Faculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat – Maroc Tel +212 (0) 37 77 18 34/35/38, Fax : +212 (0) 37 77 42 61, http://www.fsr.ac.ma
THÈSE DE DOCTORAT
Présentée par
Nom et Prénom : El GHALI Btihal
Discipline : Sciences de l’ingénieur
Spécialité : Informatique et Télécommunications
Titre : Modèles Contextuels pour la Recommandation et l'Expansion de Requêtes en Recherche d'Information.
Soutenue le 16/07/2016 Devant le jury
Président :
Pr. Rachid OULAD HAJ THAMI PES, Ecole Nationale Supérieure d'Informatique et d'Analyse des systèmes, Rabat
Examinateurs :
Pr. Salma MOULINE PH, Faculté des Sciences de Rabat
Pr. Ali EL MERZOUQI PES, Faculté des Sciences de Tétouan
Pr. El Habib NFAOUI PH, Faculté des Sciences Dhar Mahraz, Fès
Pr. Hamid BENKADDOUR PES, École Nationale des Sciences Appliquées, Tétouan
Pr. Mohamed OUADOU PES, Faculté des Sciences de Rabat
Dédicace
A vous chers parents, vous qui m’aviez offert la vie. Vous qui étiez là
pour mes premiers pas, aujourd’hui j’espère vous rendre fiers. Merci pour
vos sacrifices et vos encouragements.
A vous, mes grands-parents, vous voir me fait oublier toutes les
difficultés de cette vie, J’espère vous rendre fiers.
A vous, Tanae et Ayman, malgré le fait qu’on n’est pas sur la même
longueur d’onde, je vous aime trop et vous espère le meilleur dans cette vie.
Particulièrement, à ma tante Badia El Ghali et mon oncle Cherif
Essalih, votre soutien, vos conseils et votre présence me sont trop précieux.
Ainsi qu’à toute ma famille ; mes tantes, mes oncles, mes cousines,
mes cousins, mon neveu et mes nièces
A vous, Oumaima, Lamiae, Fadwa, Nawal et Omar, A vous mes
meilleurs amis, Meryem EL Mouhtadi, Imane Zaimi, Hind Oulhaj, et
Ahmed El Kouch vos encouragements et les moments que nous avons passé
ensemble ont été d’une grande aide pour moi.
A tous mes amies et mes collègues du laboratoire LRIT,
Ce travail vous est dédié. Votre présence dans ma vie a fait de moi ce
que je suis aujourd’hui.
Avant-propos
Les travaux présentés dans ce mémoire ont été effectués au sein du « Laboratoire de Recherche en Informatique et Télécommunications » à la faculté des sciences de Rabat, sous la direction du Professeur OUADOU Mohamed et sous l’encadrement du Professeur Habilité EL QADI Abderrahim.
Il ne sera jamais suffisant de dire à quel point, je suis reconnaissante envers toute personne qui m’a aidée et qui a contribuée, par son aide et ses encouragements, de près ou de loin à la bonne réalisation de ce projet.
Avant toute chose, je voudrais remercier infiniment M. Mohamed OUADOU d’avoir accepté de diriger ce projet de thèse. Un très grand merci pour sa disponibilité, sa gentillesse, sa compréhension, et ses conseils.
Je tiens également à remercier M. Abderrahim EL QADI pour le choix judicieux de ce sujet, pour les efforts inlassables qu’il a déployés pour que ce travail soit élaboré, pour son aide précieuse et pour la qualité de son encadrement qui m’a été d’un appui considérable. Un très grand merci pour son dévouement, sa disponibilité, sa compréhension, et ses conseils.
Je tiens également à exprimer ma profonde gratitude à M. Driss ABOUTAJDDINE de m’avoir accueilli au sein du laboratoire LRIT, pour m’avoir offert cette agréable opportunité d’intégrer l’univers de la recherche scientifique, et pour ses efforts indéniables afin de procurer aux doctorants du laboratoire les meilleures conditions pour la réalisation de leurs projets de thèse.
Je remercie infiniment M. Rachid OULAD HAJ THAMI (PES, Ecole Nationale Supérieure d'Informatique et d'Analyse des systèmes, Rabat) d’avoir accepté de présider ma soutenance de thèse. Votre présence est un grand honneur pour moi.
Je tiens à exprimer ma grande considération et ma haute estime, à Mme Salma MOULINE. Je suis fière d’avoir fait partie de l’une des promotions que vous avez influencées. Votre probité au travail, votre dynamisme et votre sens de responsabilité m’ont toujours impressionnée et sont pour moi un idéal à atteindre. Je vous remercie infiniment d’avoir accepté sans hésitation de rapporter mon travail de thèse
Je tiens aussi à exprimer mon profond respect et à remercier M. Ali El MERZOUQI (PES, Faculté des Sciences de Tetouan), d’avoir accepté de rapporter ma thèse et pour le temps qu’il a consacré à la lecture mon mémoire de thèse et à la rédaction du rapport représentant sont avis dessus.
Je tiens à remercier et à témoigner toute ma reconnaissance à M. El Habib NFAOUI (PH, Faculté des Sciences Dhar Mahraz, Fes), merci d’avoir accepté de rapporter ma thèse de doctorat, merci d’avoir consacré du temps pour lire et examiner mon mémoire, merci pour vos remarques pertinentes.
Je tiens également à exprimer ma profonde gratitude à M. Hamid BENKADDOUR (PES, École Nationale des Sciences Appliquées de Tétouan) pour ses conseils avisés, pour le soutien que vous avez accordé à ma modeste personne et pour avoir accepté d’examiner ce travail de thèse.
Résumé
La surabondance de l’information et sa large accessibilité à travers le web, ont engendré la diminution de la pertinence et la dégradation de la qualité des résultats retournés par les Systèmes de Recherche d’Information (RI) classiques, qui se caractérisent par un processus d’accès à l’information dépendant seulement de la disponibilité de l’information et des critères de sélection par le contenu. En effet, plus le volume de l’information est grand, plus le nombre de documents renvoyés par le système à l’utilisateur est grand, ce qui le pose face à une surcharge informationnelle qui le désoriente où il doit prendre la charge de sélectionner ce qui est pertinent de ce qui ne l’est pas. En clair, le problème ne réside pas dans l’indisponibilité de l’information mais dans la pertinence des résultats relativement à un contexte d’utilisation spécifique.
Afin de rapprocher au mieux la pertinence système de la pertinence utilisateur et répondre au besoin en information de ce dernier d’une façon plus précise, nous proposons dans cette thèse des approches innovantes, basées sur des modèles contextuels, pour la recommandation et l'expansion de requêtes.
Trois modèles de recommandation de requêtes ont été proposés sur la base de deux représentations de la requête : la première caractérise ses éléments par la présence ou non des termes dans la requête, la deuxième décrit la pertinence ou non d’un document à la requête. Les modèles de recommandation proposés montrent que l’information de pertinence ou non des documents influencent le score de recommandation entre les requêtes plus que l’information de présence ou non des termes. Nous avons également constaté que l’approche basée uniquement sur les modèles de langue donnent les meilleurs résultats de recommandation pour les requêtes courtes, ainsi que pour les requêtes longues.
Pour ce qui concerne l’expansion de requête, dans une première contribution nous avons proposé une méthode probabiliste qui exploite le contexte de la requête à étendre. La deuxième proposition est basée sur la représentation des requêtes en concepts, au lieu de ne considérer que des termes indépendants, en se basant sur la méthode d’Analyse Sémantique Latente (LSA). Cela nous a permis de tester trois nouvelles approches et de les comparer en fusionnant la méthode d’expansion par LSA avec les trois modèles de construction de contexte proposés.
Ces propositions ont été sujet d’expérimentations rigoureuses et le gain en résultats des recommandations et en précision des résultats de recherches par les requêtes étendues a été mesuré par des mesures d’évaluation validées. Les résultats montrent que la prise en compte du contexte autour de la requête en recherche d’information augmentent la pertinence des résultats retournés et réduit ainsi le bruit.
Mots-clés : Recherche d'Information, Contexte, Modèles de Langue, Analyse Sémantique Latente, Recommandation de requêtes, Expansion de requêtes.
