© Grace Ngambo Domche, 2021
Adaptation à la maladie de Lyme: comparaison des
modes de collectes de données par téléphone et web
Mémoire
Grace Ngambo Domche
Maîtrise en mesure et évaluation - avec mémoire
Maître ès arts (M.A.)
Adaptation à la maladie de Lyme:
Comparaison des modes de collectes de données par
téléphone et web
Mémoire
Grâce Ngambo
Sous la direction de :
ii
Résumé
Le mode de collecte web gagne de plus en plus de popularité depuis sa création, ceci notamment en raison des avantages qu’il apporte en termes de coût et de temps. Cependant, les tendances non-probabilistes des échantillons web font souvent douter de leur capacité à fournir des résultats aussi représentatifs que ceux d’un mode traditionnel typique tel que le téléphone. Le but de ce mémoire est de comparer les modes non-probabiliste web et probabiliste téléphone souvent suggérés par les firmes de sondage au Québec. Nous analysons principalement les éventuelles différences entre les échantillons web et téléphone du point de vue de l’adaptation à la maladie de Lyme. Plus spécifiquement, les trois objectifs de l’étude sont de : (1) comparer la représentativité des deux échantillons avec les données du recensement en termes de caractéristiques sociodémographiques, (2) comparer ces modes d’enquête en ce qui concerne l’estimation des taux d’adoption de comportements préventifs à l’égard de la maladie de Lyme tel que rapportés par les répondants aux deux sondages, et (3) tester l’invariance de la mesure des comportements préventifs des échantillons non probabiliste (panel Web) et probabiliste (téléphone). Les données proviennent d’une étude sur les comportements d’adaptation à la maladie de Lyme. Les échantillons panel Web (n=956) et téléphone (n=1003) sont constitués de résidents québécois de 18 ans et plus habitant les régions de risques faible à significatif. Les résultats montrent premièrement qu’aucun des échantillons n’est représentatif de la population cible au regard des caractéristiques sociodémographiques telles que rapportées dans le recensement canadien de 2016. Deuxièmement, nos résultats indiquent que le taux de non-réponse aux comportements préventifs d’adaptation à la maladie et autres variables associées est significativement plus élevé dans l’échantillon web. Cependant, la magnitude de cette différence est nulle pour 19 items sur 30, et faible pour les 11 autres. De plus, aucune différence importante n’a été relevée lors de la comparaison des deux échantillons du point de vue de l’estimation de la prévalence desdits comportements et leurs déterminants. Enfin, les analyses d’invariance de l’indice d’adaptation ou de prévention à l’égard de la maladie de Lyme révèle que la structure de l’indice est la même pour les deux échantillons. On en conclut que malgré certaines différences observées entre les modes web et téléphone, les répondants des deux échantillons ont tendance à adopter des comportements similaires d’adaptation à la maladie de Lyme.
iii
Abstract
The web data collection mode has been increasing in popularity since its creation, primarily due to its cost and time effective benefits. However, its non-probabilistic tendencies often bring doubts concerning the representativity of its results in comparison to a typical mode such as the telephone. This master’s thesis compares the non-probability web and probability telephone modes, often suggested by polling firms in the province of Quebec. It principally analyzes the eventual differences between both samples on their adaptation to the Lyme disease. More specifically, the three main goals of this study are: (1) to compare the representativeness of both samples with the census data in terms of their socio-demographic characteristics, (2) to compare those two survey modes regarding their respondents’ preventive behaviour estimates against the Lyme disease, and (3) to test the measurement invariance of the nonprobability (Web panel) and probability (telephone) samples’ preventive behaviour. The data comes from a study on the adaptation of prevention behaviors against Lyme disease. The web (n=956) and telephone samples (n=1003) are made of individuals, 18 years old and above, from low and significant risk regions.Results firstly reveal that neither survey is representative of the Canadian census of 2016. Secondly, results show that the non-response rate for Lyme disease prevention adaptive behaviors and other associated variables is higher in the web survey. However, the magnitude of this significance is nil for 19 out of 30 the items, and small for the other 11. Moreover, no important dissimilarities were found in comparing both samples’ estimates in terms of the behaviours’ prevalence and their determinants. Finally, the measurement invariance analyses on the index of adaptation to the Lyme disease show a similar structure of the index for both samples. In conclusion, although the web and telephone samples are different in some respects, their respondents tend to have similar behaviors of adaptation to the disease.
iv
Table des matières
Résumé ... ii
Abstract ... iii
Liste des tableaux ... v
Liste des sigles ... vi
Remerciements ... vii
Introduction ... 1
Contexte théorique de l’étude ... 6
Le mode de collecte de données web ... 6
Le mode de collecte de données par téléphone ... 8
Recension des écrits ... 10
Chapitre 1: Telephone versus web panel national survey for monitoring adoption of preventive behaviors to climate change in population: a case study of Lyme disease in Quebec, Canada ... 15
1.1 Abstract: ... 16 1.2 Background ... 17 1.3 Methods ... 20 1.4 Results ... 24 1.5 Discussion ... 29 1.6 Conclusions ... 32 1.7 References ... 33 1.8 Tables ... 39 1.9 Additional files ... 48 Discussion... 55
2.1 Synthèse des résultats obtenus ... 55
2.2 Interprétation sur les résultats obtenus ... 57
2.3 Forces et limites de l’étude ... 59
2.4 Conclusion ... 59
v
Liste des tableaux
Table 1. Description of the variables measured ... 39
Table 2. Threscholds for the interpretation of Cohen's and Cramer's V ... 42
Table 3. Item Non-Responses for the Sociodemographic Variables in the Web and Telephone Surveys 42 Table 4. Comparison of the Telephone and Web Survey Data with the Census Data Regarding Sociodemographic Variables ... 43
Table 5. Comparison of weighted item responses from the Web and Telephone Surveys on Lyme Disease Exposure ... 44
Table 6. Comparison of the Weighted Mean of the Web Survey with the Telephone Survey on Lyme-Disease-Related Variables ... 45
Table 7. Measurement Invariance of the Index of Adaptation ... 47
Table 8. Quotas originally provided to the polling firm ... 48
Table 9. Samples’ actual numbers per region ... 49
Table 10. Socio-demographic characteristics: comparing weighted web/phone samples and census ... 50
Table 11. Comparison of the unweighted item non-responses of the Web and Telephone Surveys on Lyme Disease Exposure ... 52
vi
Liste des sigles
OQACC Observatoire québécois d’adaptation aux changements climatiques
HTML Hypertext markup language
RDD Random digit dialing
ANOVA Analysis of variance
PCE Procedure de concordance exacte LDPB Lyme disease prevention behavior
ESS Effective sample size
CFI Comparative fit index
TLI Tucker-Lewis index
RMSEA Root mean squared error of approximation
vii
Remerciements
Je veux tout d’abord témoigner toute ma reconnaissance à mon Dieu Le grand Yahweh pour qui et par qui j’ai eu la capacité de rentrer dans ce projet de maîtrise et de l’achever. Merci Seigneur de tout mon cœur. Tu as rendu l’impossible possible encore une fois dans ma vie.
Je veux ensuite dire un énorme merci à Pierre Valois mon directeur de recherche, de m’avoir donné l’opportunité de rentrer dans ce projet. Merci du fond du cœur de m’avoir confié une telle tâche. Tes encouragements et ta patience m’ont été d’un grand réconfort, et tes conseils judicieux m’ont été d’une aide précieuse.
Je tiens à exprimer ma reconnaissance envers M. Claude Bélisle qui m’a référé à mon directeur de recherche Pierre, pour ce projet de maîtrise. Cette belle aventure a commencé grâce à la foi que vous avez eu en moi et ça je ne l’oublierai jamais.
À toi ma chère et tendre maman Marie-Josée Ngambo, Je dis merci. Pour les petites tapes dans le dos dans mes temps de procrastination, pour tes encouragements et pour le fait d’avoir cru en moi jusqu’au bout. Je ne pense pas que j’y serais arrivée sans toi.
