Évaluation de la validité et de la fiabilité des indices de
contrôle parlementaire
Mémoire
N’tcha Judicaël Moutangou
Maîtrise en science politique
Maître ès arts (M.A.)
Québec, Canada
Évaluation de la validité et de la fiabilité des indices de
contrôle parlementaire
Mémoire
N’tcha Judicaël Moutangou
Sous la direction de :
Résumé
Dans cet essai, nous testons la validité et la fiabilité des indicateurs de performance du contrôle parlementaire. Par validité nous nous référons à la validité de contenu, à la validité de construit et à la validité manifeste. La fiabilité porte sur la cohérence interne et la consistance. En employant à la fois une analyse qualitative et une analyse quantitative, nous montrons que, dans l’analyse qualitative, chacun des indices sélectionnés mesure un phénomène précis qui est différent du cadre référentiel proposé par l’UIP. Ce cadre n’évalue que l’autonomie et l’influence du parlement sur l’exécutif alors que l’IPA évalue le contrôle et la surveillance budgétaire, le PPI examine les différents pouvoirs des parlements sur l’exécutif, l’indice de Wehner capte la capacité du contrôle législatif sur les budgets et l’indice d’Imbeau-Stapenhurst évalue les processus, les capacités et les méthodes de travail des parlements dans le contrôle budgétaire.
Bien que ces indices appréhendent différents phénomènes nous avons utilisé aussi l’analyse quantitative pour vérifier leur validité et leur fiabilité. Les résultats montrent que pour les indices dont nous avons pu obtenir les données, ceux-ci sont partiellement valides. Il existe des items corrélés qui peuvent être éliminés dans le calcul de ces indices. Par contre, en ce qui concerne la fiabilité, ces indices affichent une bonne cohérence interne, mais la consistance ou la fiabilité inter-juge est faible. Nous suggérons aux constructeurs d’indices de toujours procéder à la vérification de leur fiabilité et de leur validité.
Abstract
In this essay, we test the validity and reliability of parliamentary control performance indicators. By validity, we refer to construct validity, content validity and face validity. Reliability lays on consistency and intern coherency. Both using qualitative and quantitative analysis, we show that in qualitative aspect, each index selected measures an accuracy phenomenal which is different from proposal framework of Inter Parliamentary Union. This framework accesses the autonomy and parliament influent of executive, where as African Parliamentary Index captures control and overseeing of budget process. The Parliamentary Powers Index examines different powers of parliament on government. Wehner Index accesses the capacity of legislature control on budgets Imbeau-Stapenhurst Index measures the process, the capacity and work methods of parliaments in budgetary control.
Although those index apprehend different phenomenal, we also use quantitative analysis to verify the validity and relialibility. The results show that is exist some correlation items which can be eliminate from the index calculation. Concerning reliability, those index hold solid intern coherence, but consistency is lower. We suggest the index constructor to verify items correlation before pulling those items.
T
able des matièresRésumé ... iii
Abstract ... iv
Table des matières ... v
Liste de tableaux ... vi
Liste des figures ... vii
Liste des abréviations et des sigles... viii
Remerciements ... x
Introduction ... 1
Chapitre I : problématique et méthodologie de l’étude ... 3
I. Problématique et objectifs... 3
A. Problématique ... 3
B. Objectifs et hypothèses de l’étude ... 7
II. Revue de la littérature ... 8
A. Clarification des concepts de validité et de la fiabilité d’une mesure ... 8
B. Faits empiriques ... 14
III. Méthodologie ... 18
A. Choix des indices ... 18
B. Démarche et outils d’analyse ... 20
Chapitre II : résultats des analyses ... 29
I. Analyse qualitative des indices de contrôle parlementaire... 29
A. Appréciation de l’Indice Parlementaire Africaine (IPA) ... 29
D. Indice imbeau-Stapenhurt ... 38
II. Résultats des estimations ... 48
A. Analyse de la validité et de la fiabilité des indices ... 48
B. Discussions et limites de l’étude ... 86
Conclusion ... 88
Bibliographie ... 90
Liste de tableaux
Tableau 1: récapitulatif des variables utilisées dans le calcul du sous-indice lié à l’autonomie de la CPF telle
que révélée par les statuts ... 41
Tableau 2: récapitulatif des variables utilisées dans le calcul du sous-indice d’activités telles que révélées par les pratiques ... 42
Tableau 3: récapitulatif des variables utilisées dans le calcul du sous-indice de capacités telles révélées par les ressources ... 44
Tableau 4: statistiques descriptives ... 49
Tableau 5: coefficients discrimination de l’indice de Fish et Kroenig ... 52
Tableau 6: coefficients de difficultés de Kuder-Richarson (KR-20) de l’indice de Fish et Kroenig. ... 54
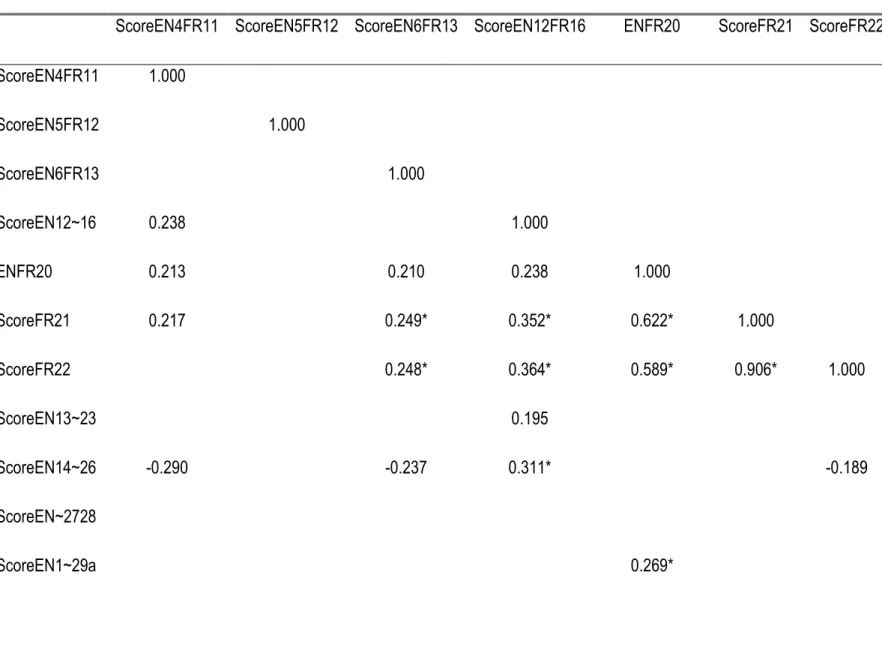
Tableau 7 : matrice de covariance des items de PPI ... 57
Tableau 8: statistiques descriptives des items ... 66
Tableau 9: coefficients de discrimination de l’indice d’imbeau-Stapenhurst ... 69
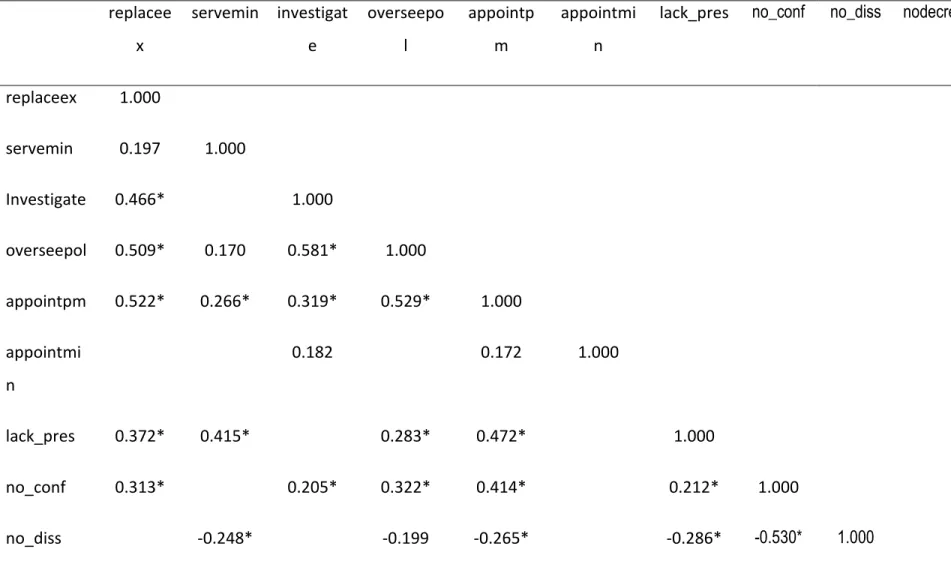
Tableau 10: matrice de corrélation du sous-indice de structure ... 73
Tableau 11 : matrice de corrélation du sous-indice d'activités ... 76
Liste des figures
Figure 1: tracé des valeurs propres de l’indice de Fish et Kroenig ... 64
Figure 2: tracé des valeurs propres du sous-indice structure ... 83
Figure 3: tracé des valeurs propres du sous-indice d’activités ... 84
Liste des abréviations et des sigles
AERA: American educational research associationAGTQ: Achievement goal tendencies questionnaire APC : Association parlementaire du Commonwealth APF : Assemblée parlementaire de la Francophonie CFA : Analyse factorielle confirmatoire
CPC : Centre parlementaire canadien CP : Centre parlementaire
PC : Parliamentary center
EPT : Analyse exploratoire des facteurs IBM : Institut de la banque mondiale ICV : Index de contenu de validité IND : Institut national pour la démocratie IPA : Indice parlementaire africain LG : Learning goals
LPI : Indice de productivité législative LPS : Legislative powers serveys MLI : Indice législatif global
OCDE : Organisation de coopération et de développement économiques PARP : Programme Africain de Renforcement Parlementaire
PG : Performance goals
PNUD : Programme des nations unies pour le développement PPI : Parliamentary powers index
QIP : Quotients d’intelligence de Performances QIV : Quotients d’intelligence verbale
SOR : Objectifs de renforcement social SRG : Social Reinforcement Goals
STCI-T : State-trait cheerfulness inventory trait UIP : Union interparlementaire
WBI : Institut de la Banque mondiale WGI : World governance indicators
« A la recherche de la vérité…Alors, faut-il tester des hypothèses, jusqu’à faire sortir la vérité du puits ? Qui ne veut pas voir la vérité toute nue ? La vérité sortant du puits » (Édouard Debat-Ponsan, 1881).
