Thèse
Présentée en vue de l’obtention du diplôme de
Doctorat 3
èmecycle
Intitulée
Domaine : Mathématiques et Informatique
Filière :
Informatique
Spécialité : STIC (Sciences et Technologies de l’Information et de la
Communication)
par
M
elleZEMMAL Nawel
Devant le jury
Pr. Mokhtar Sellami Université Badji Mokhtar – Annaba Rapporteur
Dr. Nabiha Azizi Université Badji Mokhtar – Annaba Co-Rapporteur
Pr. Mohamed Tarek Khadir Université Badji Mokhtar – Annaba Président
Pr. Mahmoud Boufaida Université de Constantine 2 Examinateur
Pr. Labiba Souici-Meslati Université Badji Mokhtar – Annaba Examinateur
Pr. Hayet Farida Merouani Université Badji Mokhtar – Annaba Examinateur
Année 2017/2018
BADJI MOKHTAR UNIVERSITY – ANNABA
Faculté Sciences de l’Ingéniorat Département d’Informatique
راتخم يجاب ةعماج
–
ةبانع
Techniques d’apprentissage pour la sélection
d’attributs : Application à la reconnaissance
REMERCIEMENTS
Je remercie tout d’abord Dieu tout puissant de m’avoir donné le courage, la force et la patience d’achever ce modeste travail.
Je remercie mon directeur de thèse Pr SELLAMI Mokhtar pour avoir dirigé ma thèse avec beaucoup d’efforts et de patience. Je tiens aussi à remercier Dr AZIZI Nabiha pour son encadrement et ses précieux conseils, sa bonne humeur, sa collaboration ainsi que son aide dans la correction de ma thèse. Elle fût tout le temps attentive et disponible malgré ses nombreuses charges. Je remercie également Mr et Mme MAAYOUFI pour leur temps, leurs conseils et leur aide dans la relecture et la correction de cette thèse.
J’exprime toute ma reconnaissance au Pr KHADIR Mohamed Tarek pour avoir bien voulu accepter de présider le jury de cette thèse. Mes remerciements vont également à Pr MAROUANI Hayet Farida, Pr SOUICI-MESLATI Labiba et Pr BOUFAIDA Mahmoud pour l’honneur qu’ils me font d’être dans mon jury de thèse.
Je tiens à exprimer mes plus vifs remerciements à la personne la plus importante de ma vie. Il s’agit de ma merveilleuse, splendide et vertueuse maman qui m’a gratifié de son amour. Je lui adresse toute ma gratitude du fond du cœur. Enfin, les mots les plus simples étant les plus forts, j’adresse toute mon affection au reste de ma famille. Merci pour avoir fait de moi ce que je suis aujourd’hui.
Pour terminer, un grand merci aux personnes qui ont cru en moi et qui m’ont permis d’arriver au bout de cette thèse.
صخلم
مظن ،رضاحلا تقولا يف ةجلاعم ازرابو اماه اناكم لتحت ةيبطلا روصلا . ةجلاعم ةمظنلأ ةحلم ةجاح انيأر ،ةريخلأا ةنولآا يف هذه روصلا مهصيخشت يف ءاربخلا ةدعاسمل . نأ بجي يتلا تانايبلا نم ةريبك ةيمك امئاد كانه ،بوساحلا ةدعاسمب صيخشتلا ماظن يف فارشلإا تحت ملعتلا تاينقت قيبطت لجأ نم ةقيقد ةقيرطب ةفرعم اهلك نوكت . بابسلأ ،امئاد اققحم رايعملا اذه نوكي لا دق ،كلذ عمو لاب قلعتت ت ح نيعتي يتلا ةلكشملل ةصقانلا ةفرعملاب وأ ةفلك اهل ، لا عمتجم لواح دقو للآا ملعت ي للاخ نم ةيلمعلا تاجايتحلاا هذه ةجلاعم .فارشلإل عضاخلا هبش ملعتلا لاخدإ ل عومجم نم ةحجان ةيصيخشت ةيلمع قيقحت ة تانايبلا لا ةدع رابتعلاا نيعب ذخأي نأ بجي ةفرعم هبش ريياعم تانايبلا ةعيبطب قلعتت ، فدهلاو ةمدختسملا ملعتلا ةيمزراوخ دارملا .هقيقحت روصلل يئاقلتلا فينصتلا ىلع زكرت ةحورطلأا هذه لا ةمدقتملا يللآا ملعتلا جذامن مادختساب ةفرعم هبش . للاخ نم ،انحرتقا دقل ةديج ةحصب يدلا صخشلا نم ضيرملا صخشلا فينصتل ةيوق بيلاسأ ،نيتمهاسم . ةطلتخم ةيثارو ةيمزراوخ لولأا ماظنلا حرتقي يملا رايتخا جهنل ملعتلاو تاز لا تازيملا رايتخا ةيلمع للاخ تانايبلا صقن رابتعلاا نيعب ذخلأا عم ،فارشلإل عضاخلا هبش . ملعتلا تاينقت نأ انظحلا دقل لا ريبك صقن اهيدل ،تلااجملا نم ديدعلا يف اهتاحاجن نم مغرلا ىلعو ،فارشلإل ةعضاخلا هبش . ذا هذه ذخأت ةريخلأا ايبلا عيمج رابتعلاا نيع يف ريغلا تان ةفرعم لضفأ ةقد نمضت يتلا تانايبلل قبسم رايتخا نود . اننإف ،حضاو لحك هبشلا فنصملا ءادأ ةدايزل ةديدج ميهافم مادختساب ةيناثلا ةمهاسملا يف نومتهم لا ريغلا روصلا رايتخاو فارشلإل عضاخ ةفرعم بسنلأا طشنلا ملعتلا مادختساب . ةيمزراوخ عم طشنلا ملعتلا ةينقت دئاوف نيب عمجي حرتقملا ماظنلا برسلا رصانع لاثمتسا تانايبلا رايتخا لجأ نم ،ةهج نم ملعتلا ةلحرم للاخ طقف ةمهملا ةهج نمو ةمدختسملا تانايبلا ىلع ةيوديلا تاملاعلا عضو نم دح ىندأ ىلإ ليلقتلل ،ىرخأ ملعتلل . اذه ةحص نم ققحتلا مت دقو ماظنلا ادج ةعجشم اهيلع لوصحلا مت يتلا جئاتنلاو ؛ةيبطلا تانايبلا تاعومجم نم ديدعلا لامعتساب .تاملكلا
ةيحاتفملا
:
؛طشنلا ملعتلا ؛فارشلإل عضاخلا هبش ملعتلا ؛تازيملا رايتخا ؛بوساحلا ةدعاسمب صيخشتلا ماظن فرعتلا ىلع طامنلأا ؛ ةيمزراوخ ةيمزراوخ ؛ةيثارو صانع لاثمتسا برسلا ر .Résumé
Les systèmes d’analyse d’images médicales occupent aujourd’hui une place importante et tout-à-fait originale. Plus récemment, nous avons assisté à une forte demande de ces systèmes de traitements des images afin d’aider les praticiens dans leurs diagnostics.
Dans un système d’aide au diagnostic, on dispose presque toujours d’un grand volume de donnée devront être toutes étiquetées d’une manière précise afin d'appliquer les techniques d'apprentissage supervisé. Or, ce critère peut ne pas être toujours satisfait, pour des raisons de coût ou bien de connaissances imparfaites sur le problème à résoudre. La communauté de l’apprentissage automatique a tenté de répondre à ces besoins pratiques en introduisant l’apprentissage semi-supervisé.
La réalisation d’un processus décisionnel performant à partir d’un ensemble de données semi-étiquetées doit prendre en compte plusieurs considérations liées à la nature des données, à l’algorithme d’apprentissage utilisé et à l’objectif à produire. Les données d’apprentissage sont généralement plus ou moins pertinentes. Tout comme les données, les attributs sont plus ou moins pertinents et ils peuvent être redondants entre eux.
Cette thèse porte sur la classification automatique d’images semi-étiquetées en utilisant des paradigmes avancés de l'apprentissage automatique. Nous avons élaboré, à travers deux contributions, des méthodes performantes et robustes permettant de classer de façon satisfaisante les images de patients sains et pathologiques.
La première contribution propose une approche hybride de sélection des caractéristiques par les algorithmes génétiques et l’apprentissage semi-supervisé, en tenant en compte du manque de données étiquetées lors de la sélection des caractéristiques.