À mon cher papa Jean-Baptiste Ngambo, à mes sœurs adorées Gabrielle Ngambo et Kelly Garvin, à mon oncle Marcel Meli et ma tante Yvonne Meli, merci pour le soutien non négligeable que vous avez été tout au long du cheminement.
Enfin, à toute l’équipe de l’OQACC, merci pour votre aide et votre soutien. Merci pour la belle atmosphère de travail et votre bonne humeur. Que Dieu vous bénisse tous.
1
Introduction
Contexte
Dans les huit dernières décennies sont apparus les quatre principaux modes de collecte de données utilisés à l’heure actuelle. Des années 1940, marquant la recherche par sondage par l’expansion des modes face à face et par voie postale, aux années 1970, qui ont connu la création et l’essor du mode par téléphone et à l’apparition 20 ans plus tard du mode web, chaque mode a connu sa période de popularité (Couper & Miller, 2008). Cette évolution constante et cette transition en popularité d’un mode à l’autre de la recherche par sondage s’explique en grande partie par une tendance naturelle à suivre la société constamment en mouvement, notamment au niveau technologique.
Le mode téléphone en son temps se démarquait des autres, particulièrement à cause de sa rapidité d’exécution, sachant qu’il était équivalent au mode face à face en termes de qualité des données (Couper, 2011). Le mode web venu par la suite a en très peu de temps impacté la recherche par sondage d’une façon profonde (Couper & Miller, 2008). L’attention méthodologique qu’il a reçue jusqu’à présent a surpassé celle qu’ont eue les autres modes en leur temps.
Ainsi, le mode par téléphone qui était encore récemment le plus utilisé parmi les modes traditionnels se voit de plus en plus mis à l’écart en faveur du mode web (Tourangeau, Conrad & Couper, 2013). Ceci s’explique par le fait que le mode web se démarque beaucoup par la rapidité de son processus de collecte et d’envoie des résultats et par son coût significativement plus bas que celui des modes traditionnels face à face, voie postale et téléphone (Bethlehem, 2008; Braunsberger, Wybenga & Gates, 2007; Fan & Yan, 2010; PewResearchCenter, May 2015; Wright, 2005). Ce sont des avantages importants qui influencent souvent les enquêtes par sondage dans le choix du mode de collecte à favoriser. Problème posé
Dans le processus de réalisation d’une enquête par sondage, une des principales étapes de démarrage consiste en la sélection d’un mode de collecte de données approprié. C’est une étape fondamentale qui influencera la qualité des données. Concernant le mode web, est-il comparable aux modes traditionnels quant à la qualité des données qu’il livre?
2
Bien que populaire en recherche par sondage, le mode web connaissait encore il y a 10 ans une certaine résistance due à des incertitudes concernant la qualité de ses données. Cette méfiance s’explique par les différences qui ont été observées entre le mode web et les modes traditionnels (Chang & Krosnick, 2009; Solomon, 2000), différences qui peuvent se traduire en avantages et inconvénients du mode web.
Le mode web recèle d’attrayants avantages. En plus de son coût significativement plus bas et de sa rapidité opérationnelle, on peut relever l’absence du biais de l’interviewer qui est parfois dû à des malentendus entre ce dernier et le répondant, à de mauvaises habitudes chez l’interviewer, etc. (Chang & Krosnick, 2009; Tourangeau et al., 2013). Par ailleurs, avec le mode web, le répondant peut compléter un questionnaire à son rythme. Il a la possibilité de relire une question qu’il n’a pas comprise, prendre une pause ou sauter une question et y revenir plus tard. Ainsi, la pression de devoir répondre à une question dans un court laps de temps est moins élevée chez le répondant du mode web (Chang & Krosnick, 2009; PewResearchCenter, May 2015). De plus, il est bien connu que la désirabilité sociale qui affecte souvent les enquêtes ayant recours à un intervieweur est moindre chez les enquêtes utilisant un questionnaire auto-administré (Gingras & Belleau, 2015; Sarracino, Riillo & Mikucka, 2017; Stephenson & Crête, 2010; Tourangeau et al., 2013). Ceci s’explique par la volonté des répondants interviewés de présenter une image socialement acceptable d’eux-mêmes devant leur interlocuteur, contrairement aux personnes qui répondent à un questionnaire auto-administré qui ont un plus grand sentiment de confidentialité. Ces derniers ont alors tendance à être plus ouverts et honnêtes dans leurs réponses (Fricker, Galesic, Tourangeau, & Yan, 2005; Zhang, Kuchinke, Woud, Velten, & Margraf, 2017).
La méthode de sondage web présente aussi des inconvénients non négligeables, comme son taux de réponse généralement plus faible que celle par téléphone (Roster, Rogers, Albaum, & Klein, 2004; Tourangeau et al., 2013), ou encore la tendance des internautes à avoir un profil différent des autres membres de la population. On constate que les premiers sont généralement moins âgés, plus éduqués, avec un revenu plus élevé (Gauvin, 2012; Le Cefrio, 2015; Porter & Donthu, 2006). Ce constat soulève une certaine inquiétude quant au niveau de la représentativité des échantillons collectés en mode web par rapport à la population. De plus l’absence de l’intervieweur peut être problématique lorsque le répondant
3
à besoin de plus d’éclairage sur la question posée. L’influence positive que peut apporter un intervieweur par son intonation et son intérêt pour le sujet d’enquête est manquante. Enfin, un répondant ayant du mal à lire ou à écrire sera difficilement inclus au sondage web (Chang & Krosnick, 2009). Ceci est un inconvénient important à considérer lorsqu’on sait que 20% de la population de la province du Québec de 16 à 65 ans est estimé comme n’étant que de niveau 1 ou moins en 2012 (5 étant le plus haut niveau) en compréhension de texte et numératie (Desrosiers, Nanhou, & Ducharme, 2015).
On a relevé que les biais dus à la qualité des données (tels que des taux de réponse bas et les biais de couverture) des modes de collecte traditionnels sont une source d’inquiétude grandissante, plus spécifiquement celui du téléphone (Breton, Cutler, Lachance, & Mierke-Zatwarnicki, 2017; Sala & Lillini, 2015; Sarracino et al., 2017). Ceci peut s’expliquer notamment par l’arrivée de nouveaux moyens tels que des envois massifs de courrier et les activités de télémarketing souvent accablantes, ainsi que la possibilité de filtrage des appels à l’aide d’écrans d’affichage. Ces nouveaux éléments réduisent la capacité à persuader les répondants de participer aux enquêtes (Braunsberger et al., 2007; Grandjean, Nelson, & Taylor, 2009). D’un autre côté, on observe une expansion sûre et constante d’internet année après année, qui très possiblement mènera à l’amélioration de la représentativité des échantillons web (Institut de la Statistique du Québec, 2013; Poushter, 2016; Sterrett, Malato, Benz, Tompson, & English, 2017).
Bien qu’il existe dans la littérature un certain nombre d’études de comparaison entre le mode web et les modes traditionnels, l’évolution continuelle de la société notamment au plan technologique influence inévitablement la qualité des données. L’actualité des changements observés est ce qui rend pertinent le problème posé ici.
Buts et objectifs
L’étude rapportée ici tente de fournir une réponse à la question de savoir s’il existe une différence entre le mode web et le mode par téléphone du point de vue des résultats observés et de la représentativité de l’échantillon. Nous avons choisi ces deux modes à cause de leur popularité au sein des firmes de sondage québécoises. Il s’ensuit donc que l’étude a été réalisée dans la province du Québec. Les données ont été collectées lors d’une étude sur
4
les comportements d’adaptation à la maladie de Lyme (Valois et al., s. d.), réalisée par l’OQACC (Observatoire Québécois d’adaptation aux changements climatiques).
