Gestion de bout en bout de la qualité de contexte pour l'internet des objets : le cadriciel QoCIM
Texte intégral
Figure
Outline
Documents relatifs
(44,25 %), mais elle est préférable pour réduire les émissions de GES, car elle permet de régler le problème d’actualité que sont les GES. Néanmoins, à la défense de ce
C’est dans ce contexte que se situe cette communication qui vise à présenter une méthodologie développée dans le cadre du projet « Prise en compte des INCERtitudes pour des
contexte transfrontalier, les travailleurs transfrontaliers et leur carrière, sur l’influence d’un tel contexte sur la gestion des carrières des travailleurs
Le DSL MuScADel [1] a ´et´e con¸cu pour permet- tre l’expression de contraintes de d´eploiement d’un syst`eme logiciel en environnement multi-´echelle, tel un gestionnaire
Le DSL MuScADel [1] a ´et´e con¸cu pour permet- tre l’expression de contraintes de d´eploiement d’un syst`eme logiciel en environnement multi-´echelle, tel un gestionnaire
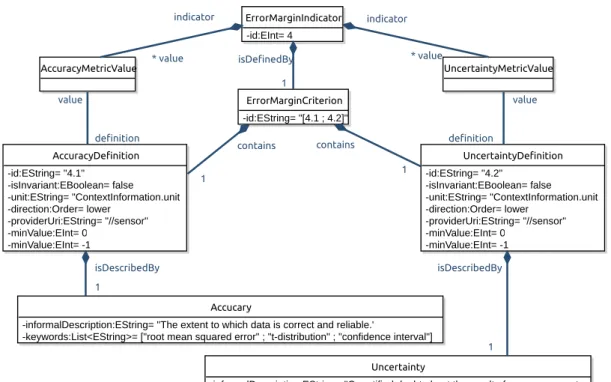
Pour cela, elle se base sur une classification du contexte et une d´ efinition de la qualit´ e de service permettant de prendre en compte les diff´ erentes propri´ et´ es
Le groupe de travail de scientifiques et de gestionnaires a réuni des informations sur les ramassages d’éponges dans les filets des campagnes de recherche
Sur l’île de la Réunion, « hot-spot » de biodiversité, cette préoccupation est particulièrement forte, car elle se pose dans un contexte décisionnel difficile :