Remerciements
Cet essai est le fruit du soutien de plusieurs personnes que je tiens à remercier du fond de mon cœur. Sans elles, ce sera l’impasse totale. D’abord, tous celles dont les noms ne figurent pas ici qu’elles en soient remerciées d’avance. Ensuite, j’ai bénéficié de l’appui de mon directeur Louis Imbeau professeur titulaire du département qui m’a orienté vers la bonne direction en me suggérant ce thème suite à nos discussions et au regard de mes centres d’intérêt. Toujours à mes chevets, il m’encourageait à tout moment que nous eûmes l’occasion de nous rencontrer. Son soutien technique dans la réalisation de ce travail ne m’a non plus fait défaut. J’ai appris de lui, la perfection associée à la rigueur dans la pensée scientifique. Je tiens aussi à remercier Marc-André Bodet, directeur du programme du 2ème et 3ème cycle pour son soutien également. Il est tout le temps à l’affût pour ses étudiants pour comprendre leurs difficultés, l’avancement de leurs cours, travaux de recherche afin de leur fournir les informations pertinentes. Je n’oublie non plus le professeur François Gélineau, Doyen de la Faculté des sciences sociales, pour m’avoir offert un cadre de travail adéquat à la Chaire de recherche sur la démocratie et les Institutions Parlementaires. Enfin, le personnel du secrétariat du département qui offre un bon cadre d’interaction entre professeurs et étudiants, qu’il en soit remercié.
Introduction
Dans cet essai, nous cherchons à vérifier la validité et la fiabilité des instruments de mesure des indices de contrôle parlementaire. Ces indices parlementaires constituent des outils importants dans le cadre du suivi des activités parlementaires. Le Centre Parlementaire (C.P, 2011) est d’avis par exemple que l’Indice Parlement Africain (IPA) est un outil d'auto-évaluation des parlements eux-mêmes à l’aide d’un questionnaire fournissant un ensemble d'indicateurs qui montrent le niveau d'engagement des parlements dans le processus du contrôle budgétaire ainsi que d’autres secteurs fonctionnels. Plusieurs variétés d’outils ou d’indicateurs de contrôle parlementaire comme les interpellations et les questions au gouvernement, sont utilisés pour obtenir des informations de l’exécutif. Les commissions parlementaires et les enquêtes aident aussi les parlements à vérifier les politiques publiques mises en place par l’exécutif dans le sens de leur amélioration, ce qui conduit à une bonne gouvernance et à la transparence (USAID et CDG, 2000).
De nombreuses organisations parlementaires comme l’Association Parlementaire du Commonwealth (APC), l’Union Interparlementaire (UIP), l’Assemblée Parlementaire de la Francophonie (APF), l’Institut de la Banque mondiale (WBI) et le Programme des Nations Unies pour le Développement (PNUD) considèrent que la mise en place de critères et de cadres d’évaluation des parlementaires contribue à témoigner des efforts et de réformes entrepris par les parlements, et oriente les praticiens du développement parlementaire ainsi que les bailleurs de fonds vers une conception de programmes de soutien plus appropriée (von Trapp, 2010; P.C, 2013; Yamamoto, 2007).
Le débat politique actuel dans les démocraties représentatives en termes de politiques publiques allant dans le sens de la réduction de la pauvreté, est centré sur la problématique d'affectations budgétaires dont les parlements assurent la surveillance. En tant que représentants des intérêts et des préoccupations des citoyens, les Parlements ont un devoir de contrôle sur l'exécutif et l’obligent à rendre compte de l’utilisation des fonds publics. La fonction de contrôle budgétaire des parlements est devenue de plus en plus importante. Moindzé (2011), admet que le contrôle budgétaire parlementaire est une fonction essentielle pour renforcer la bonne gouvernance des finances publiques qui constitue un élément essentiel des États en vue de renforcer le développement économique et la réduction de la pauvreté. Ainsi, les indices de contrôle budgétaire mesurent à cet effet, les progrès accomplis par les parlements.
Dans la littérature, les travaux récents de Stapenhurst et al. (2014) et de Imbeau (2014) ont également abordé le sujet. Stapenhurst et ses collègues ont étudié la structure, les activités et les capacités de contrôle des Comités de Compte Public (CCP) des Parlements des pays membres et non membres du Commonwealth. Après avoir décrit les structures et les activités de ces CCP, leurs résultats montrent que le contrôle de corruption et l'activité des CCP sont les déterminants principaux du produit national brut per capita. De même, Imbeau a étudié la performance de trois types d’instance supérieure de contrôle (ISC) dans 27 pays d’Afrique. Il fait remarquer que les pays membres du Commonwealth ont souvent une ISC rattachée au législatif alors que les pays membres de la Francophonie ont une ISC rattachée au judiciaire et que le rattachement de l’ISC au législatif est clairement associé à une plus grande transparence budgétaire. Il ressort respectivement de ces deux études que, le contrôle budgétaire des parlementaires est clairement associé d'une part à la création de la richesse et d'autre part à la transparence budgétaire.
On assiste de nos jours à une floraison d’élaboration des indices parlementaires pour rendre compte des progrès réalisés par les législatures permettant leur comparaison. Ces instruments de mesure portent sur les fonctions de législation, de surveillance et de représentation (CP, 2011 ; CP, 2009 ; UIP, 2008). Mais, la plupart des indices parlementaires reposent sur la fonction de contrôle du parlement. Des enquêtes par questionnaires sont utilisées pour construire ces indices sous forme d’une combinaison de multiples variables (Von Hagen 1992, Fish et Kroenig, 2009 et Lienert, 2005 ; 2004) qui examinent le rôle des institutions parlementaires dans l'approbation de l’exécution du budget. Avec cet intérêt croissant de rendre compte de la performance parlementaire à travers la construction de ces indices, il est important de s’assurer de leur qualité et de leur capacité à mesurer réellement le phénomène, car ceux-ci peuvent ne pas rendre compte fidèlement de ce qu’ils prétendent mesurer. La présente étude vise à évaluer ces instruments de mesure parlementaires dont le thème est intitulé :
« évaluation de la fiabilité et de la validité des indices de contrôle parlementaires ». Elle est
structurée comme suit : le premier chapitre aborde la problématique indiquant les raisons de cette étude et les hypothèses de travail, la revue de la littérature portant sur les concepts de validité et de fiabilité d’un instrument, et puis la méthodologie proposée. Le second chapitre traite des résultats et de la discussion portant sur ceux-ci.
Chapitre I : problématique et méthodologie de
l’étude
I. Problématique et objectifs
A. Problématique
Dans cette partie, nous soulevons l’importance de mesurer les activités parlementaires et les problèmes liés à cette mesure. Les indices parlementaires sont de plus en construits et utilisés pour mesurer la performance du contrôle budgétaire des parlementaires dont le rôle fondamental est de vérifier, d’adopter les dépenses publiques des gouvernements et, aussi d'exercer un contrôle sur les activités de l’exécutif et des structures auxiliaires (Niane et Rakotonirina, 2014 ; Lienert, 2008). Les parlementaires1 détiennent à cet égard, les cordons de la bourse et ils ont pour mandat de scruter
l’utilisation des fonds publics et d’assurer la responsabilité financière du gouvernement. Pour Posner et Park (2007) et Wohlstetter (1987), une législature efficace fournit donc des freins et contrepoids essentiels, à l’amélioration de la transparence, facilite le débat public, et aide à approfondir le consensus sur les choix budgétaires. Elle exerce une influence notable sur les résultats budgétaires de différentes structures de l’administration.
Dans cet exercice de mesure de la performance parlementaire, une gamme de variables sont souvent combinées sous forme d’indice pour rendre compte et déterminer les différences entre les parlements de pays différents en se référant soit à la structure constitutionnelle, la manière dont les pouvoirs d'amendement du budget sont conçus, soit la dynamique des partis politiques, la capacité technique des législatures d'engager des budgets, etc. Par exemple, Wehner (2006 ; 2007) a présenté un cadre comparatif pour évaluer la capacité budgétaire des législatures dans les démocraties modernes. Le cadre est constitué d'une série de six variables qui sont combinées en un indice pour
1Voir Fiche d’information – Québec, Recueil des procédures et de pratiques parlementaires, Assemblée parlementaire de la
Francophonie, http://recueil.apf francophonie.org/spip.php ? article1778
Et Assemblée parlementaire de la Francophonie : Les procédures de contrôle, Recueil des procédures et de pratiques parlementaires, Chapitre VIII, p.10, http://recueil.apf-francophonie.org/spip.php?article2171
mesurer la variation des parlements dans le processus de budgétisation entre les pays. Ces variables concernent : le pouvoir d’amendement, la possibilité de rejet du budget examiné, la flexibilité du gouvernement durant l’exécution du budget, le temps utilisé pour examiner le budget, la capacité des comités et la possibilité d’accès à l’information. L'opérationnalisation est basée sur des données d'enquête de l’Organisation de coopération et de développement économiques (OCDE) et la Banque mondiale. Von Hagen (1992) a construit aussi un indice composite de la structure du processus parlementaire, qu’il considère comme principal déterminant de l'amendement des pouvoirs d'une assemblée législative dans le contrôle budgétaire. De même, Lienert (2004) offre également un examen des institutions législatives. Son indice des pouvoirs budgétaires des législatures couvre cinq variables, à savoir le rôle du Parlement dans l'approbation des paramètres de dépenses budgétaires à moyen terme, leurs pouvoirs d’amendement, le temps disponible pour l'approbation du budget, le soutien technique à l'Assemblée législative, et les restrictions de l’exécutif pendant l’exécution du budget. Une analyse comparative des indices de Wehner et de Lienert montre que certaines variables utilisées dans la construction de chacun des indices sont différentes. La capacité des comités et l’accès à l’information retenus par Wehner ne se retrouvent pas dans l’indice de Lienert.
