un groupe nominal qui doit être interprété par rapport à un élément apparaissant avant lui dans le discours. Ce groupe nominal peut être un verbe, un nom avec un déterminant (groupe nominal plein), un pronom personnel, un pronom démonstratif ou relatif.
Il existe plusieurs systèmes de résolution d’anaphore pour l’anglais et le français et avec des performances considérables, malheureusement, ce n’est pas le cas pour la langue arabe qui rencontre moins des travaux dans ce domaine à cause de différences syntaxiques, morphologiques et sémantiques.
Anaphore
Pronominale
19
5.
Problèmes de résolution anaphoriques en arabe
Au-delà des difficultés traditionnelles de traitement automatique de la langue pour l’anglais, il existe plus de complexités pour la langue arabe qui met les travaux sur la résolution anaphorique plus compliquée que d’autres langues. Dans cette partie, nous aurons présentés quelques problèmes rencontrés pour la résolution d’anaphore en arabe [MAH, al, 11].
L’absence de voyelles : La plupart des documents arabes sont non voyelles. En effet, les voyelles ne sont utilisées que dans certains ouvrages scolaires pour débutants et dans le Coran. Un texte arabe non voyelle est fortement ambigu. En effet, 74% des mots qui le composent acceptent potentiellement plus d’une voyellation lexicale et 89,9% des noms qui le constituent acceptent potentiellement plus d’une voyelle casuelle. En effet, en absence de voyelles, il est obligé d’utiliser la sémantique qui reste aussi autre une tâche difficile.
La structure complexe de phrase arabe : l’arabe reconnu une complexité morphologique remarquable, d’où il est possible de combiner plusieurs unités lexicales en même mot, prenons l’exemple « ﻢﻫﺎﻨﻴﺠﻧﺍ » dans ce cas nous devons casser la phrase pour obtenir le sujet avant de commencer le processus de résolution d’anaphore.
La liberté de l’ordre de mots : L’ordre des mots en arabe est relativement libre. De manière générale, on met au début de la phrase le mot sur lequel on veut attirer l’attention et l’on termine sur le terme le plus long ou le plus riche en sens ou en sonorité. Cet ordre provoque des ambiguïtés syntaxiques artificielles dans la mesure où il faut prévoir dans la grammaire toutes les règles de combinaisons possibles d’inversion de l’ordre des mots dans la phrase.
L’ambiguïté de l’antécédent : par fois les algorithmes de résolution ont échouent à le correct antécédent à cause de son ambiguïté, dans ces cas, la présence d’extra informations est nécessaire, par exemple,
« ﺪﻌﺑ ﺞﻀﻨﺗ ﻢﻟ (ﺎﻫ)ـﻧﺍ ﻦﻣ ﻢﻏﺮﻟﺎﺑ ﺔﻌﺋﺎﺟ (ﺎﻫ)ـﻧﻻ (ﺓﺯﻮﻤﻟﺍ) (ﺔﻠﻔﻄﻟﺍ)ﺖﻠﻛﺍ»
Ici les pronoms (ﺎﻫ) réfèrent à deux choses différentes (ﺔﻠﻔﻄﻟﺍ) ou (ﺓﺯﻮﻤﻟﺍ), chacune de ces pronoms seront interprétées correctement par emploi de la connaissance que la fille (humain) est affamé et le bananas (fruit) est maturité.
L’antécédent caché : Dans certaines situations, le pronom peut se référé une unité qui n’est pas présentée dans le texte, dans l’exemple « (ﻮﻫ) ﻻﺍ ﺎﻬﻤﻠﻌﻳ ﻻ ﺐﻴﻐﻟﺍ ﺢﺗﺎﻔﻣ ﻩﺪﻨﻋﻭ », le pronom (ﻮﻫ) désigne « Allah ».
Manque de corpus annotés par des liens anaphoriques : ça reste le problème majeur, en effet il est nécessaire et demandé dans la plupart des systèmes du TLAN. Le processus d’annotation des liens anaphoriques consume beaucoup ressources en termes de temps et des humains
20
annotateurs. L’existence de tel corpus encourage et améliore le processus de résolution d’anaphore.
6.
Méthode de résolution
Le fait que la résolution d'anaphore soit un problème compliqué dans le traitement du langage naturel a attiré l'attention de beaucoup de chercheurs. La plupart des approches traditionnelles se basent fortement sur la connaissance linguistique. Tandis que les approches alternatives sont statistiques. Dans cette partie, les travaux précédents traditionnels et statistiques seront présentés. A noter que tous ces travaux sont effectués pour l’anglais et autres langue latins, sauf (Miktov, 1998) qui est le seul travail sur la résolution d’anaphores arabes.
