UNIVERSITÉ DE TOULOUSE III
–
PAUL SABATIER U.
F.
R.
MATHÉMATIQUES INFORMATIQUE GESTIONTHESE
en vue de l'obtention du
DOCTORAT DE L'UNIVERSITÉ DE TOULOUSE délivré par l'Université Toulouse III – Paul Sabatier
Discipline: Informatique présentée et soutenue par Fadia NEMER le 27 Février 2008
Titre
O
PTIMISATION DE L'
ESTIMATION DU WCET PARANALYSE INTER
-
TACHE DU CACHE D'
INSTRUCTIONSDirecteurs de thèse
Jean-Paul Bahsoun, professeur, Université de Toulouse III Hugues Cassé, maître de conférence, Université de Toulouse III
JURY
M. Pascal Sainrat, professeur, Université de Toulouse III, Examinateur M. Ali Awada, maître de conférence, Université Libanaise, Examinateur M. François Bodin, professeur, Université de Rennes I, Rapporteur M. Philippe Clauss, professeur, Université Louis Pasteur Strasbourg , Rapporteur
À ma mère qui m'a soutenue, encouragée
et tout simplement aimée
À mon père qui n'est plus, je t'aime papa...
je ne t'oublie pas...
« Fais de ta vie un rêve, et d'un rêve une réalité »
Antoine de Saint-Exupéry
R
EMERCIEMENTS
Je tiens à remercier Jean-Paul Bahsoun mon directeur de thèse. Ma reconnaissance va également à Hugues Cassé, pour son encadrement, son soutien et la disponibilité dont il a fait preuve.
Je remercie aussi Pascal Sainrat, directeur de l'équipe TRACES, pour ses conseils, et Ali Awada pour son aide pendant mon séjour au Liban.
Je tiens aussi à remercier vivement Monsieur François Bodin et Monsieur Philippe Clauss pour m’avoir fait l’honneur d’être les rapporteurs de cette thèse.
Un grand merci à tous les membres de l'équipe TRACES pour la bonne ambiance de travail.
Je remercie ma famille et tous mes amis pour leur support qui m'a permis de continuer mes études dans les meilleures conditions.
Je remercie particulièrement mon fiancé, Hani Kanaan, pour son soutien tout le long de cette thèse et pour la compréhension et la patience dont il a fait preuve.
AUTEUR FADIA NEMER
TITRE « Optimisation de l'estimation du WCET par analyse inter-tâche du cache
d'instructions »
DIRECTEURS DE THÈSE Jean-Paul Bahsoun, Hugues Cassé
DATE ET LIEU DE LA SOUTENANCE 27 Février 2008, Université Paul Sabatier
RÉSUMÉ
Les systèmes temps réel se distinguent des autres systèmes informatiques par la prise en compte de contraintes temporelles dont le respect est aussi important que l'exactitude du résultat. On distingue le temps-réel strict ou dur (de l'anglais hard real-time) et le temps-réel
souple ou mou (soft real-time) suivant l'importance accordée aux contraintes temporelles.
Théoriquement, le concepteur d'un système temps réel strict doit être capable de prouver que les limites temporelles ne sont jamais dépassées quelle que soit la situation. Cette vérification, appelée analyse de faisabilité, fait appel à la théorie de l'ordonnancement. Elle requiert une connaissance du pire comportement temporel du système. Il est donc nécessaire de connaître en particulier les pires instants d'arrivées des tâches, et les temps d'exécution dans le pire des
cas des tâches. C'est sur l'obtention de cette dernière information que porte notre étude.
Le temps d'exécution pire cas d'un programme peut être estimé en mesurant son temps d'exécution dans un environnement de test ou par analyse statique du code. Les approches par analyse statique ont l'avantage d'être sûres mais fournissent des estimations parfois pessimistes. Or ces méthodes calculent le WCET d’une tâche seule et non dans le cadre d’une application complète ainsi elles ignorent plusieurs facteurs des systèmes temps-réel multi-tâches, essentiellement l'enchaînement des tâches, qui affectent naturellement la précision du WCET estimé.
Nous proposons une nouvelle approche, qui s’applique aux systèmes temps-réel stricts, multi-tâches. Cette méthode étudie le comportement d’un ordonnancement statique des tâches d’une application temps-réel, s'exécutant sur un processeur, pour analyser le comportement inter- et intra- tâche de la mémoire cache. Le but est de remplacer les hypothèses conservatrices qui supposent un état vide ou indéfini du cache par un état bien défini avant l’exécution de chaque tâche de l’ordonnancement. Ceci va nous permettre d’améliorer la précision de l’estimation du WCET de ces tâches en utilisant la trace de l’exécution d’autres tâches dans le cache. Cette thèse propose aussi un benchmark temps-réel, PapaBench, décrivant une application temps-réel complète et réelle pour le pilotage d'un UAV (Unmanned Aerial Vehicle). Ce benchmark a été conçu afin de constituer une base utile pour les expérimentations de calcul de WCET par méthodes statiques ou dynamiques, il peut être aussi utile pour les analyses d'ordonnancement.
MOTS CLÉS
WCET, analyse statique, benchmark temps-réel, analyse de flot de données, interprétation abstraite
Discipline
InformatiqueINTITULÉ ET ADRESSE DU LABORATOIRE D'ACCUEIL
Institut de Recherche en Informatique de Toulouse Université Paul Sabatier
T
ABLE DES MATIÈRESIntroduction...15
Chapitre 1 – Systèmes embarqués et temps-réel...19
1.Définitions...19
1.1.Système Réactif...19
1.2.Système distribué et Système embarqué...21
1.3.Spécification des systèmes réactifs embarqués...22
1.3.1.La boucle de contrôle...22
1.3.2.L'architecture matérielle...23
1.3.3.Les contraintes temporelles et matérielles...23
2.Ordonnancement temps-réel...23
2.1.Stratégies d'ordonnancement...24
2.1.1.Modèle de tâche...24
2.1.2.Ordonnancement préemptif, non-préemptif...25
2.1.3.Ordonnancement en ligne, hors ligne...26
2.1.4.Ordonnanceur à priorités statiques, dynamiques...27
2.2.Algorithmes d'ordonnancement classiques...27
2.2.1.Rate Monotonic (RM)...27
2.2.2.Earliest Deadline First (EDF)...28
2.2.3.Deadline Monotonic (DM)...29
2.2.4.Least Laxity First (LLF)...30
3.Modélisation en AADL...30
3.1.Choix d'AADL...31
3.2.AADL : Vue Générale...31