Afin de répondre au problème posé, nous examinons en premier la représentativité des deux échantillons web et téléphone par rapport à la population du Québec du point de vue de certaines caractéristiques sociodémographiques, soit l’âge, le sexe, le plus haut niveau d’éducation atteint, la taille du ménage, la présence ou non d’enfants dans le ménage et le revenu annuel du ménage. L’évaluation de la représentativité de nos échantillons se base sur les résultats du recensement de 2016. Ensuite nous comparons les échantillons du point de vue des prévalences estimées des comportements d’adaptation à la maladie de Lyme et d’autres variables théoriquement associées. Enfin, nous testons l’invariance métrique d’un indice d’adaptation à la maladie entre le sondage web est le sondage par téléphone. Le but du test de l’invariance est de déterminer si les résultats de la mesure de l’indice varient selon le mode de collecte de données. Il est souhaité que les résultats soutiennent l’invariance de l’indice. Dans le cas contraire, les décisions des services de santé sur les mesures de protection à promouvoir ou renforcer pour se protéger des piqûres de tiques varieraient selon le mode de collecte de données utilisé. Les analyses répondant à ces objectifs sont effectuées sur les données non-pondérées, et reprises sur les données pondérées afin de pallier un éventuel problème de non-représentativité.
Ampleur de l’étude pour le domaine de recherche et le champ de mesure et évaluation Apport au domaine de recherche
Bien que des études similaires aient déjà été menées sur le sujet (Chang & Krosnick, 2009; Fricker et al., 2005; Nantel & Lafrance, 2006; PewResearchCenter, 2015; Roster et al., 2004; Xing & Handy, 2014), il n’existe aucun consensus permettant de favoriser un mode par rapport à l’autre. Par ailleurs, avec la croissance constante du taux d’utilisation d’internet et la diminution constante du nombre de familles équipée d’un téléphone fixe (Link, Battaglia, Frankel, Osborn & Mokdad, 2007; Mohorko, De Leeuw & Hox, 2013; Nantel & Lafrance, 2006; Vicente, Reis & Santos, 2009), il est important de maintenir un suivi de l’évolution de la qualité des données provenant du mode web. Des études ont démontré une diminution dans le temps du nombre de familles équippées d’une ligne fixe en faveur de l’usage exclusif de cellulaires. Ceci pourrait donner lieu à des échantillons non probabilistes
5
et engendrer des biais compromettant ainsi la validité des résultats. C’est en prennant en compte ces changements continuels, tant au niveau du mode web que celui par téléphone, que l’on peut juger de l’importance d’une étude supplémentaire sur ce sujet pour le domaine de recherche.
Apport au champ de mesure et évaluation
En mesure et évaluation, la collecte des données est une des étapes nécessaires à la mesure et l’évaluation d’un outil donné. Le mode de collecte utilisé aura une influence sur la qualité des données. La mesure d’un construit peut être tout à fait fiable en temps normal, mais donner des résultats différents selon le contexte dans lequel il a été administré. Par exemple, le biais de désirabilité sociale peut affecter les résultats, selon que le questionnaire a été auto-administré ou que le sujet a été assisté par un interviewer (Gingras & Belleau, 2015; Sarracino et al., 2017; Stephenson & Crête, 2010; Tourangeau et al., 2013). Dans un tel scénario, le test en lui-même est fidèle, mais les résultats divergeront du fait du mode de collecte employé.
Une étude de comparaison des modes web et téléphone permet de déterminer si en plus de l’avantage que le sondage web offre en termes de temps et de coût, il fournit également des données favorisant des résultats généralisables à la population étudiée. Structure du mémoire
Le mémoire est structuré de la manière suivante : Une première partie porte sur le contexte théorique de l’étude. Elle est composée d’une présentation du mode de collecte web, puis du mode de collecte par téléphone et enfin d’une recension des écrits sur des résultats d’études similaires à celle-ci et sur différents outils de comparaison des modes de collecte. La deuxième partie contient l’article dont cette étude a fait l’objet. Finalement une troisième partie contient la discussion dans laquelle est fait un bilan des résultats observés selon les objectifs préalablement fixés, ainsi qu’un état des forces et limites de l’étude, de son implication, et de suggestions de recherches futures.
6
Contexte théorique de l’étude
Le mode de collecte de données web
Le mode web est une méthode de collecte des données par internet, selon laquelle les questionnaires sont remplis sur des pages en langage hypertexte (HTML) du « World Wide Web ». Les sujets ciblés sont généralement contactés et invités à participer au sondage soit dans un courriel incluant le lien vers la page web du questionnaire, soit par une lettre à la poste contenant l’adresse du site contenant le questionnaire, ou encore lors d’une visite de ces derniers sur un site internet.
Le moyen de contact de sujets potentiels dépend du type de sondage web qu’on veut utiliser. Les types de sondages web peuvent être regroupés en deux catégories majeures (Couper, 2000; Tourangeau et al., 2013) : les sondages web probabilistes et les sondages web non probabilistes. Le premier groupe se distingue du deuxième en ce qu’il permet que tous les membres de la population aient la même chance d’être recrutés dans l’échantillon. Selon Couper (2000), la catégorie des sondages web probabilistes inclut ceux dont :
- l’échantillon est constitué de visiteurs d’un site internet spécifique, aléatoirement recrutés à l’aide d’une fenêtre d’invitation pop-up;
- les participants appartiennent à une liste d’individus représentant une population bien définie recrutés par courriel ou par la poste (p. ex. les étudiants d’une université); - l’option de compléter le questionnaire par le web est offerte aux membres de
l’échantillon lors d’un premier contact par un autre moyen (p. ex. par téléphone, par la poste, etc.);
- l’échantillon fait partie d’un panel constitué exclusivement de membres de la population des internautes contactés initialement par une méthode de sondage probabiliste telle que la composition aléatoire ou « random digit dialing » (RDD) en anglais. Il est probabiliste dans la mesure où la population visée est uniquement celle des usagers d’internet;
- l’échantillon fait partie d’un panel probabiliste représentatif de la population complète (internautes et non-internautes). En premier lieu, le panel est constitué à
7
l’aide d’une méthode probabiliste sans internet (p. ex. complétement aléatoire). L’échantillon qui en ressort est alors constitué de personnes ayant accès ou pas au web. Lors du sondage, l’équipement et les outils nécessaires à une connexion internet sont fournis aux répondants potentiels en échange de leur participation.
Toujours selon Couper (2000), les sondages non-probabilistes incluent ceux où les répondants :
- sont un groupe de volontaires, généralement visiteurs d’un site internet, auxquels on demande de participer au sondage (p. ex. sondage ayant valeur de divertissement). Les résultats de ces sondages sont sans valeur scientifique réelle;
- sont recrutés par invitations ouvertes sur des portails ou sites web fréquemment visités. Ils sont similaires aux enquêtes pour divertissement, mais dans ce contexte, les résultats se veulent scientifiquement valides;
- Prennent part à plusieurs sondages en tant que membres recrutés généralement sur des sites internet populaires.
Réaliser un sondage web probabiliste représente un défi majeur. En effet, il est très souvent difficile, voire même impossible d’avoir accès à une proportion suffisamment élevée de la population de référence. Sachant que le moyen de contact et de recrutement généralement utilisé lors des sondages web est celui par courriel, il faudrait idéalement avoir accès aux adresses électroniques d’une grande proportion de la population à étudier, ce qui est souvent impossible. C’est d’ailleurs pour cela qu’il n’existe pas encore de méthode standard d’échantillonnage web (Tourangeau et al., 2013),d’où l’intervention des sondages web non probabiliste comme solution alternative.
