Université Ahmed Draïa d'Adrar Faculté des Sciences et de la Technologie Département de Mathématiques et Informatique
Mémoire de Fin d’étude
En vue de l’Obtention du Diplôme de Master en Informatique Option ; Réseaux et Systèmes Intelligents
Thème Présenté par : SOLLAH Islam Encadrés par : Mr. MAMOUNI El Mamoun Soutenu le Mardi 02/07/2019
Devant le jury composé de : Mr. MAMOUNI El Mamoun
Mr. CHOUGUEUR Djilali Mr. CHERAGUI Mohamed Amine
Mr. MEDIANI Mohammed
Remerciements
Avant tout, je remercie Dieu le très haut qui m’aidé et
donne-moi le courage et la volonté de réaliser ce modeste
travail.
Je remercie le seigneur tout puissant de m’avoir accordé
volonté et patience dans l’accomplissement de ce travail à
terme.
Je tenu à exprimer mon vif remerciement à
Mr. MAMOUNI El Mamoun
Je remercie « TOUS » les Messieurs et dames, les
professeurs pour leurs précieux conseils.
Mes remerciements vont également aux membres du jury
d’avoir accepté d’évaluer mon travail. Sans oublier de
remercier mon amis Taki Snoussi.
Sans oublier bien sûr de remercier profondément tous ceux
qui ont contribué de près ou de loin à la réalisation de ce
travail.
À la mémoire de mon grand-père.
Vous n’êtes plus à mes cotés, mais vous resterez
toujours dans mon cœur.
Aux êtres qui me sont les plus chères au monde : mes
parents.
À mes frères
À toute ma famille
À tous mes amis (es)
À mes élèves
La reconnaissance optique de caractères est un processus qui permet de convertir un texte présenté par une image numérique en un texte modifiable.
Dans ce travail nous avons construit un système de reconnaissance des caractères arabes manuscrits hors-ligne, dans la phase de classification nous avons implémenté deux techniques (k-PPV et SVM) afin de comparer les résultats ainsi que pour la sélection de paramètres de chaque technique. Pour tester notre système nous avons utilisés une base de données contenant 2682 images, les résultats obtenus sont très encourageants.
Mots-clés : Reconnaissance, caractères arabes, classification, k-PPV, SVM.
Abstract
OCR is a process that converts text presented by a digital image into editable text.
In our thesis, we try to program an off line character recognition system which use in the classification phase two major techniques (k-PPV and SVM) and then compare the results using the best conditions of the two techniques. To test our system performance, we have a data base consist of 2682 images, the results we had are very encouraging.
OCR .ريرحتلل لباق صن ىلإ ةيمقر ةروص همدقت يذلا صنلا لوحت ةيلمع يه انتحورطأ يف ماظن ةجمرب لواحن ، ل فرحلأا ىلع فرعتل يبرعلا عملا ة ةلوز ناتينقت فينصتلا ةلحرم يف مدختسي يذلاو ( ناتيسيئر k-PPV و SVM اب جئاتنلا نراقن مث ) رايتخ اظن ءادأ رابتخلا .نيتينقتلل طورشلا لضفأ انم نوكتت تانايب ةدعاق انيدل ، نم 2682 ةروص .ةياغلل ةعجشم اهيلإ انلصوت يتلا جئاتنلا تناكو ، :ةيحاتفملا تاملكلا ،فينصت ،ةيبرع فورح ،فرعتلا K-PPV ، SVM
Dédicace………. 4
Résumé………... 5
Abstract……….. 5
لم صخ ………... 6
Tables des matières……… 7
Liste des tableaux……….………. 12
Liste des figures……….... 13
Introduction générale 1. Contexte et l’objectif du mémoire………..… 15
Chapitre 01 1. Introduction……….….. 17
2. Caractéristiques de l’écriture arabe……….….. 17
3. Différents aspects de l'OCR……….……….. 19
3.1 La reconnaissance en ligne (on-line)……….……….…. 20
3.2 Reconnaissance hors ligne (off-line)………... 20
3.2.1 Reconnaissance de texte ou analyse de documents……….. 20
3.2.2 Reconnaissance de l’imprimé ou du manuscrit………. 21
4. Approches de reconnaissance……….... 22
4.1 Approche globale………. 22
4.2 Approche analytique……….... 22
5. Les phases d’un système OCR……….. 24
5.1 L’acquisition……… 24
5.1.1 Acquisition hors ligne………... 24
5.1.2 Acquisition en ligne……….. 25
5.2 Etape d’acquisition……….. 25
5.3.1 Binarisation………..………...………. 26
5.3.2 Transformation par érosion……….. 27
5.3.3 Transformation par dilatation………... 27
5.3.4 Ouverture morphologique……….... 27 5.3.5 Fermeture morphologique……….... 27 5.4 Squelettisation………. 27 5.5 Normalisation de la taille………. 28 5.6 Le lissage………. 28 5.7 La phase de segmentation……… 29
5.7.1 Les techniques de la segmentation……….... 29
A. Segmentation implicite………... 29
1) Soit par fenêtrage……….………... 30
2) Soit par recherche de primitives………. 30
B. Segmentation explicite………... 30
5.8 Extraction des caractéristiques……….... 30
A. Caractéristiques structurelles………... 31 B. Caractéristiques statistiques………. 31 C. Transformations globales……….... 31 5.9 La reconnaissance……… 32 1) Apprentissage……….. 32 A. Supervisé………. 32 B. Non-supervisé……….. 32 2) Classification………... 32 5.10 La reconnaissance et la décision………... 33 5.11 Le post-traitement………. 33 6. Conclusion………. 33 Chapitre 02 1. Introduction………... 35
2. Méthode des K plus proches voisins (KPPV)……… 35
2.3 Quelques règles sur le choix de k………. 38
2.4 Example d’algorithme K-NN……….. 38
2.5 Avantages de la méthode des k plus proches voisins……….. 39
2.6 Inconvénients de la méthode des k plus proches voisins………. 39
2.7 Domaine d’application……….... 40
3. La technique de classification K-means (Clustring)……….. 40
3.1 Définition……….... 40
3.2 Principe de fonctionnement………. 40
3.3 L’algorithme de K-moyen………... 41
3.4 Example de classification K-means………. 42
3.5 Domaines d’application………... 43
3.6 Les avantages du K-moyen……….. 43
3.7 Les Inconvénients du K-moyen………... 44
4. Conclusion………. 44
Chapitre 03 1. Introduction………... 46
2. Machines à vecteurs de support (SVM)………. 46
2.1 Historique……….... 46
2.2 Le principe des SVM………... 47
2.3 Le SVM linéaire……….. 48
2.3.1 Cas linéairement séparable………... 48
1) Forme primale………. 49
2) Forme duale………. 50
2.3.2 Cas non linéairement séparable……….... 50
2.4 SVM multi-classes………... 54
2.4.1 Un contre tous (One Against All)……….. 54
2.4.2 Un contre un (One Against One)……….. 56
2.5 Les domaines d’application………. 57
2.6 Les avantages et les inconvénients de SVM………. 57
A. Avantages……….... 57
3.2 Historique……… 58
3.3 Neurone biologique………. 58
3.4 Les réseaux de neurones……….. 59
3.5 Neurone formel (artificiel)………... 59
3.6 Fonctions d’activation………. 60
3.7 Les réseaux de neurones célèbres………. 61
3.7.1 Perceptron……… 62
3.7.2 Le perceptron multicouches……….. 63
3.8 L’apprentissage………... 63
1) L’apprentissage supervisé………... 64
2) L’apprentissage non supervisé………. 64
3.9 Avantages des réseaux de neurones………. 64
3.10 Inconvénients des réseaux de neurones……….... 64
4. Conclusion………. 64
Chapitre 04 1. Introduction………... 67
2. Ressources matérielles et logicielles………. 67
2.1 Matérielles………... 67
2.2 Logicielles………... 67
3. Description de notre base de données……….... 69
4. Description de notre système de reconnaissance………... 70
4.1 Phase d’acquisition……….. 70
4.2 Phase de la normalisation………. 70
4.3 L’extraction des primitives……….. 71
4.4 Construction de la matrice de distribution………... 71
4.4.1 Structure de vecteur de caractéristique………. 72
4.4.2 Corpus……….. 72
5. Résultats et comparaison………... 73
5.1 Système basé sur la technique K-PPV……….. 73
2) SVM Une-contre-une……….. 75 5.3 Evaluation des résultats………... 76 6. Conclusion………. 76
Conclusion générale
Conclusion générale et Perspectives………. 78 Bibliographie
Tableau 1.1 : L’alphabet arabe……….. 17
Tableau 1.2 : Lettres arabes ayant des points diacritiques……….... 19
Tableau 4.1: Les lettres arabes utilisées (28 classes) ………... 69
Tableau 5.3: Vecteur des caractéristiques de la lettre « ج »………... 72
Tableau 5.4: Le taux de reconnaissance obtenu le noyau RBF……….... 75
Tableau 5.5: Le taux de reconnaissance obtenu le noyau linéaire……….... 75
Tableau 5.6: Le taux de reconnaissance obtenu le noyau RBF……….... 75
Figure 1.1 : Cursivité, sens et la connectivité de l’écriture arabe………... 18
Figure 1.2 : Exemple de pseudo-mots constituant des mots arabes……….... 18
Figure 1.3 : Reconnaissance d’écriture en ligne……….. 20
Figure 1.4 : Reconnaissance d’écriture hors ligne………... 21
Figure 1.5 : Différents systèmes, représentations et les approches de la reconnaissance ..….23
Figure 1.6 : le processus général de reconnaissance de l’écriture………... 24
Figure 1.7 : Communication écriture Homme-machine. ………...25
Figure 1.8 : Application de certaines opérations de prétraitement sur un mot arabe……... 26
Figure 1.9 : Exemple de Binarisation adaptative………... 27
Figure 1.10 : Résultat de squelettisation………..…… 28
Figure 1.11 : Exemple de Suppression du bruit………..…. 29
Figure 2.1 : Exemple de classification avec un KPPV : (a) k= 3, (b) k=5………..…. 36
Figure 2.2 : Example de la classification en utilisant la technique KPPV………... 39
Figure 2.3 : Organigramme de l’algorithme K-moyen……….... 42
Figure 3.1: Séparation de deux ensembles de points par un Hyperplan H………... 47
Figure 3.2 : Hyperplan optimal, marge et vecteurs de support………. 48
Figure 3.3 : Données dans le cas non séparables………... 50
Figure 3.4 : Transformation de l’espace de représentation et l’hyperplan séparateur dans le cas non linéairement séparable………... 52
Figure 3.5: Fonction polynômiale………... 53
Figure 3.6 : Approche une-contre-reste………..…. 55
Figure 3.7 : Neurone biologique………... 58
Figure 3.8 : Modèle d’un neurone formel……….... 59
Figure 3.9 : Les fonctions d’activation……….... 61
Figure 3.10 : Un exemple de perceptron………..……… 62
Figure 3.11 : schéma d'un perceptron multicouche………... 63
Figure 4.1 : L’interface de C++ Builder XE3………... 68
Figure 4.2: Des échantillons de la base de données………..………….. 69
Figure 4.3: Interface d’acquisition des images de notre application………... 70
Figure 4.4: Interface de normalisation des images de l'application………..…... 71
Figure 4.5: Exemple de matrice de distribution (7*7) de la lettre alphabet arabe «Djim»…. 72 Figure 4.6 : Interface de création des corpus………... 73
Figure 4.7 : Représentation graphique de changement du paramètre k et une comparaison entre les distances……….. 74
Introduction
générale
L’un des objectifs de la recherche en informatique est de repousser les limites de ce qui est automatisable. Les tâches répétitives, fastidieuses, portant sur de gros volumes de données, constituent de bons candidats. Citons par exemple le traitement des chèques bancaires, le tri du courrier postal, l’indexation d’archives nationales (archives militaires, formulaires de recensements, fonds bibliothécaires, ...), indexation d’archives privées, traitement du courrier entrant des entreprises, etc . . .
