Contextual Bandit for Active Learning: Active Thompson Sampling
Texte intégral
Figure
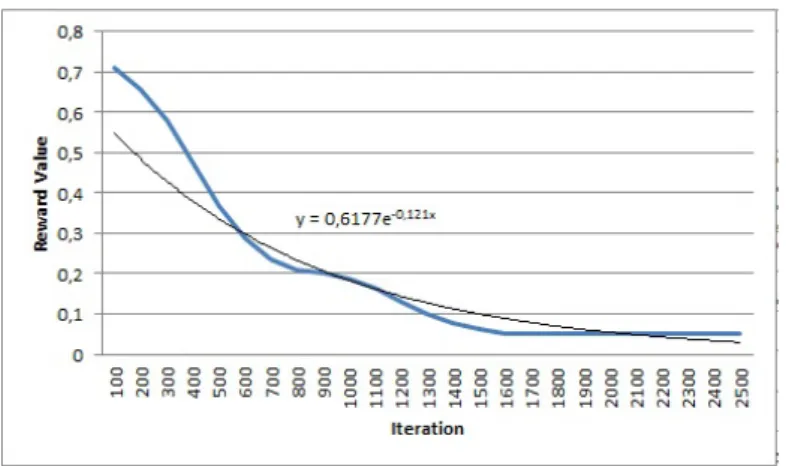

Documents relatifs
Abstract—In this paper, we propose a successive convex approximation framework for sparse optimization where the nonsmooth regularization function in the objective function is
The goal of a meta-active learning system is to learn an active-learning strategy such that, for each problem, coming with a training dataset of unlabeled examples, it can predict
An active learning approach is used to iteratively select the most informative experiments needed to improve the parameters and hidden variables estimates in a dynamical model given
In order to correct the immanent error associated with the system’s latency we apply virtual prototyping and programming by imitation to process the actions and sent
We leverage the availability of large numbers of supervised learning datasets to empirically evaluate contextual bandit algorithms, focusing on practical methods that learn by
The results obtained in this benchmark can be compared with some of the top 5 challenge’s competitors as similar methods were used: INTEL used random forest and IDE used a
The method employed for learning from unlabeled data must not have been very effective because the results at the beginning of the learning curves are quite bad on some
In practice the convex quadratic programming (QP) problem in Equation 1 is solved by optimizing the dual cost function. Those training instances are called support vectors and