Il est à noter que le Centre Parlementaire Canadien (CPC) a construit aussi un Indice Parlementaire Africain (IPA) de sept (07) pays2 africains basé sur l’autoévaluation des parlementaires,
et qui repose sur des catégories d'indicateurs beaucoup plus larges qui vont au-delà de ceux utilisés par Wehner et Liernert. Ces indicateurs couvrent les trois fonctions de base du Parlement : (1) la représentation, (2) la rédaction des lois et (3) la surveillance des dépenses et des finances publiques et sont tirés d'une série de variables combinées en un Indice pour mesurer les différences de performances entre les pays dans le contrôle budgétaire législatif. Le choix des indicateurs s'appuie sur les questions de gouvernance portées par des institutions telles que l’Institut National pour la Démocratie (IND), l'Institut de la Banque Mondiale (IBM), l'Association Parlementaire du Commonwealth (CPA), l’Union Interparlementaire et l'expérience du Centre Parlementaire au Canada. De même, Fish et Kroenig (2009) ont élaboré à travers une enquête globale, un indice sur les législatures nationales. Cet indice, appelé Parliamentary Powers Index (PPI) évalue la force de la
législature nationale de chaque pays ayant une population d'au moins un demi - million d’habitants. Le PPI donne un aperçu de l'état actuel du pouvoir législatif dans le monde à partir de 2007. L’outil principal est l'enquête sur les pouvoirs législatifs ou Legislative Powers Serveys (LPS). Une liste de trente-deux (32) items ont été élaborés mesurant l'emprise du législateur sur l'exécutif, son autonomie institutionnelle, son autorité dans des domaines spécifiques, et sa capacité institutionnelle. Les données ont été générées au moyen d'une vaste enquête internationale d’experts, d’une étude approfondie des sources secondaires, et d’une analyse minutieuse des constitutions et autres documents pertinents.
Dans cet effort de construction de ces indices, certains items diffèrent les uns des autres, alors qu’ils prétendent rendre compte du même phénomène. Selon Tessier et al (1985) et Rankin (1981), les différents éléments qui servent de variables dans la construction des indices sont "rarement purs" et il arrive fréquemment que ces variables soient en relation avec d'autres variables ne faisant pas l’objet de l'étude ou que ces variables créent tout simplement de l’endogéniété. Cette erreur de variance appelée encore variance résiduelle est la partie de la variance intragroupe qui s'éloigne de l’objet de la mesure et, par conséquent, contribue à réduire sa fiabilité. Lorsque la variance intragroupe de l’indice est importante, même si la variance intergroupe est significativement faible, d'autres contingences non soumises à l'analyse affectent le phénomène étudié et introduisent par conséquent dans la mesure des biais non contrôlables. Ils affirment qu’en raison de la multiplicité des variables, de la relative nouveauté de ces études et de l’opposition dans les courants de pensée entre les différents chercheurs, il est possible que les instruments portant sur la mesure des performances parlementaires soient de portée limitée, et pourraient contenir d'éventuelles erreurs.
Un exemple portant sur ces faits, concerne les nouvelles échelles de Wechsler relaté par Grégoire (2007). Selon lui, « les nouvelles échelles de Wechsler ont conduit à abandonner un modèle de mesure de l’intelligence en deux échelles au profit d’un autre basé sur quatre indices. Construits sur une base purement pragmatique, les Quotients d’Intelligence Verbale (QIV) et de Performances (QIP) de Wechsler avaient rencontré un grand succès chez les cliniciens. Mais les études empiriques ont très tôt révélé qu’il s’agit de constructions relativement hétérogènes, dont l’interprétation psychologique n’est pas aisée. Bien que l’échelle verbale soit la plus homogène, l’épreuve d’arithmétique qui en fait partie est corrélée avec les autres épreuves de cette échelle. En plus du
raisonnement verbal, cette épreuve fait appel au raisonnement numérique et à la mémoire de travail. L’échelle de Performance est, quant à elle, nettement plus hétérogène ».
Abondant dans le même sens, Bersch et Botero (2014) pointent trois erreurs néfastes de l’agrégation d’indicateurs de gouvernance fondées sur la perception, en l’absence de clarté conceptuelle : 1) le peu d’attention accordé à la validité du contenu ; 2) une confusion entre les causes, les caractéristiques et les conséquences de la gouvernance, et 3) la sous-estimation de l’incertitude. Kurtz et Schrank (2007b) plaident contre les indicateurs basés sur les perceptions, en particulier le World Governance Indicators (WGI), parce qu'ils introduisent un biais systématique. Ils présument que le WGI est biaisé en faveur des opinions et préoccupations des entreprises et des élites. Thomas (2010) aborde une question plus fondamentale et se demande si ces indicateurs mesurent réellement ce qu'ils prétendent mesurer. Elle déclare que les indicateurs de WGI sont basés sur des affirmations athéoriques et exigent des preuves de validité. Pour Krishnan (2013), il existe de nombreuses raisons pour lesquelles les indicateurs peuvent ne pas répondre à la norme minimale de qualité. En général, ils pourraient provenir de : (1) les défauts de la question et (2) les défauts de contenu. Plus précisément, les éléments peuvent être problématiques en raison d’un ou de plusieurs des motifs suivants :
Les items peuvent être mal formulés causant aux administrateurs d’être confondus.
Les items peuvent représenter un contenu différent de celui qui est mesuré par le reste des items.
La présence de biais dans un item pour ou contre un sous-groupe de la population.
La capacité globale de l’administrateur du test dans la compréhension de la véritable signification d'un item, ce qui pourrait augmenter les chances de deviner la bonne réponse. En faisant référence aux études de nature exploratoire, selon Piazza (1980) nous ne pouvons jamais être sûr à l'avance que les questions destinées à mesurer un phénomène vont réussir à le faire. Certaines questions peuvent être mal formulées et interprétées de différentes manières par les répondants. Ou bien, le phénomène que nous essayons de mesurer peut ne même pas exister en tant que phénomène unitaire. Dans ce cas, les répondants répondront aux questions de façon incompatible simplement parce que notre conceptualisation initiale était inadéquate. Il est presque toujours nécessaire d'examiner les modèles de réponses après les faits observés, afin de déterminer quelles questions, le cas échéant, semblent avoir mesuré un phénomène hypothétique unique. Pour Westen et Rosenthal (2003), si un test psychologique ou plus largement, une procédure de mesure
psychologique, y compris un dispositif expérimental de manipulation manque de validité de construction, les résultats obtenus en utilisant ce test ou cette procédure seront difficiles à interpréter. Ainsi, les indices parlementaires, vu l'importance des sources d'erreurs possibles, exigent aussi des preuves évidentes de consistance et de validité. C'est précisément cette démonstration qui manquent dans bon nombre de travaux où des scores sont constitués en additionnant un certain nombre d'items sous le simple prétexte qu'ils répondent tous au même construit théorique (Tessier, Pilon et Fecteau, 1985). Au regard du nombre croissant de production d’indices pour mesurer les performances de contrôle parlementaire, plusieurs interrogations sont alors à poser. Lorsque l’on mesure une grandeur, on souhaite que les résultats produits par celle-ci soient utiles et reflètent bien les concepts qu’elle représente. La question fondamentale que l’on se demande est alors de savoir si tous ces indices parlementaires sont valides et fiables ?
Les indices parlementaires sont donc importants afin de mesurer le contrôle parlementaire et ils sont élaborés sur la base de multiples sources. Ils pourront être confrontés à deux types de problèmes, provenant d'une part, de la multiplicité des sources de variations et, d'autre part, de l'absence de validité dans la définition des concepts. Les premiers limitent la validité des résultats résultant de la difficulté de contrôler en même temps toutes les sources de variations ; et les seconds caractérisés par les imprécisions de construits rendent difficiles les comparaisons d’une étude à l'autre. Il est alors important de s’assurer de la validité et de la fiabilité des indices mesurant la performance de contrôle parlementaire. L’intérêt de cette étude réside dans le fait qu’elle permet de s’assurer que les mesures du contrôle parlementaires sont correctes et correspondent exactement à ce qu’elles prétendent capter. Très peu d’études ont été faites pour vérifier la fiabilité et la validité des indices de contrôle parlementaire. Elle permettra aux développeurs de ces indices d’améliorer leurs instruments en révisant ou en écartant les items qui ne satisfont pas un minimum de standards.