Les ordinateurs séquentiels sont très performants pour les calculs, ils peuvent exécuter des opérations complexes plus vite que le cerveau humain. En reconnaissance de caractère, ce dernier est capable d’analyser une scène très complexe instantanément, alors que le meilleur des algorithmes de reconnaissance de caractère ne pourrait reconnaître que des caractères relativement simples.
La reconnaissance de caractère manuscrite par ordinateur est du domaine de la fiction pour quelques années encore surtout pour la langue arabe. Tous les chercheurs sont confrontés à un problème difficile et incontournable, celui delà d'extraction de l'information.
La variabilité de l’écriture manuscrite permet de confronter les algorithmes de classification et d’apprentissage à des problèmes difficiles et réalistes. La plupart des classifieurs classiques ont donné des résultats remarquables dans ce domaine, notamment les réseaux de neurones. Mais la nécessité de performances élevées dans des applications réelles, a poussé la recherche vers des modèles de classifications de plus en plus complexes. Plusieurs générations de machines d’apprentissage ont vu le jour dans le but de classifier, de catégoriser ou de prédire des structures particulières dans les données. La classification des caractères constitue, par ailleurs, la principale application des machines d’apprentissage, dont les différents travaux ont permis une nouvelle appréhension des modèles de classification.
L’objectif de ce mémoire est de proposer un système de reconnaissance de caractère manuscrite arabe hors-ligne. Ce système utilise deux techniques de classification, une méthode qui est très populaire appelé le K-PPV (k plus proche voisins), et l’autre considéré comme une technique avancée appelé SVM (Support Vector Machine). Après l’implémentation de cette méthode de classification, on va comparer leur résultat dans un système de reconnaissance des caractères arabes manuscrites
Chapitre Ⅰ
Les
systèmes
OCR
1.1. Introduction
De nos jours, l’écriture reste le moyen de communication visuelle le plus utilisé par l’homme. Il n’est donc pas surprenant de voir que de nombreux travaux scientifiques portent sur sa reconnaissance automatique. L’écriture est en fait la réalisation d’un message à transmettre, c’est-à-dire la représentation physique d’un contenu sémantique. Le but de la reconnaissance de l’écriture est de prendre une décision quant au contenu sémantique du message transmis à partir de sa représentation physique. Les applications de systèmes capables de remplir cette tâche sont nombreuses, nous pouvons citer entre autres, la lecture automatique de bons de commande, le traitement automatique des chèques, la vérification de signatures ou encore le tri automatique du courrier.
La reconnaissance optique de caractères ou OCR (en anglais : Optical Recognition Character) est une technologie qui permet de convertir différents types de documents tels que les documents papiers scannés, les fichiers PDF ou les photos numériques vers des formats modifiables et exploitables. Sur le plan méthodologique, l’OCR propose des approches différentes suivant le mode d’écriture : manuscrit ou imprimé. Deux domaines distincts sont considérés, il s’agit de la reconnaissance statique, dite encore « hors-ligne », qui travaille sur un instantané d’encre numérique (sur une image) et la reconnaissance dynamique « on-ligne » où les symboles sont reconnus au fur et à mesure qu’ils sont écrits à la main.
Contrairement au Latin, la reconnaissance de l’écriture arabe manuscrite reste encore aujourd’hui au niveau de la recherche et de l’expérimentation. Cependant et depuis quelques années elle a pris un nouvel essor et fait l’objet d’applications de plus en plus nombreuses. Parmi les domaines d’application, on trouve le domaine postal pour la reconnaissance du code de l’adresse postale et la lecture automatique des chèques bancaires ; le domaine administratif pour la gestion électronique des flux de documents ; les bibliothèques numériques pour l’indexation de documents et la recherche d’informations ; la biométrie pour l’identification du scripteur…etc.
1.2. Caractéristiques de l’écriture arabe
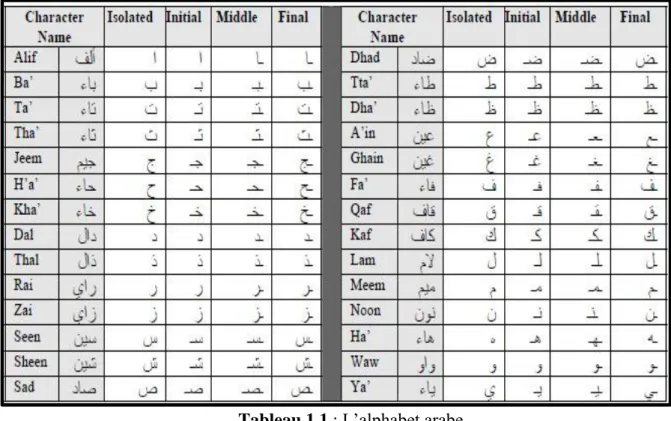
L’écriture arabe est descendue de l’écriture nabatéenne, l’ascendante directe de l’écriture araméenne ancienne qui est un rejeton de l’alphabet phénicien. De là, par dérivations et altérations, allait naître l’alphabet arabe qui restera longtemps, et définitivement jusqu’à nos jours, proche de son ancêtre. L’écriture arabe est donc née aux alentours du VIème siècle de l’écriture cursive nabatéenne. Elle possède plusieurs caractéristiques qui sont [1] :
Tableau 1.1 : L’alphabet arabe.
➢ La plupart des lettres s’attachent entre elles, même en imprimé, ce qui offre à l’écriture arabe la caractéristique de cursivité [2].
➢ L'écriture arabe s'écrit de droite à gauche.
Figure 1.1 : Cursivité, sens et la connectivité de l’écriture arabe.
➢ Six lettres ne s’attachent jamais à la lettre suivante : "ذ" ,"د" ,"ر" ,"ز","أ ", et "و" [3]. De ce fait, un mot unique peut être entrecoupé d’un ou plusieurs espaces donnant plusieurs pseudo-mots ou composantes connexes ou également sous-mots.
Figure 1.2 : Exemple de pseudo-mots constituant des mots arabes.
➢ Les caractères arabes ne possédant pas une taille fixe (hauteur et largeur), leur taille varie
➢ Les caractères arabes sont majoritairement des consonnes, on trouve seulement trois caractères dans la langue arabe qui représentent les voyelles ; "و", "ا" et "ي". Une bonne partie de la vocalisation étant produite par les signes diacritiques [5].