3.3.Types de composants...32 3.3.1.Composants Matériels...34 3.3.2.Composants Logiciels...34 3.3.3.Composants Composites...35 3.4.Les modes...35 3.5.Les propriétés...36 4.Conclusion...36
Chapitre 2 - PapaBench : un benchmark temps-réel...37
1.Le projet Paparazzi...38
1.1.Historique...38
1.2.1.Fonctionnement du microcontrôleur MCU1 (Fly by wire)...40
1.2.2.Fonctionnement du microcontroleur MCU0 (Autopilote)...41
2.Papabench1...42
2.1.Modèle aadl...43
2.2.Lien avec le modèle AADL...45
2.3.Complexité des variables...45
2.4.Représentation graphique de Paparazzi...46
3.Limitations de Papabench1...48
4.Genèse de Papabench2...50
4.1.Le modèle AADL...50
4.2.Les règles de précédences...51
5.Le benchmark...53
5.1.Détails de la compilation...54
6.Comparaison avec les benchmarks temps-réel...54
6.1.Les Benchmarks temps-réel...54
6.2.Caractéristiques du code...56
6.3.Complexité des boucles...58
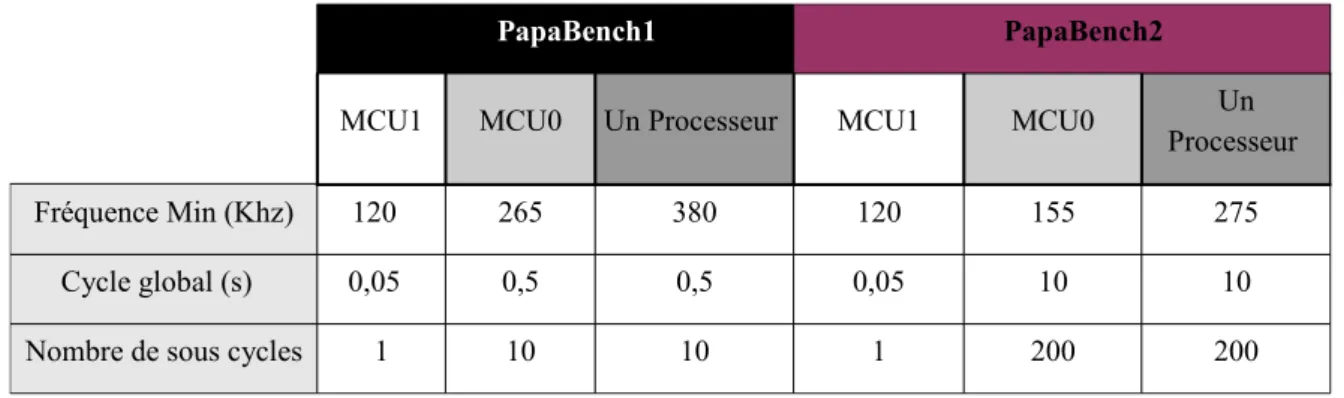
7.Papabench1 vs Papabench2...59
7.1.Outils utilisés...59
7.2.Résultats...60
7.3.Conseils de conception des applications temps-réel...63
8.Conclusion...64
Chapitre 3 – Calcul standard du temps d'exécution pire cas...65
1.Estimation du WCET...65
2.Méthodes dynamiques...66
2.1.Caractéristiques...66
2.2.Techniques de calcul du wcet par analyse dynamiques...67
3.Méthodes statiques...68
3.1.Analyse de flot de contrôle...69
3.1.1. Représentations logiques ...69
3.1.1.1.Blocs de base...69
3.1.1.2.Ligne Bloc ou L-bloc...70
3.1.1.3.Graphe de flot de contrôle ...71
3.1.1.4. Arbre Syntaxique ...72
3.1.2. Dépliage des appels de fonctions...73
3.1.3. Influence de la compilation sur la représentation logique du programme...74
3.1.4. Informations supplémentaires de flot de contrôle...75
3.2. Analyse des propriétés temporelles ...76
3.2.1.Le pipeline...76
3.2.1.1.Simulation plus Delta...78
3.2.1.2.Graphe d'exécution...83
3.2.2. Les mémoires caches...87
3.2.2.2. Les types de caches...89
3.2.2.3.Les stratégies de remplacement sur un défaut de cache...90
3.3. Techniques intra-tâche de calcul du WCET...92
3.3.1. Techniques utilisant les algorithmes de graphes...92
3.3.2. Techniques IPET...94
3.3.3.Techniques basées sur les arbres syntaxiques...99
3.3.4. Analyse Symbolique du WCET ...104
3.4.Analyses des systèmes multi-tâches ...108
3.4.1.Analyse Edgar & Burns...109
3.4.2.Analyse Diaz, Garcia & al...111
3.4.3.Analyse Tan & Mooney...112
3.4.4.Analyse Staschulat & Ernst...114
4.Conclusion...116
Chapitre 4 – Analyse d'une application multi-tâches...117
1.Définition du problème...117
1.1.Contexte...118
1.2.Comportement du cache intra-tâche...119
1.3.Comportement inter-tâche du cache...120
2.Les interférences possibles des L-blocs...121
3.Analyse de flot de données (dfa)...123
4.Analyses du cache à accès direct...124
4.1.Analyse Exit...125
4.2.Construction des états du cache...128
4.3.Analyse Entry...132
4.4.Amélioration du WCET des tâches...133
5.Analyse du cache associatif...134
5.1.Architecture d'un cache associatif...135
5.2.Stratégie de remplacement LRU...135
5.3.Sémantiques du cache...136
5.4.Analyse Exit...137
5.5.Calcul du Damage...139
5.6.Analyse Inter-Tâche...141
5.7.Analyse Entry...143
6.Injection d'un état du cache et calcul du wcet...145
7.Choix du meilleur Ordonnancement ...147
8.Conclusion...150
Chapitre 5 – Expérimentations...153
1.Benchmarks...153
2.Outils...154
3.1.Variation des paramètres du cache...155
3.1.1.Variation de la taille de bloc...155
3.1.2.Variation de la taille du cache...156
3.1.3.Variation du degré d'associativité...158
3.2.Variation de l'ordonnancement...160
3.3.Comparaison Réinjection Entry...162
3.3.1.Amélioration des WCET des tâches et du WCET global...163
4.Conclusion...168
I
NDEX DES FIGURESFigure 1.1 - Modèle d'un système réactif...20
Figure 1.2 - Exemple d'un système réactif...20
Figure 1.3 - Exemple d'ordonnancement RM...28
Figure 1.4 - Exemple d'ordonnancement EDF...29
Figure 1.5 - Calcul de la laxité d'une tâche Ti...30
Figure 1.6 - Type de ports...33
Figure 1.7 - Représentation graphique des composants AADL...33
Figure 2.1 - Le système Paparazzi...40
Figure 2.2 - Axes de roulis et de tangage...41
Figure 2.3 - Fonctionnement de MCU0 en pilotage manuel assisté et automatique...42
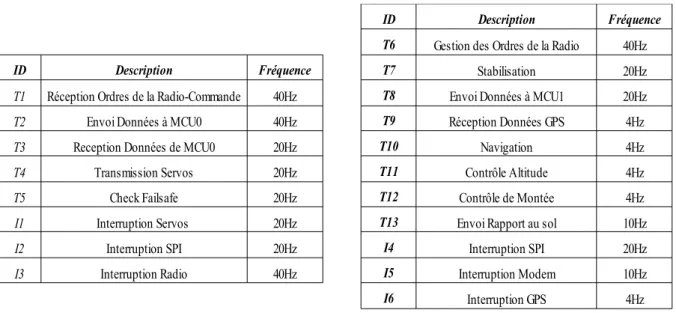
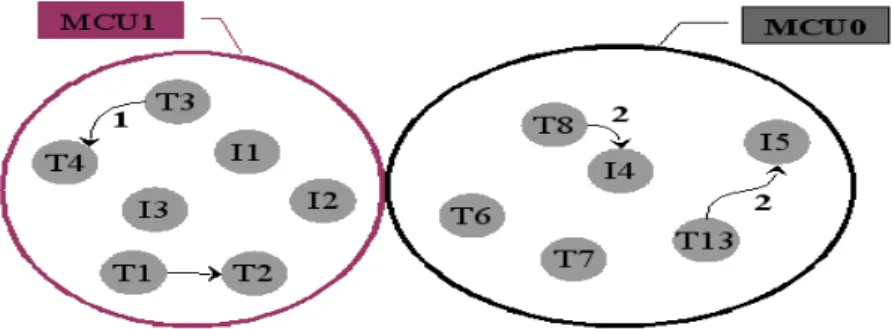
Figure 2.4 - Tâches et interruptions de MCU1 (a) et MCU0(b)...43
Figure 2.5 - Graphe de dépendances Mode Manuel...44
Figure 2.6 - Dépendances du Mode Automatique...44
Figure 2.7 - PCG de Fly_by_wire (a) et de l'autopilot (b)...45
Figure 2.8 - Le système embarqué de Paparazzi...46
Figure 2.9 - Représentation graphique du système MCU1...47
Figure 2.10 - Représentation graphique du système MCU0...47
Figure 2.11: Exemple d'ordonnancement...48
Figure 2.12 - Règles de précédences des tâches de PapaBench2...51
Figure 2.13 - PCG de MCU0 dans PapaBench2...52
Figure 2.14 - Répartition des Instructions...57
Figure 2.15 - Analyse de la complexité des boucles...58
Figure 2.16 - Statistiques du temps d'inactivité...62
Figure 2.17 - Comparaison des ordonnancements...62
Figure 3.1 - Code Source d'un programme C...70
Figure 3.2 - Construction des L-blocs...71
Figure 3.3 - Graphes de flot de contrôle ...71
Figure 3.4 - T-Graphs du programme analysé...72
Figure 3.5 - Arbre syntaxique du programme analysé...73
Figure 3.6 - Dépliage des appels de fonction dans l'arbre syntaxique (a) et dans le CFG (b)...74
Figure 3.7 - Les schémas logiques de deux compilations d'une même structure de boucle...75
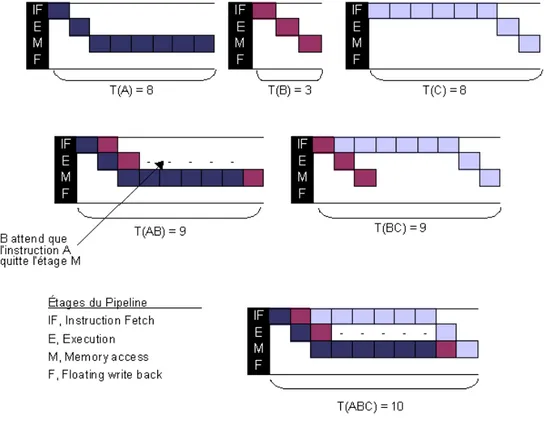
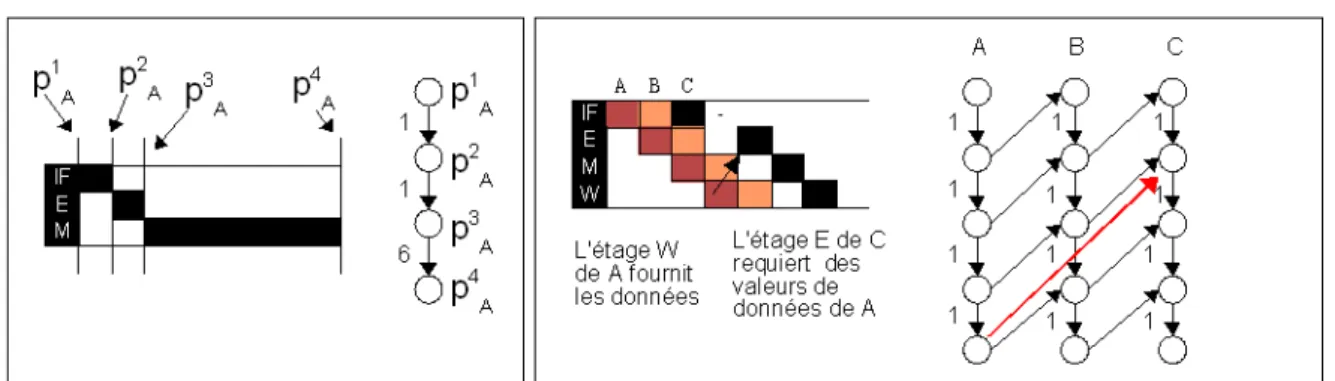
Figure 3.8 - Occupation du pipeline d'un processeur MicroSPARC...77
Figure 3.9 - Exemple de LTE...79
Figure 3.10 - Modèle de contraintes de l'exécution dans le pipeline...80
Figure 3.11 - Processeur à exécution ordonnée ayant deux pipelines parallèles...81
