Méthodes d'optimisation pour le traitement de requêtes réparties à grande échelle sur des données liées
156
0
0
Texte intégral
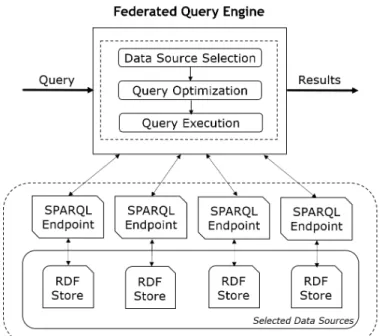
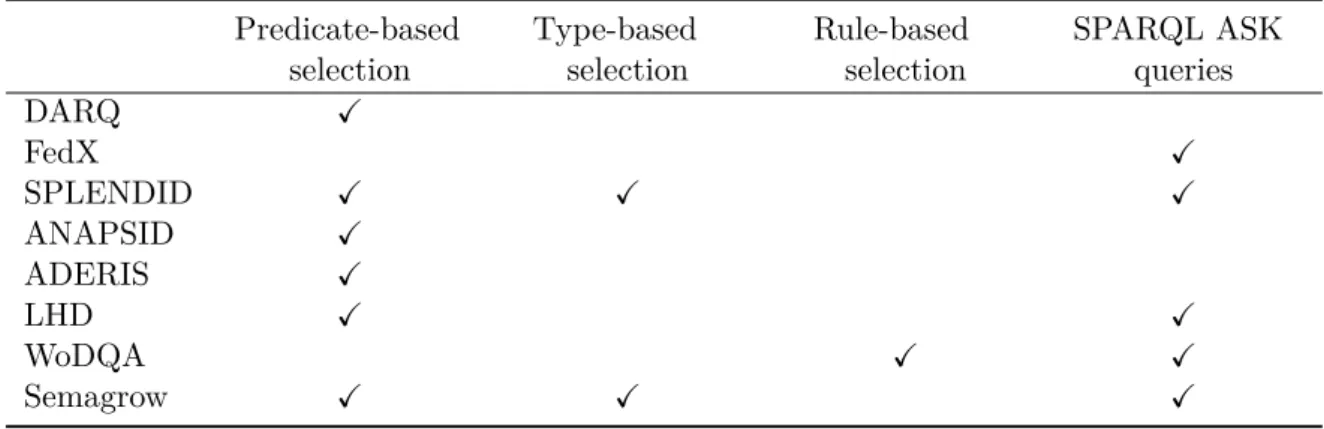
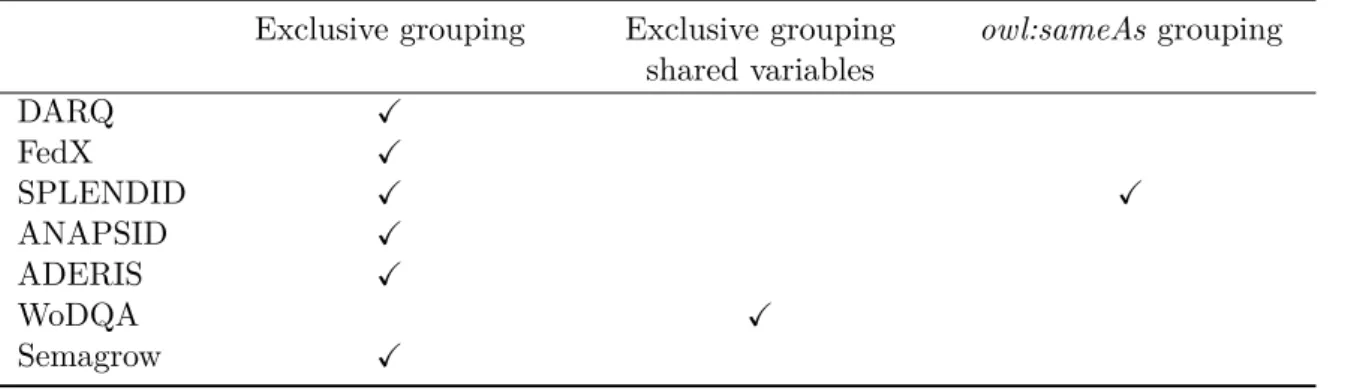
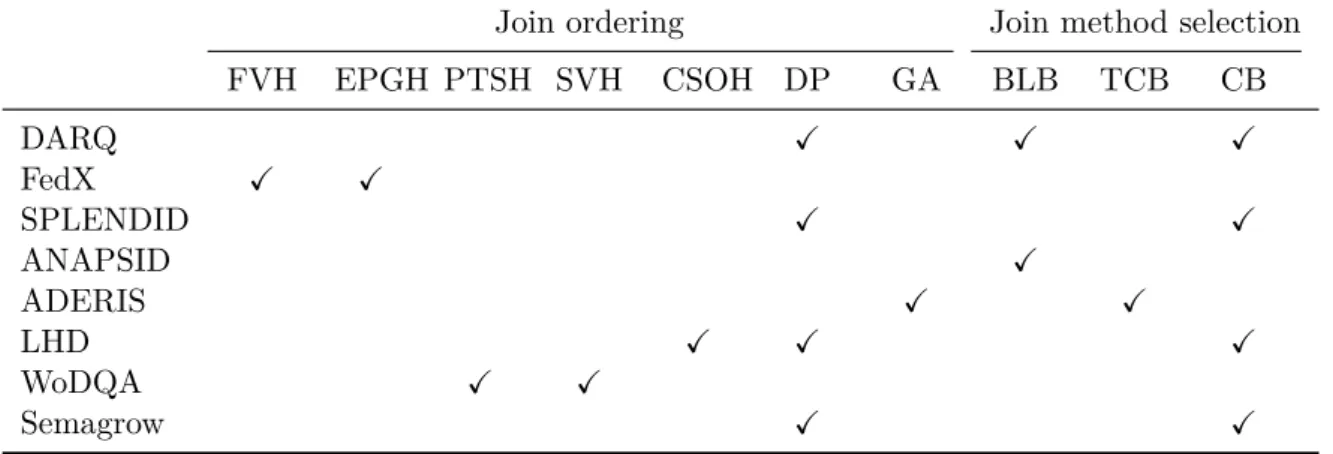
Figure

+7

Documents relatifs