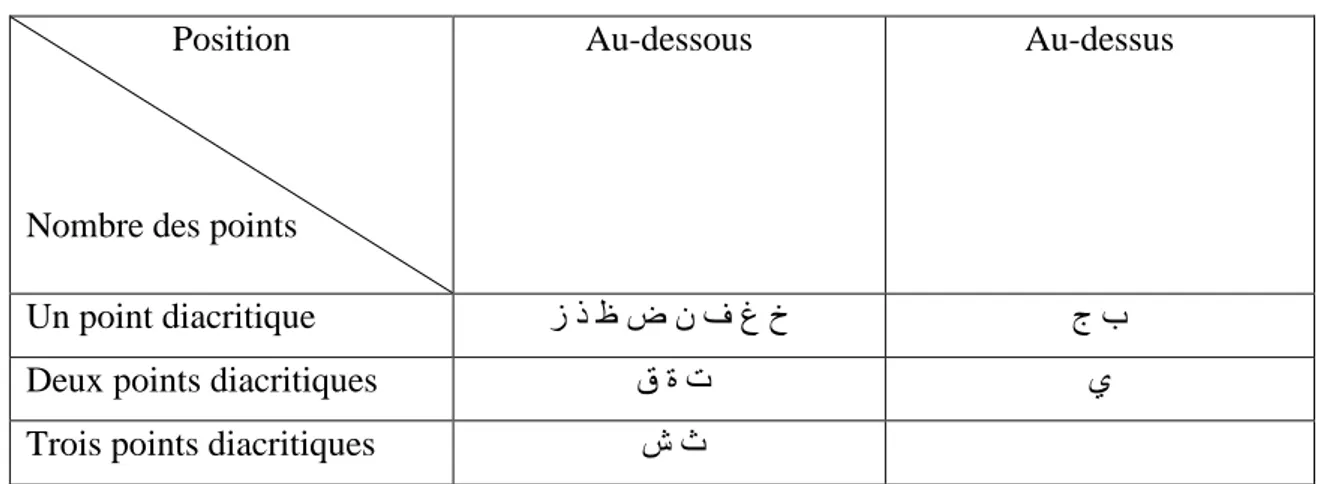
➢ Certains mots se différencient seulement par des signes diacritiques d’où leur importance pour la reconnaissance de mots. Ces signes peuvent se situer au-dessus ou au-dessous du caractère, mais jamais en haut et en bas simultanément [6]. Les signes diacritiques dans la langue arabe sont donc plus nombreux et variés que pour les caractères latins.
Position
Nombre des points
Au-dessous Au-dessus
Un point diacritique ز ذ ظ ض ن ف غ خ ج ب
Deux points diacritiques ق ة ت ي
Trois points diacritiques ش ث
Tableau 1.2 : Lettres arabes ayant des points diacritiques.
➢ La plupart des caractères sont composés de boucles et de courbes, souvent tracées dans le sens horaire [1].
1.3. Différents aspects de l'OCR
L’objectif d’un système OCR est de reconnaître le texte et puis le convertir en une forme modifiable. La reconnaissance optique de caractères implique la traduction du texte dans l’image en codes de caractères modifiables tel que l’ASCII.
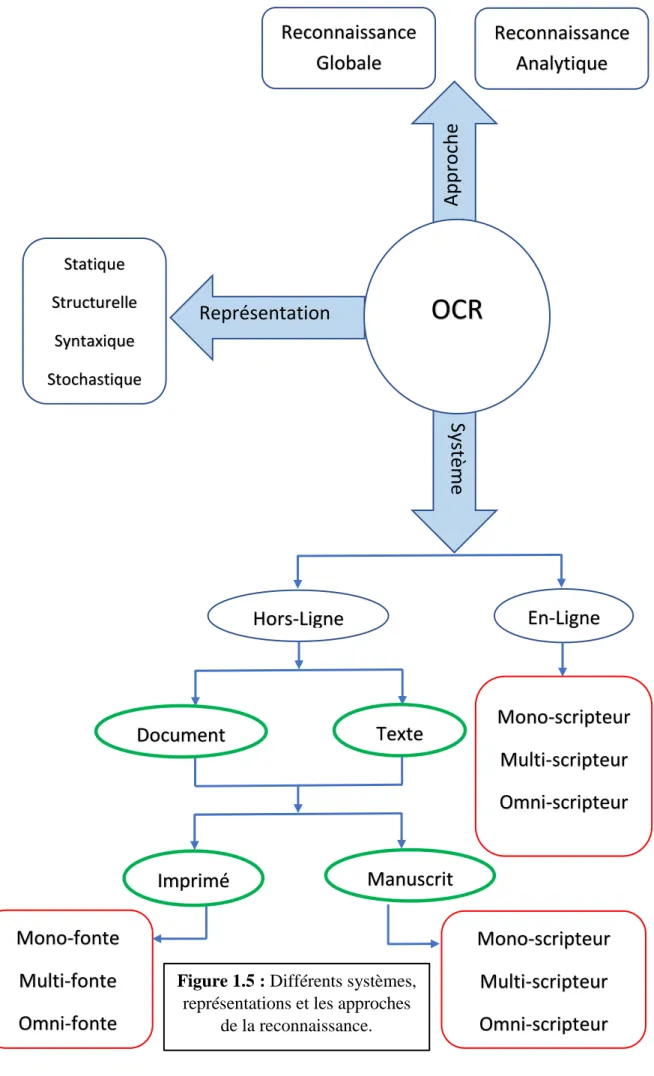
Il est très difficile de créer un système OCR capable de reconnaître n'importe quelle écriture ou fonte. Tout dépend de l'application vissée ou voulu [7] et des données à traiter. Généralement, les systèmes OCR sont classés en se basant sur trois critères :
✓ Outil d’acquisition : Les systèmes qualifiés de « en-ligne » ou « hors-ligne »,
✓ Approches de reconnaissance : approches globales ou analytiques selon que l’analyse s’opère sur la totalité du mot, ou par segmentation en caractères.
✓ Nature des traits caractéristiques : approches statistiques, structurelles ou stochastiques. La reconnaissance de l’écriture manuscrite est un traitement informatique qui a pour but de traduire un texte écrit en un texte codé numériquement. On peut distinguer deux types de reconnaissances :
1.3.1 La reconnaissance en-ligne (on-line)
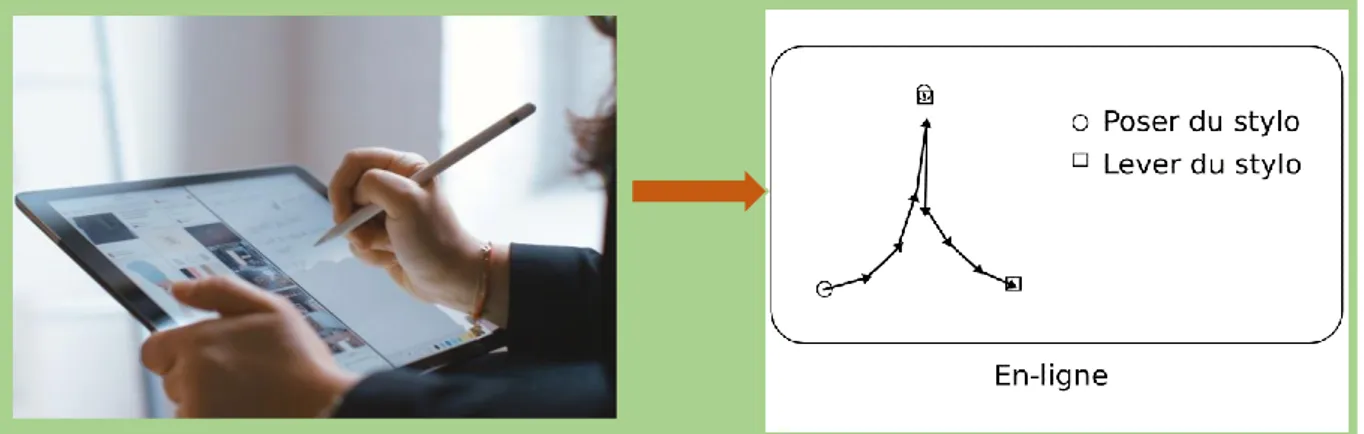
Dans le cas de la reconnaissance en-ligne le système reçois les images d'entrée de données en temps réel, ce qui permet d'intégrer les mouvements du stylo électronique et pressure information [8], et calcule la relation entre les points pour extraire les caractéristiques afin de reconnaître les symboles au fur et à mesure qu’ils sont écrits à la main [7]. Ce mode est réservé généralement à l’écriture manuscrite. La reconnaissance en-ligne présente un avantage majeur c’est la possibilité de correction et de modification de l’écriture de manière interactive vu la réponse en continu du système [9].
Figure 1.3 : Reconnaissance d’écriture en ligne. 1.3.2 Reconnaissance hors ligne (off-line)
Ce cas présente une reconnaissance statique d’images, il s’agit de reconnaître des textes manuscrits à partir de documents écrits au préalable. L’image du texte écrit est numérisée à l’aide d’un scanner, les informations recueilles se présentent sous la forme d’une image discrète constituée d’un ensemble des pixels. L’écriture prend l’aspect d’un signal spatial bidimensionnel numérisé [10].
La reconnaissance hors-ligne peut être classée en plusieurs types : 1.3.2.1 Reconnaissance de texte ou analyse de documents
Dans le premier cas il s’agit de reconnaître un texte de structure limitée à quelques lignes ou mots. La recherche consiste en un simple repérage des mots dans les lignes, puis à un découpage de chaque mot en caractères [11].
Dans le second cas (analyse de document), il s’agit de données bien structurées dont la lecture nécessite la connaissance de la typographie et de la mise en page du document. Ici la démarche n’est plus un simple prétraitement, mais une démarche experte d’analyse de document.
1.3.2.2 Reconnaissance de l’imprimé ou du manuscrit
Les approches diffèrent selon qu’il s’agisse de reconnaissance de caractères imprimés ou manuscrits. Les caractères imprimés sont dans le cas général alignés horizontalement et séparés verticalement, ce qui simplifie la phase de lecture [11].
