Optimizing FOL reducible query answering
Texte intégral
Figure



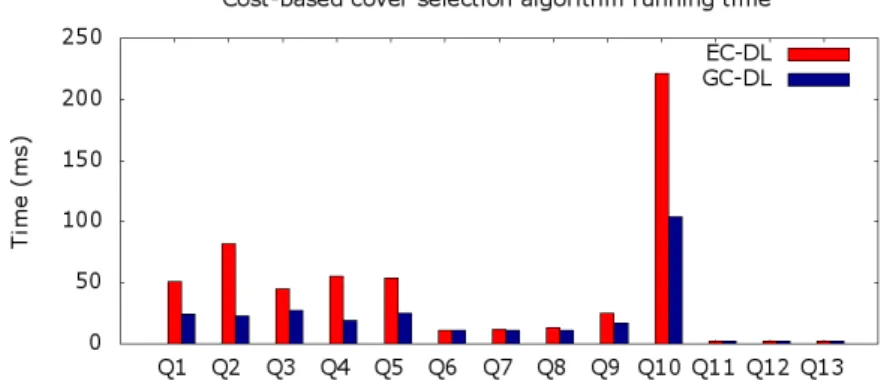
Documents relatifs
In particular, in [12], besides the AR semantics, three other inconsistency-tolerant query answering semantics are proposed, including the approximate intersection of repairs
In this talk, we focus on rule-based ontol- ogy languages, and we demonstrate the tight connection between classical and consistent query answering.. More precisely, we focus on
Our experiments using the realistic ontologies and datasets in the EBI linked data platform have shown that PAGOdA is ca- pable of fully answering queries over highly complex
In this work, which is a short version of [10], we performed an in-depth complexity analysis of the problem of consistent query answering under the main decidable classes of
For example, the function S ⊥ that always returns an empty set of finite po- sitions, WChS(S ⊥ ) is the class of sticky programs, because stickiness must hold no matter what
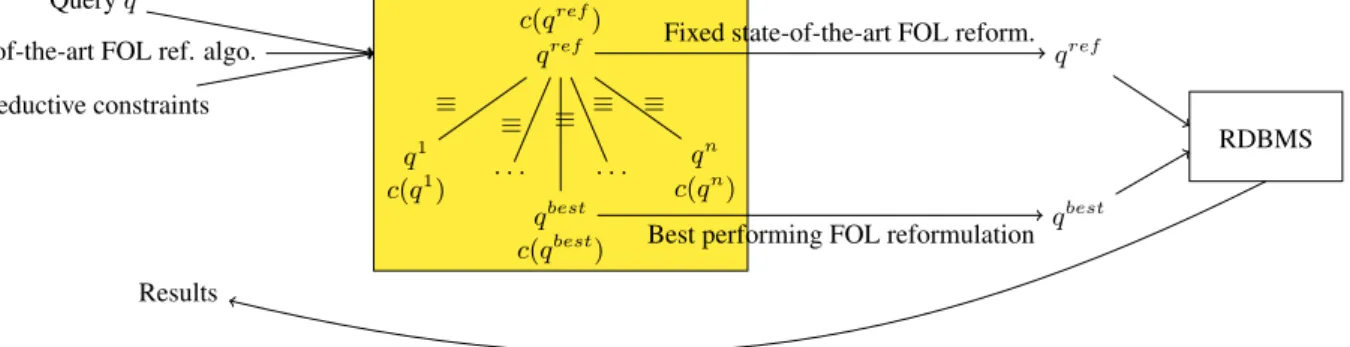
In particular, query answer- ing techniques based on FOL reducibility, e.g., [1,2,5,6,7], which reduce query an- swering against a knowledge base (KB) to FOL query evaluation
Since such atoms are not given as input, we address the problem of (e ffi ciently) computing such restricting atoms within an approximate query answering algorithm after showing
While in the combined complexity this task remains 2E XP T IME -complete, in case of fixed arity and fixed sets of rules, we observe the classical positive effect of restricting
