Nonlinear model reduction on metric spaces. Application to one-dimensional conservative PDEs in Wasserstein spaces
29
0
0
Texte intégral
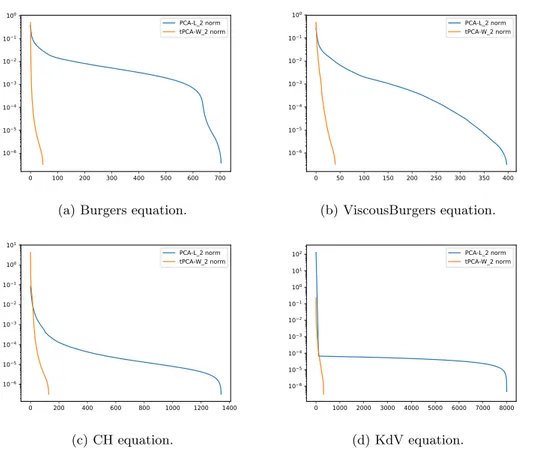
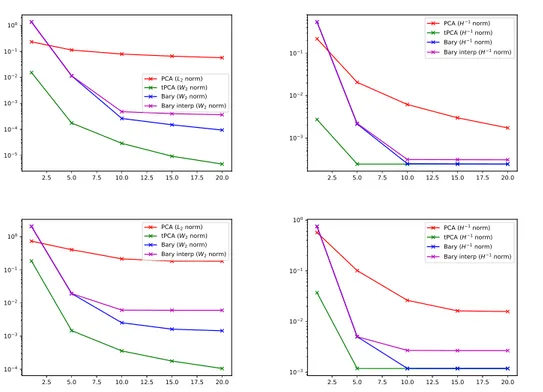
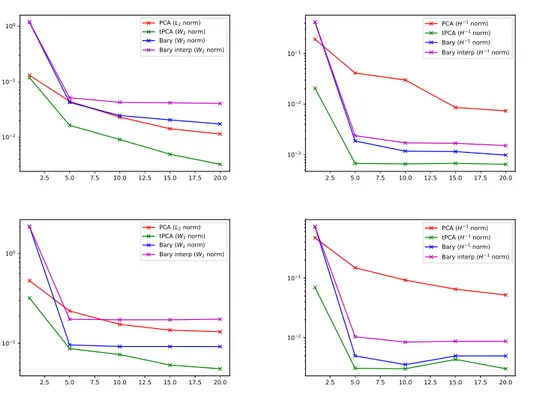