Dans le cas du manuscrit, les caractères sont souvent ligaturés et leur graphisme est inégalement proportionné provenant de la variabilité intra et inter-scripteurs.
Cela nécessite généralement l’emploi de techniques de délimitation spécifiques et souvent des connaissances contextuelles pour guider la lecture [12].
Dans le cas de l’imprimé, la reconnaissance peut être mono-fonte, multi-fonte ou omni-fonte. Un système est dit mono-fonte s’il ne peut reconnaître qu’une seule fonte à la fois c’est à dire qu’il ne connaît de graphisme que d’une fonte unique. C’est le cas le plus simple de reconnaissance de caractères imprimés [13].
Un système est dit multi-fonte s’il est capable de reconnaître divers types de fontes parmi un ensemble de fontes préalablement apprises [11]. Et un système omni-fonte est capable de reconnaître toute fonte, généralement sans apprentissage préalable. Cependant ceci est quasiment impossible car il existe des milliers de fontes dont certaines illisible par l’homme [13].
La Reconnaissance hors ligne est plus difficile à cause de l’absence d’informations temporelles (Figure1.4).
Figure 1.4 : Reconnaissance d’écriture hors ligne.
1.4. Approches de reconnaissance
Il y a deux approches s'opposent en reconnaissance hors-ligne des mots manuscrits globale et analytique :
1.4.1. Approche globale
L'approche globale se base sur une description unique de l'image du mot, vue comme une entité indivisible [14].
Disposant de beaucoup d'informations, en effet, la discrimination des mots proches est très difficile, et l'apprentissage des modèles nécessite une grande quantité d'échantillons qui est souvent difficile à réunir. Cette approche est souvent appliquée pour réduire la liste des mots candidats dans le contexte d'une reconnaissance à vocabulaire réduits.
1.4.2. Approche analytique
L'approche analytique basée sur un découpage (segmentation) du mot [14]. Elle consiste à segmenter le mot manuscrit en parties inférieures aux lettres appelés graphèmes et à retrouver les lettres puis le mot par la combinaison de ces graphèmes. Cette approche est la seule applicable dans le cas de grand vocabulaire.
Statique Structurelle Syntaxique Stochastique
OCR
App
roch
e
Sys
tè
m
e
Représentation
Reconnaissance
Globale
Reconnaissance
Analytique
Hors-Ligne
En-Ligne
Document
Texte
Imprimé
Manuscrit
Mono-scripteur
Multi-scripteur
Omni-scripteur
Mono-scripteur
Multi-scripteur
Omni-scripteur
Mono-fonte
Multi-fonte
Omni-fonte
Figure 1.5 : Différents systèmes, représentations et les approches
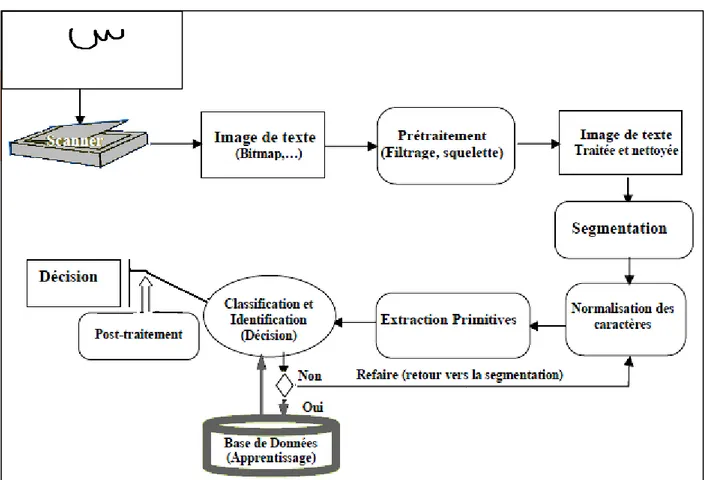
1.5. Les phases d’un système OCR
Un système de reconnaissance fait appel généralement aux étapes suivantes : Acquisition, prétraitements, segmentation, extraction des caractéristiques, classification, suivis éventuellement d’une phase de post-traitement. La figure 1.6 suivante représente globalement le processus général de reconnaissance de l’écriture :
Figure 1.6 : le processus général de reconnaissance de l’écriture 1.5.1 L’acquisition
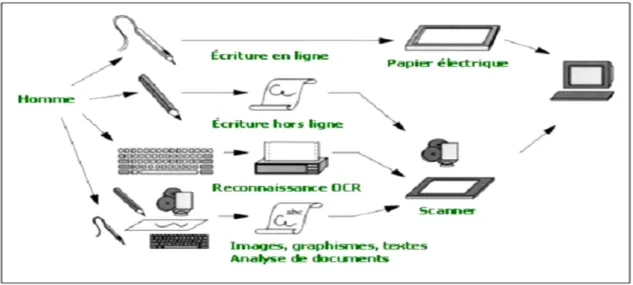
L’acquisition hors ligne et l’acquisition en ligne ce sont deux modes différents d’un système de reconnaissance des mots, ayant chacun ses outils propres d’acquisition et ses algorithmes correspondants de reconnaissance (Figure 1.7). [15]
1.5.1.1 Acquisition hors ligne
Dans le cas hors ligne, il s’agit de reconnaître des textes manuscrits à partir de documents écrits au préalable. L’image du texte écrit est numérisée à l’aide d’un scanneur, les informations recueillies se présentent sous la forme d’une image discrète constituée d’un ensemble de pixels.[15]
1.5.1.2 Acquisition en ligne
Dans le cas de l’acquisition en ligne, les dispositifs d’acquisition les plus répandus sont des tablettes à numériser ou des « papiers électroniques ». L’échantillonnage du tracé délivre une série de coordonnées décrivant la trajectoire du stylet au cours du temps. Les tablettes les plus perfectionnées permettent également d’avoir accès aux informations de pression et d’inclinaison du stylo [11].
Figure 1.7 : Communication écriture Homme-machine. 1.5.2 Etape d’acquisition
Elle consiste en deux phases :
a. Echantillonnage (numérisation) : d’une image est spatial, par découpage en pixels. b. Quantification (codage) : est une valeur numérique donnée à l’intensité lumineuse,
c’est un niveau de gris, appelé la dynamique de l’image.
Cette dynamique est donnée comme suit : 2m, où m est le nombre de bits. Par exemple : le niveau de gris 256 est codé sur 8 bits, l’image couleur est codée sur 24 bits (1 octet pour chaque couleur (R, V, B)) [16].
1.5.3 Le prétraitement
Lorsque l’acquisition est réalisée, la plupart des systèmes comportent une étape de prétraitement. Généralement, ces prétraitements ne sont pas spécifiques à la reconnaissance de texte, mais sont des prétraitements classiques en traitement d’image. Le prétraitement a pour but de préparer l’image du tracé à la phase suivante d’analyse. Il s’agit essentiellement de réduire le bruit superposé aux données et ne garder, autant que possible, que l’information
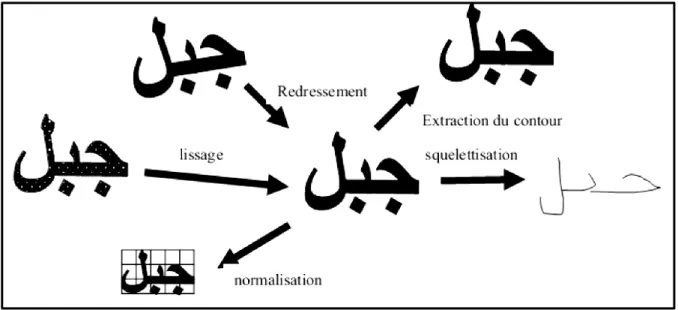
significative de la forme présentée. Le bruit peut être dû au dispositif d’acquisition, aux conditions d’acquisition (éclairage, mise incorrecte du document…), ou encore à la qualité du document d’origine. Parmi les opérations de prétraitements généralement utilisées, citons : la binarisation, le redressement de l’écriture, le lissage, la squelettisation et la normalisation. [17]
Figure 1.8 : Application de certaines opérations de prétraitement sur un mot arabe 1.5.3.1 Binarisation
La binarisation c'est le passage d'une image en couleur, définie par plusieurs niveaux de gris en image bitonale (composée de deux valeurs 0 et 1) qui permet une classification entre le fond (image du support papier en blanc) et la forme (traits des gravures et des caractères en noir). Plusieurs techniques ont été développées dans le but de transformer une image à niveaux de gris ou en couleur, en image binaire. Toutes ces techniques sont basées sur le principe de seuillage comme le montre l’équation suivante :
Ib(x,y) = {0 𝑠𝑖 I𝑛(x, y) < 𝑇
1 𝑠𝑖 I𝑛(x, y) ≥ 𝑇
I𝑛(x, y) décrit l’intensité à "n" niveaux de gris à chaque point de l’image, Ib(x, y) représente
l’intensité à deux niveaux et T est le seuil de binarisation. Si I𝑛(x, y) est supérieur à la valeur de
seuil alors on attribue le point image correspondant à la valeur d’intensité maximale (le blanc). Dans le cas contraire, le point est considéré comme noir et on lui attribue la valeur d’intensité minimale [18].
niveaux de gris). La recherche du seuil passe par plusieurs étapes : binarisation préliminaire basée sur une distribution de mixture multimodale, analyse de la texture à l’aide des histogrammes de longueurs des traits, et sélection du seuil à partir d’un arbre de décision.
