HAL Id: tel-01736695
https://hal.archives-ouvertes.fr/tel-01736695
Submitted on 18 Mar 2018
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
de bandes temporelles en vue de la supervision des
procédés énergétiques : application en ligne à un
générateur de vapeur
Rim Alaoui
To cite this version:
Rim Alaoui. Conception d’un module de diagnostic à base de suites de bandes temporelles en vue de la supervision des procédés énergétiques : application en ligne à un générateur de vapeur . Automatique / Robotique. Université des Sciences et Technologie de Lille, 2009. Français. �tel-01736695�
N° d’Ordre : 3521
Université des Sciences et Technologies de Lille
Laboratoire d’Automatique, Génie Informatique et Signal
UMR CNRS 8146
THÈSE
Présentée en vue de l’obtention du grade de
DOCTEUR DE L’UNIVERSITÉ
Spécialité : Productique, Automatique et Informatique Industrielle
par
Rim MRANI ALAOUI
Maître IEEA.
CONCEPTION D’UN MODULE DE DIAGNOSTIC A BASE DES
SUITES DE BANDES TEMPORELLES EN VUE DE LA SUPERVISION
DES PROCEDES ENERGETIQUE. Application en ligne à un
générateur de vapeur
Soutenue publiquement le 9 novembre 2004 devant la commission d’examen :
Président : Armand TOGUYENI Professeur, Ecole Centrale de Lille.
Rapporteurs : Didier MAQUIN Professeur, Institut National Polytechnique de Lorraine, Nancy.
Louise TRAVE-MASSUYES Directeur de Recherche, LAAS-CNRS Toulouse
Belkacem OULD BOUAMAMA Professeur Ecole Polytechnique de Lille (Directeur de Thèse)
Vincent Cocquempot Maître de Conférences (IUT « A », Université de lille
Armand TOGUYENI Professeur Ecole Centrale de Lille. Examinateurs :
Patrick TAILLIBERT Ingénieur de Recherches, Thales Airborne Systems, Elancourt
Table des matières
1 Introduction générale 1
2 Diagnostic dans les systèmes de supervision 5
2.1 Introduction . . . 5
2.2 Systèmes de surveillance dans un processus de supervision . . . 7
2.3 Pré requis . . . 8
2.4 Principe de détection et d’isolation des défaillances (FDI) . . . 9
2.5 Méthodes de surveillance . . . 11
2.5.1 Méthodes à base de modèle . . . 12
2.5.1.1 Estimation des paramètres . . . 13
2.5.1.2 Estimation d’état (observateur) . . . 13
2.5.1.3 Redondance analytique . . . 15
2.5.1.4 Approche structurelle . . . 15
2.5.1.5 Méthode G.D.E . . . 17
2.5.1.6 Conclusion . . . 17
2.5.2 Méthodes à base du signal . . . 17
2.5.2.1 Réseaux de neurones . . . 18
2.5.2.2 Reconnaissance des formes (RdF) . . . 18
2.5.2.3 Conclusion . . . 20
2.6 Procédures de décisions . . . 20
2.6.1 Problématique de la décision dans un système de diagnostic . . . 20
2.6.2 Procédures statistiques de décision . . . 22
2.6.2.1 Diagnostic hors ligne . . . 27
2.6.2.2 Diagnostic en ligne . . . 29
2.7 Problématique de la localisation de défaillances . . . 33
2.8 Conclusions . . . 34 i
ii Table des matières
3 Méthodes ensemblistes. Analyses par intervalles 36
3.1 Introduction . . . 36
3.2 Principe des méthodes ensemblistes pour le diagnostic . . . 36
3.2.1 Comparaison entre les approches ensemblistes et les approches proba-bilistes . . . 38
3.3 Méthodes d’analyse par intervalles . . . 40
3.3.1 Idée du calcul par intervalles . . . 40
3.3.2 Estimation d’état . . . 41
3.3.3 Application des enveloppes à la détection de défauts . . . 44
3.3.4 Enveloppes à erreur bornée . . . 46
3.3.5 Fenêtres temporelles glissantes . . . 47
3.3.6 Pourquoi l’approche à base des suites de bandes temporelles . . . 48
3.3.7 Système linéaire . . . 51
3.3.8 Système non linéaire . . . 53
3.3.9 Conclusion . . . 55
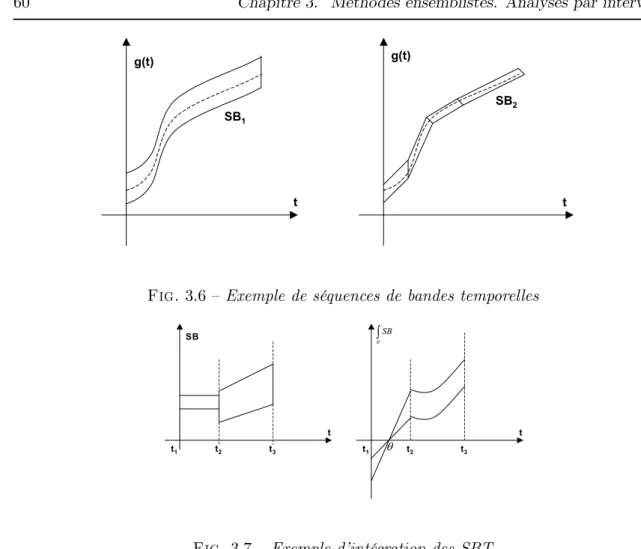
3.4 Méthode à base de suites de bandes temporelles . . . 55
3.4.1 Mise en oeuvre . . . 55
3.4.2 Rappel des opérations primitives entre les SBTs . . . 63
3.4.2.1 Primitive somme . . . 63
3.4.2.2 Primitive multiplication . . . 64
3.4.2.3 Primitive intégration . . . 65
3.4.2.4 Composition de suites de bandes temporelles . . . 66
3.4.2.5 Décalage de bandes temporelles . . . 68
3.4.2.6 Préconditions . . . 68
3.4.3 Instant de détection de l’apparition et de la disparition des pannes . . 68
3.4.4 Algorithme d’application de la méthode SBT . . . 70
3.4.5 Limites et avantages de la méthode SBTs . . . 72
3.5 Exemple de la mise en oeuvre sur des systèmes présents en génie de procédés 73 3.6 Conclusion . . . 77
4 Application à une installation pilote de génération de vapeur 81 4.1 Contexte et cadre de l’application . . . 81
4.2 Description physique du processus . . . 81
4.2.1 Caractéristiques techniques des instruments de mesures utilisés . . . . 83
4.3 Système de monitoring existant . . . 86
4.5 Calcul des relations de redondance analytique . . . 88
4.6 Table de signatures théorique des pannes . . . 95
4.7 Application . . . 96
4.7.1 Description des pannes . . . 96
4.7.2 Calcul des paramètres essentiels à l’application de la méthode des SBTs 99 4.7.3 Calcul des paramètres essentiels à l’application de l’algorithme de Cusum100 4.7.4 Résultats de la méthode à base des SBTs . . . 101
4.7.5 Résultats de la méthode de Cusum . . . 110
4.8 Analyse . . . 119
4.9 Synthèse . . . 122
4.10 Conclusion . . . 123
5 Conclusion générale 125
Chapitre 1
Introduction générale
Les processus industriels recouvrent des secteurs industriels très variés. Au sens très larges, un processus assure la fabrication d’un produit au fournit un services. Ainsi une raffinerie a pour vocation de fournir des produits pétroliers élaborés. Une centrale électrique à pour objectif de produire du courant électrique. Un avion assure un service de transport de biens et de personnes. Or, en dépit des progrès enregistrés dans le domaine du contrôle assisté par ordinateur des processus, ces dernières années de graves accidents sont survenus dans pas mal de procédés: Union Carbide’s Bhopal en Inde, AZDF de Toulouse en France, ... etc.
Dans le passé, les systèmes automatisés de production ont aidé à assister l’opérateur dans des tâches de conduite automatique du processus pour améliorer la qualité des produits finis, la sécurité et le rendement des unités industrielles. Le but essentiel était l’amélioration de la production en implantant des commandes performantes. Aujourd’hui, un autre défi est relevé, il s’agit de l’automatisation de la supervision des processus en utilisant un système intelligent fournissant à l’utilisateur une aide dans la gestion de ses tâches d’alarmes urgentes dans le but de faire augmenter la fiabilité et la sûreté de fonctionnement des processus.
Ces dernières années, les travaux de recherche sur le diagnostic ont mobilisé une large communauté de chercheurs. Terme peu répandu il y a une quinzaine d’années, le diagnostic aujourd’hui à pleinement conquis sa place. Le suivi du mode de fonctionnement d’un système est décrit par trois étapes:
- étape de la détection du mode sous lequel le système fonctionne (défaillant ou pas); - étape de l’identification et de la localisation de la cause du mauvais fonctionnement; - et l’étape du maintien du fonctionnement du processus, changement de sa configuration ou bien son arrêt définitif.