Les sondages web non probabilistes représentent toujours un certain risque dans la mesure où le manque de représentativité de l’échantillon peut biaiser les estimations que l’on veut faire sur la population de référence. Cependant, si certaines conditions sont remplies, les échantillons non-probabilistes peuvent apporter des résultats aussi probants que les échantillons probabilistes. Selon Yeager et al., (2011) ces conditions sont rencontrées, par exemples :
8
- si le facteur qui détermine la présence ou l’absence d’un membre dans l’échantillon n’est pas corrélé avec la variable d’intérêt. Par exemple, lors de l’étude sur l’adaptation de la population à la maladie de Lyme, sélectionner les centres de plein-air comme bassin de collecte des échantillons poserait un biais. En effet, les individus fréquentant ces centres sont naturellement plus sensibilisés à la maladie que d’autres. Dans ce cas particulier, le facteur déterminant la présence des sujets dans l’échantillon (centre de plein-air) est corrélé à la variable d’intérêt (variable d’adaptation à la maladie);
- la méthode des quotas est utilisée. Cette méthode peut être utilisée avant ou après la collecte des données. On regroupe la population en classes dont les effectifs réels sont connus. Ces derniers sont multipliés par le taux de sondage (portion de la population faisant partie de l’échantillon), ce qui nous donne les quotas à respecter (Desabie, 1963). Il s’agit ici d’améliorer la représentativité de l’échantillon en faisant des groupements d’individus selon une ou des variables de contrôle (p. ex. âge, sexe, revenu, région). Une variable de contrôle doit comporter les qualités suivantes : avoir une distribution statistique connue dans la population, être facile à observer sur le terrain et ne pas comporter de sérieux risques d’erreur, être étroitement corrélée à la variable d’intérêt.
Le mode de collecte de données par téléphone
La collecte des données par téléphone demeure l’un des modes les plus prisés, notamment à cause de la simplicité relative avec laquelle il permet l’obtention d’échantillons probabilistes de la population générale (Vehovar, Slavec, Berzelac & Gideon, 2012). La collecte de données par téléphone peut se faire d’une des deux manières suivantes : Par composition aléatoire (RDD en anglais) ou en se basant sur un annuaire téléphonique.
Collecte basée sur un annuaire téléphonique
Cette méthode est la plus adéquate lorsqu’une liste téléphonique précise de la population à l’étude est disponible. Les numéros seront alors sélectionnés aléatoirement parmi ceux de la liste (Lavrakas, 1987).
9
Créée par Couper (1964), cette méthode augmente les chances d’obtenir un sondage téléphonique probabiliste en réduisant le biais potentiellement créé lorsque des numéros de téléphones sont non répertoriés dans un annuaire téléphonique. En effet, la méthode RDD ne se réfère pas à une liste préalablement faite. Elle consiste à générer aléatoirement tous les numéros de téléphones qui pourraient possiblement se retrouver dans le cadre d’échantillonnage voulu. Durant ce processus, on dresse d’abord la liste exhaustive de tous les indicatifs régionaux de la zone géographique de la population qu’on veut étudier. On génère ensuite tous les numéros qui peuvent en ressortir. L’information sur la banque des lignes vacantes (celles qui ne sont pas octroyées parmi les numéros générés en RDD) peut être pourvue par la compagnie téléphonique afin de supprimer les numéros invalides. Le processus permettant d’aboutir à un sondage RDD peut s’avérer lourd en termes de temps et de coûts. Avant de s’y investir, il faut considérer l’étendue des zones géographiques à couvrir, la disponibilité de l’information sur les banques des lignes vacantes et le pays dans lequel est effectué le sondage. En effet, la complexité du système par lequel les lignes téléphoniques sont créées est parfois trop élevée dans certains pays pour envisager le recours au RDD (Vehovar et al., 2012).
Très souvent, lorsqu’on parle de sondage téléphonique en recherche, on fait référence aux lignes téléphoniques de maison. Cependant depuis les années 2000, la téléphonie mobile s’est suffisamment étendue pour être considéré comme un mode de collecte adéquat (Vehovar et al., 2012). Inclure ce nouveau mode dans un plan de sondage n’est toutefois pas évident à cause non seulement des coûts qu’il engendre (plus onéreux que le téléphone fixe), mais aussi des biais qu’il peut occasionner notamment à cause de la non-réponse, du manque de représentativité, de la difficulté à distinguer les lignes fixes et mobiles, des indicatifs régionaux ne prouvant en rien la localisation géographique des sujets jusqu’au type d’appareil téléphonique utilisé (Brick, Edwards & Lee, 2007; Lavrakas et al., 2007). En considérant tous ces éléments et en pourvoyant à une approche méthodologique adaptée, il est toujours possible d’éviter ou de contourner les biais.
C’est ce que font des compagnies telles que BIP-sondage (la compagnie de sondage engagée pour ce projet) qui possède trois banques de cellulaires qui lui ont été attribuées par un fournisseur externe. La première est une liste de RDD pour laquelle on ne peut dire au
10
départ si le cellulaire est actif ou pas. La deuxième est une liste dont les RDD ont été filtrés et dépouillés des numéros inexistants. La troisième est une liste contenant des ménages sans ligne téléphonique fixe.
Recension des écrits
Comparaisons des modes de sondage dans la littérature
Des recherches similaires à la nôtre ont déjà été faites sur le sujet. Différentes méthodes ont été employées durant le processus de comparaison, et des conclusions variables ont été établies.
Dans une étude réalisée par Zhang et al. (2017), 13 questionnaires psychologiques mesuraient les aspects positifs (p. ex. résilience, santé mentale positive, bonheur subjectif, autosuffisance) et négatifs (p. ex. pessimisme, état d’anxiété, de stress et de dépression, etc.) de la santé mentale. Quatre méthodes de collecte de données ont été comparées du point de vue de ces 13 aspects : (1) le mode par questionnaires en ligne, c’est-à-dire sur le web, (2) le mode par questionnaires hors-ligne où les sujets répondaient à partir de leurs ordinateurs personnels ou de leurs écrans de télévision connectés à un logiciel de la compagnie de sondage par l’intermédiaire d’un dispositif appelé « set-top-box », (3) le mode par téléphone et (4) le mode face à face. Les différences les plus grandes ont été observées entre les modes en ligne/hors ligne et celui par téléphone. De plus, l’analyse de l’invariance de la mesure indique l’absence d’invariance scalaire complète (des explications sur les différents tests d’invariance sont données dans le paragraphe intitulé « différents outils de comparaison ») sur l’ensemble des 4 modes pour 4 des 13 facteurs analysés. Ces 4 facteurs sont le sens de la cohérence, la résilience, le bonheur subjectif et la tradition. Pour ce qui est du sens de la cohérence, il y avait invariance scalaire complète pour les modes face à face, en ligne et par téléphone. La résilience a eu de l’invariance pleine pour les échantillons en ligne, hors-ligne et par téléphone. Concernant le bonheur subjectif on n’a trouvé de l’invariance scalaire complète qu’entre les modes hors-ligne et téléphone. Finalement, le facteur tradition a montré de l’invariance scalaire complète entre le mode face à face et ligne, en ligne et hors-ligne et entre le mode téléphone et hors-hors-ligne.
11
Chang et Krosnick (2009) ont comparé trois échantillons où les participants devaient répondre à un sondage pour la campagne électorale présidentielle de l’an 2000. Les échantillons ont été obtenus par trois modes de collecte différents : le mode téléphonique RDD, le mode internet probabiliste et le mode internet non probabiliste. L’échantillon non probabiliste était constitué de volontaires qui ont accepté de répondre à l’enquête en retour d’un montant d’argent. Ils ont découvert entre autres que lors des auto-évaluations (constituées de prédictions faites par les répondants sur leurs choix de vote, d’une évaluation des principaux candidats des élections, et d’un ensemble vaste d’attitudes et de croyances des répondants qui pourraient influencer le choix de vote), les répondants internet donnaient une description plus précise et détaillée dans leurs réponses que ceux par téléphone. Ceci s’est manifesté notamment par : une plus grande validité prédictive et convergente mesurée par la corrélation entre les réponses (à des items déterminants du choix de vote) données lors d’un sondage pré-électoral et le choix de vote réel transmis dans le sondage post-électoral. Ils ont également observé, une plus grande fidélité (selon un modèle d’équations structurelles permettant d’estimer la stabilité d’un construit). Finalement, la désirabilité sociale et le biais de suffisance - c’est lorsqu’à une question demandant un effort cognitif substantiel, le répondant préfère donner une réponse qui satisfait ou qui se base sur le statut quo (Krosnick, 1991) - étaient plus faibles chez les échantillons fournis par internet que celui par téléphone.