Figure 3.12 - Modèle de contraintes pour un processeur multi-pipeline...81
Figure 3.13 - Effets temporels calculés par simulation...83
Figure 3.14 - Exemple d'un processeur...84
Figure 3.15 - Exemple d'un graphe d'exécution (pipeline scalaire à exécution ordonnée)...84
Figure 3.16 - Graphe d'exécution (pipeline superscalaire à exécution non-ordonnée)...85
Figure 3.17 - Le découpage d'une adresse d'un bloc mémoire...89
Figure 3.18 - Cet exemple utilise un cache à 8 blocs et une mémoire de 32 blocs...90
Figure 3.19 - Traduction d'un graphe de flot de contrôle en un système de contraintes...94
Figure 3.20 - (a)Graphe de dépendances inter-modulaires, (b) appel de procédures...97
Figure 3.21 - Concaténation () de deux représentations wA et wB du pipeline...101
Figure 3.22 - Exemple...102
Figure 3.24 - Arbre Syntaxique et l'Arbre de Portée équivalent de la fonction impaire...106
Figure 3.25 - Préemption directe et préemption indirecte...112
Figure 3.26 - Scénario de Préemption...115
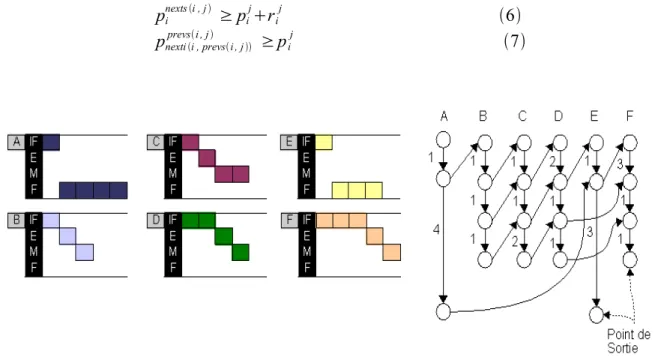
Figure 4.1 - Exemple d'un ordonnancement statique ...118
Figure 4.2 - Caractéristiques de la tâche...121
Figure 4.3 - Comportement des L-blocs d'une tâche T sachant l'état du cache IN...122
Figure 4.4 - Algorithme itératif de DFA...124
Figure 4.5 - Formules GEN, KILL...126
Figure 4.6 - Algorithme MUSTEXIT...127
Figure 4.7 - Analyse MAYEXIT...127
Figure 4.8 - Exemple d'un CFG d'une tâche...127
Figure 4.9 - Transformation d'un ordonnancement en graphe de flot de contrôle...129
Figure 4.10 - Formules GEN, KILL analyse inter-tâche...130
Figure 4.11 - Analyse inter-tâche MUST...131
Figure 4.12 - Analyse inter-tâche MAY...131
Figure 4.13 - Algorithme MUSTENTRY...133
Figure 4.14 - Analyse MAYEXIT...133
Figure 4.15 - Calcul du nombre de hit minimal et maximal...134
Figure 4.16 - Algorithme MUSTEXIT...138
Figure 4.17 - Algorithme MAYEXIT...139
Figure 4.18 - Algorithme DAMAGEMUST...140
Figure 4.19 - Algorithme DAMAGEMAY...141
Figure 4.20 - Analyse Inter-tâches MUST...143
Figure 4.21 - Analyse Inter-tâches MAY...143
Figure 4.22 - Analyse MUSTENTRY...144
Figure 4.23 - Analyse MAYENTRY...144
Figure 4.24 - Exemple1...146
Figure 4.25 - Exemple 2...147
Figure 5.1 - mcu0 (PapaBench1), nombre de hits total (cache 16 Ko)...155
Figure 5.2 - mcu0 (PapaBench2), nombre de hits total (cache 16 Ko)...155
Figure 5.3 - mcu1, nombre de hits total (cache 16 Ko)...156
Figure 5.4 - mcu0(PapaBench1), nombre de hits total (taille bloc 8 octets)...156
Figure 5.5 - mcu0(PapaBench2), nombre de hits total (taille bloc 8octets)...157
Figure 5.6 - mcu1, nombre de hits total (taille de bloc 8octets)...157
Figure 5.7 - mcu0 (PapaBench1), variation du nombre de hits total en fonction de A...158
Figure 5.8 - mcu0 (PapaBench2), variation du nombre de hits total en fonction de A...159
Figure 5.9 - mcu1, variation du nombre de hits total en fonction de A...159
Figure 5.10 - mcu0 (PapaBench1), impact de la variation de l'ordonnancement...160
Figure 5.11 - mcu0 (PapaBench2), impact de la variation de l'ordonnancement...161
Figure 5.12- mcu1, impact de la variation de l'ordonnancement...161
Figure 5.13- mcu0 (PapaBench1), réinjection / ENTRY...162
Figure 5.14 - mcu0 (PapaBench2), réinjection / ENTRY...163
Figure 5.15 - mcu1, réinjection / ENTRY...163
Figure 5.16 - mcu1, amélioration des WCET des tâches...164
Figure 5.17 - mcu0 (PapaBench1), amélioration des WCET des tâches...165
Figure 5.18 - mcu0 (PapaBench2), amélioration des WCET des tâches...166
Figure 5.19 - mcu0 (PapaBench1), Pourcentage de réduction du WCET global...167
Figure 5.20 - mcu0 (PapaBench2), Pourcentage de réduction du WCET global...167
I
NDEXDEST
ABLESTableau 2.1 - Tâches et interruptions de MCU0...50
Tableau 2.2 - Statistiques sur les Benchmarks temps-réel...56
Tableau 2.3 - Caractéristiques générales des deux versions...60
Tableau 3.1 - Les différentes catégories des références mémoires...93
Tableau 3.2 - Formules de calcul de WCET de [30]...99
Tableau 3.3 - Extension du schéma temporel pour prendre en compte les caches et le pipeline...100
Tableau 3.4 - Calcul du WCET d'une structure sachant son niveau d'imbrication dans une boucle ...103
Tableau 3.5 - Expressions par défaut pour chaque type de portée...106
I
NDEX DESF
ORMULES Formule 3.1 - Expression de calcul du WCET...95Formule 3.2 - Évaluation du WCET en tenant compte du cache d'instructions...96
Formule 3.3 - distribution de Gumbel...110
Formule 3.4 - estimation statistique du WCET...110
Formule 3.5 - relation entre ω et ε...110
Formule 3.6 - Calcul récursif du WCRT d'une tâche Ti...113
Formule 3.7 - estimation conservatrice du WCRT...115
Formule 3.8 - Estimation améliorée du WCRT...115
Formule 4.1 - Formule générale de DFA itératif...123
I
NTRODUCTIONP
ROBLÉMATIQUEDu métro sans conducteur au pilote automatique dans les avions, les systèmes temps-réel envahissent notre vie quotidienne. Ce monde du temps-réel est si vaste que ses technologies s'appliquent à divers secteurs tels que le contrôle d’une centrale nucléaire, les systèmes d’aide au pilotage des avions, les téléphones portables, le transport, la télécommunication, …. Les progrès accomplis en électronique et en informatique ont apporté beaucoup à l’augmentation de la puissance de calcul des machines et à l’amélioration de la performance de ces systèmes.
Les systèmes temps-réel se distinguent des autres systèmes informatiques par la prise en compte de contraintes de tempsdont le respect est aussi important que l'exactitude du résultat. Autrement dit, le système ne doit pas simplement délivrer des résultats exacts mais il doit les délivrer dans des délais imposés, c'est-à-dire que le système doit réagir à chaque événement de l'environnement externe avant l'échéance imposée par l'environnement pour le prochain événement.