Les communautés Automatique et Intelligence Artificielle ont toutes les deux consacré un bon nombre de travaux au développement d’algorithmes de détection et de localisation des défaillances. Ces algorithmes sont conçus à partir des méthodes à base de modèle, ou sur le traitement des signaux issus des procédés. Les techniques développées reposent sur
la redondance d’informations présente sur les systèmes. Cette redondance peut être calculée à partir de la connaissance physique du système (modèles analytiques, modèles issus d’une phase d’apprentissage) ou bien uniquement à partir des informations délivrées par ses entrées et ses sorties.
Le diagnostic à l’aide des méthodes à base de modèle se fait selon deux étapes. La première étape consiste à générer les résidus à partir de la détermination des relations de redondance analytique [39], [36]. La deuxième étape a pour but de décider l’état de fonctionnement du système. Généralement la décision se fait à l’aide d’un seuil fixé par apprentissage, au-delà duquel le résidu est déclaré anormal. Or, comme les performances du système de surveillance dépendent de la qualité du modèle. Les incertitudes issues des capteurs et des paramètres ne sont pas tenues en compte. Ceci rend la fixation du seuil délicate, car si ce dernier est très grand, on se trouve devant le problème de non détections de pannes, autrement si le seuil est très petit c’est au tour du problème de fausses alarmes d’apparaître. Pour résoudre ce problème, on fait appel aux tests statistiques (test de page, test baysien, Cusum,... etc ), leur application repose sur les cinq opérations suivantes:
1- Définition de l’hypothèse H0 à contrôler, dans ce qui nous préoccupe, nous allons tester
si la valeur moyenne d’un résidu peut être considérée comme nulle;
2- Choix de la fonction discriminante z, fonction des résultats expérimentaux dont la distribution de probabilité sous l’hypothèse H0 (P (z/H0)) est connue (analytiquement ou
par estimation);
3- Choix d’un seuil de confiance et de la taille de l’échantillon;
4- Définition de la région de rejet (ou région critique) de l’hypothèse H0;
5- Evaluation de la fonction discriminante sur la base des échantillons.
Il existe de très nombreuses fonctions de discriminations pour élaborer une décision à propos d’une hypothèse donnée. Il est donc nécessaire d’avoir des critères de choix pour sélectionner une fonction particulière. De manière évidente, la meilleur fonction z est celle qui a la plus faible probabilité de rejeter H0 lorsqu’elle est vraie et la plus grande probabilité
de rejeter H0 lorsqu’elle est fausse. Ensuite, il s’agit de fixer le seuil de confiance et la taille
de l’échantillon. Deux types d’erreur peuvent alors être commises, rejeter H0 alors qu’elle est
vraie (fausse alarme) ou bien accepter H0 alors qu’elle est fausse (non détection). L’idéal sera
de faire un compromis optimisant le ration entre les probabilités d’occurrence de ces erreurs [76].
Dans le diagnostic à base de signal des processus, la décision se réalise au fur et à mesure que la réception de données. Donc aucun modèle analytique n’est déterminé. Or, ce type de méthodes est adapté aux processus stationnaires où les caractéristiques et la structure des procédés ne varient pas. Ceci n’est pas toujours le cas quand il s’agit des systèmes en génies des procédés.
3 Les méthodes développées par la communauté Intelligence Artificielle dont les méthodes à base d’intervalles font partie, assurent un bon et simple diagnostic. Ces méthodes permettent d’établir un lien entre les méthodes numériques, limitées quant à leur garantie de résultats, et les méthodes analytiques, limitées quant à la complexité des systèmes qu’elles peuvent consi-dérer [46]. Contrairement aux approches statistiques, aucune information sur le système à diagnostiquer n’est demandée en avance. Il suffit de représenter les variables par leur domaine d’appartenance, souvent des intervalles. Ainsi, avec cette présentation, les opérations non li-néaires sont simple à traiter. Les erreurs de mesures sur une donnée expérimentale sont faciles à prendre en considération, comme elles sont données en terme de tolérance par les appareils des mesures. De même, les incertitudes due aux erreurs numériques peuvent être incorporées dans le calcul des domaines [42]. Ces méthodes donnent une solution aux problèmes de non détections et de fausses alarmes rencontrées au moment de la décision de l’état de fonctionne-ment des procédés. Or, ces problèmes peuvent toujours réapparaître, et cette fois ci à cause de l’évaluation numérique de la dérivée quand elle est présente dans le calcul des résidus. Dans ce contexte et toujours grâce à l’idée de travailler par intervalles, vient la méthode à base des suites de bandes temporelles [87], [85], [86]. Cette dernière assure la détection de l’incohérence des résidus sans passer par aucun calcul de la dérivée. Son point faible réside dans la déter-mination de ses résidus. Contrairement aux approches citées plus haut; cette méthode oblige d’avoir les résidus sous une forme canonique bien déterminée: f + g0+ h00... = 0 où f, g, h.... sont des fonctions de quantités mesurables et des paramètres à surveiller. La technique par la suite est simple, il suffit de faire une intégration formelle de ces résidus ou lieu de calculer la dérivée, tout en prenant en considération les erreurs relatives et absolues des appareils de mesures. Ceci se fait au moment de la construction des suites de bandes temporelles.
Comme cette méthode a été validée sur les systèmes électroniques [86], notre travail sera de pouvoir valider cette méthode sur des processus industriels caractérisés par le couplage de plusieurs phénomènes (thermique, hydraulique, mécanique et chimique). Le nombre de variables pour décrire ce type de procédé est supérieur ou égal à deux. Les performances du système de diagnostic appliquées à un générateur de vapeur, seront comparées par la suite avec les procédés de décision des méthodes statistiques. Pour cette comparaison, nous avons choisi la méthode de Cusum comme méthode de référence. Ce travail a été financé par la société Thalès Airoborne System.
Plan de mémoire
Ce mémoire est constitué de trois chapitres précédés d’un chapitre d’introduction générale et finalisés par un chapitre de conclusions générales et de perspectives.
Chapitre 2: Diagnostic dans les systèmes de supervision
Après quelques définitions sur les concepts de la surveillance et l’intérêt de la supervision, ce chapitre est consacré à un état de l’art sur les méthodes de surveillance des processus en
génie des procédés, que ce soit des méthodes à base de modèle ou celle à base de signal. La problématique de la décision dans les systèmes de supervision et une synthèse des approches statistiques seront exposées dans ce chapitre.
Chapitre 3: Méthodes ensemblistes: Analyse par intervalles
Ce chapitre a pour objectif de décrire le principe des méthodes ensemblistes pour le diagnostic et de faire un état de l’art sur les méthodes à base d’intervalles. Ensuite un détail de la méthode à base des suites de bandes temporelles, utilisée dans la suite de notre travail, sera présenté ainsi que les problèmes rencontrés au cours de son application sur les systèmes en génies des procédés.
Chapitre 4: Application à une installation pilote de génération de vapeur Ce chapitre est consacré à l’implémentation en ligne des algorithmes développés à une installation pilote de génération de vapeur. Le calcul des paramètres essentiels à l’application de la méthode à base des suites de bandes temporelles et celle statistique de Cusum sera détaillé. Ainsi qu’une analyse de leurs résultats et une comparaison seront données à la fin.
Chapitre 2
Diagnostic dans les systèmes de
supervision
Ce premier chapitre a pour objectif de donner un état de l’art sur les méthodes et les approches utilisées dans le domaine de la surveillance et la supervision des systèmes.
A ce titre, après une introduction et un rappel de quelques définitions, nous abordons les différentes méthodes et approches de la détection et de la localisation des défaillances dans un processus industriel. Ces méthodes sont connues sous l’appellation FDI (Fault Detection and Isolation).
Comme notre travail se focalise sur le diagnostic des systèmes et plus particulièrement sur la partie ”détection” des pannes, un résumé des méthodes statistiques de décision sera développé dans ce chapitre.
2.1
Introduction
L’un des objectifs les plus importants de l’automatisation aujourd’hui concerne l’augmen-tation de la fiabilité, de la disponibilité et de la sûreté de fonctionnement des processus tech-nologiques. C’est la raison pour laquelle on met en oeuvre des systèmes de surveillances dont l’objectif est d’être capable, à tout instant, de fournir l’état de fonctionnement des différents équipements constitutifs d’un processus technologique.
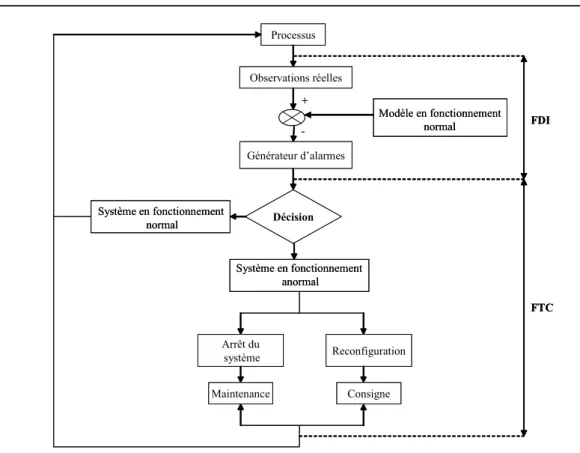
Tant au niveau de la détection et de l’isolation des fautes (FDI) qu’au niveau de la tolérance aux fautes (FTC: Fault Tolerant Control ), l’opérateur de supervision gère deux types d’information. Le premier concerne la détection et l’isolation de défauts survenus sur l’installation, et le deuxième indique les possibilités de laisser fonctionner ou non le processus. La Fig. 2.1 résume, le principe de la FDI et de la FTC.