Figure 1.9 : Exemple de Binarisation adaptative 1.5.3.2 Transformation par érosion
Si un pixel ‘p’ est noir (p(x,y)=0), et il y a au moins 3 pixels, ou 7 pixels dans les 4-voisins, ou les 8-voisins respectivement, qui sont blancs (Pvoisin(x,y)=1), alors on affecte à ce pixel la
couleur blanche (p(x,y)=1), c-à-d. on efface ce pixel, (C'est un lissage d’un ou deux pixels d’une forme connexe) [18].
1.5.3.3 Transformation par dilatation
C’est l’inverse de la transformation par érosion, si un pixel ‘p’ est blanc (p(x,y)=1), et il y a au moins 3 pixels, ou 7 pixels dans les 4-voisins, ou les 8-voisins respectivement, qui sont noir (Pvoisin(x,y)=0), alors on affecte à ce pixel la couleur noir (p(x,y)=0).
1.5.3.4 Ouverture morphologique
C'est une combinaison d'opérations : érosion suivie d'une dilatation d'une image par le même élément structurant. Servant à adoucir les contours, simplifier les formes en lissant les bosses tout en conservant l’allure globale [18].
1.5.3.5 Fermeture morphologique
C'est le contraire de l’ouverture, elle consiste en une combinaison d'opérations : une dilatation suivie d'érosion d'une image par le même élément structurant. Elle permet de simplifier les formes, en comblant les creux.
1.5.4 Squelettisation
Un algorithme de squelettisation efficace doit permettre la réduction de la quantité de données et la préservation uniquement des caractéristiques essentielles de la forme, de plus, il doit avoir les propriétés suivantes :
1) Préservation de la connexité de la forme.
2) Convergence vers des squelettes d’épaisseur unitaire. 3) Approximation de l’axe médian de la forme.
4) Réduction maximale de données.
Les algorithmes destinés spécifiquement à la squelettisation de l’écriture arabe restent relativement peu nombreux [20] [21]. Notons que l’application directe des algorithmes de squelettisation conçus notamment pour l’écriture latine ou chinoise sur l’écriture arabe ne permet pas d’obtenir des squelettes adaptés, du fait de la présence de marques diacritiques, et la squelettisation de ces marques par ces algorithmes peut les faire disparaître ou les déformer totalement. Par exemple, un point diacritique comme dans la lettre "ب" peut se transformer après squelettisation en un petit trait, ce qui n’est plus adapté pour l’écriture arabe manuscrite, car il est très fréquent que certains scripteurs utilisent un petit trait à la place de deux points comme dans la lettre ي" ". A cause de ces problèmes, les marques diacritiques sont parfois extraites de l’image d’écriture avant la squelettisation puis sont classifiées séparément [22] [23].
Figure 1.10 : Résultat de squelettisation. 1.5.5 Normalisation de la taille
La taille d’un caractère peut varier d’une écriture à l’autre, ce qui peut causer une instabilité des paramètres. Une technique naturelle de prétraitement consiste à ramener les caractères à la même taille [24].
Après la normalisation de la taille, les images de tous les caractères se retrouvent définies dans une matrice de même taille, Pour faciliter les traitements ultérieurs. Cette opération introduit généralement de légères déformations sur les images. Cependant certains traits caractéristique s tels que la hampe dans les caractères ( ط ظ ل ا par exemple) peuvent être éliminées à la suite de la normalisation, ce qui peut entraîner à des confusions entre certains caractères [25]. Des techniques de normalisation tels que la correction de l’inclinaison des lignes, la correction de l’inclinaison des lettres et la normalisation des caractères tendent à réduire cette variation de styles, tailles et orientations d’écriture pour arriver à une forme plus ou moins standard de données [4].
1.5.6 Le lissage
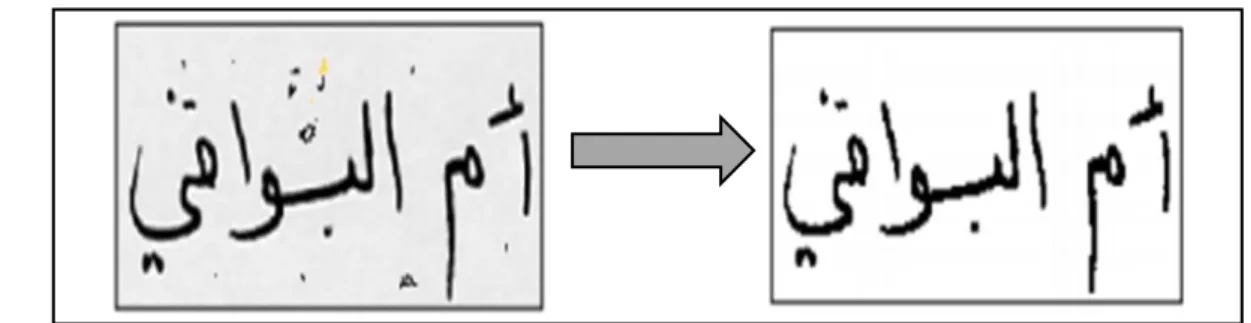
L’image des caractères peut être entachée de bruits dus aux artefacts de l’acquisition et à la qualité du document, conduisant soit à une absence de points ou à une surcharge de points. Les
techniques de lissage permettent de résoudre ces problèmes par des opérations locales qu’on appelle opérations de bouchage et de nettoyage [26].
L’opération de nettoyage permet de supprimer les petites tâches et les excroissances de la forme. Pour le bouchage il s’agit d’égaliser les contours et de boucher les trous internes à la forme du caractère en lui ajoutant des points noirs. Plusieurs autres techniques similaires sont utilisées dont la méthode statistique, une méthode basée sur la morphologie mathématique, …etc, (pour plus de détail sur ces technique le lecteur peut se référer à [11]).
Figure 1.11 : Exemple de Suppression du bruit. 1.5.7 La phase de segmentation
La segmentation est une opération appliquée à l’image qui consiste à subdiviser une scène réelle, en parties constituantes ou objets, en projetant une scène réelle sur un plan. Elle est la première opération à réaliser dans « la reconnaissance des formes ». Il faut donc, disposer d’un certains nombres d’attributs, représentatifs des régions que l’on cherche à extraire, pour procéder à la classification individuelle des points [27].
1.5.7.1 Les techniques de la segmentation
Il existe deux techniques permettant de mettre en œuvre la segmentation. La première, connue sous le nom de segmentation implicite, et la deuxième c’est la segmentation explicite.
A. Segmentation implicite
Les méthodes de segmentation implicite s’inspirent des approches utilisées dans le domaine de la parole, où le signal est divisé en intervalles de temps réguliers, et procèdent à une sur-segmentation importante de l’image du mot à pas fixe (un ou quelques pixels). Cela permet d’assurer un taux de présence important des points de liaison entre les lettres considérées. La segmentation s’effectue pendant la reconnaissance qui assure son guide. Le système recherche dans l’image, des composantes ou des groupements de graphèmes qui correspondent à ses classes de lettres [28]. Classiquement, il peut le faire de deux manières:
1) Soit par fenêtrage : le principe est d’utiliser une fenêtre mobile de largeur variable (qui n’est pas facile à déterminer) pour trouver des séquences de points de segmentation potentiels qui seront confirmés ou non par la reconnaissance de caractères. Elle nécessite deux étapes : la génération d’hypothèses de segmentation (séquences de points obtenus par le fenêtrage) ; la deuxième est le choix de la meilleure hypothèse de la reconnaissance (validation).
2) Soit par recherche de primitives : il s’agit de détecter les combinaisons de primitives qui donneront la meilleure reconnaissance.
B. Segmentation explicite
Cette approche, souvent appelée dissection, est antérieure à la reconnaissance et n’est pas remise en cause pendant la phase de reconnaissance. Les hypothèses des caractères sont déterminées à partir des informations de bas niveau présentes sur l’image. Ces hypothèses sont définitives, et doivent être d’une grande fiabilité car la moindre erreur de segmentation remet en cause la totalité des traitements ultérieurs.
Les approches de segmentation explicite, s’appuient sur une analyse morphologique du mot manuscrit pour localiser des points de segmentation potentiels. Elles sont particulièrement adaptées à l’analyse de la représentation bidimensionnelle et donc plus souvent utilisées dans les systèmes de reconnaissance hors-ligne de mots. Certaines méthodes de segmentation explicite sont basées sur une analyse par morphologiques mathématiques, exploitent les concepts de régularité et singularité du tracé, analyse des contours supérieurs/inferieurs du mot. Les points de segmentation potentiels détectés sont confirmés à l’aide de diverses heuristiques [28].
1.5.8 Extraction des caractéristiques
Au lieu d'alimenter directement le module de reconnaissance avec l'image du caractère, il est préférable de la paramétrer grâce à l'extraction de certaines de ses caractéristiques. Cette étape de la reconnaissance consiste à extraire des caractéristiques permettant de décrire de façon non équivoque les formes appartenant à une même classe de caractères tout en les différenciant des autres classes [29].
Les types de caractéristiques peuvent être classés en trois groupes principaux : caractéristiques structurelles, caractéristiques statistiques et les transformations globales [30][31].
A. Caractéristiques structurelles
Les caractéristiques structurelles décrivent une forme en termes de sa topologie et sa géométrie en donnant ses propriétés globales et locales. Parmi ces caractéristiques on peut citer : [30]
• Les traits et les anses dans les différentes directions ainsi que leurs tailles. • Les points terminaux.