On distingue le temps-réel strict ou dur (de l'anglais hard real-time) et le temps-réel souple ou mou (soft real-time) suivant l'importance accordée aux contraintes temporelles. Les systèmes temps-réel stricts ne tolèrent aucun dépassement de ces contraintes, ce qui est nécessaire si de tels dépassements peuvent conduire à des situations critiques, voire catastrophiques : pilote automatique d'avion, système de surveillance de centrale nucléaire, etc. À l'inverse, le temps-réel souple s'accommode des dépassements de contraintes de temps dans certaines limites au-delà desquelles le système devient inutilisable : visioconférence, jeux en réseau, etc.
On peut ainsi considérer qu'un système temps-réel strict doit respecter des limites temporelles données même dans la pire des situations d'exécution possibles. En revanche un système temps-réel souple doit respecter ses limites pour une moyenne de ses exécutions. On tolère un dépassement exceptionnel, qui sera peut être rattrapé à l'exécution suivante. Théoriquement, le concepteur d'un système temps-réel strict devrait être capable de prouver que les limites temporelles ne sont jamais dépassées quelle que soit la situation. Cette vérification est appelée test d'acceptabilité, analyse de faisabilité ou encore contrôle d'admission ; elle fait appel à la théorie de l'ordonnancement et sa vérification dépend de l'ordonnanceur utilisé et des caractéristiques des tâches du système.
Cette analyse requiert une connaissance du pire comportement temporel du système. Il est nécessaire de connaître en particulier les pires instants d'arrivées des tâches, et les temps
d'exécution dans le pire des cas des tâches. C'est sur l'obtention de cette dernière information
que porte notre étude.
Le temps d'exécution pire cas d'un programme peut être estimé en mesurant son temps d'exécution dans un environnement de test qui peut être un système réel ou un simulateur. Les mesures doivent être réalisées pour tous les jeux d'entrée possibles ou alors il faut être capable de définir un jeu d'entrée qui conduit certainement au temps d'exécution le plus long. Il existe un autre moyen de mesure du WCET en utilisant des méthodes d'analyse statique de son code sans avoir à l’exécuter sur le matériel cible.
En théorie, le test dynamique est approprié pour l'analyse du WCET du code. En effet, le temps d'exécution du programme est mesuré pour une exécution avec un jeu d'entrée particulier. Un outil de test idéal exécuterait le programme pour chaque ensemble possible de valeurs en entrée et mesurerait le temps d'exécution. Mais ceci n'est pas toujours possible en pratique car la complexité des programmes à analyser conduit à un nombre extrêmement grand de tests possibles. Si pour un programme donné, on a pu définir le jeu d'entrée pire cas, alors ces méthodes permettent d'obtenir une valeur précise du WCET notée « WCET réel ».
En revanche, les approches par analyse statique ont l'avantage d'être sûres. Cette sûreté des estimations a une contrepartie, les estimations obtenues sont parfois pessimistes. Ce pessimisme induit une surestimation des moyens matériels nécessaires au fonctionnement du système. Ces méthodes fournissent alors une borne supérieure du WCET appelée aussi « WCET estimé ». Nous proposons dans ce manuscrit une méthode qui permet de réduire ce pessimisme.
A
PPROCHELes propositions de cette thèse sont classées dans la catégorie des méthodes par analyse statique du code.
La plupart des méthodes d'évaluation du WCET par analyse statique, proposées dans la littérature, calculent le WCET d'une seule tâche en considérant des hypothèses conservatrices sur l’état du matériel qui garantissent la condition nécessaire et suffisante, le WCET estimé est supérieur ou égal au WCET réel, pour qu'il n'y ait pas un risque de violation des contraintes temps-réel. Bien que ces méthodes produisent des approximations sûres sous réserve de certaines hypothèses sur le processeur, elles ignorent plusieurs facteurs des systèmes temps-réel multi-tâches, essentiellement l'enchaînement des tâches qui affectent naturellement la précision du WCET estimé.
Nous proposons une nouvelle approche, qui s’applique aux systèmes temps-réel stricts, multi-tâches. Cette méthode étudie le comportement d’un ordonnancement statique des tâches d’une application temps-réel, s'exécutant sur un processeur, pour analyser le comportement
inter- et intra tâche de la mémoire cache. Le but est de remplacer les hypothèses conservatrices qui supposent un état vide ou indéfini du cache par un état bien défini avant l’exécution de chaque tâche de l’ordonnancement. Ceci va nous permettre d’optimiser l’estimation du WCET de ces tâches en utilisant la trace de l’exécution d’autres tâches dans le cache.
Comme tout logiciel, le calcul du WCET nécessite des expérimentations, des évaluations et des comparaisons d’où la nécessité des benchmarks qui représentent les fonctionnalités des applications temps-réel. Cependant, il est très difficile de se procurer une application réelle pour tester le système avant de le mettre en utilisation vu les critères de confidentialité dont s'entourent les industriels.
En même temps, les benchmarks temps-réel sont très rares et sont constitués généralement d'un ensemble d'algorithmes de base utilisés dans les applications temps-réel. Ces benchmarks sont déconnectés des particularités des applications embarquées telles que la gestion des capteurs et actionneurs. Les fonctions qu'ils fournissent sont exécutées seules et non dans le contexte d'une application complète. Il est ainsi impossible de les utiliser pour expérimenter l’impact de l’enchaînement des tâches sur l’estimation du WCET. Comme solution à ce problème, nous avons conçu un benchmark temps-réel, PapaBench, décrivant une application temps-réel complète pour le pilotage d'un UAV (Unmanned Aerial Vehicle). Il a été conçu afin de constituer une base utile pour les expérimentations de calcul de WCET par méthodes statiques ou dynamiques mais il peut être aussi utile pour les analyses d'ordonnancement.
P
LANL’organisation du document est la suivante. Le premier chapitre présente les caractéristiques des systèmes temps-réel embarqués à contraintes temps-réel stricts, l'ordonnancement temps-réel et les politiques d'ordonnancement les plus utilisées, et pour terminer, il explique notre choix de la norme AADL pour modéliser les applications temps-réel.
Nous présentons au deuxième chapitre, les deux versions de notre benchmark temps-réel PapaBench1 et 2, leur intérêt, leurs différences et leur utilité pour les expérimentations des approches de calcul de WCET et pour l'étude des ordonnancements.
Le troisième chapitre passe en revue les principales méthodes d'estimation du temps d'exécution pire cas, statiques et dynamiques, intra-tâche et multi-tâches. Le quatrième chapitre décrit notre approche qui permet d'optimiser l'estimation du WCET des tâches en étudiant leurs contextes d'exécution. Nous nous intéressons surtout à l'analyse du comportement de l'ordonnancement de ces tâches sur le cache d'instructions pour construire les états du cache à l'entrée de chaque tâche. Ces états remplacent les hypothèses conservatrices utilisées par les méthodes d'analyse statique usuelles pour fournir des estimations sûres mais pessimistes du temps d'exécution pire cas. Ainsi chaque tâche
bénéficie des traces d'exécutions des tâches précédentes, ce qui va nous permettre de détecter les faux défauts de cache induits par les hypothèses conservatrices, et ainsi d'optimiser l'estimation du WCET de la tâche. Nous introduisons à la fin de ce chapitre un algorithme itératif basé sur notre approche qui permet de choisir le meilleur ordonnancement des tâches d'une application temps-réel pour une politique d'ordonnancement fixée au départ.
Les résultats expérimentaux présentés au cinquième chapitre prouvent l'intérêt de notre approche. Ces expérimentations sont effectuées sur les deux versions de PapaBench pour plusieurs configurations du cache et pour plusieurs ordonnancements. Nous montrons la variation du WCET global de l'application en fonction de la taille du cache, de la taille du bloc de cache, du degré d'associativité et de la politique d'ordonnancement. Enfin nous concluons cette étude en mettant en avant les apports de notre travail et les perspectives ouvertes par ce dernier.
C
HAPITRE
1
S
YSTÈMES EMBARQUÉS ET TEMPS-
RÉELLes systèmes temps-réel sont de plus en plus présents dans de nombreux secteurs d'activités comme l'aéronautique, l'automobile, l'énergie, les télécommunications, le contrôle de processus industriel et le secteur militaire. Ces systèmes réalisent souvent des tâches complexes qui sont souvent critiques. Ils sont soumis aux contraintes temporelles de l'environnement qu'ils doivent respecter. En effet, pour qu'une application temps-réel soit valide, elle doit non seulement fournir un résultat correct, mais elle doit le délivrer en respectant certaines contraintes temporelles qui sont le plus souvent des échéances de terminaison au plus tard. En d'autres termes un système temps-réel se distingue d'un système traditionnel par sa capacité à garantir l'exécution des tâches en respectant certaines échéances.