Au niveau de la FTC, deux approches sont à distinguées: l’approche passive et l’approche active [65]. L’approche passive est basée sur la commande robuste qui vise à définir pour
Processus Observations réelles FDI FTC + -Générateur d’alarmes Modèle en fonctionnement normal Décision Système en fonctionnement normal Système en fonctionnement anormal Arrêt du système Reconfiguration Maintenance Consigne Processus Observations réelles FDI FTC + -Générateur d’alarmes Modèle en fonctionnement normal Décision Système en fonctionnement normal Système en fonctionnement anormal Arrêt du système Reconfiguration Maintenance Consigne
Fig. 2.1 — Schéma de principe de la supervision
les systèmes contrôlés en boucle fermée, des régulateurs insensibles aux fautes [33]. Aucune information sur les défaillances fournies par les algorithmes de FDI n’est utilisée, ainsi que la structure du système n’est pas modifiée. Par contre, l’approche active, comme son nom l’indique, utilise les informations du module FDI en temps réel pour adapter le système à sa nouvelle situation en cas d’occurrence de défaillances [81]. Dans notre travail, on s’intéresse uniquement à la partie FDI. Pour plus de détail sur la FTC, le lecteur pourra se référencer à [3].
Les travaux de recherche sur le diagnostic ont mobilisé ces dernières années une large communauté de chercheurs. Car, il faut dire que le diagnostic était peu répandu il y a une quinzaine d’années. Aujourd’hui en raison, d’une part des contraintes économiques de com-pétitivité accentuées par la mondialisation, et d’autre part de la sûreté de fonctionnement, le diagnostic a pleinement conquis sa place, surtout pour les processus en génie des procédés en raison de leur caractère à risque (processus chimique, nucléaire, etc ...). De plus le souci de la protection de l’environnement est une raison supplémentaire de l’importance du diagnostic de ce type de procédé.
Que le système de diagnostic travaille par propagation de valeurs (utilisée surtout en Intel-ligence Artificielle) ou par élimination symbolique des grandeurs non mesurables (Redondance
2.2. Systèmes de surveillance dans un processus de supervision 7 Analytique), le principe est le même : il faut détecter une inconsistance de laquelle sera dé-duite le diagnostic. La seule différence porte sur la nature de l’expression soumise au test de consistance. Dans le premier cas, il s’agit d’une simple comparaison entre deux prédictions ou entre une mesure et une prédiction ; dans le second cas, il s’agit de déterminer si une expression de plusieurs variables est différente de zéro. Pourtant, dans les deux cas, l’égalité stricte n’est jamais obtenue. Il faut mettre en place une procédure de décision. Celle-ci posera d’autant plus de problèmes si le système est dynamique (équations différentielles).
2.2
Systèmes de surveillance dans un processus de supervision
La surveillance est la base d’une excellente sûreté de fonctionnement des processus tech-nologiques. Elle constitue une interface entre l’opérateur et l’installation physique, son rôle est de fournir les informations sur l’état de fonctionnement (correct ou erroné) des dispositifs surveillés ainsi que valider les informations issues des capteurs et localiser les composants défaillants.
La surveillance se réalise à l’aide des algorithmes conçus pour traiter les données brutes (issues des automatismes et des opérateurs) et les données mesurées (issues des capteurs) dans l’objectif de produire des données dont l’efficacité a été prouvée par le système. Il s’agit des données valides.
Les algorithmes de diagnostic permettent aussi, en fonction de la nature des défaillances localisées et de leur importance, la reconfiguration des systèmes. Ils sont tous basés sur le principe de la redondance des sources d’information.
On distingue deux types de redondance:
— Redondance matérielle (physique): Il s’agit d’une procédure de surveillance des appa-reils de mesure ([34], [70], et [16]). Le principe consiste à mesurer une même grandeur caractéristique du processus à l’aide de plusieurs capteurs identiques. Pour la détection de pannes simples, il est nécessaire de doubler les capteurs. Par contre, la localisation des défaillances se fait grâce à un vote majoritaire entre au moins trois capteurs. Cette façon de procéder à été largement utilisée dans l’industrie, grâce à sa fiabilité et à sa simplicité de mise en oeuvre. Cependant elle se révèle très coûteuse et alourdit considé-rablement les installations déjà très complexes. De plus pour des raisons architecturales et matérielles, la redondance des capteurs n’est pas toujours possible à réaliser. Mais l’inconvénient majeur de ce type de méthode réside dans son champ d’application limité aux seules défaillances capteurs.
— Redondance analytique: La redondance analytique est un complément de la redondance physique. Elle consiste à exploiter les contraintes liant les différentes variables du sys-tème afin d’obtenir des relations ne contenant que les variables connues (mesurées). Ces
relations sont appelées ”Relations de Redondance Analytique (RRA)”.
2.3
Pré requis
Donnons quelques définitions pour la suite de notre travail :
Définition 1 Un processus industriel est un assemblage fonctionnel de composants tech-nologiques associés les uns aux autres de façon à former une entité unique accomplissant ou pouvant accomplir une activité clairement définie (i.e générateur de vapeur, colonne de distil-lation, moteur électrique...). Au sens large, un processus assure la fabrication d’un produit ou fournit un service [91]. Un processus est appelé aussi système (nous utilisons indifféremment ces deux termes dans la suite), qui peut être défini comme un ensemble, susceptible d’évoluer dans le temps, composé d’éléments réagissant entre eux et avec le milieu extérieur.
Un système est composé de trois ensembles de variables [10] (Fig. 2.2). Il s’agit des va-riables d’état x (représentant la mémoire du système) et associés aux vava-riables d’énergies stockées par le système, des variables de sortie y (représentant des grandeurs mesurées par les capteurs) et des variables d’entrée u (représentant des sources d’énergie fournies par des actionneurs commandés u2 ou non, ou des signaux de commande délivrés par des contrôleurs
u1). Ces entrées peuvent être connues ou non (perturbations). L’évaluation de ces variables
se fait suivant les lois physiques sous l’influence des perturbations ou des entrées inconnues non contrôlées.
Actionneurs
Contrôleurs Processus
Capteurs
Fautes Fautes Fautes
Sorties Consigne Fautes u1 u2 y ( - ) x Actionneurs Contrôleurs Processus Capteurs
Fautes Fautes Fautes
Sorties Consigne Fautes u1 u2 y ( - ) x
Fig. 2.2 — Schéma de principe d’un processus régulé
Définition 2 Un composant industriel est un organe technologique qui forme une partie du processus industriel (réservoir, conduite, pompe ...). Ce dernier peut être affecté par des pannes (Fig 2.2).
Définition 3 Le terme faute (ou défaut) est généralement défini comme une déviation d’une variable observée ou d’un paramètre calculé par rapport à sa valeur fixée dans les carac-téristiques attendues du processus lui-même, des capteurs, des actionneurs ou de tout autre
2.4. Principe de détection et d’isolation des défaillances (FDI) 9 équipement. Un défaut peut être invisible pendant un certain temps avant de donner lieu à une défaillance.
Définition 4 La défaillance est une modification indésirable du système se traduisant par une variation d’un ou de plusieurs paramètres par rapport à une valeur de référence. Les défaillances peuvent provenir des actionneurs, des capteurs, des contrôleurs ou du processus lui même (pannes physiques) [27] (Fig 2.2).
Définition 5 Une panne est une interruption permanente de la capacité du système à réa-liser sa fonction requise.
Définition 6 Une erreur est définie comme l’écart entre une valeur mesurée ou estimée d’une variable et la vraie valeur spécifiée par le modèle d’un capteur jugé théoriquement cor-recte.
Définition 7 Un dysfonctionnement est une irrégularité intermittente dans la réalisation d’une fonction désirée du système [40].
Définition 8 Les contraintes sont les limitations imposées par la nature (lois physiques) ou l’opérateur.
Définition 9 Un résidu ou indicateur de faute exprime l’incohérence entre les informations disponibles et les informations théoriques fournies par un modèle (supposées décrire correcte-ment le processus).
Définition 10 Le diagnostic des systèmes permet d’identifier les causes possibles de la défaillance. Il a pour objectif de fournir les informations sur l’instant et sur l’amplitude de la défaillance [40].