Hobbs : J Hobbs [HOB, 78] a élaboré un algorithme sur la base de contraintes imposées par
la syntaxe de l'anglais. L'algorithme prend en entrée un arbre syntaxique complet et correct qu'il parcourt à la recherche d'antécédents en leur appliquant diverses contraintes syntaxiques et morphologiques. Au niveau intraphrastique, l'algorithme consiste en un parcours en largeur de gauche à droite avec une préférence pour l'antécédent le plus proche de l'anaphore. Un parcours en largeur est aussi effectué au niveau interphrastique, avec une préférence pour les sujets comme antécédents. En effectuant le parcours, l'algorithme fait l'inventaire des antécédents possibles, qu'il vérifie ensuite en appliquant des contraintes d'accord morphologique (traits de genre et nombre).Les pronoms traités par cet algorithme sont les pronoms personnels he, she, it et they. Le taux de réussite global était assez élevé (le taux est le nombre d'anaphores trouver sur le nombre totale des anaphores), il est de 88.3%. Cependant, il échoue sur certains cas, tels que la reprise d'éléments phrastiques tels que : Salim avait des ennuis et il (le) savait.
Lappin et Leass :S. Lappin et H.J. Leass [LAP, al, 94] proposent un algorithme pour
l'identification des antécédents nominaux de pronoms de troisième personne (he, she, they, it) et d'anaphores réflexives et réciproques (himself, herself, themselves, itself) en anglais. L'algorithme se base sur l'utilisation d'informations de nature syntaxique et morphologique. Il utilise un modèle qui calcule dynamiquement la saillance d'un antécédent potentiel sur la base de différents facteurs. A chaque facteur est attribué un indice différent selon son utilité dans la procédure de résolution. Cette mesure de saillance pondérée est utilisée afin de classer les candidats potentiels pour déterminer une préférence. Ensuite, un filtre de contraintes21
morphologiques et syntaxiques élimine les candidats qui ne satisfont pas les contraintes de la théorie du liage ou les contraintes d'accord de genre et nombre.
Une implémentation de l'algorithme a été effectuée en Prolog et testée sur un corpus de manuels informatiques. Les tests ont donné un taux de réussite de 86%, 4% de plus que l'algorithme de Hobbs sur le même corpus.
Mitkov : Le principe de l'algorithme de R. Mitkov [RUS, al, 02]
est de minimiser l'utilisation de données syntaxiques et sémantiques, qui sont assez coûteuses en termes de développement, pour la résolution d'anaphores. Le but est de faciliter l'implémentation tout en assurant un bon taux de réussite sur le traitement de manuels techniques, et de permettre l'adaptation d'une langue à l'autre. Cette approche ne nécessite ni analyse syntaxique ni analyse sémantique, mais prend simplement en entrée la sortie d'un étiqueteur morpho- syntaxique. L'algorithme consiste en l'application de simples heuristiques préférentielles (antecedent indicators) basées sur des données empiriques.7.
Domaines d’applications de la résolution des anaphores
La résolution d’anaphores est considérée comme une tache très importante pour un certain nombre des applications du TLAN, parmi ces applications [SAH, 11]
La traduction automatique
La majorité de systèmes de traduction automatique ne traitent pas la résolution d'anaphore et leur réussie habituellement ne dépasse pas le niveau de phrase. La complexité est due aux anomalies de genre à travers les langages, pour numéroter des anomalies des mots dénotant le même concept, aux anomalies dans la transmission de genre des pronoms possessifs et anomalies dans la sélection de l'anaphore de la langue cible. Ce dernier peuvent être vus par fait que quoique dans la plupart des cas le pronom dans la langue source soit traduit par un pronom de langue cible (l'équivalent de traduction de l'antécédent du pronom de langue source au lequel correspond dans le genre et le nombre), là sont quelques langages dans lesquels le pronom est souvent traduit directement par son antécédent (Malais). En plus, des anaphores pronominales souvent sont elliptiquement omis dans le langage cible (espagnol, italien, japonais, coréen).
22
Extraction de l'information
La résolution d'anaphore dans l'extraction de l'information a pu être considérée en tant qu'élément des plus tâche générale de la résolution de coréférence qui prend la forme de fusionner des données partielles objecte les entités à peu près identiques, les rapports d'entité, et les événements décrits à différent positions de discours.