Un système temps-réel est un système réactif qui réagit avec son environnement à un rythme imposé par cet environnement. Il peut être distribué ou embarqué ou embarqué/distribué. Comme notre étude s'intéresse essentiellement au systèmes embarqués temps-réel qui sont le plus souvent distribués, ce chapitre présente la particularité de chacune de ces catégories. Nous définissons aussi l'ordonnancement temps-réel et nous présenterons une vue générale des politiques d'ordonnancement utilisées par la suite.
1. D
ÉFINITIONS
1.1. S
YSTÈMER
ÉACTIFLe concept de système réactif a été défini dans la littérature, par plusieurs travaux. La définition suivante est donnée par [1]:
Définition 1 (Système réactif) Un système réactif est un système qui réagit continûment
avec son environnement à un rythme imposé par cet environnement. Il reçoit, par l'intermédiaire de capteurs, des entrées provenant de l'environnement, appelées stimuli, réagit à tous ces stimuli en effectuant un certains nombre d'opérations et produit, grâce à des actionneurs, des sorties utilisables par l'environnement, appelées réactions ou commandes
Chapitre 1 - Systèmes embarqués et temps-réel 1.Définitions (voir figure 1.1).
Dans un système réactif, la validité d'une commande ne dépend pas uniquement de la validité de la valeur de son résultat, mais aussi de son instant de délivrance. Parfois, dans la littérature, le système réactif est appelé système de contrôle, et l'environnement système contrôlé [2].
Un exemple très simple d'un système réactif est celui de la régulation de niveau d'eau dans un réservoir (figure 1.2). Dans cet exemple, l'environnement est constitué d'un réservoir d'eau, d'une vanne et de deux capteurs sensibles à la présence d'eau. Supposons qu'à l'instant t=0 le niveau d'eau dans le réservoir soit le niveau du capteur 1 et que la vanne soit ouverte. Le rôle de ce système est de maintenir le niveau d'eau entre les deux capteurs 1 et 2: si le capteur 2 est mouillé le système doit envoyer une commande de fermeture de la vanne avant que le réservoir déborde, et si le capteur 1 est sec le système doit envoyer une commande d'ouverture de la vanne.
Les exigences fonctionnelles et temporelles sont donc deux caractéristiques essentielles des Figure 1.2 - Exemple d'un système réactif
Chapitre 1- Systèmes embarqués et temps-réel 1.Définitions systèmes réactifs. D'une part, Les exigences fonctionnelles imposent au système de produire des résultats corrects du point de vue des valeurs du domaine. D'autre part, les exigences temporelles imposent au système de produire ces résultats à temps, c'est-à-dire que le système doit réagir à chaque événement de l'environnement externe avant l'échéance imposée par l'environnement pour le prochain événement.
Suivant les exigences temporelles d'un système réactif, nous distinguons deux classes de systèmes:
➢ Systèmes réactifs temps-réel stricts – ces systèmes doivent impérativement garantir le respect des contraintes de temps imposées par l'environnement. Ces contraintes sont
cruciales pour de tels systèmes car une erreur temporelle peut avoir des conséquences catastrophiques (humaines, matérielles, financières, écologiques, etc.). Les systèmes de contrôle de trafic aérien et de conduite de missile sont deux exemples de ces systèmes.
➢ Systèmes réactifs temps-réel souples - les contraintes temporelles de ces systèmes sont
définies pour assurer une qualité de service mais peuvent exceptionnellement être violées sans mettre en cause la sécurité du matériel et des personnes impliquées. Il s'agit d'exécuter les fonctions dans les meilleurs délais. Par exemple, le traitement vidéo d'un système multimédia peut omettre quelques images sans que la qualité visuelle ne soit détériorée.
1.2. S
YSTÈME DISTRIBUÉ ETS
YSTÈME EMBARQUÉNotre étude porte essentiellement sur les systèmes temps-réel embarqués. Comme ces systèmes possèdent le plus souvent une architecture distribuée surtout pour des raisons de sécurités et de performance, ce paragraphe fournit la définition d'un système distribué et d'un système embarqué.
Définition 2 (Système distribué) Un système distribué est tel que son architecture matérielle
est composée de plusieurs machines multiprocesseurs ou monoprocesseur reliées entre elles par un ensemble de moyens de communication (mémoire partagée, bus, liaisons point-à-point ...). En général, cette architecture distribuée est hétérogène – les processeurs respectivement moyens de communication ont des caractéristiques physiques différentes.
Définition 3 (Système embarqué) Lorsqu'un système temps-réel est physiquement intégré à
l'environnement qu'il contrôle et qu'il est soumis aux mêmes contraintes physiques (température, pression, ...) que son environnement, il est dit embarqué. Un système embarqué est un système réactif ayant des ressources limitées, telles que la mémoire, la consommation d'énergie, la taille, le poids, la puissance de calcul ...
Un système temps-réel intégré dans un robot mobile est un système embarqué, alors qu'un système de contrôle de bras de robot n'en est pas un. Dans le premier cas, le système temps-réel fait partie intégrante du robot, il se déplace avec lui et il est ainsi soumis aux mêmes contraintes physiques externes. Dans le deuxième cas, le système peut être dans une
Chapitre 1 - Systèmes embarqués et temps-réel 1.Définitions armoire électrique placée dans une pièce différente de celle où se situe le robot. Ce système temps-réel est donc indépendant du bras manipulateur, il n'est pas intégré à son environnement (bras + objets manipulés).
Les systèmes embarqués sont généralement soumis à des contraintes spécifiques de coûts pris au sens large du terme. Ces contraintes sont dues, d'une part, au type d'applications couvertes par ce type de système et, d'autre part, à l'intégration du système à son environnement. Ces contraintes particulières de coût sont de plusieurs types : encombrement, consommation d'énergie, prix, etc. Un système possède souvent des ressources limitées, telles que sa taille (un avion, PDA – Personal Digital Assistant).
1.3. S
PÉCIFICATION DES SYSTÈMES RÉACTIFS EMBARQUÉSNous nous intéressons dans la suite de ce document aux systèmes réactifs embarqués à contraintes temps-réel strictes. Pour des raisons de lisibilité, nous écrivons « système temps-réel strict » au lieu de « système réactif embarqué à contraintes temps-réel strictes ».
La spécification de ces systèmes est réalisée en trois phases complémentaires et dépendantes :
➢ La spécification fonctionnelle – consiste à définir la boucle de contrôle avec ses exigences fonctionnelles
➢ La spécification architecturale – consiste à définir l'architecture matérielle qui doit implanter cette spécification
➢ La spécification des contraintes – consiste à attribuer des propriétés temporelles et matérielles à l'exécution de la boucle de contrôle sur l'architecture.
1.3.1. La boucle de contrôle
La boucle de contrôle d'un système réactif représente les fonctions nécessaires au contrôle et à la commande de l'environnement. Elle est composée d'un ensemble de composants logiciels, que nous appelons tâches. Chacun assure une fonctionnalité spécifique du système – telle que la commande d'une vanne de régulation.
Définition 4 (Tâche) – On définit une tâche comme une séquence ordonnée indivisible
d'instructions à laquelle on peut associer des propriétés temporelles devant être respectées à l'exécution.
La boucle de contrôle peut être modélisée par un graphe de dépendances. Les sommets représentent les tâches et les arcs représentent les dépendances de données et de contrôle entre ces tâches. Une dépendance de données entre deux tâches T1 et T2, est telle que T1 apparaît
avant T2 dans le graphe de dépendances, signifie que T2 commencera son exécution après
avoir reçu les données de sortie de T1. Tandis qu'une dépendance de contrôle, signifie que T1
Chapitre 1- Systèmes embarqués et temps-réel 1.Définitions échange de données entre ces deux tâches. Nous utilisons la notation T1 < T2 pour représenter cette dépendance de donnée, ainsi T2 dépendant des résultats de T1.
1.3.2. L'architecture matérielle
Cette étape consiste à caractériser tous les composants de l'architecture et à choisir la topologie du réseau de communication:
➢ Processeurs – la spécification de la boucle de contrôle ne peut être complètement indépendante de l'architecture, puisque les attributs temporels des tâches sont en relation directe avec le type de processeurs utilisé. Ainsi la durée d'exécution d'une tâche est différente d'un processeur à un autre dans le cas d'une architecture hétérogène.
➢ Capteurs et actionneurs – les systèmes réactifs utilisent des capteurs et des actionneurs pour interagir avec l'environnement extérieur qu'ils contrôlent. Dans le cas d'une architecture distribuée, le choix de l'emplacement physique de ces capteurs / actionneurs sur l'architecture est important dans la conception de ces systèmes.
➢ Moyen de communication – les processeurs de l'architecture distribuée communiquent en utilisant deux types de communication : envoi de messages ou partage de données. Pour gérer les communications inter-processeurs entre des tâches dépendantes, placées sur des processeurs distincts, il est donc nécessaire de connaître le type des communications et le type de média de communication (mémoire partagée, bus, lien point-à-point, ...).