• Les points d’intersections. • Les boucles.
• Le nombre de points diacritiques et leur position par rapport à la ligne de base. • Les voyellisions et les zigzags (hamza).
• La hauteur et la largeur du caractère.
• La catégorie de la forme (partie primaire ou point diacritique, etc).
• Plusieurs autres caractéristiques peuvent être tirés, suivant qu’ils soient extraits d’une courbe, un trait ou un segment de contour [32].
B. Caractéristiques statistiques
Les caractéristiques statistiques décrivent une forme en termes d’un ensemble de mesures extraites à partir de cette forme. Les caractéristiques utilisées pour la reconnaissance de textes arabes sont : le zonage (zonning), les caractéristiques de lieu géométrique (Loci) et les moments [30].
La méthode Loci est basée sur le calcul du nombre de segments blancs et de segments noirs le long d'une ligne verticale traversant la forme, ainsi que leurs longueurs [31]. C. Transformations globales
Elles sont naturellement basées sur une transformation globale de l'image. La transformation consiste à convertir la représentation en pixels en une représentation plus abstraite pour réduire la dimension des caractères, tout en conservant le maximum d'informations sur la forme à reconnaître. Par exemple : la transformée de Hough, la transformée de Fourier, et les moments de Zernike [28].
1.5.9 La reconnaissance
Cette étape consiste à déterminer la classe d’appartenance de la forme considérée en utilisant un classifieur. Les classifieurs les plus utilisés dans la reconnaissance d’écriture sont les SVMs (Machine à Vecteur de Support), les K-ppv (K-plus proche voisins) et les RNA (Réseau de Neurone Artificiel).
L’étape de la reconnaissance englobe deux phases : l’apprentissage et la décision ou aussi la classification.
1) Apprentissage : dans le cas d’apprentissage il s’agit en fait de fournir au système un ensemble de formes qui sont déjà connues (on connaît la classe de chacune d’elles). C’est cet ensemble d’apprentissage qui va permettre de « régler » le système de reconnaissance de façon à ce qu’il soit capable de reconnaître ultérieurement des formes de classes inconnues [33]. Il existe deux types d’apprentissage :
A. Supervisé : l’apprentissage est dit supervisé si les différentes familles des formes sont connues a priori et si la tâche d’apprentissage est guidée par un superviseur ou professeur, c'est-à-dire le concepteur, qui indique, pour chaque forme de l’échantillon rentrée, le nom de la famille qui la contient.
B. Non-supervisé : l’apprentissage non-supervisé ou sans professeur, consiste à faire une classification automatique. Il s’agit, à partir d’échantillon de référence et de règles de regroupement, de construire automatiquement les classes ou les modèles sans intervention de l’opérateur. Ce mode d’apprentissage nécessite un nombre élevé d’échantillons et des règles de construction précises et non-contradictoires pour bien assurer la formation des classes. Il évite l’assistance d’un opérateur mais n’assure pas toujours une classification correspondante à la réalité (celle de l’utilisateur) [34].
2) Classification : à partir du vecteur descriptif d'une entrée, le module de reconnaissance cherche parmi les classes d'apprentissage connues, celles qui sont les plus proches. La classification peut conduire à un succès si la réponse est unique (un seul modèle répond à la description de la forme), et à une confusion si la réponse est multiple (plusieurs modèles correspondent à la description). Elle peut aussi conduire à un rejet de la forme s’il n’existe aucun modèle correspond à sa description. Dans le cas où la classification est un succès ou une confusion, la décision peut être accompagnée d'une mesure de vraisemblance, appelée aussi score ou taux de reconnaissance. Les équations suivantes
montrent respectivement comment calculer les trois mesures de performance d’un OCR ; le taux de reconnaissance (TL), le taux d’erreur (TE) et le taux de rejet (TR).
TL
=
𝑵𝒐𝒎𝒃𝒓𝒆 𝒅′𝒆𝒏𝒕𝒊𝒕é𝒔 𝒃𝒊𝒆𝒏 𝒓𝒆𝒄𝒐𝒏𝒏𝒖𝒆𝒔 𝑵𝒐𝒎𝒃𝒓𝒆 𝒕𝒐𝒕𝒂𝒍 𝒅′𝒆𝒏𝒕𝒊𝒕é𝒔 𝒑𝒓é𝒔𝒆𝒏𝒕é𝒆𝒔 𝒂𝒖 𝒄𝒍𝒂𝒔𝒔𝒊𝒇𝒊𝒆𝒖𝒓 TE=
𝑵𝒐𝒎𝒃𝒓𝒆 𝒅′𝒆𝒏𝒕𝒊𝒕é𝒔 𝒎𝒂𝒍− 𝒓𝒆𝒄𝒐𝒏𝒏𝒖𝒆𝒔 𝑵𝒐𝒎𝒃𝒓𝒆 𝒕𝒐𝒕𝒂𝒍 𝒅′𝒆𝒏𝒕𝒊𝒕é𝒔 𝒑𝒓é𝒔𝒆𝒏𝒕é𝒆𝒔 𝒂𝒖 𝒄𝒍𝒂𝒔𝒔𝒊𝒇𝒊𝒆𝒖𝒓 TR=
𝑵𝒐𝒎𝒃𝒓𝒆 𝒅′𝒆𝒏𝒕𝒊𝒕é𝒔 𝒓𝒆𝒋𝒆𝒕é𝒆𝒔 𝑵𝒐𝒎𝒃𝒓𝒆 𝒕𝒐𝒕𝒂𝒍 𝒅′𝒆𝒏𝒕𝒊𝒕é𝒔 𝒑𝒓é𝒔𝒆𝒏𝒕é𝒆𝒔 𝒂𝒖 𝒄𝒍𝒂𝒔𝒔𝒊𝒇𝒊𝒆𝒖𝒓 1.5.10 La reconnaissance et la décisionLa décision est l’ultime étape de reconnaissance. A partir de la description en paramètres du caractère traité, le module de reconnaissance cherche parmi les modèles de référence en présence, ceux qui lui sont les plus proches.
La reconnaissance peut conduire à un succès si la réponse est unique (un seul modèle répond à la description de la forme du caractère). Elle peut conduire à une confusion si la réponse est multiple (plusieurs modèles correspondent à la description). Enfin elle peut conduire à un rejet de la forme si aucun modèle ne correspond à sa description. Dans les deux premiers cas, la décision peut être accompagnée d’une mesure de vraisemblance, appelée aussi score ou taux de reconnaissance [11].
1.5.11 Le post-traitement
L’objectif du post-traitement est d’améliorer le taux de la reconnaissance. Il est responsable de sélectionner une solution parmi un ensemble en ayant recours à des informations de haut niveau (lexicales, syntaxiques, sémantiques, pragmatiques …) qui ne sont pas disponibles au niveau du classifieur [17]. Comme la classification peut aboutir à plusieurs candidats possibles, le post-traitement a pour objet d'opérer une sélection de la solution en utilisant des niveaux d'informations plus élevés (syntaxiques, lexicales, sémantiques...) [35]. Le post-traitement se charge également de vérifier si la réponse est correcte (même si elle est unique) en se basant sur d'autres informations non disponibles au classifieur.
1.6 Conclusion
Nous avons présenté dans ce chapitre le concept de reconnaissance des caractères d’une façon générale, en mettant le point sur les caractéristiques de l’écriture manuscrite Arabe et les différents aspects d'un OCR ainsi que l’organisation générale d’un système de reconnaissance. Ensuite nous avons abordé les différentes étapes intervenant dans la conception d'un système de reconnaissance de caractères. Nous nous focaliserons dans le chapitre suivant sur les méthodes utilisés dans la phase de classification par des techniques classiques.
Chapitre Ⅱ
Les
techniques de
classification
2.1 Introduction
Les méthodologies de reconnaissance sont nombreuses. En réalité, il n’existe pas de méthode "spécifique" pour la reconnaissance de caractères, ce sont plutôt des adaptations des méthodes d’optimisation issues des méthodes classiques de reconnaissance de formes. Cependant, les capacités de l’homme à reconnaître des objets, des personnes ou l’écriture d’une personne inconnue par exemple, quel que soit le contexte (on peut reconnaître une personne que l’on connaît de dos, ou encore lire l’écriture de tierces personnes), ce qui a conduit les chercheurs à trouver des méthodes et des techniques de reconnaissance souples et intelligentes. Parmi ces méthodes de classification on trouve les méthodes statistiques, stochastiques, linguistiques et hybrides.
Les approches statistiques bénéficient des méthodes d’apprentissage automatique qui s’appuient sur des bases théoriques fondées, telles que la théorie de la décision bayésienne, les méthodes de séparation linéaire, les méthodes de classification non supervisée…. En reconnaissance, le problème revient à affecter une forme inconnue à l’une des classes obtenues pendant l’apprentissage.
Parmi les méthodes statistiques les plus couramment utilisées la méthode de K-PPV (K plus proches voisins) et la technique K-moyen.
2.2 Méthode des K plus proches voisins (KPPV)
2.2.1 Définition
La méthode des plus proches voisins (noté parfois k-PPV ou k-NN pour -Nearest-Neighbor) consiste à déterminer pour chaque nouvel individu que l’on veut classer, la liste des plus proches voisins parmi les individus déjà classés. L’individu est affecté à la classe qui contient le plus d’individus parmi ces plus proches voisins. Cette méthode nécessite de choisir une distance, la plus classique est la distance euclidienne, et le nombre de voisins à prendre en compte [36].