Nous avons observé que les techniques d’apprentissage semi-supervisé, malgré leurs succès dans plusieurs domaines, présentent un inconvénient majeur. Ce type d'apprentissage prend en considération toutes les données non étiquetées, sans sélection préalable de celles-ci, assurant une meilleure précision. À ce titre, nous nous sommes intéressés dans la deuxième contribution à l'introduction de nouveaux concepts pour augmenter la performance du classifieur semi-supervisé et sélectionner les images non étiquetées les plus appropriées en utilisant l'apprentissage actif comme une solution évidente. Le système proposé (dans le cadre de cette deuxième contribution) combine les avantages de cette technique d’apprentissage avec un algorithme d’optimisation par essaims particulaires afin de sélectionner seulement les données informatives durant la phase d’apprentissage d’une part, et de minimiser l’étiquetage manuel des données utilisées pour l’apprentissage d’autre part. Cette approche a été validée sur de nombreuses bases de données médicales et les résultats obtenus sont très encourageants.
Mots clefs. Systèmes d’aide au diagnostic ; Apprentissage semi-supervisé ; Apprentissage
Actif ; Reconnaissance des formes ; Sélection des Caractéristiques ; Algorithmes Génétiques ; Optimisation par Essaims Particulaires.
Abstract
Nowadays, medical image analysis systems occupy an important and prominent place. More recently, we have seen a strong need for these image processing systems to help experts in their diagnoses.
In a computer aided diagnosis system, there is always a large amount of data which must be all labeled in a precise manner in order to apply the supervised learning techniques. However, this criterion may not always be satisfied, for reasons of cost or imperfect knowledge of the problem to be solved. The statistical learning community has attempted to address these practical needs by introducing semi-supervised learning.
Achieving a successful diagnostic process from semi-labeled datasets must take into account several considerations related to the nature of the data, the learning algorithm used and the objective to be produced. The learning data is generally more or less relevant. Like data, attributes are more or less relevant and can be redundant.
This dissertation focusses on the automatic classification of semi-labeled images using the advanced machine learning paradigms. We have developed, through two contributions, powerful and robust methods for satisfactorily classifying images of healthy and pathological patients.
The first system proposes a hybrid genetic algorithm for features selection approach and semi-supervised learning, taking into account the deficit of labeled data during the feature selection process.
We have observed that semi-supervised learning techniques, and despite their successes in several fields, have a major drawback. This learning process takes into consideration all unlabeled data without prior selection of data which ensure better accuracy. as an obvious solution, we have interested in the second contribution to the use of new concepts to increase the performance of the semi-supervised classifier and to select the most appropriate unlabeled images using active learning. The proposed system combines the benefits of this learning technique with an evolutionary algorithm which is Particle Swarm Optimization in order to select the informative samples only during the learning phase on the one hand; on the other, to minimize the manual labeling of data used for learning. This approach has been validated on many medical datasets; the results obtained are very encouraging.
Keywords: Computer Aided Diagnosis; Features Selection; Semi-Supervised Learning;
Table des matières
Remerciements صخلم Résumé Abstract Introduction Générale 1Chapitre 01 Système d'aide à la décision médicale 7
1. Introduction 7
2. Imagerie médicale 8
2.1. La radiographie (rayons X ordinaires) 8
2.2. La mammographie 9
2.3. Imagerie par Résonance Magnétique 10
2.4. Rétinographies mydriatique (RM) et non mydriatique (RNM) 11 3. Les systèmes d’aide au diagnostic/ détection 13
3.1. Définition 13
3.2. Composition d’un système d’aide au diagnostic 14
3.2.1. Prétraitement 15
3.2.2. Segmentation 16
3.2.3. Extraction des caractéristiques 18
3.2.3.1. Les caractéristiques de couleur 18
3.2.3.2. Les caractéristiques de texture 19
3.2.3.2.1. La matrice de co-occurrence à niveau de gris 19 3.2.3.2.2. La matrice de longueurs de plages à niveau de gris 23
3.2.3.2.3. Les motifs binaires locaux 24
3.2.3.3. Les caractéristiques de forme 24
3.2.3.3.1. Les moments Centraux 25
3.2.3.3.2. Les moments de Hu 26
3.2.3.3.3. Les moments de Zernike 27
3.2.4. Sélection des caractéristiques 28
3.2.5. Classification 29
Chapitre 02 Techniques de sélection des caractéristiques 34
1. Introduction 34
2. Sélection supervisée des caractéristiques 35
2.1. Définition de la sélection supervisée des caractéristiques 35 2.2. Procédure de la sélection des caractéristiques 36
2.2.1. Génération 37
2.2.2. Evaluation 37
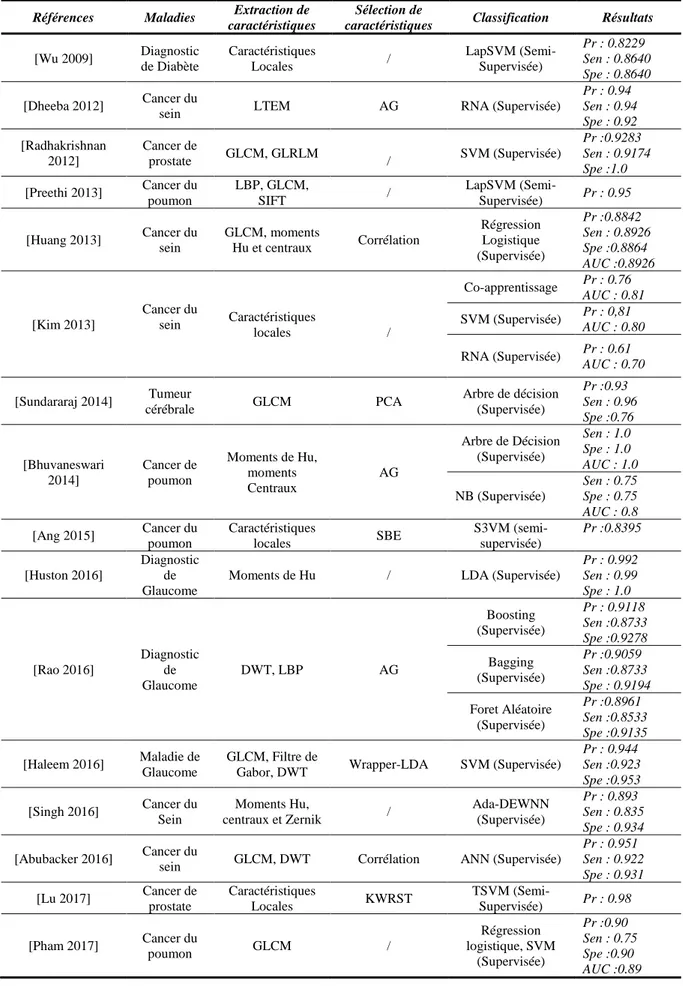
2.2.2.1. La méthode Filter 37
2.2.2.2. Les méthodes Wrapper 38
2.2.2.3. Les méthodes Embedded 39
2.2.3. Critère d’arrêt 40
2.2.4. Validation 40
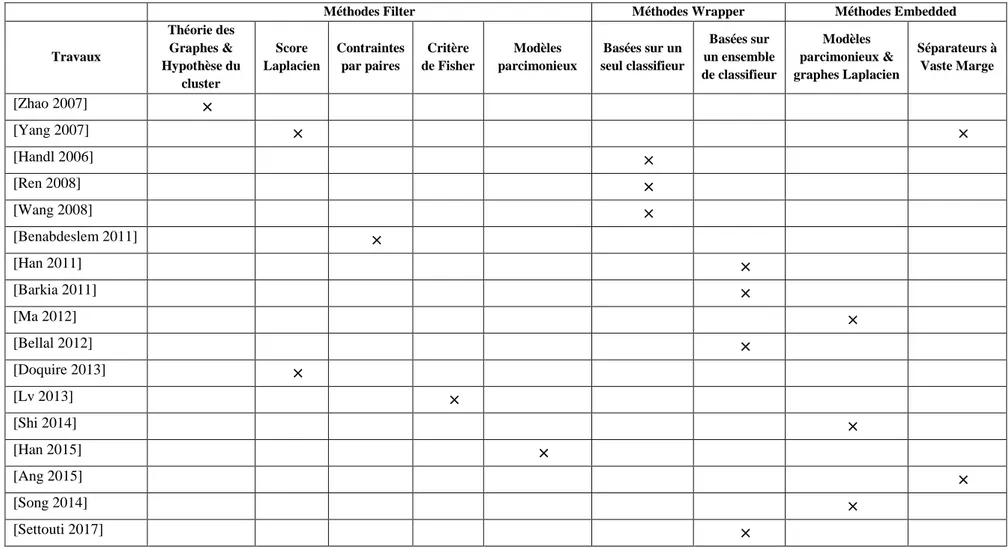
3. Sélection semi-supervisée des caractéristiques 41 3.1. Définition de la sélection semi-supervisée des caractéristiques 42 3.2. Méthodes de la sélection semi-supervisée des caractéristiques 42 4. Revue sur quelques méthodes de sélection des caractéristiques 46
4.1. Les méthodes SFS et SBE 46
4.2. Minimum-Redundancy-Maximum-Relevance 47
4.3. Métaheuristiques 48
4.3.1. Algorithmes Evolutionnaires 48
4.3.1.1. Les Algorithmes Génétiques 49
4.3.1.2. La Programmation Génétique 53
4.3.1.3. La Programmation Evolutionnaire 54
4.3.2. L’intelligence en essaim 55
4.3.2.1. L’Optimisation par Essaims Particulaires 55 4.3.2.2. L'Optimisation par Colonie de Fourmis 58 4.3.2.3. L’Optimisation par Colonie d’Abeilles artificielles 59
5. Conclusion 59
Chapitre 03 Apprentissage semi-supervisé pour la classification des données 61
1. Introduction 61
2. Apprentissage supervisé 62
4. Apprentissage semi-supervisé 65
4.1. Définition 65
4.2. Classification des techniques d’apprentissage semi-supervisé 66
4.2.1. L’auto-apprentissage 66
4.2.2. Le co-apprentissage 67
4.2.3. Méthodes à base de graphe 69
4.2.4. Séparateur Semi-Supervisé à Vaste Marge 70