1.3.3. Les contraintes temporelles et matérielles
Les contraintes temporelles s'expriment, pour chaque tâche de la boucle de contrôle, en termes de sa date début d'exécution, sa période, et sa date d'échéance. La date de début d'exécution est liée à l'occurrence de certains événements ou à la satisfaction de certaines conditions (i.e. la réception de données), tandis que l'échéance est liée au comportement exigé par l'environnement.
La spécification de la boucle de contrôle n'est pas complètement indépendante de l'architecture : par exemple, afin de réduire le câblage, certains capteurs et actionneurs doivent être gérés par des processeurs spécifiques de l'application. Il est donc nécessaire de spécifier des contraintes matérielles pour chaque composant de cette boucle de contrôle. Cela conduit à attribuer à chacun, un ou plusieurs processeurs de l'architecture matérielle qui peuvent l'exécuter.
2. O
RDONNANCEMENT
TEMPS
-
RÉEL
Chapitre 1 - Systèmes embarqués et temps-réel 2.Ordonnancement temps-réel elle consiste à distribuer et à ordonnancer les tâches sur l'ensemble des composants de l'architecture matérielle (processeurs, bus, ...). La distribution est une allocation spatiale d'une tâche à une ressource, alors que l'ordonnancement est une allocation temporelle d'une tâche sur une ressource. Le but est de distribuer et d'ordonnancer toutes les tâches pour former un programme. Ces questions d'ordonnancement ont donné lieu à de nombreux travaux [3 à 12].
Définition 5 (Ordonnancement temps-réel) – L'ordonnancement est le terme informatique
désignant le mécanisme permettant de réaliser la sélection, parmi plusieurs composants de la boucle de contrôle, de celui qui va obtenir l'utilisation d'un composant de l'architecture pour s'exécuter de manière à optimiser un ou plusieurs critères. L'ordonnancement temps-réel a une particularité qui nécessite de respecter des contraintes temps-réel. Le processus qui réalise une telle sélection, et donc qui définit un ordre d'exécution entre les composants de la boucle de contrôle, est appelé algorithme d'ordonnancement.
Il existe, pour une architecture donnée, un grand nombre de possibilités d'ordonnancement et de distribution mais seulement un certain nombre d'entre elles permet de satisfaire à la fois aux contraintes liées à la boucle de contrôle (dépendances de données) et aux contraintes temps-réel (aspect temporel) mais aussi aux contraintes de l'architecture (aspect matériel). Cet espace de solutions valides est d'autant plus restreint que les contraintes sont fortes. C'est le cas des systèmes temps-réel embarqués qui sont des applications souvent complexes et dont les contraintes de coût se traduisent généralement par de fortes contraintes matérielles.
2.1. S
TRATÉGIES D'
ORDONNANCEMENTUn système temps-réel strict doit impérativement garantir le respect des échéances fixées pour l'exécution des tâches. Le dépassement de l'échéance par au moins une tâche temps-réel stricte peut conduire à une défaillance générale du système. Pour cette raison, on cherche à avoir la certitude absolue, avant exécution, que toutes les échéances seront toujours respectées lors de l'exécution de l'application.
Une politique d'ordonnancement est appliquée pour vérifier le respect des échéances des tâches, des contraintes matérielles et des dépendances de données. Cette politique est constituée d'une part de l'algorithme d'ordonnancement et d'autre part du test d'ordonnançabilité. L'algorithme d'ordonnancement est chargé de décider de l'ordre d'exécution des tâches. Tandis que, le test d'ordonnançabilité (appelé aussi analyse d'ordonnançabilité, ou analyse de faisabilité) permet de vérifier que l'algorithme choisi permettra à toutes les tâches de respecter toutes le contraintes énumérées ci-dessus en toutes circonstances (voir § 2.2).
2.1.1. Modèle de tâche
La majorité des stratégies d’ordonnancement fait appel à la notion de tâche. On trouve dans la littérature les définitions de plusieurs modèles de tâche [3], [4], [5]. Les tâches sont
Chapitre 1- Systèmes embarqués et temps-réel 2.Ordonnancement temps-réel indépendantes mais elles peuvent partager des variables globales.
Définition 6 (Tâche périodique) – Une tâche périodique, comme son nom l’indique, doit être exécutée à des intervalles de temps fixés (ou périodes). Dans sa version la plus générale, une tâche périodique est définie par le quadruplet Ti (Φi; Ci ; Pi ;Di) où Φi ≥ 0, Ci > 0 et
Ci ≤ min(Pi, Di), Pi > 0, et Di > 0. La phase Φi de la tâche dénote la date de son premier
réveil, Ci son temps d’exécution pire cas ou WCET(Worst Case Execution Time), Pi sa
période d’exécution, et Di son échéance relative, c’est-à-dire le temps maximal dont on
dispose pour exécuter la tâche. La période d’exécution de la tâche correspond à la contrainte de cadence qui est imposée à la tâche [4], [5].
Définition 7 (Tâche apériodique, sporadique) – Les tâches apériodiques et sporadiques
sont des tâches exécutées à des instants à priori non connus. L’exécution de ces tâches est généralement déclenchée par un événement provoqué par le processus contrôlé. Les tâches apériodiques ont aussi des contraintes temporelles, par exemple après le déclenchement de son exécution, une tâche apériodique doit se terminer dans un temps prédéfini. Cependant les tâches apériodiques n'ont pas d'échéance stricte, elles ont des échéances particulièrement importantes pour tenir compte des événements critiques du système [4]. La période d’exécution n’intervient donc pas dans le modèle de ces tâches. On distingue une tâche sporadique d’une tâche apériodique par la connaissance d’un intervalle de temps minimum entre deux exécutions de la tâche sporadique.
2.1.2. Ordonnancement préemptif, non-préemptif
Lorsque l’exécution d’une tâche active peut être interrompue à tout moment pour allouer le processeur à une autre tâche jugée plus prioritaire, l’ordonnancement est dit préemptif. Un ordonnancement est non-préemptif si chaque tâche s'exécute de son démarrage à sa terminaison sans interruption [6].
Un ordonnancement préemptif apporte un sur-coût sur le temps de calcul. En effet, au moment de la préemption, le contexte de la tâche préemptée doit être sauvegardé. Ce contexte doit être restauré lorsque la préemption s’achève, c’est-à-dire au moment où l’exécution de la tâche préemptée doit reprendre. Par contre, un ordonnancement préemptif permet, dans certains cas, de garantir des contraintes temporelles impossibles à garantir avec un ordonnancement non-préemptif. On peut distinguer deux types de préemption, celle déclenchée par des interruptions matérielles (événement extérieur) et celle déclenchée par les algorithmes d’ordonnancement (tâche prioritaire, synchronisation).
Dans le cadre d’un ordonnancement préemptif, il est nécessaire de garantir qu’une ressource n’est accédée que par une seule tâche à la fois. L’accès en exclusion mutuelle à une ressource peut engendrer un phénomène d’inversion de priorité au cours duquel l’exécution d’une tâche de haute priorité voulant accéder à une ressource est retardée par l’exécution de tâches de plus basse priorité, dont l’une est rendue non-préemptible pendant l’accès à cette même ressource [7], [8].
Chapitre 1 - Systèmes embarqués et temps-réel 2.Ordonnancement temps-réel
2.1.3. Ordonnancement en ligne, hors ligne
L’ordonnancement peut être calculé lors de la conception du logiciel, dans ce cas, l’ordonnancement est dit hors ligne. Il consiste à analyser la boucle de contrôle du système et ses contraintes temporelles afin de définir la séquence d’exécution des tâches qui permet de respecter ses contraintes, temporelles et matérielles (cf. §2.2). Dans ce cas, l’exécutable qui gère l’application est simple car le code à exécuter est composé d’une séquence d’opérations insérées dans une boucle principale qui représente la boucle de contrôle.
Cette approche de l’ordonnancement nécessite une spécification rigoureuse de la boucle de contrôle afin de le calculer automatiquement par des outils logiciels. C’est généralement celle qui est utilisée quand cette boucle est spécifiée avec des langages synchrones car la réalisation d’une séquence d’exécution des opérations a l’avantage de permettre de facilement conserver et de s’assurer que l’ordre des événements, défini par la spécification, est conservé à l’exécution et donc que les propriétés mises en évidence par la vérification sont conservées par l’implantation.
Lorsque l’ordonnancement est calculé pendant l’exécution, on parle d’ordonnancement en ligne. Dans ce type d’approche, l’exécutable est construit autour d’un ordonnanceur chargé de gérer l’activation, la mise en attente et l’arrêt des tâches [8], [9]. Un ordonnancement en ligne est plus coûteux à l’exécution qu’un ordonnancement hors ligne car, en plus des calculs liés la boucle de contrôle de l’application, le calculateur doit aussi réaliser les calculs liés à l’ordonnanceur. De plus, un ordonnancement hors ligne est prédictible car la séquence de calcul est connue avant l’exécution alors que dans un ordonnancement en ligne, l’ordre d’exécution est déterminé par l’ordonnanceur, il n’est donc pas toujours possible de connaître à l’avance l’ordre précis d’exécution des tâches. Un ordonnancement en ligne sera par contre plus flexible qu’un ordonnancement hors ligne, en ce sens qu’il pourra plus facilement prendre en compte les événements dont l’occurrence est imprévisible (tâches apériodiques ou sporadiques).