La méthode K-PPV suppose que les données se trouvent dans un espace de caractéristiques. Cela signifie que les points de données sont dans un espace métrique. Les données peuvent être des scalaires ou même des vecteurs multidimensionnels [37] [38].
La méthode des k plus proches voisins est utilisée pour la classification et la régression. Dans les deux cas, l'entrée se compose des k données d’entraînement les plus proches dans l'espace de caractéristiques [37] [38].
L'algorithme KNN est l'un des plus simples de tous les algorithmes d'apprentissage automatique. Il est un type d'apprentissage basé sur l'apprentissage paresseux (lazy learning).
En d'autres termes, il n'y a pas de phase d'entraînement explicite ou très minime. Cela signifie que la phase d'entraînement est assez rapide [37].
L’algorithme KNN figure parmi les plus simples algorithmes d’apprentissage artificiel. Dans un contexte de classification d’une nouvelle observation 𝑥, l’idée fondatrice simple est de faire voter les plus proches voisins de cette observation. La classe de 𝑥 est déterminée en fonction de la classe majoritaire parmi les 𝑘 plus proches voisins de l’observation 𝑥 [39].
La méthode KNN est donc une méthode à base de voisinage, non-paramétrique, Ceci signifiant que l’algorithme permet de faire une classification sans faire d’hypothèse sur la fonction 𝑦 = 𝑓(𝑥1, 𝑥2, … , 𝑥𝑝) qui relie la variable dépendante aux variables indépendantes [39].
Cette méthode utilise principalement deux paramètres : une fonction de similarité pour comparer les individus dans l’espace de caractéristiques et le nombre k qui décide combien de voisins influencent la classification [40]. Les choix de la distance et du paramètre k sont primordiaux pour le bon fonctionnement de cette méthode.
Figure 2.1 : Exemple de classification avec un KPPV : (a) k= 3, (b) k=5.
2.2.2 Algorithme K-NN
L’algorithme K Plus Proche Voisins KPPV affecte une forme inconnue à la classe de son plus proche voisin en le comparant aux formes stockées dans une classe de références nommée prototypes. Il renvoie les K formes les plus proches de la forme à reconnaître suivant un critère de similarité. Une stratégie de décision permet d’affecter des valeurs de confiance à chacune des classes en compétition et d’attribuer la classe la plus vraisemblable (au sens de la métrique choisie) à la forme inconnue [11][26].
(a) (b)
1) Algorithme 1-NN
La méthode du plus proche voisin est une méthode non paramétrique où une nouvelle observation est classée dans la classe d’appartenance de l’observation de l’échantillon d’apprentissage qui lui est la plus proche, au regard des covariables utilisées. La détermination de leur similarité est basée sur des mesures de distance. Formellement, soit L l’ensemble de données à disposition ou échantillon d’apprentissage :
𝐿 = {(𝑦𝑖, 𝑥𝑖), 𝑖 = 1, … . , 𝑛𝐿}
Où 𝑦𝑖 ∈ {1, … . , 𝑐} dénote la classe de l’individu 𝑖 et le vecteur 𝑥𝑖 = (𝑥𝑖1, … , 𝑥𝑖𝑝) représente les variables prédicatrices de l’individu 𝑖. La détermination du plus proche voisin est basée sur un fonction distance arbitraire 𝑑(. , . ).
La distance euclidienne ou dissimilarité entre deux individus caractérisés par 𝑝 covariables est définie par :
𝑑𝑒(𝑥, 𝑦) = √∑(𝑥𝑖 − 𝑦𝑖)2 𝑛
𝑖=1
Ou 𝑥, 𝑦 sont des vecteurs.
Ainsi, pour une nouvelle observation (𝑦, 𝑥) le plus proche voisin (𝑦1− 𝑥1) dans l’échantillon d’apprentissage est déterminé par :
𝑑(𝑥, 𝑥1) = 𝑚𝑖𝑛𝑖(𝑑(𝑥, 𝑥𝑖))
Et 𝑦 = 𝑦1, la classe du plus proche voisin, est sélectionnée pour la prédiction de 𝑦. Les notations 𝑥(𝑗) et 𝑦(𝑗), représentent respectivement le jème plus proche voisin de x et sa classe d’appartenance.
La méthode est justifiée par l’occurrence aléatoire de l’échantillon d’apprentissage. La classe 𝑌(1) du voisin le plus proche 𝑥(1) d’un nouveau cas 𝑥 est une variable aléatoire. Ainsi la probabilité de classification de 𝑥 dans la classe 𝑌(1) est 𝑃[𝑌(1)/𝑥(1)]. Pour des grands échantillons d’apprentissage, les individus 𝑥 et 𝑥(1) coïncident de très près, si bien que 𝑃[𝑌(1)/𝑥(1)] ≈ 𝑃[𝑦/𝑥]. Ainsi, la nouvelle
observation (individu) 𝑥 est prédite comme appartenant à la vraie classe 𝑦 avec une probabilité égale approximativement à 𝑃[𝑦/𝑥] [39].
2) Algorithme K-NN
Une première extension de cette idée, qui est largement et communément utilisée en pratique, est la méthode des k plus proches voisins. La plus proche observation n’est plus la seule observation utilisée pour la classification. Nous utilisons désormais les 𝑘
plus proches observations. Ainsi la décision est en faveur de la classe majoritairement représentée par les 𝑘 voisins. Soit 𝑘𝑟 le nombre d’observations issues du groupe des plus proches voisins appartenant à la classe 𝑟 [39].
∑ 𝑘𝑟 = 𝑘 𝑐
𝑟=1
Ainsi une nouvelle observation est prédite dans la classe 𝑙 avec : 𝑙 = 𝑚𝑎𝑥𝑟(𝑘𝑟)
Ceci évite que la classe prédite ne soit déterminée seulement à partir d’une seule observation. Le degré de localité de cette technique est déterminé par le paramètre 𝑘 : pour 𝑘 = 1, on utilise la méthode du seul plus proche voisin comme technique locale maximale, pour 𝑘 → 𝑛𝑙 on utilise la classe majoritaire sur l’ensemble intégral des
observations (ceci impliquant une prédiction constante pour chaque nouvelle observation à classifier) [39].
2.2.3. Quelques règles sur le choix de k
Le paramètre 𝑘 doit être déterminé par l’utilisateur : 𝑘 ∈ 𝑁 . En classification binaire, il est utile de choisir 𝑘 impair pour éviter les votes égalitaires. Le meilleur choix de 𝑘 dépend du jeu de donnée. En général, les grandes valeurs de 𝑘 réduisent l’effet du bruit sur la classification et donc le risque de sur-apprentissage, mais rendent les frontières entre classes moins distinctes. Il convient donc de faire un choix de compromis entre la variabilité associée à une faible valeur de 𝑘 contre un ‘oversmoothing’ ou surlissage (i.e gommage des détails) pour une forte valeur de 𝑘. Un bon 𝑘 peut être sélectionné par diverses techniques heuristiques, par exemple, de validation-croisée ou la valeur de 𝑘 qui minime l’erreur de classification [39].
2.2.4 Example d’algorithme K-NN
Dans l’exemple suivant, on a 3 classes et le but est de trouver la valeur de la classe de l’exemple .
Figure 2.2 : Example de la classification en utilisant la technique KPPV
Classification avec l'algorithme des k plus proches voisins, le nouvel individu (le cercle noir) sera affecté à la classe " cercle bleu " dans les deux cas : k=5 ou k=18, car la majorité de ses k voisins appartiennent à cette classe.
2.2.5 Avantages de la méthode des k plus proches voisins
La méthode des k plus proches voisins représente des avantages tels que : 1. L’algorithme KNN est robuste envers des données bruitées.[42]
2. La méthode des k plus proches voisins est efficace si les données sont larges et incomplètes.[43]
3. Cette méthode est l'une des plus simples de tous les algorithmes d'apprentissage automatique.[37]
2.2.6 Inconvénients de la méthode des k plus proches voisins
La méthode des k plus proches voisins comporte des inconvénients tels que :
1. Le besoin de déterminer la valeur du nombre des plus proches voisins (le paramètre k).[41] 2. Le temps de prédiction est très long puisqu’on doit calculer la distance de tous les
exemples.[42]
3. Cette méthode est gourmande en espace mémoire car elle utilise une grande capacité de stockage pour le traitement des corpus.[40]
2.2.7 Domaine d’application
L’algorithme k-NN est utilisé dans des nombreux domaines, on peut citer : ❖ La reconnaissance des formes.
❖ La recherche des nouveaux biomarqueurs pour le diagnostic. ❖ Algorithmes de compression.
❖ Analyse d’image satellite. ❖ Le marketing ciblé.
2.3 La technique de classification K-means (Clustring)
2.3.1 Définition
L’algorithme K-means (K-moyen) est l’un des plus simples algorithmes d’apprentissage non supervisé, appelée algorithme des centres mobiles [44] [45]. La méthode k-moyen a été introduite par MacQueen en 1967. En 1965 Forgy a publié un algorithme similaire, c’est pour cette raison qu’elle est parfois référée à Forgy. C’est une méthode efficace qui permet de diviser un ensemble de données en k classes homogènes [46].
La méthode K-moyen est utilisée dans l’apprentissage non supervisé. Elle est itérative c’est-à-dire qu’elle converge vers une solution quelque soit son point de départ [46] [47].