Braunsberger et al. (2007) ont comparé la consistance dans le temps du panel web et de la méthode téléphonique au cours d’une enquête qui incluait l’évaluation de la couverture de l’assurance maladie en se basant sur 10 critères (p. ex. digne de confiance, bien informée, reconnu par les médecins). Le contenu du questionnaire était le même pour les deux modes, et pour chaque mode de sondage, ils ont effectué une première collecte des données à un temps 1, et une deuxième au temps 2, environ 2 mois plus tard. Ils ont ensuite comparé les deux modes de collecte de données du point de vue de leur capacité à demeurer fidèles dans le temps. On voulait donc savoir si le passage du temps affectait la qualité d’un mode de collecte plus que l’autre. Pour ce faire, on a d’abord effectué un test d’ANOVA afin de comparer sur chacun des 10 critères l’échantillon web au temps 1 à celui du temps 2, puis l’échantillon téléphone du temps 1 à celui du temps 2. Les résultats ont montré une congruence dans le temps des échantillons par internet, contrairement aux échantillons par téléphone. En effet, des différences significatives ont été trouvées sur les 10 critères dans le
12
cas du mode par téléphone, tandis que concernant le mode web, un seul critère a abouti à des résultats significativement différents dans le temps. Sur la base de ces résultats, ils ont conclu que le mode web peut produire des résultats plus fiables que celui par téléphone. Une enquête de (Rankin et al., 2008) est également arrivée à des conclusions similaires.
Bien que des différences significatives aient été observées entre le web et le téléphone dans plusieurs études, on a relevé d’autres études dont les conclusions indiquaient que les deux modes peuvent obtenir des résultats similaires. C’est le cas par exemple d’une étude de Roster et al. (2004) qui ont mesuré la réputation d’une entreprise spécifique dans une région métropolitaine majeure lors d’un sondage. Le questionnaire a été soumis à deux groupes : l’un consistait en un échantillon probabiliste collecté par mode téléphonique et le second en un échantillon tiré d’un panel web. Ils n’ont trouvé aucune différence entre les deux groupes de leur enquête du point de vue de la prédiction de leurs comportements. Les profils sociodémographiques ce sont cependant révélées différents d’un mode de sondage à l’autre.
De façon générale, plusieurs chercheurs sont d’accord sur le fait que le web et le téléphone présentent des dissimilarités certaines, alors que d’autres sont plus enclin à croire que les deux modes ne sont pas si différents et peuvent même être complémentaires l’un à l’autre (Breton et al., 2017; Couper, 2011). Cependant, la réponse à la question : « Lequel des modes de collecte de données est le plus satisfaisant en termes de représentativité? », reste difficile à obtenir. Afin de répondre à cette question, il est d’abord primordial de déterminer les critères et outils qui permettront de juger de la qualité des données.
Critères et outils de comparaison
Selon Bowling (2005), chaque mode nécessite des capacités cognitives différentes de la part des répondants, et varie selon le niveau d’intimité et d’anonymat dont il fait bénéficier ces derniers, ce qui affecte le processus de réponse aux questions, et par là même, la qualité des données. Plusieurs méthodes de comparaison permettant de vérifier si les échantillons sont affectés par l’effet des modes ou de biais et ainsi déterminer le mode de collecte le plus approprié ont été identifiées la littérature.
La comparaison des caractéristiques sociodémographiques des échantillons est un bon début. En d’autres termes, on pourrait comparer l’âge, le sexe, la situation matrimoniale,
13
le salaire, le niveau d’éducation, l’origine etc. (Beck, Yan, et Wang, 2009; Chang et Krosnick, 2009; Dillman et al., 2009), selon les besoins de l’étude et des données disponibles. On effectue aussi parfois une comparaison de chaque échantillon avec les données du recensement dans le but d’évaluer la représentativité des échantillons à la population générale (Beck, Yan, et Wang, 2009; Chang et Krosnick, 2009; Dillman et al., 2009).
Ensuite, on peut choisir certaines variables du questionnaire de l’étude et effectuer des comparaisons de moyennes ou de proportions. Des tests de chi-deux ou de Fisher pourraient être effectués sur les variables catégorielles (Read & Cressie, 2012), des analyses de la variance (ANOVA) (Xing et Handy, 2014) ou encore des tests de Student, un cas particulier de l’ANOVA (Fricker et al., 2005; Roster et al., 2004). Dans le cas d’un manque de représentativité de la part des échantillons, une pondération permet de les ajuster. Les tests nommés plus haut peuvent alors être reproduits sur les données pondérées. La pondération peut être faite de différentes façons. Deux exemples proposés de pondération sont : la pondération basée sur les données de la population externe (Fricker et al., 2005) et la procédure de concordance exacte (PCE) où le groupe traitement et le groupe contrôle sont équilibrés. Autrement dit, les groupes traitement et contrôle ont une distribution similaire à leurs covariances (Sarracino et al., 2017).
Un autre moyen utilisé pour comparer les modes de sondage est l’analyse de l’invariance de la mesure. Elle consiste à vérifier si l’association entre le facteur latent et le score qui lui est attribué ne dépend pas de l’appartenance à un groupe ou à une mesure dans le temps. L’absence d’invariance est un signe qu’au moins un des modes de sondage impliqués donne des résultats biaisés au regard du facteur en question. L’invariance de la mesure repose généralement sur trois principaux tests. D’abord, l’invariance configurale qui teste l’intégrité de la structure factorielle (Chen, Dai & Gao, 2019; Zhang et al., 2017). Ensuite, l’invariance métrique qui vérifie que les échantillons répondent aux items du facteur de la même manière. En d’autres mots, elle vérifie si la corrélation entre les items et leur construit latent est similaire d’un groupe à l’autre (Sass & Schmitt, 2013; Steenkamp & Baumgartner, 1998). Enfin, l’invariance scalaire qui vérifie que les individus ayant les mêmes scores aux items ont également le même score au niveau du facteur indépendamment du groupe auquel ils appartiennent (Zhang et al., 2017). Ces tests se font dans l’ordre et
14
l’aboutissement du dernier garantit que les deux autres ont obtenu un résultat positif. L’établissement de l’invariance métrique et scalaire permettent de conclure qu’il y a invariance de la mesure (Sass & Schmitt, 2013). À chaque test, l’invariance peut être considérée nulle (le modèle testé pour invariance est inadéquat avec ou sans modification), partielle (le modèle testé est adéquat seulement après modifications), complète (le modèle testé est adéquat sans modification préalable) (Putnick & Bornstein, 2016). Il existe d’autres tests complémentaires d’invariance tels que : l’invariance stricte qui permet de vérifier si les effets résiduels (unicité) des items sont les mêmes pour tous les groupes comparés; l’invariance de la moyenne latente et l’invariance de la variance latente qui vérifient respectivement l’équivalence de la moyenne et de la variance du score estimé du facteur d’un échantillon à l’autre (Steenkamp & Baumgartner, 1998).
Finalement, selon Dillman et al. (2009), le taux de réponse globale et les taux de réponse par question présentent également un certain attrait pour la comparaison d’échantillons. D’autres indicateurs tels que le taux de réponse sur les variables sociodémographiques comparées aux données du recensement, les coefficients des estimations de variation, les tests de différence statistique entre le taux de répondants et de non-répondants par région peuvent être utilisés dans le processus de comparaison des modes de collecte de données (Bélanger, Gosselin, Valois, Abdous, et Morin 2013). Les taux de réponse doivent cependant être utilisés avec précaution. En effet, seuls, ils ne suffisent pas à émettre une conclusion en ce qui concerne la qualité des estimations faites sur les données d’un échantillon (Bethlehem et al., 2008).
Les outils mentionnés ci-dessus sont les plus utilisés dans la littérature. Leur pertinence et leur fiabilité justifient leur utilisation courante dans des études de comparaison des modes de collecte. Notre étude n’en a pas fait exception. Chacun de ces outils de comparaison y ont été insérés.