Abstract
The glut of information and its wide accessibility through the web, have led to the decrease of the relevance and degradation of the quality of results returned by the standard Information Retrieval Systems (IR), which is characterized by a process of access to information that depends only on the availability of information and selection by the content criteria. Indeed, the more the volume of information increase the more the number of documents returned by the system to the user is high, which put the user face to face to an overload of information disorienting him while he should take charge of selecting what is relevant from what is not. Obviously, the problem doesn’t lie in the availability of information but it lies in the relevance of the results regarding a specific user context.
In order to approximate at best, the system relevance to the user relevance, and meet the user’s information need in a more precise way, we propose in this thesis, innovative approaches based on contextual models for the recommendation and the expansion of queries. Three queries recommendation models have been proposed based on two representations of the query: the first characterizes its elements by the presence or absence of terms in the query, while the second describes the relevance or not of a document to the query. The proposed recommendation models show that the information of relevancy or not of documents influence the recommendation score between queries more than the information of presence or not of terms. We also found that the approach based only on language models gives the best results of recommendation for short queries, and also for long queries.
Regarding the query expansion, as a first contribution we proposed a probabilistic method that exploits the context of the query to expand. The second proposal is based on the representation of queries as concepts, instead of considering only independent terms, based on the Latent Semantic Analysis (LSA) method. That allowed us to test three new approaches and compare them by merging the LSA-based expansion method with the three proposed context building models.
These proposals were subject of rigorous experiments and the gain in results of recommendations and the gain in precision of results of the research by the expanded query is measured by validated evaluation measures. The results show that taking into account the context around the query in the information retrieval process increase the relevance of the returned results and reduces the noise.
Keywords: Information retrieval, Context, Language Models, Latent Semantic Analysis,
صخلم
لوصولا ةلوهسو تامولعملا ةرفو تدأ
اهيلإ
،قاطنلا ةعساولا تنرتنلإا ةكبش ربع
ضافخنا ىلإ
لاإ دمتعت لا يتلاو ،ةيديلقتلا تامولعملا عاجرتسا مظن لبق نم ةدرتسملا ثحبلا جئاتن ةدوجو ةيمهأ
لإ لوصولا ةيلمع يف ىوتحملا ىلع ةينبم رايتخا ريياعمو تامولعملا رفوت ىلع
اهي
مجح داز املكف .
هكبري يذلا رملأا ،مدختسملل ماظنلا اهعجري يتلا تادنتسملا ددع داز ،تامولعملا
لمح مامأ هعضيو
نمف .كلذ نود امو ةلص وذ وه ام ديدحت يف ةيلوؤسملا ذخأ هيلع بجوتيف تامولعملا نم دئاز
تامولعملا رفوت يف نمكت لا ةلكشملا نأ حضاولا
بسحو
قفو ةدرتسملا جئاتنلا ةيمهأ يف امنإو ،
.نيعم لامعتسا قايس
لضفأ قيقحتل
مدختسملاو ماظنلا نيب قفاوت
ةيبلتو
ةجاح
ةقيرطب ةبولطملا ةمولعملل ريخلأا اذه
ةقد رثكأ
،
ةغايص ةداعلإ ةيقايس جذامن ىلإ دنتست ةركتبم جهانم ةحورطلأا هذه يف حرتقن اننإف
و حيجرت وأ اهتعسوت قيرط نع تاراسفتسلاا
ةيصوت
تاراسفتسا
رخأ
ى
اهلدب
.
ىلإ ادانتسا تاراسفتسلاا حيجرتل جذامن ةثلاث حارتقا مت دقو
نيفيرعت
ثا
هرصانع زيمي لولأا :نين
راسفتسلاا ءاوتحا مدع وأ ءاوتحا للاخ نم
ىلع
ةيمهأ ىدم ىلع يناثلا دمتعي امنيب ،تاحلطصملا
دامتعا نع ةمجانلا تامولعملا نأ ةحرتقملا حيجرتلا جذامن رهظتو .راسفتسلال ةبسنلاب ام دنتسم
رثكأ تاراسفتسلاا نيب حيجرتلا ةجرد ىلع رثؤت تادنتسملا ةيمهأ
تامولعملا اهيلع رثؤت امم
ىلع طقف ةمئاقلا جهانملا نأ ىلإ انلصوت امك .تاحلطصملا دوجو مدع وأ دوجو ىلع ةدمتعملا
.ةليوطلاو ةريصقلا تاراسفتسلال حيجرت جئاتن لضفأ يطعت ةغللا جذامن
و ،ىرخأ ةيحان نم
ست ةيلامتحا ةقيرط يلوأ ماهسإك انحرتقا ،راسفتسلاا ةعسوتب قلعتي اميف
لغت
ةعسوتلل حشرملا راسفتسلاا قايس
.
امنيب
اندنتسا
ىلع تاراسفتسلاا ليثمت ىلع يناثلا انحارتقا يف
نماكلا يللادلا ليلحتلا ةينقت ىلإ ادانتسا كلذو طقف ةلقتسم تاحلطصم رابتعا نم لادب ،ميهافم لكش
LSA
تاملكلا نيبو تادنتسملا نم ةعومجم نيب تاقلاعلا ليلحت ىلع دمتعت يتلا
يوتحت يتلا
ةثلاث رابتخاب انل حمس ام اذهو .تاحلطصملاو تادنتسملاب قلعتت "ميهافم" ءانب للاخ نم اهيلع
ةينقت ىلع دنتسي يذلا ةعسوتلا بولسأ جمد قيرط نع اهتنراقمو ةديدج جهانم
LSA
جذامن عم
.ةحرتقملا ةثلاثلا قايسلا ءانب
ةمراص براجتل تاحرتقملا هذه لك تعضخأ
دقو
يق مت
ةقد دودرمو تايصوتلا جئاتن دودرم سا
.ةيعرشو لوعفملا ةيراس مييقت ريياعم لامعتساب اهتعسوت مت يتلا تاراسفتسلااب ثوحبلا جئاتن
عاجرتسا يف راسفتسلاا لوح رودي يذلا قايسلل رابتعلاا نيعب ذخلأا نأ جئاتنلا ترهظأو
نم كلذب للقيو ةعجرملا جئاتنلا ةيمهأ نم ديزي تامولعملا
.ةشوشملا جئاتنلا
ةيرهوجلا تاملكلا
حيجرت ،نماكلا يللادلا ليلحتلا ،ةغللا جذامن ،قايسلا ،تامولعملا عاجرتسا :
.تاراسفتسلاا ةعسوت ،تاراسفتسلاا
Table des matières
INTRODUCTION GENERALE ... 1
Contexte et problématique ... 1
Contributions ... 3
Organisation du mémoire ... 5
PARTIE I : ETAT DE L’ART ... 8
Chapitre 1 : Recherche d’information et contexte ... 9
1.Introduction... 10
2. La Recherche d’Information : processus, techniques et outils ... 10
2.1. Le processus de Recherche d’Information ... 11
2.1.1 L’expression du besoin en information : l’interrogation du corpus de documents ... 12
2.1.2 Le processus d’indexation ... 13
2.1.2.1 L’analyse lexicale ... 14
2.1.2.2 L’élimination des mots vides ... 14
2.1.2.3 La lemmatisation ... 15
2.1.2.4 La pondération des termes ... 16
2.1.3 L’appariement document-requête ... 17
2.1.4 La reformulation de la requête ... 19
2.2. Les modèles-piliers de la Recherche d’Information ... 20
2.2.1 Modèles ensemblistes ... 21
2.2.1.1 Le modèle booléen ... 21
2.2.1.2 Le modèle flou ... 22
2.2.2 Modèles algébriques ... 23
2.2.2.1 Le modèle vectoriel ... 23
2.2.2.2 Le modèle d’Analyse Sémantique Latente (LSA) ... 25
2.2.3 Modèles probabilistes ... 26
2.2.3.1 Le modèle probabiliste ... 26
2.2.3.2 Les modèles de langue ... 27
2.3. Les outils de Recherche d’Information ... 29
2.3.1 Les moteurs de recherche ... 30
2.3.2 Les annuaires ... 32
2.3.3 Les méta-moteurs ... 33
3. Intégration du contexte en Recherche d’Information ... 33
3.1.1. Le profil utilisateur ... 35
3.1.2. Fichier journaux (Log) ... 36
3.2. Phases d’intégration du contexte ... 37
3.2.1. Au début du processus de RI ... 37
3.2.2. Pendant le processus de RI ... 38
3.3. Architecture d’un Système de Recherche d’Information Contextuel ... 39
4. Evaluation des systèmes de Recherche d’Information ... 40
4.1. Notion de pertinence ... 41
4.1.1. Pertinence système ... 41
4.1.2. Pertinence utilisateur ... 42
4.2. Collection de test ... 42
4.2.1. SMART (Salton’s Magical Automatic Retriever of Text) ... 43
4.2.2. Les campagnes TREC (Text REtrieval Conference) ... 45
4.3. Mesures d’évaluation ... 46