B. Objectifs et hypothèses de l’étude
L’objectif général de cette étude est d’analyser la validité et la fiabilité des indices qui mesurent la performance du contrôle budgétaire des parlements. A cet objectif général se rattachent deux objectifs spécifiques : d’une part, (1) évaluer la validité de quelques indices parlementaires et d’autre part, (2) évaluer leur fiabilité. Nous formulons les hypothèses ci-après :
H2 : Les indices parlementaires sont fiables.
II. Revue de la littérature
Les principaux indicateurs de la qualité d'un instrument de mesure sont généralement la fiabilité et la validité. Dans cette revue de littérature, nous définissons les concepts de validité et la fiabilité des instruments de mesure ou d’indices afin de mieux les évaluer. Puis nous présentons le mode d’évaluation de chaque concept au regard des fondements empiriques y afférents. Ainsi, nous aurons une compréhension approfondie des diverses méthodes d’évaluations des instruments de mesure permettant de formuler une méthodologie d’analyse de ces indices parlementaires.
A. Clarification des concepts de validité et de la fiabilité d’une mesure
De façon générale, deux éléments sont mis en avant pour définir la validité ou la fiabilité d’une mesure. Le premier a trait à la capacité de la mesure à décrire ce qu’elle mesure réellement et le second se focalise sur le type d’erreurs que comporte une mesure. Wehner (2007) définit la validité d'une mesure comme étant le degré auquel cette mesure ou instrument réussit à décrire ou quantifier ce pourquoi il est conçu à mesurer, alors que la fiabilité d'une mesure est le degré auquel une technique de mesure peut être dépendante de résultats résultant d’une application répétée.
Par contre, Kimberlin et Winterstein (2008) et Adcock et Collier (2001) indiquent que la plupart des mesures peuvent contenir des marges d’erreurs qui affecteraient leur qualité de validité et de fiabilité. Ils identifient trois principales sources d’erreurs3 et deux types d’erreurs relatives à la validité
et la fiabilité. Ces trois principales sources d’erreurs identifiées portent notamment sur l’objet mesuré, l’observateur et l’appareil de mesure contenant deux types4 d’erreurs. Le premier type d’erreurs est
appelé erreurs aléatoires, qui ne sont pas rattachables à une cause bien précise. Mais, lorsqu’il existe un nombre suffisamment important d’observations, ces erreurs aléatoires peuvent se compenser du fait que certains éléments mesurés surestiment et d’autres sous-estiment le phénomène. Donc, une erreur est aléatoire si d'une mesure à l'autre, la valeur obtenue peut être sous-évaluée ou surévaluée par rapport à la valeur réelle. Ces types d’erreurs influencent la fiabilité de la mesure. Le second type
3Voir http://www.med.uottawa.ca/sim/data/Measurement_validity_f.htm
d’erreurs, qualifié d’erreurs systématiques allant dans une direction donnée, est imputable à une cause spécifique se rattachant à l’observateur ou à l’instrument de mesure. Lorsque ces erreurs sont orientées dans une direction donnée, celles-ci introduisent un biais dans la mesure. Une erreur est systématique lorsqu'elle contribue à toujours surévaluer ou sous-évaluer la valeur mesurée. Ces erreurs systématiques font donc partie de la validité de la mesure. Bien que nous ayons une bonne compréhension globale des concepts de validité et de fiabilité, il est nécessaire de détailler les différents types de validité et de fiabilité. C’est ce que nous décrivons dans ce qui suit.
a. La validité
La validité indique dans quelle mesure un instrument capte le phénomène qu’il vise à représenter. Il existe plusieurs types de validité dont les principaux sont la validité de construit ou construct validity, la validité du contenu ou content validity, la validité de critère ou criterion validity et la validité manifeste ou face validity (Demeuse et Henry, 2004 ; Fermanian, 2005).
Validité prédictive ou de critère
Pour Demeuse et Henry, la validité de critère repose sur « la prédiction des résultats qu’obtiendront les sujets à d’autres tests ou à un autre instrument quelconque. La validité de critère indique dans quelle mesure un instrument est conforme à un autre instrument prédictif. Le phénomène est appréhendé à la fois par l’échelle ou l’indice étudié et un critère extérieur à celui-ci pris comme référence en mesurant l’intensité du lien statistique existant entre les deux échelles ». Demeuse et Henry indiquent l’existence de deux types de validité de critère. La première concerne la validité prédictive correspondant à la possibilité de prédiction des résultats qu’obtiendraient des sujets à d’autres tests ou à une autre mesure quelconque. La seconde, appelée validité concomitante (concurrent validity) correspond au cas où l’échelle et le critère de référence sont utilisés en même temps chez chaque sujet. Yu (2012) établit la validité de critère comme la conclusion des résultats des tests de performance. Le score élevé d’un test indique que l’indice a satisfait les critères de performance et qu’une régression peut être appliquée en utilisant la variable de prédiction considérée comme exogène et la variable de critère comme dépendante. Tous les auteurs sont d’avis que pour mesurer la validité de critère, on pourrait calculer le coefficient de corrélation ou une concordance entre la mesure obtenue et la mesure de critère. Si les deux scores (échelle et critère) sont exprimés sous forme de variables quantitatives, on emploie le coefficient de corrélation de Pearson, mais si les
hypothèses théoriques du modèle ne sont pas vérifiées, les coefficients5 de corrélation de Spearman
ou celui de Kendall sont calculés.
La validité manifeste ou face validity
Appelée aussi validité d‘apparence, la validité manifeste se caractérise par un jugement subjectif émis par l’utilisateur après un examen attentif de l’échelle de mesure (DeVon et al, 2007). Son avis tient compte des caractéristiques de la mesure, tels que la formulation des items, les modalités de réponse etc… Fermanian fait remarquer qu’il ne faut pas la confondre avec la validité de contenu qui suppose une étude approfondie, faite par des experts. Ici il s’agit d’un simple jugement superficiel émis par l’utilisateur et la validité manifeste est généralement considérée comme la forme faible de la validité de contenu.
La validité du contenu ou content validity
Il existe plusieurs définitions relatives à la validité de contenu que la plupart décrivent comme le degré auquel les éléments de la mesure sont représentatifs et ont un lien direct avec ce qui est mesuré. Il s’agit de savoir si oui ou non les items représentent adéquatement le domaine qu’ils prétendent mesurer (Polit et Beck, 2006 ; Waltz, Strickland et Lenz, 2005 et Wynd, Schmidt et Schaefer, 2003). La validité de contenu se réfère aussi à l’opinion formulée par les experts sur la mesure contrairement à la validité manifeste ou c’est l’avis de l’utilisateur qui est pris en compte (Lynn, 1986 ; Beck et Gable, 2001 ; Haynes, S., & al. 1995 ; Mastaglia, Toye et Kristjanson, 2003).
Pour Fermanian, les experts évaluent dans quelle mesure les items composant l’échelle sont pertinents et constituent un échantillon représentatif de l’univers de tous les items possibles pouvant décrire le phénomène mesuré. Il fournit l’exemple suivant pour l’illustrer. Supposons une échelle de 28 items construite pour mesurer par exemple le handicap dans les gestes de la vie quotidienne de malades atteints de polyarthrite rhumatoïde. Après une étude faite par deux experts, les items possibles ont été divisés en six domaines distincts : A = faire sa toilette, B = s’habiller, C = manger, ... F = faire des achats. Pour évaluer la validité de contenu de l’échelle, les experts vérifient que :
5 http://www.cons-dev.org/elearning/stat/stat7/st7.html
• chaque item correspond bien à l’un des six domaines identifiés. Ainsi, ils voient que l’item 1 correspond à C, l’item 2 étudie A, etc. Chacun des 28 items correspond bien à l’un des domaines ; • chaque domaine est représenté par un ou plusieurs items en fonction de son importance. Les experts peuvent se rendre compte que A est représenté par trois items, B par quatre items, ... F par cinq items. À l’issue de cet examen les deux experts s’accordent pour donner une appréciation globale sur la validité de contenu si tous les domaines sont représentés. Pour Delgado-Rico et al. (2012), la validité du contenu comprend tous les éléments qui influent directement sur la façon dont les données sont obtenues et indiquent que les trois étapes importantes pour évaluer la validité de contenu sont : 1) la définition du domaine ou du contenu à évaluer, 2) la construction des items, et 3) le jugement d’experts des éléments de construction.