5. Apprentissage actif 73
5.1. Définition 73
5.2. Scénarios d’apprentissage actif 75
5.2.1. Requêtes d’appartenance 75
5.2.2. Apprentissage actif à partir d’un flux de données 76 5.2.3. Apprentissage actif à partir d’un réservoir de données 76
5.3. Stratégies d’apprentissage actif 77
5.3.1. Stratégies basées sur l’incertitude 77
5.3.1.1. Faible probabilité de prédiction 78
5.3.1.2. Marge entre les deux classes les plus probables 78
5.3.1.3. Entropie de Shannon 78
5.3.2. Stratégies de requêtes par désaccord 79
5.3.3. Stratégie de requêtes par comité 80
6. Conclusion 81
Chapitre 04 Conception d’un système semi-supervisé d’aide au diagnostic pour la classification des images médicales
82
1. Introduction 82
2. Système CADx proposé 83
2.1. Bases des images médicales 85
2.1.1. DDSM (Digital Database for Screening Mammography) 85 2.1.2. RIM-ONE (An Open Retinal Image Database for Optic Nerve Evaluation) 86
2.2. Prétraitement 87
2.3. Extraction des caractéristiques 89
2.4. Sélection des caractéristiques 90
2.5. Apprentissage et classification 94
3. Résultats et discussions 95
3.1. Mesures de performances utilisées 96
3.2. Performance du classifieur SVM-Transductive 97
3.3. Etude comparative du système proposé 102
4. Conclusion 108
Chapitre 05 Approche hybride combinant l’apprentissage actif et l'algorithme PSO pour la classification des images médicales
109
1. Introduction 109
2. Approche hybride combinant l’apprentissage actif avec PSO (AL-PSO) 111
2.1. Etapes principales du AL-PSO proposé 115
2.2. Nouvelle fonction objective PSO basée sur la pondération des instances 116
2.2.1. Pondération des instances 117
2.2.2. Description de la fonction objective 118
3. Résultats et discussions 120
3.1. Bases de validation 120
3.2. Paramètres expérimentaux 120
3.3. Analyse des résultats 122
4. Conclusion 131
Conclusion Générale et Perspectives 132
Bibliographie 137
Liste des figures
Figure 1. Schéma du concept général des systèmes CAD 2 Figure 1.1 Une radiographie typique du thorax dans laquelle les régions de l'os apparaissent
blanches
9
Figure 1.2 Tissu mammaire normal tel qu'il apparaît sur une mammographie 10 Figure 1.3 L'IRM fournit une excellente définition de contraste élevé, comme le montre cette
image du thorax
11
Figure 1.4 Rétinographe Non Mydriatique 12
Figure 1.5 Photo couleur du fond d’œil prise par une Rétinographe non mydriatique 12 Figure 1.6 Organigramme illustrant l'architecture typique d'un CADe et d'un CADx 15 Figure 1.7 Les quatre pixels les plus proches du pixel X selon les quatre directions 20 Figure 2.1 Processus de sélection des caractéristiques 37
Figure 2.2 Illustration du modèle filtre 38
Figure 2.3 Illustration du modèle wrapper 39
Figure 2.4 Illustration du modèle embedded 40
Figure 2.5 Cycle typique d’un algorithme génétique 49
Figure 2.6 Le croisement à 1-point 52
Figure 2.7 Le croisement à deux points 52
Figure 2.8 Le croisement uniforme 52
Figure 2.9 Opération de croisement pour deux arbres d'analyse parents 54 Figure 2.10 Stratégie de déplacement des particules 57
Figure 3.1 Apprentissage supervisé 63
Figure 3.2 Apprentissage non supervisé 64
Figure 3.3 (a) Avec seulement des données étiquetées, la limite de décision linéaire qui maximise la distance à n'importe quelle instance étiquetée est tracée avec un trait en gras. La marge associée est représentée en pointillé. (b) Avec des données non étiquetées supplémentaires, en supposant que les classes sont bien séparées, la frontière de décision cherche un écart dans les données non étiquetées
70
Figure 4.1 Schéma général du système CADx proposé 84 Figure 4.2 Un échantillon de la base DDSM : La première ligne représente des images
mammaires à masse maligne et la deuxième ligne contient des masses bégnines.
86
Figure 4.3 Un exemple des images tirées de la base de données RIM-ONE : (a) et (b) des cas normaux, (c) et (d) des cas glaucome
87
Figure 4.4 Exemple des images mammaires de la base de données DDSM : La première ligne consiste en deux images de la classe bénigne et deux images de classe maligne. La deuxième ligne représente les images en niveau de gris après extraction de la tumeur. Les images binaires sont représentées en troisième ligne.
88
Figure 4.5 Un échantillon de la base de données RIM-ONE : La première ligne représente deux images de la classe normal et deux images de classe glaucome. La représentation en niveau de gris de ces images est donnée dans la deuxième ligne. Le résultat de la binarisation est montré dans la troisième ligne.
89
Figure 4.6 Deux schémas proposés de sélection des caractéristiques : à gauche le schéma GA-SVM (un algorithme génétique avec une fonction objective wrapper supervisé) et à droite le schéma GA-TSVM (un algorithme génétique avec une fonction objective wrapper semi-supervisé)
91
Figure 4.7 Frontière de décision du TSVM 95
Figure 4.8 Evolution de la précision des schémas de sélection de caractéristiques en fonction de nombre de générations utilisant la base de données DDSM
99
Figure 4.9 Evolution de la précision des schémas de sélection de caractéristiques en fonction de nombre de générations utilisant la base de données RIM-ONE
99
Figure 4.10 Une étude de sensibilité, spécificité, NPV et PPV du système proposé : (a) et (b) représentent les performances des schémas GA-SVM et GA-TSVM sur DDSM, (c) et (d) représentent les performances des schémas GA-SVM et GA-TSVM sur RIM-ONE.
102
Figure 4.11 Comparaison entre les schémas proposés et les différentes méthodes de sélection des caractéristiques utilisant la base de données DDSM
103
Figure 4.12 Comparaison entre les schémas proposés et les différentes méthodes de sélection des caractéristiques utilisant la base de données RIM-ONE
103
Figure 4.13 Les courbes ROC correspondant à la performance de trois classifieurs couplés avec différentes méthodes de sélection de caractéristiques :(a) l’AG avec wrapper
supervisé, (b) l’AG avec wrapper supervisé, (c) la méthode PSO, (d) la méthode PCA, et (e) la méthode MRMR, testées sur la base de données RIM- ONE.
Figure 5.1 Organigramme du AL-PSO proposé 112
Figure 5.2 Ensemble de données bidimensionnelles avec deux instances incertaines (Instances A et B) avec deux cas : (a) Traite toutes les instances de façon égale dans un ensemble de données avec des instances incertaines qui peuvent affecter la frontière de classification. (b) la façon dont une instance peut être incertaine dépend des autres instances d'un ensemble de données.