4.3.1. Rappel et précision ... 46
4.3.2. Précision moyenne ... 48
4.3.3. Mesures combinées ... 49
5. Conclusion ... 50
Chapitre 2 : Méthodes de recommandation de requêtes ... 51
1. Introduction ... 52
2. Techniques basées sur le contenu ... 52
3. Techniques basées sur le contexte ... 54
3.1. Approche Classique : Clustering des requêtes ... 54
3.2. Amélioration du rang de classement des documents pertinents ... 56
3.3. Prédiction de requêtes séquentielles ... 58
4. Techniques basées sur le contenu et le contexte ... 62
4.1. Contexte 1 : Les requêtes les plus récentes ... 62
4.2. Contexte 2 : Les documents (URLs) retournés par le SRI ... 66
4.3. Contexte 3 : Les URLs cliqués ... 68
4.3.1. Approches Basées sur le Clustering des requêtes passées ... 68
4.3.2. Approche Basée sur les extraits d’URLs (Snippets) ... 72
4.3.3. Approche Basée sur les annotations sociales ... 74
5. Conclusion ... 76
Chapitre 3 : Méthodes d'expansion de requêtes ... 77
1. Introduction ... 78
3. Expansion globale ... 79
3.1. WordNet ... 80
3.1.1. Les bases de WordNet ... 81
3.1.2. Le principe de WordNet ... 82
3.1.3. L’expansion globale et WordNet ... 83
3.2. Le Thésaurus de similarité ... 84
3.2.1. Expansion du concept de la requête ... 84
3.2.2. La construction du thésaurus de similarité ... 83
3.3. Corpus de domaine ... 86
4. Expansion locale ... 87
4.1. Réinjection de pertinence (RP) ... 88
4.1.1. Le processus de la réinjection de pertinence ... 88
4.1.2. Algorithme de Rocchio ... 90
4.1.3. Les avantages et limitations de la RP ... 91
4.2. La Pseudo Réinjection de pertinence ... 92
4.2.1. L’expansion par les représentants de documents ... 93
4.2.2. L’expansion par l’approche théorétique d’information ... 94
4.2.3. L’expansion par phrases pour modèles de langue ... 96
5. Expansion basée sur les journaux de requêtes ... 97
5.1. Exploitation de l’information du lieu ... 98
5.2. Exploitation de l’information d’interaction système-utilisateur ... 99
6. Conclusion ... 101
PARTIE II : CONTRIBUTIONS ... 102
Chapitre 4 : Proposition et Evaluation des modèles de recommandation de requêtes .. 103
1. Introduction ... 104
2. Algorithme de Recommandation de requêtes ... 104
2.1 Les étapes de l’algorithme TQRA ... 105
2.2 Les requêtes de test et les documents les plus restitués ... 106
2.3 Comparaison des mesures de similarités ... 107
2.4 Comparaison des fonctions de pondérations ... 110
3. Recommandation de requêtes par Modèles de langue ... 112
4. Méthode hybride ... 114
5. Spécification des valeurs des paramètres et comparaisons ... 115
5.1 Variation du paramètre de normalisation ... 115
5.2 Variation du paramètre de lissage ... 117
5.4 Comparaison des méthodes de recommandation proposées ... 119
6. Conclusion ... 120
Chapitre 5 : Approches contextuelles d'expansion de requêtes ... 122
1. Introduction ... 123
2. Corrélation entre les termes des requêtes et des documents... 124
3. Méthode probabiliste d’expansion de requêtes ... 125
3.1. Le processus d’expansion ... 126
3.2. Spécification des valeurs des paramètres ... 128
4. Expansion par Analyse Sémantique Latente ... 134
4.1. Construction de contexte par Modèles de Langue ... 137
4.2. Variation des modèles de recommandation pour les requêtes courtes ... 142
5. Conclusion ... 148 CONCLUSION GENERALE ... 150 Synthèse ... 150 Perspectives ... 152 Bibliographie ... 154 Annexes ... 163
Liste des tableaux
Tableau 1.1 - Part du marché mondial des moteurs de recherche les plus connus ... 31
Tableau 1.2 - Nombre de documents et de requêtes de la collection CISI ... 44
Tableau 1.3 - Exemple de restitution de document pour une requête q ... 48
Tableau 2.1 - Exemple de couple de requêtes avec leurs score TermOverlap (T.O.) et ResultOverlap (R.O.) ... 68
Tableau 4.1 - Mesures de pondération Tf-Idf et LTC ... 105
Tableau 4.2 - Expressions de similarités à comparer ... 106
Tableau 4.3 - Requêtes ayant le plus grand nombre de documents pertinents ... 107
Tableau 4.4 - Les documents les plus restitués dans la collection CISI ... 107
Tableau 4.5 - Les meilleures requêtes recommandées pour les trois expressions de similarité ... 108
Tableau 4.6 - Comparaison des fonctions de pondération Tf-Idf et Ltc ... 111
Tableau 4.7 - Nombre de documents pertinents et de termes en commun entre chaque requête et sa meilleure requête recommandée ... 111
Tableau 4.8 - Les valeurs AISA pour les trois approches proposées pendant la variation du nombre de requêtes recommandées ... 119
Tableau 4.9 - Les valeurs de l’AISA pour les requêtes courtes et longues ... 120
Tableau 5.1 - Requêtes d’entrée ... 128
Tableau 5.2 - La performance de la valeur de MAP en utilisant l’approche LSARQ ... 141
Tableau 5.3 - Comparaison des meilleures valeurs pour chaque cas de méthode d’expansion avec ses conditions appropriées (pour les requêtes courtes) ... 146
Tableau 5.4 - Comparaison des deux approches LSARQ et LMLSA en se basant sur les mêmes conditions ... 147
Liste des figures
Figure 1.1 - Processus en U de Recherche d’Information ... 12
Figure 1.2 - Architecture de base d’un Système de Recherche d’Information Contextuelle (Tamine 2008) ... 39
Figure 1.3 - Aperçu des requêtes dans la collection CISI ... 44
Figure 1.4 - Un exemple de représentation de document dans la collection CISI ... 44
Figure 1.5 - Les jugements de pertinence de la collection CISI ... 45
Figure 1.6 - Partition de la collection pour une requête (Tamine 2000) ... 46
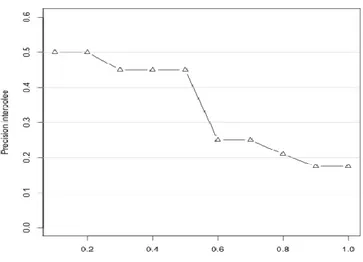
Figure 1.7 - Exemple de courbe rappel-précision interpolée pour une requête – Cas de précisions interpolées aux 6 points standards du rappel ... 48
Figure 2.1 - Architecture QUBIC (Li et al. 2008) ... 55
Figure 2.2 - L’approche de prédiction de Cao et al. (2008) ... 59
Figure 2.3 - Un arbre de séquences de concepts (Cao et al. 2008) ... 59
Figure 2.4 - Un contexte de recherche avec des tâches intercalées (Feild et Allan 2013) ... 63
Figure 2.5 - Exemples de segmentation on-task/off-task (Feild et Allan 2013) ... 65
Figure 2.6 - Le texte dans le carré rouge représente un extrait de document - Snippet (En considérant l’exemple de la requête « Information retrieval » sur le moteur de recherche google.com) ... 72
Figure 2.7 - Graphe Tripartite Requête-URL-étiquette (Guo et al. 2010) ... 75
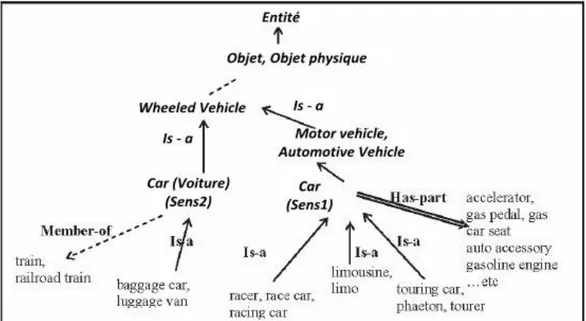
Figure 3.1 - Exemple de sous hiérarchie dans WordNet correspondant au concept « Car » (Baziz 2005) ... 82
Figure 3.2 - Les relations entre les termes d’une collection et une requête donnée q (Imran et sharan 2009) ... 84
Figure 3.3 - Le Processus de la réinjection de pertinence ... 89
Figure 3.4 - Représentation requête-document en graphe bipartite ... 98
Figure 4.1 - Comparaison entre le nombre de requêtes recommandées ... 108
Figure 4.2 - Le score de recommandation de la meilleure requête recommandée en utilisant la mesure Cosinus avec les valeurs de score pour les trois expressions du TABLEAU 4.2 ... 109