La validité de construit ou construct validity
La validité de construit démontre dans quelle mesure l’instrument décrit une vraie mesure. Selon Kimberlin et Winterstein (2008) et Fermanian (2005), elle part de la conception théorique que nous avons du phénomène mesuré par l’échelle permettant de faire un certain nombre d’hypothèses. La validité du construit s’affirme et croît au fur et à mesure que des expériences successives viennent confirmer les hypothèses préalables. On cherche à savoir à travers les hypothèses formulées si les scores de l’échelle étudiée sont fortement corrélés avec d’autres variables (validité convergente). Ainsi la validité de construit indique si la définition opérationnelle d’une variable reflète en réalité la véritable signification théorique d’un concept6. Pour Amarenco, et al. (2000), la validité empirique des échelles
doit être établie (validité de contenu, validité concourante). De même, la pertinence du regroupement des items de l’échelle doit être vérifiée. Il existe plusieurs méthodes pour vérifier la validité convergente et divergente des items à l’aide des analyses factorielles, qui étudient les liens entre les items en regroupant les plus corrélés sur chacun des axes factoriels. Après cet examen de la validité, nous définissons la fiabilité.
b. La fiabilité
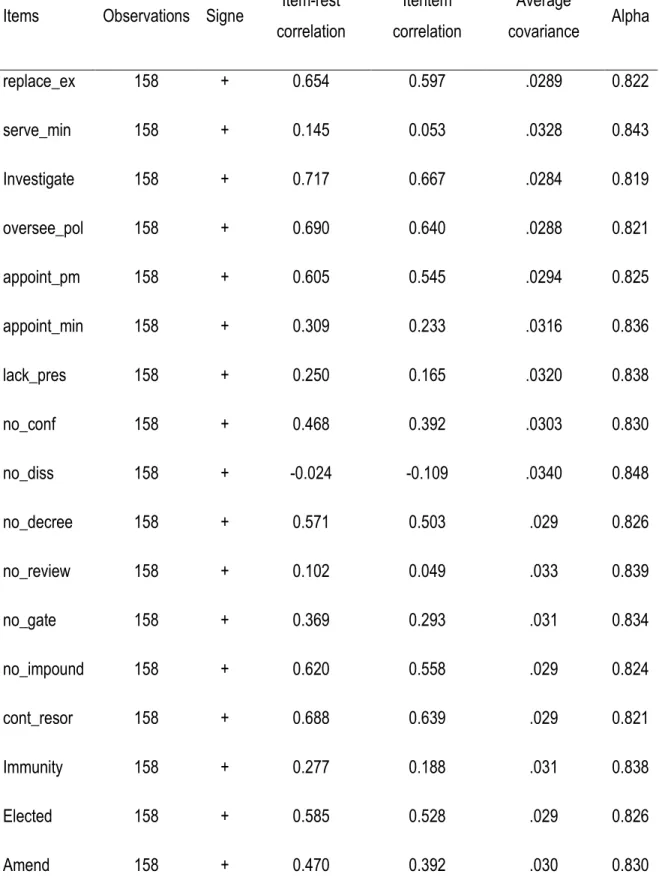
La fiabilité se rapporte à la capacité d’un instrument à mesurer systématiquement un attribut (DeVon et al, 2007). Elle représente le degré de consistance, de cohérence ou de stabilité d’une mesure. La fiabilité est donc la capacité d'un test ou d'une échelle à obtenir les mêmes résultats quand il est répliqué à plusieurs reprises. La fiabilité est déterminée en calculant le coefficient de corrélation entre les séries répétées de scores par intervalle de temps. Si le coefficient de corrélation est de 0,80 ou plus, il est généralement considéré comme étant un test fiable. Pour être considéré comme fiable, un test ne doit pas donner une corrélation positive parfaite de 1,07.
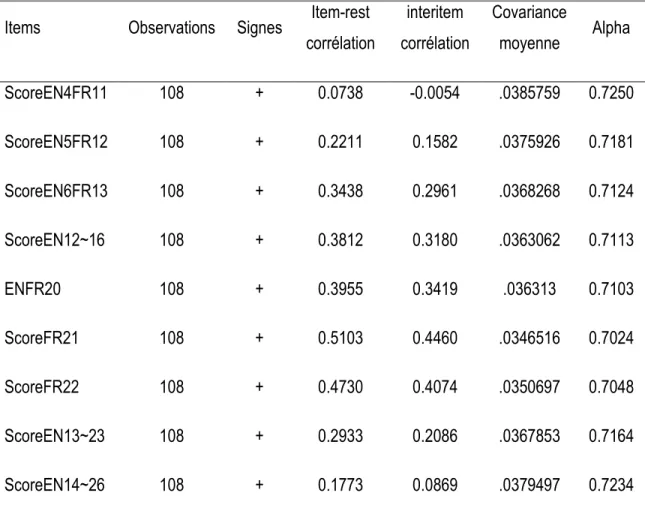
Une vue classique des types de fiabilité a été faite par l’AERA en 1985, Amarenco, et al. (2000) portant sur les éléments qui sont la stabilité temporelle, la cohérence et la fiabilité inter-jugement. La première fiabilité correspondant à la stabilité temporelle utilise la même forme du test sur deux ou à plusieurs reprises appliquée au même groupe de sujets examinés (test-retest). À chaque reprise, le résultat de la mesure du retest est identique au résultat du test précédent. Dans de nombreuses reprises, cette approche n’est pas pratique parce que les comportements des sujets examinés pourraient être affectés par des mesures répétées. On pourrait mesurer la cohérence interne ou internal consistency de la mesure en utilisant le coefficient de résultats des tests obtenus à partir d’un seul test ou d'une enquête (Alpha de Cronbach, KR20). Quant au troisième, la fiabilité inter-jugement ou rater consistency, résulte de l’accord entre deux évaluateurs, des codeurs ou des observateurs.
L’estimation de la fiabilité est utile lorsque l'objet sous le jugement est très subjectif. Si l'échelle de notation est continue, le coefficient de corrélation de Pearson est adapté. Si l'échelle est ordinale par nature, le coefficient de Spearman est l'approche la plus appropriée pour la classification catégorielle. Les coefficients de Kappa ou de corrélations intra classes sont parfois utilisés. Une valeur seuil de .70 à .80 est recommandée (Landis et Koch, 1977).
Amarenco, et al. (2000) étudient la construction et la validation des échelles de qualité de vie en France et résument les qualités d’un instrument de mesure en ces termes. Pour eux, la validité de contenu est le fait que le questionnaire mesure ce qu’il prétend mesurer, tandis que la validité de construit témoigne que le questionnaire est un véritable instrument de mesure. Ils affirment que la validité critérielle établit la validité empirique de l’échelle par rapport à un autre questionnaire existant considéré comme la référence. Quant à la fiabilité, elle représente la capacité du questionnaire à se comporter de manière fiable et de mesurer de manière reproductible. La reproductibilité est la stabilité de la mesure dans le temps, et l’analyse de la cohérence interne peut être appréciée par le calcul de I’alpha de Cronbach. Ce coefficient indique dans quelle mesure les items d’une dimension investiguent le même concept. Il varie de 0 (faible cohérence) à 1 (parfaite cohérence). Un minimum de 0,5 est requis, mais 0,70 est recommandé pour avoir une bonne cohérence interne. La stabilité est la capacité du questionnaire à mesurer les mêmes choses chez une même personne sur un laps de temps donné. Un regard critique a été porté à la fois sur la fiabilité et la validité (Salvucci, Walter, Colley, Fink, et Saba ,1997) en examinant la possibilité d’inclusion de la fiabilité dans la validité. Les chercheurs comme Salvucci, Walter, Colley, Fink, et Saba contredisent l’opinion traditionnelle selon laquelle la fiabilité est une condition nécessaire non suffisante de validité. Ces auteurs conceptualisent la fiabilité comme une invariance et la validité comme un biais. Pour eux, un échantillon statistique peut avoir une valeur attendue égal au paramètre (sans biais) de la population, et présenter une très forte variance, et inversement. De ce point de vue, une mesure peut être peu fiable en présentant une variance élevée, et être valide, donc non biaisée. Yu recommande alors de vérifier à la fois la viabilité et la fiabilité lorsqu’on se prête à l’évaluation des indices.
Par contre, Moss (1994) évoque l’inclusion de la fiabilité dans la validité et considère que la validité est un concept plus large que la fiabilité. La fiabilité serait contenue dans la validité. Selon lui, Il ne peut y avoir validité sans fiabilité si elle est définie comme la cohérence entre les mesures indépendantes. La fiabilité est un aspect de la validité conceptuelle. Comme l'évaluation devient moins standardisée, les distinctions entre la fiabilité et la validité est floue. Cet avis est partagé par Li (2003) qui fait valoir que l’indépendance entre fiabilité et validité est incorrecte. Il affirme que la fiabilité doit être définie en rapport à la théorie classique des tests représentant la corrélation au carré entre les vrais scores observés ou la proportion de variance réelle dans les résultats des tests obtenus. La fiabilité est une mesure sans unité, et donc il est déjà un modèle libre ou libre standard. Il est possible
que de multiples facteurs soient introduits dans un test pour améliorer la validité, mais diminuent la cohérente de la fiabilité.
Thompson et al. (2003) apportent une nuance sur la perception faite de la fiabilité par Li. Pour eux, la fiabilité n’est pas une propriété des tests ; elle est plutôt fixée par la propriété des données puis, ils ajoutent que les mesures ne sont pas fiables. Il est important d'explorer la fiabilité dans pratiquement toutes les études en généralisant, ce qui est similaire à la méta-analyse et devrait être mis en œuvre pour évaluer la variance de l'erreur de mesure à travers de nombreuses études.
B. Faits empiriques
Après la revue théorique, il est important de vérifier empiriquement comment l’évaluation des mesures se fait. Cette partie de la revue empirique nous permettra de comprendre la démarche méthodologique suivie par certains auteurs et les techniques d’analyse utilisées. Erol (2010) a examiné la validité et la fiabilité de l'échelle de traduction de la perception de la politique organisationnelle en Turquie. Cette Perception a été testée en termes de contenu et de structure. La technique suivie est conçue comme un processus en deux étapes. A la première étape, la validité du contenu a été testée. Dans la deuxième étape, les preuves de la validité conceptuelle de l'échelle ont été recherchées en faisant une analyse exploratoire des facteurs (EPT), puis l'analyse factorielle confirmatoire (CFA) pour les données obtenues. Pour déterminer la fiabilité de l'item total de l’échelle des corrélations de score et le coefficient de Cronbach alpha ont été utilisé. La démarche faite pour la validité et la fiabilité de l'échelle a été menée sur les données recueillies auprès de 277 membres du corps professoral qui travaillent dans les facultés d'éducation des universités. En tant que méthode de réalisation de ces membres du corps professoral, un échantillonnage aléatoire simple est utilisé. Les propriétés psychométriques de la version Turque de la perception de la politique organisationnelle d’échelle a montré que celle-ci a un niveau satisfaisant de fiabilité et de validité dans l'échantillon des employés Turcs.