15
Chapitre 1: Telephone versus web panel national survey for
monitoring adoption of preventive behaviors to climate change
in population: a case study of Lyme disease in Quebec, Canada
Authors: Grâce Ngambo Domche, B.Sc.1, Pierre Valois, Ph.D.1*, Magalie Canuel, M.Sc.2, Denis Talbot, Ph.D.3,4, Maxime Tessier, B.Sc.1, Cécile Aenishaenslin, Ph.D.5, Catherine Bouchard, Ph.D.5,6, Sandie Briand, Ph.D.7
1 Faculty of Education, Université Laval, 2320, rue des Bibliothèques, Quebec City, QC, Canada, G1V 0A6
2 National Institute of Public Health of Québec, 945 av Wolfe, Quebec City, QC, Canada, G1V 5B3 3 Faculty of Medicine, Université Laval, 1050 Avenue de la Médecine, Quebec City, QC, Canada,
G1V 0A6
4 Populational health and optimal practices axis, CHU de Québec – Université Laval Research center, Quebec City, QC, Canada, G1S 4L8
5 Groupe de recherche en épidémiologie des zoonoses et santé publique (GREZOSP), Faculté de médecine vétérinaire (FMV), Université de Montréal, Saint-Hyacinthe, QC, Canada
6 Public Health Risk Sciences Division, National Microbiology Laboratory, Public Health Agency of Canada, Saint-Hyacinthe, QC, Canada
7 National Institute of Public Health of Québec, Montréal, QC, Canada
16
1.1 Abstract:
Background
To monitor the adoption of climate change adaptive behaviors in the population, public health authorities have to conduct national surveys, which can help them target vulnerable subpopulations. To ensure reliable estimates of the adoption of these preventive behaviors, many data collection methods are offered by polling firms. The aim of this study was to compare a telephone survey with a web survey on Lyme disease with regard to their representativeness.
Methods
The data comes from a cross-sectional study conducted in the Province of Québec (Canada). In total, 1,003 people completed the questionnaire by telephone and 956 filled in a web questionnaire. We compared the data obtained from both survey modes with the census data in regard to various demographic characteristics. We then compared the data from both samples in terms of self-reported Lyme disease preventive behaviors and other theoretically associated constructs. We also assessed the measurement invariance (equivalence) of the index of Lyme disease preventive behaviors across the two samples.
Results
Findings showed that neither the telephone nor the web panel modes of data collection can be considered more representative of the target population. The results showed that the proportion of item non-responses was significantly higher with the web questionnaire (5.6%) than with the telephone survey (1.3%), and that the magnitude of the differences between the two survey modes was nil for 19 out of the 30 items related to Lyme disease, and small for 11 of them. Results from invariance analyses confirmed the measurement invariance of an index of adaptation to Lyme disease, as well as the mean invariance across both samples. Conclusions
Our results suggest that both samples provided similar estimates of the level of adaptation to Lyme disease preventive behaviors. In sum, the results of our study showed that neither survey mode was superior to the other. Thus, in studies where adaptation to climate change is monitored over time, using a web survey instead of a telephone survey could be more cost-effective, and researchers should consider doing so in future surveys on adaptation to climate. However, we recommend conducting a pretest study before deciding whether to use both survey modes or only one of them.
17
1.2 Background
With the unavoidable warming of the climate system, more frequent climatic hazards, such as heat waves and floods, will result in greater health impacts on the population [1]. For instance, higher heat exposure due to average temperature warming, as well as heat waves and urban heat islands, affects the health of organizations, systems, and populations [2–4]. Heat also affects the health of populations by causing, for instance, increased air pollution, the spread of disease vectors, food insecurity, and undernutrition [5]. The impacts of the changing climate on human health include not only these dangerous climatic events, but also a probable increase in the occurrence of zoonotic diseases. One example is Lyme disease, a tick-borne zoonosis which occurs mostly in temperate regions. Its vector, Ixodes scapularis tick, is slowly spreading further north due to rising global temperatures and are now found in areas where they never were before and the disease affects an increasing number of Canadians since the last decade [6–13]. The Public Health Agency of Canada is reporting an increase of over 588% in reported cases in Canada since 2009 [14]. In Québec, where Lyme disease is a notifiable disease, there were 338 cases of Lyme disease contracted in 2019, compared to 66 in 2014 [15].
Because of these deleterious effects of global warming and climate change on human health, various national surveys are being conducted to determine whether the preventive behaviors promoted by public health authorities are adopted by the population. These surveys are used to monitor adaptation to climate change over time. They enable public health agencies to better identify protective measures that should be reinforced in health promotion campaigns and to target groups that are not adapting.
The results of these surveys are based on sampling procedures intended to generate representative samples of the populations concerned with specific effects of climate change. Over the past four decades, telephone surveys were one of the data collection methods favored by researchers in psychology, sociology, and health-related fields to monitor behaviors, health status, and other determinants [16,17]. However, in recent years, telephone surveys have gradually been supplanted by methods incorporating computer technologies [17]; for a more detailed discussion of these developments, see [18]. The use of web surveys has increased and expanded quickly around the world [19–21] in large part because of the
18
extremely low marginal cost for each additional case in a web survey compared with a telephone survey [17]. At the Québec Observatory of Adaptation to Climate Change, we carried out several surveys in recent years. Our experiences with the survey firms that we contacted to submit proposals to administer our questionnaires indicate that low cost is definitely one of the greatest benefits of web surveys over telephone surveys.
Recent studies showed that web panel surveys would have additional advantages over telephone surveys besides the lower cost, for instance: the absence of interviewer bias [22], the fact that a self-administered questionnaire makes the respondents more open and honest [23–28], and the possibility of completing the questionnaire at one’s own pace [22,29]. However, web panel surveys present some non-negligible disadvantages compared with telephone surveys: they do not include the portion of the population without an internet connection [30], one of the main reasons why most web samples are generally considered non-probabilistic [31]; response rates are usually lower than with telephone surveys [17,32]; and the respondents tend to be younger, to be more educated, and to have higher incomes than non-internet users [33–35]. Finally, other disadvantages include the absence of interviewers to explain the meaning of a question to the respondents, and the impossibility of recruiting individuals with problems of illiteracy or blindness [22].
Overall, some researchers agree that the web and telephone modes present dissimilarities that cannot be easily dismissed, whereas others are more inclined to believe that both modes are relatively similar and can even complement each other [36,37]. The legitimacy of these two points of view is undoubtedly subject to the context of the surveys conducted. Furthermore, the differences or similarities observed between the data collected via these two modes may depend on the topic of the study. For example, in the case of condom use, one can expect a greater risk of the effect of social desirability in data collected by phone than via the web [38,39]. Inversely, a telephone interview could be expected to produce more reliable results in a study concerning living wills. Indeed, in such a case, the interviewer could help reduce measurement errors by providing respondents with explanations of the specific meaning of questions that refer to a more abstract concept like living will.
19
A sample generated in web mode can be considered either probabilistic or non-probabilistic. In a non-probabilistic web panel mode of data collection, the sample consists of volunteers recruited by responding favorably to prior invitations. Those invitations are usually made through popular websites, internet portals, or other means [40,41]. In a probabilistic web panel mode, participants are selected at random with a procedure ensuring that all the people in the population have equal or known probabilities of being chosen, as in the case of random digit dialing (RDD). Phone numbers are generated at random and people reached are subsequently invited to join the web panel for a survey [22].
Our research team (Québec Observatory for the Adaptation to Climate Change) conducts surveillance of the adoption of climate change adaptation behaviors in the province of Québec, Canada (1,667,441 square kilometers, or 643,802 square miles; population of 8.3 million). Several surveys are conducted annually and must be replicated over time to monitor the evolution of adaptation. It is important to determine from the outset which data collection mode is best for future surveys. This study is part of a more general project aiming to identify the factors that are associated with the adoption of Lyme disease prevention behaviors (LDPB). It pertains more specifically to the issue of modes of information collection and seeks to detect potential differences between two samples of respondents contacted either via the web (non-probabilistic sample) or by phone (probabilistic sample). The differences sought concern not only the results observed but also the representativeness of the two samples in terms of certain characteristics of the target populations. Both survey modes are often proposed by polling firms in the Province of Québec (Canada), where the household rate of internet connection was estimated at 90% in 2016 [42].