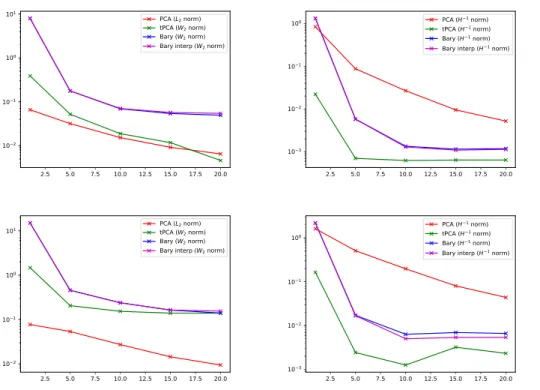
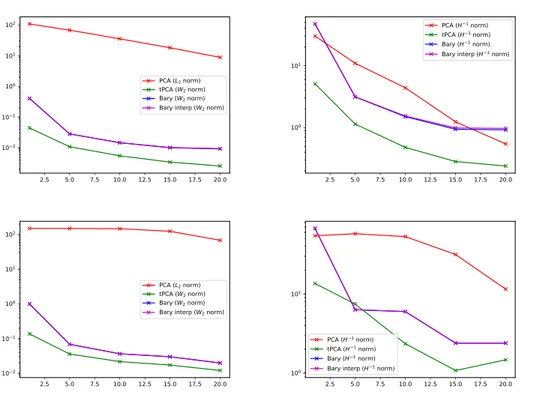
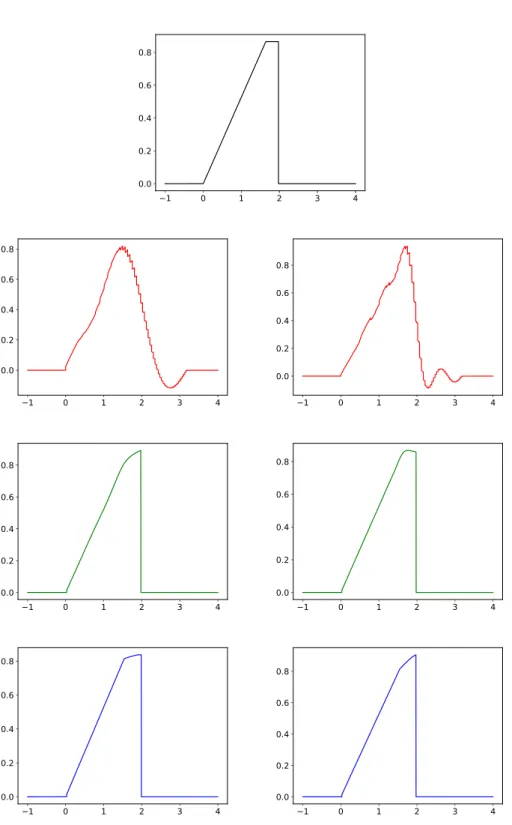
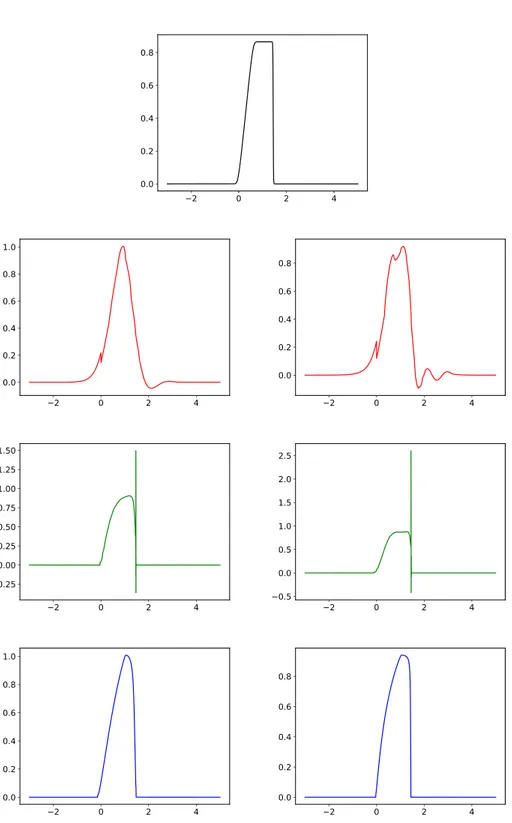
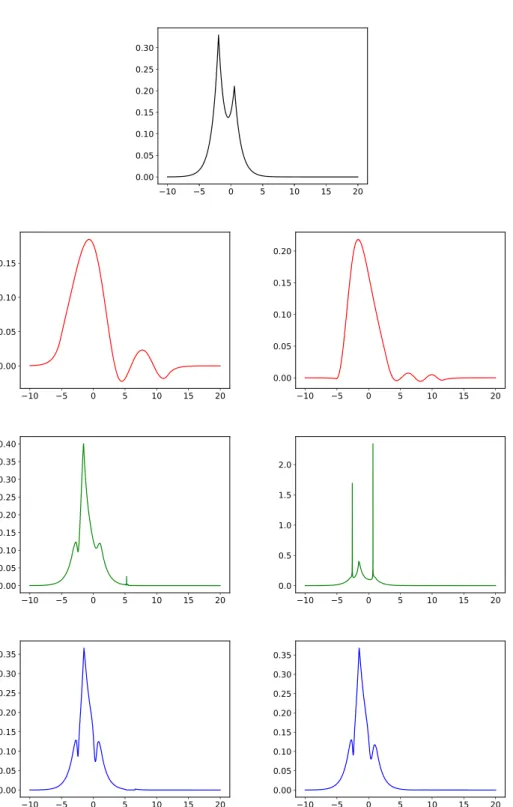
Figure
+6
Documents relatifs