Reconnaissance automatique de sons de <i>human beatbox</i>
Texte intégral
Figure


![Figure 1.8 – Évolutions de la recherche en reconnaissance automatique de la parole Source: [Juang and Rabiner, 2004]](https://thumb-eu.123doks.com/thumbv2/123doknet/7341601.212369/32.892.208.677.139.408/figure-évolutions-recherche-reconnaissance-automatique-parole-source-rabiner.webp)

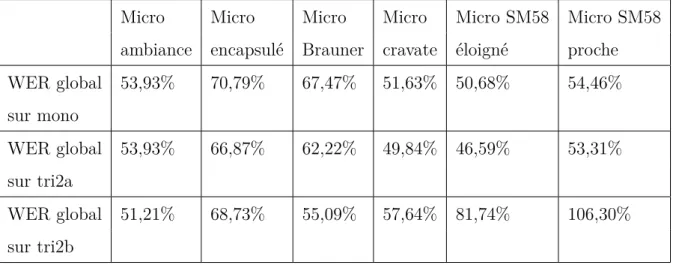

Documents relatifs
Romain Huret ajoute, à ce propos, dans la Revue internationale d'éducation de Sèvres, que l'Université améri- caine, réputée dans le monde entier et si souvent prise en référence,
Maintenant que le moteur de reconnaissance vocale tourne et que la grammaire est en place, il faut d'un côté développer la grammaire pour que le nombre de commandes vocales
Nous continuerons d’œuvrer à une union européenne de la santé forte et proposerons un nouveau cadre pour un secteur pharmaceutique de l’UE dynamique, afin de
On rappelle que l’on a définit pour un terme fortement normalisable v l’entier N (v) qui est la somme des longueurs des suites de réductions de v (lemme de König).. Prouvons
- Au milieu des mots : un hôpital, une cote, un pôle, un coté, un cône, un diplôme, un arôme, un fantôme, un polynôme, le chômage, une clôture, un symptôme, un hôtel, un
Et une bien belle et intéressante surprise : à Ertvelde (Evergem), louis delhaize a récupéré l'emplacement d'un Smatch fermé pour en faire un magasin qui se déploie sur un
Nous avons utilisé l’intégrale floue de shoquet, pour fusionner les scores issus des systèmes SVM RBF un contre un et SVM RBF un contre tous, après plusieurs expériences sur
(Si vous pensez que les élèves ont besoin de plus d’informations sur la composition d’un plan, consultez les pages 11 et 12 du document Ressources pour créer des médias dans