The three specific objectives of this study are to: (1) compare the representativeness of the two samples with census data in terms of sociodemographic characteristics (gender, age, highest level of education, annual income, presence of children in the household, household size), (2) compare these survey modes with regard to the estimation of the population’s rates of reported Lyme disease adaptive behaviors and other theoretically associated variables, and (3) test the measurement invariance or equivalence of the latent construct of Lyme disease adaptive behavior across the non-probabilistic web panel and telephone samples. For instance, a non-invariance of the uniquenesses of the behavioral items
20
composing the latent construct of Lyme disease adaptation would indicate that this construct is assessed with different levels of measurement error and precision in the two survey modes. Consequently, health agencies’ decisions to protect individuals against Lyme disease would depend on the survey mode chosen, which is not desirable. It is also possible to use weighting methods to correct for the non-representativeness of the samples as compared to census data. Thus, comparisons of the data obtained from the telephone and web surveys will also be performed on the weighted data for all three objectives to verify the effect of the statistical correction.
1.3 Methods
Target population
The data comes from a cross-sectional study conducted in the Province of Québec (Canada). The target population studied consisted of people living in a municipality where the risk of contracting Lyme disease was low (i.e. where at least one tick was collected through active surveillance activities) or significant (i.e. at least three human cases of Lyme disease acquired locally in a municipality of fewer than 100,000 inhabitants or at least 23 tick submissions from human passive surveillance acquired in the municipality in the past five years in a municipality of fewer than 100,000 inhabitants, or three life-cycle stages—larva, nymph, and adult—of the tick collected in the municipality in one year, through active surveillance in which at least one nymph tested positive for Borrelia burgdorferi). Most of the municipalities where the risk was significant were located in the southern part of the province [43]. The respondents had to be at least 18 years old and speak English or French to participate in the study.
We used the 2016 Canadian census data to compare the representativeness of the web and telephone samples in terms of sociodemographic characteristics (gender, age, highest level of education, annual income, presence of at least one child in the household, household size). Census statistics specific to our target population were obtained from Statistics Canada (at the cost of CAD 1,400), for people 18 years of age and older living in one of the 111 municipalities that were included in our study.
21
The census data came from two questionnaires. One was a short-form questionnaire addressed to 100% of the Canadian population, which provided information on age, gender, household size, and family structure. The response rate was very high, at 98.4%, which represents 15,067,444 private dwellings [44]. The census data for our target population covered 1,031,220 private dwellings, or 1,924,155 people aged 18 years or older.
The other questionnaire was a long-form questionnaire administered to 25% of Canadian private dwellings (hereafter named “25% census sample”), which included information on the highest education level and the total household income. The response rate was also very high, at 97.8%, the best ever recorded [45]. Given this high response rate, we decided to keep this data subset to determine the level of representativeness of the web and telephone samples in regard to the highest education level and the annual income. This data subset was weighted according to the sampling probability of being selected; see Statistique Canada [46] for more details regarding the weighting method used.
Samples and data collection
For the web survey, a polling firm (BIP Research) surveyed 956 people (women, 55.4%) through a web questionnaire. The data were collected from May 18 to August 28, 2018. The web sample was selected from a web panel that included 40,000 Quebeckers at least 18 years old, all randomly recruited by telephone from previous probabilistic surveys. Of the 40,000 people, 5,512 lived in the municipalities where the risk of contracting Lyme disease was low or significant and were contacted for our study. The municipalities of residence were verified a second time with a question in the online questionnaire. The respondents were not paid to participate in the survey, but the survey firm organizes a lottery each quarter (i.e., four times per year), so the members of the panel who answered a questionnaire during this period of time have the chance of winning CAD 1,000. A panel member is not solicited more than six times a year. New panel members are recruited every week, and inactive members are removed from the database. According to the survey firm, the average panel recruitment response rate at the time of the current study is between 20% and 30%, depending on the subject and the length of the questionnaire.
For the telephone sample, the polling firm randomly drew 200,000 of all the available landline phone numbers. Among those drawn, 64,631 corresponded to the target
22
municipalities. Of the 64,631 numbers, 6,985 were called, and the person was asked to participate in the present study. The data from this sample were also collected from May 18 to August 28, 2018. A maximum of 10 attempts were made to establish contact before a telephone number was rejected. A total of 1,003 people (woman, 68.3%) completed the questionnaire by telephone.
We used the Kish selection method to determine quotas by region [47,48]. The quotas for smaller and larger regions were readjusted to ensure minimal statistical power in smaller regions and to meet the quota of 1,000 respondents for both samples (see online resource 1 for the quotas and online resource 2 for the final samples).
We used Kish’s [49] formula to estimate the effective sample size (ESS) of both web questionnaire and telephone samples, after weighting the data. The ESS estimates the “worth” of a given sample as compared to a simple random sampling from the population. The ESS of the 956 people surveyed by the web questionnaire was 383, whereas that of the 1,003 people who answered the telephone questionnaire was 238.
Questionnaire
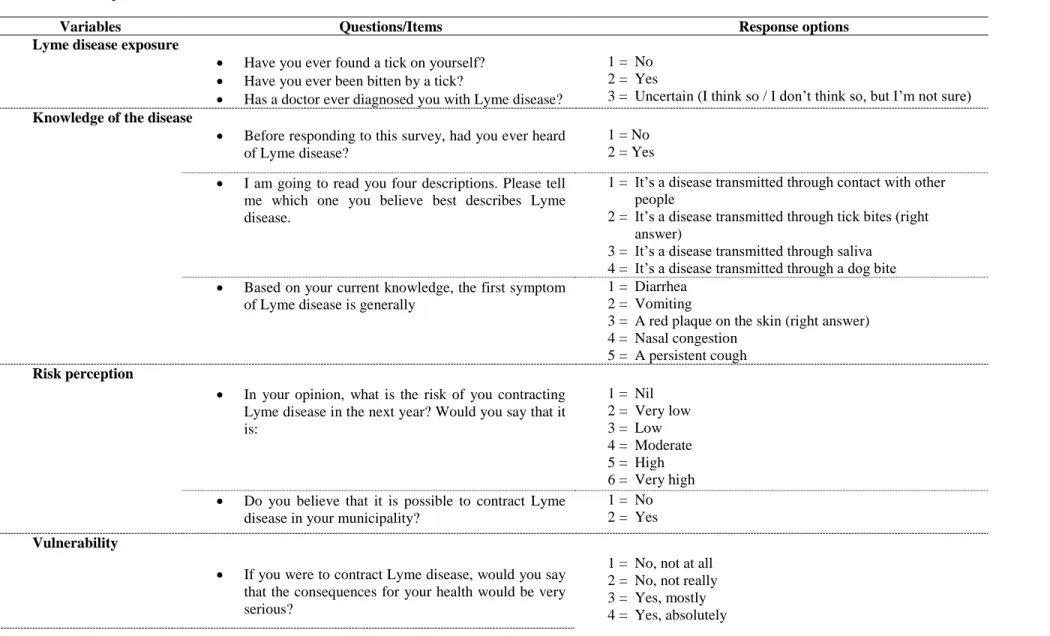
Participants were asked to complete a 91-item questionnaire administered as part of a larger survey conducted by the Québec Observatory of Adaptation to Climate Change. The aim of this survey was to identify factors associated with the adoption of LDPB among people in the Province of Québec (Canada). Of these questions, 30 were linked to psychosocial models, in particular to the theory of planned behavior and the health belief model, and were used in the current study to compare the telephone and web data collection modes. The questions pertained to Lyme disease exposure (three items), knowledge of the disease (three item), risk perception (two items), vulnerability (one item), opinions on vaccines (three items), attitudes towards the adoption of LDPB (one item), perception of social pressure (one item), perception of control over these behaviors (one item), intention to adopt these behaviors (one item), and various (14 items) self-reported adopted LDPB (Table 1).