117
Figure 5.3 L’intervalle de confiance tracé pour chaque approche d'apprentissage 123 Figure 5.4 Courbes d'apprentissage (Learning curves) de l'AL-PSO proposé contre les deux
mesures d’incertitudes validées sur 18 bases de données
127
Liste des tableaux
Tableau 1.1 Les systèmes d’aide au diagnostic de différentes maladies (CADx) récents 32 Tableau 2.1 Les méthodes de sélection semi-supervisée des caractéristiques basées sur la
taxonomie des méthodes de sélection de caractéristiques
44
Tableau 2.2 Les méthodes de sélection semi-supervisée des caractéristiques basées sur la taxonomie des méthodes d’apprentissage semi-supervisé
45
Tableau 4.1 Les caractéristiques utilisées pour représenter les images médicales 90
Tableau 4.2 L’ensemble d’apprentissage/teste utilisé 96
Tableau 4.3 Etude des performances des méthodes d’extraction de caractéristiques ainsi que les deux schémas de sélection de caractéristiques proposés sur la base de données DDSM
100
Tableau 4.4 Etude des performances des méthodes d’extraction de caractéristiques ainsi que les deux schémas de sélection de caractéristiques proposés sur la base de données RIM-ONE
101
Tableau 4.5 Evaluation en termes de AUC 107
Tableau 4.6 Présente différents systèmes d’aide au diagnostic du cancer du sein 107
Tableau 4.7 Résume diverses approches développées pour le diagnostic du glaucome en utilisant des systèmes CAD
108
Tableau 5.1 Description des bases de données utilisées 121
Tableau 5.2 Moyenne et écart type du AL-PSO proposée versus les différents classifieurs 122 Tableau 5.3 Le Score moyen obtenu en utilisant précision, l’erreur de classification, la
sensibilité, la spécificité, F-mesure et la moyenne géométrique
124
Tableau 5.4 Les résultats comparatifs de l’approche proposée contre les autres techniques d’apprentissage en termes d’AUC
Liste des Abréviations
ACO Optimisation par colonie de fourmis (Ant Colony Optimization) ACP Analyse des Composantes Principales
Ada-DEWNN Adaptive differential evolution wavelet neural network AG Algorithme Génétique
AL Apprentissage Actif (Active Learning)
AUC L’air sous la courbe ROC (Area Under ROC Curve) AVC Accident Vasculaire Cérébral
BCO Optimisation par colonie d’abeilles Artificielle (Bee Colony Optimization)
BI-RADS Système de comptes-rendus et de données d’imagerie mammaire (Breast Imaging Reporting and data system)
CAD Système d’aide au diagnostic/détection (Computer Aided Diagnosis/Detection) CADe Système d’aide à la détection (Computer Aided Detection)
CADx Système d’aide au diagnostic (Computer Aided Diagnosis)
CBIR La recherche d'image par le contenu (Content Based Image Retrieval)
CFS Sélection des caractéristiques basée sur la corrélation (Correlation based Feature Selection) DDSM La base de données numérique pour la mammographie de dépistage (Digital Database for
Screening Mammography)
DR Réduction de dimensionnalité (Dimensionality Reduction) DW Transformée par ondelettes (Wavelet Transform)
DWT Transformée par ondelettes discrète (Discrete Wavelet Transform) EA Algorithmes évolutionnaires (Evolutionary Algorithm)
ECG Electrocardiogramme
ELM Machine d’apprentissage extrême (Extreme Learning Machine) FFDM Full Field Digital Mammography
GLCM La matrice de co-occurrence des niveaux de gris (Gray Level Co-occurrence Matrix) GLRLM Matrice de longueurs de plages des niveaux de gris (Gray Level Run Length Matrix) HOS Higher Order Spectra
HWT Hyper Analytic Wavelet Transformation IRM Imagerie par Résonance Magnétique kPPV k-Plus Proches Voisins
LBP Motifs binaires locaux (Local Binary Pattern)
LDA Analyse Discriminante Linéaire (Linear Discriminant Analysis) LTEM Texture Energy Measures
MRMR Minimum Redundancy Maximum Relevance NB Naïf Bayésien (Naive Bayes)
PE Programmation Evolutionnaire PG Programmation Génétique
PSO Optimisation par essaims particulaires (Particle Swarm Optimization) QBC Requêtes par comité (Query By Committee)
QDB Requêtes par désaccord (Query By Disagreement)
RIM-ONE Une Base de données rétinienne pour l’évaluation du nerf optique (Retinal Image Database for Optic Nerve Evaluation)
RM Rétinographies Mydriatique RNA Réseau de Neurone Artificiel RNM Rétinographies Non-Mydriatique
ROC Fonction d’efficacité du récepteur (Receiver Operating Characteristic) ROI Région d’intérêt (Region Of Interest)
S3VM Séparateur Semi-Supervisé à Vaste Marge (Semi-Supervised Support Vector Machine) SBE Elimination séquentielle descendante (Sequential Backward Elimination)
SFS Sélection séquentielle ascendante (Sequential Forward Selection) SI Intelligence en essaim (Swarm Intelligence)
SIFT Transformation de caractéristiques visuelles invariante à l'échelle (Scale-Invariant Feature Transform)
SSL Apprentissage semi-supervisé (Semi-Supervised Learning) SVM Machine à vecteur de support (Support Vector Machine) TDM Tomodensitométrie
Introduction Générale
Contexte général
Les systèmes d’aide à la décision clinique ou système d’aide au diagnostic médical « Computer Aided Diagnosis (CAD) » permettent de guider les médecins en temps réel dans l’établissement du bien-fondé du diagnostic à partir des examens d’imagerie diagnostique chez un patient donné. En l’intégrant à des systèmes informatiques d’entrée à ordonnances ou aux dossiers de santé électroniques, il est possible d’utiliser une aide décisionnelle dans le cadre des activités normales de travail. Les systèmes d’aide à la décision clinique varient, allant de simples outils servant à un nombre déterminé d’examens d’imagerie et d’indications à des systèmes plus complexes interagissant sur le contenu des images médicales dans le but de l'interprétation et du diagnostic de la maladie.
L’utilisation de ces outils reposant sur les techniques issues de l’apprentissage artificiel et de reconnaissance de formes sont de plus en plus élaborés, et même considérés comme étant essentiels dans la prise de décision médicale. Le concept de base des systèmes CAD est de fournir des informations sur la base d'une analyse diagnostique quantitative de l'image médicale (Figure 1).
L’imagerie médicale est certainement l’un des domaines de la médecine qui a le plus progressé ces vingt dernières années. Dans ce domaine, l’exploitation d’images numériques est courante depuis de nombreuses années à travers des outils comme les scanners, les radiographies, échographes et microscopes numériques. Ces appareillages exploitent des outils de traitements d’images d’une haute technicité.
Plus récemment, nous avons assisté à une forte demande de logiciels de traitements des images afin d’aider les praticiens dans leurs diagnostics. La disponibilité croissante d’images
médicales ouvre la porte à de nombreuses applications cliniques qui ont une incidence sur la prise en charge du patient.
Figure 1. Schéma du concept général des systèmes CAD [Goti 2010].
De nouveaux traits caractéristiques, cliniquement pertinents, peuvent alors être découverts pour expliquer, décrire et représenter une maladie. Les progrès dans le développement de techniques d’apprentissage artificiel ont permis de répondre à cette attente. L’origine de cette demande est de plus en plus pressante et accroît l’importance de l’analyse d’images dans ce domaine.
Des techniques d'apprentissage automatique supervisé ont été appliquées avec succès aux systèmes d’aide au diagnostic (CAD) [Doi 2007 ; Shin 2015 ; Lin 2016]. Ces méthodes prennent à leur compte des hypothèses issues d'une grande quantité d'échantillons diagnostiqués (données médicales), C'est-à-dire les données collectées, à partir d'un certain nombre d'examens médicaux réellement faits et leurs diagnostics respectifs réellement établis par des experts médicaux, présentent une plateforme d’aide aux médecins en matière de diagnostic.
En pratique, les données sans étiquette sont souvent les plus abondantes et offrent une large richesse en informations : l’étiquetage est un processus long et coûteux qui nécessite souvent l’intervention d’un expert. Cette phase va à l’encontre de l’acquisition automatique des données. Il n’est pas rare de se retrouver avec un volume important de données dont seulement une petite partie a pu être étiquetée. Par exemple, en recherche d’images par contenu, l’utilisateur souhaite étiqueter le minimum d’images pour fouiller une base aussi grande que possible. Dans ce contexte, l’apprentissage semi-supervisé (SSL) intègre les données non-étiquetées dans la mise en place du modèle de prédiction. En ce sens, l’apprentissage
semi-Traitement d’image Radiologie Intelligence Artificielle Apprentissage Automatique Caractérisation quantitative Connaissances qualitatives
supervisé est à mi-chemin entre l’apprentissages supervisé et non-supervisé : le SSL cherche à exploiter les données non-étiquetées pour apprendre la relation entre les exemples et leur étiquette.
Problématiques
Dans le cadre de cette thèse, L'objectif est de concevoir un système ayant pour rôle de classer des images biomédicales par apprentissage automatique en vue de découvrir des patrons de pathologies cliniquement pertinents.
Les algorithmes d’apprentissage automatique apprennent selon des objectifs particuliers divisés en deux principales catégories : l’apprentissage supervisé et l’apprentissage non-supervisé. Il existe également un paradigme d’apprentissage semi-supervisé qui mélange les apprentissages supervisés et non-supervisés.