2.4
Principe de détection et d’isolation des défaillances (FDI)
En général, le diagnostic se réalise selon les étapes suivantes (Fig. 2.3): — Première étape (Acquisition de données):
Cette étape à pour objectif de rassembler toutes les données sur le processus physique à diagnostiquer, que cela soit des données réelles issues des capteurs, ou bien des paramètres réels de chacun de ces composants. Cette étape fournit les informations sur le comportement réel du procédé.
Données théoriques Modèle Comparaison Diagnostic Alarmes Données réelles (sorties capteurs et paramètres du système) Processus réel Capteurs Identification Isolation E tap e 1: A cqu isi ti on E tap e 3: Id en ti fi ca ti on Et ap e 2: Dét ect io n Données théoriques Modèle Comparaison Diagnostic Alarmes Données réelles (sorties capteurs et paramètres du système) Processus réel Capteurs Identification Isolation E tap e 1: A cqu isi ti on E tap e 3: Id en ti fi ca ti on Et ap e 2: Dét ect io n
Fig. 2.3 — Etapes de diagnostic
Dans cette étape, on s’intéresse à la détection en surveillant le fonctionnement réel du processus, en testant la cohérence entre les données issues du modèle et celles délivrées par les capteurs (observations). Si ces dernières ne vérifient pas le comportement de référence donné par son modèle, on en déduit que le fonctionnement réel du système n’est pas son fonc-tionnement normal. Une relation de redondance exprime le fait que le résultat d’une fonction de variables connues (son résidu) doit être nul. Cette relation est vérifiée si le comportement du système suit exactement le modèle : le résidu est alors strictement nul. En pratique, le résidu est en général différent de zéro. Deux hypothèses se présentent alors :
- H0: Le résidu est différent de zéro à cause des bruits de mesures (modèle imparfait des
relations de connaissances) ou des erreurs de modélisation, sachant que le fonctionne-ment du système est normal.
- H1: Le résidu est différent de zéro à cause d’une défaillance de l’un de ces composants.
Le rôle des méthodes de décision est de détecter la défaillance (préciser dans quelle hypothèse se situe le système étudié (H0 ou H1)). Dans la littérature, il existe plusieurs
méthodes statistiques de décision, dont le but est de déclencher une alarme dans le système une fois la panne présente et ceci dans un minimum de temps et avec un minimum de fausses alarmes. Une présentation sommaire des méthodes statistiques de décision sera donnée plus loin.
2.5. Méthodes de surveillance 11 Cette étape se déclenche une fois qu’une alarme est envoyée par l’étape précédente. Ici, on cherche à identifier les causes précises de cette anomalie grâce à des signatures répertoriées par les experts, et validées après expertise et réparation des dysfonctionnements. Les infor-mations ainsi obtenues sont fournies au service de maintenance. Le travail de recherche que nous présentons dans ce document concerne la 1ère et la 2ème étape.
2.5
Méthodes de surveillance
En fonction du type de connaissance utilisée pour vérifier la cohérence entre les observa-tions réelles et de référence, on distingue deux types de méthodes: les méthodes avec modèle et les méthodes sans modèles que nous appellerons dans le présent document méthode à base de signal. Cette appellation est utilisée ici afin de distinguer les méthodes à base de modèle, où le modèle est fourni sous forme d’équation algébrique ou différentielle. L’approche à base de signal consiste à surveiller le système sans connaître son modèle analytique déduit par des lois physiques ou par identification. Elle repose sur des descripteurs qui caractérisent le fonctionnement du système observé dans différents modes de fonctionnement (normal, exis-tence de pannes (pannes capteurs, pannes composants ...)). Son algorithme de surveillance consiste à reconnaître en temps réel l’appartenance de ces descripteurs aux formes acquises dans une procédure d’apprentissage ([32], [68]). La méthode de diagnostic par reconnaissance des formes ([32], [28], [7]) est parmi les méthodes la plus utilisée. Elle est utilisée dans le cas des systèmes complexes, pour lesquels un modèle est difficile à obtenir. Les uniques informations disponibles sont issues des différents signaux. Le but de la reconnaissance des formes a priori est la classification automatique des formes dans des modes. Les principales limites de cette approche se situent au niveau de l’étape d’apprentissage des différents modes de fonctionne-ment nécessaire pour un diagnostic précis. Cette difficulté est plus importante dans le cas des processus rencontrés en génie des procédés en raison de leur caractère non stationnaire. Le modèle peut aussi être fourni par un expert sous forme de règles de type if, else, then; ...etc. Même si des tentatives de générer ces règles sous forme automatique, l’obtention de ce type de modèle est assujetti à des problèmes de subjectivisme et de combinatoire. D’autres part le caractère non linéaire et complexe (dû au couplage de différentes énergies) des procédés énergétiques, compliquent l’utilisation en temps réel de ces méthodes.
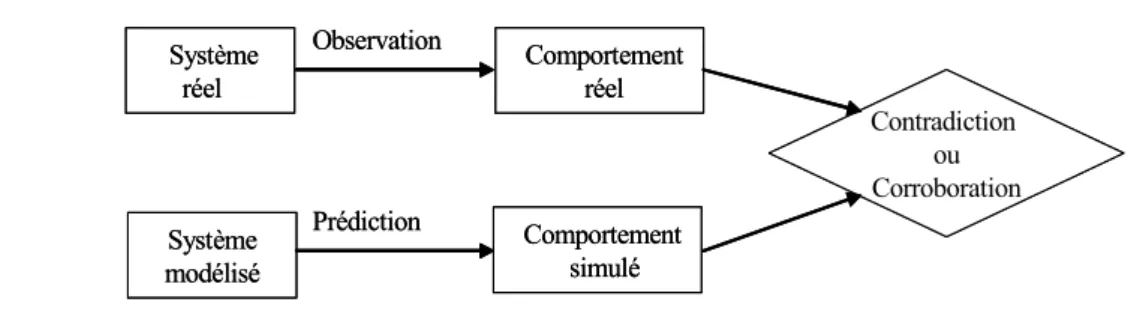
Par contre l’approche avec modèle, utilise un modèle opératoire. Il s’agit d’utiliser la redondance d’information et la connaissance fournie par le modèle pour caractériser l’état du système (son mode de fonctionnement), et pour passer ensuite à l’étape de la détection [39] et [36]. Le fonctionnement de cette approche se résume dans le schéma, Fig. 2.4. Elle sera utilisée tout le long de ce travail.
Système modélisé Système réel Observation Prédiction Comportement réel Comportement simulé Contradiction ou Corroboration Système modélisé Système réel Observation Prédiction Comportement réel Comportement simulé Contradiction ou Corroboration
Fig. 2.4 — Diagnostic à base de modèle
2.5.1
Méthodes à base de modèle
Ces approches se basent essentiellement sur l’existence de redondance matérielle ou ana-lytique. Un grand nombre de travaux leur est consacré. Une synthèse peut être trouvée dans [39], [36]. Selon la manière dont la connaissance est utilisée, on distingue trois grandes ap-proches: l’approche par estimation de paramètres, celle par estimation d’état (à base d’observateur) et enfin celle par espace de parité.
Le modèle analytique le plus utilisé exprime le comportement d’un système par un en-semble d’équations linéaires:
- modèle du système : x(t + 1) = A(θp)x(t) + B(θp)u(t) x(t0) = x0 (2.1) avec :
x(t) ∈ Rn vecteur d’état du système à l’instant t u(t) ∈ Rp vecteur de commande à l’instant t θp ∈ Rq vecteur des paramètres
A(θp) et B(θp) sont des matrices de dimensions convenables
t, t + 1 sont les instants d’échantillonnage - modèle de la mesure
y(t) = C(θs)x(t) (2.2)
avec :
y(t) ∈ Rm vecteur des sorties
θs vecteur des paramètres de mesure
2.5. Méthodes de surveillance 13 Rappelons que les résidus sont des variables dont la valeur est égale à zéro en cas de fonctionnement idéal. La vérification en temps réel de la valeur des résidus oblige la récep-tion à tout instant t des valeurs de commande et de sortie, respectivement [u(t),u(t − 1),...] et [y(t),y(t − 1),...]. Pour la construction de tels résidus, trois façons de procéder sont prin-cipalement utilisées [66]: l’estimation des paramètres, l’estimation d’état et la redondance analytique.
2.5.1.1 Estimation des paramètres
A partir des signaux d’entrée/sortie, les paramètres θp et θs sont estimés en utilisant
des procédures d’identification. Les résidus sont ensuite générés simplement en comparant les valeurs estimées avec les valeurs nominales (supposé connues). Le vecteur des résidus est alors : r (t) = θpN θsN − bθp(t) bθs(t) (2.3) où :
bθp(t) et bθs(t) sont les paramètres, du systèmes et des capteurs, estimés à l’instant t, et
θpN, θsN sont leurs valeurs nominales.
Lorsque les valeurs nominales ne sont pas connues, il suffit de les remplacer par des valeurs estimées à l’instant t − 1. r (t) = bθp(t − 1) bθs(t − 1) − bθp(t) bθs(t) (2.4)
Dans ce cas, l’écart des résidus par rapport à zéro est le résultat des variations de para-mètres. La connaissance sous-jacente du système exprime simplement que dans des conditions opératoires normales, les paramètres du systèmes demeurent constants. Un schéma de principe de cette méthode est donné par la Fig. 2.5.