Figure 4.3 - La Comparaison entre les deux fonctions de pondération TF-IDF et LTC ... 112
Figure 4.5 - Variation du paramètre de Lissage 𝜆 dans le score de modèles de langue basé sur
les termes ... 118
Figure 4.6 - L’effet de la variation du nombre de requêtes recommandées ... 119
Figure 4.7 - Comparaison des méthodes de recommandation de requêtes TQRA, ML et MH ... 120
Figure 5.1 - Les sessions de requêtes, les termes de requêtes et les termes de documents .... 124
Figure 5.2 - Les corrélations probabilistes entre les termes des requêtes et les termes des documents ... 125
Figure 5.3 - Méthode probabiliste d’expansion de requêtes basée sur l’Algorithme de Recommandation de requêtes ... 126
Figure 5.4 - Variation du nombre de termes d’expansion pour les requêtes courtes ... 129
Figure 5.5 - Variation du nombre de termes d’expansion pour les requêtes longues ... 129
Figure 5.6 - L’effet du nombre de documents utilisés sur le processus d’expansion pour les requêtes courtes ... 130
Figure 5.7 - L’effet du nombre de documents utilisés sur le processus d’expansion pour les requêtes longues ... 131
Figure 5.8 - Variation du nombre de requêtes recommandées utilisées pour l’expansion des requêtes courtes ... 131
Figure 5.9 - Variation du nombre de requêtes recommandées utilisées pour l’expansion des requêtes longues ... 132
Figure 5.10 - Comparaison entre la méthode d’expansion probabiliste (PQEM) et l’algorithme de Rocchio pour les requêtes courtes ... 133
Figure 5.11 - Comparaison entre la méthode d’expansion probabiliste (PQEM) et l’algorithme de Rocchio pour les requêtes longues ... 133
Figure 5.12 - Structure générale de l’approche d’expansion proposée utilisant l’Analyse Sémantique Latente ... 136
Figure 5.13 - Variation du nombre de requêtes recommandées utilisées dans LSARQ ... 138
Figure 5.14 - Variation du nombre de termes d’expansion dans LSARQ ... 139
Figure 5.15 - Comparaison de différentes méthodes d’expansion ... 140
Figure 5.16 - Comparaison de la performance par la F-mesure ... 142
Figure 5.17 - Variation du nombre de documents utilisés pour la construction du contexte pour les trois techniques d’expansion QRALSA, LMLSA et MHLSA ... 144
Figure 5.18 - Variation du nombre de termes utilisés pour l’expansion des requêtes courtes par QRALSA, LMLSA et MHLSA ... 145
Figure 5.19 - Variation du nombre de requêtes recommandées utilisées pour l’expansion des requêtes courtes par la méthode QRALSA sur la base de requêtes étendues initialement par WordNet ... 148
Figure A.1 - Répartition des pages en bon Hubs, bonnes autorités et pages indépendantes .. 164 Figure A.2 - Opérateurs de mise à jour des potentiels Hub (yp) et Autorité (xp) ... 165
Introduction générale
Contexte et problématique
Le Web est un immense espace de lecture-écriture d'information où de nombreux éléments tels que des documents, des images ou autres supports multimédias peuvent être consultés. Dans ce contexte, plusieurs technologies ont été mises au point pour aider les utilisateurs à rechercher les informations sur le Web, et les plus utilisées sont les systèmes de recherche d’information (SRI) « moteurs de recherche ». Les utilisateurs interrogent, au moyen d’une requête, une base de documents numériques et le SRI leur renvoie une liste de documents susceptibles de répondre à leur besoin. La taille énorme du Web et l'imprécision des termes les plus couramment utilisés pour formuler des requêtes posent encore un problème énorme pour atteindre parfaitement cet objectif.
Avec l’élargissement de l’accessibilité à l’Internet, le volume de données disponibles en ligne à faible coût, et le nombre d’utilisateurs des sites web ont augmenté de façon spectaculaire. Au cours de ces dernières années, cette croissance excessive d’information, ainsi que le manque d’organisation des ressources s’y rapportant sur le World Wide Web ont rendu difficile la tâche des utilisateurs du web pour accéder à l’information dont ils ont besoin. Surtout, que les requêtes ayant des termes ambigus peuvent récupérer des documents qui ne correspondent pas au domaine de recherche de l’utilisateur et peuvent induire ce dernier en erreur s’il n’a pas des informations précises de ce qu’il cherche et qu’il n’est pas expert du domaine.
Dans un environnement ayant une telle prolifération de ressources, l’accès à une information pertinente devient un défi pour la Recherche d’Information (RI) classique, qui ne propose en réponse qu’une liste massive de documents estimés pertinents indépendamment du contexte de recherche de l’utilisateur, où la sélection de l’information consiste à considérer que tout document contenant les mots de la requête (quel que soit leur ordre) est potentiellement pertinent.
Plus le volume des ressources disponibles est important, plus la liste des résultats retournés par le système de RI est plus importante. Ce qui entraine une surcharge informationnelle face à l’utilisateur, qui le rend incapable de distinguer ce qui est pertinent de ce qui ne l’est pas.
Ajoutant à cela que le vocabulaire varie considérablement d’un auteur à un autre, sans oublier que les utilisateurs ont généralement tendance à ne pas utiliser les mêmes termes figurant dans les documents comme termes de recherche. Il est aussi généralement observé que les utilisateurs du web soumettent des requêtes très courtes et/ou ambigües aux moteurs de recherche et que la longueur moyenne de ces requêtes est de moins de deux mots (Wen et al. 2001), ce qui accentue la problématique de l’expressivité du besoin en information. Les requêtes courtes n'ont généralement pas les mots suffisants pour couvrir les termes de recherche utiles et donc affectent négativement les performances de la recherche.
Cela fait de la recherche d’information un domaine en développement continu afin d’améliorer les services fournis aux utilisateurs. En général, pour dépasser le problème des requêtes courtes ou bien la discordance des termes entre la requête de l’utilisateur et les documents récupérés, des techniques de « Reformulation de requêtes » sont proposées, où la RI est alors considérée comme une suite de formulations et de reformulations de requêtes jusqu’à la satisfaction du besoin d’information de l’utilisateur. De plus, des approches se basant sur les relations sémantiques entre les termes de la requête et les termes des documents, sont également utilisées et permettent par la suite d’enrichir la requête de l’utilisateur par les termes de documents.
Une autre faiblesse constatée dans le domaine, réside dans le fait que la plupart des moteurs de recherche permettent aux utilisateurs de spécifier des requêtes sous forme d’une liste de mots-clés et se fondent uniquement sur ces mots clés contenus dans les requêtes pour chercher et classer les documents pertinents, et ce malgré le fait que ces mots clés ne sont pas toujours de bons descripteurs du contenu que l’utilisateur cherche.