Ingles et al. (2009) ont examiné les éléments de preuve de fiabilité et de validité établi à partir des scores de la version espagnole de la réalisation des Objectifs Généraux de Tendances du Questionnaire (AGTQ) en utilisant un échantillon de 2.022 (51,1% de garçons) des étudiants espagnols de grades 7 à 10. Comme Erol, ils utilisent une méthode fondée sur l'analyse factorielle confirmatoire qui reproduit la structure corrélée à trois facteurs de l'AGTQ dans cet échantillon : Objectifs d'apprentissage (LG), Objectifs de Renforcement social (SOR) et objectifs de rendement (PG). Selon
ces auteurs, l’AGTQ donne des résultats relativement fiables pour les étudiants espagnols. La preuve de la fiabilité de la version espagnole des scores sur l’AGTQ a été évaluée à l’aide du coefficient alpha de Cronbach. La consistance interne montre des coefficients de .79 pour LG ; .74 pour SOR et .71 PG. Les Test- retest de fiabilités, sur un intervalle de 6 semaines, ont fournis les résultats suivants : 0.67 pour LG ; .67 pour SRG, et .59 en ce qui concerne PG. Par ailleurs, au-delà de l’analyse factorielle, des analyses de régression logistique ont été utilisées pour fournir des preuves de validité supplémentaire des scores de l’AGTQ sur la réussite scolaire (général, en espagnol et les mathématiques). Les résultats indiquent que la réussite scolaire générale était de 15% et 5% plus de chances à chaque fois que les scores sur les échelles LG et PG ont augmenté de 1 point, respectivement, et que la réussite scolaire générale était de 9% moins de chances à chaque fois que les scores sur l'échelle de SRG ont augmenté de 1 point. Ces résultats étaient similaires pour l'espagnol et les mathématiques. Cependant, le score sur l'échelle LG n'a pas fourni de succès dans les deux sujets. On peut alors conclure que les scores LG et PG sont bien prédictives et possèdent une validité prédictive meilleure que le score SRG.
De même, une étude de la fiabilité et de la validité des scores portant sur la version révisée de l’AGTQ dans les échantillons d'étudiants du Collège japonais a été menée par Hayamizu et Weiner (1991). Ceux-ci ont reproduit la structure à trois facteurs des scores d’AGTQ représentés par LG, SOR et PG trouvés chez les élèves du secondaire japonais dont les items ont été différemment distribués. L’échelle LG comporte huit items, alors que les échelles SOR et PG, chacun se compose de six items. Dans leur analyse, les scores SOR et PG sont interdépendants avec un coefficient de .44, tandis que les coefficients de corrélation avec les scores LG étaient faibles : .10 et .05, respectivement. L’inter corrélation moyenne entre les scores sur ces facteurs était de .20. Ces auteurs ont constaté que les scores de l'AGTQ ont montré des coefficients de cohérence internes adéquats : .89 pour LG, .78 pour SRG, et .71 pour PG, contrairement à Ingles et al., qui trouvent que seuls les scores LG et PG sont fiables. Ils ont indiqué que, la faible stabilité a été négativement liée au score sur l'échelle de LG, comme l’affirme Dweck (1986). Ce dernier a déclaré que, les directions des relations entre la stabilité et la contrôlabilité de la faible capacité et le score de l'échelle PG de l’AGTQ étaient parfaitement liées. Enfin, les résultats indiquent que la perception de l'effort et la difficulté des tâches aussi étaient des prédicteurs de l'objectif de réalisation des trois scores.
Delgado-Rico et al. (2012) étudient quant à eux, la validité de contenu dans le développement de test à partir de l'analyse de l'adaptation espagnole de la qualité de l’État portant sur l’inventaire des formes de gaieté (STCI -T). L’article illustre les étapes nécessaires pour analyser la validité. D’abord : 1) définition du domaine contenu à évaluer, ensuite 2) faire le point de construction des items, et enfin 3) un jugement d'expert des éléments de la construction des items. Cette étude a porté essentiellement sur la troisième étape et les résultats sont obtenus avec un panel sélectionné d'experts. Le papier décrit brièvement les critères les plus importants à considérer dans la sélection des experts, la procédure recommandée pour obtenir des jugements, la manière d’administrer, les aspects des éléments à évaluer, et le type d'analyses qui doivent être effectués. Dans leur étude, 106 items originaux du STCI -T (gaieté : 38 items ; mauvaise humeur : 31 items ; gravité : 37 items) ont été soumis à la traduction par 04 spécialistes bilingues. Étant donné le nombre élevé d'éléments de la version expérimentale espagnole du STCI-T (188) et les multiples facettes de chacune de ses dimensions, un grand nombre de juges a été choisi à raison de 03 juges par item. L'objectif était de repartir les items à évaluer parmi les juges pour éviter un biais dû à la fatigue, la perte de motivation dans la tâche, ou d'autres causes. L’index de Contenu de Validité (ICV) de Polit et Beck (2006) a été calculé afin de valider les résultats. Comme critère général, il est considéré que les valeurs de l'ICV devraient être supérieures à .70. Pour analyser la pertinence, il est fortement recommandé d'inclure un indice d’accord inter juges qui prend en compte le nombre de juges et le nombre de classifications possibles ainsi que le nombre total d'items lors de l'analyse de la dimension globale. La recommandation indique d’utiliser l'indice Kappa d’accord inter juges (Wynd et al., 2003) avec une valeur supérieure à .40. Les résultats montrent que tous les juges qui ont été invités à évaluer les items, les ont remplis. Sur les 188 items évalués, 60 ont été considérés comme ayant une validité de contenu insuffisant (ICV < .70 et Kappa < .40) dans la représentativité et / ou pertinence). L’analyse dimensionnelle de la STCI –T conduit à l'élimination de 16 items pour la gaieté, 24 items pour la gravité, et 20 items pour mauvaise humeur. La valeur de l’ICV globale de représentativité était .89, .80 et .82 respectivement pour la gaieté, la gravité et de mauvaise humeur. En ce qui concerne la pertinence, les valeurs de l'ICV globale étaient .81 ; .75 et .79 pour gaieté, gravité et mauvaise humeur respectivement. La valeur Kappa était .55 pour gaieté, .48 pour gravité et .50 pour mauvaise humeur.
Dans le domaine législatif Grant et Kelly (2007) ont procédé à la mesure et la vérification de leur indice. Ils mesurent d’abord la productivité législative de toute l'histoire du Congrès américain de la période 1789-2004 qui est le nombre de lois publiques adoptées par un Congrès et, mesurer l’indice
de productivité législative (LPI) et l’indice législatif global (MLI). Ceux-ci somment ensuite les informations provenant des indicateurs de productivité en LPI et en MLI pour construire un indice. Pour s’assurer de la qualité de leur mesure, ils examinent le contenu, la convergence, et la validité de construit. Deux types de convergence sont étudiés, la validation de convergence qui est le processus de démonstration de la similitude entre une mesure et d'autres mesures, et la validité de divergence comprenant également des comparaisons avec des mesures de concepts qui sont théoriquement distinct du nouveau concept. Le modèle de construction de validité inclut les déterminants potentiels de productivité législative. En outre, la validation des index est réalisée en effectuant la validation des tests de construction, en examinant la relation entre leurs mesures de la productivité et les variables qui pourraient, selon les recherches antérieures, déterminer les niveaux de productivité. Pour eux, la productivité est déterminée par la partisannerie ; elle est également influencée par des changements dans les exigences sociétales, telles que mesurées par les préférences politiques du public. Ils concluent que LPI et MLI sont valides et sont des mesures de productivité supérieures à d'autres mesures utilisées dans la littérature.
Au terme de cette revue de la littérature tant théorique qu’empirique, une synthèse est nécessaire pour récapituler la démarche et les méthodes empruntées par les différents auteurs. Les concepts de validité et fiabilité recouvrent plusieurs aspects (voir Demeuse et al. et AERA) et que chacun de ces aspects peut être analysé en employant plus techniques. Par exemple pour établir la validité de contenu, on peut faire référence à la pertinence des items en utilisant soit l’analyse factorielle, soit la matrice des corrélations (Amarenco, et al, 2000 ; Ingles et al, 2009). Delgado-Rico et al nous apprennent qu’il est aussi possible d’employer les techniques d’analyse qualitative et quantitative. Nous bâtirons notre méthodologie au regard de cette littérature. Mais, nous avançons l’idée que la validité de critère ne pas être vérifiée dans notre analyse des indices puisqu’elle exige l’existence d’un indice standard accepté comme norme. Dans notre cas précis, au vu de la nouveauté dans la construction des indices de contrôle parlementaire, cette référence n’est pas disponible.
III. Méthodologie
Pour évaluer les indices de contrôle parlementaires, nous décrirons la démarche utilisée, les techniques d’analyse et le choix des indices. Cette étape est nécessaire pour s’assurer de la robustesse de nos résultats.