Remarque 2.5.1 Dans cette approche, une alarme est associée à chaque résidu, c’est-à-dire à chaque paramètre surveillé du système. Son déclenchement est démonstratif d’un écart anormal entre la valeur nominale du paramètre et sa valeur réelle (telle qu’elle est estimée par l’algorithme d’identification). Les déviations des paramètres sont en général indépendantes, cette approche limite donc les avalanches d’alarmes (lorsque les modèles utilisés ne sont pas grossièrement faux).
Estimation des paramètres
Comparaison avec les valeurs nominales
Système x , θ Décision Sortie Entrée u θˆ θ Système réel Estimation des paramètres Comparaison avec les valeurs nominales
Système x , θ Décision Sortie Entrée u θˆ θ Système réel
Fig. 2.5 — Principe de l’approche par estimation des paramètres
2.5.1.2 Estimation d’état (observateur)
Une approche semblable à l’estimation des paramètres est l’estimation de l’état. En uti-lisant les signaux d’entrée et de sortie, l’état du système x(t) et ses sorties y(t) sont estimés (les sorties peuvent être estimées directement sans passer par l’estimation préalable de l’état). Les résidus sont générés par comparaison des sorties réelles et de leurs estimations. Le vecteur des résidus s’exprime sous la forme :
r(t) = y(t) − by(t) (2.5)
où y(t) est l’estimation de la sortie à l’instant t. Le principe général d’un estimateur deb sortie est donné par la Fig. 2.6. Des travaux de diagnostic fondés sur les observateurs ont été développés, nous citons quelques références [37], [18],[31] et [53].
Capteurs Processus Observateur y yˆ + -Résidu x u Sortie reconstruite Capteurs Processus Observateur y yˆ + -Résidu x u Sortie reconstruite
2.5. Méthodes de surveillance 15 Remarque 2.5.2 Cette approche associe un résidu à chaque capteur du système. Chaque alarme générée est significative de la défaillance du capteur correspondant. Ces défaillances n’étant en général pas carrelées, les risques d’avalanche d’alarmes sont réduits. Les difficultés résident dans la construction de l’observateur surtout pour les systèmes en génies des procédés où la mise sous forme d’état des modèles n’est pas triviale.
2.5.1.3 Redondance analytique
Cette approche conduit à une ré-écriture des équations d’état et de mesure, dans laquelle seules des variables connues (commandes et sorties) sont autorisées à figurer. Dans le cas linéaire, ces équations sont appelées équations de parité, et relations de redondance analytique (RRA) dans le cas le plus général.
Une relation de redondance analytique représente une propriété d’invariance du système non défaillant sous la forme :
ϕ[u(t,t − p),y(t,t − p)] = 0 (2.6)
Cependant, cette égalité ne sera jamais vérifiée, le système n’étant jamais dans des condi-tions de fonctionnement idéal. Dans ce sens, le vecteur des résidus construit à partir des relations de redondance analytique aura la forme :
r(t) = ϕ[u(t,t − p),y(t,t − p)] (2.7)
De nombreux schémas de calcul ont été spécifiquement construits pour chacune de ces trois approches (identification des paramètres de systèmes en temps continu, filtres de Kal-man, observateurs, résidus structurés). Un certain nombre de propriétés d’équivalence ont été prouvées [90], [80], [66], et de nombreuses applications ont été développées pour la surveillance de systèmes technologiques [64].
Remarque 2.5.3 A chaque relation entrée/sortie du système, cette approche associe un ré-sidu. Les corrélations entre les réactions des différents résidus sont traitées à l’aide de la table des signatures binaires des défaillances. Les défaillances capteurs, actionneurs et paramètres n’engendrent pas d’avalanche d’alarmes. On parle de défaillances indépendantes.
2.5.1.4 Approche structurelle
Pour les systèmes de grande taille, l’application des approches qui viennent d’être pré-sentées n’est pas triviale. En effet, ces méthodes dépendent de la disponibilité des modèles
analytiques de bonne qualité décrivant d’une part le système et ses actionneurs, d’autre part le système de mesure.
Pour la génération des résidus, ces méthodes nécessitent la connaissance des valeurs nu-mériques des paramètres.
L’approche structurelle utilise une connaissance très pauvre du système. Elle s’avère de ce fait très intéressante lorsqu’on se situe dans les premières phases du processus de conception du système de surveillance, ou lorsqu’il s’agit de concevoir des extensions d’un système existant. Dans le domaine de la surveillance, les concepts structurels n’ont été utilisés jusqu’à peu que pour mettre en place les procédures de localisation qui constituent la troisième phase pour tout système de surveillance [38]. Ils constituent en fait un cadre général pour la conception des systèmes de surveillance, permettant de générer, calculer, évaluer et implémenter une procédure de surveillance utilisant les relations de redondance analytique.
L’analyse structurelle est l’analyse des propriétés structurelles du système, c’est-à-dire des propriétés qui sont indépendantes des valeurs réelles des paramètres (plus exactement, des propriétés qui sont vraies presque partout dans l’espace des paramètres). L’analyse structu-relle s’applique aux modèles linéaires comme aux modèles non linéaires, elle n’exige aucune précision du modèle de calcul du comportement et permet une représentation homogène de tous les types de modèles (par la matrice d’incidence d’un graphe bi-parti [77]).
Enfin, l’analyse structurelle traite uniquement les données binaires et s’avère efficace pour l’analyse de grands systèmes (complexes). Bien que les données d’entrée soient extrêmement pauvres, elles constituent la plus grande partie de connaissance nécessaire à la conception des systèmes de surveillance. En effet, à l’aide de l’analyse structurelle, plusieurs étapes du processus de conception sont franchies, on cite:
a) L’analyse des redondances locales du système, permettant de mettre en évidence les possibilités de surveillance.
b) Le problème de placement des capteurs [12]
c) La détermination des séquences de calcul dont le résultat est un résidu (graphe orienté). d) L’analyse de la structure des résidus dont le but d’évaluer la détectabilité et l’isolabilité des défaillances.
e) L’analyse de la structure des résidus pour l’implémentation distribuée des algorithmes de surveillance.
f) L’utilisation des propriétés structurelles et causales des modèles band graph permet de générer les RRA formelles [11]. Les résultats de ces travaux ont été formalisés par le développe-ment d’un logiciel ”MOD BUILD” dans le cadre du projet CHEM (Advanced Decision Support System for Chemical and Petrochemical Processes), Par la conception d’al-gorithme de supervision des processus de production.
2.5. Méthodes de surveillance 17 2.5.1.5 Méthode G.D.E
Il existe aussi une méthode nommée G.D.E (General Diagnosis Engine) [23]. Cette mé-thode se divise en quatre grandes parties. La première étape consiste à faire le calcul des grandeurs du système à partir des modèles des composants et des observations. La deuxième étape a pour but de comparer les valeurs prédites entre elles et avec les observations. Les conflits sont détectés dans le cas où une incohérence entre ces valeurs est détectée. Dans la troisième étape, il s’agit de construire une liste de candidats possibles (les composants dont les pannes peuvent expliquer le comportement anormal du système). Et à la quatrième étape, il s’agit de déterminer la grandeur dont l’observation est susceptible de permettre l’affinement du diagnostic.
2.5.1.6 Conclusion
Le diagnostic à l’aide des méthodes à base de modèle est divisée en deux grandes étapes. La première étape consiste à générer les résidus à partir de la détermination des relations de redondance analytique. La deuxième étape a pour but de décider l’état de fonctionnement du système.
Les performances du système de surveillance dépendent de la qualité du modèle. Les incertitudes issues aussi bien des capteurs que des paramètres ne sont pas tenues en compte. L’obtention des modèles est d’autant plus difficile dans le cas des systèmes en génies des procédés en raison de leur caractère non stationnaire (introduisant des incertitudes et des erreurs de modélisation). Dans le cas où le modèle analytique n’est pas disponible, on construit d’autres types de connaissances sur la base des signaux ou des règles issues des procédés ou des experts.
Dans le paragraphe suivant, nous allons voir d’autres méthodes de surveillance dites sans modèle qu’on appelle méthode à base de signal, capables de décider l’état de fonction-nement des processus à partir juste des signaux de sortie (sans passer par le calcul des RRA).
2.5.2
Méthodes à base du signal
Les méthodes à base de signal, comme leur nom l’indique, ne disposent pas de modèle décrivant le comportement normal et le(s) comportement(s) défaillant(s) du système. Dans la littérature, on trouve les méthodes à base d’Intelligence Artificielle. Près de 70 % de toutes les installations d’IA au sein de l’industrie lourde se composent de systèmes experts; les autres sont formés de réseaux neuronaux, reconnaissance des formes (RDF) et de systèmes à logique floue [32].