L’apparition de nouveaux domaines de recherche d’information tels que : la RI géographique, la RI sociale (les agendas personnels, réseaux sociaux) et bien d’autres application (la RI médicale, etc.), rend le contexte de recherche de l’utilisateur, une source d’information de prime importance pour l’amélioration de la précision de la recherche. En effet, ces nouveaux environnements de recherche imposent des contraintes spécifiques de recherche, qui peuvent être : géographiques (liées à la localisation de l’utilisateur), temporelles (liées à l’instant de soumission de la requête) ou matérielles (liées aux dispositifs d’accès à l’information dont dispose l’utilisateur), etc.
Pour faire face à ces problèmes et pouvoir adapter les résultats de la recherche aux besoins spécifiques d’un utilisateur donné dans un contexte particulier, les travaux en RI contextuelle ont vu le jour, pour mettre respectivement en avant les aspects liés au contexte, aux échanges d’information entre l’utilisateur, son environnement et le système. Et, proposer l’adaptation de la recherche à l’utilisateur, aux ressources, au système ou à l’environnement.
La Recherche d’Information Contextuelle (RIC) permet d’intégrer le contexte dans l’une ou toutes les étapes du processus de RI. En reformulation de requête, cela se présente par l’enrichissement des requêtes des utilisateurs par du contexte supplémentaire. Ce contexte peut être extrait de différentes ressources dont les principales sont le profil utilisateur ou bien les journaux de requêtes, et peut être exploité dans les différentes étapes du processus de RI. Toutefois, un seul profil utilisateur peut regrouper une grande variété de domaines et d’intérêts, qui ne sont pas toujours pertinents pour une requête particulière (Bai et al. 2007). Ce qui nous a poussé à se focaliser sur l’exploitation des journaux de requêtes qui représentent une mine d’informations pertinentes et diversifiées permettant de satisfaire le besoin d’un utilisateur à base de l’expérience de recherche des autres utilisateurs.
Contributions
Les travaux présentés dans ce mémoire de thèse, se situent précisément dans le domaine de la recherche d’information contextuelle. Afin d’assurer une continuité
dans l’enchaînement de nos contributions et procurer de cette façon une meilleure couverture des objectifs de cette thèse, nous avons réparti les approches que nous avons proposées sur deux grands axes de la RIC :
- Un premier axe relatif à l’extraction du contexte par la recherche des requêtes passées les plus similaires à la nouvelle requête que nous considérons comme le contexte autour de la requête en combinaison avec leurs documents les mieux classés. Cet axe regroupe trois contributions que nous avons testées et comparées (El Ghali et al. 2015-a) :
La première contribution se présente par un algorithme de recommandation se basant sur le modèle vectoriel et consiste en un calcul de similarité cosinus entre les vecteurs de requêtes, où chaque requête est représentée par deux vecteurs pondérés, l’un à base de la présence où absence des termes et l’autre à base de la pertinence ou non des documents à la requête.
La deuxième contribution consiste en une approche probabiliste qui modélise les requêtes à base des modèles de langue et calcule la probabilité de génération de la nouvelle requête par les requêtes passées des utilisateurs. Cette contribution se base également sur les deux représentations de la requête à base des termes et des documents.
La dernière contribution de recommandation proposée est une méthode hybride qui combine les deux premières contributions, en utilisant la représentation à base de termes dans la correspondance par modèles de langue, et la représentation à base de documents dans la similarité cosinus.
- Un deuxième axe concerne l’expansion des requêtes afin de les enrichir par des termes complémentaires, qui modélisent le contexte autour de la requête à étendre, mais également permettent de minimiser la discordance entre les termes des requêtes et les termes des documents.
Notre première contribution d’expansion (El Ghali et al. 2013), exploite le contexte construit par la première contribution de recommandation et calcule les corrélations probabilistes entre la nouvelle requête de l’utilisateur et les termes candidat d’expansion d’une façon assez précise. Cette méthode est fondée sur la théorie des probabilités, ce qui fait sa force, sa flexibilité et sa haute performance.
La deuxième approche d’expansion de requêtes proposée (El Ghali et El Qadi 2016), étend les requêtes initialement par l’ajout des synonymes des termes de ces dernières, extraits à partir de WordNet. Puis, se base sur le contexte construit par modèles de langue et utilise la méthode d’Analyse Sémantique Latente (Latent Semantic Analyses : LSA) afin de sélectionner les termes d’expansion. Cette méthode permet de surmonter les problèmes de correspondance lexicale par la récupération des informations sur la base d'une signification conceptuelle au lieu de considérer les mots individuels. Trois autres approches d’expansion par LSA se basant sur l’extraction du
contexte par les trois contributions de recommandation ont également été testées et comparées à la deuxième approche d’expansion dans la communication indexée (El Ghali et al. 2015-b).
Un ensemble d’expérimentations a été réalisé durant cette thèse. L’objectif de ces expérimentations était double : d’abord, spécifier les paramètres adéquats et les combinaisons adéquates pour les différentes approches proposées, puis comparer, tester et valider chacune de nos contributions.
Organisation du mémoire
Ce mémoire est organisé en cinq chapitres : le premier présente le contexte dans lequel se situent nos travaux, c’est-à-dire la recherche d’information et plus précisément la RI contextuelle ; le second et troisième forment un état de l’art sur les méthodes existantes de recommandation et d’expansion de requêtes ; tandis que les deux derniers chapitres décrivent nos contributions en recommandation et expansion de requêtes.
L’objectif du chapitre 1 « La recherche d’information », est de présenter le domaine de la RI en détails, en exposant les étapes du processus de recherche, les modèles sur lesquels se base la RI et ses outils. Puis, de porter la lumière sur l’émergence de la RI contextuelle par la définition de la notion du contexte, ses ressources, les phases de son intégration et l’architecture générale d’un système de recherche d’information contextuel. Enfin, de décrire la notion de pertinence, les collections de test ainsi que les mesures d’évaluation les plus importantes, dans une partie qui concerne l’évaluation des SRI.
Le chapitre 2 « Les méthodes de Recommandation de requêtes », s’intéresse aux approches de recommandation de requêtes web proposées dans la littérature. A cet effet, nous avons classifié ces techniques en trois catégories : les unes basées sur le contenu uniquement et qui représentent la catégorie la plus rare ; les autres basées sur le contexte uniquement dont l’objectif diffère des approches de segmentation (Clustering) des requêtes, celles qui améliorent le rang de classement des documents pertinents, à celles qui visent à prédire les requêtes séquentielles ; la troisième catégorie regroupe les techniques basées sur le contenu et le contexte qui varient selon la notion du contexte exploitée.
Le chapitre 3 « Les méthodes d’expansion de requêtes » traite des approches d’expansion de requêtes de la littérature, où nous avons introduit premièrement les sources des termes d’expansion. Les techniques d’expansion sont également divisées en trois catégories : la première globale, utilise les sources de données lexicales, sémantiques où thésaurus et englobe tout le corpus de documents dans le processus de sélection des termes d’expansion. La deuxième est l’expansion locale qui se divise à son tour en deux classes, les techniques de réinjection de pertinence (RP) qui exploitent le feedback de l’utilisateur et les techniques de pseudo-RP qui considèrent les documents les mieux classés comme des documents pertinents. La troisième catégorie concerne l’expansion de requêtes basée sur les journaux de requêtes, qui se positionne dans le domaine de la RIC et englobe nos contributions.
Le chapitre 4 « Contributions de recommandation de requêtes » présente trois de nos contributions, dont le but est double : premièrement des approches de recommandation
de requêtes performantes et exploitables dans le processus de RI, deuxièmement des méthodes de construction du contexte autour de la requête afin de l’exploiter par la suite dans un processus d’expansion de requêtes. Ces approches sont testées avec variations de leurs paramètres et comparées entre elles.
Le chapitre 5 « Contributions d’expansion de requêtes » décrit nos contributions dans le domaine d’expansion de requêtes, qui se basent toutes sur l’une des méthodes de construction du contexte et ressoudent le problème de discordance entre les termes des requêtes et les termes des documents, en exploitant le contexte constitué des documents les mieux classés de la requête à étendre, ses requêtes les plus recommandées et leurs documents les mieux classés. Ce qui permet de calculer les corrélations entre l’espace des termes des requêtes et celui des termes des documents à travers les liens de pertinence entre les documents et les requêtes passées.