Il attribue chaque point dans un cluster dont le centre (centroïde) est le plus proche. Le centre est la moyenne de tous les points dans le cluster, ses coordonnées sont la moyenne arithmétique pour chaque dimension séparément de tous les points dans le cluster car chaque cluster est repr
é
senté
par son centre de gravité.2.3.2 Principe de fonctionnement
Dans un premier temps, l’algorithme choisit le centre des 𝑘 clusters à 𝑘 objets. Par la suite, on calcule la distance entre les objets et les 𝑘 centres et on affecte les objets aux centres les plus proches. Ensuite, les centres sont redéfinis à partir des objets qui ont été affectés aux différents clusters. Puis, les objets sont assignés en fonction de leur distance aux nouveaux centres et ainsi de suite [46] [47]. Après, on réitère le processus jusqu’à atteindre un état de stabilité où aucune amélioration n’est possible, nous pouvons constater que les 𝑘 centroïdes changent leur localisation par étape jusqu’à plus de changements sont effectués. En d’autres termes les centroïdes ne bougent plus.
▪ Ils minimisent la distance entre les points assignés à chaque classe et les centre de gravité associés : 1 𝑁∑(𝑥 − 𝜇𝜔̂ (𝑥)) 𝑇 . (𝑥 − 𝜇𝜔̂ (𝑥)) 𝑥
▪ Où 𝜔̂(𝑥) est la classe d'assignation de la donnée 𝑥.
▪ 𝜔̂(𝑥) est la classe dont le centre de gravité est le plus proche de 𝑥 : 𝜔̂(𝑥) = 𝑎𝑟𝑔𝑚𝑖𝑛𝐾(𝑥 − 𝜇𝑘)𝑇. (𝑥 − 𝜇𝑘)
Il existe plusieurs types de distance pour calculer la distance entre les objets et les k centres. Parmi ces distances, on peut citer : [48]
- La distance Euclidienne. - La distance de Minkowsky. - La distance de Manhattan.
La distance Euclidienne est souvent utilisée. [48]
L'algorithme K-moyen est un algorithme glouton (Greedy Algorithm) dont la performance dépend fortement de l’estimation initiale de la partition. Les méthodes d'initialisation couramment utilisées sont Forgy et la partition aléatoire. Dans la méthode de Forgy les k centres initiaux sont choisis au hasard de l’ensemble de données. La méthode de partition aléatoire affecte chaque objet à un cluster aléatoire puis elle calcule le centre initial de chaque cluster. [46] [49]
2.3.3 L’algorithme de K-moyen
Le fonctionnement de K-moyen se résume dans les étapes suivantes :[40]
1. On choisit k objets au hasard qu’on considère comme des centres pour les classes initiales. 2. On affecte chaque objet au centre le plus proche pour obtenir une partition de k classes.
𝑆𝑖(𝑇) = {𝑥𝑖: ‖𝑥𝑗− 𝑚(𝑡)𝑖 ‖ ≤ ‖𝑥𝑗− 𝑚𝑖∗(𝑡)‖ 𝑝𝑜𝑢𝑟 𝑖∗ = 1, … , 𝑘} 3. On recalcule les centres de chaque classe.
𝑚𝑖(𝑡+1) = 1
|𝑆𝑖(𝑡)|∑𝑥𝑗∈𝑆𝑗(𝑡)𝑥𝑗
Figure 2.3 : Organigramme de l’algorithme K-moyen
2.3.4 Example de classification K-means
Assignation Mise à jour des centres
𝜇̂
𝑘12.3.5 Domaines d’application
❖ Marketing :
Segmentation du marché afin d’obtenir des groupes de clients distinct à partir d’une base de données d’achat.
❖ Assurance :
Identifications des groupes d’assurés distincts associés à un nombre important de déclarations.
❖ Planifications des villes :
Identifications des groupes d’habitons suivant le type d’habitation, ville, localisation géographique …
❖ Médecine :
Localisation des tumeurs dans le cerveau.
2.3.6 Les avantages du K-moyen
La méthode du K-moyen comporte des avantages, comme par exemple : 1. L’assimilation de cette méthode est rapide.
2. La méthode simple à appliquer.
3. Applicable à des données de grandes tailles, et aussi à tout type de données (mêmes textuelles), en choisissant une bonne notion de distance.
2.3.7 Les Inconvénients du K-moyen
La méthode du K-moyen comporte les inconvénients suivants : 1. La difficulté de comparer la qualité des clusters obtenus.
2. La performance de l’algorithme dépend fortement de l’estimation initiale de la partition. 3. Le choix du paramètre k influence les résultats.
2.4 Conclusion
Dans ce chapitre, nous avons présenté une vue détaillée des principales méthodes de classification classique qui existent déjà et qui sont incluses dans un processus de reconnaissances des caractères arabes manuscrits, ainsi que des exemples bien expliqués sur chaque technique après nous avons cité quelques avantages et inconvénients de chacune d’entre elles.
Dans le chapitre suivant nous nous intéresserons sur les techniques de classification avancées qui sont utilisées dans la reconnaissance des caractères arabes.
Chapitre Ⅲ
Les techniques
de
classification
avancées
3.1 Introduction
En reconnaissance de formes, les phases d'apprentissage et de classification constituent des étapes fondamentales qui conditionnent en grande partie les performances du système. Classifier des formes ou individus (par exemple des objets, des images, des phonèmes, …) décrits par un ensemble de grandeurs caractéristiques (taille ou masse de l’objet, pixels de l’image numérisée, spectre acoustique du phonèmes, …), c’est les ranger en un certain nombre de catégories ou classes définies à l’avance.
La classification c’est l’action de ranger par classes, par catégories des objets avec des propriétés communes. Il existe deux catégories de classification : classification supervisée et classification non supervisée. La classification est l’élaboration d’une règle de décision qui transforme les attributs caractérisant les formes en appartenance à une classe ; passage de l’espace de représentation vers l’espace de décision. La classification consiste alors à identifier les classes auxquelles appartiennent les formes à partir des caractéristiques préalablement choisies et calculés. L’algorithme ou la procédure qui réalise cette application est appelé classifieur.
Dans la littérature scientifique, plusieurs méthodes de classification ont été présentées. Dans ce chapitre nous allons présenterdeux techniques : Machines à vecteurs de support et réseau de neurones.
3.2 Machines à vecteurs de support
3.2.1 Historique
Introduit par Vapnik en 1990, les machines à vecteurs de support sont des techniques d'apprentissage supervisé destinées à résoudre des problèmes de classification et de régression. Elles reposent sur deux notions principales : la notion de marge maximale et la notion de fonction noyau. [53] [40]
Ce modèle était toutefois linéaire et l’on ne connaissait pas encore le moyen d’induire des frontières de décision non linéaires. En 1992, Boser et Al proposent d’introduire des noyaux non-linéaires pour étendre le SVM au cas non-linéaire [50]. En 1995, Cortes et Al proposent une version régularisée du SVM qui tolère les erreurs d’apprentissage avec pénalités [51] [52]. Depuis, les SVMs (le pluriel est utilisé pour désigner les différentes variantes du SVM) n’ont cessé de susciter l’intérêt de plusieurs communautés de chercheurs de différents domaines
3.2.2 Le principe des SVM
Le but des SVM est de trouver un séparateur entre deux classes qui soit au maximum éloigné de n'importe quel point des données d'entraînement. Si on arrive à trouver un séparateur linéaire c’est-à-dire qu’il existe un hyperplan séparateur alors le problème est dit linéairement séparable sinon il n'est pas linéairement séparable et il n'existe pas un hyperplan séparateur. [53] [40]
Figure 3.1: Séparation de deux ensembles de points par un Hyperplan H.
Pour deux classes et des données linéairement séparable, il y a beaucoup de séparateurs linéaires possibles. Les SVM choisissent seulement celui qui est optimal, c’est-à-dire la recherche d’une surface de décision qui soit éloignée au maximum de tout point de données. Cette distance de la surface de décision au point de données le plus proche détermine la marge maximale du classifieur. En effet, pour obtenir un hyperplan optimal, il faut maximiser la marge entre les données et l’hyperplan. [53] [40]
H Y
Figure 3.2 : Hyperplan optimal, marge et vecteurs de support.
Par intuition, le fait d’avoir une marge plus large fournit plus de sécurité lorsque l’on classe un nouvel exemple. De plus, si l’on trouve le classificateur qui se comporte le mieux vis- à-vis des données d’apprentissage, il est clair qu’il sera aussi celui qui permettra au mieux de classer les nouveaux exemples.
3.2.3 Le SVM linéaire
Le principe de base des SVM consiste de ramener le problème de la discrimination à celui, linéaire, de la recherche d’un hyperplan optimal. Deux idées ou astuces permettent d’atteindre cet objectif :
▪ La première consiste à définir l’hyperplan comme solution d’un problème d’optimisation sous contraintes dont la fonction objective ne s’exprime qu’à l’aide de produits scalaires entre vecteurs et dans lequel le nombre de contraintes “actives” ou vecteurs supports contrôle la complexité du modèle.
▪ Le passage à la recherche de surfaces séparatrices non linéaires est obtenu par l’introduction d’une fonction noyau (kernel) dans le produit scalaire induisant implicitement une transformation non linéaire des données vers un espace intermédiaire (feature space) de plus grande dimension.
3.2.3.1 Cas linéairement séparable
Considérons « 𝑙 » points {(𝑥1, 𝑦1) , (𝑥2, 𝑦2) , … … … . , (𝑥𝑙, 𝑦𝑙)} ,𝑥𝑖 ∈ 𝑅𝑁