Les systèmes experts servent à recueillir les connaissances et à émuler les techniques de résolution de problèmes provenant des meilleurs opérateurs humains et ce, dans des domaines
circonscrits et bien définis. Les réseaux neuronaux sont des réseaux de traitement de l’infor-mation qui règlent leur réponse sur la valeur de la donnée d’entrée. La plupart des applications font appel à la modélisation de prévision, à la classification et à la reconnaissance d’éléments récurrents. Les systèmes à logique floue sont des outils perfectionnés de résolution de pro-blèmes qui font appel à l’heuristique (art de bien deviner) et qui peuvent traiter des données d’entrée ambiguës.
2.5.2.1 Réseaux de neurones
Les réseaux de neurones sont un outil d’analyse statistique permettant de construire un modèle de comportement à partir d’un certain nombre d’exemples (constitués d’un certain nombre de variables descriptives) de ce comportement. Par exemple, en faisant apprendre à un réseau de neurones des descriptions d’emprunteurs d’argent (situation de famille, profession, etc.), avec leur comportement passé vis-à-vis du remboursement, on peut construire un modèle du risque associé aux descriptions des clients.
Si maintenant on demande des prédictions à ce modèle sur des nouveaux dossiers, on constate que le réseau de neurones prédit correctement si l’emprunteur sera bon, ou bien mauvais payeur dans 80 à 95% des cas. Il s’agit ici de ce que l’on appelle segmentation ou classification.
Le réseau de neurones, ”ignorant” au départ, réalise un ”apprentissage” à partir de ces exemples et devient, par modifications successives, un modèle rendant compte du compor-tement observé en fonction des variables descriptives.
La construction du modèle est automatique et directe à partir des données, elle ne nécessite pas d’intermédiaire rare ou coûteux comme un expert.
Il est possible, par exemple, d’apprendre à associer des relevés de mesures sur une machine-outil à ses pannes : le prédicteur obtenu réalise une maintenance préventive en indiquant la possibilité de panne dès que les mesures prennent des valeurs qu’il estime suspectes (ou un diagnostic à partir des derniers relevés si on est arrivé trop tard). Ceci s’est beaucoup fait, par exemple pour le diagnostic vibratoire des machines tournantes [91]. L’utilisation des réseaux de neurones s’est largement répondu ces dernières années par l’obtention de modèles dans le domaine chimique. Toutefois, leur limite reste liée à l’étape de l’apprentissage sur les procédés
2.5.2.2 Reconnaissance des formes (RdF)
La méthode à base de reconnaissances des formes (RdF) est la plus utilisée dans le domaine de la supervision à base de signal. Elle est utilisée surtout quand les observations sont de type numérique (issues des capteurs), mais les modèles mathématiques correspondants à chaque mode de fonctionnement du système ne sont pas construits à cause de la complexité physique du système.
2.5. Méthodes de surveillance 19 Le diagnostic par RdF, se présente comme une solution alternative à l’approche par modèle puisque les modes de fonctionnement sont modélisés, pas de manière analytique, mais en utilisant uniquement un ensemble des mesures de ces modes, générant ainsi des domaines de fonctionnement [8].
La RdF est la science qui se base sur la définition d’algorithmes permettant de classer des objets ou des formes en le comparant à des formes types [6]. Ses applications interviennent dans des domaines tels que la connaissance vocale, la reconnaissance de caractères, l’automa-tisation industrielle, le diagnostic médical et la classification des documents. Deux types de RdF sont à distingués :
- la RdF structurelle qui se base sur une représentation des formes à l’aide de grammaires, - la RdF statistique qui s’appuie sur une représentation purement numérique des formes. Dans le domaine industriel, la RdF statistique est la plus utilisée, dont on définit la forme par un ensemble de n paramètres, appelés aussi caractères. L’espace est constitué à l’aide d’une base dont chaque élément est associé à un caractère, cet espace est appelé espace de représentation. Une forme est représentée par un point dans l’espace de dimension n. A cause du bruit, à chaque forme type, on associe une zone géométrique et par conséquent une classe Wi (Fig. 2.7), tel que xi représente la valeur du ième caractère ou composant de vecteur
forme x. Le problème de la reconnaissance des formes est de trouver les frontières qui séparent les classes ([91], chapitre 6).
xn x2 x1 W1 W2 W3 Wm
Fig. 2.7 — Principe du problème de la reconnaissance des formes
Diverses méthodes d’obtention de frontières existent, dépendent du degré de connaissance que l’on a du problème: connaissance complète, partielle ou nulle de la modélisation pro-babiliste des classes. La RdF permet le diagnostic des systèmes, il suffit juste de définir les domaines suivants:
être utilisés pour le diagnostic. Ils ont été choisis pour leur pertinence vis à vis du problème posé.
B- Les modes de fonctionnement sont représentés par des classes. La caractérisation d’un mode de fonctionnement devient la caractérisation d’une classe.
Une fois que les deux domaines sont spécifiés et après avoir déterminé les frontières entre les classes, un système de diagnostic peut être construit, tout en associant à chaque classe une décision et une interprétation possible (mode de fonctionnement). Cependant tous les modes de fonctionnement ne sont pas connus a priori lors de la construction d’un système de diagnostic. Ils existent d’autres méthodes appelées avec rejet qui sont aptes à prendre en considération l’ignorance de certaines classes. On cite le rejet d’ambiguïté [29], si le vecteur x ne peut pas faire partie des classes M déjà définies, et le rejet de distance [32] et ([91], chapitre 6), qui lui est basé sur la distance aux classes. Une observation sera jugée éloigner des classes si sa densité de probabilité est trop faible (inférieure à un seuil).
La qualité du diagnostic dépend pour ces méthodes de celle des descripteurs et donc de l’étape d’apprentissage effectuée sur le procédé réel.
2.5.2.3 Conclusion
Dans le diagnostic à base de signal des processus, l’étape de la décision (Choisir dans quel mode se situe le fonctionnement du système (défaillant ou pas)) se déclenche au fur et à mesure de la réception des données. Toutefois l’avantage principales réside dans le fait qu’un modèle analytique (sous forme d’équation mathématique) n’est pas nécessaire. Ce type de méthode est plutôt bien adapté aux processus stationnaires où les caractéristiques et la structure des procédés ne varient pas.
2.6
Procédures de décisions
2.6.1
Problématique de la décision dans un système de diagnostic
Le modèle d’un système dynamique se met généralement sous la forme suivante: ˙ Z = f (Z,U,θ) Y = g(Z,U,θ) (2.8)
avec: U : entrées du système, considérées connues; Y : sorties, mesurées;
Z: vecteur d’état (inconnu); θ: paramètres (connus);
2.6. Procédures de décisions 21 f et g, fonctions linéaires ou non linéaires;
Une fois le modèle établi, la démarche de la redondance analytique est appliquée comme suit:
Il s’agit d’éliminer les composantes du vecteur d’état, qui sont des variables inconnues, pour ne conserver que des relations entre l’entrée, la sortie et leurs dérivées. Ceci se fait par projection des équations du modèle dans un espace particulier appelé ”espace de parité”.
Les relations obtenues, appelées relations de redondance analytique, sont de la forme:
ω1( _ y,_u,θ) = 0 ... ωq( _ y,_u,θ) = 0 (2.9)
où_y et_u représentent Y , U et leurs dérivées respectives jusqu’à un certain ordre de gran-deur. Les relations ωi peuvent être linéaires ou non selon les fonctions f et g. En remplaçant
les composantes _y et _u par leurs valeurs réelles, mesurées lors du processus on trouve:
ω1( _ y,_u,θ) = 0 ... ωq( _ y,_u,θ) = 0 = r1( _ y,_u,θ) = 0 ... rq( _ y,_u,θ) = 0 (2.10)
où le vecteur r = [r1,...,rq]T, est appelé résidu. Il représente l’écart entre ce qui est observé
et qui correspond au système réel, et ce qui est modélisé qui correspond au fonctionnement théorique normal.
Généralement le résidu (r) est différent de zéro dans les différents modes de fonctionne-ment du système, à cause des bruits de mesures, l’imprécision des appareils de mesures, des paramètres des composants qui constituent le processus, ainsi que l’évaluation numérique de la dérivée quand elle existe. La décision peut être effectuée à l’aide d’un simple test de seuil, des moyennes mobiles des résidus, ou faire appel à la théorie statistique de décision. L’éva-luation des résidus peut être booléenne, son but est d’attribuer un facteur de croyance à un ensemble de défaillances [50]. La combinaison des informations peut être effectuée à l’aide de la théorie de l’évidence [75] ou en utilisant des fonctions floues. Dans ce qui suit, nous allons nous intéresser aux méthodes statistiques de décision.