Résumé automatique
Le but d’un résumé automatique de texte est de produire une représentation abrégée d'un ou de plusieurs documents. Des chercheurs dans le résumé automatique se sont intéressés à la résolution des anaphores puisque les techniques pour extraire des phrases importantes sont plus précises si des références anaphoriques des concepts/groupes nominaux sont résolues.
8.
Conclusion
Dans ce chapitre nous avons présenté une des tâches importantes de traitement automatique de la langue naturelle qui est la résolution des anaphores. Son but est de déterminer pour un pronom, ou une structure quelconque son antécédent approprié pour établir la cohérence dans les textes. Du fait de son importance, plusieurs recherches et implémentations ont été effectuées pour réaliser la résolution anaphorique pour les différentes langues du monde surtout l’anglais et latins. Cependant, les travaux destinés pour notre langue l’arabe, restent encore insuffisantes à cause de sa particularité et complexité morphologique et syntaxique.
Dans le prochain chapitre, nous allons détailler le processus de résolution d’anaphores du point de vue technique et architecturel.
Chapitre
Conception et Architecture
d’AraPhore
24
d’AraPhore
1.
Introduction
La résolution des anaphores est une branches très active du domaine du Traitement automatique des langues (TAL). Ce phénomène est très répandu dans les langues naturelles.
En effet, plusieurs outils de résolution des anaphores ont été développés pour des langues naturelles surtout l’anglais et le fronçais, mais ce n’est pas le cas pour la langue arabe, qui propose peu de travaux dans ce domaine.
Le but de notre recherche est de contribuer au développement de l'automatisation de la langue arabe par le biais de proposer un formalisme de résolution de problème d’anaphore.
Ce chapitre est consacré à la description et à la présentation de l’outil mis en œuvre à travers la conception et l’architecture élaborée, ainsi que les ressources utilisées.
2.
Conception et architecture générale d’AraPhore
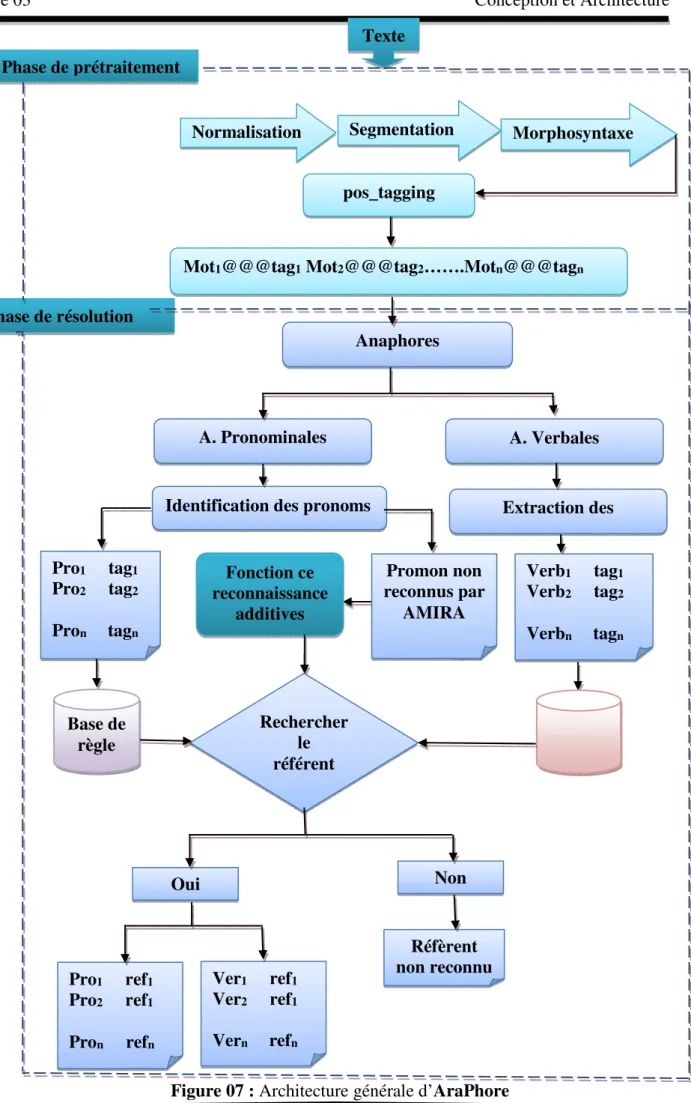
Nous décrivons dans cette section l’architecture générale de notre outil, dans le but de mettre en place une application en traitement automatique qui permettra d’identifier les anaphores d’un texte arabe en indiquant leur réfèrent.