A. Choix des indices
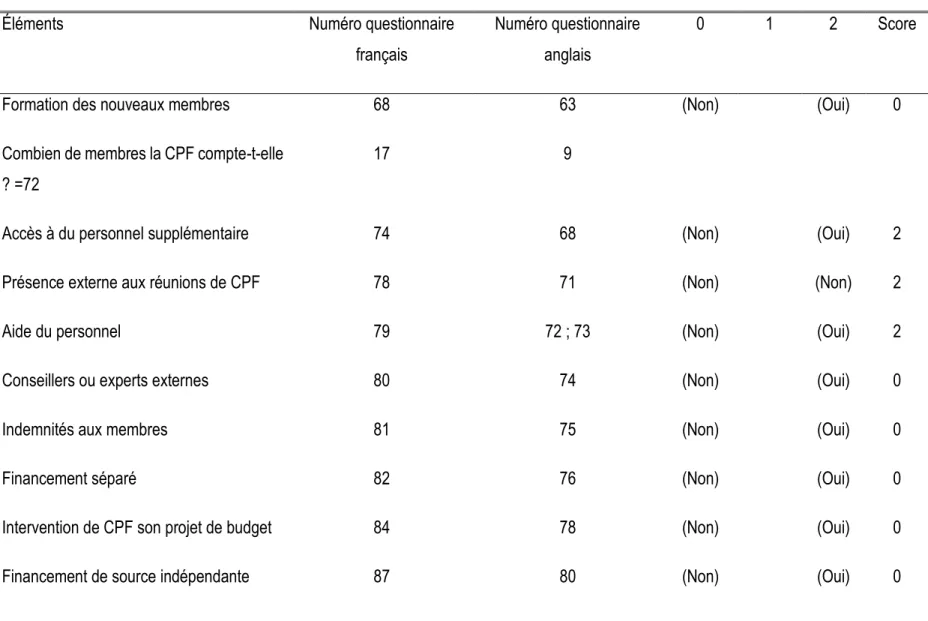
Dans la littérature, il existe un nombre important d’indices élaborés pour mesurer la performance des parlements. Certains se focalisent sur une fonction particulière donnée du Parlement. Étant donné qu’il existe trois principales fonctions accomplies par les parlements (législative, représentation et contrôle), nous retiendrons ici dans cette étude, les indices qui traitent des aspects du contrôle parlementaire jugé important par la plupart des auteurs. Afin d’apporter une évaluation exhaustive des indices, la taille des pays participant à la construction de la mesure de l’indice est retenue. Nous retiendrons des indices construits avec un petit nombre de pays et aussi d’un grand nombre de pays. Ces critères ont guidé le choix de nos indices pour s’assurer de la représentativité de nos résultats. Le processus de calcul de certains indices et leur accessibilité n’a pas été possible. L’évaluation portera sur quatre indices qui offrent une estimation différente du contrôle budgétaire. Le premier est l’Indice Parlementaire Africain (IPA) élaboré par le Centre Parlementaire de l’Agence Canadienne de Développement International (ACDI), qui évalue 07 parlements africains. Ces pays sont le Bénin, le Ghana, le Kenya, le Sénégal, la Tanzanie, l’Ouganda et la Zambie. Cet indice est particulièrement intéressant à étudier à cause de la taille ou nombre réduit de pays couverts. L'outil d'auto-évaluation qui consiste à l’évaluation des parlementaires par eux-mêmes à l’aide d’un questionnaire, a couvert cinq domaines principaux
(1) la représentation ; (2) la législation ;
(3) les fonctions de surveillance ; (4) la capacité institutionnelle ; et (5) l'intégrité institutionnelle.
Nous évaluons l’indice qui couvre les domaines du contrôle et de la surveillance budgétaire du Parlement et d’autres principaux domaines fonctionnels qui touchent directement les rôles de surveillance financière des Parlements. Les questions étaient qualitatives, et demandent aux
répondants de donner leurs avis et de noter chaque variable ou chaque indicateur sur une échelle de quatre points où : 4 désigne un niveau élevé de la capacité du Parlement en place ; 3 montre un niveau modéré de capacité ; 2 indique l'existence d'un niveau basique de capacité ; et 1 signale un besoin clair d’augmentation de capacité.
Le second indice est celui de Wehner dont le cadre se compose d'une série de variables qui sont combinées en un indice pour mesurer la variation de contrôle par pays dans la budgétisation. L'opérationnalisation est basée sur des données d'enquête des pays membres de l'Organisation de Coopération et de Développement Économique (OCDE) et la Banque mondiale portant sur les arrangements institutionnels qui facilitent le contrôle législatif sur les budgets de l’État. L’indice est construit à l'aide des données de 36 pays à partir d'une enquête sur les procédures budgétaires de 2003. L'indice est construit suivant 06 variables institutionnelles du contrôle législatif. Ces variables sont les pouvoirs d’amendement du parlement, les budgets réversifs, la flexibilité du pouvoir exécutif au cours la mise en œuvre, le calendrier du budget, les comités législatifs et les informations budgétaires.
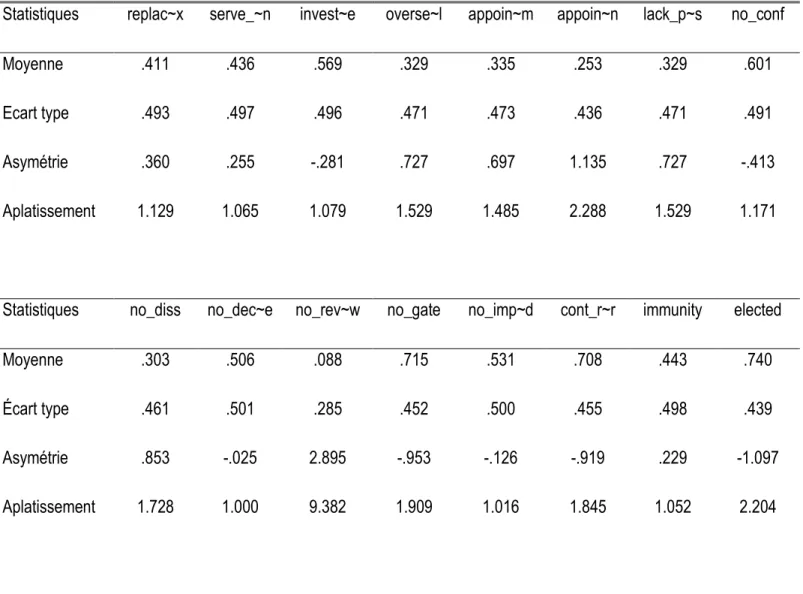
Le troisième indice qui est le Parliamentary Powers Index (PPI) de Fish et Kroenig qui évaluent un ensemble de 158 pays à travers le monde. Le Parliamentary Powers Index (PPI) évalue la force de la législature nationale de chaque pays dans le monde ayant une population d'au moins un demi - million d'habitants. Le PPI donne un aperçu sur l'état actuel du pouvoir législatif dans le monde en 2007 et 2009 en matière de contrôle budgétaire. L’outil principal de collecte des données est l'enquête appelée Pouvoirs Législatifs Surveys (LPS). Le questionnaire comprend une liste de 32 variables ou items qui mesurent l'emprise du contrôle législatif sur l'exécutif, son autonomie institutionnelle, son autorité dans des domaines spécifiques, et sa capacité institutionnelle. Les données ont été générées au moyen d'une vaste enquête internationale d'experts, d’étude approfondie des sources secondaires, et une analyse minutieuse des constitutions et autres documents pertinents.
Le quatrième indice est celui d’Imbeau-Stapenhurst qui couvre un ensemble de 97 législatures dont 28 sont francophones et 69 sont anglophones. Ces législatures sont issues de trois types de système parlementaire : 61 de type unicaméral, 35 de type bicaméral et 1 de type tricaméral (Sénat, chambre des représentants et conseil des sages). Les législatures sondées sont reparties géographiquement comme suit : 32 assemblées africaines, 30 assemblées d’Amérique et de Caraïbes, 15 assemblées asiatiques, une assemblée du pacifique et 19 assemblées européennes. Cet indice est
mesuré à partir de trois scores relatifs aux capacités structurelles, d’activité et de ressources des différentes législatures. Les données ont été obtenues à l’aide d’un questionnaire administré aux parlements nationaux et sous-nationaux dans différents pays.
B. Démarche et outils d’analyse
L’évaluation des indices sélectionnés portera sur la validité de contenu, la validité de construit, la validité manifeste et la fiabilité. Nous adopterons une approche qualitative et quantitative suivant Drapeau (2004). L’approche qualitative consistera à apprécier la validité de contenu et la validité manifeste des instruments de mesure. Elle vise à apprécier les items du questionnaire avant la collecte des données pour s’assurer de la conformité et la pertinence des informations collectées. Après cette collecte de données, les items peuvent présenter des problèmes de multi colinéarité dont il faut se débarrasser. L’analyse statistique permettra de surmonter à ces problèmes. Pour assurer la qualité de l’analyse, nous mènerons ainsi une analyse quantitative pour suppléer l’analyse qualitative. Cette analyse quantitative traite de la validité de construit, de la pertinence qui a rapport à la validité de contenu et la fiabilité des instruments.
