Decoupled image-based visual servoing for cameras obeying the unified projection model
Texte intégral
Figure

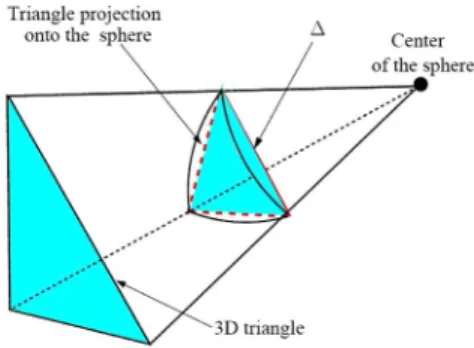




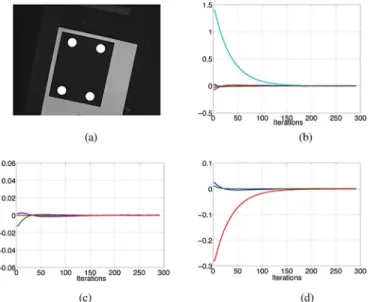

Documents relatifs
On the contrary, when looking for a motion stimulus, can attention be captured by an irrelevant but highly salient
In this paper, a combinatorial method based on Ant System (AS) optimization is proposed in order to minimize the current unbalance factor (CUF) by controlling the connection
C’est le nombre de communes qui considèrent les sentiers, circuits sportifs et randonnées comme un motif d’attraction touristique sur leur territoire ramené au nombre total
Gruber, Bounding the feedback vertex number of digraphs in terms of vertex degrees, Discrete Applied Mathematics, 2011.. Reducibility among combinatorial problems,
Pour rester dans la thématique des labels, concluons en signalant la très bonne nouvelle qui nous est parvenue dans les
61 Antiquités celtiques et antédiluviennes, I, p. 62 L’Industrie primitive : premier titre des Antiquités celtiques et antédiluviennes. 63 Antiquités celtiques et
found recently in the iConnect study that a 1-year decrease in cycling for commuting (not for walking) was associated with a decrease in LTPA [19]. A limitation in previous
To validate DYRK1A as a biomarker for AD diagnosis, we assessed the levels of DYRK1A and the related markers brain-derived neurotrophic factor (BDNF) and homocysteine in two