D'une manière générale, un ordonnancement est dit statique s'il possède les caractéristiques suivantes :
➢ Construction hors ligne d'une séquence complète de planification sur la base de tous les paramètres temporels des tâches. Cette séquence est un procédé défini par l'utilisateur
➢ Régularité temporelle du monde externe – les événements asynchrones sont observés à des dates précises.
➢ L'ordonnancement des tâches est régi par un calendrier. C'est une table spécifiant la liste des différents processus à activer qui est exploitée cycliquement.
➢ L'ordonnancement est ainsi périodique.
➢ Le temps est découpé en unité de base insécable appelé cycle de base.
Chapitre 1- Systèmes embarqués et temps-réel 2.Ordonnancement temps-réel
➢ Un ordonnanceur en ligne qui ré-évalue à chaque nouvelle demande la tâche qui doit être exécutée.
➢ Il permet de tenir compte des tâches apériodiques et sporadiques
2.1.4. Ordonnanceur à priorités statiques, dynamiques
L’ordonnanceur est la fonction de l’exécutable chargée de choisir l’ordre d’exécution des tâches dans un ordonnancement en ligne. Différentes hypothèses simplificatrices sont généralement faites :
➢ les propriétés temporelles d’une tâche sont constantes tout au long de la durée de vie de l’application ;
➢ les tâches sont indépendantes, le découpage de l’application en un ensemble de tâches doit donc être judicieux.
Le choix de l’ordonnancement est basé sur des priorités affectées aux tâches. A des intervalles de temps réguliers, l’ordonnanceur détermine la tâche à exécuter parmi une liste. Ce choix est réalisé en comparant la priorité d’exécution de la tâche en cours à la priorité de chacune des tâches de la liste. Généralement les priorités des tâches sont déterminées à la compilation et sont invariantes pendant l’exécution de l’application, on parle d'ordonnancement à priorités statiques. Dans certains exécutables, les priorités peuvent varier pendant l’exécution. Dans ce cas l’ordonnancement est dit ordonnancement à priorités
dynamiques. L’assignation des priorités aux tâches est parfois empirique, elle repose sur le
savoir-faire des programmeurs de l’application. Généralement, elle repose sur des règles définies par la politique d’ordonnancement (cf §2.2).
2.2. A
LGORITHMES D'
ORDONNANCEMENT CLASSIQUESDans cette section, nous donnons une idée générale de quelques politiques d'ordonnancements que nous avons utilisées pour effectuer nos expérimentations.
2.2.1. Rate Monotonic (RM)
Dans cette approche, l'échéance D de la tâche est toujours égale à sa période P et la priorité associée à l'exécution de la tâche est inversement proportionnelle à sa période d'exécution P. C'est un ordonnancement à priorités statiques. Les tâches sont périodiques et indépendantes.
Il a été démontré qu'avec ce type d'ordonnancement pour qu'une implantation soit acceptable (pour que les échéances de toutes les tâches soient satisfaites), il suffit que l'ensemble des tâches respecte la condition suivante (test d'ordonnançabilité) [10], [11]:
U =
∑
i=1
n C
i
Pi
Chapitre 1 - Systèmes embarqués et temps-réel 2.Ordonnancement temps-réel La limite de ce test d'ordonnançabilité est fonction du nombre de tâches du système. Notons que :
lim
n ∞n 2
1 /n
−1=ln 2≈0.69
Ceci implique qu'un ensemble de tâches est ordonnançable si U ≤ 0.69, mais il se peut qu'il ne soit pas ordonnançable si 0.69 < U ≤ 1.
Cette politique d'ordonnancement est beaucoup utilisée étant donné qu'elle utilise des priorités fixes et qu'elle est donc simple à mettre en œuvre.
La figure 1.3 montre l'ordonnancement de trois tâches périodiques T1, T2
et T3 d'un système temps-réel, caractérisées par une phase = 0 et, des
WCET, des échéances et des périodes spécifiques. L'ordonnancement Rate Monotonic autorise la préemption des tâches. La jième activation d'une
tâche Ti est notée par Ti,j. Comme la tâche T2 possède la plus grande
priorité, elle est exécutée en premier. Elle est suivie par les tâches T3 puis T1. Comme T2 possède une priorité supérieure à celle de T1, elle
interrompt l'exécution de celle-ci à l'instant t = 5 correspondant à sa période d'exécution. Les flèches vertes correspondent au temps d'activation des tâches – la tâche est prête à être exécutée (comme la phase est nulle, ces flèches sont marquées à la fin de la période des tâches sauf pour la première activation car on suppose que toutes les tâches sont prête à t = 0).
2.2.2. Earliest Deadline First (EDF)
La priorité est ici déterminée en fonction de l'échéance relative D de la tâche et c'est la tâche qui a la plus petite échéance absolue di = nPi + Di qui est la plus prioritaire, où n est le
nombre d'exécutions antérieures de la tâche [12]. Dans le cas où il existe deux tâches qui ont la même échéance absolue, l'une d'elles est choisie d'une manière arbitraire. Comme les échéances relatives des instances de tâches changent, EDF est un ordonnancement à priorités
Chapitre 1- Systèmes embarqués et temps-réel 2.Ordonnancement temps-réel dynamiques.
Quand les tâches sont à échéances sur requête (Pi = Di), on dispose de la condition
nécessaire et suffisante d'ordonnançabilité U =
∑
i=1
n C
i
Pi
≤ 1 . Pour des tâches à échéances quelconques, cette condition est seulement nécessaire et une condition suffisante est alors
∑
i=1 n C i Di ≤ 1 .Cette politique d'ordonnancement est plus difficile à mettre en oeuvre que celle du Rate Monotonic, car il est parfois difficile de fixer les échéances des tâches. Par contre, grâce à l'exploitation de l'échéance, paramètre commun à tous les types de tâches, la prise en compte des tâches sporadiques et apériodiques est facilitée [11].
EDF est plus avantageux que RM vu qu'on n'a pas besoin d'attribuer des priorités aux tâches. De plus, c'est un algorithme optimal car si un ensemble de tâches est ordonnançable, U ≤ 1, donc il est sûrement ordonnançable par EDF, ce n'est pas un cas général pour RM (voir §2.5.1). Ensuite, EDF peut ordonnancer n'importe quel ensemble de tâches ordonnançables par RM mais la réciproque n'est pas correcte. Enfin, EDF utilise le processeur avec un temps d'inactivité inférieur ou égal à celui fournit par RM [13].
La figure 1.4 montre l'ordonnancement EDF des tâches T1(0,3,7,20),
T2(0,2,4,5) et T3(0,1,8,10). T2 est la tâche prioritaire car elle possède
la plus petite échéance relative. Elle est ensuite suivie de T1 puis de
T3. Notons que les flèches vertes indiquent la date d'activation de la
tâche tandis que les rouges montrent la date d'échéance relative de chaque tâche. On peut également remarquer que si on garde les mêmes échéances que dans l'exemple de la figure 1.3, nous obtiendrons le même ordonnancement avec EDF.
2.2.3. Deadline Monotonic (DM)
C'est un algorithme d'ordonnancement à priorité fixe tel que la priorité d'une tâche est Figure 1.4 - Exemple d'ordonnancement EDF
Chapitre 1 - Systèmes embarqués et temps-réel 2.Ordonnancement temps-réel inversement proportionnelle à son échéance relative. Pour cet algorithme, l'échéance relative d'une tâche peut être inférieure ou égale à sa période – D ≤ P [11]. Si l'échéance des tâches est égale à leur période, l'algorithme est équivalent au Rate Monotonic.
Si nous considérons l'ensemble des tâches de la figure 1.4, nous obtiendrons le même ordonnancement qu'avec EDF.
2.2.4. Least Laxity First (LLF)
Cet algorithme est une variante d'EDF, il est donc basé sur le calcul dynamique des priorités des tâches. A chaque décision d'ordonnancement, on augmente la priorité de chaque tâche en fonction de leur marge temporelle (Laxity). Celle dont la laxité est la plus petite sera alors la plus prioritaire.
La laxité li d'une tâche T (Pi, Ci, Di) est définie comme suit:
li= Di− t ci '
où t, temps courant et c'i , temps de calcul restant (cf figure 1.5).