Une conclusion générale qui dresse le bilan de nos travaux est présentée à la fin de ce mémoire, elle résume les points essentiels de cette thèse et présente quelques perspectives de recherche suggérées dans la contextualisation de la RI tout en restant dans le cadre de l’amélioration de la performance des SRI.
Partie I
Chapitre 1 – Recherche
d’Information et Contexte
1.Introduction... 10 2. La Recherche d’Information : processus, techniques et outils ... 10
2.1. Le processus de Recherche d’Information ... 11 2.1.1 L’expression du besoin en information : l’interrogation du corpus de documents ... 12 2.1.2 Le processus d’indexation ... 13 2.1.3 L’appariement document-requête ... 17 2.1.4 La reformulation de la requête ... 19 2.2. Les modèles-piliers de la Recherche d’Information ... 20 2.2.1 Modèles ensemblistes ... 21 2.2.2 Modèles algébriques ... 23 2.2.3 Modèles probabilistes ... 26 2.3. Les outils de Recherche d’Information ... 29
3. Intégration du contexte en Recherche d’Information ... 33
3.1. Définition du contexte ... 34 3.2. Phases d’intégration du contexte ... 37 3.3. Architecture d’un Système de Recherche d’Information Contextuel ... 39
4. Evaluation des systèmes de Recherche d’Information ... 40
4.1. Notion de pertinence ... 41 4.2. Collection de test ... 42 4.3. Mesures d’évaluation ... 46
1. Introduction :
La recherche d’information (RI) est une discipline de recherche qui intègre des modèles et des techniques dont la finalité est de localiser et délivrer l’information pertinente à un utilisateur selon son besoin en information. Le défi dans ce domaine est de pouvoir trouver, parmi le volume important de documents disponibles, ceux qui correspondent le mieux aux attentes de l’utilisateur. L’opérationnalisation de la RI est réalisée par un ensemble de programmes informatiques appelés « Systèmes de Recherche d’Information » (SRI). Ces systèmes ont pour but de mettre en correspondance les besoins des utilisateurs, exprimés sous forme de requêtes, avec l’information pertinente représentée par le contenu des documents web au moyen d’une fonction d’appariement (ou de comparaison) document-requête.
L’essor du web a mis la RI face à de nouveaux défis d’accès à l’information, il s’agit cette fois de retrouver l’information pertinente aux requêtes dans un espace diversifié et de taille considérable. La limite majeure de la plupart des modèles de recherche classiques réside en partie dans le fait qu’ils sont basés sur une approche généraliste qui considère que le besoin en information d’un utilisateur est complétement représenté par sa requête. Par conséquent, ils délivrent des résultats qui ne tiennent en compte que des critères de sélection par contenu et de la disponibilité des sources d’information. Ces difficultés ont donné naissance à une nouvelle discipline appelée la Recherche d’Information Contextuelle (RIC). Les techniques s’apparentant à la RIC se base sur différentes notions du contexte afin d’améliorer le processus de RI.
Ce chapitre est organisé en trois grandes parties : la première présente les concepts de base de la RI, décrit le processus de RI et les différents modèles qui y ont été proposés. La deuxième partie, présente la RIC et les notions de contextes utilisables par les SRI. La troisième partie sera consacrée aux techniques d’évaluation des SRI.
2. La Recherche d’Information : processus, techniques et outils
La recherche d'information (Bouramoul 2011) est un domaine historiquement lié aux sciences de l'information et à la bibliothéconomie, qui ont toujours eu comme souci lefait d’établir des représentations des documents dans le but d'en récupérer des informations à travers la construction d’index. L’informatique a permis le développement d’outils pour traiter l’information et établir la représentation automatique des documents au moment de leur indexation, ainsi que pour rechercher l’information.
Par conséquent, la RI (Sauvagnat 2005) est également définie comme la branche de l’informatique qui s’intéresse à l’acquisition, l’organisation, le stockage, la recherche et la distribution de l’information. Dans cette section nous abordons le processus général de la RI, puis nous décrivons ses principaux modèles et nous présentons les outils de RI sur le web.
2.1. Le processus de Recherche d’Information
Le processus de Recherche d’Information a pour but de mettre en relation des informations disponibles sur le web d’une part, et les besoins de l’utilisateur d’autre part. Ces besoins sont traduits de façon structurée par l’utilisateur sous forme de requête. Par contre, le SRI manipule un corpus de documents qu’il transpose à l’aide d’une fonction d’indexation en un corpus indexé (structuré). Ce corpus lui permet de résoudre les requêtes traduites à partir des besoins des utilisateurs.
La mise en relation des besoins des utilisateurs et des informations contenues dans le corpus est effectuée par le SRI, dans le but de retourner à l’utilisateur le maximum de documents pertinents et le minimum de documents non-pertinents par rapport à son besoin. La notion de pertinence est fortement subjective (dépendante de l’utilisateur), ce qui la rend difficile à automatiser. Le but des SRI est alors de faire correspondre au mieux la pertinence système avec la pertinence utilisateur.
Le processus de RI, couramment appelée Processus en U de Recherche d’Information, consiste en trois phases principales (comme l’illustre la figure 1.1) : L’indexation des documents et des requêtes, l’appariement document-requête et la modification des documents et/ou requête qui se présente en général sous forme d’une reformulation de la requête.
Fig. 1.1 Processus en U de Recherche d’Information
2.1.1. L’expression du besoin en information : l’interrogation du corpus de documents
L’utilisateur est à la fois la source et le déclencheur d’une recherche d’information, ainsi que le validateur du résultat de cette recherche. Mieux comprendre les mécanismes cognitifs de l’utilisateur, en particulier son mécanisme de satisfaction, permettrait d’améliorer les performances d’un SRI. Toutefois, il ne faut pas perdre de vue que l’utilisateur est plus concerné par retrouver l’information sur le sujet qui l’intéresse plutôt que par retrouver des données qui satisfont une requête donnée, le plus souvent mal formulée.
Le besoin en information de l’utilisateur est l’expression mentale de ce qu’il recherche. Ce besoin est représenté à travers une requête, qui sera traitée par le SRI. Il s’agit en général d’une liste de mots-clés, qui peut être exprimée en langage naturel. Ces mots-clés peuvent éventuellement être reliés entre eux par des opérateurs booléens (ET, OU, NON) et/ou par des variables linguistiques (comme (plus) récent, (plus) important, ...). Ces mots-clés peuvent aussi être organisés sous forme d’expressions, mais en général avec un nombre maximal de mots accepté.
Toutefois la requête de l’utilisateur pourrait également être graphique ou bien une requête en texte libre, ce qui permet à l’utilisateur d’exprimer son besoin de façon plus naturelle qu’avec une suite de mots-clés. Ces requêtes offrent surtout la possibilité d’utiliser un document complet ou une image en tant que requête (ce qui reviendrait à dire : trouve-moi tous les documents semblables à celui-ci).
Pour Kleinberg (1999), d’un point de vue sémantique, il existe trois formes différentes de requêtes :
– Les requêtes spécifiques, du type ”Quelle est la dernière version du JDK ?” – Les requêtes larges, comme par exemple : ”trouve des informations concernant le langage de programmation Java”.
– Les requêtes par similarité, du type ”trouve les pages similaires à java.sun.com”.
2.1.2. Le processus d’indexation
A l’intersection de la problématique de l’existence d’une source d’information (le document) et celle du besoin d’accès à cette information, se trouve l’indexation (Badjo et Berthier 2003), qui consiste à repérer dans un document (ou une requête), certain mots ou expressions particulièrement significatifs (appelés termes ou concepts) dans un contexte donné. L’indexation peut être :
– Manuelle : chaque document est analysé par un spécialiste du domaine ou par un documentaliste ;
– Semi-automatique : le choix final revient au spécialiste ou au documentaliste qui intervient souvent pour choisir d’autres termes significatifs ;
– Automatique : le processus d’indexation est entièrement informatisé,
L’indexation manuelle permet d’assurer une meilleure pertinence des réponses retournées par le SRI. Toutefois, elle présente plusieurs inconvénients : deux indexeurs différents (personnes physiques) peuvent présenter des termes différents pour caractériser un même document, et un indexeur à deux moments différents peut représenter le même concept par deux termes distincts. De plus, le temps nécessaire à la réalisation de ce type d’indexation est très important.