Le processus de réolution anaphorique proposé est acheminé en deux phase prancipales La phase de prétraitement
La phase de résolution
25 d’AraPhore Texte Phase de prétraitement Phase de résolution Anaphores pos_tagging
Mot1@@@tag1 Mot2@@@tag2…….Motn@@@tagn
Normalisation Segmentation
ion Morphosyntaxe
A. Verbales A. Pronominales
Extraction des Identification des pronoms
Pro1 tag1 Pro2 tag2 Pron tagn Promon non reconnus par AMIRA Verb1 tag1 Verb2 tag2 Verbn tagn Fonction ce reconnaissance additives Rechercher le référent Base de règle Pro1 ref1 Pro2 ref1 Pron refn Ver1 ref1 Ver2 ref1 Vern refn Oui Non Réfèrent non reconnu
26
d’AraPhore
3.
Phase de prétraitement
Considéré comme une première étape dans le processus globale, dans laquelle le texte arabe est normalisé, segmenté et étiqueté en utilisant l’outil AMIRA 2.0.
3.1.
Présentation d’AMIRA
C’est un analyseur gratuit développé en perl par l'équipe de Mona Diab en 2010 à l'université de Columbia New York.
AMIRA est un package développé sur les systèmes Linux, et constitué des modules séparés destinés pour le traitement de scripts arabes (en buckwalter, UTF-8 ou CP-1256), il permet de générer une version tokenisé, POS tagged et Chunked de fichier texte. Ce système est entrainé et testé sur le corpus Arabic Tree Bank ATB 3 2.0 et ATB 2 V2.0.
3.2.
Pourquoi AMIRA ?
Notre choix est porté sur la boite à outils AMIRA pour deux raisons majeurs, à savoir :
AMIRA obtient des résultats performants au niveau de la segmentation (99.2%) et une précision de plus de 96% au niveau de l'étiquetage [GHO, 11].
AMIRA est gratuit (Free)
3.3.
Les phases de Pré traitement
♣ Normalisation : Afin de manipuler les variations du texte qui peuvent être représentées en arabe, une normalisation de texte est nécessaire par remplacer hamza ﺉ،ء،ﺅ،ﺁ،ﺇ،ﺃ par ﺍ et aussi Remplacer ﻯ par ﻱ et aussi supprimer des signes de vocalisation.
♣ Segmentation
: La segmentation consiste à identifier les préfixes, la racine et les suffixes
forment un mot. Au cours de notre recherche, nous avons essayé d’élaborer un algorithme de segmentation en se basant sur des règles qui s’appuient sur des listes de clitiques (d'enclitiques, proclitiques), préfixes, suffixes et racines
♣ Analyse morphosyntaxique
: L’analyse morphosyntaxique est axée sur l’étude des
particularités morphologiques (la forme) et syntaxiques (la fonction) des unités formant le texte en entré. D’à affecter des étiquettes morphosyntaxiques propres à chaque mot du texte segmenté.
Le résultat obtenu d’AMIRA est présenté sous forme de fichiers de tokenisation (.amiratok) et de postagging (.amirapos) illustré par les figures suivantes :
27 d’AraPhore Exemple : ُﺐﻴِﻧُﺃ ِﻪْﻴَﻟِﺇ َﻭ ﺖْﻠﱠﻛ َﻮَﺗ ِﻪْﻴَﻠَﻋ ِ ﱠFَﺎِﺑ ﱠﻻﺇ ﻲِﻘﻴِﻓ ْﻮَﺗ ﺎَﻣ َﻭ" ﻰﻟﺎﻌﺗ ﻝﺎﻗ " 3 3 88 ﺔﻳﻵﺍ "ﺩﻭﻫ" ﺓﺭﻭﺳ