L’apprentissage semi-supervisé concerne le cas où le jeu de données D est partiellement étiqueté. L’objectif est d’entrainer un modèle qui soit capable de tirer profit à la fois des cibles présentes mais aussi des données non étiquetées.
La réalisation d’un processus décisionnel performant à partir d’un ensemble de données semi étiquetées doit prendre en compte plusieurs considérations liées à la nature des données, à l’algorithme d’apprentissage utilisé et à l’objectif à produire. Les données d’apprentissage peuvent être bruitées ou moins pertinentes. Tout comme les données d’apprentissage, les attributs sont plus ou moins fortement pertinents et ils peuvent être redondants.
Les exemples d’apprentissage peuvent être moins pertinents pour deux raisons : i) les valeurs des attributs de certains exemples sont plus bruitées que d’autres et/ou ii) l’étiquetage n’a pas été réalisé correctement.
Afin d’assurer une bonne représentation ainsi qu’une bonne discrimination entre les anomalies, il serait plus opportun de tirer le maximum d’informations présentes dans l’image médicale. Pour cette raison, plusieurs études favorisent l’utilisation de plusieurs descripteurs afin de générer une bonne représentation des données. Par conséquent, une telle représentation est parfois compliquée et engendre un espace de caractéristiques de haute dimension. Dans la plupart des cas, cet espace contient des caractéristiques redondantes, non pertinentes et qui n‘apporte aucune information supplémentaire au modèle.
La sélection de caractéristiques a pour objectif le choix des informations pertinentes afin de discriminer entre les classes et d’éliminer celles qui sont inutiles. Le bon choix des
caractéristiques a une influence importante sur (i) la taille de la mémoire, (ii) la précision de la classification, (iii) le coût de la classification et (iv) la robustesse du système de diagnostic.
La sélection d’attributs, la prise en compte des données non étiquetées, la manière de sélection de celles-ci et la décomposition en sous-problèmes sont liées à la nature des données, et également à l’objectif à réaliser.
Contributions
Les travaux effectués dans le cadre de cette thèse tentent de répondre aux problèmes cités ci-dessous en vue de réaliser un système d’aide au diagnostic qui permet de classer aisément les anomalies présentes dans l’image médicale.
À travers les problèmes discutés précédemment, apparaissent quatre aspects principaux, traités dans cette thèse, qui doivent être pris en considération pour construire un système d’aide au diagnostic robuste :
Afin d'assurer une bonne représentation du contenu des images médicales, une utilisation de familles hétérogènes de descripteurs est établie ;
La réduction de la taille du vecteur de descripteurs utilisés en ne maintenant que les caractéristiques pertinentes non redondantes par une méthode évolutionnaire de sélection de caractéristiques ;
La prise en compte des données étiquetées et non étiquetées lors de l’apprentissage du modèle de classification est assurée par une approche semi supervisée ;
L'analyse du rôle de l'apprentissage actif -dans le cadre semi supervisé sur la performance du module de classification. Ce dernier a pour but la minimisation des interventions humaines dans l’étiquetage manuel des données informatives utilisées pour l’apprentissage.
Deux contributions ont été proposées afin de répondre aux besoins cités ci-dessus.
La première contribution consiste à la réalisation d'un système CAD intégrant des techniques d’extraction et de sélection de caractéristiques afin de fournir au module de classification un vecteur descripteur contenant le maximum d’informations pertinentes pour qu’il puisse facilement assurer la discrimination en classes de maladies. Nous avons également pris en compte le manque et la non-disponibilité des données étiquetées dans la majorité des bases de données médicales en faisant appel à une technique semi-supervisée lors de la phase de classification et de prise de décision.
L'apprentissage semi supervisé prend en compte toutes les données non étiquetées durant l'apprentissage engendrant un coût en temps. De plus, ces dernières peuvent être non informatives et engendrent une mauvaise marge de séparation entre classes. Pour pallier à cet inconvénient, nous proposons dans la deuxième contribution, une approche hybride jumelant l’apprentissage actif et un algorithme d’optimisation en se basant sur la méthode d’optimisation par essaims particulaires afin de réduire le coût de l'étiquetage tout en construisant un classifieur plus efficace.
Organisation du manuscrit
Ce manuscrit est composé de cinq chapitres auxquels s’ajoute une conclusion afin de résumer notre contribution et tracer les futures perspectives.
Le premier chapitre (Système d'Aide à la décision médicale) est destiné à présenter le contexte général et la problématique de ce travail. Une première partie de ce chapitre sera consacrée aux concepts généraux de l’imagerie médicale ainsi que ses différentes modalités. Dans la deuxième partie, un survol des définitions des systèmes d’aide au diagnostic ainsi que les détails des différentes phases constituant ces outils seront présentés.
Dans le deuxième chapitre (Techniques de sélection des caractéristiques), nous définissons les différents concepts de sélection des caractéristiques. Les étapes du processus de sélection seront détaillées, suivi par un état de l’art des techniques de sélection de caractéristiques utilisant des données semi-étiquetées. A la fin du chapitre, nous présenterons quelques méthodes de sélection de caractéristiques proposées dans la littérature en mettant l’accent sur les techniques utilisées dans cette thèse.
Le troisième chapitre (Apprentissage semi-supervisé pour la classification des données) est consacré à la description des techniques d’apprentissage automatique en se focalisant sur l’apprentissage semi-supervisé et son extension qui est l’apprentissage actif.
Le quatrième chapitre (Conception d’un système semi-supervisé d’aide au diagnostic
pour la classification des images médicales) décrit notre première contribution qui consiste
en la réalisation d’un système d’aide au diagnostic prenant en comptes deux critères importants : la bonne représentation du vecteur de caractéristiques décrivant l’image médicale. La prise en considération des données non labélisées conjointement avec celles étiquetées pour générer le modèle de classification. La validation du système proposé est établie par deux bases des images médicales : la base de données DDSM (Digital Database for Screening
Mammography) pour la classification du cancer du sein, et la base de données RIM-ONE (Retinal IMage database for Optic Nerve Evaluation) pour la classification de la maladie du glaucome.
Le cinquième chapitre (Approche hybride combinant l’apprentissage actif et
l’algorithme PSO pour la classification des images médicales) décrit notre seconde
contribution. Le système proposé se base sur l’apprentissage actif et l’algorithme d’optimisation par essaims particulaires pour la sélection des instances informatives à partir des données non étiquetées. Ces dernières ayant comme objectif l'amélioration de la précision du système tout en réduisant l’effort d’étiquetage des données par les experts médicaux. La validation du modèle a été assurée par 18 bases de données de références.
La conclusion souligne l’avantage des approches proposées, tout en discutant des résultats obtenus tout au long de cette thèse sans oublier les perspectives à donner à ce travail.
Chapitre 01
Système d'aide à la décision médicale
1. Introduction
L'objectif de la reconnaissance des formes est la classification des objets en plusieurs catégories ou classes. Selon l'application, ces objets peuvent être des images, des signaux, ou tout type de mesure à classer. Nous ferons référence à ces objets en utilisant le terme générique forme. La reconnaissance des formes a une longue histoire, mais avant les années 1960, c'était surtout la sortie de la recherche théorique dans le domaine des statistiques. Comme avec tout le reste, l'avènement des ordinateurs a augmenté la demande pour des applications pratiques de la reconnaissance de formes, qui à son tour a établi de nouvelles demandes pour d'autres développements théoriques. Alors que notre société évolue, l'automatisation, le besoin de traitement et de récupération de l'information prennent de plus en plus d'importance. Cette tendance a poussé la reconnaissance des formes à la limite supérieure des applications récentes de l’ingénierie et de la recherche. La reconnaissance des formes fait partie intégrante de la plupart des systèmes d'intelligence artificielle conçus pour la prise de décision.
Le système d’aide à la décision, aussi appelé système d’aide au diagnostic/détection (Computer Aided Diagnosis/ Detection (CAD)) est une application importante de la reconnaissance des formes, visant à aider les médecins à prendre des décisions diagnostiques. Le diagnostic final, bien sûr, est fait par le médecin. On distingue principalement deux formes du CAD : système d’aide au diagnostic (Computer Aided Diagnostic (CADx)) et système d’aide à la détection (Computer Aided Detection (CADe)). Le CAD a été appliqué, il est d'intérêt pour une variété de données médicales. La nécessité d'un système d’aide à la décision découle du
fait que les images médicales sont souvent difficiles à interpréter, et l'interprétation dépendra de l'habileté du médecin.