The self-reported adopted preventive behaviors were selected based on a literature review [50–55] and recommendations from public health agencies [43,56]. Using these
23
behavioral indicators, we created and validated an index of LDPB [57]. The index was validated for both the telephone interviews and the web self-administered questionnaire.
These questions and their respective response options are presented in Table 1.
Statistical analysis
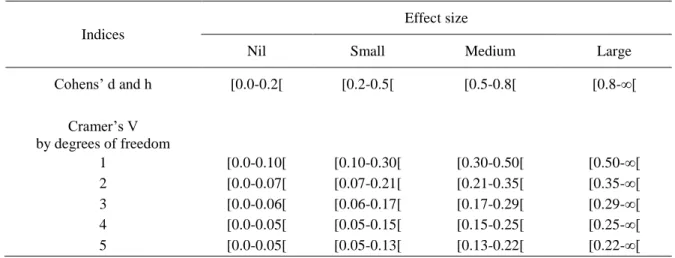
First, to assess the representativeness of the telephone and web surveys, we compared the data obtained through each data collection mode with the census data in regard to gender, age, presence of children in the household, and household size. We also compared the telephone and web surveys with the 25% census sample in regard to annual income and highest education level. To do so, we used a one-sample chi-square test or a Fisher’s exact test (when the minimum number of observations in a cell was less than 5) and evaluated the effect size using Cramer’s V statistic.
Second, we compared the data collected from the telephone and web surveys on specific items of the questionnaire in regard to means and proportions of self-reported Lyme disease adaptive behaviors and other theoretically associated constructs. A Student’s t-test or chi-square test/Fisher’s exact test was used depending on whether means or frequencies were being compared. Z tests for independent proportions were also performed on all the categories of nominal variables. The effect sizes were also calculated: Cohen’s d for Student’s t-tests, Cramer’s V for chi-square/Fisher’s exact tests, and Cohen’s h for the Z tests for independent proportions [58]. Table 2 provides a better understanding of how to interpret those effect size indicators. In addition, we compared the web and telephone data on the nonresponse rates for each of the items mentioned earlier, as well as the sociodemographic variables. The nonresponse rates consisted of all those who answered “Do not know” and those who simply refused to give an answer. We used Z tests for independent proportions for these comparisons.
Third, we assessed the measurement invariance (equivalence) of the index of LDPB across the telephone and web samples. This invariance is a necessary condition for unambiguous mean comparisons of the index across both survey modes [59–61].
First, a model with no invariance of any parameters, also referred to as the configural invariance model, was estimated. We then tested the strong invariance of the model by
24
constraining the factor loadings and item thresholds to equality for both groups, which is equivalent to the weak invariance model because we used binary items [62]. Third, we tested the strict invariance of the model by constraining the factor loadings, item thresholds, and item uniquenesses to equality across groups. Finally, we tested the invariance of the latent variance and latent mean of the estimated factor. In this study, we used the comparative fit index (CFI), the Tucker-Lewis index (TLI), and the root mean squared error of approximation (RMSEA) to compare models and assess model fit. Acceptable model fit is indicated by CFI and TLI values greater than or equal to 0.90 and less than 0.95. Excellent model fit is indicated by CFI and TLI values greater than or equal to 0.95. As for RMSEA, values between 0.05 and 0.08 indicate an adequate model fit, and values less than or equal to 0.05 indicate an excellent model fit [63,64].
Finally, we reproduced the previous statistical analyses where the data collected from the telephone and web surveys were compared once the data were weighted for both samples. To do so, we first weighted the data by administrative region with a raking ratio method using six variables: age, sex, household size, household structure, highest education level, and income [65]. Second, we reweighted the data using a ratio adjustment, so that the proportions of the administrative regions in the web and telephone samples would be the same as those in the population.
1.4 Results
The response rates for the telephone and web surveys were 24.5%, and 17.0%, respectively. Telephone response rate was determined by dividing the number of completed questionnaires by the number of eligible individuals. We also took into account a proportion of the cases of unknown eligibility in the number of eligible individuals, as indicated in the American Association for Public Opinion Research Standard Definitions [66]. The proportion of cases of unknown eligibility taken into account was estimated by dividing the number of valid telephone numbers by the number of valid telephone numbers added to the number of invalid telephone numbers. For the web survey, the response rate was determined by dividing the number of completed questionnaire by the number of sent emails.
In the web survey, 44.6% of the respondents were men and 55.4% were women, compared with 31.7% and 68.3%, respectively, in the telephone survey. The average
25
connection time to the website was 17 minutes in the web survey, whereas the telephone interviews lasted an average of about 20 minutes.
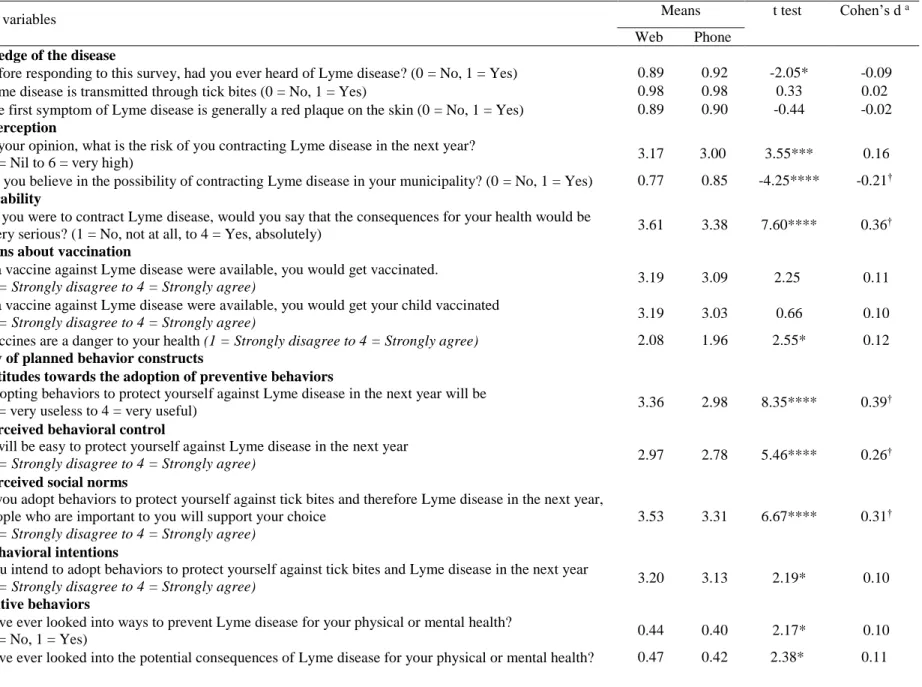
Comparison of the web and telephone surveys with the census
The results presented in Table 3 showed that, in general, the percentages of non-responses for sociodemographic variables were very low and similar (no effect size) in both surveys, except for the reported household annual gross income were there is a higher percentage of non-responses for the reported household annual gross income in the telephone survey (15.8% for the web sample and 20.5% for the telephone sample). This difference was statistically significant but negligible according to effect size analyses (Cohen’s h < .20).
Our results showed also that almost all the sociodemographic characteristics of the web and telephone surveys were statistically different from those in the census and the 25% census sample (see Table 4). The only two exceptions were the average household annual gross income obtained in the web survey, where the distribution appeared to be representative of the population, and the presence of at least one child in the household, where the estimates in the telephone survey were not statistically different from the census data. Results regarding the magnitude or practical significance of these differences showed that the effect size for the web survey could be qualified as medium for two variables (age and highest education level), small for two other variables (household size and presence of at least one child in the household), and nil for one variable (gender). For the telephone survey, the results indicated one large (age), two medium (gender and highest education level), and two small (household size and household annual gross income) effect sizes.
Examination of Table 4 also revealed that the differences between the web and the telephone samples were all statistically significant. Furthermore, although the differences for the household annual gross income, the presence of at least one child in the household, and the household size were statistically significant, the magnitude of these differences was negligible according to the effect size analysis. The results also indicated that the effect sizes were small for age (Cramer’s V = 0.14), gender (Cramer’s V = 0.13), and the highest education level obtained (Cramer’s V = 0.10).