Opportunisme et ordonnancement en optimisation sans dérivées
Texte intégral
Figure
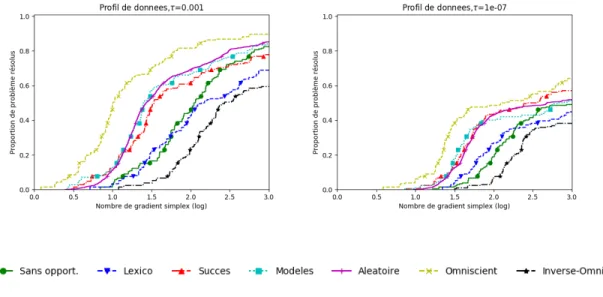
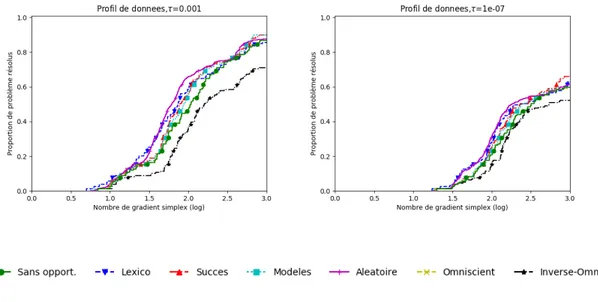
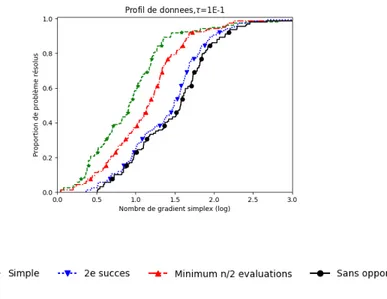
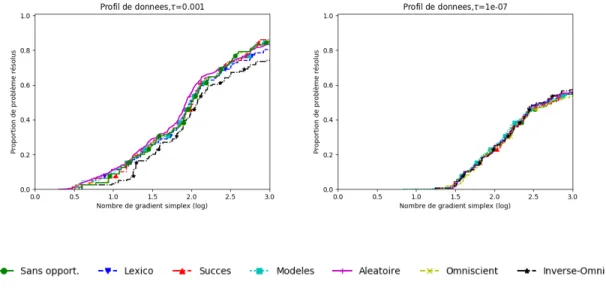
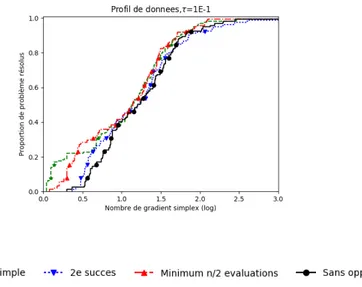
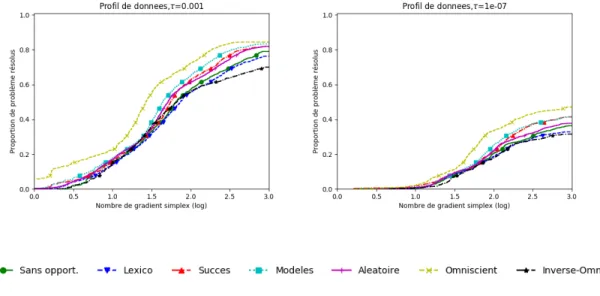
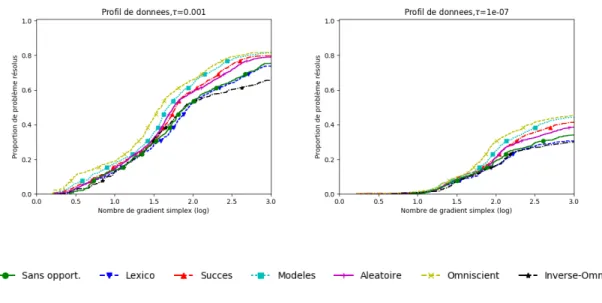
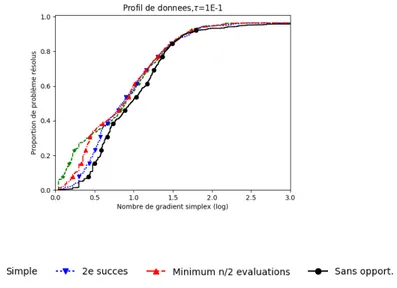
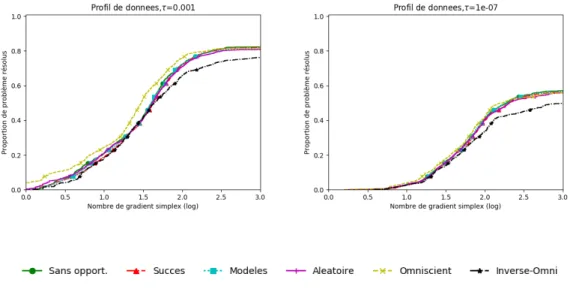
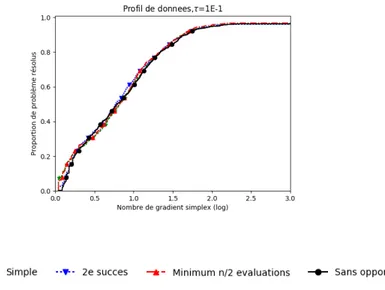
Documents relatifs
Le succès des modèles d’équilibre général dynamique et stochastique (DSGE 7 ) pour l’étude des politiques conjoncturelles s’explique par leur capacité à
Des modèles stellaires calculés avec le TGEC ont également été comparés avec des modèles calculés par d’autres codes d’évolution stellaires, utilisant la méthode de Burgers,
Douja Promotion Groupe Addoha a clôturé avec succès l’augmentation de capital par apport en numéraire et par compensation avec des créances liquides et
Les modèles de paramètres par défaut sont disponibles uniquement si vous avez intégré Trend Micro Remote Manager avec Licensing Management Platform et uniquement pour votre
Avec les dépenses engagées dans la recherche de fonds, la Fédération Suisse des Sourds génère les fonds pour mettre en œuvre sa stratégie avec succès et, par le biais de
Par ailleurs, la comparaison du modèle micromécanique avec des modèles rhéologiques prédictifs très connus a montré que le modèle proposé est très satisfaisant pour la
Afin de comparer facilement la puissance thermique dégagée par la combustion calculée par les deux modèles (k-ε et k-ω), le sous modèle CFD est résolu en mode stationnaire avec un
Les trois paramétrages de vitesses en question sont présentées avec les temps d’opérations correspondants : — réglage n°1 réglages de vitesses de marquage donnés par défaut