3. M
ODÉLISATION
EN
AADL
Les systèmes temps-réel offrent de plus en plus de fonctionnalités et ont des domaines d'application toujours plus nombreux que ce soit dans le monde industriel, ou sous forme embarquée dans l'automobile et l'aviation. Les langages de conception doivent permettre de maîtriser la complexité de tels systèmes, d'améliorer leur qualité et de minimiser les coûts de développement. Ces langages de description d'architecture sont très utiles car ils permettent l'introduction des méthodes formelles et des modèles de technologie dans l'analyse des architectures de logiciel et de système [14].
Chapitre 1- Systèmes embarqués et temps-réel 3.Modélisation en AADL La norme AADL, Architecture Analysis & Design Language a été développée pour les systèmes embarqués temps-réel de sûreté critique. Ces systèmes supportent l'utilisation de diverses approches formelles pour analyser l'impact de la composition des systèmes matériels et logiciels et pour réaliser la génération du code de système répondant aux normes de qualités et de performance prévues. AADL, est basée sur le langage MetaH [15]. Il inclut des profils UML utilisés pour l'avionique, l'espace, les véhicules à moteur, la robotique et d'autres domaines en temps-réel de traitements concurrents comprenant des applications de sûreté critique.
Le standard international d'AADL a été développé par la SAE (Society of Automotive Engineers) depuis 2001. La version 1.0 a paru en 2004. Le comité de standardisation comporte les principaux acteurs de l'industrie avionique et aérospatiale, en Europe comme aux USA (Honeywell, ESA, Airbus, Rockwell Collins, EADS, AMCOM, NIST, Boeing, etc).
3.1. C
HOIX D'AADL
Le modèle AADL [16], [17] décrit entièrement un système embarqué. Comme AADL possède une description graphique et textuelle, il permet de comprendre plus facilement le fonctionnement de l'application.
De plus, le langage AADL peut être utilisé pour réaliser des traitements automatiques. Par exemple, on peut générer plusieurs ordonnancements à partir de la description. Nous utilisons CHEDDAR [18] pour accomplir cette tâche. CHEDDAR est un outil qui permet de générer des ordonnancements d'une liste de tâches bien définie. Il est développé et maintenu au LISYC de l'université de Brest. Nous allons utiliser cet outil pour expérimenter notre approche de calcul du WCET sur l'application complète
Dans le cadre de l'analyse statique, bien que le modèle AADL soit basé sur une application réelle et vu que nous ne réalisons pas de simulations fonctionnelles, nous pouvons le changer librement selon nos besoins expérimentaux. Nous pouvons ajouter / supprimer des composants, changer des propriétés et / ou ajouter de nouvelles propriétés pour évaluer les paramètres de l'application. Comme nous sommes spécifiquement intéressés par les contraintes temporelles pour le calcul du WCET et pour l'analyse d'ordonnancement, AADL peut être très utile pour évaluer ces propriétés sans avoir à changer la structure de l'application.
3.2. AADL : V
UEG
ÉNÉRALELe SAE-AADL a été développé pour les systèmes temps-réel embarqués qui ont des contraintes critiques de ressources (taille, poids, puissance), des contraintes de réponse en temps-réel, de tolérance des fautes, et de matériel spécialisé d'entrée-sortie, et qui doivent être certifiés à des niveaux élevés de fiabilité. AADL a été conçu pour servir de base à l'analyse et à la génération des systèmes embarqués basés sur des modèles. La notation a été conçue
Chapitre 1 - Systèmes embarqués et temps-réel 3.Modélisation en AADL comme un noyau de langage extensible avec des sémantiques bien définies et des présentations graphiques et textuelles.
Le langage est employé pour décrire la structure d'un système temps-réel embarqué comme un ensemble de composants logiciels et matériels. Il supporte les spécifications des interfaces fonctionnelles (tels que des entrées et des sorties de données) et les aspects non fonctionnels (tels que la synchronisation des composants). AADL décrit la composition et l'interaction entre les composants de l'application, et comment ces composants sont assignés aux processeurs dans la plate-forme d'exécution. Les mécanismes d’extension permettent d’introduire des propriétés spécifiques aux analyses supplémentaires d'architecture comme des attributs de qualité tels que la fiabilité, la sécurité, etc.
AADL peut être employé de deux manières : analyse légère des patrons d'architecture identifiés dans les systèmes temps-réel pour découvrir les enjeux systémiques potentiels ( sécurité, sûreté, inversion de priorité, connexions requises,etc.), et l'analyse complète d'un modèle complet de systèmes avec des valeurs quantifiées de ses propriétés.
3.3. TYPES DE COMPOSANTS
Le but d'AADL est de modéliser l'architecture des systèmes logiciels qui sont des systèmes d'application liés à une plate-forme d'exécution. L'architecture est modélisée en hiérarchie de composants, dont l'interaction est représentée par des connexions. Un composant possède un type de composant et une ou plusieurs implémentation(s) de composant.
Définition 8 (Type de Composant) – décrit une interface fonctionnelle en termes de
caractéristiques, spécification de flot, et propriétés. Il représente la spécification du composant avec laquelle d'autres composants peuvent fonctionner, c-à-d son interface extérieure visible. Des implémentations du composant sont exigées pour satisfaire ces spécifications.
Définition 9 (Implémentation de Composant) – spécifie une structure interne en termes de
sous-composants, de connexions entre les dispositifs de ces sous-composants, de flots à travers un ordonnancement des sous-composants, de modes (cf. § 2.4) pour représenter les états opérationnels, et des propriétés. À la différence de beaucoup d'autres langages, AADL permet la déclaration de multiples implémentations avec la même interface fonctionnelle (type).
La généralisation des composants est possible du fait que les types de composants et les composants d’implémentation peuvent être exprimés comme des prolongements d'autres types de composants et implémentations de composants [14].
Chapitre 1- Systèmes embarqués et temps-réel 3.Modélisation en AADL
L'interface d'un composant est formée de ports de connexions représentant : le flot directionnel de données et/ou de contrôle à partir des données, des événements, et des données d'événement (figure1.6), des appels synchrones de sous-programme entre les threads, potentiellement situés sur différents processeurs et des accès concurrents aux données.
Des connexions de ports de données peuvent être indiquées pour exécuter des communications immédiates au cours de la même période d'activation, ou des communications retardées pour que les données soient disponibles après la date limite du thread initial. Ces sémantiques assurent le transfert déterministe des flux de données entre les threads périodiques : c’est une caractéristique importante pour les systèmes de contrôle embarqués. Le transfert déterministe signifie qu'un thread reçoit toujours des données avec le même temps de retard [14].
Cette norme définit les types de composants suivants : données, sous-programmes, threads, groupe de threads, processus, paquets, mémoires, bus, processeurs, dispositifs, et système.
Ces types sont répartis en trois sous-catégories : Logicielle, Matérielle et Composite (figure1.7). Ils forment le noyau du vocabulaire de modélisation d'AADL.
Figure 1.6 - Type de ports
Chapitre 1 - Systèmes embarqués et temps-réel 3.Modélisation en AADL
3.3.1. Composants Matériels
Pour modéliser les plate-formes d'exécution, quatre catégories de composants sont proposées :
➢ processeur : abstraction du matériel et du logiciel qui est responsable d’ordonnancer et d'exécuter des unités d'exécution concurrentes (thread) selon un protocole d’ordonnancement spécifique et peut permettre la partition de l’espace par des espaces d’adresse protégés.
➢ mémoire : une abstraction du stockage physique accessible aléatoirement (RAM, ROM) qui peut contenir des données et / ou du code.
➢ bus : une abstraction de connecteur entre les composants de la plate-forme d’exécution.
➢ dispositif (device) : une abstraction d'un composant actif (tels que capteur, actionneur, caméra, ...) avec lequel un système d'application peut interagir et auquel un processeur peut accéder via un bus.
Les composants de la plate-forme d'exécution peuvent représenter des composants de matériel ou des composants abstraits de plate-forme d'exécution, dont l’implantation peut être réalisée par des machines virtuelles qui sont représentées par d'autres plate-formes d'exécution, avec des liens au matériel réel.
Chaque catégorie de plate-forme d'exécution a un certain nombre de propriétés prédéfinies telles que le temps de changement de thread et de processus ou le protocole d’ordonnancement des processeurs. Le noyau AADL prédéfinit de telles propriétés et un ensemble initial de valeurs de propriétés acceptables qui peut être étendu. Par exemple, de nouveaux protocoles d’ordonnancement peuvent être présentés par un mécanisme d’extension de propriété.
3.3.2. Composants Logiciels
La modélisation du système d'application est réalisée à partir de deux groupes de catégories de composants.
Le premier groupe se concentre sur le comportement de l'exécution d'un système et est composé de :
➢ threads : unité de base d'exécution concurrente.
➢ groupes de threads : groupement structurel des threads dans un processus.Un groupe de threads peut contenir des données, des threads, et des sous-composants de groupe de threads. Il peut exiger et permettre d'accéder aux sous-composants de données. ➢ processus : unité d'espace d'adresse protégée. Il modélise des partitions de l'espace en
termes d'espaces d’adresses virtuelles contenant le texte source qui forme le programme complet comme défini dans un langage de programmation standard.