Dans le cas d’une indexation semi-automatique, les indexeurs utilisent un thésaurus (une base terminologique), qui est une liste organisée de mots-clés décrivant des concepts, obéissant à des règles terminologiques propres et reliés entre eux par des relations sémantiques.
Enfin, L’indexation automatique, que nous présentant en détail dans ce qui suit, est une technique informatique qui est naît de l’explosion documentaire que connaît le monde ces dernières décennies, et qui permet de repérer des éléments significatifs dans un fichier informatique. Son but essentiel est de minimiser les coûts de recherche, par la résolution des problèmes du temps de traitement de l’information et par la suite du temps d’accès aux informations pertinentes au sein d’un grand document.
L’indexation automatique se définie comme un ensemble de traitements automatisés sur un document ou une requête. Ses différentes étapes sont : l’extraction automatique des mots, l’élimination des mots vides, la lemmatisation (radicalisation ou normalisation) des mots, le repérage de groupes de mots, la pondération des mots et enfin la création de l’index.
2.1.2.1 L’analyse lexicale
L’analyse lexicale est l’étape qui permet de convertir le texte d’un document en un ensemble de termes. Un terme est une unité ou entité lexicale, appelée aussi Token en anglais. L’analyseur lexical permet de détecter les espaces de séparation des mots, les chiffres, les ponctuations, etc… et les supprimer.
2.1.2.2 L’élimination des mots vides
Un mot vide est un mot non significatif figurant dans un texte, un mot qui apparaît avec une fréquence semblable dans chacun des textes de la collection, donc un mot qui ne permet pas de distinguer les textes les uns par rapport aux autres.
Un mot vide (HLAOUA 2007) peut être un pronom personnel, une préposition ou un autre mot grammatical, comme il peut être, un mot athématique, c’est-à-dire qu’il peut se trouver dans n’importe quel document, car il expose le sujet mais ne le traite pas (par exemple : contenir, appartenir…).
L’élimination de ces mots non significatifs est une étape fondamentale dans l’indexation, pour laquelle nous distinguons deux techniques :
L’utilisation d’une liste préétablie de mots vides (aussi appelée anti-dictionnaire, Stop-List en anglais), et la suppression de tous les mots du document figurant dans cette liste (TEBRI 2004).
L’élimination des mots dépassant un certain seuil, en ce qui concerne le nombre d’occurrence dans la collection.
2.1.2.3 La lemmatisation
Un mot donné peut avoir différentes formes dans un texte, mais leur sens reste le même ou très similaire. Par exemple on peut citer économie, économiquement, économétrie, économétrique, etc. Il n’est pas forcément nécessaire d’indexer tous ces mots alors qu’un seul suffirait à représenter le concept signifié. Pour résoudre le problème, une substitution des termes par leur racine, ou lemme, est utilisée.
Les algorithmes de lemmatisation (en anglais Stemming) visent à normaliser tous les mots significatifs en les réduisant à leurs formes tiges ou racines.
Ainsi, les principaux termes d'une requête ou d'un document sont représentés par des lemmes plutôt que par les mots d'origine. Cela signifie que :
- Les différentes variantes d'un terme peuvent être confondues à une forme représentante unique.
- La taille du dictionnaire est donc réduite. Tel que la taille du dictionnaire est, le nombre de termes distincts nécessaires pour représenter un ensemble de documents.
La racine d’un terme est obtenue par une méthode spécifique selon le type de langue du texte qui le contient :
- L’algorithme de Porter (Porter 1980) pour les documents en anglais, - La troncature pour les autres langues (français, allemand, etc.).
La troncature est un signe qui remplace une ou plusieurs lettres d'un mot. En général, elle est représentée par l'astérisque « * », et peut être droite (mot*), gauche (*mot) ou interne (m*t). Toutefois, dans le cas d’une troncature d’un seul caractère, elle est représentée par un point d’interrogation « ? ». Selon les auteurs, la troncature est appelée « troncation », « joker », « wildcard » ou « masque ».
Exemple :
Le mot « grecque » peut être tronqué ainsi : grec*. En faisant cette troncature, le moteur de recherche recherchera les mots « grec, grecs, grecque et grecques, grécité, latin, latine, latins et latines, et romain, gréco-romains, gréco-romaines ».
2.1.2.4 La pondération des termes
La pondération des termes est une étape fondamentale dans la majorité des approches proposées en recherche d’information. Elle traduit l’importance des termes en mesurant leurs poids dans un document ou une requête. Cette importance est souvent calculée sur la base d’aspects statistiques (ou parfois linguistiques). L’objectif est de trouver les termes qui représentent le mieux le contenu d’un document.
Parmi les nombreuses formules de pondération définies dans le domaine, la mesure TF-IDF est de loin la plus connue et la plus utilisée. Ainsi que sa version normalisée appelée LTC.
- TF-IDF:
La formule de pondération Tf-Idf est construite par la combinaison de deux facteurs : - Un facteur de pondération locale (TF : Terme Frequency), qui quantifie la
représentativité locale d’un terme dans le document.
- Un second facteur, de pondération globale (IDF : Inverse Document Frequency), qui mesure la représentativité globale du terme vis-à-vis de la collection des documents, dont la formule est :
IDF(𝑡𝑖) = log(𝑁
Avec N est la taille de la collection et 𝑛𝑖 le nombre de document où apparaît le terme
ti.
La formule TF-IDF pour le calcul du poids d’un terme 𝑡𝑖 dans un document 𝑑𝑗 = [𝑟1𝑗, 𝑟2𝑗, … , 𝑟𝑖𝑗, … , 𝑟𝑚𝑗] est comme suite (Zahera 2010) :
𝑟𝑖𝑗 = 𝑡𝑓𝑖𝑗× 𝑖𝑑𝑓𝑖 = 𝑡𝑓𝑖𝑗 × log(𝑁
𝑛𝑖) (1.2)
Où, tfij est le nombre d’occurrence du terme 𝑡𝑖 dans le document 𝑑𝑗. - LTC :
L’approche de pondération LTC emploie également les deux facteurs de pondération locale et globale, mais avec une formule différente (Aas et Eikvil 1999) :
𝑟𝑖𝑗 =
log(𝑡𝑓𝑖𝑗+1)×𝑖𝑑𝑓𝑖
√∑𝑚𝑘=1[log(𝑡𝑓𝑖𝑘+1)×𝑖𝑑𝑓𝑖]
(1.3)
En utilisant le logarithme du facteur de pondération locale, qui représente la fréquence d’apparition d’un terme dans le document, la formule présentée par l’équation (1.3) réduit les effets de grandes différences dans les fréquences.
2.1.3. L’appariement document-requête
Le processus de mise en correspondance ou d’appariement document-requête revient à mesurer un score, supposé représenter la pertinence d’un document vis-à-vis d’une requête, en calculant un score de correspondance entre la représentation de chaque document et celle de la requête. Ce score traduit un degré de pertinence système, que l’on essaye de rapprocher le plus possible du jugement de pertinence de l’utilisateur vis-à-vis du document. Cette valeur est calculée en utilisant une fonction ou une probabilité de similarité appelée : RSV(q, d) (Retrieval Status Value), où q est une requête et d un document. Cette mesure tient compte des poids des termes calculés dans l’étape précédente du processus de recherche d’information.
La fonction de correspondance est très étroitement liée aux opérations d’indexation et de pondération des termes de la requête et des documents du corpus. Notons que d’une
façon générale, l’appariement document-requête et le modèle d’indexation permettent de caractériser et d’identifier un modèle de recherche d’information. Il existe un certain nombre de modèles théoriques, dans la littérature les plus connus étant le « Modèle Booléen », le « Modèle Vectoriel », et le « Modèle Probabiliste ». La description des modèles de recherche d’information fait l’objet de la sous-section suivante (Sous-section 2.2).