Cette évaluation des indices se décomposent en trois étapes. La première étape consiste à une analyse des corrélations d’un item aux scores totaux des items et des techniques d’analyse factorielle. Le but de cette étape est d’examiner l’indépendance des items qui sont manifestes avec les principaux points d’intérêt. La deuxième étape évalue les covariations entre les items. Les deux premières étapes nécessitent une matrice de corrélation des items ; par conséquent, les données peuvent être résumées raisonnablement dans une telle forme. Notons que la matrice de corrélation et l’analyse factorielle sont utiles lorsque les items sont peu nombreux. En pratique, comme c’est le cas dans la présente étude, les chercheurs utilisent souvent de grands nombres d'items et peuvent souhaiter prendre de nombreuses variables en compte. Cette analyse consistera à vérifier si l’ensemble de ces items sont indépendants ou dépendantes. D’autres procédures spécifiques (la troisième étape) liées à la cohérence, à la consistance ou à la fiabilité inter-juges portant sur la fiabilité seront adoptées afin de mener à bien l’analyse.
a. Techniques d’analyse qualitative des indices
La validité manifeste et de contenu reposent sur l’appréciation des utilisateurs et des juges sur le contenu des items appartenant aux indices. A cet, à l’aide des questionnaires utilisés par les
constructeurs des indices, nous les comparerons au questionnaire recommandé par l’UIP. Cela nous permettra d’inspecter si les items utilisés par les constructeurs d’indices sont conformes à ceux de l’UIP. Nous nous basons sur ce questionnaire de l’UIP dit de benchmark législatif utilisée par Joseph (2010) pour comparer différents indices. Ce benchmark est utilisé par les institutions comme l’Association Parlementaire du Commonwealth (APC). Il comporte 87 items permettant d’évaluer les parlementaires et leur staff. Ces items sont validés par les conseillers procéduraux de la chambre des Opérations et l’Office de Recherche du Sénat et de la Chambre des représentants. Mais certains benchmarks ne faisant pas partir du domaine du contrôle budgétaire ne feront pas l’objet d’analyse. Les parlementaires mènent des discutions entre eux de l’évaluation à faire en se servant du benchmark, puis individuellement ils portent leur jugement. Cette procédure a été utilisée par l’APC et l’Assemblée Parlementaire de la Francophonie (APF). On comparera alors ces benchmarks à ceux utilisés par les chercheurs afin de vérifier si les différents items utilisés par les chercheurs sont conformes au benchmark. Cette démarche permettra de se prononcer sur la représentativité du contenu des indices. Ceci revient à démontrer que les items couvrent bien l’ensemble des domaines au contrôle budgétaire. Puisque les chercheurs utilisent les questionnaires multidimensionnels, le contenu de chaque dimension du questionnaire sera analysé afin de s’assurer de la cohérence des items. Pour ce faire, nous décrirons les items du benchmark.
Benchmark d’évaluation parlementaire de l’UIP
Afin de pouvoir vérifier la validité de contenu des indices à évaluer, il est nécessaire de décrire le référentiel ou standard de base permettant de juger la validité de construction et de contenu des indices. Les questions ou éléments correspondant aux items du benchmark couvrent 06 volets ou domaines que voici.
- La représentativité du Parlement
Elle concerne entre autres les éléments ci-après :
La diversité de la composition du Parlement des opinions politiques des partis du pays La représentative des femmes, des groupes et régions marginalisés ;
La facilité des personnes à revenu moyen de se faire élire ;
Le rôle des structures destinées à garantir les partis ou groupes d’opposition, les groupes minoritaires et leurs membres à réellement contribuer aux travaux du Parlement ;
La facilité de l’infrastructure du Parlement et ses règles tacites à la participation des hommes et des femmes et,
Le degré de liberté d’expression et de protection des députés.
- Le contrôle parlementaire sur l’exécutif
Dans ce volet, les éléments retenus se rapportent à :
La rigueur des procédures permettant aux parlementaires de poser des questions à l’exécutif et d’en obtenir les informations demandées ;
Le degré d’efficacité des commissions spécialisées ;
L’influence du Parlement sur le budget national et de son examen ;
L’efficacité du Parlement à examiner les nominations à des postes de responsabilité et à demander des comptes aux titulaires ;
Le degré d’autonomie du Parlement à l’égard du gouvernement ;
La correspondance des effectifs et les qualifications du personnel parlementaire aux besoins, tant individuels que collectifs, dans l’accomplissement de leurs fonctions et ;
La correspondance des services de recherche, d’information et autres aux besoins des parlementaires et de leurs groupes.
- La fonction législative du Parlement
Les éléments retenus sont :
La satisfaction des procédures de soumission d’un projet de loi à une discussion approfondie et ouverte au Parlement ;
L’efficacité de la procédure des commissions dans l’examen et l’amendement des projets de lois ;
La transparence de la procédure de consultation des groupes et des intérêts concernés lors de l’élaboration d’une loi ;
La garantie de la clarté, de la concision et l’intelligibilité de la législation ;
La compatibilité des lois adoptées avec la Constitution et les droits fondamentaux des citoyens et ;
- La transparence et l’accessibilité du Parlement
Ce volet prend en compte :
L’accessibilité des médias et du public aux débats du Parlement et de ses commissions ; Le degré de liberté des journalistes dans leurs reportages sur le Parlement et les activités
des parlementaires ;
Le degré d’informations parlementaires, passant par différents canaux, offertes aux citoyens concernant leurs travaux ;
L’intensité et la réussite des initiatives destinées à intéresser les jeunes aux travaux Parlementaires ;
Le degré de convivialité de la procédure permettant à des particuliers ou à des groupes de soumettre des informations à une commission parlementaire ou une commission d’enquête et Le degré d’implication offert aux citoyens dans l’élaboration de la législation.
- L’obligation de rendre compte du Parlement
Le cinquième volet comporte :
Les dispositifs obligeant les parlementaires à tenir les électeurs informés de leur travail ; Le degré d’efficacité du système électoral ;
La garantie du respect par les parlementaires des codes d’éthiques en vigueur ; La transparence et l’efficacité de la procédure destinée à éviter les conflits d’intérêts ;
La garantie du financement des partis et des candidats à l’indépendance des parlementaires dans l’exercice de leurs fonctions et ;
Le suivi et l’analyse du degré de confiance des citoyens à l’égard du Parlement.
- La participation du Parlement à la politique internationale
Le dernier volet concerne :
L’examen parlementaire de la politique étrangère du gouvernement et sa contribution ; Information du Parlement de la position adoptée par le gouvernement dans les instances
régionales ou universelles ;
Le degré d’influence du Parlement sur les engagements juridiques ou financiers contraignants pris par le gouvernement dans des enceintes internationales ;
L’examen des rapports nationaux élaborés dans le cadre des mécanismes internationaux de suivi ;
La promotion du dialogue politique destiné à régler des conflits, tant sur le sol national qu’à l’étranger ;
L’examen de la politique et de la performance des organisations internationales auxquelles le gouvernement du pays apporte des ressources financières, humaines et matérielles et ; Le contrôle du déploiement des forces armées nationales à l’étranger.
Ce benchmark représente le questionnaire global de l’UIP évaluant les différentes fonctions du parlement. Dans notre étude, nous nous intéressons aux items relatifs au domaine qui est en rapport avec le contrôle budgétaire du parlement.
b. Les techniques d’analyse quantitative
- Validité de construit
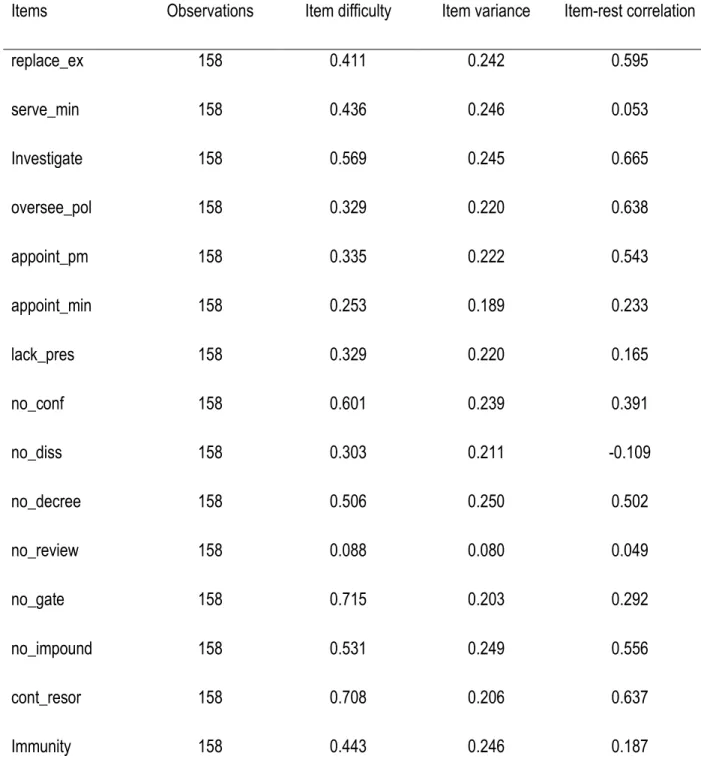
Pour évaluer la validité de construit, nous utilisons les indices de difficulté, de discrimination et l’analyse factorielle exploratoire. L’indice de difficulté (P) et l’indice de discrimination (D) des items sont deux paramètres qui aident à évaluer la norme des questions à choix simples ou multiples (QCM) utilisées, avec des valeurs anormales indiquant une mauvaise qualité (Mitra, Nagaraja, Ponnudurai, Judson, 2009). Ces indices P et D seront utilisés pour l’évaluation des indices parlementaires, ils fournissent une mesure de la validité de construit pouvant être utilisée dans des situations où un grand d’échantillon d’items est réalisé. Cette méthode a été employée par Polit et Beck (2006). L'indice de difficulté P des items est obtenu en calculant le pourcentage du nombre total de réponses correctes des tests d’items, tandis que l'indice de la discrimination mesure la différence entre les pourcentages dans le groupe supérieur à celui du groupe inférieur qui a obtenu les réponses correctes.
L’indice P8 est obtenu par la formule
𝑃𝑖 = ( 𝐴𝑖
𝑁𝑖
⁄ ), où Pi = indice de difficulté de l’item i
Ai = Nombre de réponses correctes de l’item i
Ni = Nombre de réponses correctes et incorrectes de l’item i.
La recommandation générale est d'utiliser des éléments avec des valeurs p contenues dans une fourchette de 0.40 à 0.60.
8 Voir Krishnan (2013)