Virtual, Digital and Hybrid Twins: A New Paradigm in Data-Based Engineering and Engineered Data
Texte intégral
Figure

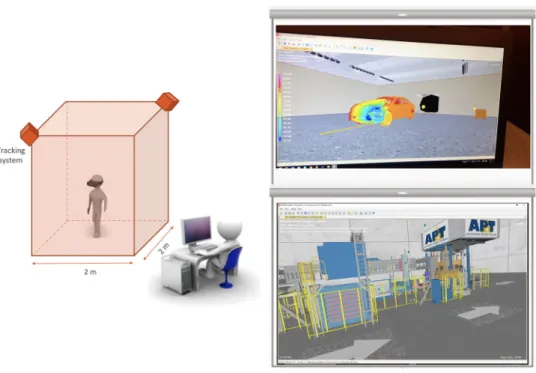


Documents relatifs
This paradigm can be applied to different database models (e.g., relational, semi-structured, graph) and a class of queries adequate to the database model (e.g., join queries for
Abstract. This paper proposes a novel graph based learning approach to classify agricultural datasets, in which both labeled and unlabelled data are applied to
Alors sans intervention de type supervisé (cad sans apprentissage avec exemples), le système parvient à détecter (structurer, extraire) la présence de 10 formes
• Cet algorithme hiérarchique est bien adapté pour fournir une segmentation multi-échelle puisqu’il donne en ensemble de partitions possibles en C classes pour 1 variant de 1 à N,
Keywords: Challenge-based learning, active learning, experiential learn- ing, project based learning, data science, computational biology..
Kamra, Johina, “A Review: Data Mining Technique Used In Education Sector”, International Journal of Computer Science and Information Technologies, Vol. Sugasini, “Analysis
This paper is organized as follows: The next section intro- duces the concept of knowledge mining. Section III describes the algorithms of induction rules mining. Then,
The different mentioned existing DL-based methods, which are dedicated for data completion and correction to improve the indoor localization accuracy, are based on unsupervised