Avant de procéder aux définitions des systèmes d’aide à la décision (CAD), il est utile de donner quelques définitions sur l’imagerie médicale ainsi que ces différentes modalités. Par la suite, l’ambiguïté sur les systèmes d’aide au diagnostic (CADx) et les systèmes d’aide à la détection (CADe) est soulevée. La méthodologie de conception de ces systèmes ainsi que les étapes nécessaires à leurs réalisations sont présentées.
2. Imagerie médicale
L'imagerie médicale a été largement utilisée pour faciliter le diagnostic et l'évaluation du corps humains, avec des avantages et des applications plus grands au fur et à mesure que la technologie progresse [Shin 2015]. En raison de sa capacité à évaluer la structure et la fonction physiologiques, l'imagerie médicale peut aider de manière non invasive à la détection, au diagnostic, et au suivi de la progression du développement des maladies. Compte tenu de ces avantages, l'imagerie médicale est continuellement avancée pour l'utilisation dans la gestion des différents types de maladies allant du dépistage à l'évaluation de la progression.
Les techniques d’imagerie médicale ne donnent pas une simple « photographie » du tissu ou de l’organe étudié mais une représentation visuelle fondée sur des caractéristiques physiques ou chimiques particulières. Les appareillages utilisés sont autant variés que les techniques elles-mêmes ; des techniques qui peuvent être complémentaires les unes aux autres.
Les systèmes d'imagerie médicale détectent différents signaux physiques provenant d'un patient et produisent des images. Une modalité d'imagerie est un système d'imagerie qui utilise une technique particulière. Au fil des années, différentes modalités d'imagerie médicale ont été développées, chacune avec ses propres avantages et inconvénients.
2.1. Radiographie (rayons X ordinaires)
Malgré le développement de technologies les radiographies aux rayons X ordinaire demeurent un outil important pour le diagnostic de nombreux troubles. En radiographie, un faisceau de rayons X, produit par un générateur de rayons X, est transmis à travers un objet, par ex. la partie du corps à scanner. Les rayons X sont absorbés par l’objet qu'ils traversent en quantités différentes selon la densité et la composition de l’objet. Les rayons X qui ne sont pas absorbés traversent l'objet et sont enregistrés sur un film sensible aux rayons X.
Alors que l'os absorbe particulièrement bien les rayons X, les tissus mous telles que les fibres musculaires, de densité inférieure à celle de l'os, absorbent moins. Il en résulte le contraste familier vu dans les images radiographiques, avec les os montrés comme zones blanches clairement définies et les zones de tissu plus sombres (Figure 1.1).
Figure 1.1. Une radiographie typique du thorax dans laquelle les régions de l'os apparaissent blanches. [Siemens 2017]
L'imagerie par rayons X fournit des images rapides de haute résolution et relativement peu coûteuses. Les images radiographiques sont stockées sur une pellicule appelée radiographie. Celles-ci sont interprétées par un médecin spécialement formé appelé radiologue. Le rayonnement ionisant utilisé dans la production des images radiographiques est cancérigène. L’exposition continue à ces rayons au fil du temps peut causer des dommages et augmenter le risque de cancer. Cependant, les experts considèrent que les avantages tirés d'un diagnostic impliquant rayons X l'emportent de loin sur le risque relativement faible lié à leur exposition.
Les rayons X de n'importe quelle partie du corps ne sont pas recommandés pour les femmes enceintes. Les risques des rayons X sont plus grands pour les jeunes enfants et les bébés à naître et le médecin en tiendra toujours compte lorsqu'il décidera de la nécessité d'une imagerie médicale.
2.2. La mammographie
La mammographie est un type spécifique d'imagerie par rayons X qui utilise un système de radiographie à faible dose spécialement conçu pour créer des images détaillées de mammaires connues sous le nom de mammographies (Figure 1.3).
La mammographie peut être utilisée comme un outil de dépistage pour la détection précoce du cancer du sein chez les femmes sans signes ou symptômes de maladie mammaire ou pour
diagnostiquer une maladie du sein chez les femmes présentant des symptômes telles qu'une masse, une douleur…etc.
La mammographie numérique, également connue sous le nom de Full-Field Digital Mammography (FFDM), utilise des détecteurs électroniques qui convertissent les rayons X en signaux électriques. Les images de la poitrine peuvent être visualisées sur un écran d'ordinateur. Des développements avancés en mammographie permettent des réductions considérables de la dose de rayonnement requise. Par exemple, la mammographie numérique elle-même peut réduire la dose jusqu'à 50% par rapport à une mammographie conventionnelle. De nouveaux logiciels sont également disponibles pour réduire encore la dose de 30% tout en conservant la même qualité d'image.
Figure 1.2. Tissu mammaire normal tel qu'il apparaît sur une mammographie. [Siemens 2017]
Un équipement de dépistage moderne est spécialement conçu pour émettre une dose de rayonnement extrêmement faible et les chances qu'une mammographie provoque le développement d'un cancer sont donc extrêmement faibles. Les avantages en termes de nombre de cancers détectés, liè aux doses, dépassent de loin les faibles risques de mammographie.
2.3. Imagerie par Résonance Magnétique
Les systèmes d'IRM utilisent un champ magnétique puissant et des impulsions de radiofréquences pour produire des images détaillées des structures internes du corps sous forme d'images ou de coupes transversales (Figure 1.5). Sans exposer le patient aux rayonnements ionisants (rayons X), l'IRM fournit des images de haute qualité avec d'excellents détails de contraste des tissus mous et des structures anatomiques telles que les matières grise et blanche dans le cerveau. Il est utilisé dans un large éventail d'examens allant des tumeurs cérébrales à
l'inflammation de la colonne vertébrale aux hernies discales, évaluant le flux sanguin et le fonctionnement du cœur. L'IRM n'émet aucun rayonnement ionisant.
Figure 1.3. L'IRM fournit une excellente définition de contraste élevé, comme le montre cette image du thorax. [Siemens 2017]
De nombreuses maladies, telles que certaines tumeurs cérébrales, peuvent être visualisées en utilisant l'IRM en raison d'une définition de contraste élevée, qui ne nécessite pas toujours des agents de contraste pour produire des images détaillées des vaisseaux sanguins. L'IRM peut scanner beaucoup de parties du corps, y compris les blessures des articulations, les vaisseaux sanguins, la poitrine, ainsi que les organes abdominaux et pelviens tels que le foie ou les organes reproducteurs.
2.4. Rétinographies mydriatique (RM) et non mydriatique (RNM)
Le rétinographe est le nom français de l’appareil qui s’appelle « fundus camera », cet appareil sert à photographier le fond d'œil, soit tout ce qui est visible en arrière de l'iris et du cristallin. On peut y observer la rétine, la papille optique, la macula, l'ensemble portant le nom de pôle postérieur.
Le rétinographe est utilisé pour surveiller d'éventuelles modifications du fond d'œil, pour transmettre des images à un ophtalmologiste distant ou réaliser des assemblages couvrant une grande surface de la rétine. Il permet, entre autre, d'évaluer et de surveiller les symptômes de décollement de la rétine, de rétinopathies diabétique, d'affections vasculaires ou inflammatoires et diverses maladies oculaires tel que le glaucome. L'examen est totalement indolore. Il peut être réalisé sans dilatation pupillaire (d'où le nom de RNM, Rétinographe Non Mydriatique) (figure 1.6).
Figure 1.4. Rétinographe Non Mydriatique. [Bouziane 2017]
Les nouveaux rétinographes non-mydriatiques permettent de photographier de nombreuses pathologies rétiniennes, pour mieux les évaluer, les traiter et les surveiller (figure 1.7).
Figure 1.5. Photo couleur du fond d’œil prise par une Rétinographe non mydriatique. [Zanlonghi 2005]
Existe-t-il une technique supérieure aux autres ? Loin d’être en concurrence les unes avec les autres, chaque modalité d’imagerie apporte une information différente et complémentaire. Au fur et à mesure que les technologies d'imagerie progressent, un grand nombre d'images médicales sont produites et interprétées par les médecins et les radiologues. Ainsi, les aides informatiques sont demandées et deviennent indispensables dans la prise de décision des médecins à partir d'images médicales. Par conséquent, les systèmes d’aide au diagnostic/détection (CAD) [Doi 2007 ; Shin 2015 ; Lin 2016] ont été un domaine de recherche actif se basant sur l’imagerie médicale.
La suite de ce chapitre présente les deux grandes familles de CAD : les systèmes d’aide à la détection (Computer Aided Detection (CADe)) et les systèmes d’aide au diagnostic
(Computer Aided Diagnosis (CADx)), leurs particularités ainsi que leurs fonctionnements. La méthodologie de conception des CADx ainsi que toutes les étapes nécessaires à leur réalisation seront citées plus en détail car notre objectif de thèse se focalise sur ces derniers. Nous clôturons ce chapitre par un état de l’art récent des CADs proposés visant à une aide à la décision des plusieurs types de maladies.