La fonction de similarité permet ensuite d’ordonner les documents retournés à l’utilisateur. La qualité de cet ordonnancement est primordiale du fait que l’utilisateur se contente généralement d’examiner les premiers documents renvoyés (les 10 ou 20 premiers). Si les documents recherchés ne sont pas présents dans cette tranche, l’utilisateur considèrera la recherche comme insatisfaisante. Nous présentons dans ce qui suit, les expressions de similarités les plus connues et communément utilisées.
- SIMILARITÉ DE COSINE :
La similarité cosinus ou Cosine est une mesure qui permet de calculer la similarité entre deux vecteurs en déterminant l’angle entre eux et dont les valeurs sont contenues dans l’interval [0,1].
Deux objets (la requête 𝑞𝑖 et le document 𝑑𝑗) sont similaires si leurs vecteurs sont
confondus (Slimani et al. 2007). Sinon, les deux objets ne sont pas similaires et leurs vecteurs forment un angle (𝑞⃗𝑖, 𝑑⃗𝑗), dont le cosinus représente la valeur de la similarité. L’expression de similarité à base de cosinus est :
𝑆𝑖𝑚𝑐(𝑞𝑖, 𝑑𝑗) = | cos(𝑞⃗𝑖, 𝑑⃗𝑗) | = |𝑞⃗⃗𝑖×𝑑⃗𝑗|
||𝑞⃗⃗𝑖||×||𝑑⃗𝑗|| (1.4)
Avec ‖𝑞⃗𝑖‖ = √∑𝑚 |𝑟𝑘𝑖|
𝑘=1 .
- SIMILARITÉ DE DICE :
La similarité de Dice appelée également « coefficient de Dice » est définie par le nombre des termes communs entre la requête et le document multiplié par 2, le tout sur
la somme des cardinalités des ensembles 𝑄𝑖 et 𝐷𝑖. Tel que 𝑄𝑖 et 𝐷𝑗 sont les ensembles
des termes de la requête 𝑄𝑖 et du document 𝐷𝑗, respectivement.
La mesure de Dice qui permet d’évaluer la similarité entre les ensembles également, contrairement à la similarité à base de cosinus qui utilise la représentation vectorielle uniquement, est donc définie par la formule suivante :
𝑆𝑖𝑚𝑑(𝑞𝑖, 𝑑𝑗) = 2|𝑄𝑖∩𝐷𝑗|
|𝑄𝑖|+|𝐷𝑗| =
2|𝑞⃗⃗𝑖×𝑑⃗𝑗|
||𝑞⃗⃗𝑖||+||𝑑⃗𝑗|| (1.5)
- SIMILARITÉ DE JACCARD :
La mesure de similarité de Jaccard, nommée « indice de Jaccard » ou « coefficient de Jaccard », permet aussi d’évaluer la similarité entre les ensembles. Elle est définie par le rapport entre la cardinalité de l’intersection des ensembles 𝑄𝑖 et 𝐷𝑗, et la cardinalité de l’union des mêmes ensembles, qui est définie par le nombre total des termes de la requête 𝑞𝑖 et du document 𝑑𝑗 moins le nombre des termes commun entre eux.
L’expression de cette mesure est comme suite :
𝑆𝑖𝑚𝑗(𝑞𝑖, 𝑑𝑗) =|𝑄𝑖∩𝐷𝑗| |𝑄𝑖∪𝐷𝑗| = | 𝑞⃗⃗𝑖×𝑑⃗𝑗 𝑞⃗⃗𝑖2+𝑑⃗𝑗 2 −𝑞⃗⃗𝑖×𝑑⃗𝑗 | (1.6) 2.1.4. La reformulation de la requête
A cause du volume croissant des bases documentaires, retrouver des informations pertinentes en utilisant la requête initiale de l’utilisateur est aujourd’hui quasi-impossible. Il est souvent difficile, pour l’utilisateur, de formuler son besoin exact en information. Par conséquent, la plupart du temps les résultats que lui fournit le SRI ne lui conviennent pas. Afin de faire correspondre au mieux la pertinence utilisateur et la pertinence du système, une étape de reformulation de la requête est souvent nécessaire. De ce fait, plusieurs techniques ont été proposées pour améliorer les performances des SRI face aux nouveaux défis présentés. La requête initiale est traitée comme un essai pour retrouver de l’information. Les documents initialement retrouvés sont examinés et une formulation améliorée de la requête est construite, dans l’espoir de retourner plus de documents pertinents.
La reformulation peut se faire par une expansion de requêtes, en enrichissant la requête par l’ajout de nouveaux termes extraits par différentes méthodes de sélection de termes possible. De plus, la reformulation d’une requête peut être réalisée par une recommandation des requêtes passées les plus proches de la requête initiale. La description de ces deux catégories de reformulation en détails fait l’objet du deuxième et du troisième chapitre de cette thèse.
2.2. Les modèles-piliers de la Recherche d’Information
Un système de recherche d’information repose sur la définition d’un modèle de recherche d’information qui effectue les deux transpositions des documents et des requêtes vers des représentations structurées et qui fait correspondre les documents aux requêtes lors de l’appariement document-requête.
Il existe un grand nombre de modèles théoriques dans la littérature, dont les plus connus et utilisés sont trois modèles dit classiques : Le « Modèle Booléen », le « Modèle Vectoriel » et le « Modèle Probabiliste ». Dans le modèle booléen, les requêtes sont représentées sous forme de termes reliés par les opérateurs booléens (ET, OU, NON, ...). Le modèle vectoriel de son côté considère les documents et les requêtes comme des vecteurs pondérés, chaque élément du vecteur représentant le poids d’un terme dans la requête ou le document. Tandis que le modèle probabiliste tente d’estimer la probabilité qu’un document donné soit pertinent pour une requête donnée (Kompaoré 2008).
Dans ce qui suit nous utilisons les notations suivante : RSV(q,d) est le score d’appariement entre la requête q et le document d. Soit T est l’ensemble de tous les termes de l’index avec T= {t1, …, tk}, où ti un terme de l’index. Soit dj un document et wij le poids associé au couple (ti, dj). Ce poids quantifie l’importance du terme dans le document. Généralement, à chaque document dj est associé un vecteur pondéré ou non pondéré des termes de l’index représenté par 𝑑⃗⃗⃗⃗ = {𝑤𝑗 1𝑗, … , 𝑤𝑘𝑗}.
2.2.1. Modèles ensemblistes
Dans ces modèles, qui trouvent leurs fondements théoriques dans la théorie des ensembles, des opérateurs logiques (Et, OU et NON) séparent les termes de la requête et permettent d’effectuer des opérations d’union, d’intersection et de différence entre les ensembles de résultats associés à chaque terme. Leur représentant le plus connu est le modèle booléen pur (Boolean Model), et on distingue également : le modèle booléen étendu (Extended Boolean Model) et le modèle flou (Fuzzy Set Model).
2.2.1.1. Le modèle booléen
Le modèle booléen (Salton 1971-a) est le premier qui s’est imposé dans le domaine de la recherche d’information. Il est basé sur la théorie des ensembles classiques et l’algèbre de Bool. Chaque document est représenté, dans ce modèle, par une conjonction logique des termes non pondérés qui constitue l’index du document. En effet, il considère que les termes de l’index sont soit présents ou bien absents d’un document. En conséquence, les poids des termes dans l’index sont binaires (wij ∈{0, 1}).
Une requête q est, elle aussi, composée de termes liés par les trois connecteurs logiques ET, OU et NON. La fonction de correspondance vérifie alors si l’index de chaque document d implique l’expression logique de la requête q (Ressad-Bouidghaghen 2011).
La similarité entre un document et une requête est définie par :
𝑅𝑆𝑉(𝑞, 𝑑) = {1sidappartientàl’ensembledécritparlarequête
0sinon (1.7) Ainsi, ce modèle considère que chaque document est soit pertinent soit non-pertinent. Il n’y a pas de notion de réponse partielle à la requête de l’utilisateur. Considérons, par exemple, la requête « modèle ET Recherche ET information ET classique ». Un document contenant les trois termes modèle, recherche et information, ne sera pas pertinent pour cette requête.