Visual-Based Eye Contact Detection in Multi-Person Interactions
7
0
0
Texte intégral
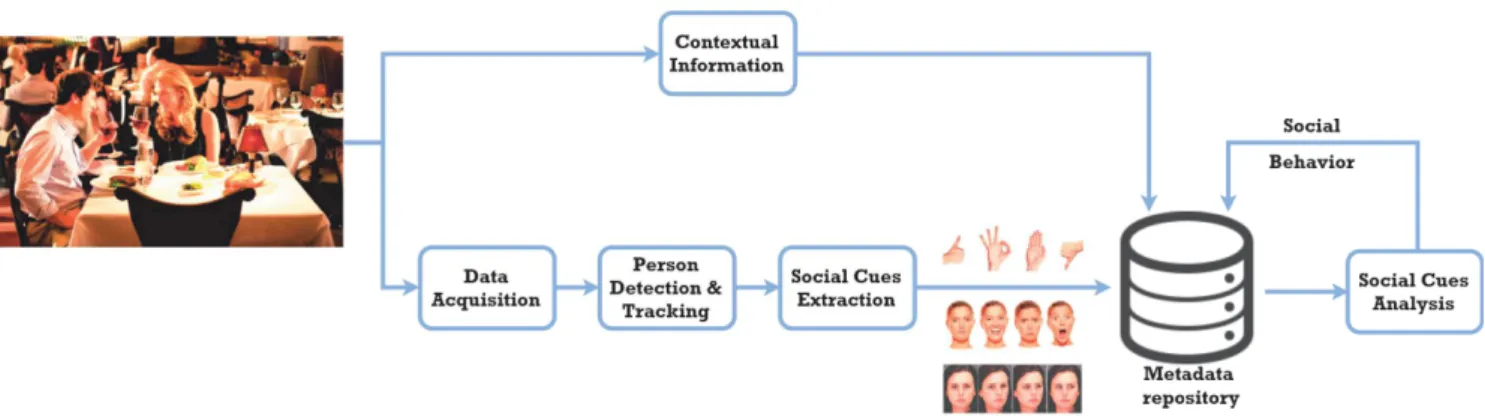
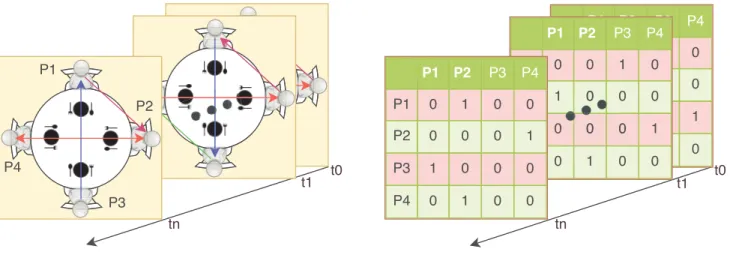
Figure


Documents relatifs