3. Les systèmes d’aide au diagnostic/ détection
La détection ou le diagnostic assisté par ordinateur (CAD) est une application importante de la reconnaissance des formes, des outils informatiques et des techniques de traitement et d'analyse d'images, visant à aider les médecins à prendre des décisions médicales. Une fois que les données sont souvent difficiles à interpréter, les systèmes CAD aident le médecin à détecter les lésions subtiles et à réduire la probabilité d'échec. Ces systèmes computationnels sont prometteurs dans la détection des cas suspects et pour aider dans la décision diagnostique en tant que « deuxième opinion ». Au cours des dernières années, les systèmes CAD et les techniques connexes ont attiré l'attention des chercheurs et des radiologues ; beaucoup de travaux et de publications ont été proposés [Romany 2017 ; Nurul 2017 ; Boawei 2017].
3.1. Définition
Plusieurs définitions, du système d’aide au diagnostic/détection, ont été proposées dans la littérature. Les auteurs [Kong 2008 ; Stojkovska 2010] ont défini le système d’aide au diagnostic/détection comme un logiciel conçu pour aider à la prise de décision clinique, dans lequel les caractéristiques d'un patient correspondent à une base de connaissances cliniques informatisée et les évaluations ou les recommandations spécifiques au patient sont ensuite présentées au clinicien pour avoir une décision :
« Software designed to be a direct aid to clinical decision-making, in which the characteristics of an individual patient are matched to a computerized clinical knowledge base and patient specific assessments or recommendations are then presented to the clinician or the patient for a decision ».
L'intégration des techniques de reconnaissances de forme et de traitement d’images dans le processus d'interprétation de l'imagerie radiologique peut augmenter la précision de l'interprétation de l'image. Il y a deux grandes catégories des systèmes d’aide au diagnostic/détection : des systèmes d’aide à la détection (CADe) et des systèmes d’aide au diagnostic (CADx).
- Système d’aide à la détection (CADe) : Les systèmes CADe sont des outils informatisés qui aident les radiologistes à localiser et à identifier les anomalies possibles dans les images radiologiques, laissant l'interprétation de l'anomalie au radiologue [Burhenne 2000]. Le potentiel des modèles CADe pour améliorer la détection du cancer a été étudié dans plusieurs études rétrospectives [Brem 2003 ; Malich 2009]. Le schéma générique d’un système d’aide à la détection (CADe) des lésions dans les images médicales est représenté par la figure 1.8. Un schéma CADe se compose généralement de quatre étapes principales : (i) Le prétraitement, (ii) la segmentation et la détection de la région d’intérêt, (iii) l’extraction et analyse des caractéristiques de la région d’intérêt détecté ; et enfin (iv) Classification afin de générer une décision sur la présence ou l’absence de lésion. Cette dernière étape est très importante, car elle détermine la performance finale du CADe.
- Système d’aide au diagnostic (CADx) : Les schémas CADx en imagerie médicale visent à aider les radiologues dans le diagnostic des lésions (ex ; malignité vs bénignité) identifiées par un radiologue ou un modèle CADe, et de réduire ainsi le nombre de recommandations de biopsies sur des lésions bénignes. Le processus du CADx démarre avec une phase de prétraitement de l’image en entrée. Puis, une étape de segmentation automatique ou manuelle à partir des lésions détectées (localisées).En d'autres termes, la localisation d'une lésion d'intérêt est connue. Par la suite, l’étape d’extraction des caractéristiques décrivant la région d’intérêt est établie. A la fin de ce modèle, une phase de classification qui a pour but de classifier les zones suspectes en bénignes, malignes ou autres types de lésions selon différentes techniques d’apprentissage automatique. (voir Figure 1.8).
3.2. Composition d’un système d’aide au diagnostic (CADx)
Le concept de base du système CADx est de fournir des informations sur la base d'une analyse diagnostique quantitative de l'image médicale à l'aide d'ordinateurs. Ce concept peut améliorer la précision et la cohérence du diagnostic de la lésion et réduire le temps de lecture des images.
Le traitement d'images médicales nécessite une connaissance préalable du contenu et de la nature de l'image afin de sélectionner les méthodes appropriées pour implémenter le système de CADx. Afin d'atteindre un haut niveau d'efficacité pour le diagnostic automatisé, il est important d'utiliser des approches de traitement d'image et d’apprentissage automatique efficaces dans les principales étapes du système de CADx. On détaille dans les sections qui suivent l’état de l’art concernant les différentes étapes de ces systèmes.
Figure 1.6. Organigramme illustrant l'architecture typique d'un CADe et d'un CADx. [Hidetaka 2009]
3.2.1. Prétraitement
En particulier, le diagnostic et le suivi de diverses maladies sont limités par plusieurs facteurs tels que le contraste, la luminosité ou le bruit présent dans les images obtenues. Cela dégrade les performances des systèmes d’aide au diagnostic ou conduit à la mauvaise interprétation des tissus par des experts.
Dans le traitement d'images médicales, le prétraitement d'images joue un rôle important pour obtenir les résultats idéaux dans les autres étapes du système CADx, telles que la segmentation et l'extraction de caractéristiques. L'étape de prétraitement vise à améliorer la qualité de l'image médicale originale et à rendre les étapes suivantes du CADx plus faciles et plus fiables. [Kyawn 2013].
Image Médicale Prétraitement Extraction de caractéristiques Segmentation Classification Type de lésion
Expert décide sur le diagnostic final de lésion CADx Image Médicale Prétraitement Extraction de caractéristiques Segmentation Classification Identification de lésion
Expert décide sur l’emplacement réel
de lésion
CADe
Sélection de caractéristiques
Il convient de noter que dans certains systèmes d’aide au diagnostic le prétraitement n’est pas utilisé, car les opérations de prétraitement peuvent affecter l’information contenue dans l’image [Jalalian 2017]. L’opération de prétraitement d'image inclut des techniques telles que : - Le filtrage : Le filtrage est une méthode utilisée pour supprimer les composants indésirables de l'image. Le filtre gaussien a été utilisé pour lisser les images, surmonter les variations de coloration [Waheed 2007] et aussi pour éliminer le bruit [Seminowich 2010 ; Nandy 2012]. De même, le filtre médian a également été utilisé pour éliminer le bruit des images médicales [Jadhavet 2006 ; Irshad 2014a]. Le lissage des images médicales a été assuré par différentes techniques dont : la diffusion anisotrope [Sertel 2009a ; Arif 2007b ; Li et al 2015], basée sur l'équation différentielle partielle (EDP) assistée par un filtrage bilatéral [Arif 2007a], qui préserve les contours mais supprime le bruit.Le filtrage de Wiener a été utilisé pour supprimer le bruit des images mammaires [Beevi 2014]. La taille et la forme d'un filtre est un aspect important dans la conception des filtres. Une sélection soigneuse de ces deux paramètres fournira le résultat requis.
- Techniques basées sur l’histogramme : L'histogramme d'une image est une représentation graphique d'une image qui donne le nombre total de pixels présents à chaque niveau de gris dans l'image. Il représente l'image en termes de contraste (faible contraste ou contraste élevé), de luminosité (si l'image est sombre ou claire) et de qualité. L'histogramme d'une image de bonne qualité est bien réparti avec approximativement le même nombre de pixels dans chaque niveau de gris. L'égalisation de l'histogramme et l'appariement de l'histogramme sont les deux techniques qui ont été utilisées pour éliminer les variations de couleur dues au processus de coloration et aux conditions d'illumination [Sertel 2009a ; Tabesh 2007]. La méthode de Contrast Limited Adaptive Histogram Equalization (CLAHE) a également été utilisée pour améliorer le contraste de l'image [Wang 2009].
3.2.2. Segmentation
La segmentation est parfois considérée comme l’étape initiale dans un système d’aide au diagnostic. En imagerie médicale, la sélection des méthodes de segmentation dépend largement de l'application spécifique et de la modalité d'imagerie. Avec l'augmentation de la dimension et la résolution de l'image dans diverses modalités, les images ne peuvent pas être examinées manuellement en ce qui concerne l'énorme quantité d'informations des images. Les techniques de segmentation aident à mettre en évidence des régions importantes et à extraire diverses structures tels que des organes ou des tumeurs pour un examen plus approfondi.
Les méthodes de segmentation sont classées généralement en deux groupes : semi-automatique et entièrement semi-automatique. Fournir un algorithme semi-automatique en médecine pour détecter et localiser les anomalies est hautement souhaitable. Par conséquent, les méthodes d'évaluation des algorithmes de segmentation constituent une autre dimension des systèmes CADx dans l'aspect pratique.
