Analyzing Polemics Evolution from Twitter Streams Using Author-based Social Networks
12
0
0
Texte intégral
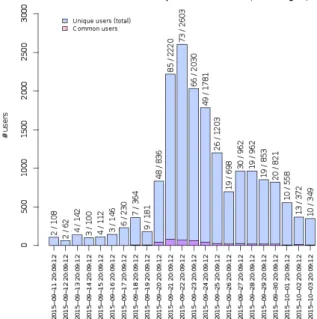
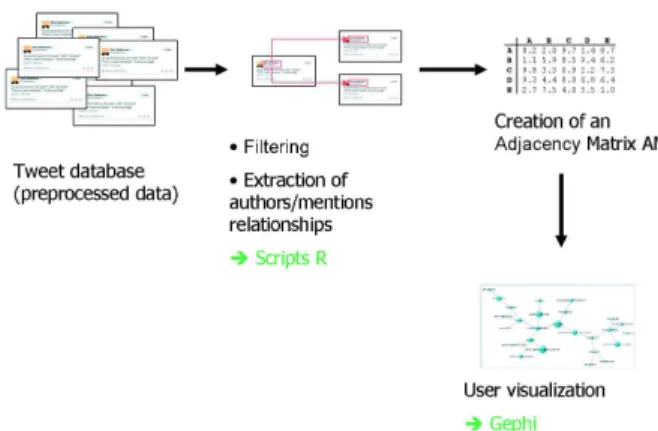
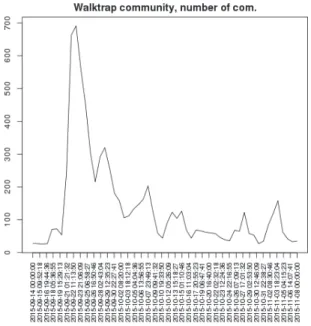
Figure


+2
Documents relatifs
