Recommendation of XML Documents exploiting Quality Metadata and Views
Texte intégral
Figure

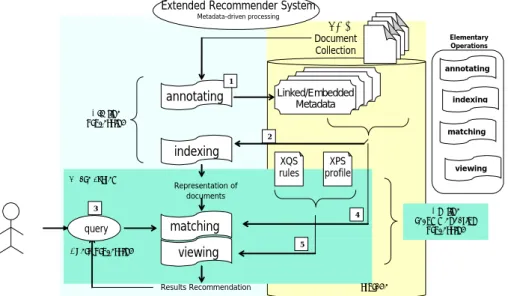



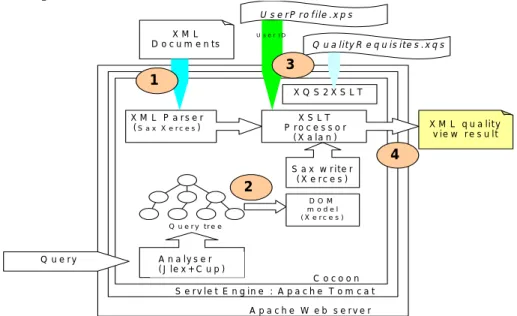
Documents relatifs
• Si dans la feuille de style on prévoit une instruction xsl:template pour traiter un certain élément, ne pas oublier de préciser dans l’instruction ce qui doit se passer avec
The problem of online dictionary matching of XML is stated as follows: Given a set of linear XPath expressions without predicates (the patterns ) and a stream of XML documents
Summing up the contributions of our work, we propose an approach to inte- grate efficiently heterogeneous and distributed web sources under the following assumptions: (i) the
At first glance, [5] deals with a problem that is more similar to ours: finding a minimal-cost sequence of elementary edit operations (relabeling a node, and deleting or inserting
On verra par exemple que le choix d’un éditeur XML n’est pas simple, suivant les critères retenus : open source ou payant, adapté pour la saisie d’un grain ou bien d’un
For the goal of determining whether XML documents were invalidated due to schema evolution, the system must recognize and analyze the differences be- tween the old ( S 0 ) and new ( S
Via the inspection of the state space of an automaton recognising regular expressions, we are always able to find all minimal repairs represented by recursively nested
Trans- formation systems are mostly based on one of these formal models - syntax directed translation schema, tree transformation grammar, descending tree transducer and higher