2.6.2
Procédures statistiques de décision
En général, le diagnostic à base de modèle insiste sur la connaissance du comportement des composants et sur la structure du processus à diagnostiquer (la liste des composants qui le constituent et les connexions entre eux). Sa difficulté réside dans la détermination de la valeur du seuil ε à partir de laquelle un résidu est en fonctionnement anormal. Une fois ce test est appliqué sur l’ensemble des résidus ri, il conduit à un vecteur binaire cohérent
C = ·
c1 c2 ... cn
¸
. Chaque composant ci de C est obtenu en utilisant la règle suivante:
ci = 1 si ri> ε sinon ci = 0 (2.11)
La structure du résidu est un vecteur binaire Vb qui exprime quelles sont les mesures qui
influent sur la valeur du résidu.
Vb(i) = 1 si le résidu contient la ième mesure
V (i) = 0 sinon
(2.12)
Les procédures de décision que nous allons développer par la suite, sont basées uniquement sur les résidus générés par les RRA. En comparant avec les méthodes de génération de rési-dus basées sur les observateurs ([48], [52]) la méthode basée sur les relations de redondance analytique présente quelques caractéristiques intéressantes:
— elle est simple à comprendre,
— les RRA peuvent être générées sous forme symbolique et donc adaptées à une implé-mentation informatique (réelle).
Position du problème de détection:
On suppose qu’il existe un système dynamique (statistique) stochastique à temps discret (équation. 2.13)
Y (k) = g(X(k),θ(k),ζ(k),k) (2.13)
où Y (k) est le vecteur des mesures, X(k) le vecteur d’état inconnu, ζ(k) représente le bruit et θ(k) le vecteur paramètre du modèle. Dans les conditions normales de fonctionnement, on a θ(k) = θ0.
Si une panne se produit à un instant inconnu k0, le vecteur paramètre devient θ1 [2].
Le problème à résoudre est la détection de la présence de la panne dans le plus bref délai, avec le minimum possible de fausses alarmes et de localisations erronées. Les algorithmes de
2.6. Procédures de décisions 23 décision doivent calculer le couple (N,µ) sur la base des observations Y (i)i=1...n, où N est
l’instant de détection de la panne et µ représente la décision finale.
Définition 11 :on appelle hypothèse simple Hj une hypothèse qui définit de façon unique la
distribution de l’échantillon Y (1),Y (2)...Y (n) et que l’on note : Hj = {Y (1),Y (2),...,Y (n)˜Pj},
j = 1,2,...,K où Pj est la probabilité d’existence
Définition 12 :on appelle un test statistique (règle de décision) de choix entre K hypothèses H1,H2,...,Hk, une application surjective de l’espace des échantillons sur l’ensemble des
hypo-thèses envisagées δ : y −→ {H1,H2,...,Hk}.
Définition 13 :on appelle probabilité d’erreur du jème espèce du test δ la probabilité de rejeter l’hypothèse Hj lorsqu’elle est vraie :
αj = Prj(δ(Y (1),Y (2),...,Y (n)) 6= Hj), j = 1,2,...,K
Après la détermination des relations de redondance analytique, les résidus sont calculés en remplaçant les variables par les données réelles issues du processus (les mesures et les paramètres des composants). Les algorithmes de décision ont pour but de vérifier si le système est en bon état de fonctionnement ou pas (Fig. 2.8).
y Indicateurs de défauts Oui Non =0 ? Algorithme de surveillance y Indicateurs de défauts Oui Non =0 ? Algorithme de surveillance
Ces algorithmes se retrouvent à devoir confrontés à trancher entre plusieurs hypothèses de fonctionnement. Pour simplifier, on traite le cas de deux hypothèses de fonctionnement H0
et H1, tel que:
— H0 est l’hypothèse du bon fonctionnement du processus surveillé, dont l’équation d’état
est sous la forme suivante (équation. 2.14):
. x(t) = f (x,u,t,η) y(t) = g(x,ζ) (2.14)
où u : entrée du système; y : sortie;
x : vecteur d’état; η : paramètres; t : temps; ζ : bruit et
f et g: fonctions linéaires ou non.
Dire que le système est en bon fonctionnement, consiste à dire que y est produit selon la loi g, x est produit selon la loi f et ζ est produit selon la loi P0. P0est la densité de probabilité
du bruit ζ.
— H1est l’hypothèse alternative de H0. Le système est en fonctionnement défaillant à cause
du fait que y ne suit pas la loi g (y(t) 6= g(x,ζ)), ou bien parce quex(t) 6= f(x,u,t,η) ou. c’est le bruit ξ qui ne suit pas la loi de distribution P0.
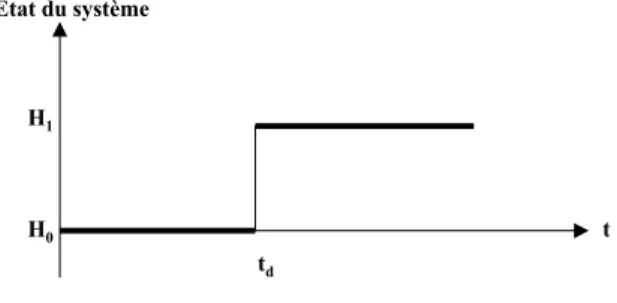
Problème: Etant donné la trajectoire des signaux y(t)t=1....N observés, il s’agit de vérifier
si H0 est vraie ou pas? Autrement dit, il faut déterminer s’il y a une rupture dans le système
et si oui à quel instant td(Fig. 2.9)?.
H0 H1
Etat du système
t td
2.6. Procédures de décisions 25 Détection de rupture:
Détecter les ruptures dans les processus physiques, revient à vérifier si H0 est vraie sur
tous les échantillons (de 1 à N ) contre H0 qui est vraie entre 1 et td et H1 entre td+1 et N
(Fig. 2.9). Sachant que les deux tests sont aléatoires, on doit définir deux lois de distribution qui dépendent de l’instant td. Il s’agit d’une distribution paramètrée par tdque l’on ne connaît
pas. D’où la solution de tester ”H0 entre 1 et N ” qu’on note domaine D0 contre ”H1 entre 1
et N ”, domaine D1 (Fig. 2.10). Pratiquement cette solution a l’inconvénient de détecter les
pannes avec un certain retard:
Si H0 est vraie alors z =¡ y(1) y(2).. y(N )
¢
est distribué selon P (z/H0)
(sachant que le bruit suit une loi normaleN (θ0,P))
⇒ le résidu calculé suit la loi normale N(θ0,wPwt)
Si H1est vraie alors z =
¡y(1) y(2).. y(N )
¢
est distribué selon P (z/H1)
⇒ le résidu calculé suit la loi N(θ1,wPwt) (θ1 est fixée)
avec: P (z/Hk) est la probabilité d’existence de z sachant que Hk est vraie.
D1 D0 Z2 Z1 D1 P(z/H1) P(z/H0)
Fig. 2.10 — Schéma statistique de la distribution des deux hypothèses
Rappelons que le problème est de déterminer dans quel domaine se trouve le système étudié (Fig. 2.10). Si la partition des z se trouve dans l’une des deux zones séparées (D0
ou D1), il est facile de décider si le système est en bon état de fonctionnement ou pas. Par
contre si cette partition se trouve dans la zone où les deux domaines sont chevauchés, il est impossible de conclure sur l’état du fonctionnement du système. Le but dans ce cas est de chercher une séparatrice des deux domaines avec le minimum possible de fausses alarmes. Le problème se transforme à la connaissance du critère qu’il faut optimiser pour éviter les fausses alarmes.
La résolution de ce problème oblige à connaître deux hypothèses. La première est la connaissance des probabilités a priori d’occurrence des hypothèses H0 et H1. La deuxième
hypothèse est relative à la connaissance des fonctions des coûts relatives aux décisions du domaine D0 ou D1. Le tableau suivant présente la relation décision/hypothèse dans le cas
d’un test entre deux hypothèses (théorie des jeux, Tab. 2.1):
H0 H1
D0 Bon fonctionnement Non détection ”nd”
D1 Fausse alarme ”f a” Mauvais fonctionnement
Tab. 2.1 — Principe de la théorie des jeux
Seules les décisions D0/H0et D1/H1sont des décisions correctes, la décision D0/H1
repré-sente une fausse alarme (ou un risque de première espèce) car le système est déclaré défaillant alors qu’en réalité il fonctionne normalement tandis que la décision D1/H0 correspond à une
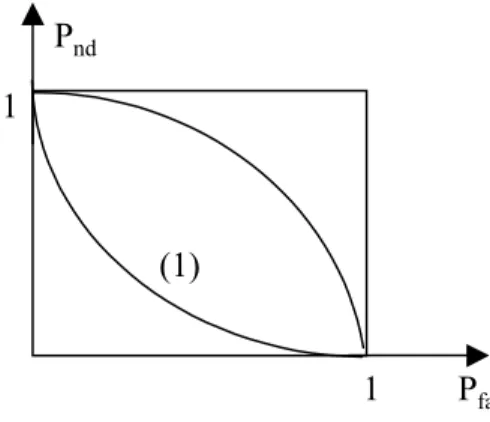
non détection (ou à une erreur de deuxième espèce) de la défaillance. Comme le montre la Fig. 2.11, il est impossible de réduire simultanément la probabilité de fausses alarmes Pf a et
la probabilité de non détection Pnd. Il s’agit en effet de faire un compromis.