Les approches de segmentation basées sur les propriétés de l'image sont généralement organisées en deux groupes : l'approche basée sur la discontinuité et celle basée sur la similarité. La première partitionne une image en se basant sur les variations brusque d'intensité [Rastgarpour 2011]. Les méthodes de segmentation basées sur les contours constituent une famille de cette approche. Tandis que l’approche basée sur la similarité partitionne une image selon des critères de similarité prédéterminés. Cette approche englobe les méthodes basées sur le seuillage (Thresholding methods) et les méthodes basées régions [Lee 2015].
- Méthodes basées sur le contour : Les méthodes de segmentation basées sur le contour se basent sur une technique structurelle permettant de détecter les contours ou les pixels parmi les différentes régions qui présentent une variation brutale d'intensité [Pal 1993]. La méthode basée sur le contour fonctionne bien sur les images de contraste élevé et sans bruit. Il existe plusieurs méthodes pour la segmentation basée sur le contour telles que : Sobel, Prewitt et Canny …etc. [Dromain 2013].
- Méthodes basées sur le seuillage : elles constituent un moyen efficace de distinguer le premier plan de l’arrière-plan de l'image [Zhang, 2006]. Comme leur nom l’indique, ces méthodes nécessitent la sélection d’un seuil appropriée en fonction des propriétés de l'image. La sélection automatique de la valeur du seuil requiert la connaissance des caractéristiques d'intensité des objets, de la taille des objets et du nombre de différents types d'objets présents dans l'image [Al-Amri 2010]. Les méthodes basées sur le seuillage ont été largement utilisées pour développer des systèmes CADx afin d'extraire des zones significatives pour une analyse supplémentaire. Diverses techniques de seuillage ont été comparées pour la segmentation des images mammaires et des images du fond d’œil [Al-Bayati 2013]. Une segmentation automatique des images mammaires en utilisant un seuillage basé sur l'histogramme a été développée par [Saha 2015]. Le résultat montre une précision de 97% dans la détection de la tumeur.
- Méthodes basées régions : Les méthodes de segmentation basées régions divisent une image en régions homogènes de pixels connectés en fonction de critères prédéfinis telle que l'intensité, la couleur ou la texture. Les méthodes basées sur les régions sont généralement classées en deux groupes : les méthodes de croissance de région (Region Growing) et les méthodes de division et fusion de région (Split & Merge) [Narkhede 2013]. Ces dernières années, les algorithmes de segmentation par région sont largement utilisés dans les systèmes CADx. Une approche de croissance de région est appliquée pour l'extraction d'une région d'intérêts (ROI) [Rouhi 2015]. En revanche [Chondro 2018] propose un schéma de croissance de région avec une technique graph-cut adaptative pour la segmentation pulmonaire sur les radiographies thoraciques simples. Cette méthode atteint une précision de segmentation de 96,3%.
3.2.3. Extraction des caractéristiques
Avant que le diagnostic ou la classification puisse être effectué, un ensemble utile de descripteurs doit être extrait à partir de l'image. Le calcul des descripteurs ou de caractéristiques à partir d'une image est nécessaire pour réduire le volume de données. Les descripteurs sont des caractéristiques de l'ensemble de l'image ou de la région d'intérêts. Le bon choix des caractéristiques a une influence importante sur : (i) la taille de la mémoire, (ii) la précision de la classification, (iii) le coût de la classification et (iv) la robustesse du système CADx.
Selon la littérature [El-Atlas 2014], les descripteurs d'images sont classés en trois catégories, à savoir les descripteurs de forme, de texture et de couleur. Les différents types de descripteurs et leurs utilités sont détaillés dans les sections qui suivent.
3.2.3.1. Les caractéristiques de couleur
La couleur est un attribut visuel des formes qui résultent de la lumière qu’elles émettent ou transmettent ou reflètent. Les descripteurs fondés sur la couleur constituent le repère visuel important pour la récupération d'images et la reconnaissance d'objets [Liu 2013]. La couleur forme une partie significative de la vision humaine. Deux avantages majeurs de l'utilisation de la vision des couleurs sont : (i) la couleur fournit des informations supplémentaires qui permettent de distinguer les différentes causes physiques des variations de couleurs dans le monde telles que les ombres, les réflexions de sources lumineuses et les variations de réflectance des objets; (ii) La couleur est une propriété discriminante importante des objets.
Avec la publication de diverses modalités d'imagerie médicale impliquant des informations de couleur telles que : la démoscopie, la rétinographie et l’endoscopie gastro-intestinale, les descripteurs de couleurs deviennent importants dans les applications d'analyse d'images médicales [Celebi 2012]. Par contre, ils sont rarement utilisés dans l’analyse des images mammaires pour la détection du cancer du sein.
3.2.3.2. Les caractéristiques de texture
La texture est une notion très générale difficile à décrire en mots. La texture concerne principalement une structure spécifique, spatialement répétitive, de surfaces formées en répétant un élément particulier ou plusieurs éléments dans différentes positions spatiales relatives. John R. Smith définit la texture comme étant des motifs visuels ayant des propriétés d'homogénéité [Smith 1996]. Les caractéristiques de texture sont également une autre expression des caractéristiques visuelles qui est pratique dans le traitement d'image médicale, et qui sont largement appliquées durant la conception des systèmes CADx [Moon 2011 ; Liu 2013 ; Sundararaj 2014].
De nombreuses méthodes ont été proposées pour décrire la caractéristique de texture. Nous présentons ci-dessous une brève étude de quelques techniques existantes sur l’extraction des caractéristiques de texture appliquées à l’analyse des images médicales.
3.2.3.1.1 La matrice de co-occurrence à niveau de gris
L’une des méthodes les plus utilisées pour décrire la caractéristique de texture est la matrice de co-occurrence à niveau de gris (Gray Level Cooccurrence Matrix (GLCM)). Introduite par [Haralick 1973], la matrice de cooccurrence permet de déterminer la fréquence d’apparition des paires de valeurs de pixels situés à une certaine distance dans l’image. Cette méthode considère la relation entre deux pixels voisins, le premier pixel est connu comme une référence et le second est connu comme un pixel voisin.
La matrice de co-occurrence à niveau de gris consiste à calculer la probabilité pd,θ(i,j) qui représente le nombre de fois où un pixel de niveau de gris i apparaît à une distance relative (d) d’un pixel de niveau de gris j et selon l'orientation de la direction (θ). Généralement, d=1 et θ= 0°, 45°, 90°, 135° donnent les meilleurs résultats [Zhang 2001 ; Sharma 2001].
![Figure 1. Schéma du concept général des systèmes CAD [Goti 2010].](https://thumb-eu.123doks.com/thumbv2/123doknet/2030472.4099/19.892.176.744.186.484/figure-schema-concept-general-systemes-cad-goti.webp)
![Figure 1.2. Tissu mammaire normal tel qu'il apparaît sur une mammographie. [Siemens 2017]](https://thumb-eu.123doks.com/thumbv2/123doknet/2030472.4099/27.892.348.578.424.664/figure-tissu-mammaire-normal-tel-apparait-mammographie-siemens.webp)
![Figure 1.6. Organigramme illustrant l'architecture typique d'un CADe et d'un CADx. [Hidetaka 2009]](https://thumb-eu.123doks.com/thumbv2/123doknet/2030472.4099/32.892.102.788.104.649/figure-organigramme-illustrant-architecture-typique-cade-cadx-hidetaka.webp)
![Figure 2.2. Illustration du modèle filter. [Tan 2007]](https://thumb-eu.123doks.com/thumbv2/123doknet/2030472.4099/55.892.172.750.262.476/figure-illustration-modele-filter-tan.webp)
![Figure 2.3. Illustration du modèle wrapper. [Kohavi 1997]](https://thumb-eu.123doks.com/thumbv2/123doknet/2030472.4099/56.892.118.756.176.464/figure-illustration-du-modele-wrapper-kohavi.webp)
![Figure 2.4. Illustration du modèle embedded. [Kaushik 2016] 2.4.3. Critère d’arrêt](https://thumb-eu.123doks.com/thumbv2/123doknet/2030472.4099/57.892.150.681.120.294/figure-illustration-du-modele-embedded-kaushik-critere-arret.webp)
![Tableau 2.2. Les méthodes de sélection semi-supervisée des caractéristiques basées sur la taxonomie des méthodes d’apprentissage semi- semi-supervisé [Sheikhpoura 2017]](https://thumb-eu.123doks.com/thumbv2/123doknet/2030472.4099/62.1262.99.1163.133.692/methodes-selection-supervisee-caracteristiques-taxonomie-apprentissage-supervise-sheikhpoura.webp)
![Figure 2.5. Cycle typique d’un algorithme génétique. [Tang 1996]](https://thumb-eu.123doks.com/thumbv2/123doknet/2030472.4099/66.892.193.704.809.1053/figure-cycle-typique-algorithme-genetique-tang.webp)