Figure 08 :Traitement effectué par AMIRA Texte entrée Normalisation Morphosyntaxique Postagging Mot Mot1@@@Tag1 Mot2@@@Tag2 ……..Motn@@@Tagn Lemnien voyelles Segmentation
Préfixe + Racine + Suffixe
Figure 09 :Exemple de traitement effectué par AMIRA
ُﺐﻴِﻧُﺃ ِﻪْﻴَﻟِﺇ َﻭ ﺖْﻠﱠﻛ َﻮَﺗ ِﻪْﻴَﻠَﻋ ِ ﱠmَﺎِﺑ ﱠﻻﺇ ﻲِﻘﻴِﻓ ْﻮَﺗ ﺎَﻣ َﻭ" ﻰﻟﺎﻌﺗ ﻝﺎﻗ " ﺐﻴﻧﺃ ﻪﻴﻟﺇ ﻭ ﺖﻠﻛﻮﺗ ﻪﻴﻠﻋ ﷲ ﺏ ﻻﺇ ﻲﻘﻴﻓﻮﺗ ﺎﻣ ﻭ " ﻰﻟﺎﻌﺗ ﻝﺎﻗ " ﻝﺎﻗ VBD_MS3@@@ ﻰﻟﺎﻌﺗ VBD_MS3@@@ PUNC@@@" ﻭ CC@@@ ﺎﻣ WP@@@ ﻲﻘﻴﻓﻮﺗ VBP_FS3@@@ ﻻﺇ NN@@@ ﺏ IN@@@ ﷲ NNP@@@ ﻪﻴﻠﻋ VBG_PRP_MS3@@@ ﺖﻠﻛﻮﺗ VBD_FS3@@@ ﻭ CC@@@ ﻪﻴﻟﺇ NN_PRP_MS3@@@ ﺐﻴﻧﺃ PUNC@@@"NN@@@ Normalisation Segmentation Pos tagging ﻻﺇ ﻲﻘﻴﻓﻮﺗ ﺎﻣ ﻭ " ﻰﻟﺎﻌﺗ ﻝﺎﻗ ﷲ ﺏ ﺐﻴﻧﺃ ﻪﻴﻟﺇ ﻭ ﺖﻠﻛﻮﺗ ﻪﻴﻠﻋ "
28
d’AraPhore
Entrée : texte (ensemble de mots) Sortie : <Anaphore, référent>
- Analyse morphosyntaxique (texte) retourne < unité, tag> <unité, tag> = AMIRA (texte)
- Extraction des anaphores < unité, tag> Sélectionner les tags de type (DT_) - Résolution des anaphores <unité, tag>
Pour chaque tag de type pronoms démonstratifs rechercher son référent dans le texte - Liste des mots possible = règle<anaphore>
- Suivent choisi = recherche en avant (pronoms démonstratifs, liste des mots possibles, texte) - Résultat final : sortie <Anaphore, Antécédent choisi>
4.
Phase de résolution
L’anaphore est un mot ou un syntagme dans un énoncé qui assure une reprise sémantique qu’en appelé réfèrent, notre étude s’intéresse à la résolution de deux types d’anaphore, à savoir : les anaphores
pronominales et les anaphores verbales.
En se basant sur les résultats obtenus par l’outil AMIRA, qui est présenté sous forme <unité, tag>, l’ensemble des pronoms et des verbes (relatifs, démonstratifs, personnels et verbe faire (ﻞﻌﻓ)) et ses tags en ERTS_PERE (WP, DT_, PRP_, VBP_), est extraites afin de sélectionner parmi les mots du texte celle qui est le référent suivant les règles linguistiques.
4.1.
Résolution de l’anaphore pronominale
Cette résolution concerne différents types, pronoms démonstratifs, pronoms personnelles et pronoms relatif.
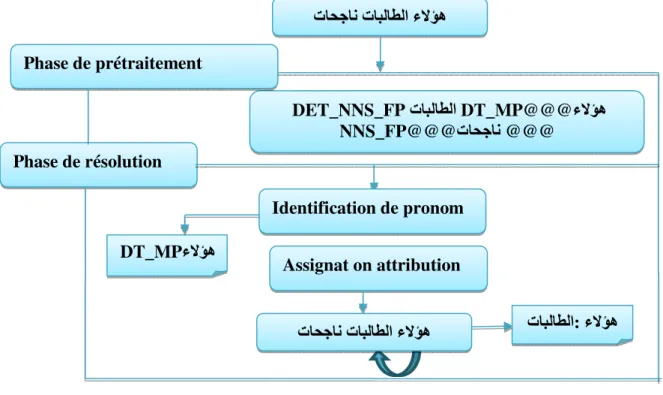
4.1.1 Résolution des anaphores pronominales de Types démonstratifs (ﺓﺭﺎﺷﻹﺍ ءﺎﻤﺳﺃ)
Algorithme
Cet algorithme est base sur deux parties : la Première est l’Analyse morphosyntaxique qui va extraire les postagging de chaque mot dans le texte (un traitement effectué par AMIRA), la deuxième partie consiste à situé les pronoms démonstratifs dans le texte ainsi que les référents de chaque pronom en effectuant une recherche en avant. Pour cette raison nous appliquons la règle suivante :
« Le référent de pronom démonstratif est situé après le pronom et de type tag référent et doit être conforme en nombre et type. »
Le pseudo code suivant décrit l’algorithme de résolution des pronoms démonstratif.