Fig. 2.11 — Représentation du test binaire de décision
Les différentes méthodes que nous allons décrire dans ce chapitre concernent: — le nombre K d’hypothèses Hk,
— la connaissance des lois Pk a priori de probabilité de Hk,
— le nombre d’échantillons de l’espace d’observation, — les coûts associés à chaque décision,
— une fonction de coût globale R,
— la connaissance des lois conditionnelles de densité de probabilité des observations Py/Hk(Y /Hk),
2.6. Procédures de décisions 27 2.6.2.1 Diagnostic hors ligne
Algorithme de Bayes
Le test de bayes permet de prendre une décision fondée sur les coûts affectés à chaque alternative et donc de réaliser des compromis vis à vis des différentes situations. Ce test considère que le nombre d’hypothèses et leurs probabilités sont connus. Avec cette méthode, les coûts associés à chaque décision et les probabilités a priori associées à chaque hypothèses sont connus. Sur la Fig. 2.12) sont tracées, en fonction des différents paramètres qui peuvent influencer les décisions, les courbes de COR dites ”courbes caractéristiques du récepteurs”. Pour une valeur du paramètre considéré, on trace le point dans le plan (Pf a,Pnd). Ce paramètre
peut être la valeur de la probabilité P0, de la variance σ2, la moyenne du bruit, etc... .
(1) 1
1 Pnd
Pfa
Fig. 2.12 — Schéma de principe pour la minimisation de l’un des paramètres (courbe de COR) Minimiser le coût des fausses alarmes ou de non détection revient à tracer la tangente à la courbe (1) (Fig. 2.12) qui a comme pente α
β tel que αPnd est le coût de non détection et βPf a est le coût des fausses alarmes. Cela revient à minimiser le coût moyen qui est égale à la
somme des deux coûts: Cmoy = αPnd+ βPf a. Le problème devient dans ce cas, la recherche
du domaine D = D 0∪ D1, tel que Pf a et Pnd minimisent αPnd+ βPf a pour α et β donnés:
- Pour le cas des fausses alarmes:
z est distribué selon P (z/H0) alors qu’on signale le domaineD1 :
pf a = p(H0).p(z ∈ D1/H0) tel que p(z ∈ D1/H0) = R
D1p(z/H0)dz - Pour les non détections:
z est distribué selon P (z/H1) alors qu’on signale le domaine D0 :
pnd = p(H1).p(z ∈ D0/H1)
αPnd+ βPf a= α.p(H1) + R D1[β.p(H0)p(z/H0) − αp(H1)p(z/H1)]dz = α.p(H1) + R D1Ψ(z)dz avec : Ψ(z) = β.p(H0)p(z/H0) − αp(H1)p(z/H1) (2.15)
d’où l’objectif de chercher le domaine D1 qui minimise Ψ(z) :
Λ(z) =p(z/H1) p(z/H0) > η = β α p(H0) p(H1) l’hypothèse H1 Λ(z) =p(z/H1) p(z/H0) < η = β α p(H0) p(H1) l’hypothèse H0
tel que Λ(z) est appelé le rapport de vraisemblance de densités de probabilités condition-nelles et η est le seuil de détection.
Test du Minimax
Les tests bayésiens font l’hypothèse explicite que les probabilités a priori des hypothèses sont connues. Au plan théorique cela ne pose pas de problème particulier mais par contre pour un système industriel, il est rare de disposer de données fiables pour ces valeurs. Seul un retour d’expérience de qualité portant sur un grand nombre de matériels identiques est capable de fournir des informations crédibles. Pour cette raison, d’autres techniques ont été développées pour fixer les zones de décision sans connaître les probabilités à priori tout en minimisant la fonction du coût. Le test de Minmax, dans le cas binaire, consiste à sélectionner la valeur de la probabilité à priori P qui maximise le risque tout en minimisant la fonction du coût R. Ce test suppose également que les coûts Cij associés à chaque décision Dij sont connus. Comme
P (H0) + P (H1) = 1, on peut reformuler la fonction du coût en fonction de P1 selon:
R = C00(1 − Pf a) + C10Pf a+ P (H1)[(C11− C00) + (C01− C11)Pnd− (C10− C00)Pf a]
Si on fixe la probabilité P1 pour une valeur comprise entre 0 et 1, on retombe dans le cas
bayésien pour lequel la décision est prise en prenant la rapport de vraisemblance [4]: Λ(R) < (1 − P (H1))(C10− C00) P (H1)(C01− C11) Hypothèse H0 Λ(R) > (1 − P (H1))(C10− C00) P (H1)(C01− C11) Hypothèse H1 (2.16)
Test de Neyman Pearson
Ce test ne fait aucune hypothèse sur la probabilité a priori des hypothèses Hk. Les
pro-babilités conditionnelles associées à Pf a et Pd sont supposées connues et le test consiste à
2.6. Procédures de décisions 29 fixée à un seuil. Comme nous avons Pd+ Pnd= 1, cela est équivalent à minimiser la
probabi-lité de non détection P nd
M in Pnd sachant que Pf a ≤ a
Cela revient à tracer la limite Pf a = a et ensuite la tangente qui passe par le point
d’intersection de la courbe (1) avec cette limite (Fig. 2.12). Test progressif de Wald (SPRT)
Pour le test de Wald, ou test séquentiel du rapport de vraisemblance (SPRT), l’objectif est toujours le même. Il faut décider entre deux hypothèses concernant un paramètre θ (une moyenne ou une variance):
H0: θ = θ0 H1: θ = θ1
La différence est qu’on calcule au fur et à mesure de l’obtention des mesures, une fonction de ces dernières qui est confrontée à deux limites correspondantes au refus et à l’acceptation d’une hypothèse. Après chaque mesure, une des trois décisions suivantes est prise :
1. accepter H0 2. accepter H1 3. n’accepter ni H0 ni H1
l’acceptation de l’une des deux premières hypothèses ou la non prise de décision s’effectuent grâce au test du rapport de vraisemblance. En fixant la valeur α des risques d’erreurs et β pour le rejet des l’hypothèses H0 et H1 quand elles sont vraies:
Λ(z) =p(z/H1) p(z/H0) < β 1 − α on accepte H0 Λ(z) =p(z/H1) p(z/H0) > 1 − β α on accepte H1 β 1 − α < Λ(z) < 1 − β
α on décide rien, on poursuit le calcul 2.6.2.2 Diagnostic en ligne
Test de Page (Cusum)
Le point de départ de la théorie des tests d’hypothèses statistiques repose sur le fait que toutes les observations Y (1),Y (2)...Y (n) sont issues de l’une des distributions P1,P2...Pk, ou
le fait d’avoir des observations équidistribuées. Supposons maintenant que les observations P1, P2..Pk−1 sont issues de la distribution P (H0) et que les observations Y (k),Y (k + 1) sont
issues de la distribution P (H1). On appelle instant de rupture td l’instant à partir duquel la
distribution de Y (i) soit P (H1).
Une solution optimale à ce problème est constituée par l’algorithme de la somme Cumulée (Cusum) proposé par Page ([62],[2]). Celui ci est fondé sur la comparaison à chaque instant de la différence entre la valeur du rapport de vraisemblance et sa valeur minimale courante avec un seuil h donné:
Z(n,1) − min 0≤k<nZ(k,1) = max1≤k≤nZ(n,k) Z(n,k) = n P i=kln f1(Y (i)) f0(Y (i))
tel que f0(Y (i)) et f1(Y (i)) représente la densité de probabilité de l’occurrence de Y (i)
sous H0 et H1 respectivement.
L’intérêt de ce test est l’estimation qu’il peut apporter de l’instant de rupture dans un signal: td= inf ½ n ≥ 1 : max 1≤k≤nZ(n,k) ≥ h ¾ td= inf {n ≥ 1 : g(n) ≥ h} g(0) = 0 (2.17)
avec g(n) = max(0,g(n−1)+lnff1(Y (i))
0(Y (i))
). Cet algorithme est basé sur le fait que l’élément lnf1(Y (i))
f0(Y (i))
de la somme cumulée Z(n,1) change de signe en moyenne après la rupture. Supposant que le signal de sortie suit une loi gaussiènne, sa densité de probabilité sous l’hypothèse H 0 et H1 s’écrit sous la forme suivante:
f (z/H0) = 1 σ√2πexp(− (z − θ0)2 2σ2 ) f (z/H1) = 1 σ√2πexp(− (z − θ1)2 2σ2 )
tel que θ0, θ1représentent ses valeurs moyennes sous l’hypothèse H0 et H1 respectivement
et σ son écart type.
en calculant le rapport lnf (z/H1) f (z/H0) on trouve: g0 = 0 g(n) = sup(0,(g(n − 1) + y(n) − θ0− ν 2)) td= min{n ≥ 1 : g(n) ≥ γ} (2.18)